
FE-FAIR: Feature-Enhanced Fused Attention for Image Super-Resolution


Abstract
1. Introduction
- We propose a better transformer-based super-resolution reconstruction method called FE-FAIR. It combines a shallow feature enhancement module with a fused attention mechanism to achieve better model performance.
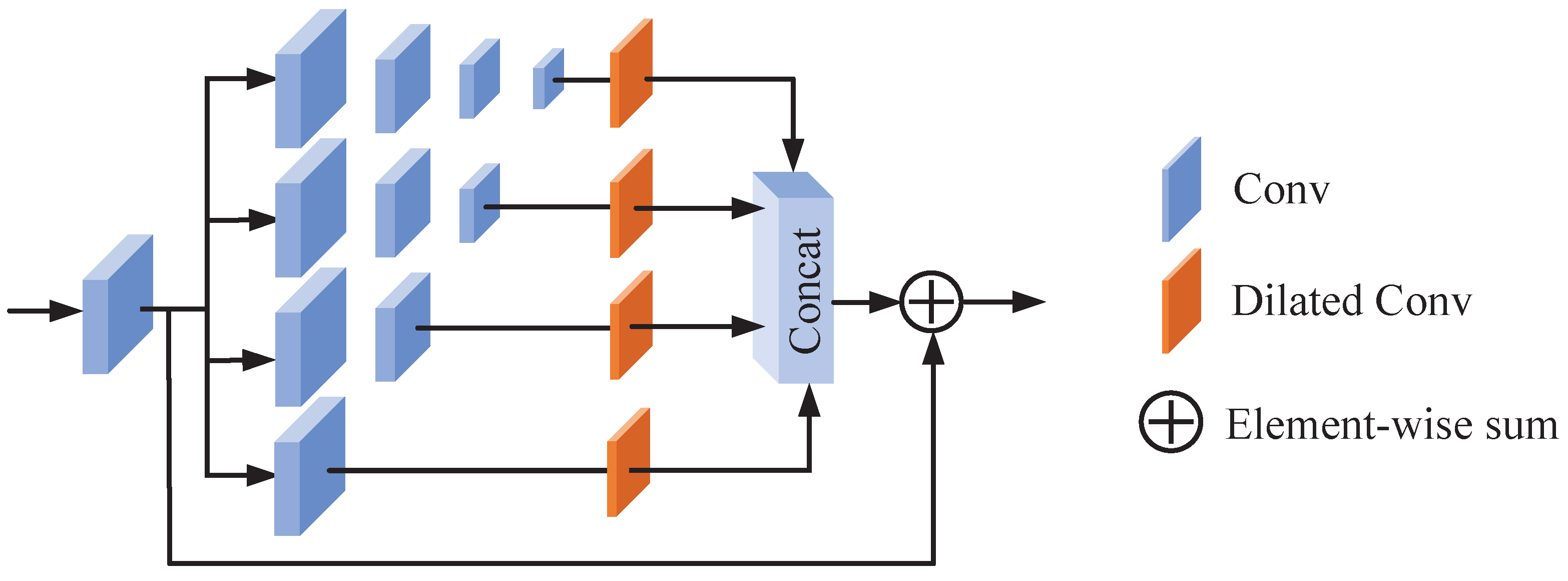
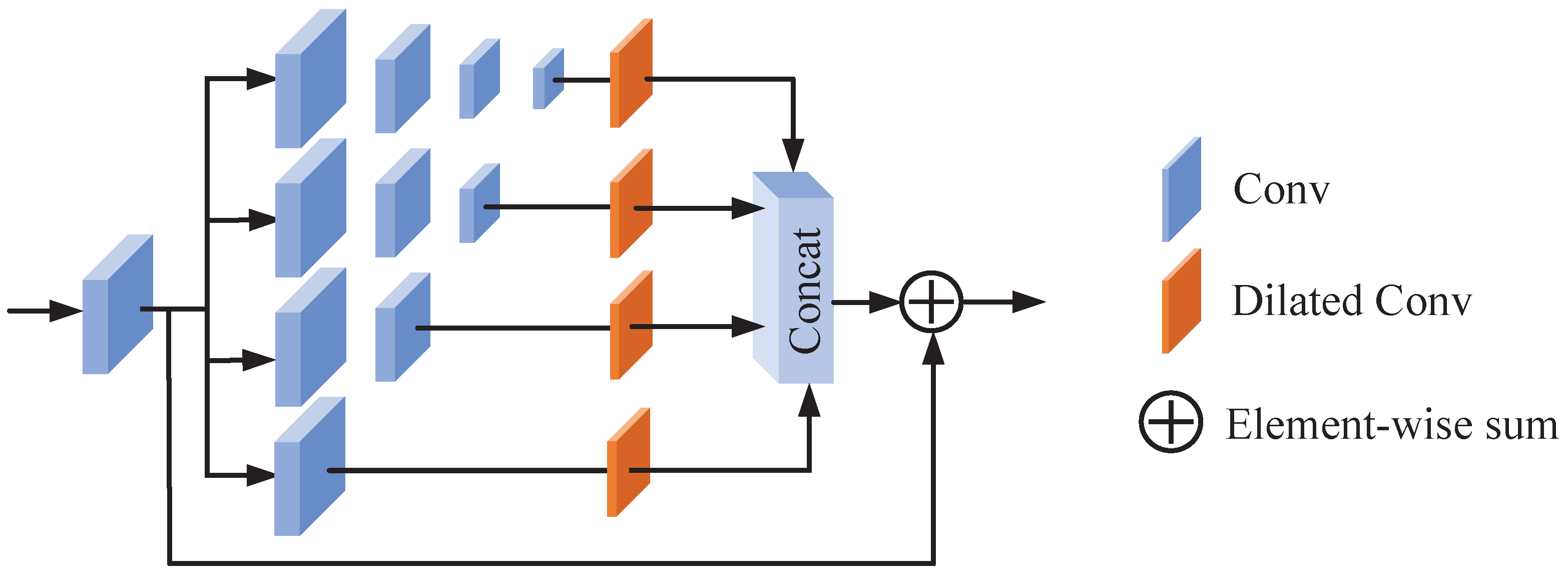
- We propose a more effective shallow feature extraction layer known as the multi-scale feature extraction (MSFE) module, aimed at enhancing the model’s capability to capture low-frequency information. By adjusting the depth and channel number of the convolutional layers of different branches and adding dilated convolutions, the receptive field is expanded and finer-grained shallow features are extracted.
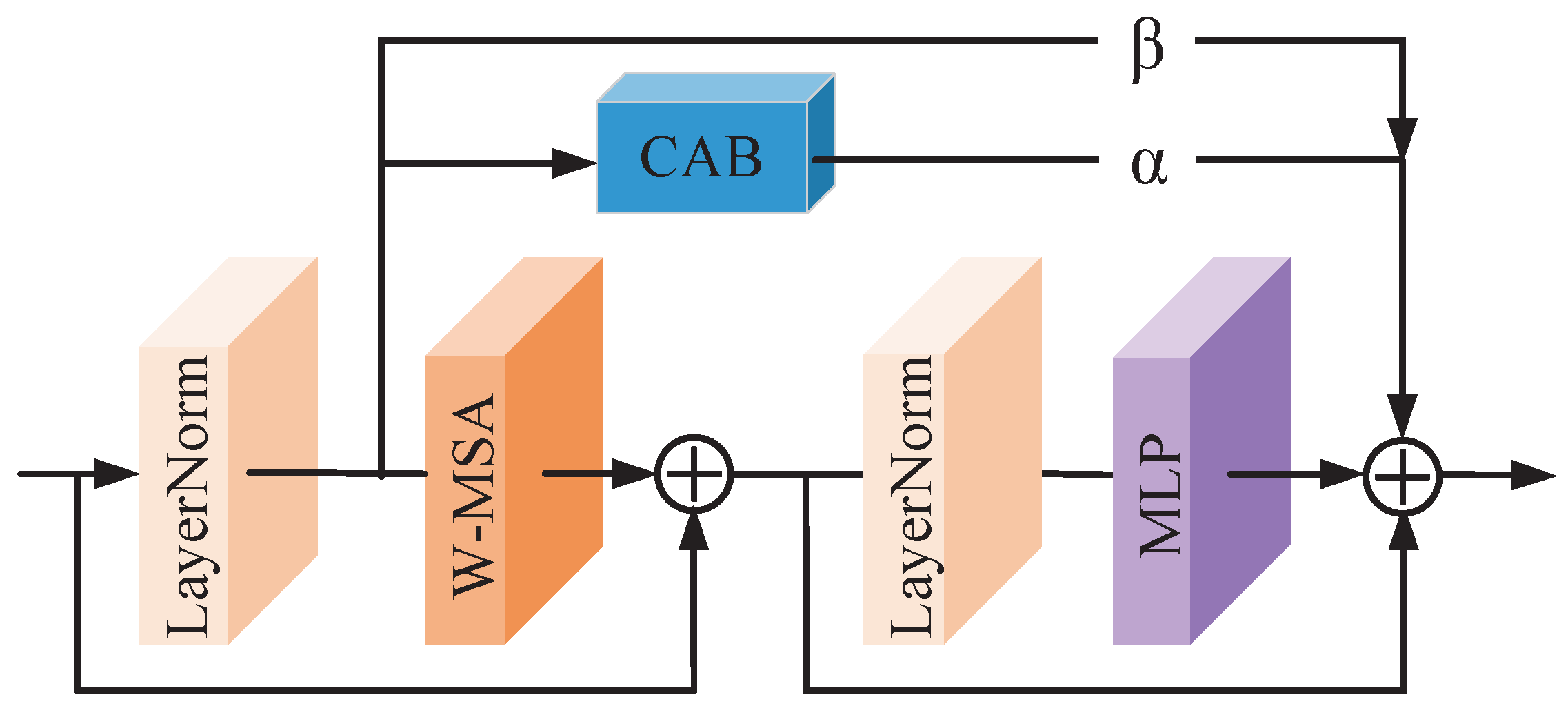
- We analyze the characteristics of window self-attention and propose the fused attention block FAB. Based on moving window multi-head self-attention, we add channel attention through the residual structure to achieve information fusion of global and local features.
- We explore several additional strategies aimed at enhancing the model’s performance. These include employing data augmentation techniques, implementing a smoother Smooth Loss function, enlarging the window size of the swin-transformer, and adopting pre-training strategies.
2. Related Work
2.1. Deep Network Methods for Image SR
2.2. Transformer-Based Methods for Image SR
3. Methodology
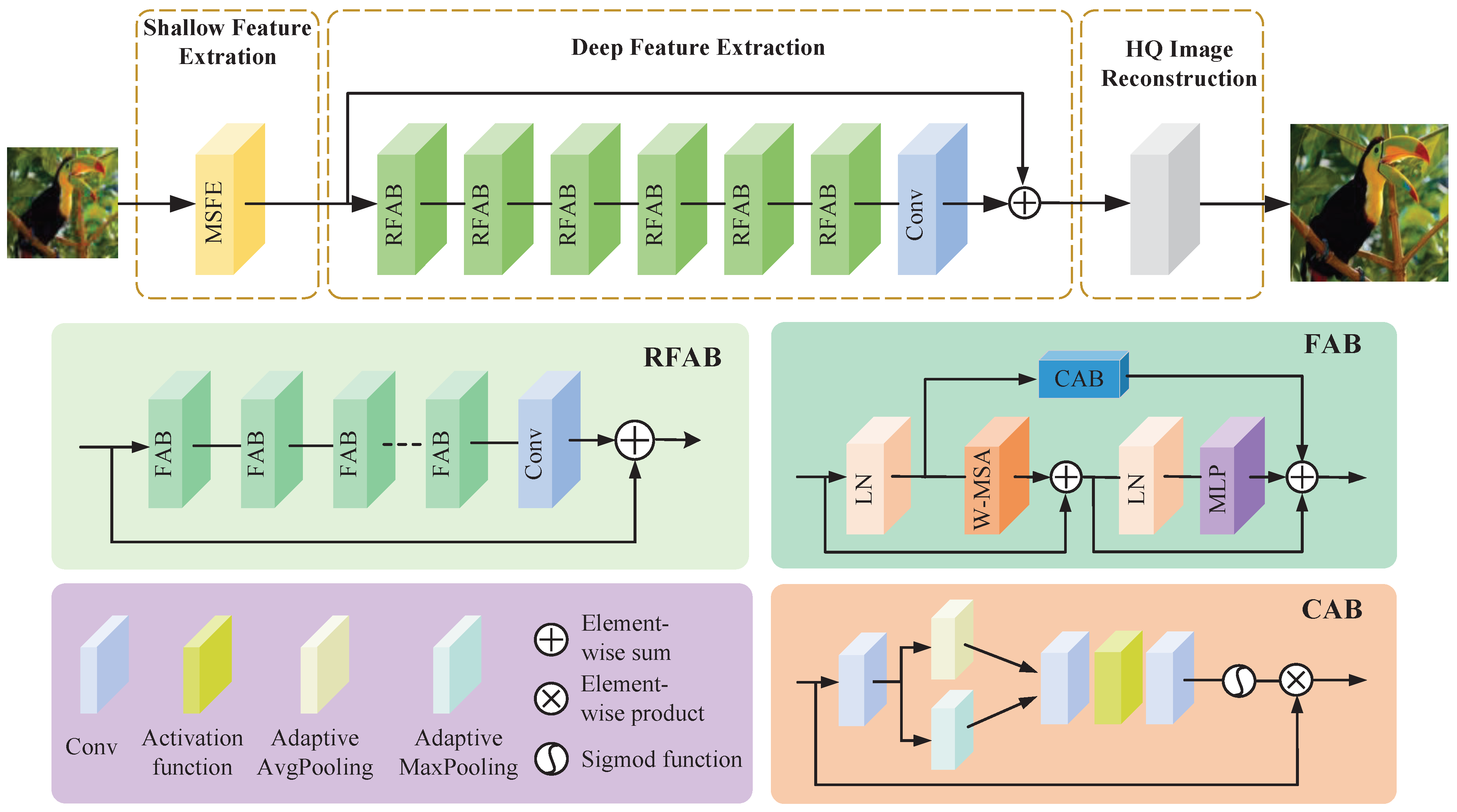
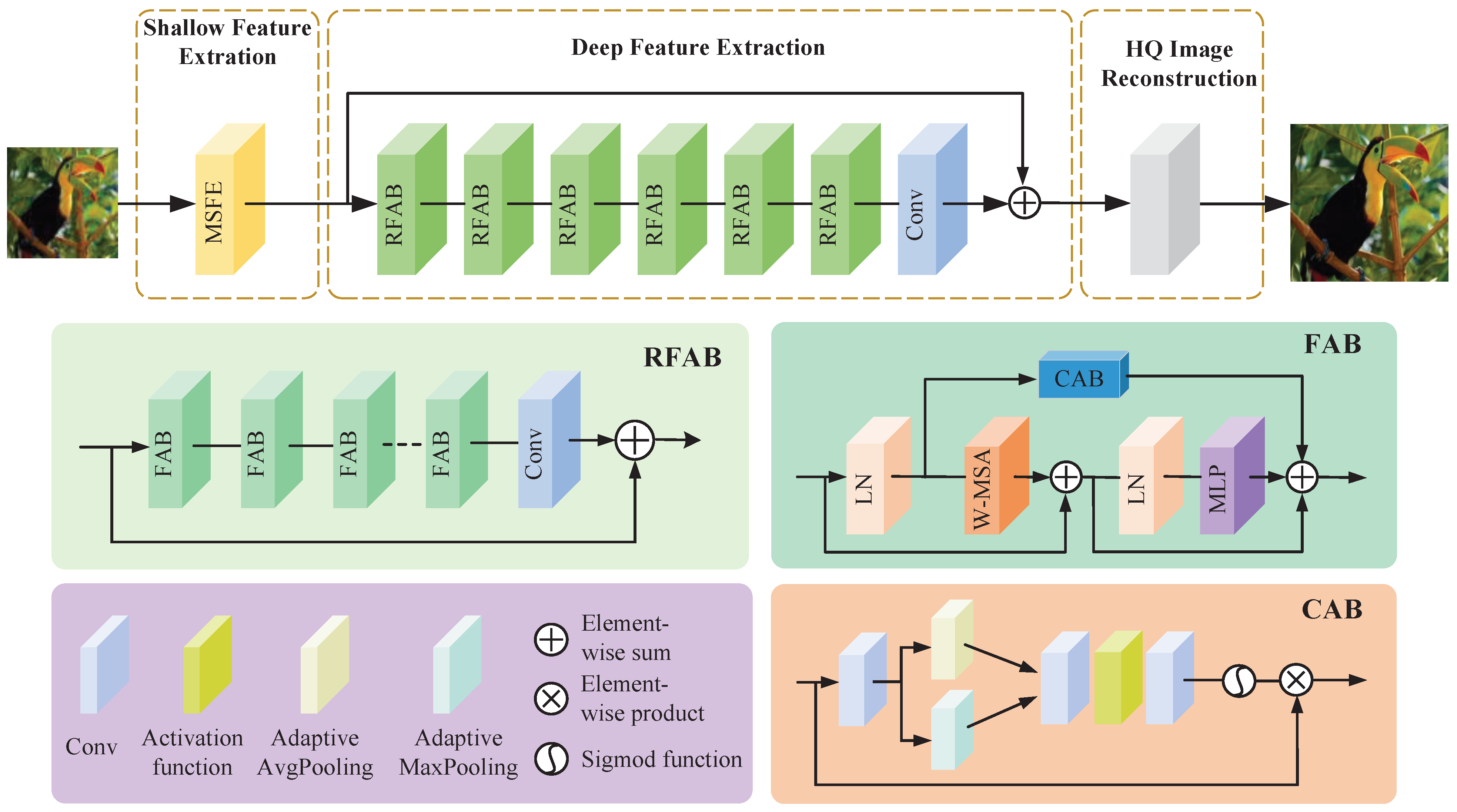
3.1. Network Architecture
3.2. Multi-Scale Feature Extraction (MSFE) Module
3.3. Fused Attention Block (FAB)
3.4. Loss Function
4. Experiments
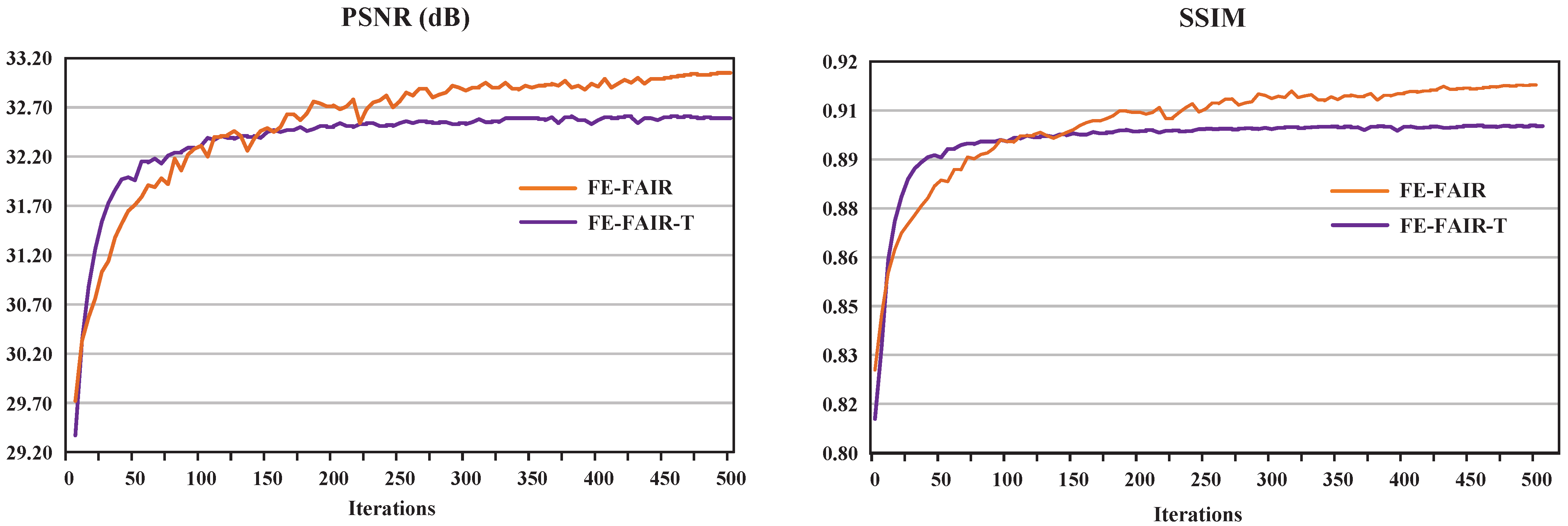
4.1. Experimental Setup
4.2. Ablation Experiment
4.2.1. Effectiveness of MSFE
4.2.2. Effects of the FAB
4.2.3. Effects of Smooth
4.2.4. Effects of Window Size
4.3. Comparison Result
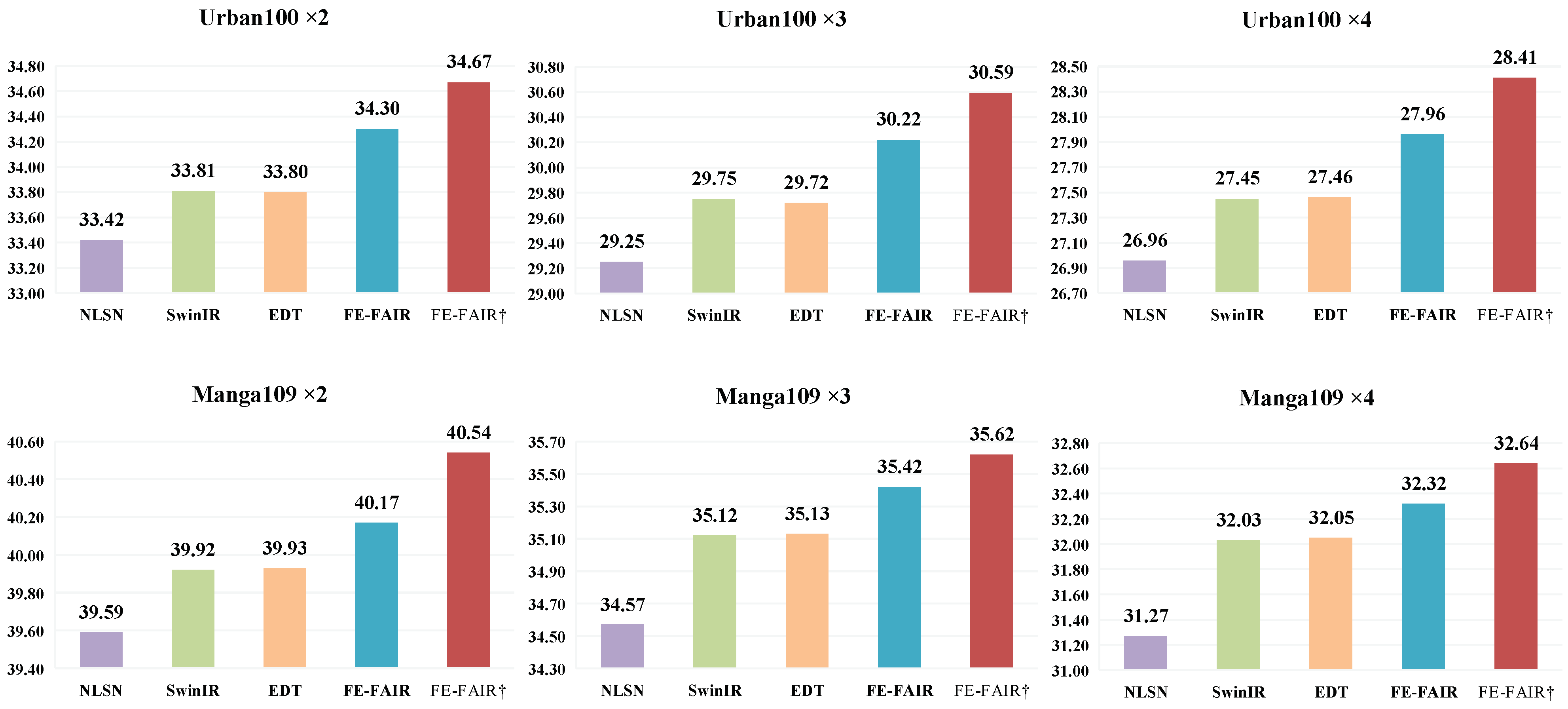
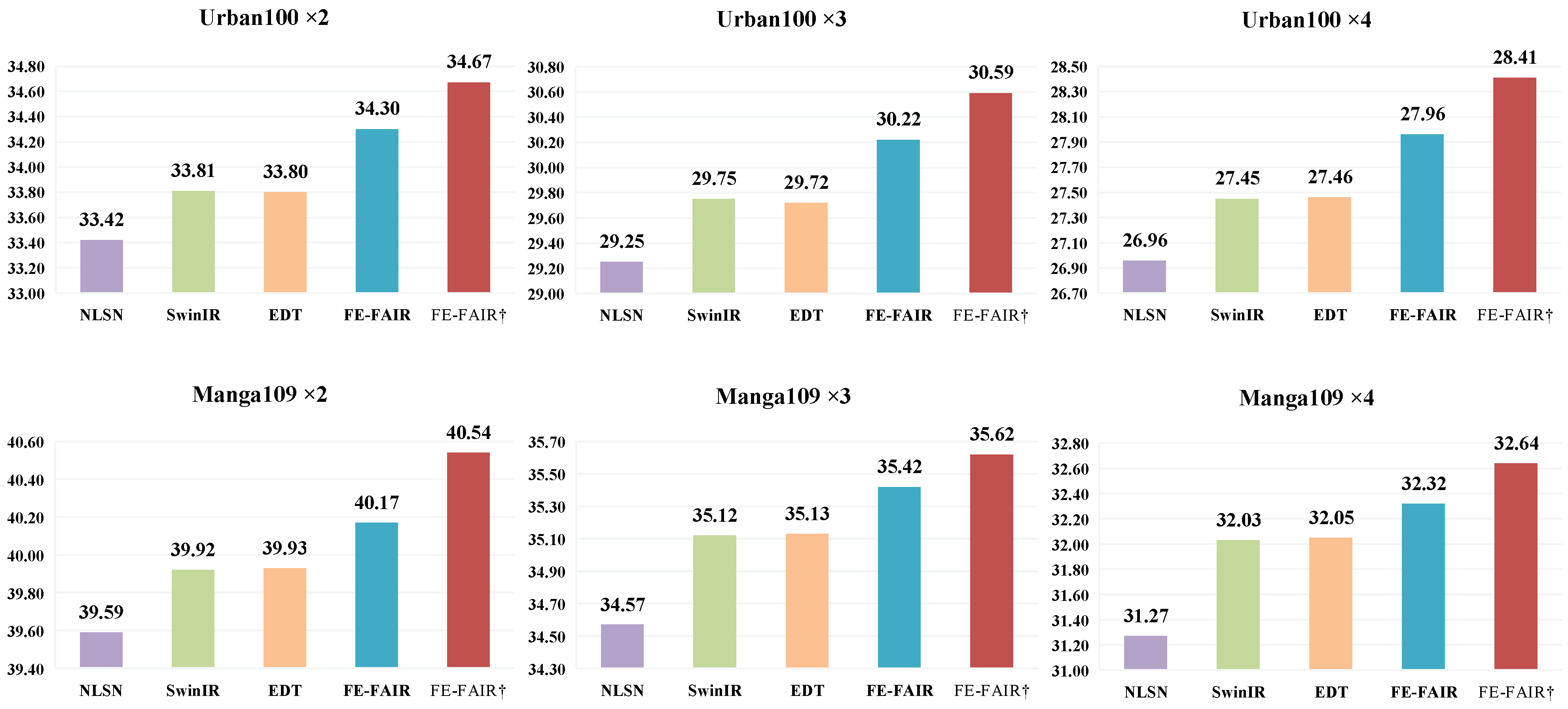
4.3.1. Results on Classical Image Super-Resolution
4.3.2. Results on Lightweight Image Super-Resolution
4.3.3. Results on Image Denoising
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Park, S.C.; Park, M.K.; Kang, M.G. Super-resolution image reconstruction: A technical overview. IEEE Signal Process. Mag. 2003, 20, 21–36. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part IV 13. Springer: Cham, Switzerland, 2014; pp. 184–199. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Cham, Switzerland, 2016; pp. 391–407. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single image super-resolution via a holistic attention network. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XII 16. Springer: Cham, Switzerland, 2020; pp. 191–207. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 18–24 June 2019; pp. 11065–11074. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 15. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12299–12310. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 1833–1844. [Google Scholar]
- Li, W.; Lu, X.; Qian, S.; Lu, J.; Zhang, X.; Jia, J. On efficient transformer-based image pre-training for low-level vision. arXiv 2021, arXiv:2112.10175. [Google Scholar]
- Lu, Z.; Li, J.; Liu, H.; Huang, C.; Zhang, L.; Zeng, T. Transformer for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 457–466. [Google Scholar]
- Chen, X.; Wang, X.; Zhou, J.; Qiao, Y.; Dong, C. Activating more pixels in image super-resolution transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22367–22377. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Deng, J. A large-scale hierarchical image database. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 126–135. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Mei, Y.; Fan, Y.; Zhou, Y. Image super-resolution with non-local sparse attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3517–3526. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Wu, B.; Xu, C.; Dai, X.; Wan, A.; Zhang, P.; Yan, Z.; Tomizuka, M.; Gonzalez, J.; Keutzer, K.; Vajda, P. Visual transformers: Token-based image representation and processing for computer vision. arXiv 2020, arXiv:2006.03677. [Google Scholar]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the design of spatial attention in vision transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 9355–9366. [Google Scholar]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 22–31. [Google Scholar]
- Xiao, T.; Singh, M.; Mintun, E.; Darrell, T.; Dollár, P.; Girshick, R. Early convolutions help transformers see better. Adv. Neural Inf. Process. Syst. 2021, 34, 30392–30400. [Google Scholar]
- Yuan, K.; Guo, S.; Liu, Z.; Zhou, A.; Yu, F.; Wu, W. Incorporating convolution designs into visual transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 579–588. [Google Scholar]
- Wang, Y.; Liang, B.; Ding, M.; Li, J. Dense semantic labeling with atrous spatial pyramid pooling and decoder for high-resolution remote sensing imagery. Remote Sens. 2018, 11, 20. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.; Chen, D. Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1091–1100. [Google Scholar]
- Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; Xu, C. Cmt: Convolutional neural networks meet vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12175–12185. [Google Scholar]
- Sutanto, A.R.; Kang, D.K. A novel diminish smooth L1 loss model with generative adversarial network. In Proceedings of the Intelligent Human Computer Interaction: 12th International Conference, IHCI 2020, Daegu, Republic of Korea, 24–26 November 2020; Proceedings, Part I 12. Springer: Cham, Switzerland, 2021; pp. 361–368. [Google Scholar]
- Zhou, S.; Zhang, J.; Zuo, W.; Loy, C.C. Cross-scale internal graph neural network for image super-resolution. Adv. Neural Inf. Process. Syst. 2020, 33, 3499–3509. [Google Scholar]
- Li, Y.; Agustsson, E.; Gu, S.; Timofte, R.; Van Gool, L. Carn: Convolutional anchored regression network for fast and accurate single image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight image super-resolution with information multi-distillation network. In Proceedings of the 27th ACM International Conference on Multimedia, Multimedia, Nice, France, 21–25 October 2019; pp. 2024–2032. [Google Scholar]
- Li, W.; Zhou, K.; Qi, L.; Jiang, N.; Lu, J.; Jia, J. Lapar: Linearly-assembled pixel-adaptive regression network for single image super-resolution and beyond. Adv. Neural Inf. Process. Syst. 2020, 33, 20343–20355. [Google Scholar]
- Luo, X.; Xie, Y.; Zhang, Y.; Qu, Y.; Li, C.; Fu, Y. Latticenet: Towards lightweight image super-resolution with lattice block. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXII 16. Springer: Cham, Switzerland, 2020; pp. 272–289. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Gu, S.; Zhang, L.; Zuo, W.; Feng, X. Weighted nuclear norm minimization with application to image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2862–2869. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning deep CNN denoiser prior for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3929–3938. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef] [PubMed]
- Liu, D.; Wen, B.; Fan, Y.; Loy, C.C.; Huang, T.S. Non-local recurrent network for image restoration. arXiv 2018, arXiv:1806.02919v2. [Google Scholar]
- Jia, X.; Liu, S.; Feng, X.; Zhang, L. Focnet: A fractional optimal control network for image denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6054–6063. [Google Scholar]
- Liu, P.; Zhang, H.; Zhang, K.; Lin, L.; Zuo, W. Multi-level wavelet-CNN for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 773–782. [Google Scholar]
- Zhang, K.; Li, Y.; Zuo, W.; Zhang, L.; Van Gool, L.; Timofte, R. Plug-and-play image restoration with deep denoiser prior. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6360–6376. [Google Scholar] [CrossRef]
- Peng, Y.; Zhang, L.; Liu, S.; Wu, X.; Zhang, Y.; Wang, X. Dilated residual networks with symmetric skip connection for image denoising. Neurocomputing 2019, 345, 67–76. [Google Scholar] [CrossRef]
- Xia, Z.; Chakrabarti, A. Identifying recurring patterns with deep neural networks for natural image denoising. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 2426–2434. [Google Scholar]
- Tian, C.; Xu, Y.; Zuo, W. Image denoising using deep CNN with batch renormalization. Neural Netw. 2020, 121, 461–473. [Google Scholar] [CrossRef]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the 23rd British Machine Vision Conference (BMVC), Surrey, UK, 3–7 September 2012. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the Curves and Surfaces: 7th International Conference, Avignon, France, 24–30 June 2010; Revised Selected Papers 7. Springer: Cham, Switzerland, 2012; pp. 711–730. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef]
- Ma, K.; Duanmu, Z.; Wu, Q.; Wang, Z.; Yong, H.; Li, H.; Zhang, L. Waterloo exploration database: New challenges for image quality assessment models. IEEE Trans. Image Process. 2016, 26, 1004–1016. [Google Scholar] [CrossRef]
- Yu, S.; Park, B.; Jeong, J. Deep iterative down-up cnn for image denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhang, L.; Wu, X.; Buades, A.; Li, X. Color demosaicking by local directional interpolation and nonlocal adaptive thresholding. J. Electron. Imaging 2011, 20, 023016. [Google Scholar]
- Lay, J.A.; Guan, L. Image retrieval based on energy histograms of the low frequency DCT coefficients. In Proceedings of the 1999 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings. ICASSP99 (Cat. No. 99CH36258), Phoenix, AZ, USA, 15–19 March 1999; Volume 6, pp. 3009–3012. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Scale | Set14 [57] | Urban100 [59] | Manga109 [60] |
|---|---|---|---|---|
| Conv | 2 | 34.46/0.9250 | 33.81/0.9427 | 39.92/0.9797 |
| 3 × Conv | 2 | 34.47/0.9252 | 33.82/0.9428 | 39.93/0.9796 |
| ASPP [34] | 2 | 34.48/0.9253 | 33.84/0.9431 | 39.94/0.9798 |
| MSFE | 2 | 34.52/0.9257 | 33.92/0.9435 | 39.98/0.9804 |
| Conv | 4 | 29.09/0.7950 | 27.45/0.8254 | 32.03/0.9260 |
| 3 × Conv | 4 | 29.10/0.7949 | 27.47/0.8256 | 32.05/0.9259 |
| ASPP [34] | 4 | 29.12/0.7952 | 27.48/0.8259 | 32.07/0.9262 |
| MSFE | 4 | 29.15/0.7958 | 27.53/0.8271 | 32.11/0.9265 |
| Module | Set14 [57] | Urban100 [59] | Manga109 [60] |
|---|---|---|---|
| STL | 29.15/0.7958 | 27.53/0.8271 | 32.11/0.9265 |
| FAB | 29.17/0.7959 | 27.62/0.8277 | 32.17/0.9270 |
| FAB + + | 29.19/0.7960 | 27.65/0.8282 | 32.20/0.9273 |
| Module | Loss | Smooth Loss |
|---|---|---|
| PSNR/SSIM | 27.65/0.8282 | 27.68/0.8289 |
| Window Size | Set14 [57] | Urban100 [59] | Manga109 [60] |
|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | |
| (8, 8) | 29.20/0.7962 | 27.68/0.8289 | 32.23/0.9268 |
| (12, 12) | 29.22/0.7966 | 27.87/ 0.8348 | 32.28/0.9279 |
| (16, 16) | 29.21/0.7966 | 27.96/0.8377 | 32.32/0.9287 |
| Method | Scale | Training | Set5 [56] | Set14 [57] | BSD100 [58] | Urban100 [59] | Manga109 [60] |
|---|---|---|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | |||
| EDSR [6] | ×2 | DIV2K | 38.11/0.9602 | 33.92/0.9195 | 32.32/0.9013 | 32.93/0.9351 | 39.10/0.9773 |
| RCAN [8] | ×2 | DIV2K | 38.27/0.9614 | 34.12/0.9216 | 32.41/0.9027 | 33.34/0.9384 | 39.44/0.9786 |
| SAN [10] | ×2 | DIV2K | 38.31/0.9620 | 34.07/0.9213 | 32.42/0.9028 | 33.10/0.9370 | 39.32/0.9792 |
| IGNN [38] | ×2 | DIV2K | 38.24/0.9613 | 34.07/0.9217 | 32.41/0.9025 | 33.23/0.9383 | 39.35/0.9786 |
| HAN [9] | ×2 | DIV2K | 38.27/0.9614 | 34.16/0.9217 | 32.41/0.9027 | 33.35/0.9385 | 39.46/0.9785 |
| NLSN [25] | ×2 | DIV2K | 38.34/0.9618 | 34.08/0.9231 | 32.43/0.9027 | 33.42/0.9394 | 39.59/0.9789 |
| SwinIR [16] | ×2 | DF2K | 38.42/0.9623 | 34.46/0.9250 | 32.53/0.9041 | 33.81/0.9427 | 39.92/0.9797 |
| EDT [17] | ×2 | DF2K | 38.45/0.9624 | 34.57/0.9263 | 32.52/0.9041 | 33.80/0.9425 | 39.93/0.9800 |
| FE-FAIR | ×2 | DF2K | 38.58/0.9629 | 34.73/0.9266 | 32.58/0.9048 | 34.30/0.9460 | 40.17/0.9804 |
| IPT † [15] | ×2 | ImageNet | 38.37/- | 34.43/- | 32.48/- | 33.76/- | -/- |
| EDT † [17] | ×2 | DF2K | 38.63/0.9632 | 34.80/0.9273 | 32.62/0.9052 | 34.27/0.9456 | 40.37/0.9811 |
| FE-FAIR † | ×2 | DF2K | 38.66/0.9632 | 34.99/0.9275 | 32.66/0.9057 | 34.67/0.9490 | 40.54/0.9812 |
| EDSR [6] | ×3 | DIV2K | 34.65/0.9280 | 30.52/0.8462 | 29.25/0.8093 | 28.80/0.8653 | 34.17/0.9476 |
| RCAN [8] | ×3 | DIV2K | 34.74/0.9299 | 30.65/0.8482 | 29.32/0.8111 | 29.09/0.8702 | 34.44/0.9499 |
| SAN [10] | ×3 | DIV2K | 34.75/0.9300 | 30.59/0.8476 | 29.33/0.8112 | 28.93/0.8671 | 34.30/0.9494 |
| IGNN [38] | ×3 | DIV2K | 34.72/0.9298 | 30.66/0.8484 | 29.31/0.8105 | 29.03/0.8696 | 34.39/0.9496 |
| HAN [9] | ×3 | DIV2K | 34.75/0.9299 | 30.67/0.8483 | 29.32/0.8110 | 29.10/0.8705 | 34.48/0.9500 |
| NLSN [25] | ×3 | DIV2K | 34.85/0.9306 | 30.70/0.8485 | 29.34/0.8117 | 29.25/0.8760 | 34.57/0.9508 |
| SwinIR [16] | ×3 | DF2K | 34.97/0.9318 | 30.93/0.8534 | 29.46/0.8145 | 29.75/0.8826 | 35.12/ 0.9537 |
| EDT [17] | ×3 | DF2K | 34.97/0.9316 | 30.89/0.8527 | 29.44/0.8142 | 29.72/0.8814 | 35.13/0.9534 |
| FE-FAIR | ×3 | DF2K | 35.02/0.9326 | 31.02/0.8551 | 29.50/0.8162 | 30.22/0.8898 | 35.42/0.9547 |
| IPT † [15] | ×3 | ImageNet | 38.37/- | 34.43/- | 32.48/- | 33.76/- | -/- |
| EDT † [17] | ×3 | DF2K | 35.13/0.9328 | 31.09/0.8553 | 29.53/0.8165 | 30.07/0.8863 | 35.47/0.9550 |
| FE-FAIR † | ×3 | DF2K | 35.14/0.9335 | 31.24/0.8569 | 29.53/0.8172 | 30.59/0.8944 | 35.62/0.9561 |
| EDSR [6] | ×4 | DIV2K | 32.46/0.8968 | 28.80/0.7876 | 27.71/0.7420 | 26.64/0.8033 | 31.02/0.9148 |
| RCAN [8] | ×4 | DIV2K | 32.63/0.9002 | 28.87/0.7889 | 27.77/0.7436 | 26.82/0.8087 | 31.22/0.9173 |
| SAN [10] | ×4 | DIV2K | 32.64/0.9003 | 28.92/0.7888 | 27.78/0.7436 | 26.79/0.8068 | 31.18/0.9169 |
| IGNN [38] | ×4 | DIV2K | 32.57/0.8998 | 28.85/0.7891 | 27.77/0.7434 | 26.84/0.8090 | 31.28/0.9182 |
| HAN [9] | ×4 | DIV2K | 32.64/0.9002 | 28.90/0.7890 | 27.80/0.7442 | 26.85/0.8094 | 31.42/0.9177 |
| NLSN [25] | ×4 | DIV2K | 32.59/0.9000 | 28.87/0.7891 | 27.78/0.7444 | 26.96/0.8109 | 31.27/0.9184 |
| SwinIR [16] | ×4 | DF2K | 32.92/0.9044 | 29.09/0.7950 | 27.92/0.7489 | 27.45/ 0.8254 | 32.03/0.9260 |
| EDT [17] | ×4 | DF2K | 32.82/0.9031 | 29.09/0.7939 | 27.91/0.7483 | 27.46 /0.8246 | 32.05/0.9254 |
| FE-FAIR | ×4 | DF2K | 33.05/0.9053 | 29.21/0.7966 | 27.97/0.7514 | 27.96/0.8377 | 32.32/0.9287 |
| IPT † [15] | ×4 | ImageNet | 38.37/- | 34.43/- | 32.48/- | 33.76/- | -/- |
| EDT † [17] | ×4 | DF2K | 33.06/0.9055 | 29.23/0.7971 | 27.99/0.7510 | 27.75/0.8317 | 32.39/0.9283 |
| FE-FAIR † | ×4 | DF2K | 33.19/0.9075 | 29.35/0.7992 | 28.03/0.7531 | 28.41/0.8450 | 32.64/0.9301 |
| Method | Scale | # Params | Set5 [56] | Set14 [57] | B100 [58] | Urban100 [59] | Manga109 [60] |
|---|---|---|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | |||
| CARN [39] | ×2 | 1592 k | 37.76/0.9590 | 33.52/0.9166 | 32.09/0.8978 | 31.92/0.9256 | 38.36/0.9765 |
| IMDN [40] | ×2 | 548 k | 38.00/0.9605 | 33.63/0.9177 | 32.19/0.8996 | 32.17/0.9283 | 38.88/0.9774 |
| LAPAR-A [41] | ×2 | 548 k | 38.01/0.9605 | 33.62/0.9183 | 32.19/0.8999 | 32.10/0.9283 | 38.67/0.9772 |
| LatticeNet [42] | ×2 | 756 k | 38.15/0.9610 | 33.78/0.9193 | 32.25/0.9005 | 32.43/0.9302 | -/- |
| SwinIR [16] | ×2 | 878 k | 38.14/0.9611 | 33.86/0.9206 | 32.31/0.9012 | 32.76/0.9340 | 39.12/0.9783 |
| EDT [17] | ×2 | 917 k | 38.23/0.9615 | 33.99/0.9209 | 32.37/0.9021 | 32.98/0.9362 | 39.45/0.9789 |
| FE-FAIR | ×2 | 2291 k | 38.30/0.9621 | 33.10/0.9214 | 32.41/0.9027 | 33.37/0.9417 | 39.56/0.9808 |
| CARN [39] | ×3 | 1592 k | 34.29/0.9255 | 30.29/0.8407 | 29.06/0.8034 | 28.06/0.8493 | 33.50/0.9440 |
| IMDN [40] | ×3 | 703 k | 34.36/0.9270 | 30.32/0.8417 | 29.09/0.8046 | 28.17/0.8519 | 33.61/0.9445 |
| LAPAR-A [41] | ×3 | 544 k | 34.36/0.9267 | 30.34/0.8421 | 29.11/0.8054 | 28.15/0.8523 | 33.51/0.9441 |
| LatticeNet [42] | ×3 | 765 k | 34.53/0.9281 | 30.39/0.8424 | 29.15/0.8059 | 28.33/0.8538 | -/- |
| SwinIR [16] | ×3 | 886 k | 34.62/0.9289 | 30.54/0.8463 | 29.20/0.8082 | 28.66/0.8624 | 33.98/0.9478 |
| EDT [17] | ×3 | 919 k | 34.73/0.9299 | 30.66/0.8481 | 29.29/0.8103 | 28.89/0.8674 | 34.44/0.9498 |
| FE-FAIR | ×3 | 2299 k | 34.80/0.9311 | 30.75/0.8492 | 29.33/0.8105 | 29.25/0.8727 | 34.52/0.9518 |
| CARN [39] | ×4 | 1592 k | 32.13/0.8937 | 28.60/0.7806 | 27.58/0.7349 | 26.07/0.7837 | 30.47/0.9084 |
| IMDN [40] | ×4 | 715 k | 32.21/0.8948 | 28.58/0.7811 | 27.56/0.7353 | 26.04/0.7838 | 30.45/0.9075 |
| LAPAR-A [41] | ×4 | 659 k | 32.15/0.8944 | 28.61/0.7818 | 27.61/0.7366 | 26.14/0.7871 | 30.42/0.9074 |
| LatticeNet [42] | ×4 | 777 k | 32.30/0.8962 | 28.68/0.7830 | 27.62/0.7367 | 26.25/0.7873 | -/- |
| SwinIR [16] | ×4 | 897 k | 32.44/0.8976 | 28.77/0.7858 | 27.69/0.7406 | 26.47/0.7980 | 30.92/0.9151 |
| EDT [17] | ×4 | 922 k | 32.53/0.8991 | 28.88/0.7882 | 27.76/0.7433 | 26.71/0.8051 | 31.35/0.9180 |
| FE-FAIR | ×4 | 2310 k | 32.59/0.9002 | 28.97/0.7903 | 27.79/0.7447 | 27.04/0.8139 | 31.41/0.9199 |
| Dataset | BM3D [43] | WNNM [44] | DnCNN [45] | IRCNN [46] | FFDNet [47] | NLRN [48] | FOCNet [49] | MWCNN [50] | DRUNet [51] | SwinIR [16] | FE-FAIR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Set12 [45] | 15 | 32.37 | 32.70 | 32.86 | 32.76 | 32.75 | 33.16 | 33.07 | 33.15 | 33.25 | 33.36 | 33.41 |
| 25 | 29.97 | 30.28 | 30.44 | 30.37 | 30.43 | 30.80 | 30.73 | 30.79 | 30.94 | 31.01 | 31.07 | |
| 50 | 26.72 | 27.05 | 27.18 | 27.12 | 27.32 | 27.64 | 27.68 | 27.74 | 27.90 | 27.91 | 27.96 | |
| BSD68 [58] | 15 | 31.08 | 31.37 | 31.73 | 31.63 | 31.63 | 31.88 | 31.83 | 31.86 | 31.91 | 31.97 | 32.04 |
| 25 | 28.57 | 28.83 | 29.23 | 29.15 | 29.19 | 29.41 | 29.38 | 29.41 | 29.48 | 27.50 | 27.54 | |
| 50 | 25.60 | 25.87 | 26.23 | 26.19 | 26.29 | 26.47 | 26.50 | 26.53 | 26.59 | 26.58 | 26.61 | |
| Urban100 [59] | 15 | 32.35 | 32.97 | 32.64 | 32.46 | 32.40 | 33.45 | 33.15 | 33.17 | 33.44 | 33.70 | 33.81 |
| 25 | 29.70 | 30.39 | 29.95 | 29.80 | 29.90 | 30.94 | 30.64 | 30.66 | 31.11 | 31.30 | 33.45 | |
| 50 | 25.95 | 26.83 | 26.26 | 26.22 | 26.50 | 27.49 | 27.40 | 27.42 | 27.96 | 27.98 | 28.12 |
| Dataset | BM3D [43] | DnCNN [45] | IRCNN [46] | FFDNet [47] | DSNet [52] | RPCNN [53] | BRDNet [54] | IPT [15] | DRUNet [51] | SwinIR [16] | FE-FAIR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CBSD68 [58] | 15 | 33.52 | 33.90 | 33.86 | 33.87 | 33.91 | - | 34.10 | - | 34.30 | 34.42 | 34.46 |
| 25 | 30.71 | 31.24 | 31.16 | 31.21 | 31.28 | 31.24 | 31.43 | - | 31.69 | 31.78 | 31.81 | |
| 50 | 27.38 | 27.95 | 27.86 | 27.96 | 28.05 | 28.06 | 28.16 | 28.39 | 28.51 | 28.56 | 28.58 | |
| Kodak24 [62] | 15 | 34.28 | 34.60 | 34.69 | 34.63 | 34.63 | - | 34.88 | - | 35.31 | 35.34 | 35.39 |
| 25 | 32.15 | 32.14 | 32.18 | 32.13 | 32.16 | 32.34 | 32.41 | - | 32.89 | 32.89 | 32.97 | |
| 50 | 28.46 | 28.95 | 28.93 | 28.98 | 29.05 | 29.25 | 29.22 | 29.64 | 29.86 | 29.79 | 29.91 | |
| McMaster [63] | 15 | 34.06 | 33.45 | 34.58 | 34.66 | 34.67 | - | 35.08 | - | 35.40 | 35.61 | 35.67 |
| 25 | 31.66 | 31.52 | 32.18 | 32.35 | 32.40 | 32.33 | 32.75 | - | 33.14 | 33.20 | 33.31 | |
| 50 | 28.51 | 28.62 | 28.91 | 29.18 | 29.28 | 29.33 | 29.52 | 29.98 | 30.08 | 30.22 | 30.27 | |
| Urban100 [59] | 15 | 33.93 | 32.98 | 33.78 | 33.83 | - | - | 34.42 | - | 34.81 | 35.13 | 35.26 |
| 25 | 31.36 | 30.81 | 31.20 | 31.40 | - | 31.81 | 31.99 | - | 32.60 | 32.90 | 33.06 | |
| 50 | 27.93 | 27.59 | 27.70 | 28.05 | - | 28.62 | 28.56 | 29.71 | 29.61 | 29.82 | 30.12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, A.; Shen, K.; Liu, J. FE-FAIR: Feature-Enhanced Fused Attention for Image Super-Resolution. Electronics 2024, 13, 1075. https://doi.org/10.3390/electronics13061075
Guo A, Shen K, Liu J. FE-FAIR: Feature-Enhanced Fused Attention for Image Super-Resolution. Electronics. 2024; 13(6):1075. https://doi.org/10.3390/electronics13061075
Chicago/Turabian StyleGuo, Aiying, Kai Shen, and Jingjing Liu. 2024. "FE-FAIR: Feature-Enhanced Fused Attention for Image Super-Resolution" Electronics 13, no. 6: 1075. https://doi.org/10.3390/electronics13061075
APA StyleGuo, A., Shen, K., & Liu, J. (2024). FE-FAIR: Feature-Enhanced Fused Attention for Image Super-Resolution. Electronics, 13(6), 1075. https://doi.org/10.3390/electronics13061075