
Deep Convolutional Dictionary Learning Denoising Method Based on Distributed Image Patches



Abstract
1. Introduction
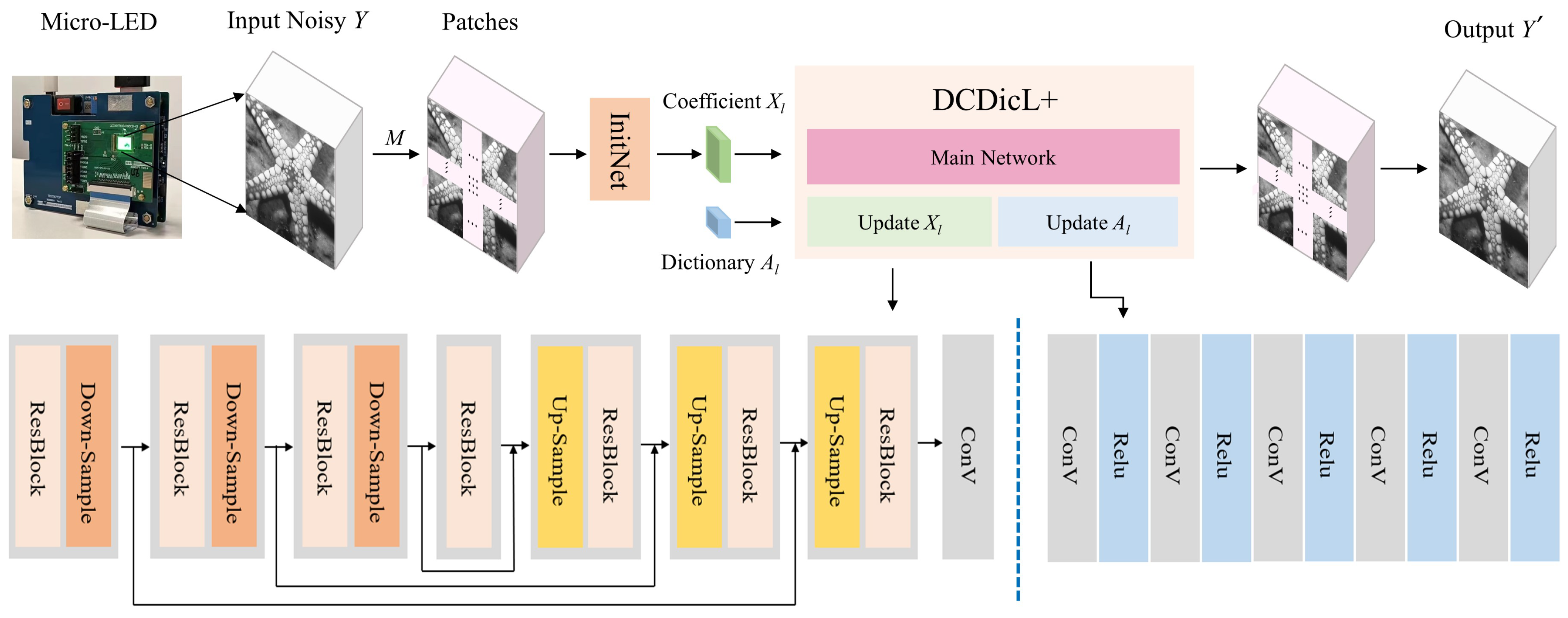
- Novel denoising method. An improved denoising method based on deep convolutional dictionary learning, where images are decomposed into small patches and adaptive dictionary learning is conducted, is proposed. This method provides a better representation of the fine structure of images, as both global and local features are incorporated, allowing for a more comprehensive representation of the fine structure present in images.
- Optimization algorithm. A new confidence-weighted fusion algorithm is developed to optimize the proposed method in our model; it can utilize the structures of the convolutional sparse coding structure, and local and global operators.
- Different applications. On the grayscale dataset Set12, compared with DCDicL, the PSNR and SSIM of the proposed method are increased by 3.87 dB and 0.0012 at the noise level of . On the color dataset Urban100, compared with DCDicL, the PSNR and SSIM of the proposed method are increased by 3.49 dB and 0.0133 at the noise level of .
2. Related Works
2.1. Patch Denoising
2.2. Convolutional Dictionary Learning
3. Methodology
3.1. Proposed Method
3.2. Optimization Algorithm
3.3. Confidence-Weighted Fusion of Image Patches
| Algorithm 1: DCDicL+ |
 |
4. Experimental Results
4.1. Parameter Settings
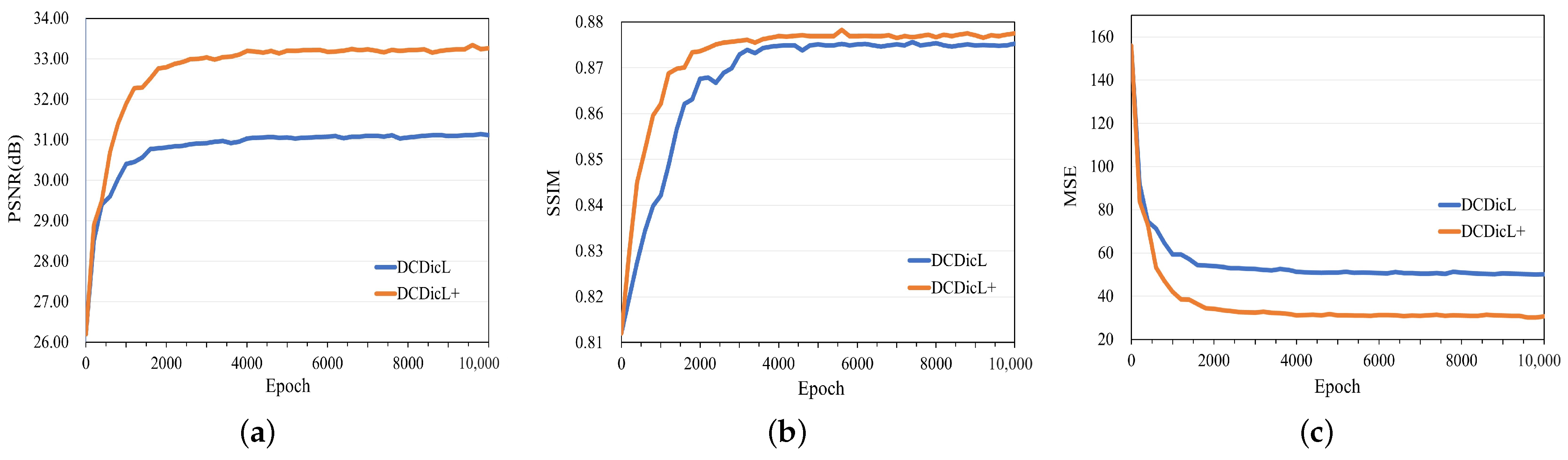
4.1.1. Training Iterations
4.1.2. Confidence Scaling Factor
4.2. Comparison Results
4.2.1. Grayscale Datasets
4.2.2. Color Datasets
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Anwar, A.R.; Sajjad, M.T.; Johar, M.A.; Hernandez-Gutierrez, C.A.; Usman, M.; Lepkowski, S. Recent progress in micro-LED-based display technologies. Laser Photonics Rev. 2022, 16, 2100427. [Google Scholar] [CrossRef]
- Lin, C.C.; Wu, Y.R.; Kuo, H.C.; Wong, M.S.; DenBaars, S.P.; Nakamura, S.; Pandey, A.; Mi, Z.; Tian, P.; Ohkawa, K.; et al. The micro-LED roadmap: Status quo and prospects. J. Phys. Photonics 2023, 5, 042502. [Google Scholar] [CrossRef]
- Chen, D.; Chen, Y.C.; Zeng, G.; Zhang, D.W.; Lu, H.L. Integration Technology of Micro-LED for Next-Generation Display. Research 2023, 6, 0047. [Google Scholar] [CrossRef]
- Pandey, A.; Min, J.; Reddeppa, M.; Malhotra, Y.; Xiao, Y.; Wu, Y.; Sun, K.; Mi, Z. An Ultrahigh Efficiency Excitonic Micro-LED. Nano Lett. 2023, 23, 1680–1687. [Google Scholar] [CrossRef]
- Zhu, G.; Liu, Y.; Ming, R.; Shi, F.; Cheng, M. Mass transfer, detection and repair technologies in micro-LED displays. Sci. China Mater. 2022, 65, 2128–2153. [Google Scholar] [CrossRef]
- Lin, J.; Jiang, H. Development of microLED. Appl. Phys. Lett. 2020, 116, 100502. [Google Scholar] [CrossRef]
- Chen, Z.; Yan, S.; Danesh, C. MicroLED technologies and applications: Characteristics, fabrication, progress, and challenges. J. Phys. D Appl. Phys. 2021, 54, 123001. [Google Scholar] [CrossRef]
- James Singh, K.; Huang, Y.M.; Ahmed, T.; Liu, A.C.; Huang Chen, S.W.; Liou, F.J.; Wu, T.; Lin, C.C.; Chow, C.W.; Lin, G.R.; et al. Micro-LED as a promising candidate for high-speed visible light communication. Appl. Sci. 2020, 10, 7384. [Google Scholar] [CrossRef]
- Hsiang, E.L.; Yang, Z.; Yang, Q.; Lan, Y.F.; Wu, S.T. Prospects and challenges of mini-LED, OLED, and micro-LED displays. J. Soc. Inf. Disp. 2021, 29, 446–465. [Google Scholar] [CrossRef]
- Zhang, X.; Yin, L.; Ren, K.; Zhang, J. Research on Simulation Design of MOS Driver for Micro-LED. Electronics 2022, 11, 2044. [Google Scholar] [CrossRef]
- Mohammed Abd-Alsalam Selami, A.; Freidoon Fadhil, A. A study of the effects of gaussian noise on image features. Kirkuk Univ. J.-Sci. Stud. 2016, 11, 152–169. [Google Scholar] [CrossRef]
- Fan, L.; Zhang, F.; Fan, H.; Zhang, C. Brief review of image denoising techniques. Vis. Comput. Ind. Biomed. Art 2019, 2, 7. [Google Scholar] [CrossRef] [PubMed]
- Buades, A.; Coll, B.; Morel, J.M. A review of image denoising algorithms, with a new one. Multiscale Model. Simul. 2005, 4, 490–530. [Google Scholar] [CrossRef]
- Tian, C.; Fei, L.; Zheng, W.; Xu, Y.; Zuo, W.; Lin, C.W. Deep learning on image denoising: An overview. Neural Netw. 2020, 131, 251–275. [Google Scholar] [CrossRef]
- Goyal, B.; Dogra, A.; Agrawal, S.; Sohi, B.S.; Sharma, A. Image denoising review: From classical to state-of-the-art approaches. Inf. Fusion 2020, 55, 220–244. [Google Scholar] [CrossRef]
- Yu, S.; Ma, J.; Wang, W. Deep learning for denoising. Geophysics 2019, 84, V333–V350. [Google Scholar] [CrossRef]
- Tomasi, C.; Manduchi, R. Bilateral filtering for gray and color images. In Proceedings of the Sixth International Conference on Computer Vision, Bombay, India, 4–7 January 1998; IEEE Cat. No. 98CH36271. IEEE: New York, NY, USA, 1998; pp. 839–846. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Srivastava, M.; Anderson, C.L.; Freed, J.H. A new wavelet denoising method for selecting decomposition levels and noise thresholds. IEEE Access 2016, 4, 3862–3877. [Google Scholar] [CrossRef] [PubMed]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Jalalzai, K. Some remarks on the staircasing phenomenon in total variation-based image denoising. J. Math. Imaging Vis. 2016, 54, 256–268. [Google Scholar] [CrossRef]
- Gu, S.; Zhang, L.; Zuo, W.; Feng, X. Weighted nuclear norm minimization with application to image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2862–2869. [Google Scholar]
- Yao, C.; Jin, S.; Liu, M.; Ban, X. Dense residual Transformer for image denoising. Electronics 2022, 11, 418. [Google Scholar] [CrossRef]
- Tian, C.; Xu, Y.; Fei, L.; Yan, K. Deep learning for image denoising: A survey. In Proceedings of the Genetic and Evolutionary Computing: Proceedings of the Twelfth International Conference on Genetic and Evolutionary Computing, Changzhou, China, 14–17 December 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 563–572. [Google Scholar]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning deep CNN denoiser prior for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3929–3938. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef] [PubMed]
- Alsaiari, A.; Rustagi, R.; Thomas, M.M.; Forbes, A.G.; Alhakamy, A. Image denoising using a generative adversarial network. In Proceedings of the 2019 IEEE 2nd International Conference on Information and Computer Technologies (ICICT), Kahului, HI, USA, 14–17 March 2019; IEEE: New York, NY, USA, 2019; pp. 126–132. [Google Scholar]
- Im Im, D.; Ahn, S.; Memisevic, R.; Bengio, Y. Denoising criterion for variational auto-encoding framework. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Simon, D.; Elad, M. Rethinking the CSC model for natural images. Adv. Neural Inf. Process. Syst. 2019, 32, 11. [Google Scholar]
- Scetbon, M.; Elad, M.; Milanfar, P. Deep k-svd denoising. IEEE Trans. Image Process. 2021, 30, 5944–5955. [Google Scholar] [CrossRef] [PubMed]
- Daubechies, I.; Defrise, M.; De Mol, C. An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Commun. Pure Appl. Math. A J. Issued Courant Inst. Math. Sci. 2004, 57, 1413–1457. [Google Scholar] [CrossRef]
- Zheng, H.; Yong, H.; Zhang, L. Deep convolutional dictionary learning for image denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 630–641. [Google Scholar]
- Bian, S.; He, X.; Xu, Z.; Zhang, L. Hybrid Dilated Convolution with Attention Mechanisms for Image Denoising. Electronics 2023, 12, 3770. [Google Scholar] [CrossRef]
- Ilesanmi, A.E.; Ilesanmi, T.O. Methods for image denoising using convolutional neural network: A review. Complex Intell. Syst. 2021, 7, 2179–2198. [Google Scholar] [CrossRef]
- Sun, Y.; Yang, Y.; Liu, Q.; Chen, J.; Yuan, X.T.; Guo, G. Learning non-locally regularized compressed sensing network with half-quadratic splitting. IEEE Trans. Multimed. 2020, 22, 3236–3248. [Google Scholar] [CrossRef]
- Reddy, B.S.; Chatterji, B.N. An FFT-based technique for translation, rotation, and scale-invariant image registration. IEEE Trans. Image Process. 1996, 5, 1266–1271. [Google Scholar] [CrossRef]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: New York, NY, USA, 2020; pp. 1055–1059. [Google Scholar]
- Zheng, H.; Yang, Z.; Liu, W.; Liang, J.; Li, Y. Improving deep neural networks using softplus units. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; IEEE: New York, NY, USA, 2015; pp. 1–4. [Google Scholar]
- Ma, K.; Duanmu, Z.; Wu, Q.; Wang, Z.; Yong, H.; Li, H.; Zhang, L. Waterloo exploration database: New challenges for image quality assessment models. IEEE Trans. Image Process. 2016, 26, 1004–1016. [Google Scholar] [CrossRef] [PubMed]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 126–135. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision (ICCV 2001), Vancouver, BC, Canada, 7–14 July 2001; IEEE: New York, NY, USA, 2001; Volume 2, pp. 416–423. [Google Scholar]
- Roth, S.; Black, M.J. Fields of experts: A framework for learning image priors. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 21–25 June 2005; IEEE: New York, NY, USA, 2005; Volume 2, pp. 860–867. [Google Scholar]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Guo, X.; O’Neill, W.C.; Vey, B.; Yang, T.C.; Kim, T.J.; Ghassemi, M.; Pan, I.; Gichoya, J.W.; Trivedi, H.; Banerjee, I. SCU-Net: A deep learning method for segmentation and quantification of breast arterial calcifications on mammograms. Med. Phys. 2021, 48, 5851–5861. [Google Scholar] [CrossRef] [PubMed]
- Marmolin, H. Subjective MSE measures. IEEE Trans. Syst. Man Cybern. 1986, 16, 486–489. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Sahu, S.; Singh, A.K.; Ghrera, S.; Elhoseny, M. An approach for de-noising and contrast enhancement of retinal fundus image using CLAHE. Opt. Laser Technol. 2019, 110, 87–98. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Noise | |||
|---|---|---|---|---|
| Set12 | 15 | 34.45/0.9142 | 34.45/ | |
| 25 | 33.17/0.8765 | |||
| 50 | 31.25/0.8109 | |||
| BSD68 | 15 | 32.14/0.9136 | 32.14/ | |
| 25 | 31.15/0.8577 | |||
| 50 | 30.23/0.7292 | |||
| Urban100 | 15 | 33.42/0.9472 | ||
| 25 | 32.20/0.9179 | |||
| 50 | 30.93/0.8556 |
| Dataset | Noise | |||
|---|---|---|---|---|
| Set12 | 15 | 34.45/0.9142 | 34.45/ | |
| 25 | 34.16/0.9460 | |||
| 50 | 32.46/0.9014 | |||
| CBSD68 | 15 | 34.90/0.9381 | /0.9381 | |
| 25 | 33.32/0.8976 | |||
| 50 | 31.94/0.8156 | |||
| Kodak24 | 15 | 35.70/0.9316 | ||
| 25 | 34.11/0.8947 | |||
| 50 | 32.63/0.8230 |
| Dataset | Set12 | BSD68 | Urban100 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method | ||||||||||
| BM3D | 32.37/ | 29.97/ | 26.72/ | 31.07/ | 28.57/ | 25.60/ | 32.35/ | 29.70/ | 25.95/ | |
| 0.8952 | 0.8504 | 0.7676 | 0.8717 | 0.8013 | 0.6864 | 0.9220 | 0.8777 | 0.7791 | ||
| WNNM | 32.71/ | 30.26/ | 27.05/ | 31.37/ | 28.83/ | 25.87/ | 32.53/ | 30.38/ | 26.83/ | |
| 0.8988 | 0.8557 | 0.7775 | 0.8766 | 0.8087 | 0.6982 | 0.9271 | 0.8885 | 0.8047 | ||
| FFDNet | 32.75/ | 30.43/ | 27.32/ | 31.63/ | 29.19/ | 26.29/ | 32.40/ | 29.90/ | 26.50/ | |
| 0.9024 | 0.8631 | 0.7899 | 0.8902 | 0.8288 | 0.7239 | 0.9265 | 0.8979 | 0.8048 | ||
| DnCNN | 32.86/ | 30.44/ | 27.18/ | 31.73/ | 29.23/ | 26.23/ | 32.64/ | 29.95/ | 26.26/ | |
| 0.9024 | 0.8617 | 0.7828 | 0.8907 | 0.8279 | 0.7189 | 0.9246 | 0.8781 | 0.7856 | ||
| SwinIR | 33.36/ | 31.01/ | 27.91/ | 31.97/ | 29.50/ | 26.58/ | 32.70/ | 31.30/ | 27.98/ | |
| 0.8898 | 0.8482 | 0.8119 | 0.8959 | 0.8321 | 0.7298 | 0.9104 | 0.8724 | 0.8039 | ||
| LKSVD | 28.72/ | 24.85/ | 20.84/0 | 28.48/ | 24.96/ | 20.97/ | 28.46/ | 23.80/ | 20.22/ | |
| 0.7826 | 0.7354 | 0.7042 | 0.7835 | 0.7371 | 0.7035 | 0.7836 | 0.7331 | 0.7018 | ||
| DCDicL | 33.34/ | 31.03/ | 28.00/ | 31.95/ | 29.52/ | 26.63/ | 32.31/ | 29.65/ | 26.22/ | |
| 0.9115 | 0.8748 | 0.8122 | 0.8957 | 0.8379 | 0.7395 | 0.9383 | 0.9129 | 0.8336 | ||
| SCUNet | 33.43/ | 31.09/ | 28.04/ | 31.99/ | 29.55/ | 26.67/ | 32.88/ | 31.58/ | 28.56/ | |
| 0.9017 | 0.8754 | 0.8132 | 0.9001 | 0.8402 | 0.7456 | 0.9458 | 31.58/ | 0.8392 | ||
| Our | ||||||||||
| Dataset | Urban100 | CBSD68 | Kodak24 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method | ||||||||||
| BM3D | 33.93/ | 31.36/ | 27.93/ | 33.50/ | 30.69/ | 27.36/ | 34.26/ | 31.67/ | 28.44/ | |
| 0.9408 | 0.9092 | 27.93/ | 0.9215 | 0.8672 | 0.7626 | 0.9147 | 0.8670 | 0.7760 | ||
| WNNM | 32.86/ | 32.86/ | 27.18/ | 31.73/ | 31.73/ | 26.23/ | 32.64/ | 29.95/ | 26.26/ | |
| 0.9024 | 0.9024 | 0.7828 | 0.8907 | 0.8907 | 0.7189 | 0.9246 | 0.8781 | 0.7856 | ||
| FFDNet | 33.83/ | 31.40/ | 28.05/ | 33.87/ | 31.21/ | 27.96/ | 34.63/ | 32.13/ | 28.98/ | |
| 0.9418 | 0.9120 | 0.8476 | 0.9290 | 0.8821 | 0.7887 | 0.9224 | 0.8791 | 0.7952 | ||
| DnCNN | 32.98/ | 30.81/ | 27.59/ | 33.89/ | 31.23/ | 27.92/ | 34.48/ | 32.03/ | 28.85/ | |
| 0.9314 | 0.9015 | 0.8331 | 0.9290 | 0.8830 | 0.7896 | 0.9209 | 0.8775 | 0.7917 | ||
| SwinIR | 35.13/ | 32.90/ | 29.82/ | 34.42/ | 31.78/ | 28.56/ | 35.34/ | 32.89/ | 29.79/ | |
| 0.9532 | 0.9284 | 0.8675 | 0.9203 | 0.8862 | 0.7890 | 0.9212 | 0.8864 | 0.8041 | ||
| LKSVD | 32.76/ | 30.37/ | 27.12/ | 31.63/ | 29.15/ | 26.19/ | 32.46/ | 29.80/ | 26.22/ | |
| 0.8106 | 0.7798 | 0.7187 | 0.8282 | 0.7848 | 0.7169 | 0.8236 | 0.7831 | 0.7318 | ||
| DCDicL | 34.90/ | 32.77/ | 28.99/ | 34.36/ | 31.75/ | 28.57/ | 35.38/ | 32.97/ | 29.96/ | |
| 0.9511 | 0.9300 | 0.8884 | 0.9348 | 0.8930 | 0.8107 | 0.9300 | 0.8928 | 0.8219 | ||
| SCUNet | 35.18/ | 33.03/ | 30.14/ | 34.40/ | 31.79/ | 28.61/ | 35.34/ | 32.92/ | 29.87/ | |
| 0.9553 | 0.9342 | 0.8901 | 0.9351 | 0.8931 | 0.8130 | 0.9293 | 0.8922 | 0.8198 | ||
| Our | ||||||||||
| Method | |||||||
|---|---|---|---|---|---|---|---|
| Image | DCDicL | Our | DCDicL | Our | DCDicL | DCDicL | |
| C.man | 0.7702 | 0.6903 | 0.5840 | ||||
| Peppers | 0.7445 | 0.5765 | 0.4968 | ||||
| House | 0.7633 | 0.7633 | 0.7194 | 0.6513 | |||
| Airplane | 0.8480 | 0.7996 | 0.7155 | ||||
| Couple | 0.8685 | 0.8312 | 0.7542 | ||||
| Parrot | 0.7598 | 0.6870 | 0.5749 | ||||
| Man | 0.8144 | 0.7447 | 0.6574 | ||||
| Monarch | 0.6675 | 0.6067 | 0.5136 | ||||
| Starfish | 0.8743 | 0.8395 | 0.7533 | ||||
| Boat | 0.6598 | 0.5865 | 0.4796 | ||||
| Barbara | 0.7203 | 0.6261 | 0.4789 | ||||
| Lena | 0.7209 | 0.6513 | 0.5422 | ||||
| Average | 0.7677 | 0.6969 | 0.6004 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, L.; Gao, W.; Liu, J. Deep Convolutional Dictionary Learning Denoising Method Based on Distributed Image Patches. Electronics 2024, 13, 1266. https://doi.org/10.3390/electronics13071266
Yin L, Gao W, Liu J. Deep Convolutional Dictionary Learning Denoising Method Based on Distributed Image Patches. Electronics. 2024; 13(7):1266. https://doi.org/10.3390/electronics13071266
Chicago/Turabian StyleYin, Luqiao, Wenqing Gao, and Jingjing Liu. 2024. "Deep Convolutional Dictionary Learning Denoising Method Based on Distributed Image Patches" Electronics 13, no. 7: 1266. https://doi.org/10.3390/electronics13071266
APA StyleYin, L., Gao, W., & Liu, J. (2024). Deep Convolutional Dictionary Learning Denoising Method Based on Distributed Image Patches. Electronics, 13(7), 1266. https://doi.org/10.3390/electronics13071266