
SlowR50-SA: A Self-Attention Enhanced Dynamic Facial Expression Recognition Model for Tactile Internet Applications

 , ,
, ,  and
and 
Abstract
1. Introduction
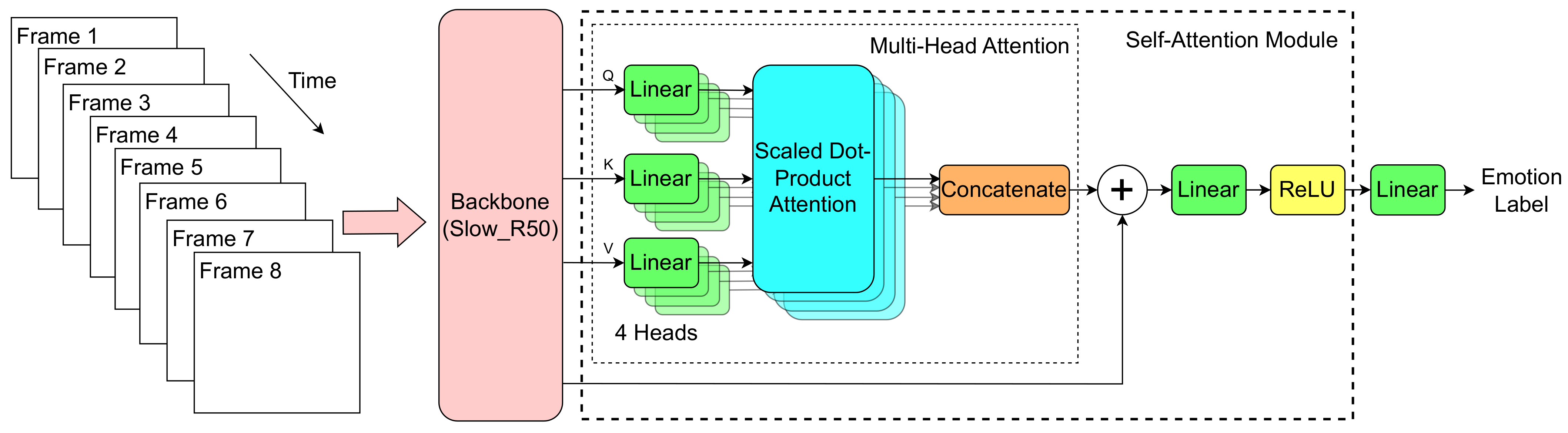
- Presenting a novel deep learning architecture for DFER, the model effectively extracts spatiotemporal features using the SlowR50 (8 × 8) model. This architecture integrates a slow pathway with low temporal resolution for capturing long-range temporal information and identifying subtle changes in facial expressions. The inclusion of an SA module further refines the feature vector, dynamically attending to relevant spatial and temporal details, enhancing the representation of nuanced facial expressions.
- The proposed algorithm achieves superior performance on benchmark datasets (DFEW and FERV39K) compared to state-of-the-art methods, demonstrating its effectiveness in Dynamic Facial Expression Recognition. The model outperforms competitors in terms of both UAR and WAR, showcasing its capability to accurately classify emotions.
- The model demonstrates computational efficiency by achieving state-of-the-art results with only eight frames of input. This efficiency, combined with its high performance, positions the algorithm as a promising candidate for real-world applications, especially in TI scenarios, where it can effectively recognize and respond to facial expressions with reduced computational cost.
2. Related Work
3. Algorithm Description
3.1. Proposed Model
3.2. Implementation Details
4. Experiments
4.1. Datasets
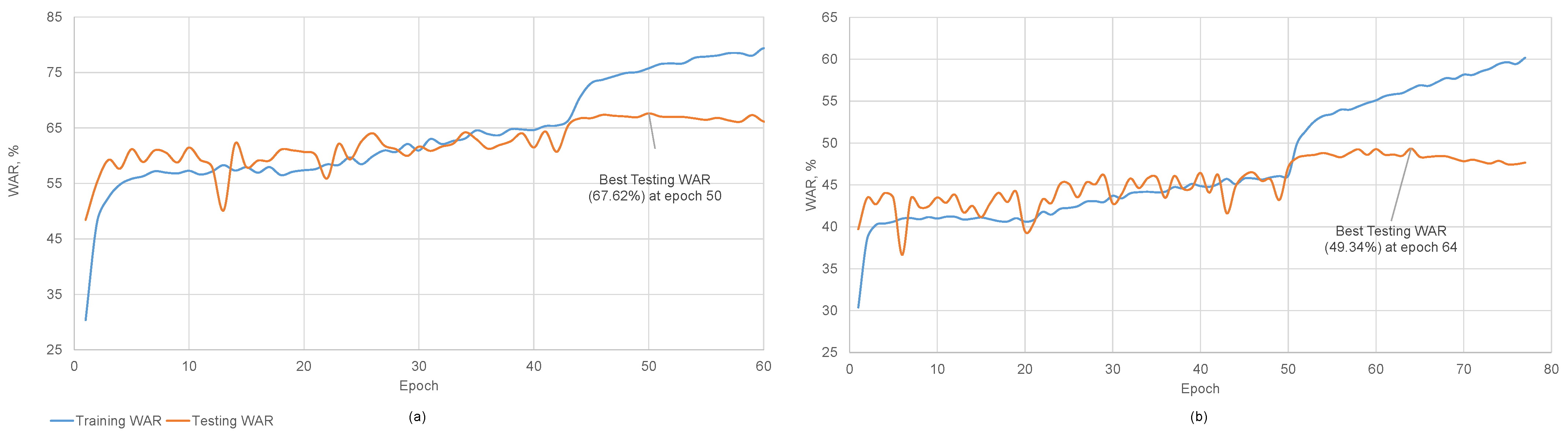
4.2. Experimental Protocol
4.3. Comparison of the Proposed Method with the State-of-the-Art Methods
4.4. Ablation Study on Self-Attention Module
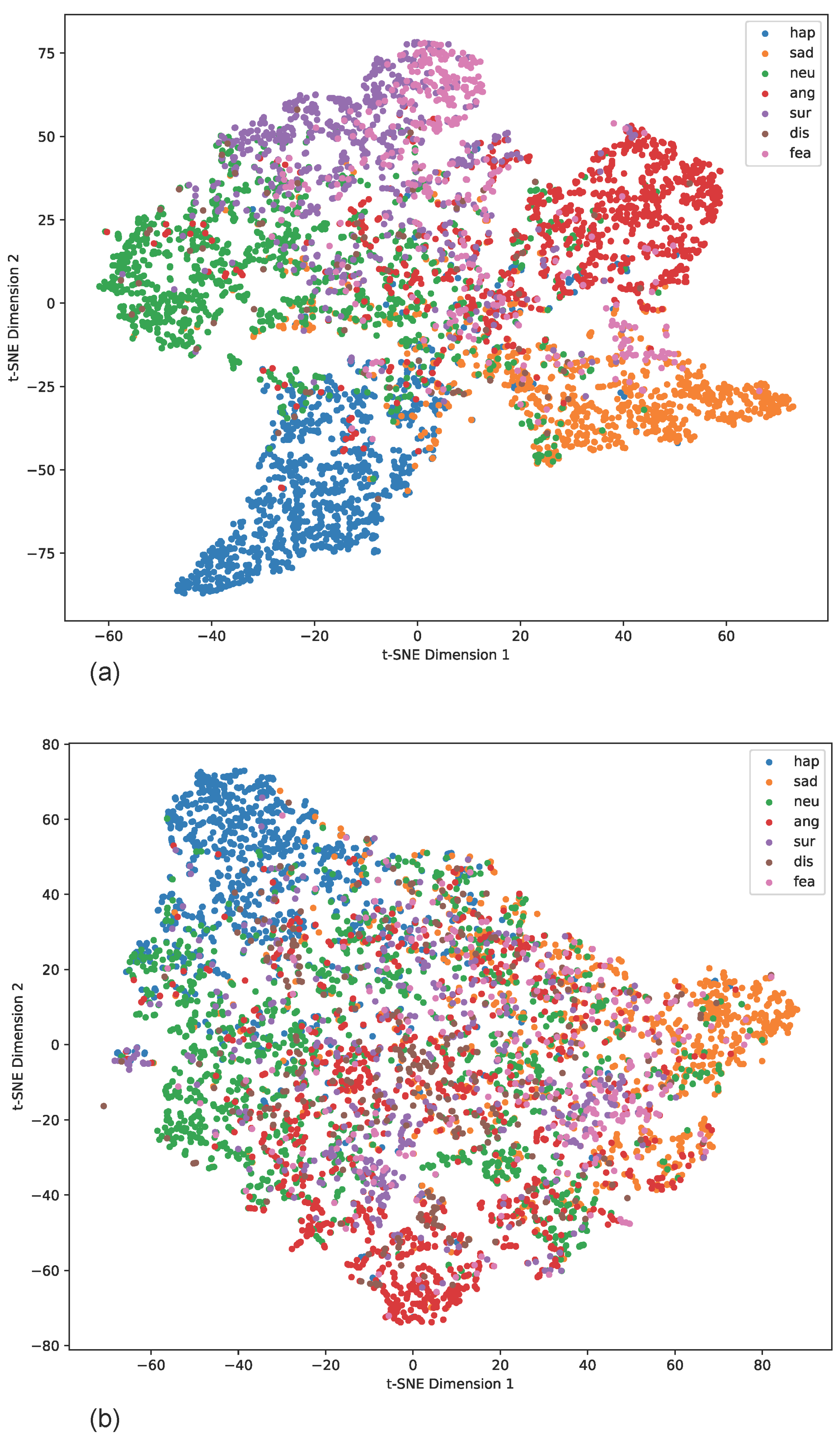
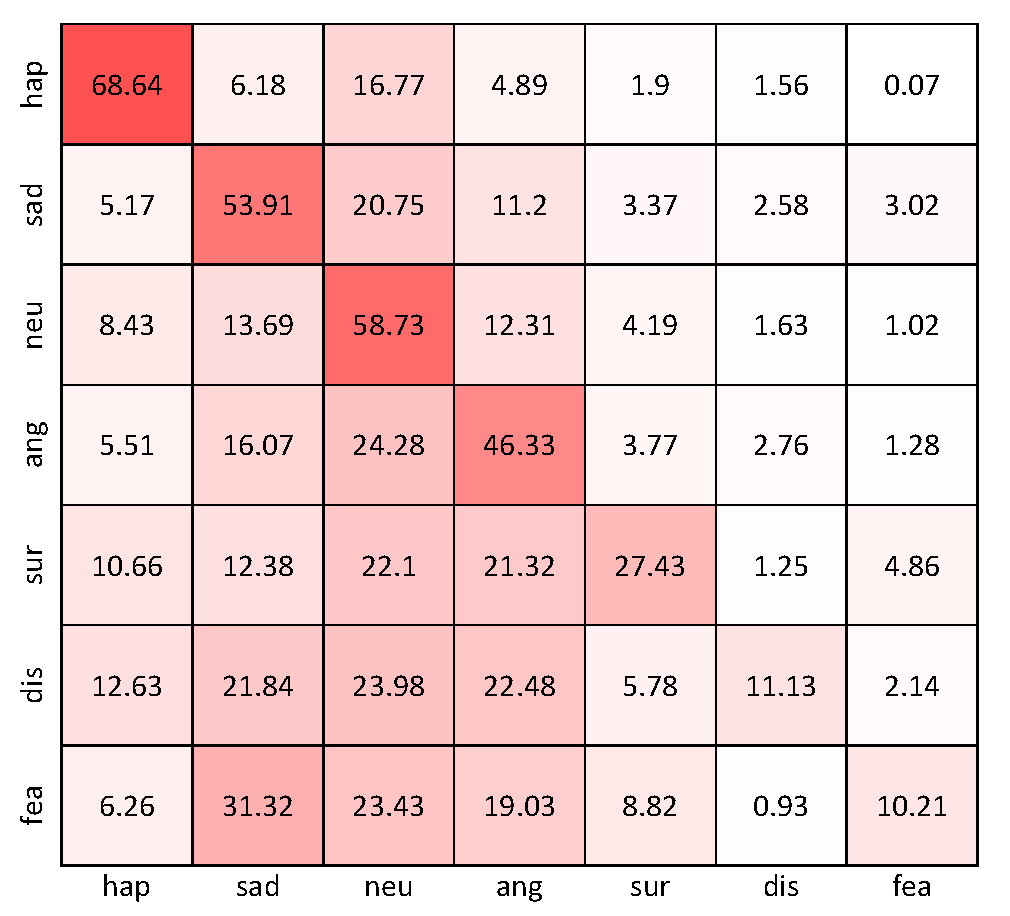
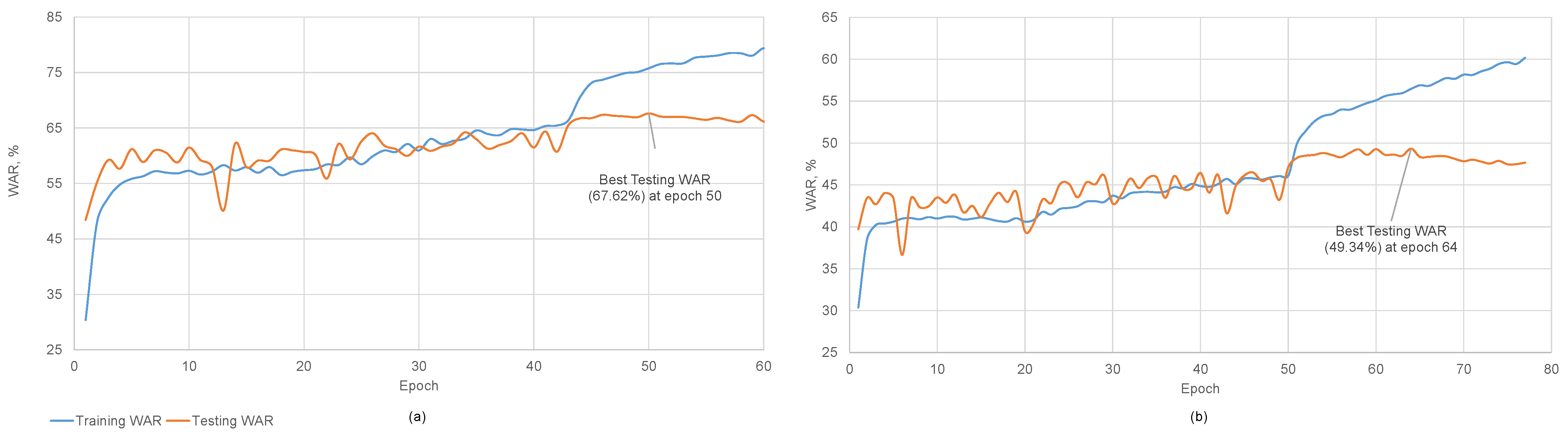
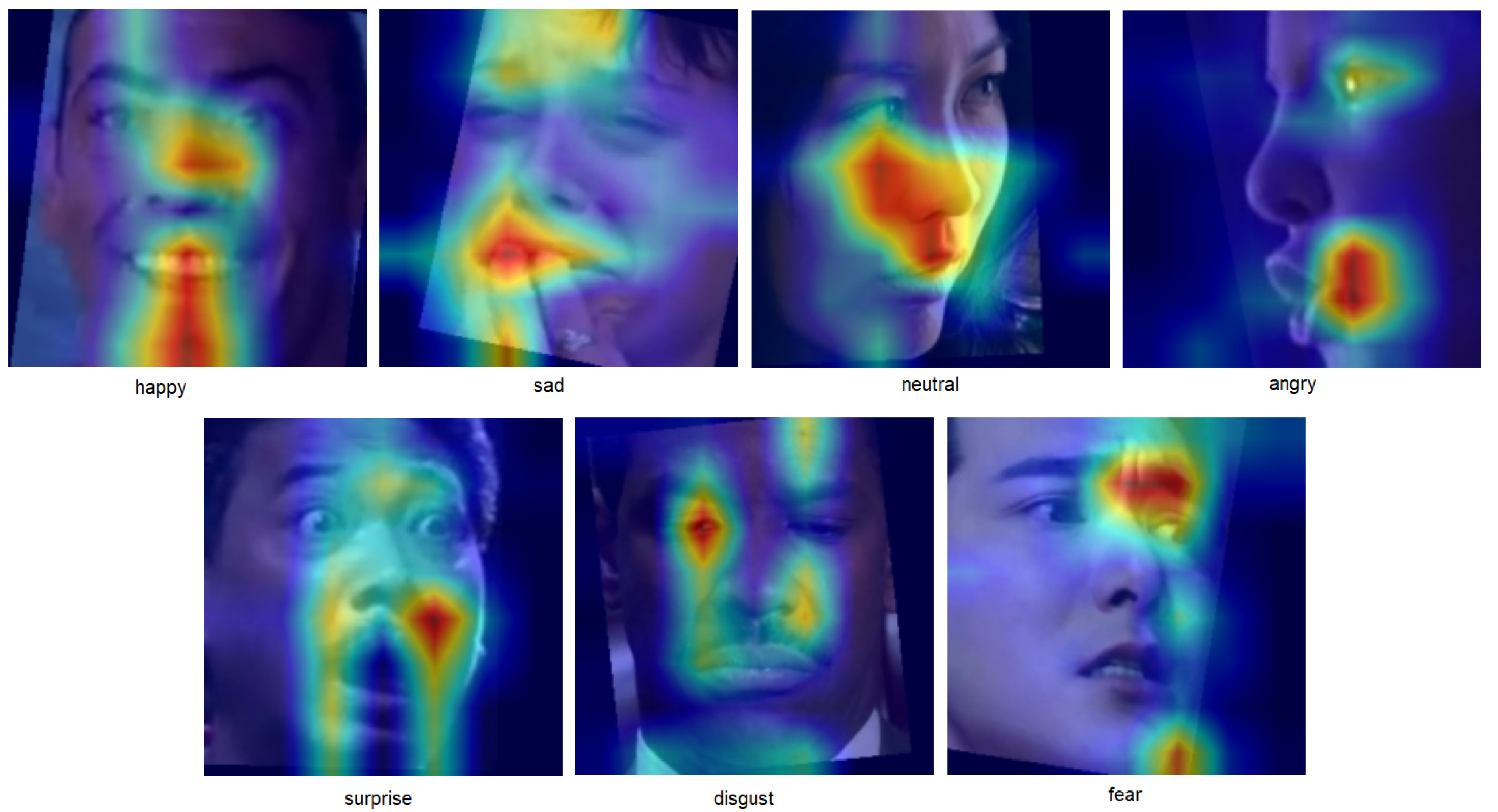
4.5. Detailed Results
4.6. Limitations of the Presented Work
- While the proposed SlowR50-SA algorithm demonstrates superior performance on the DFEW and FERV39K datasets, its property to generalize to other datasets or real-world scenarios remains untested. The datasets used may not fully represent the diversity of facial expressions encountered in real-world settings, potentially limiting the algorithm’s applicability in practical situations.
- Both DFEW and FERV39K datasets may suffer from class imbalance issues, which can affect the model’s performance, especially for minority classes such as disgust and fear. Imbalanced datasets may lead to biased models that prioritize majority classes, potentially resulting in lower accuracy for minority classes.
- The ablation study focuses solely on the addition of the Self-Attention module to the SlowR50 backbone. Further analyses, such as investigating the impact of different hyperparameters or architectural variations, could provide deeper insights into the algorithm’s performance and help optimize its design.
- Although the proposed algorithm achieves good performance with only eight frames of input, its computational efficiency in real-world applications, especially on resource-constrained devices or in real-time systems, remains unclear. Assessing the algorithm’s efficiency in practical deployment scenarios is essential for its feasibility in TI applications.
- Generalization to diverse datasets: We acknowledge the importance of evaluating the algorithm’s performance on a wider range of datasets, including those with more diverse facial expressions and real-world scenarios. Future work could involve testing the SlowR50-SA algorithm on additional datasets and assessing its robustness across various settings.
- Mitigating class imbalance issues: To mitigate the impact of class imbalance on model performance, future studies could explore techniques such as data augmentation, oversampling of minority classes, or using advanced loss functions tailored to handle imbalanced datasets. Additionally, efforts could be made to collect or curate datasets that better represent the distribution of facial expressions in real-world scenarios.
- Extended scope of ablation study: Further analysis could extend beyond the addition of the Self-Attention module to explore the effects of different hyperparameters, architectural variations, or alternative model components. Conducting comprehensive experiments would provide deeper insights into the algorithm’s behavior and aid in optimizing its performance.
- Evaluation of computational efficiency: Future research should prioritize assessing the algorithm’s computational efficiency in practical deployment scenarios. This could involve benchmarking the algorithm on resource-constrained devices, evaluating its runtime performance, and optimizing its implementation for real-time applications.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AR | Augmented Reality |
| AEN | Affectivity Extraction Network |
| CS-Former | convolutional spatial transformer |
| DCT | dynamic class tag |
| DFER | Dynamic Facial Expression Recognition |
| DFEW | Dynamic Facial Expression in-the-Wild |
| DLIAM | Dynamic Long-term Instance Aggregation Module |
| DSF | dynamic–static fusion module |
| EST | Expression Snippet Transformer |
| FC | Fully Connected |
| FLOPs | Floating Point Operations Per second |
| GCA | global attentional bias |
| GPU | Graphics Processing Unit |
| IAL | intensity-adaptive loss |
| LOGO-Former | local–global spatiotemporal transformer |
| MIL | multi-instance learning |
| M3DFEL | multi-3D dynamic facial expression learning |
| QoE | quality of experience |
| SA | Self-Attention |
| SF | fragment-based filter |
| TaHiL | Tactile Internet with Human-in-the-Loop |
| TI | Tactile Internet |
| T-Former | temporal transformer |
| UAR | Unweighted Average Recall |
| VR | Virtual Reality |
| WAR | Weighted Average Recall |
References
- Fanibhare, V.; Sarkar, N.I.; Al-Anbuky, A. A survey of the tactile internet: Design issues and challenges, applications, and future directions. Electronics 2021, 10, 2171. [Google Scholar] [CrossRef]
- Holland, O.; Steinbach, E.; Prasad, R.V.; Liu, Q.; Dawy, Z.; Aijaz, A.; Pappas, N.; Chandra, K.; Rao, V.S.; Oteafy, S.; et al. The IEEE 1918.1 “tactile internet” standards working group and its standards. Proc. IEEE 2019, 107, 256–279. [Google Scholar] [CrossRef]
- Oteafy, S.M.; Hassanein, H.S. Leveraging tactile internet cognizance and operation via IoT and edge technologies. Proc. IEEE 2018, 107, 364–375. [Google Scholar] [CrossRef]
- Ali-Yahiya, T.; Monnet, W. The Tactile Internet; John Wiley & Sons: Hoboken, NJ, USA, 2022. [Google Scholar]
- Xu, M.; Ng, W.C.; Lim, W.Y.B.; Kang, J.; Xiong, Z.; Niyato, D.; Yang, Q.; Shen, X.S.; Miao, C. A full dive into realizing the edge-enabled metaverse: Visions, enabling technologies, and challenges. IEEE Commun. Surv. Tutor. 2022, 25, 656–700. [Google Scholar] [CrossRef]
- Rasouli, F. A Framework for Prediction in a Fog-Based Tactile Internet Architecture for Remote Phobia Treatment. Ph.D. Thesis, Concordia University, Montreal, QC, Canada, 2020. [Google Scholar]
- Van Den Berg, D.; Glans, R.; De Koning, D.; Kuipers, F.A.; Lugtenburg, J.; Polachan, K.; Venkata, P.T.; Singh, C.; Turkovic, B.; Van Wijk, B. Challenges in haptic communications over the tactile internet. IEEE Access 2017, 5, 23502–23518. [Google Scholar] [CrossRef]
- Tychola, K.A.; Voulgaridis, K.; Lagkas, T. Tactile IoT and 5G & beyond schemes as key enabling technologies for the future metaverse. Telecommun. Syst. 2023, 84, 363–385. [Google Scholar]
- Amer, I.M.; Oteafy, S.M.; Hassanein, H.S. Affective Communication of Sensorimotor Emotion Synthesis over URLLC. In Proceedings of the 2023 IEEE 48th Conference on Local Computer Networks (LCN), Daytona Beach, FL, USA, 2–5 October 2023; pp. 1–4. [Google Scholar]
- Dar, S.A. International conference on digital libraries (ICDL)-2016 Report, Teri, New Delhi. Libr. Tech News 2017, 34, 8. [Google Scholar] [CrossRef]
- Akinyoade, A.J.; Eluwole, O.T. The internet of things: Definition, tactile-oriented vision, challenges and future research directions. In Proceedings of the Third International Congress on Information and Communication Technology: ICICT 2018, London; Springer: Berlin/Heidelberg, Germany, 2018; pp. 639–653. [Google Scholar]
- Gupta, M.; Jha, R.K.; Jain, S. Tactile based intelligence touch technology in IoT configured WCN in B5G/6G-A survey. IEEE Access 2022, 11, 30639–30689. [Google Scholar] [CrossRef]
- Steinbach, E.; Strese, M.; Eid, M.; Liu, X.; Bhardwaj, A.; Liu, Q.; Al-Ja’afreh, M.; Mahmoodi, T.; Hassen, R.; El Saddik, A.; et al. Haptic codecs for the tactile internet. Proc. IEEE 2018, 107, 447–470. [Google Scholar] [CrossRef]
- Alja’Afreh, M. A QoE Model for Digital Twin Systems in the Era of the Tactile Internet. Ph.D. Thesis, Université d’Ottawa/University of Ottawa, Ottawa, ON, Canada, 2021. [Google Scholar]
- Shamim Hossain, M.; Muhammad, G.; Al-Qurishi, M.; Masud, M.; Almogren, A.; Abdul, W.; Alamri, A. Cloud-oriented emotion feedback-based Exergames framework. Multimed. Tools Appl. 2018, 77, 21861–21877. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, W.; Feng, C.; Zhang, H.; Chen, Z.; Zhan, Y. Expression snippet transformer for robust video-based facial expression recognition. Pattern Recognit. 2023, 138, 109368. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Q. Former-dfer: Dynamic facial expression recognition transformer. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 1553–1561. [Google Scholar]
- Lee, B.; Shin, H.; Ku, B.; Ko, H. Frame Level Emotion Guided Dynamic Facial Expression Recognition With Emotion Grouping. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5680–5690. [Google Scholar]
- Li, H.; Sui, M.; Zhu, Z. Nr-dfernet: Noise-robust network for dynamic facial expression recognition. arXiv 2022, arXiv:2206.04975. [Google Scholar]
- Wang, H.; Li, B.; Wu, S.; Shen, S.; Liu, F.; Ding, S.; Zhou, A. Rethinking the Learning Paradigm for Dynamic Facial Expression Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17958–17968. [Google Scholar]
- Ma, F.; Sun, B.; Li, S. Spatio-temporal transformer for dynamic facial expression recognition in the wild. arXiv 2022, arXiv:2205.04749. [Google Scholar]
- Li, H.; Niu, H.; Zhu, Z.; Zhao, F. Intensity-aware loss for dynamic facial expression recognition in the wild. Proc. Aaai Conf. Artif. Intell. 2023, 37, 67–75. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 6202–6211. [Google Scholar]
- Pytorch.org, Instalation of Pytorch v1.12.1. Available online: https://pytorch.org/get-started/previous-versions/ (accessed on 25 March 2024).
- Jiang, X.; Zong, Y.; Zheng, W.; Tang, C.; Xia, W.; Lu, C.; Liu, J. Dfew: A large-scale database for recognizing dynamic facial expressions in the wild. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2881–2889. [Google Scholar]
- Wang, Y.; Sun, Y.; Huang, Y.; Liu, Z.; Gao, S.; Zhang, W.; Ge, W.; Zhang, W. Ferv39k: A large-scale multi-scene dataset for facial expression recognition in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20922–20931. [Google Scholar]
- Awesome Dynamic Facial Expression Recognition. Available online: https://github.com/zengqunzhao/Awesome-Dynamic-Facial-Expression-Recognition (accessed on 25 March 2024).
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 6299–6308. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3D residual networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5533–5541. [Google Scholar]
- Hara, K.; Kataoka, H.; Satoh, Y. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6546–6555. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Gildenblat, J. Contributors. PyTorch Library for CAM Methods. 2021. Available online: https://github.com/jacobgil/pytorch-grad-cam (accessed on 12 April 2024).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DFEW | FERV39K | |||
|---|---|---|---|---|
| Method | UAR (%) | WAR (%) | UAR (%) | WAR (%) |
| R(2+1)D-18 [20,28] | 42.79 | 53.22 | 31.55 | 41.28 |
| C3D [20,29] | 42.74 | 53.54 | 22.68 | 31.69 |
| I3D [20,30] | 43.4 | 54.27 | 30.17 | 38.78 |
| P3D [20,31] | 43.97 | 54.47 | 23.2 | 33.39 |
| EC-STFL [20,25] | 45.35 | 56.51 | - | - |
| 3D-ResNet18 [20,32] | 46.52 | 58.27 | 26.67 | 37.57 |
| ResNet18-LSTM [22,33,34] | 51.32 | 63.85 | 30.92 | 42.95 |
| Former-DFER [17,22] | 53.69 | 65.7 | 37.2 | 46.85 |
| EST [16,27] | 53.94 | 65.85 | - | - |
| Logo-Form [21,27] | 54.21 | 66.98 | 38.22 | 48.13 |
| ResNet18-ViT [27,33,35] | 55.76 | 67.56 | 38.35 | 48.43 |
| NR-DFERNet [19,27] | 54.21 | 68.19 | 33.99 | 45.97 |
| IAL [22] | 55.71 | 69.24 | 35.82 | 48.54 |
| M3DFEL [20] | 56.1 | 69.25 | 35.94 | 47.67 |
| AEN [18] | 56.66 | 69.37 | 38.18 | 47.88 |
| SlowR50-SA (proposed) | 57.09 | 69.87 | 39.48 | 49.34 |
| Method | UAR (%) | WAR (%) | Params (M) | FLOPs (G) |
|---|---|---|---|---|
| SlowR50 | 56.78 | 69.40 | 31.65 | 71.88 |
| SlowR50-SA | 57.09 | 69.87 | 49.47 | 71.92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Neshov, N.; Christoff, N.; Sechkova, T.; Tonchev, K.; Manolova, A. SlowR50-SA: A Self-Attention Enhanced Dynamic Facial Expression Recognition Model for Tactile Internet Applications. Electronics 2024, 13, 1606. https://doi.org/10.3390/electronics13091606
Neshov N, Christoff N, Sechkova T, Tonchev K, Manolova A. SlowR50-SA: A Self-Attention Enhanced Dynamic Facial Expression Recognition Model for Tactile Internet Applications. Electronics. 2024; 13(9):1606. https://doi.org/10.3390/electronics13091606
Chicago/Turabian StyleNeshov, Nikolay, Nicole Christoff, Teodora Sechkova, Krasimir Tonchev, and Agata Manolova. 2024. "SlowR50-SA: A Self-Attention Enhanced Dynamic Facial Expression Recognition Model for Tactile Internet Applications" Electronics 13, no. 9: 1606. https://doi.org/10.3390/electronics13091606
APA StyleNeshov, N., Christoff, N., Sechkova, T., Tonchev, K., & Manolova, A. (2024). SlowR50-SA: A Self-Attention Enhanced Dynamic Facial Expression Recognition Model for Tactile Internet Applications. Electronics, 13(9), 1606. https://doi.org/10.3390/electronics13091606