
Reinforcement Learning-Based Event-Triggered Active-Battery-Cell-Balancing Control for Electric Vehicle Range Extension




Abstract
1. Introduction
2. Preliminaries on RL and MPC
2.1. Reinforcement Learning
2.2. Deep Neural Network-Based RL
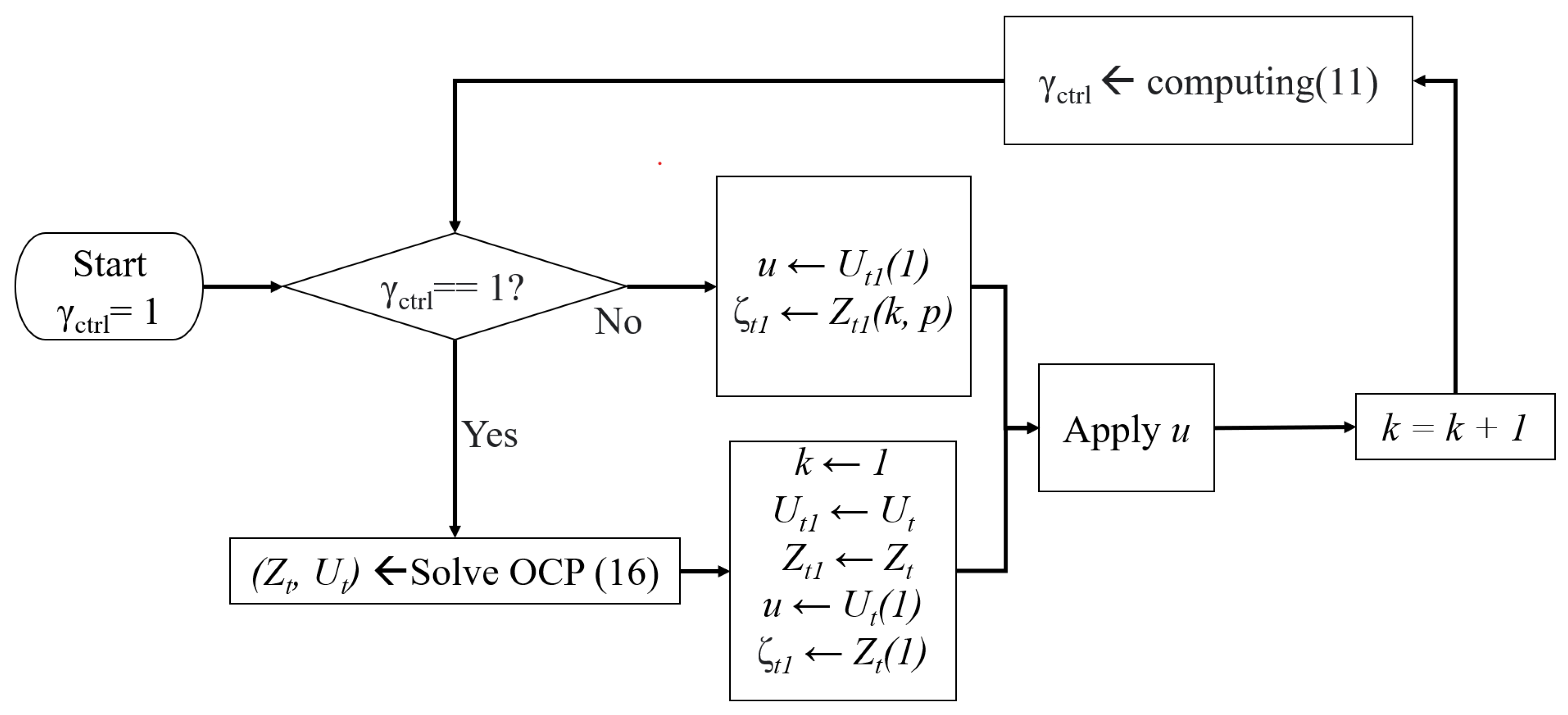
2.3. Event-Triggered MPC
| Algorithm 1 Event-triggered MPC [46] |
|
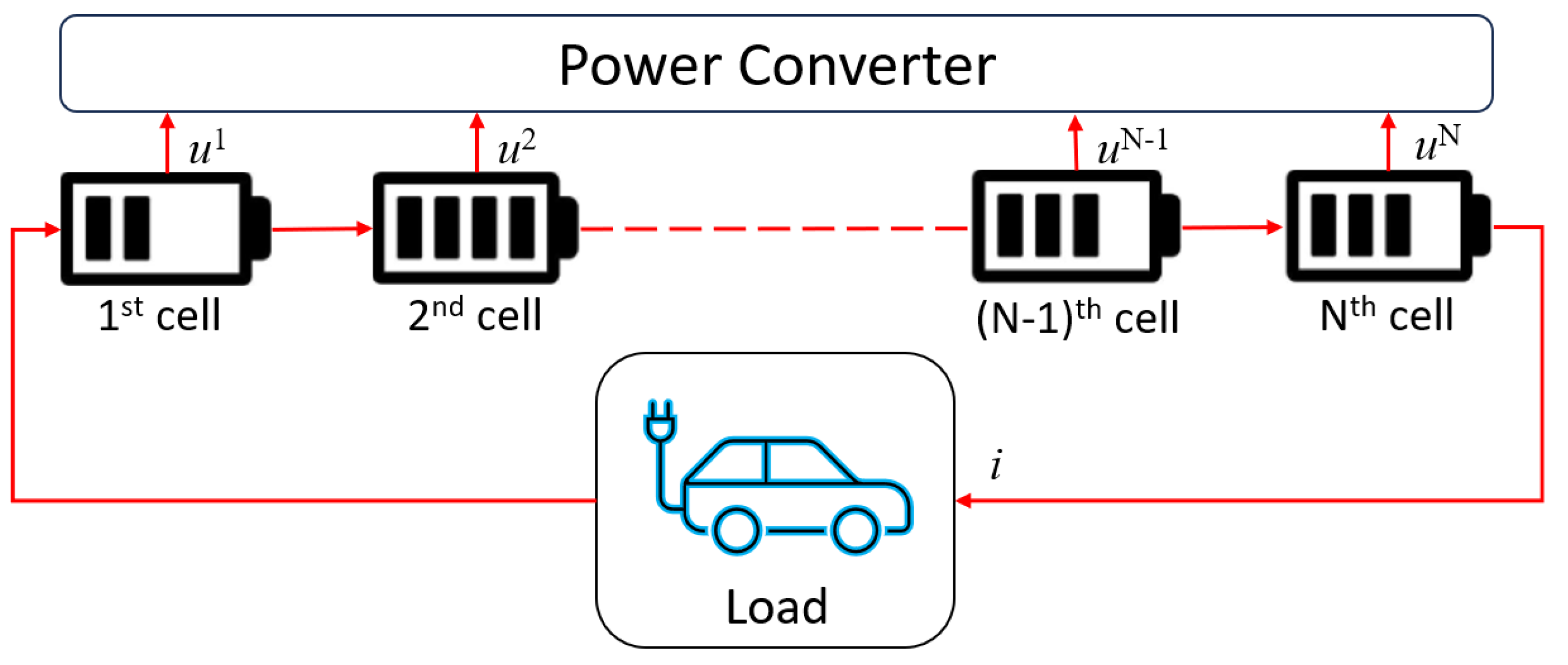
3. Problem Formulation
3.1. Active-Battery-Cell-Balancing Control
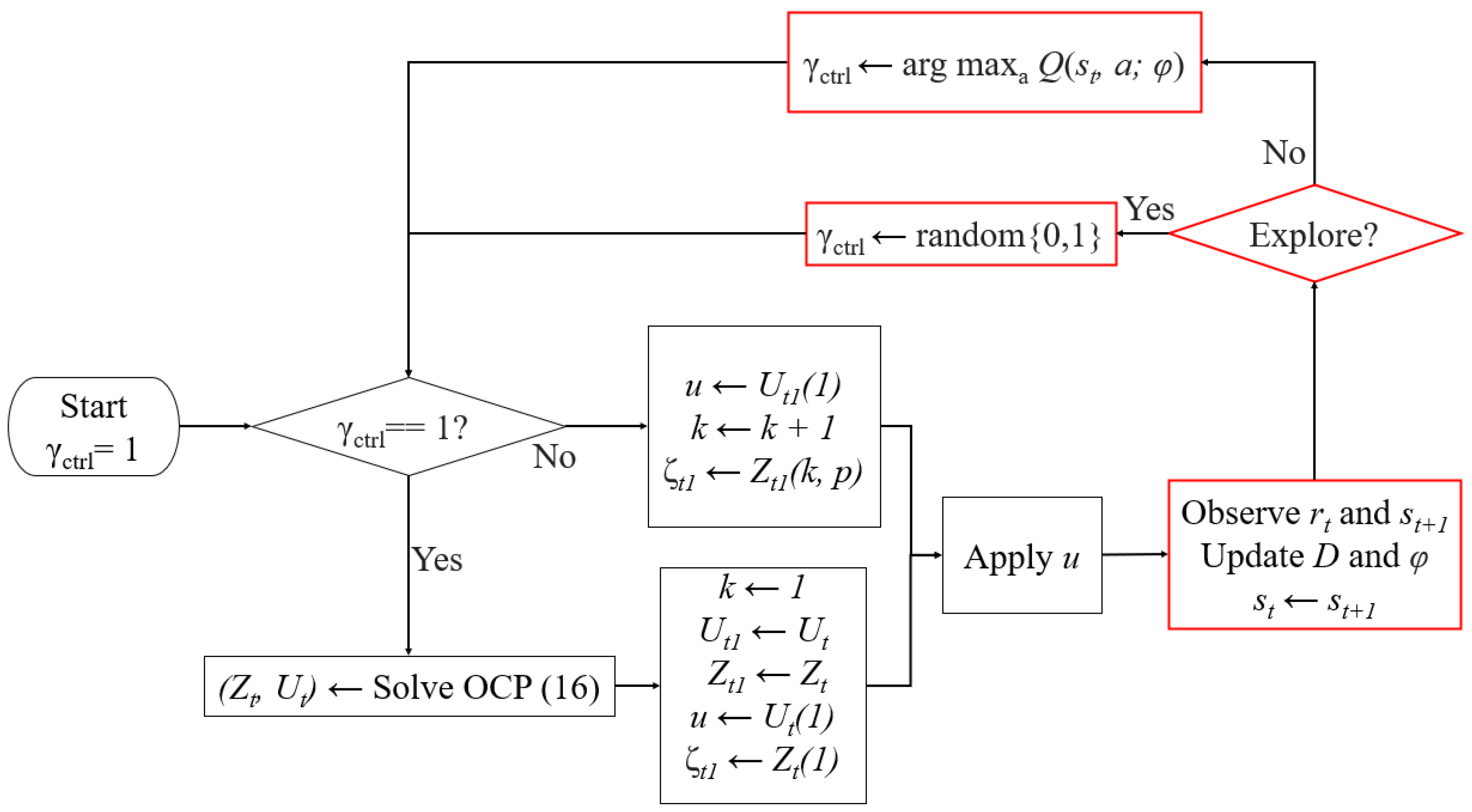
3.2. RLeMPC for Active Cell Balancing
| Algorithm 2 RL-based event-triggered MPC |
|
4. Simulation Results and Discussion
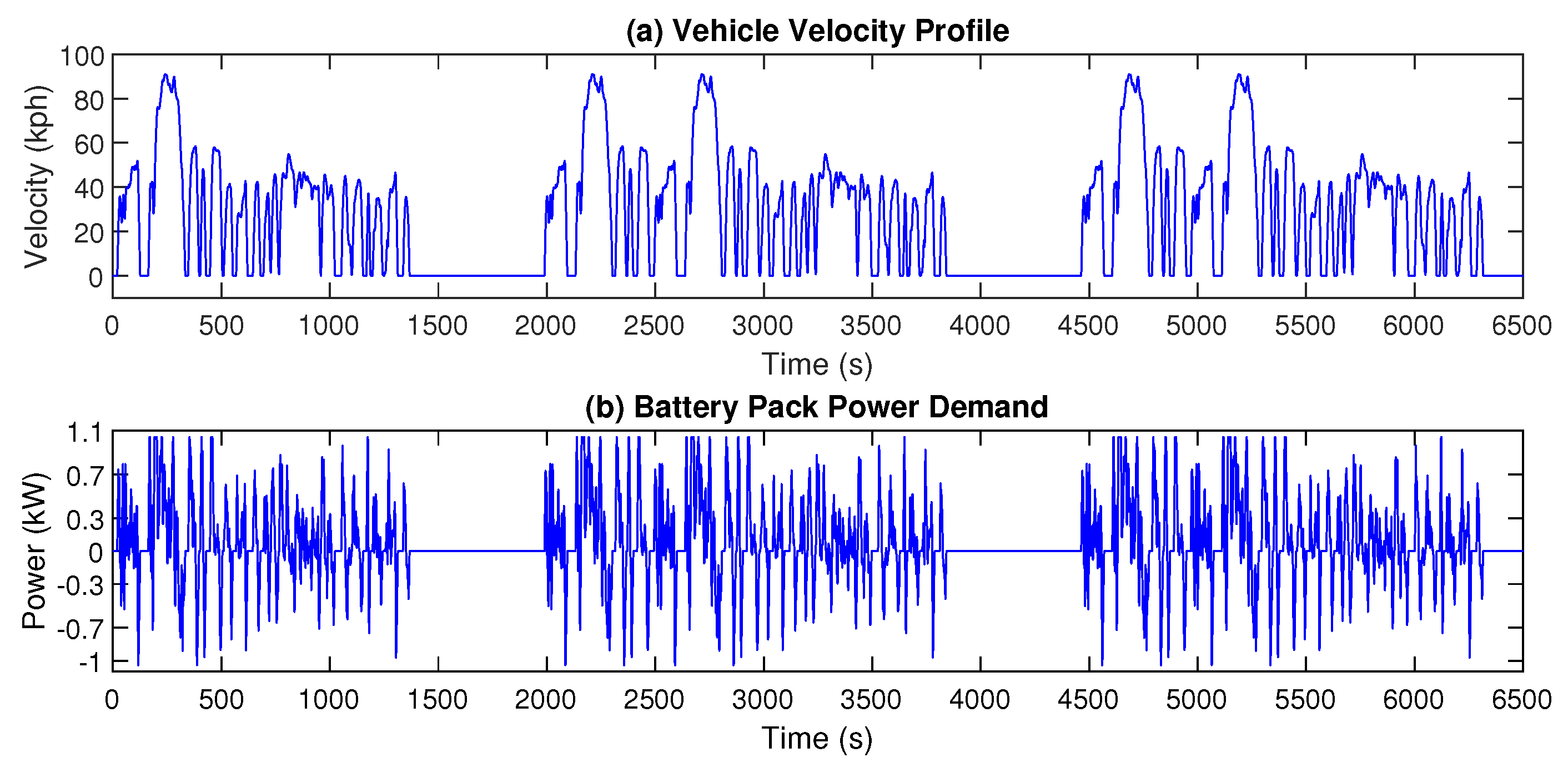
4.1. Simulation Environment
4.2. Evaluation Criteria
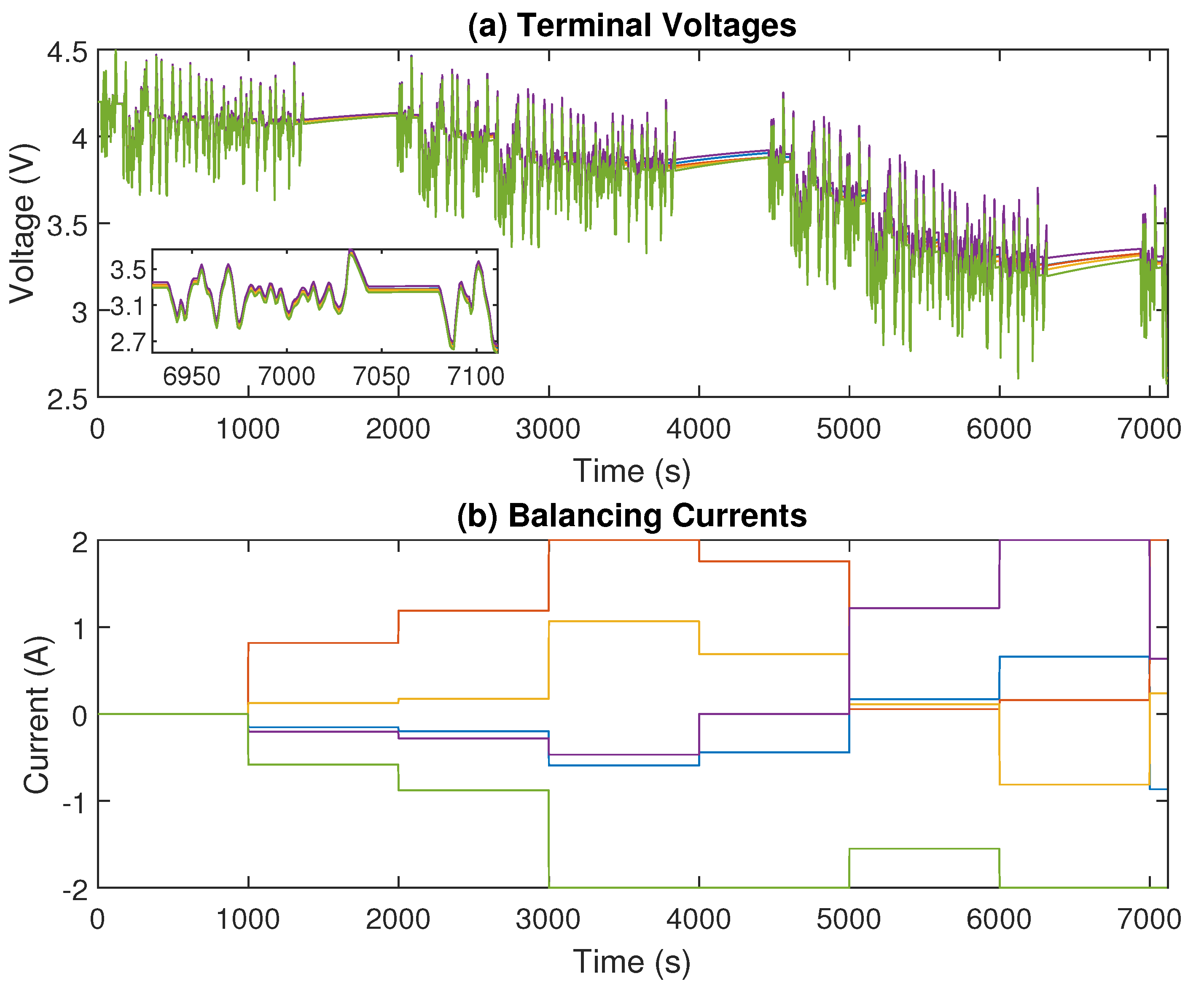
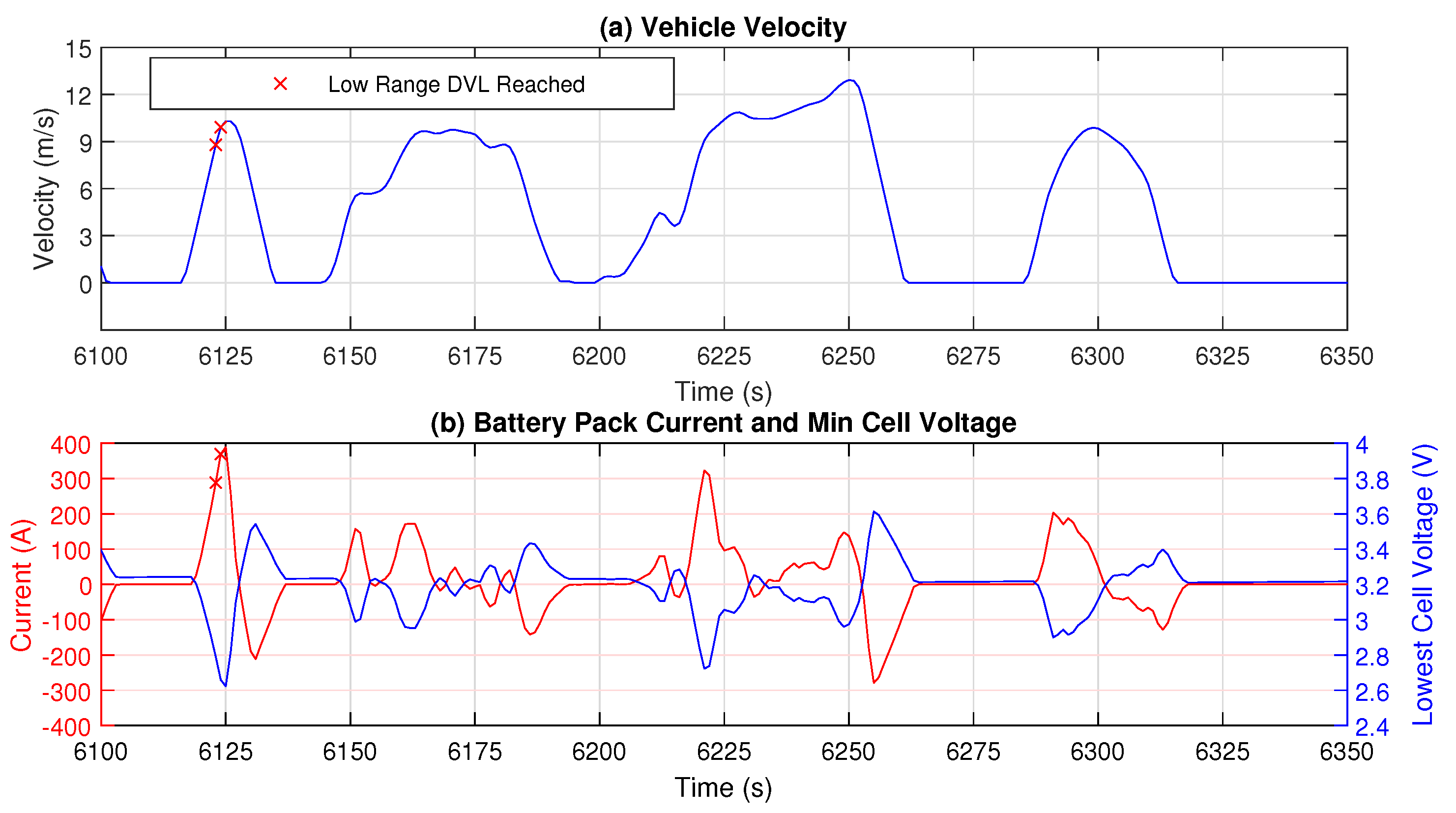
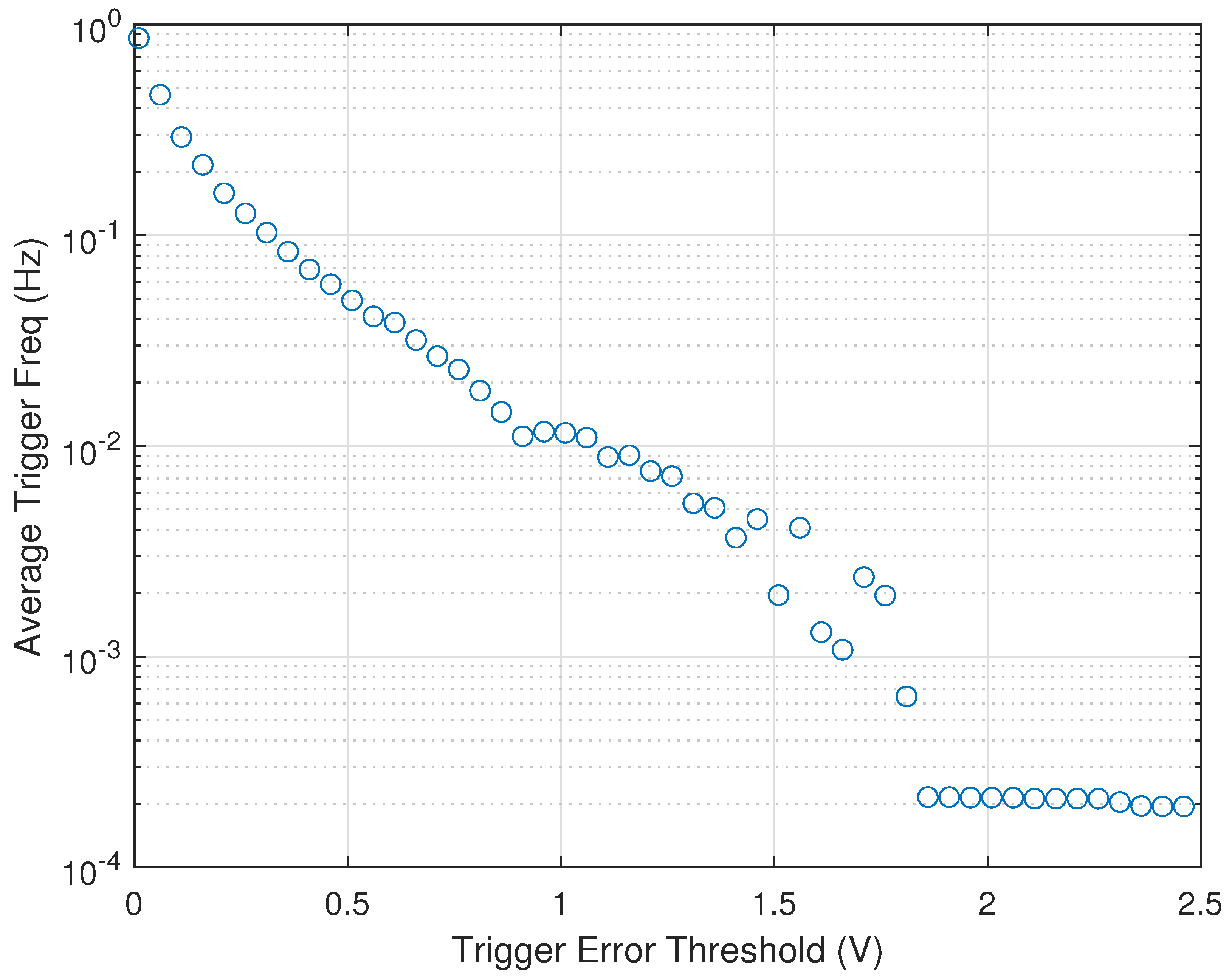
4.3. Results with Constant Trigger Period
4.4. Results with Threshold-Based eMPC
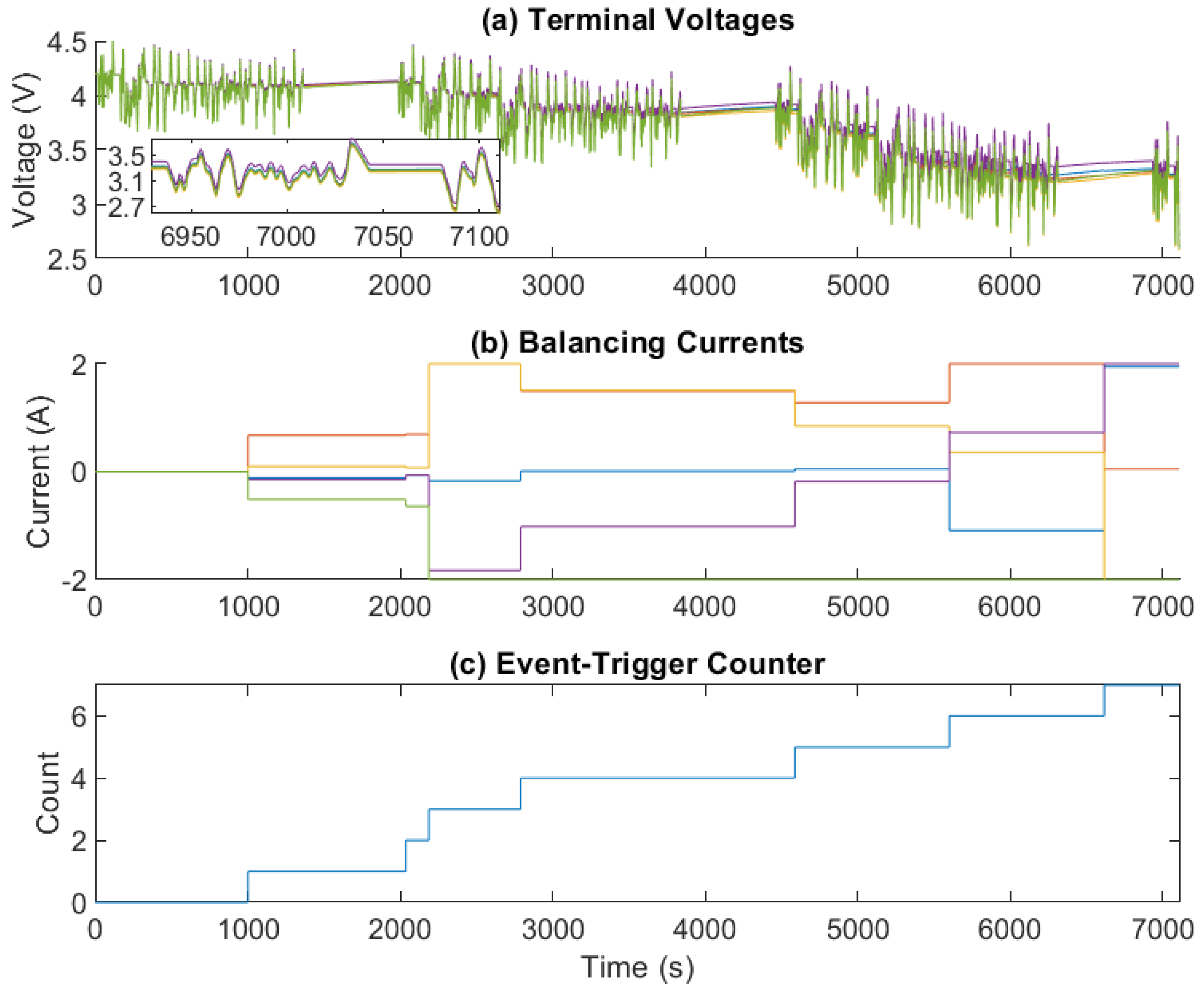
4.5. Results with RLeMPC
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, J.; Behal, A.; Li, C. Active battery cell balancing by real time model predictive control for extending electric vehicle driving range. IEEE Trans. Autom. Sci. Eng. 2023; accepted. [Google Scholar] [CrossRef]
- Preindl, M. A battery balancing auxiliary power module with predictive control for electrified transportation. IEEE Trans. Ind. Electron. 2017, 65, 6552–6559. [Google Scholar] [CrossRef]
- Liu, J.; Chen, Y.; Fathy, H.K. Nonlinear model-predictive optimal control of an active cell-to-cell lithiumion battery pack balancing circuit. IFAC PapersOnLine 2017, 50, 14483–14488. [Google Scholar] [CrossRef]
- Razmjooei, H.; Palli, G.; Abdi, E.; Terzo, M.; Strano, S. Design and experimental validation of an adaptive fast-finite-time observer on uncertain electro-hydraulic systems. Control. Eng. Pract. 2023, 131, 105391. [Google Scholar] [CrossRef]
- Shibata, K.; Jimbo, T.; Matsubara, T. Deep reinforcement learning of event-triggered communication and consensus-based control for distributed cooperative transport. Robot. Auton. Syst. 2023, 159, 104307. [Google Scholar] [CrossRef]
- Abbasimoshaei, A.; Chinnakkonda Ravi, A.; Kern, T. Development of a new control system for a rehabilitation robot using electrical impedance tomography and artificial intelligence. Biomimetics 2023, 8, 420. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, Y.; Chen, Z.; Li, G.; Liu, Y. A novel learning-based model predictive control strategy for plug-in hybrid electric vehicle. IEEE Trans. Transp. Electrif. 2021, 8, 23–35. [Google Scholar] [CrossRef]
- Rostam, M.; Abbasi, A. A framework for identifying the appropriate quantitative indicators to objectively optimize the building energy consumption considering sustainability and resilience aspects. J. Build. Eng. 2021, 44, 102974. [Google Scholar] [CrossRef]
- Tøndel, P.; Johansen, T.A.; Bemporad, A. An algorithm for multi-parametric quadratic programming and explicit mpc solutions. Automatica 2003, 39, 489–497. [Google Scholar] [CrossRef]
- Wang, Y.; Boyd, S. Fast model predictive control using online optimization. IEEE Trans. Control Syst. Technol. 2010, 18, 267–278. [Google Scholar] [CrossRef]
- Badawi, R.; Chen, J. Performance evaluation of event-triggered model predictive control for boost converter. In Proceedings of the 2022 IEEE Vehicle Power and Propulsion Conference, Merced, CA, USA, 1–4 November 2022. [Google Scholar]
- Li, H.; Shi, Y. Event-triggered robust model predictive control of continuous-time nonlinear systems. Automatica 2014, 50, 1507–1513. [Google Scholar] [CrossRef]
- Brunner, F.D.; Heemels, W.; Allgöwer, F. Robust event-triggered MPC with guaranteed asymptotic bound and average sampling rate. IEEE Trans. Autom. Control 2017, 62, 5694–5709. [Google Scholar] [CrossRef]
- Zhou, Z.; Rother, C.; Chen, J. Event-triggered model predictive control for autonomous vehicle path tracking: Validation using CARLA simulator. IEEE Trans. Intell. Veh. 2023, 8, 3547–3555. [Google Scholar] [CrossRef]
- Yoo, J.; Johansson, K.H. Event-triggered model predictive control with a statistical learning. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 2571–2581. [Google Scholar] [CrossRef]
- Badawi, R.; Chen, J. Enhancing enumeration-based model predictive control for dc-dc boost converter with event-triggered control. In Proceedings of the 2022 European Control Conference, London, UK, 12–15 July 2022. [Google Scholar]
- Yu, L.; Xia, Y.; Sun, Z. Robust event-triggered model predictive control for constrained linear continuous system. Int. J. Robust Nonlinear Control 2018, 29, 1216–1229. [Google Scholar]
- Chen, J.; Meng, X.; Li, Z. Reinforcement learning-based event-triggered model predictive control for autonomous vehicle path following. In Proceedings of the American Control Conference, Atlanta, GA, USA, 8–10 June 2022. [Google Scholar]
- Dang, F.; Chen, D.; Chen, J.; Li, Z. Event-triggered model predictive control with deep reinforcement learning for autonomous driving. IEEE Trans. Intell. Veh. 2023, 9, 459–468. [Google Scholar] [CrossRef]
- Baumann, D.; Zhu, J.-J.; Martius, G.; Trimpe, S. Deep reinforcement learning for event-triggered control. In Proceedings of the 2018 IEEE Conference on Decision and Control (CDC), Miami, FL, USA, 17–19 December 2018; pp. 943–950. [Google Scholar]
- Leong, A.S.; Ramaswamy, A.; Quevedo, E.D.; Karl, H.; Shi, L. Deep reinforcement learning for wireless sensor scheduling in cyber–physical systems. Automatica 2020, 113, 108759. [Google Scholar] [CrossRef]
- Chen, J.; Zhou, Z. Battery cell imbalance and electric vehicles range: Correlation and NMPC-based balancing control. In Proceedings of the 2023 IEEE International Conference on Electro Information Technology, Romeoville, IL, USA, 18–20 May 2023. [Google Scholar]
- Dubarry, M.; Vuillaume, N.; Liaw, B.Y. Origins and accommodation of cell variations in li-ion battery pack modeling. Int. J. Energy Res. 2010, 34, 216–231. [Google Scholar] [CrossRef]
- Chen, J.; Zhou, Z.; Zhou, Z.; Wang, X.; Liaw, B. Impact of battery cell imbalance on electric vehicle range. Green Energy Intell. Transp. 2022, 1, 100025. [Google Scholar] [CrossRef]
- Daowd, M.; Omar, N.; Van Den Bossche, P.; Van Mierlo, J. Passive and active battery balancing comparison based on MATLAB simulation. In Proceedings of the 2011 IEEE Vehicle Power And Propulsion Conference, Chicago, IL, USA, 6–9 September 2011; pp. 1–7. [Google Scholar]
- Karnehm, D.; Bliemetsrieder, W.; Pohlmann, S.; Neve, A. Controlling Algorithm of Reconfigurable Battery for State of Charge Balancing using Amortized Q-Learning. Preprints 2024. [Google Scholar] [CrossRef]
- Hoekstra, F.S.J.; Bergveld, H.J.; Donkers, M. Range maximisation of electric vehicles through active cell balancing using reachability analysis. In Proceedings of the 2019 American Control Conference (ACC), Philadelphia, PA, USA, 10–12 July 2019; pp. 1567–1572. [Google Scholar]
- Shang, Y.; Cui, N.; Zhang, C. An optimized any-cell-to-any-cell equalizer based on coupled half-bridge converters for series-connected battery strings. IEEE Trans. Power Electron. 2018, 34, 8831–8841. [Google Scholar] [CrossRef]
- Wang, L.Y.; Wang, C.; Yin, G.; Lin, F.; Polis, M.P.; Zhang, C.; Jiang, J. Balanced control strategies for interconnected heterogeneous battery systems. IEEE Trans. Sustain. Energy 2015, 7, 189–199. [Google Scholar] [CrossRef]
- Evzelman, M.; Rehman, M.M.U.; Hathaway, K.; Zane, R.; Costinett, D.; Maksimovic, D. Active balancing system for electric vehicles with incorporated low-voltage bus. IEEE Trans. Power Electron. 2015, 31, 7887–7895. [Google Scholar] [CrossRef]
- Xu, J.; Cao, B.; Li, S.; Wang, B.; Ning, B. A hybrid criterion based balancing strategy for battery energy storage systems. Energy Procedia 2016, 103, 225–230. [Google Scholar] [CrossRef]
- Gao, Z.; Chin, C.; Toh, W.; Chiew, J.; Jia, J. State-of-charge estimation and active cell pack balancing design of lithium battery power system for smart electric vehicle. J. Adv. Transp. 2017, 2017, 6510747. [Google Scholar] [CrossRef]
- Narayanaswamy, S.; Park, S.; Steinhorst, S.; Chakraborty, S. Multi-pattern active cell balancing architecture and equalization strategy for battery packs. In Proceedings of the International Symposium on Low Power Electronics and Design, Seattle, WA, USA, 23–25 July 2018; pp. 1–6. [Google Scholar]
- Kauer, M.; Narayanaswamy, S.; Steinhorst, S.; Lukasiewycz, M.; Chakraborty, S. Many-to-many active cell balancing strategy design. In Proceedings of the 20th Asia and South Pacific Design Automation Conference, Chiba, Japan, 19–22 January 2015; pp. 267–272. [Google Scholar]
- Mestrallet, F.; Kerachev, L.; Crebier, J.; Collet, A. Multiphase interleaved converter for lithium battery active balancing. IEEE Trans. Power Electron. 2013, 29, 2874–2881. [Google Scholar] [CrossRef]
- Maharjan, L.; Inoue, S.; Akagi, H.; Asakura, J. State-of-charge (SOC)-balancing control of a battery energy storage system based on a cascade PWM converter. IEEE Trans. Power Electron. 2009, 24, 1628–1636. [Google Scholar] [CrossRef]
- Einhorn, M.; Roessler, W.; Fleig, J. Improved performance of serially connected li-ion batteries with active cell balancing in electric vehicles. IEEE Trans. Veh. Technol. 2011, 60, 2448–2457. [Google Scholar] [CrossRef]
- Hoekstra, F.S.; Ribelles, L.W.; Bergveld, H.J.; Donkers, M. Real-time range maximisation of electric vehicles through active cell balancing using model-predictive control. In Proceedings of the 2020 American Control Conference, Denver, CO, USA, 1–3 July 2020; pp. 2219–2224. [Google Scholar]
- Pinto, C.; Barreras, J.; Schaltz, E.; Araujo, R. Evaluation of advanced control for li-ion battery balancing systems using convex optimization. IEEE Trans. Sustain. Energy 2016, 7, 1703–1717. [Google Scholar] [CrossRef]
- McCurlie, L.; Preindl, M.; Emadi, A. Fast model predictive control for redistributive lithium-ion battery balancing. IEEE Trans. Ind. Electron. 2016, 64, 1350–1357. [Google Scholar] [CrossRef]
- Altaf, F.; Egardt, B.; Mårdh, L. Load management of modular battery using model predictive control: Thermal and state-of-charge balancing. IEEE Trans. Control. Syst. Technol. 2016, 25, 47–62. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Watkins, C.J.C.H. Learning from Delayed Rewards. Ph.D. Thesis, University of Cambridge, Cambridge, UK, 1989. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Hasselt, H.V.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Chen, J.; Yi, Z. Comparison of event-triggered model predictive control for autonomous vehicle path tracking. In Proceedings of the IEEE Conference Control Technology and Applications, San Diego, CA, USA, 8–11 August 2021. [Google Scholar]
- Pei, Z.; Zhao, X.; Yuan, H.; Peng, Z.; Wu, L. An equivalent circuit model for lithium battery of electric vehicle considering self-healing characteristic. J. Control Sci. Eng. 2018, 2018, 5179758. [Google Scholar] [CrossRef]
- Wehbe, J.; Karami, N. Battery equivalent circuits and brief summary of components value determination of lithium ion: A review. In Proceedings of the 2015 Third International Conference on Technological Advances in Electrical, Electronics and Computer Engineering (TAEECE), Beirut, Lebanon, 29 April–1 May 2015; pp. 45–49. [Google Scholar]
- The MathWorks Inc. Deep Q-Network (DQN) Agents; The MathWorks Inc.: Natick, MA, USA; Available online: https://www.mathworks.com/help/reinforcement-learning/ug/dqn-agents.html#d126e7212 (accessed on 29 January 2024).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Unit | |||||
|---|---|---|---|---|---|---|
| C | Ah | 62.87 | 60.00 | 66.61 | 56.73 | 61.66 |
| mΩ | 6.40 | 5.66 | 5.47 | 6.68 | 6.36 | |
| kF | 153.7 | 177.8 | 175.9 | 168.9 | 150.4 | |
| mΩ | 1.49 | 1.27 | 1.41 | 1.51 | 1.53 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Flessner, D.; Chen, J.; Xiong, G. Reinforcement Learning-Based Event-Triggered Active-Battery-Cell-Balancing Control for Electric Vehicle Range Extension. Electronics 2024, 13, 990. https://doi.org/10.3390/electronics13050990
Flessner D, Chen J, Xiong G. Reinforcement Learning-Based Event-Triggered Active-Battery-Cell-Balancing Control for Electric Vehicle Range Extension. Electronics. 2024; 13(5):990. https://doi.org/10.3390/electronics13050990
Chicago/Turabian StyleFlessner, David, Jun Chen, and Guojiang Xiong. 2024. "Reinforcement Learning-Based Event-Triggered Active-Battery-Cell-Balancing Control for Electric Vehicle Range Extension" Electronics 13, no. 5: 990. https://doi.org/10.3390/electronics13050990
APA StyleFlessner, D., Chen, J., & Xiong, G. (2024). Reinforcement Learning-Based Event-Triggered Active-Battery-Cell-Balancing Control for Electric Vehicle Range Extension. Electronics, 13(5), 990. https://doi.org/10.3390/electronics13050990