1. Introduction
The evolution of containerised applications has resulted in the creation of container orchestration platforms like
Kubernetes [
1].
Kubernetes uses the Horizontal Pod Autoscaler (HPA) [
2], which determines the number of resources to be provisioned based on resource utilisation metrics such as the CPU, RAM, or network throughput. The HPA increases the number of pod replicas if the current resource utilisation metric is above a particular utilisation threshold (target utilisation). On the other hand, if the current resource utilisation metric is below the target utilisation, the HPA decreases the number of pod replicas. The target threshold utilisation setting is the most influential parameter to control the application’s performance as it controls the amount of resource provision during each autoscaling action. However, the authors of
Kubernetes do not provide recommendations on setting the threshold, especially for cases when the user aims to ensure that the application performs as per the Service Level Objectives (SLOs) defined in a Service Level Agreement (SLA). As a result, the determination of the threshold becomes a long and challenging process [
3]. If the thresholds are set too low, this can result in the overprovisioning of resources. However, this will allow for a quicker response to load changes and, as a result, lead to improved application performance. Conversely, choosing a threshold that is too high may lead to fewer replicas being provisioned and leaving no buffer for the detection of and reaction to the load increase [
4]. These two factors may cause a decline in performance and an increased risk of failing to meet the application performance regarding the SLOs [
5].
Also, the HPA has a slow reaction [
6], so it is not enough to benchmark the application performance and establish a relationship between the response time and resource utilisation to find thresholds that ensure compliance with the SLOs. The utilisation threshold must be set lower to allow time for a reaction to an increase in the load and wait for new replicas to be provisioned. This buffer is essential for ensuring that the system can cope with sudden changes in demand [
4]; however, it is not clear how to estimate the size of such a buffer.
The threshold determination becomes even more challenging, as the cloud environment is not homogeneous, which causes inconsistency in resource provisioning [
7,
8,
9]. Noisy neighbours are another problem that causes inconsistency in provisioned resources’ performance [
10,
11]. Additionally, cloud-native applications are constantly updated and redeployed, requiring dynamic updates to autoscaling thresholds. As a result, finding a suitable threshold is a challenging process, which can be viewed as an optimisation that aims to identify the operating parameters that guarantee the desired level of system performance [
7,
9,
12]. As a result, practitioners and academia propose many alternatives to the HPA in the form of custom autoscalers. Nevertheless, the HPA remains one of the most popular horizontal autoscaling solutions [
13].
According to Amiri et al. [
14], efficient resource management in the cloud addresses the SLA-fulfilment and resource-waste-avoidance aspects. When the solution is oriented towards SLA fulfilment, it aims to ensure that the obligations of the cloud for its users are met, even if this causes an increase in operational costs. On the other hand, resource waste avoidance focuses on minimising the provisioning of the required resources for SLA fulfilment, thereby reducing cost or energy waste. The HPA was specifically designed to minimise operational costs, and as a result, it inherently addresses the resource-waste-avoidance aspect. This research aims to introduce an approach for identifying the HPA target utilisation threshold, which enables the HPA to address the SLA-fulfilment aspect effectively.
It is important to note that most scientific studies addressing the issues of SLA-fulfilment-oriented autoscalers [
7,
9,
12,
15,
16] propose implementing prediction methods based on complex machine learning algorithms. However, applying these methods can be quite challenging and requires custom autoscaler implementations, which may complicate their seamless integration into production environments. Additionally, operating and adopting such solutions requires in-depth knowledge of the machine learning field. In contrast, this article proposes a method that allows users to continue using the HPA. The solution solely relies on data exploration analysis techniques to adjust the thresholds without machine learning to avoid additional complexity when operating the HPA.
It is common for many solutions [
7,
16,
17,
18] to track the average response time to improve the application’s performance. However, this monitoring approach might not provide enough information about current or upcoming SLO violations, and information about small amounts of events that were not compliant with the SLO is lost due to the applied average value technique. To address this issue, the solution proposed in this work tracks the number of events where the
percentile of the response time values resulted in SLO violations during the specified monitoring period. This approach helps identify the potentially upcoming violations and also considers the violations that actually happened while the system operated at a particular CPU utilisation level. This helps identify the target utilisation threshold that minimises the number of SLO violations.
To summarise, the main contributions of this research are as follows:
A novel approach is introduced that supports the process of identifying target utilisation thresholds for the HPA. It aims to ensure that the system performance conforms to the defined SLO and does not exceed the number of allowed violations.
A prototype of a dynamic threshold update add-on to the Horizontal Pod Autoscaler, named the SLA-Adaptive Threshold Adjuster (SATA), has been implemented. This enables the evaluation and practical testing of the proposed target utilisation-detection approach. The evaluation of the approach revealed that the type of smoothing techniques and the length of the period during which data for threshold evaluation are collected have a different impact on the efficiency of the algorithm depending on the load pattern (slowly changing or volatile).
The proposed approach was tested in a real environment under various workload conditions using real-world workload traces to evaluate its effectiveness. The experimental results demonstrated that the proposed solution enables the HPA to manage resources in a way that ensures system performance alignment with the SLO with negligible or only around 10% resource overprovisioning.
The experiments revealed that, even though the same application and pods with the same resource setting threshold were used, different target utilisation values must be applied depending on the load pattern.
It is important to note that the purpose of the research is not to provide a new autoscaler solution, but instead, to improve the autoscaling decision-making process of the HPA, allowing users to continue using the HPA without introducing additional complexity, in cases when there are strict SLOs, which must be met. In other words, the solution enables the HPA to address the SLA-fulfilment [
14] aspect of efficient resource management.
Before continuing with the next section, it is worth noting that SLOs can cover various aspects of SLAs, including application availability, disaster recovery, and more, as mentioned in the SLA Catalog [
5]. In this document, we will focus on performance-based SLOs that are measured using service level indicators (SLIs), such as response time, throughput, and tail latency.
The paper is organised in several sections.
Section 2 introduces the background and related work.
Section 3 introduces the threshold determination approach proposed, detailing the metrics and methods employed.
Section 4 presents the prototype solution necessary to test the proposed approach with the HPA. The experimental setup is detailed in
Section 5, while
Section 6 presents the evaluation criteria, experiments, and the results of the experiments. Finally, the paper is concluded with
Section 7, which summarises the findings and suggests areas for future research.
3. Threshold-Determination Approach
In this section, we introduce an approach to identify the target utilisation threshold that ensures the system performs at the level defined in the SLA. The implementation of this process is constituted by a series of steps. As the first step, a sufficient number of metrics are collected to be able to provide the suggestion. In the second step, the collected metrics are cleaned up, and outliers are removed to improve the accuracy of the algorithm. As a third step, the collected metrics are aggregated into CPU ranges, and the ratio between the number of compliant events and violations is calculated per each range. In the fourth step, the collected metrics are aggregated into CPU ranges, and the ratio between the number of compliant events and violations is calculated for each range. As the last step, the suitable threshold is determined by finding the highest CPU value where the desired SLO is met. The steps described above are elaborated on in more detail in the text below.
Step 1: collection of a sufficient number of monitoring data points.
As the first step, the system should collect enough metrics to be able to identify the number of violations per threshold. To achieve the goal, the following metrics are collected at each moment n:
—average CPU utilisation;
—performance-based service level indicator value, such as average response time, tail latency, throughput (e.g., requests per second (rps));
—average number of requests per second;
—number of pods in “Ready” state.
Let us denote the set of the metrics provided above as tuple m. Then, can be defined as , where .
The size of depends on two factors: the length of the period during which the data for threshold evaluation are collected (threshold evaluation period ) and how frequently the metrics are collected (length of metric-collection period ). In other words, . The experiment results showed that, while detecting the threshold is possible with 150 samples per evaluation period, the recommended number of samples is 300 for improved accuracy.
The and metrics are optional and are collected to remove outliers in the CPU performance values, which appear when the number of pods is very small. The process of removing outliers is explained in the following step, along with the specifics on how to clean invalid data.
Step 2: data cleaning.
This step is applied to refine the accuracy of the algorithm. It involves identifying and removing invalid values and outliers that might have been introduced due to system-specific monitoring issues. It is possible for empty requests per second or response time values to occur in the monitoring system when it is overloaded and unable to report the metrics, depending on its configuration. To clean up the data, as the first step, empty metrics are removed from
. For instance, data points (
) where the
metric is not available are removed as presented in Equation (
1).
Here,
.
Next, to ensure that the algorithm does not propose very low CPU utilisation, the metrics collected when there was no load are removed, denoted as
in Equation (
2).
Here, .
During the upscale and downscale actions where the number of pod replicas is low, outliers can be introduced. For instance, during an upscale action, the system may report many violations while CPU utilisation drops. This happens because the load has yet to be distributed across all replicas, and some replicas still report high response times with low CPU utilisation. Removing such anomalous data is recommended to improve the accuracy of the algorithm. To follow the recommendation, the interquartile range (IQR) method [
33,
34] for outlier detection is used in this work.
The interquartile range (IQR) is a statistical technique that is used to identify outliers within a dataset. The dataset is first sorted and then divided into four equal parts. The points dividing the dataset into four equal parts are known as quartiles. The first quartile (
) represents the initial 25% of the data or the 25th percentile, while the third quartile (
) represents the final 25% or the 75th percentile. The interquartile range represents the middle half of the data, which includes all the data between the third quartile (
) and the first quartile (
). Values falling at least
above
or below
are considered anomalous. The
,
, and
are computed as presented in Equation (
3).
Here,
X is an element of an ordered dataset,
z is the number of elements in the dataset (size of the dataset), and the subscript of
X represents the equation used to identify the index of the element belonging to the respective quartile (
).
As described at the beginning of the step description, the system may report anomalous metrics. The number of requests per second (rps) that a single CPU can handle (
) and the number of rps that a single pod can handle (
) can help detect the anomalous container performance of pods. For each metric
, the
and
values are calculated as presented in Equation (
4) and Equation (
5), respectively.
Once the
and
are calculated, the metrics
are sorted by the
value in ascending order and the IQR method is applied to remove anomalies. The value of the first quartile (
) and third quartile (
) of the
is identified using Equation (
3). Finally, all the metrics, where
, are considered as outliers and are removed from
. The same procedure is repeated using the
, to obtain a set of metrics to proceed with CPU threshold estimation, denoted as
.
Step 3: the data grouping by CPU range and number of violations’ calculation per CPU range.
In this step, the collected and cleaned metrics are grouped into ranges by the CPU using the following actions, denoted as A:
A1. The cleaned metrics are first ordered by the CPU from the low to high CPU value. Let the new sequence be denoted as .
A2. The elements of are grouped into smaller subsequences, or ranges, based on their CPU values. Metrics with CPU values that fall into the same 1% CPU range are placed into the same group (). This procedure is applied to all available metrics while maintaining their original sorting by the CPU value. In such a way, the sequence of sequences is created , where is the sequence of metrics belonging to the same 1% CPU. Here, i is an index of the CPU range.
A3. It is assumed that the 1% CPU range should contain at least 1% of all collected metrics during the threshold evaluation period (). However, might contain a smaller number of elements. As a result, up to three subsequent subsequences might be united into a bigger or the same size range to ensure they contain at least 1% of all metrics collected during , but not less than five elements (). If , then . Here, r denotes an index equal to the index of the last CPU range included in the combined range. For instance, if unites the and ranges, then ; if unites only one range, then .
After grouping the metrics, the SLO (
) for each CPU range
is calculated as presented in Equation (
6).
Here,
represents the total number of events
where the SLI value (
) exceeded the SLI target value (
), indicating a violation of the SLO, as shown in Equation (
7). The index
p corresponds to the elements in the set
, and
b indicates the index of the last element in the range.
As can be seen in the first line of Equation (
6),
is the percentage of events that conform with the target SLI value within a range. An SLO of 100% is assigned to the CPU range of 0%, as there are no violations when there is no or minimal load. Conversely, SLO compliance is equal to 0% when the CPU range index is 99 or higher because the SLO cannot be met when CPU utilisation is near 100%. This allows the imputation [
35] of missing values by replacing missing initial and last values for the SLO.
The mapping is created between the
and
ranges corresponding the IDs, denoted as
in Equation (
8).
Here,
is the ID of a range that is equal to the value of the CPU metric with the highest value in the range.
Before proceeding to the next step, it is important to note that the metrics are grouped into ranges larger than 1% to ensure that each range has enough metrics to calculate the SLO metric accurately. This minimises fluctuations between neighbouring values. Let us say we have two metrics collected at a very low CPU utilisation, where the CPU value is around 3%. In this scenario, each metric will be given a weight of 50% when calculating the SLO of the range. For instance, if the next range has a CPU value of 4% and contains 10 compliant values, then the SLO for the range will be 100%. However, if there is only one non-compliant event in the range of 3%, the SLO for the range may fluctuate up to 50%. While it is possible to unite more than three 1% CPU ranges (), it is not recommended to estimate the SLO for ranges larger than 3% as this would negatively impact the algorithm’s accuracy.
The next step aims to improve the accuracy of threshold prediction and remove noise caused by fluctuations between neighbouring values.
Step 4: smoothing of the values of the SLO per the CPU range.
As the algorithm might work with a relatively low number of events, the low number of events per
might introduce fluctuations in the relation between
and
, as seen in
Figure 1a and described in the previous step. To address this issue, a smoothing technique called the Simple Moving Average (SMA) is applied to remove fluctuations and reveal underlying trends [
36]. The SMA calculates the average value of a set of numbers over a specified number of previous periods, known as a window or lag. The formula for calculating the Simple Moving Average (SMA) is presented in Equation (
9).
Here,
is the SLO value of a range
r smoothed over a window of size
w;
are the SLO values of the CPU ranges with indexes varying within the window size
w (from
to
r).
The recommendation provided by [
37] and discussed in [
38] is followed to determine the appropriate window size
w, or lag, to be applied for SMA smoothing (Equation (
10)).
Step 5: suggestion for the desired CPU threshold value.
After smoothing out the CPU values, the next step is to choose the highest CPU range that has a number of violations (
) that is lower than or equal to the SLO-defined number of violations (
). This chosen threshold is then considered the target utilisation threshold
and is determined using Equation (
11).
Here,
Before concluding this section, it is worth mentioning that, in this work, the use of the Centred Moving Average (CMA) [
37] was also evaluated to smooth out the fluctuations and identify the target utilisation threshold. It was assumed that this method would provide more conservative suggestions for thresholds compared to the SMA. Three experiments using the HPA were executed, and the utilisation thresholds were set to values of 44%, 48%, and 50% to evaluate these approaches. The results are presented in
Figure 1b,c, where the lines present the relationship between the CPU range ID and SLO, and the SLOs achieved by the end of each experiment are presented as dots. As can be seen, the relationship between the threshold and SLO values is identified more accurately by the SMA than the CMA. So, the SMA is used as the main smoothing technique in this work. However, experiments later demonstrated that the CMA may be effective in volatile load scenarios due to its tendency to slightly underestimate the threshold value. This causes a faster reaction to an increase in load, thus minimising the risk of SLO violation.
The algorithm presented in this section assists in the identification of a threshold value that autoscaling algorithms can use to maintain the desired quality of service (QoS) levels. This approach is most effective when there are no significant changes in performance or load during the period when the threshold was estimated. Additionally, it is best suited when there is no significant difference in the load patterns between the future period and the period for which the threshold was estimated. However, in real-life production environments, load fluctuations are common, and the algorithm may select the lowest CPU threshold when assessing performance for longer periods, leading to resource overprovisioning. Additionally, the performance of cloud resources can also fluctuate, and the provisioned resources may not be uniform. As a result, the target utilisation threshold that ensures that the system operates at the performance level required to achieve the SLO during the night might fail to achieve the SLO during the day. Therefore, there is a need to adjust the proposed threshold value dynamically to meet the SLA requirements.
In the following section, the dynamic threshold-adjustment algorithm will be outlined to address the above-mentioned issues. The algorithm is then implemented as a prototype solution (SATA) to assess the effectiveness of the dynamic adjustment.
6. Evaluation and Results
A set of experiments was executed in order to assess the efficacy of the proposed dynamic threshold-adjustment algorithm using the SATA prototype. One set of experiments was conducted to assess the influence of various settings on algorithm performance. The assessment includes an evaluation of the impact of varying threshold evaluation period lengths, the frequency of threshold updates, and the implementation of different types of moving-average-smoothing techniques on the efficacy and efficiency of the solution. The second set of experiments assesses how the algorithm performs under changing workload conditions.
To evaluate the performance of the solutions, three types of workloads were used—the WorldCup98 dataset [
45], the EDGAR dataset [
46], and the On–off workload pattern.
The WorldCup98 dataset used in this work contains all the requests made to the 1998 World Cup Website between 30 April 1998 and 26 July 1998, and is commonly referenced in research articles [
15,
29,
47,
48,
49,
50]. This pattern has unpredictable high load spikes followed by a stable load without high deviation. Each experiment uses logs from different time intervals, and the interval details are provided in each experiment section.
The EDGAR dataset is the logs of the filling search of the Electronic Data Gathering, Analysis, and Retrieval (EDGAR) system. It is a public database allowing users to research, for example, a public company’s financial information and operations by reviewing the filings the company makes with the U.S. Securities and Exchange Commission. The load is characterised as a lightly shaking load with constant small fluctuations of 10–15% in magnitude. The dataset used in this work contains all the search requests made for EDGAR filings through the
SEC.gov site on 30 June 2023, between 02:00 and 05:00.
The experiment involved evaluating a workload pattern known as the On–off workload, which is commonly used in batch-processing systems. This pattern involves an increase in the number of requests to 140 per second over a 2 s interval, which is then maintained for 45 s. The load is then decreased to 0 requests per second over 2 s, followed by a 45 s period of no load. This pattern is repeated throughout the experiment, causing stress conditions that require constant upscaling and downscaling of pods. This synthetic workload was introduced to identify SATA behaviour under volatile traffic patterns with a constant load. This allows us to see the behaviour patterns of the algorithm, as load pattern repeats.
Other load types were not included as the WorldCup98 dataset already had various patterns, and adding specific synthetic loads would have made the experiments redundant. The following subsections describe the experiments and their results in detail.
6.1. Evaluation of the Impact of the Threshold Adjustment and Evaluation Periods on the Algorithm Performance
Four experiments were conducted to evaluate the influence of threshold adjustment frequency (length of threshold adjustment period ) and the impact of the duration of the period used to collect metrics for the threshold value estimation on autoscaling efficiency and the ability to dynamically determine the threshold that allows operating as close as possible to the SLO-defined performance target ().
Table 3 shows the values of
and
used in each experiment. These values are presented as multiples of the upscale period (
). The value of
was set to 4, as it is the minimum number of periods required for the system to detect the impact of the latest threshold adjustment action. The setting of
to 8 should be sufficient to observe the impact of a longer update period without requiring a drastic extension of the experiment’s length.
For clarity, each of the experiments will be referred to as n × m, where n and m are multipliers of the scale periods used in and . For example, 4 × 10 means that the threshold is adjusted every scale period based on data collected from the last 10 scale periods. The evaluation periods, , of lengths 10 and 20, were used in the evaluation. This covers cases when the length is close to (8 × 10 case), when is 2.5- or 5-times longer than (4 × 10, 8 × 20, and 4 × 10 cases, accordingly).
The following are the common settings for all the experiments:
Load: WorldCup98 on 78th day from 19:37 to 21:37.
Application: calculation of the factorial of a number between 8000 and 12,000.
HPA initial threshold: 50.
Pod replicas: Min: 1, Max: 35.
Based on the data presented in
Figure 2 and
Table 3, it appears that the SATA solution is the most accurate in meeting the defined SLOs (the system performs closest to the desired SLO value) when
is equal to 4 (red and dark red lines). Longer
periods tended to suggest a lower threshold, but the system was able to make more granular suggestions as more events were collected (dark red and dark blue lines). However, extending
also increased the overprovisioning period, as the algorithm adapted to the lowest threshold that satisfied the target SLO over the period, leading to persistent overprovisioning. On the other hand, longer update periods proved advantageous when the load was fluctuating, as a lower threshold minimised the risk of violations and ensured that the autoscaling work was more stable and did not repeat the fluctuation pattern. Experiment 8 × 10 showed the worst performance and was the least adaptive to the detected changes (light blue line). However, it was still able to support the SLO.
It can be concluded that the evaluation time () should be at least 2–3-times as long as the update time (). The algorithm performed well with set to 150, but when was increased to 300, the approach demonstrated better prediction accuracy. However, there was slight overprovisioning as it took longer to collect the events, and as a result, lower thresholds were selected.
6.2. Evaluation of the Impact of the Smoothing Technique on the Algorithm Performance
In this experiment, we tested different types of moving averages (CMA and SMA) to evaluate their impact on the ability of the approach to adapt to frequent load changes.
The experiment was executed under the following conditions:
Load: On–off scenario, repeating pattern for 140 periods with a maximum load of 140 rps.
Application: calculation of the factorial of a number between 8000 and 12,000.
Pod replicas: Min: 1, Max: 27.
As can be seen from
Figure 3 and
Table 4, both the CMA (red line) and SMA (green line) were able to support the desired SLO levels, but with a high resource overprovisioning.
As can be seen from panels (a) and (b) by the dashed blue line in
Figure 3, the threshold of value above 48% CPU utilisation was causing a high drop in the quality of services as a high amount of violations were happening when the system operated above the value. This was causing the SATA algorithms to select lower CPU thresholds, which guaranteed the performance at the level required to support SLO compliance, showing that the solution aims to restore the SLO in the case of SLO violations [
17].
As can be seen in
Table 4, the SATA algorithm using CMA smoothing demonstrated superior precision, accuracy, and resource provisioning results. However, as seen in
Figure 3a, it experienced multiple periods where the SLO was violated. Despite this, the HPA, using the SATA with the CMA, restored the SLO at the desired level without reaching the maximum number of pod replicas in most cases.
Based on the data presented in
Figure 3c, it can be observed that the SATA algorithm with the CMA makes less granular steps than the SMA while approaching the 48% threshold. This enables the algorithm to respond to sudden changes in load with fewer steps and minimises the periods of the overprovisioning and underprovisioning of resources. However, it also increases the likelihood of SLA violations due to a higher chance of suggesting too high thresholds.
The SATA with the SMA was less sensitive to load changes than the SATA with the CMA. Based on the data presented in
Figure 3c, it can be observed that the threshold-adjustment process was more granular and required more iterations in comparison to the CMA method while approaching the 48% utilisation threshold. This led to longer periods of overprovisioning and shorter periods of underprovisioning, resulting in more consistent conformance with the SLO.
The experiments conducted in this section were aimed at gaining a better understanding of the behaviour of the proposed approach under different settings. The experiments showed that the CMA is suitable for cases where a light tolerance for SLA stability is acceptable to save costs. The SMA is more suitable where the SLA must be met, even at the cost of overprovisioning.
In the next section, experiments that are designed to evaluate the performance of SATA under varying load conditions and to compare its performance with the state-of-the-art technology, the HPA, will be described.
6.3. Evaluation of Performance under Different Workload Scenarios
In this section, the experiments were executed to evaluate the algorithms’ performance under varying load conditions and their ability to support the SLO for the whole period while the experiment was conducted. Two real-world workload scenarios were evaluated:
The efficacy of the SATA approach was evaluated under different load patterns by comparing it to the Horizontal Pod Autoscaler (HPA) in order to understand the improvements brought to the HPA by SATA. The HPA is also used as a baseline in multiple articles [
6,
10,
15,
17,
18,
28,
51] when the efficiency and efficacy of the proposed solution are evaluated.
In order to evaluate SATA’s impact on the HPA, the HPA should be set up with a threshold that allows the system to operate at the edge of the allowed SLO value, as this is what SATA aims to achieve. This requires that, during all experiment lengths, the measured SLA (see
Section 5.3) should be as close as possible to its target of 98%, which was chosen as the SLO for the experiments. The approximate target utilisation values for the HPA were identified using the approach defined in this article and further tuned by conducting experiments to validate that the system is able to meet the desired SLO level as closely as possible. The performance of the system met the requirements with the HPA static utilisation threshold set to 47% for the WorldCup98 workload and 35% for EDGAR. During the experiments with the HPA enabled by SATA, the initial threshold was set to 50% at the start of each experiment.
The next sections describe the evaluation of the workloads and the achieved results in more detail.
6.3.1. Evaluation of SATA Performance in WorldCup98 Workload Scenario
In this experiment, we assessed the ability of the algorithms to adjust the thresholds under the real-world mixed pattern load. The following settings were applied:
Load: WorldCup98 on the 78th day from 19:00 to 22:00 and its inverse version.
Application: calculation of the factorial of a number between 8000 and 12,000.
Pod replicas: Min: 1, Max: 34.
As the WorldCup98 load in the selected time window had a tendency to increase constantly, its inverse version was appended to see how algorithms perform when the load tends to decrease constantly. The load pattern is presented in
Figure 4e.
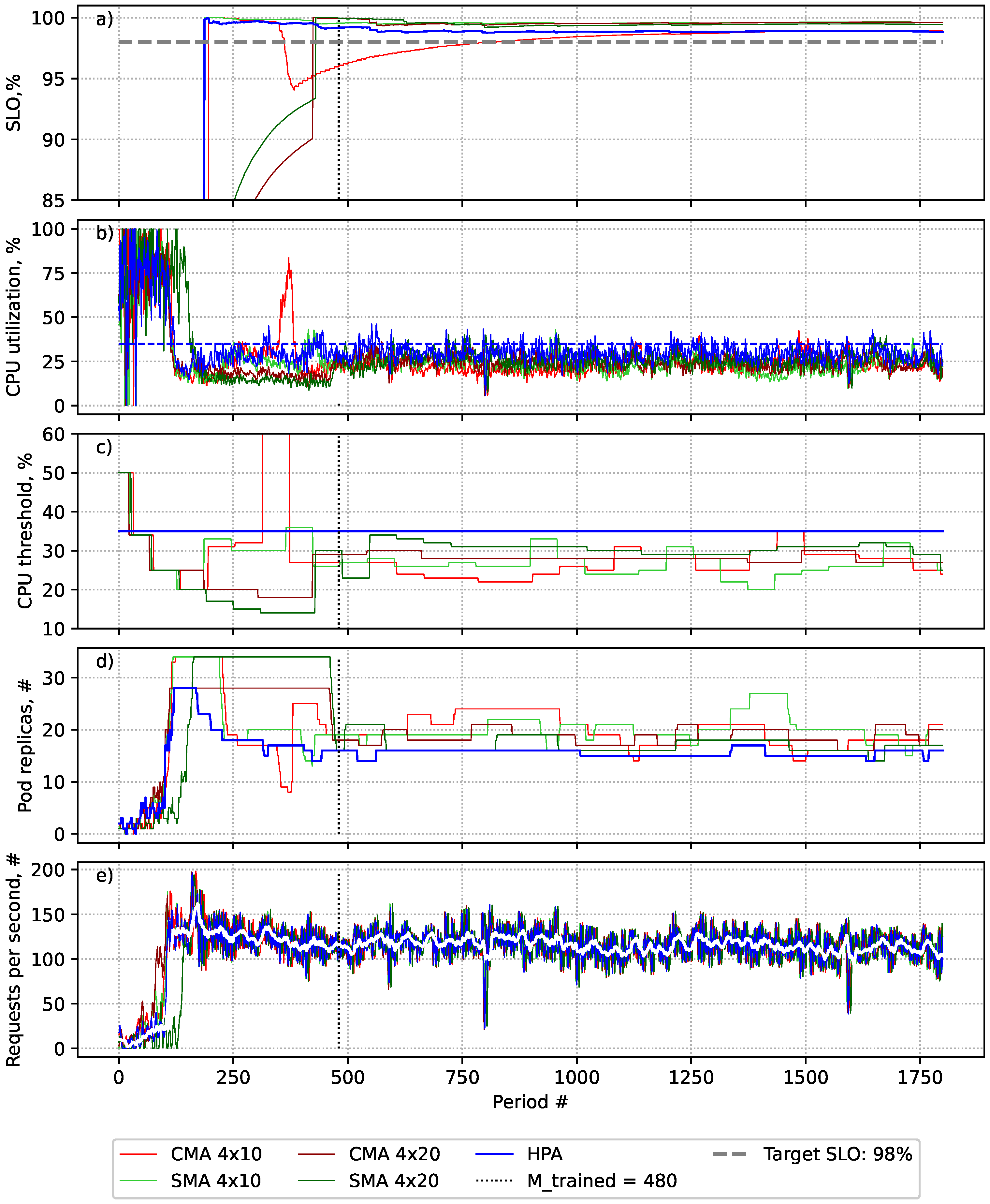
The experiment results presented in
Figure 4 and
Table 5 show that all of the evaluated approaches were compliant with the SLO throughout the experiment.
As can be seen from
Figure 4a,b, there is a noticeable decrease in the SLO value when the CPU threshold exceeds the target utilisation threshold of 47% (dark blue dashed line in
Figure 4b).
As seen in
Figure 4c, in the event of sudden increases in workload, the algorithms decrease the threshold value, and vice versa. At the same time, all the algorithms tend to approach the target utilisation value, aiming to increase efficiency by adjusting the provisioned resource number to actual resource demand. When the load is decreasing, it suggests higher thresholds than the CMA, thus becoming more efficient in downscale scenarios. However, in upscale scenarios, it is less efficient. This can be observed in the last half of the experiment (
Figure 4d) for downscale scenarios and in the first half of the experiment for upscale scenarios.
As can be seen from
Table 5, SATA required a slightly higher number of pod replicas in all scenarios compared to the HPA. In general, SATA achieved higher precision in 4 × 10 scenarios and was less precise for 4 × 20 scenarios compared to the HPA. When using the CMA as the smoothing method, the length of the threshold evaluation period did not significantly affect the efficiency and accuracy of SATA. However, when adopting the SMA, a longer period had a positive impact on the precision of SATA.
The experiment with the SMA in a 4 × 10 scenario showed the highest accuracy across SATA algorithms while supporting the defined SLO. The performance of the CMA in a 4 × 10 scenario was similar to that of the HPA but with slight overprovisioning. However, the SMA in a 4 × 10 scenario was more accurate in meeting the desired SLO. This is because SATA with SMA smoothing has higher accuracy in detecting threshold values and is more vulnerable to unexpected load growth when a shorter threshold evaluation period is used. This can be seen in
Figure 4a at around the 600th and 1200th metrics’ collection periods (light green line).
The HPA with a static threshold was the most efficient, with precision and accuracy similar to SATA with the CMA with a shorter threshold evaluation period (a 4 × 10 scenario). It must be emphasised that it is hard to achieve such precision in practice without knowing the workload and number of violations per threshold in advance, as was done for this experiment, meaning that the threshold might not be suitable to handle the load changes in the pattern in the future, causing SLO violations. The resource overprovisioning of 4% produced by SATA could be considered as neglectable as it is within the HPA tolerance range of 10% [
2] and is expected from SLA-fulfilment-oriented solutions. For example, Prametsi et al.’s [
51] experiments show that autoscalers that use a performance-based SLI, such as response time, to ensure compliance with the SLA, require more resources than the HPA, which uses CPU-utilisation-based thresholds.
Interestingly, the HPA enabled by the SATA solution achieved the SLO support goal by solely manipulating the threshold values. It dynamically adapted to the workload to ensure that the desired SLO is achieved consistently. As the experiment shows, the SATA solution is self-adaptive to load changes and automatically updates the thresholds to achieve the desired SLO. The SATA increases the threshold value in the case of downscaling, leading to faster downscaling and resulting cost savings. In the case of a load increase, it automatically decreases the threshold, leading to faster resource provisioning and minimising SLO violations.
The next section describes the experiments with a slightly shaky workload scenario.
6.3.2. Evaluation of SATA Performance in EDGAR Workload Scenario
In this experiment, we assessed the ability of the algorithms to adjust the thresholds under the real-world shaky load pattern. The following settings were applied:
Load: EDGAR access logs on 30 July 2023, from 02:00 to 05:00.
Application: calculation of the factorial of a number between 8000 and 12,000.
Pod replicas: Min: 1, Max: 27.
Figure 5e presents the EDGAR workload. While the load might be seen as constant, it contains a big number of periods where the load changes unexpectedly, but with low magnitude, that is the number of requests changes more than twice in a short period of time, e.g., see the number of events at around 600th the 900th monitoring periods.
The experiment results are presented in
Figure 5 and
Table 6. As seen in
Figure 5a, all of the evaluated approaches were compliant with the SLO throughout the experiment, with the exception of the SATA CMA 4 × 10 use case, where the suggested threshold value was higher than required. However, the system has been adjusted in the next two upscale periods by altering the thresholds, and hence, the operation has been restored to the desired level. The HPA algorithm was the most accurate in maintaining the target SLO value.
As seen in
Figure 5a,b, any increase in CPU utilisation above 35% caused a decrease in the SLO value. As presented in
Figure 5c, SATA suggested lower threshold values in all cases as the solution is sensitive to frequent load fluctuations. However, longer threshold evaluation periods resulted in better stability and adjustment of the threshold to a value close to 35%. All scenarios, with the exception of CMA 4 × 10, showed similar accuracy, with SMA 4 × 20 demonstrating slightly better accuracy in identifying the target utilisation threshold. Thus, HPA with SMA 4 × 20 operated closer to the desired utilisation threshold of 35%, resulting in more efficient resource provisioning than other SATA setups, as seen in
Figure 5d and
Table 6.
During the experiment, it was observed that, in the HPA without the SMA scenario, the supported SLO values began to decrease towards the end of the experiment, as depicted in
Figure 5a. This suggests that the current baseline threshold may not be suitable for future workload changes and might not restore the SLO. On the other hand, the SATA approaches have proven to be effective in ensuring compliance with the SLO and the ability to restore the SLO, as evidenced by the achieved results.
As presented in
Table 6, the HPA achieved the best resource-management efficiency and accuracy across algorithms that met the SLO during all evaluation periods. The CMA 4 × 10 had the best accuracy, but did not manage to support the SLO in all periods, even though it was the second most overprovisioning solution in this experiment. In
Section 6.2, it is shown that, while SMA’s tendency to underestimate the target utilisation threshold improves efficiency in volatile load scenarios, it causes a decrease in efficiency when the load is stable, as evidenced by the data presented in
Table 6. According to the results, SMA 4 × 20 performed the best in terms of accuracy and efficiency across all SATA settings and had only 10% overprovisioning in comparison to the HPA with a static threshold setup. As mentioned in
Section 6.3.1, overprovisioning is expected, and a 10% overprovisioning rate can be considered a good outcome when the algorithm’s aim is to ensure SLA fulfilment.
The experiments conducted with the WorklCup98 and EDGAR workloads demonstrated that, depending on the workload pattern and SATA settings, the solution can identify thresholds that allow the system to operate close to the defined SLO. The amount of resource overprovisioning can vary from negligible to deviating from 10% to 30% depending on the workload and settings. This is in comparison to using the Horizontal Pod Autoscaler (HPA) with the target utilisation threshold set as closely as possible to the value that allows the system to operate at a performance level where the number of violations does not exceed the maximum allowed. This value is never known upfront, so, in practice, it is challenging to achieve such precision threshold settings. As a result, such a level of overprovisioning is expected.
This section presents the experiments conducted in this work and the achieved results. The next section aims to conclude and discuss the results.
7. Discussion and Conclusions
Container orchestration solutions have become increasingly popular with the rise of containerised applications. The
Kubernetes platform is the most widely used container orchestration solution and has its own implementation for horizontal application autoscaling, known as the Horizontal Pod Autoscaler. Determining resource utilisation thresholds for the HPA to ensure desired service levels can be challenging. In an effort to address the limitations of the HPA, various attempts have been made to implement alternative solutions. However, these alternatives would require the implementation of autoscaling solutions that are not natively supported by
Kubernetes. Additionally, such alternative solutions have relied on machine learning algorithms [
7,
12,
28] or complex rules [
17,
27], which may be challenging to understand for those without a deep understanding of the field.
In this work, a threshold-detection approach and SATA prototype for dynamic threshold adjustment were presented. The approach is based on data explanatory analysis and moving average smoothing, which helps to understand and implement the solution without extensive knowledge of machine learning. The SATA prototype, using the Simple Moving Average, is able to detect the desired threshold in real-world workloads with slight overprovisioning. On the other hand, the Centred Moving Average approach showed better accuracy, but was less stable in meeting the SLO values. Therefore, the SMA method is recommended to ensure SLO compliance, and the CMA can be used when cost saving is more important in volatile load scenarios. Longer evaluation periods showed better efficiency where there is a low deviation in the load; in contrast, shorter threshold evaluation periods allowed the algorithm to perform more efficiently in scenarios with high-variation loads.
Interestingly, the experiments revealed that, while the experiments used the same application and pods with the same resource settings, different target utilisation values must be applied depending on the load pattern in order to ensure compliance with the SLO. Based on that, it can be concluded that approaches that use load testing on a single pod instance to determine the maximum CPU utilisation at which the application’s performance meets the SLO requirements may not be sufficient for determining the target utilisation threshold for the HPA.
To improve the algorithm’s performance, it can be customised by adjusting the threshold and evaluation period length based on the expected load pattern. The type of moving average can also be selected to control accuracy depending on the load pattern, whether it is highly volatile or not. Overall, the developed dynamic threshold-detection approach showed good potential. Further prototype stability improvement, experimentation with different SLIs, and adopting the approach to other autoscaling solutions are areas for future research and improvements.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}