1. Introduction
As computing and storage resources continue to advance, mobile phones, smart wearable devices, and various sensors are constantly collecting people’s daily activity data and storing them in large storage clusters. Meanwhile, vast amounts of collected data can be utilized more efficiently in practical problem-solving and modeling processes with the maturation of large-scale machine learning algorithms and big data processing technologies, along with the continuous improvement of computer hardware performance. Successful applications such as face recognition, speech recognition, machine translation, and personalized recommendations rely on large amounts of annotated data. However, real-world applications often lack billion-level data, requiring the integration of decentralized resources to expand the data scale and support machine learning algorithms.
In 2016, Google proposed federated learning for mobile devices [
1], with the goal of creating customized machine learning models based on data from multiple distributed devices while preventing data leakages. At that time, issues related to the misuse of personal data and privacy breaches were globally recognized concerns. Addressing these concerns, laws and regulations were enacted gradually to protect data privacy, such as the General Data Protection Regulation (GDPR) established by the European Union [
2]. These regulations require companies to obtain users’ consent before collecting personal data and to safeguard against data breaches. Given the paramount importance of compliance with data privacy and security laws and regulations, the challenge of jointly training machine learning models utilizing data from multiple parties assumes critical significance. In this context, federated learning is considered the foundation of the next generation of artificial intelligence (AI) collaborative algorithms and cooperative networks. It allows participants to collectively build models without sharing data, thus breaking down data silos and facilitating AI collaboration [
3].
As the use of federated learning becomes increasingly common, there have been concerns about its capacity to protect privacy [
4]. It is known that federated learning protects local data by exchanging model parameters with the server. Nevertheless, scholars have found that the privacy information of training data may also be exposed via exchanged model gradients. Hitaj et al. [
5] devise a privacy attack method by employing a generative adversarial network (GAN) that allows them to deduce sensitive information relating to a select group of clients’ local data. Similarly, Zhu et al. [
6] propose deep leakage from gradients (DLG), which can reconstruct the training data through gradient computation. Specifically, the adversary generates random “virtual” data and labels
and computes the forward and backward propagation of the model F. After obtaining the corresponding virtual gradient
, the inputs and labels are then optimized to minimize the distance between
and the genuine gradient w, effectively matching
to the original data
. In response to these challenges, researchers have suggested solutions to enhance the privacy protection in federated learning aggregation, such as incorporating secret sharing, homomorphic encryption, and differential privacy technologies. Although these methods can enhance the security during training, they often require significant additional computational or communication overheads, potentially at the expense of model performance. Therefore, designing an efficient federated learning scheme that balances privacy protection, communication costs, and model performance is crucial.
In this paper, we present the Effective Private-Protected Federated Learning Aggregation Algorithm (EPFed), which is an innovative federated learning framework designed to enhance the data privacy and computational efficiency. EPFed ingeniously integrates blockchain technology, homomorphic encryption, and secret sharing mechanisms. Its primary goal is to facilitate secure and efficient model parameter exchange and updates without compromising data privacy. Unlike traditional approaches that heavily rely on blockchain in establishing trust, blockchain serves merely as a platform for trusted data exchanges in EPFed. The framework establishes “trust groups” to allow participants to share and aggregate model parameters securely and effectively, maintaining data privacy and security.
The framework’s innovation lies in its utilization of a secret sharing scheme, integrated with Paillier homomorphic encryption, to streamline the processes of data exchange and model aggregation in federated learning. This approach significantly alleviates the computational load and minimizes decryption-related delays. EPFed is anchored by two foundational elements: firstly, the creation of trust groups and a secure mechanism for the exchange of model parameters within these groups. This is achieved through a secret sharing scheme inspired by the Chinese Remainder Theorem, coupled with Paillier’s homomorphic encryption, to adeptly manage encrypted data’s aggregation calculations. This scheme employs addition for encryption, markedly reducing the computational complexity compared to conventional cryptographic encryption methods. Paillier’s encryption ensures that the model parameters can be aggregated without decryption, thus shortening the decryption times while preserving the privacy of the data exchange.
Secondly, EPFed introduces a model parameter aggregation and update mechanism predicated on an accuracy-driven approach. This method uses performance metrics from local sample data validation, such as accuracy, recall, and MAP, to steer the aggregation process. This method utilizes local data samples to calculate the accuracy-related parameters, which can effectively counter the risk of model contamination by malicious actors providing invalid model parameters, thereby safeguarding the process’s efficiency and security. Moreover, the framework achieves an optimal balance between communication performance and security during the data exchange phase, proposing a novel solution to enhance the privacy protection and efficiency in federated learning.
The primary contributions are as follows.
(1) Enhanced Privacy through Advanced Cryptography: The EPFed framework integrates homomorphic encryption with a secret sharing scheme to fortify data confidentiality and participant authentication in federated learning systems. Specifically, it employs Paillier homomorphic encryption to facilitate encrypted data aggregation, alongside a secret sharing mechanism based on the Chinese Remainder Theorem for secure model parameter exchange within trust groups. This approach not only ensures robust privacy protection but also streamlines the computational process by minimizing the need for decryption, thereby enhancing the security and efficiency of data exchange among participants.
(2) Performance-Driven Model Aggregation: The EPFed framework prioritizes accuracy- related parameters through a performance-driven model aggregation process, which evaluates model parameters using local sample data. This local evaluation leverages metrics such as accuracy, recall, and mean average precision (MAP) to calculate a comprehensive score for each participant’s model. By utilizing local data to verify these performance indicators, EPFed effectively prevents collusion among participants from contaminating the model parameters. This approach ensures that only models verified for their accuracy and reliability contribute to the federated learning process, thereby maintaining the integrity and quality of the aggregated model. The performance-driven strategy not only enhances the federated learning system’s efficacy but also safeguards against potential security threats posed by malicious participants.
(3) Empirical Validation of Practical Efficacy: The EPFed framework underwent comprehensive empirical validation to affirm its practical applicability, particularly focusing on its contribution to data privacy and computational efficiency in federated learning. Our experiments were conducted using the NSL-KDD dataset to evaluate the framework’s performance in identifying network traffic anomalies. When compared to FedAvg, EPFed demonstrated a marked improvement in latency, thereby enhancing the overall efficiency of the federated learning process. Specifically, while EPFed maintained an accuracy level around 0.9, FedAvg’s performance dropped to approximately 0.8 under similar conditions. Moreover, the evaluation of the model update latency indicated a linear increase with the number of clients, a critical metric for federated learning systems’ scalability and responsiveness.
2. Related Works
Federated learning (FL), first proposed by Konean et al. [
7], is a distributed machine learning paradigm that aims to train a shared model through collaboration among multiple participants while maintaining the privacy and security of their data. FL’s essence is in enabling multiple entities to collaboratively train a shared model, while ensuring that data remain decentralized—thus circumventing the concentration or dissemination of sensitive information. FedAvg is a widely utilized algorithm in federated learning, known for aggregating model parameters via a process of weighted averaging [
7]. Fundamentally, FedAvg involves uploading the parameters from local models to a central server. The server then computes the weighted average of all these model parameters and subsequently distributes this computed average back to each participating local device. This iterative process is repeated multiple times, aiming for the convergence of the model parameters. Despite FL’s inherent privacy safeguards, it remains susceptible to potential threats, notably inference attacks and membership leakage, prompting the imperative development of robust privacy-preserving mechanisms.
Differential privacy (DP), a widely endorsed privacy preservation technique, mitigates the risk of individual data inference by integrating noise into the data or model parameters. Agarwal et al. [
8,
9,
10] advanced methodologies such as cpSGD, the binomial mechanism with random k-level quantization, and the multi-dimensional Skellam mechanism. These approaches aim to enhance the communication efficacy, particularly under scenarios of client–server distrust. Wei et al. [
11] introduced NbAFL, a novel FL methodology infusing noise into client parameters pre-aggregation, aligning with central differential privacy standards. Concurrently, Li et al. [
12] introduced a personalized FL approach, amalgamating differential privacy and convergence assurances, thus bolstering both model personalization and privacy protection. Additionally, Triastcyn et al. [
13] and Zhang et al. [
14] elevated the privacy precision and efficiency via Bayesian differential privacy and the clipping-enabled federated learning method, respectively. Progress in local differential privacy (LDP) research is ongoing. Ponomareva et al. [
15] and Rathee et al. [
16] have, respectively, introduced FL methods based on LDP and the Randomized Aggregatable Privacy-Preserving Ordinal Response mechanism. Truex et al. [
17,
18] have proposed a hybrid privacy-protected FL framework and LDP-Fed, integrating differential privacy and homomorphic encryption.
Secret sharing technology also plays a significant role in fortifying FL privacy measures. Dong et al. [
19] devised an efficacious FL strategy, amalgamating secret sharing with Top-K gradient selection, thereby striking a balance between privacy, communication overhead, and model efficacy. Further, He et al. [
20] present an FL model in IoT settings, enhancing the privacy through adaptive local differential privacy and clustering methodologies. Moreover, Zhang et al. [
21] underscore the enhancement in privacy protection and learning efficiency in intricate scenarios through sophisticated algorithms and frameworks.
Secure aggregation protocols, too, are instrumental. Bonawitz et al. [
22] introduced SecAgg, a protocol for the aggregation of multiple updates, primarily utilizing one-time passwords for input obfuscation. Cheng et al. [
23] developed a secure federated enhanced tree algorithm with homomorphic encryption, yielding accuracy on par with that of centralized learning models. Wang et al. [
24] proposed a novel privacy preservation technique by integrating diverse technologies, offering a fresh perspective in the FL domain. Further, Phong et al. [
25], Hao et al. [
26], and Chai et al. [
27] have proposed encryption and decryption methodologies using public and private key pairs, ensuring secure update uploads and model aggregation.
Recent investigations have concentrated on augmenting FL’s privacy and efficiency. Jahani-Nezhad et al. [
28] proposed Swiftagg, an efficient, packet-loss-resistant secure aggregation method with comprehensive security assurances. Tian et al. [
29] developed Sphinx, facilitating privacy-protected online learning in cloud environments. Lu et al. [
30] introduced practical, lightweight secure aggregation methods for sparsified secure aggregation and federated submodel learning, aimed at privacy preservation.
The inherent architecture of blockchain technology plays a pivotal role in distributing trust among a network of nodes, thereby significantly mitigating the risk associated with single-point failures. This decentralization is particularly beneficial in the realm of federated learning (FL), where it not only fosters resilience but also ensures the auditability of operations and data processed on the blockchain. Blockchain technology’s incorporation offers an alternative avenue for privacy and data security within FL. Wu et al. [
31] explored Fed-SMP, a scheme ensuring differential privacy at the data owner level. Boenisch et al. [
32] highlighted FL’s privacy loopholes, particularly data reconstruction attack risks, underscoring the necessity for robust protection in FL systems. Fang C. et al. [
33] introduced a pivotal advancement in blockchain-based federated learning, articulating a methodology that preserves privacy while ensuring verifiability. Central to their approach is a secure aggregation protocol that maintains the confidentiality of gradients, coupled with an innovative blockchain architecture designed for the verification of global gradients, thereby safeguarding against potential tampering threats. Furthermore, the selection of encryption algorithms not only ensures varying levels of security protection but also significantly influences the performance of federated learning systems. Fang et al. [
33] employed an ElGamal-based encryption method to enhance the security of parameter transmission in federated learning. In a similar vein, Yang et al. [
34] and Xu et al. [
35] implemented comparable blockchain frameworks. However, they differed in their encryption choices, utilizing RSA-based and BGN-based algorithms, respectively. These choices were specifically aimed at ensuring the privacy of parameter updates within federated learning environments.
In summary, the realm of federated learning is witnessing swift advancements in privacy protection technologies, a response to the escalating privacy and security challenges. This evolution spans differential privacy and homomorphic encryption to blockchain technology, each striving to optimize the learning efficiency and accuracy within the confines of data privacy. These methods confront a triad of challenges, including the trade-off between computational efficiency, communication overhead, and the extent of privacy safeguarding. Future research requires the further exploration of more sophisticated and dependable privacy protection mechanisms, thereby broadening the scope and applicability of federated learning across diverse domains.
4. Architecture
In this section, we provide a comprehensive overview of the threat models inherent in the current federated learning, with a specific focus on two entities: clients and servers. Each entity is vulnerable to two distinct threat types: semi-honest and malicious. Subsequently, we introduce a decentralized federated learning architecture that effectively harnesses the intrinsic structure of blockchain. Publicly transparent smart contracts serve as the primary operational nodes, displacing the server in occupying the central position in traditional federated learning to mitigate the undue reliance on the server during the model training process.
Following this, we propose a streamlined model sharing scheme capable of establishing trust groups through identity authentication, fostering intra-group information transparency and reducing the communication overhead. Additionally, we design a model weight allocation method based on the model performance. This method not only optimizes the local models but also safeguards against malicious clients and servers attempting to upload low-quality models, thereby contaminating the user-customized models. In the model aggregation phase, the employed model obfuscation algorithm robustly guards against threats posed by semi-honest servers and malicious servers. Finally, a thorough security analysis is conducted on aspects related to the disconnection tolerance and confidentiality in the aforementioned scenarios.
4.1. Threat Model
Before designing efficient architectures and solutions based on the threat model, it is crucial to identify the types of adversaries initiating privacy and safety attacks. We assume that both the servers and clients have undergone qualification audits before registering on the blockchain. The server has powerful computational abilities that can assist in global model training, while the client resources are limited, and some clients may include semi-honest or malicious adversaries.
- *
Semi-honest adversaries faithfully comply with and execute the communication protocol’s procedures during participating rounds, exhibiting no malicious behavior when interacting with other nodes. However, they attempt to infer more content based on the received information. They do not interfere with the training process or compromise the integrity and availability of the model.
- *
Malicious adversaries operate without constraints, potentially violating the communication or model exchange protocols established by the system. For instance, they may maliciously tamper with messages sent by other nodes, inducing them to disclose more information. Alternatively, they might intentionally upload low-quality models, thereby disrupting or even sabotaging the model training process.
In a federated learning setting, clients and servers can be either semi-honest or malicious.
Semi-honest clients can view all the messages exchanged during the training process, including the global model and the local models of other clients. However, they do not interfere with the training process.
Malicious clients can disrupt the training process by poisoning the data or models.
Semi-honest servers can inspect the models uploaded by the clients. They may engage in reconstruction attacks or model reverse engineering. However, they do not disrupt the training process.
Malicious servers can interfere with the training process by updating clients with incorrect models.
Existing research predominantly relies on the assumption of semi-honest adversaries to design privacy protection solutions. In cryptographic protocols like secure multiparty computation, resisting both semi-honest and malicious adversaries often requires substantial additional computational and communication overheads, making it challenging to ensure the efficiency and practicality of the solution. Balancing the security, efficiency, and usability of federated learning is the central focus of this section.
4.2. EPFed Architecture
In the realm of federated learning, traditional training architectures often center around a central server handling communication and computation. However, this centralization poses significant privacy risks, especially if the server is compromised or inherently untrustworthy. The EPFed architecture marks a paradigm shift from this traditional model, emphasizing decentralization to effectively counter these privacy concerns.
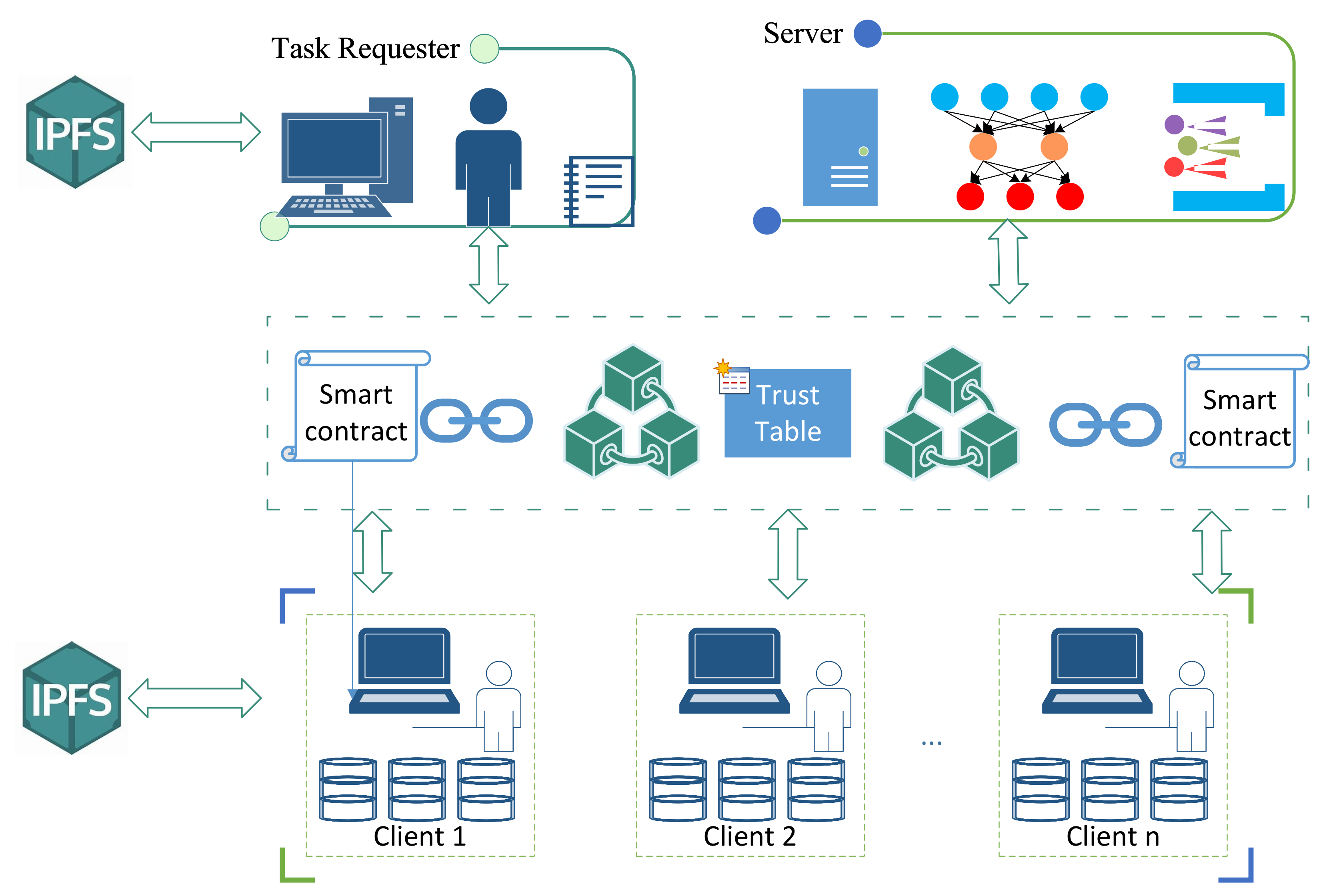
At the heart of EPFed’s innovation is the integration of blockchain technology, which is pivotal in ensuring secure information exchange, storage, and overall system transparency, as illustrated in
Figure 2. This decentralized approach comprises three main components: client devices, a blockchain network, and a large-scale computation server. Client devices focus on training local models and interfacing with the blockchain for information exchange. The blockchain network, serving as the backbone of EPFed, securely stores model data from both the clients and the server. The computation server, on the other hand, retrieves client models from the blockchain and contributes by uploading aggregated global model parameters back to the network. A unique aspect of this architecture is that the nodes within the blockchain are designed to prevent direct communication channels amongst each other, thereby enhancing the security and mitigating the potential risks associated with centralized models.
4.2.1. Initialization
The clients () and server (S) nodes are both registered on the blockchain network. The blockchain issues node identification , threshold value t, and secret update time , and n numbers that are mutually prime .
The verified generates Paillier public key and private key . S generates Paillier public key and private key .
The EPFed system publishes transaction (, ) to the blockchain, and S publishes (, ) for public key exchange.
Initialize the local model and local model parameters .
4.2.2. User Secret Sharing and Trust Group Establishment
When , randomly generates a local secret and secret shares , where . Simultaneously, it generates a digital signature . Here, ’Enc’ denotes Paillier encryption.
encrypts the secret shares to get , representing the secret share that client needs to transmit to .
publishes the transaction to the blockchain. In this transaction, the first parameter specifies that is intended to decrypt this message, while the second parameter indicates that the information originates from . signifies ‘secret’. Other clients can use the public key of to encrypt the signature. This process allows them to verify the authenticity of the message source and authenticate the identity of .
retrieves the latest encryption and the public key of from the blockchain. Using its private key, decrypts the information to obtain the secret share and signature . Subsequently, it employs the public key to verify the signature. Upon successful verification, publishes a transaction to share its secret share with .
publishes and downloads a transaction for mutual verification with , where the first parameter is . uses its private key to decrypt the corresponding encryption . It then compares the values of and to perform a secondary identity confirmation and confirm the value of the secret share. If they are the same, is added to the trust table of . signifies ‘verification’.
publishes transaction , where is the user group trusted by , called the trust table.
The smart contract in the blockchain checks each trust table to determine which users exceed the threshold t and then adds these users to the trust group. The smart contract publishes the trust group .
publishes decryptable message to the blockchain, where . signifies recovery.
recovers the secrets of other clients.
4.2.3. Training
trains the local model to obtain the optimal model parameters .
confuses the initial model with secret to acquire , and publishes to the blockchain.
downloads models from other trusted nodes, validates the performance of these models using a locally verified dataset, and then calculates the proportion list for each model during aggregation. Additionally, it obtains the corresponding model parameter lists .
During the training process, the metrics of accuracy, recall, and mean average precision (MAP), collectively forming the judging metric () for each model, serve as the basis for the calculation of the aggregation weights. Subsequently, the calculation of is performed, allowing the derivation of a comprehensive score for each model.
Following this, is computed, representing the weight of each model during the model aggregation process, ensuring that the sum of all weights is equal to 1. Here, ‘n’ represents the total number of models to be aggregated.
re-generates a random noise model , confuses all the models in the list to be aggregated, obtaining , and publishes .
4.2.4. Server Aggregation
Server S downloads the parameter list and corresponding proportions that wishes to aggregate, calculates the corresponding aggregation result , and publishes it to the blockchain.
4.2.5. Client Update
downloads the corresponding aggregation parameters, validates the new model, and calculates the comprehensive scores v1 and v2 for the aggregated model and the local model , respectively. Then, it computes the corresponding aggregation weights, and . Finally, the models are fused according to the specified proportions .
The communication complexity is very high when the secret sharing algorithm is employed in every federated learning training process. Therefore, we introduce the concept of a trust group. The communication and encryption/decryption procedure can be simplified by performing periodic mutual authentication and secret sharing processes between nodes. During each secret sharing process, client generates n shares of its secret , which are used to confuse the model parameters. The remaining shares are transmitted to the blockchain after being encrypted with corresponding clients’ Paillier public keys. Finally, each client independently downloads and decrypts their respective shares from the blockchain.
During the mutual authentication process, transmits the encrypted to and transmits the encrypted to . If either client is able to decrypt the value received from the other party without revealing their private keys, their identity is proven authentic. Therefore, can confirm identity by decrypting , and subsequently all clients can verify each other and add the validated clients to their respective trust tables.
Once all clients have published their trust tables, the smart contract written in the blockchain aggregates the tables and initiates the establishment process of the trust group T. appearance above a certain threshold value (t) indicates that is trusted by t or more clients. Afterward, the secret shares are shared among the members of T. encrypts and disseminates it to all trusted clients; as a result, each client can aggregate the secret shares linked with other clients within T and calculate their secrets.
During the iterative process of federated learning, every client employs secret obfuscation mechanisms to guard their model parameters. Access to fellow clients’ models and secrets is exclusive to the trusted group. Once the models of other clients have been verified, high-quality models will be obfuscated and published on the blockchain. With the help of computing servers, these models are fused with the client’s model, resulting in a significant boost to the quality of the local model without impairing its integrity.
4.3. Security Analysis
This section presents an in-depth security analysis of the EPFed architecture, with a specific emphasis on its capabilities in handling drop tolerance and ensuring confidentiality. These elements are fundamental to the integrity and effectiveness of decentralized federated learning systems, where the security challenges are inherently more intricate due to the dispersed nature of operations.
Firstly, we explore the aspect of drop tolerance in
Section 4.3.1. Drop tolerance is crucial in maintaining the continuity and reliability of the learning process, especially in scenarios where participant nodes may unpredictably leave or join the network. We assess how EPFed mitigates the impacts of such disruptions, ensuring consistent performance and data integrity. Subsequently, in
Section 4.3.2, the focus shifts to confidentiality, a paramount concern in federated learning environments. We examine the mechanisms employed by EPFed to safeguard data against unauthorized access and leaks, particularly in the context of collaborative learning among multiple participants. This analysis highlights the encryption techniques and protocols integral to EPFed, demonstrating its commitment to maintaining stringent data privacy and security standards.
4.3.1. Tolerance for Disconnection
All types of information, including the initialization information, information required for authentication, and information about the training process, are uploaded to the blockchain. Due to the tamper-proof nature of blockchain security, the uploaded information remains unmodifiable while being available for access and viewing.
During the secret sharing process, client can access shares sent by other clients from the blockchain and upload its shares within the secret update period , in case of a temporary disconnection. can join the trust group if it reconnects and completes prior authentication before other clients publish their trust tables. If this window is missed, other clients can resubmit their trust tables to include in the trust group. Once the trust group has been established, other clients transmit the secret shares to . obtains secrets from other clients to participate in the subsequent model sharing process.
If briefly drops during the secret recovery process, it may not affect the recovery of secrets if the number of online clients exceeds the threshold t. In cases where the number of online clients is below t, they can wait for other clients to reconnect before proceeding with the secret recovery process. Once is online, it can directly retrieve the necessary information from the blockchain to restore the secrets. It is worth noting that the aforementioned operations are only valid within the secret update time period .
4.3.2. Confidentiality Analysis
Due to the public and transparent nature of the blockchain, all necessary information must be encrypted before being uploaded, whether this is secret share or model parameter information. For instance, information shared between clients is encrypted using the recipient’s public key, and no entity can access the relevant content unless they obtain the corresponding private key. Additionally, the model parameters sent from clients to the server are obfuscated by a random noise model and encrypted using the server’s public key. After decryption, the server can only obtain the confused model list and not extract any privacy information. Moreover, due to the tamper-resistant nature of the blockchain, the information stored on the chain is traceable. If a server or client uploads a low-quality model to the blockchain, it will receive a significantly lower weight before aggregation. Therefore, the impact on user-customized models is minimal, and such behavior is traceable. In summary, this solution can resist semi-honest and malicious servers, as well as malicious clients, in the absence of collusion.
5. Evulation
5.1. Experimental Setup
The experiments were conducted on an Intel(R) Core(TM) i7-8700 CPU @ 3.20 GHz 3.19 GHz, utilizing the python3.7 programming language alongside the PyTorch framework and fabric-python-sdk. To assess the efficacy of the proposed model, we employed it in a network traffic anomaly detection scenario and conducted tests on the identification performance using the NSL-KDD dataset [
38]. The NSL-KDD dataset, a collection of TCP/IP traffic data amassed from authentic internet environments, encompasses not only normal traffic but also 22 distinct classes of cyber-attacks. This dataset is characterized by data samples each comprising 41 attributes and a single label. These attributes are categorized into three categorical features and 38 numerical features. This dataset is widely used in the performance testing of federated learning methods.
5.2. Performance Analysis
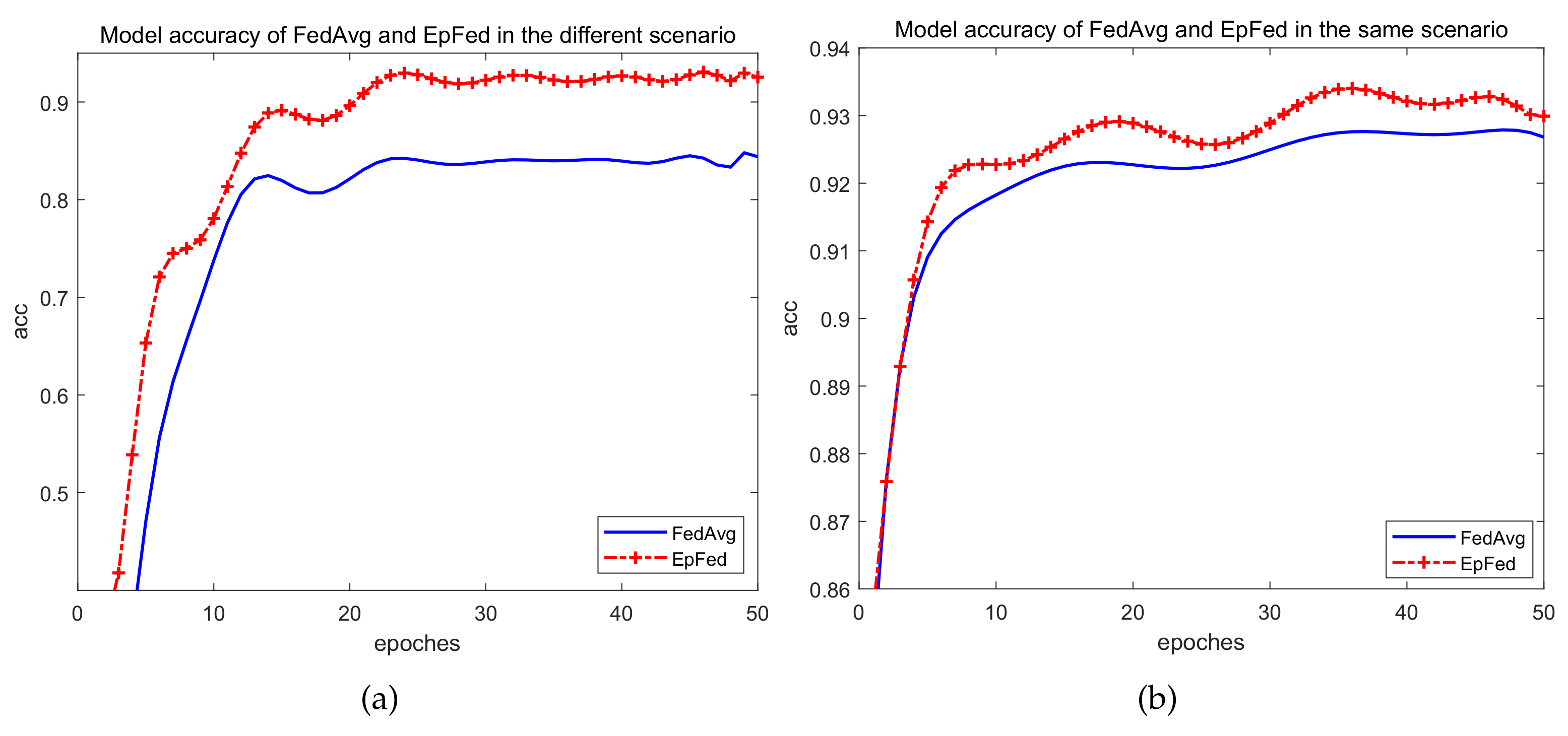
We evaluated the model’s performance using various training cycles and recorded the results, as shown in
Figure 3. Based on our observations, we can draw the following conclusions: (1) for smaller epoch values, the recognition accuracy of each model progressively improves as the number of training rounds increases; (2) the convergence times vary depending on the number of participants. The loss function graph shows that when only one participant is involved, the function converges more slowly than in other scenarios, requiring the largest number of training rounds to achieve convergence.
This outcome could be attributed to the characteristics of federated learning. When the number of participants is limited, the model lacks adequate data resources to learn diversified features, leading to relatively poor overall training outcomes. Nevertheless, as the number of participants increases, the number of training sets consequently enlarges, which eventually translates to better overall training outcomes. However, when the participant count reaches a critical threshold, the data aggregation algorithm in federated learning cannot extract any fresh data features, rendering it increasingly difficult to enhance the overall model performance.
To assess the effectiveness of our EPFed based on the model accuracy, we conducted several tests across diverse scenarios. The training dataset was segmented into five distinct parts, each representing different application scenarios with unique data type distributions. Similarly, the test dataset was sampled following the same distribution pattern as the training data. Under these conditions, we compared EPFed’s performance against the traditional federated learning aggregation algorithm, FedAvg [
7]. FedAvg is currently the most popular federated learning framework. It is frequently utilized as a standard benchmark for the assessment of performance in academic studies. In our decentralized accuracy-based approach, each participant’s model is uniquely trained, leading to varied accuracy. The reported experimental results reflect the average accuracy across all participant models.
As shown in
Figure 4, when the distribution of the training datasets is identical for each participant, both the accuracy-based EPFed and FedAvg algorithms maintain the accuracy of network traffic anomalies between 0.92 and 0.93. Nevertheless, the accuracy of EPFed is higher than that of FedAvg. However, in scenarios wherein the network traffic anomalies are identified in multiple distributions of the training datasets for different participants, the recognition accuracy of EPFed remains approximately 0.9, whereas the performance of FedAvg drops to around 0.8.
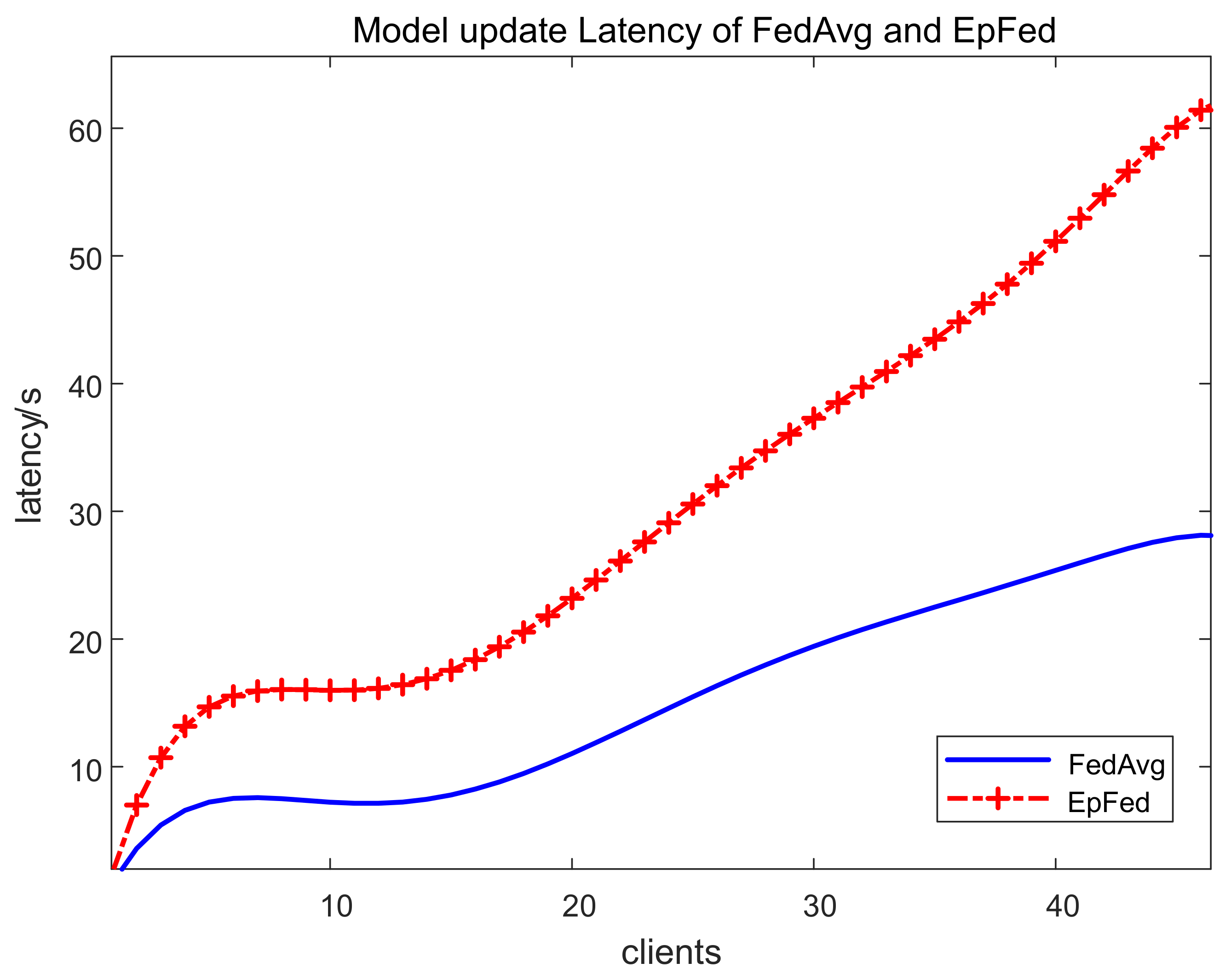
The local model update latency is impacted by several factors, namely communication, model obfuscation, model validation, and transaction updates to the blockchain. In
Figure 5, it is evident that the average client local model latency increases linearly as the number of clients increases. When comparing EPFed with FedAvg, it is clear that the additional functionalities that EPFed introduces, including secret sharing and recovery, the trust group establishment process, and model validation, significantly enhance the latency.
The results demonstrate that the EPFed mechanism effectively facilitates the personalization of participant client models, reducing the necessity of sharing the same global model among various participants, which enhances the model’s performance in diverse scenarios. Nevertheless, the adoption of certain functionalities, such as secret sharing and model confusion, leads to a noticeable increase in the model update latency. Despite this, such latency is acceptable within the distributed architecture model training process when compared to transmitting an extensive quantity of data.
Moreover, we present a comparative analysis between the EPFed scheme introduced in this paper and the federated learning schemes proposed by Fang [
33], Yang [
34], and Xu [
35], as shown in
Table 1. All these schemes incorporate blockchain technology to supplant the central server in federated learning, thereby offering federated learning with enhanced privacy protection. The primary distinction among these schemes is their use of various encryption algorithms to safeguard the privacy of models. This is primarily achieved by applying protective measures to the data gradient parameters, pivotal in the model training process. Specifically, Fang’s scheme utilizes an ElGamal-based algorithm, Yang’s scheme employs an RSA-based algorithm, and Xu’s scheme is grounded in a BGN-based algorithm. In contrast, the EPFed scheme introduced in this paper also leverages a form of homomorphic encryption but diverges in its privacy protection approach. Predominantly, it implements a secret sharing scheme—a technique for the distributed storage of critical information—emphasizing the safeguarding of clients’ confidential data. This strategy not only indirectly bolsters the overall model security but also contributes to a reduction in computational resource demands. The comparative analysis of these four schemes, focusing on the user overhead, server overhead, and total expenditure, distinctly underscores the performance benefits derived from EPFed’s implementation of the secret sharing scheme.
The comparison in
Table 1, centered around the user overhead, server overhead, and total expenditure, is crucial in understanding the relative efficiencies and computational demands of these schemes, particularly in the context of varying gradient quantities.
EPFed, the mechanism introduced in our research, demonstrates a nuanced balance between the computational overhead and privacy protection. Despite exhibiting a marginally higher user overhead compared to Fang’s and Yang’s schemes, it maintains a comparable level to Xu’s. This slight increase in user overhead is a direct consequence of the enhanced privacy measures intrinsic to EPFed’s design, specifically its implementation of a secret sharing scheme. While this approach slightly intensifies the computational load on the client side, it plays a pivotal role in fortifying the confidentiality of client data, a critical aspect in the landscape of federated learning.
A significant distinction of EPFed lies in its server-side efficiency. The data clearly indicate a substantial reduction in server overhead for EPFed, in comparison to the other schemes. This efficiency is attributed to the scheme’s streamlined design, which notably omits the signature aggregation step. Such a reduction in server-side computational demands not only highlights the innovative nature of EPFed but also underscores its potential in optimizing server resource utilization.
The total computational expenditure, encompassing both the user and server overheads, is a key metric in evaluating the overall efficiency of federated learning mechanisms. Here, EPFed excels, consistently showcasing lower total expenditure across all gradient scenarios. This efficiency reflects EPFed’s strategic design, which, while placing a slightly higher computational demand on clients, substantially alleviates the burden on servers, resulting in a net reduction in the overall computational overhead.
In conclusion, the analysis presented in
Table 1, following the detailed discussions, firmly positions EPFed as a promising and balanced approach in the domain of federated learning. Its innovative integration of a secret sharing scheme for heightened privacy, combined with its marked reduction in server-side computational demands, not only enhances the scheme’s efficiency but also strengthens its applicability in diverse federated learning environments.
6. Conclusions
In conclusion, our research introduces EPFed, a novel decentralized federated learning architecture that redefines the approach to secure and efficient machine learning. By integrating blockchain technology, advanced encryption methods, and an accuracy-centric aggregation strategy, we have crafted a system that ensures the secure and verifiable exchange of encrypted data between participants and a central server. The use of homomorphic encryption and secret sharing schemes not only authenticates participant nodes but also creates trust groups, enhancing the security in multi-party computations and optimizing the communication overhead.
Our architecture adapts to multiple training scenarios through a client-customized model aggregation mechanism. This approach allows clients to improve their local models’ generalization abilities without sacrificing performance. To combat the risk of low-quality model contributions, we have implemented a model aggregation proportion allocation mechanism based on model scores, ensuring that higher-quality models have a greater influence in the aggregation process.
The effectiveness of EPFed is demonstrated through its application in network traffic anomaly detection using the NSL-KDD dataset, where it achieved an impressive 92.5% accuracy in five-category recognition. This performance highlights the robustness and practicality of EPFed in addressing the critical challenges of security and privacy in federated learning, making it a promising solution for real-world federated learning applications.


 and
and 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}