
Domain Adaptive Subterranean 3D Pedestrian Detection via Instance Transfer and Confidence Guidance


Abstract
1. Introduction
- (1)
- A novel domain adaptive subterranean 3D pedestrian detection method is proposed in this paper to mitigate the impact of large domain gaps between the road scenes and the subterranean scenes, thus achieving accurate subterranean 3D pedestrian detection.
- (2)
- By transferring the annotated instances from the road scenes to the subterranean scenes, an instance transfer-based scene updating strategy is proposed to achieve scene updating of the target domain, in turn obtaining sufficient high-quality pseudo labels.
- (3)
- To further optimize the network learning, a pseudo label confidence-guided learning mechanism is introduced to fully utilize pseudo labels of different qualities in the self-training stage.
- (4)
- Extensive experiments demonstrate that the proposed method obtains great performance in domain adaptive subterranean 3D pedestrian detection.
2. Related Works
2.1. LiDAR-Based 3D Detection
2.2. Domain Adaptive Object Detection
2.3. Visual Tasks in Subterranean Scenes
3. Method
3.1. Problem Statement and Overview
3.2. Instance Transfer-Based Scene Updating Strategy
3.3. Pseudo Label Confidence-Guided Learning Mechanism
3.4. Implementation Details
| Algorithm 1 The training procedure of the proposed method. |
|
4. Experiments
4.1. Experimental Settings
4.2. Comparison Results
4.3. Ablation Studies
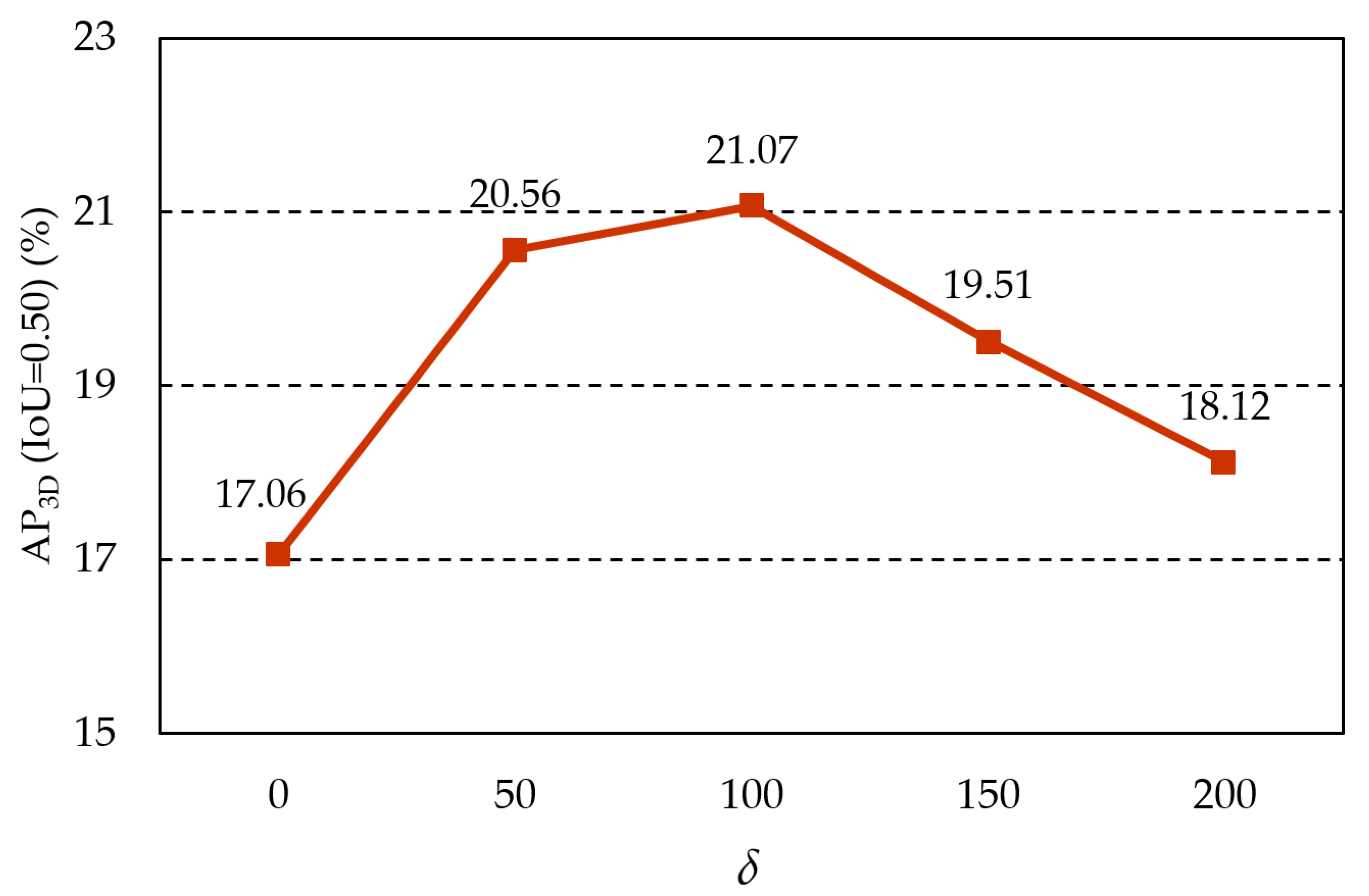
4.4. Hyperparameter Selection Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, H.; Savkin, A.V.; Vucetic, B. Autonomous area exploration and mapping in underground mine environments by unmanned aerial vehicles. Robotica 2020, 38, 442–456. [Google Scholar] [CrossRef]
- Yu, C.; Lei, J.; Peng, B.; Shen, H.; Huang, Q. SIEV-Net: A structure-information enhanced voxel network for 3D object detection from LiDAR point clouds. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5703711. [Google Scholar] [CrossRef]
- Lima, J.P.; Roberto, R.; Figueiredo, L.; Simoes, F.; Teichrieb, V. Generalizable multi-camera 3D pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Sierra-García, J.E.; Fernández-Rodríguez, V.; Santos, M.; Quevedo, E. Development and experimental validation of control algorithm for person-following autonomous robots. Electronics 2023, 12, 2077. [Google Scholar] [CrossRef]
- Zhang, Z.; Gao, Z.; Li, X.; Lee, C.; Lin, W. Information separation network for domain adaptation learning. Electronics 2022, 11, 1254. [Google Scholar] [CrossRef]
- Lei, J.; Qin, T.; Peng, B.; Li, W.; Pan, Z.; Shen, H.; Kwong, S. Reducing background induced domain shift for adaptive person re-identification. IEEE Trans. Ind. Inform. 2023, 19, 7377–7388. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, X.; You, Y.; Li, L.E.; Hariharan, B.; Campbell, M.; Weinberger, K.Q.; Chao, W.L. Train in Germany, Test in the USA: Making 3D object detectors generalize. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020. [Google Scholar]
- Zhang, W.; Li, W.; Xu, D. SRDAN: Scale-aware and range-aware domain adaptation network for cross-dataset 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Luo, Z.; Cai, Z.; Zhou, C.; Zhang, G.; Zhao, H.; Yi, S.; Lu, S.; Li, H.; Zhang, S.; Liu, Z. Unsupervised domain adaptive 3D detection with multi-level consistency. In Proceedings of the IEEE International Conference on Computer Vision, Virtual, 11–17 October 2021. [Google Scholar]
- Yang, J.; Shi, S.; Wang, Z.; Li, H.; Qi, X. ST3D: Self-training for unsupervised domain adaptation on 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Yang, J.; Shi, S.; Wang, Z.; Li, H.; Qi, X. ST3D++: Denoised self-training for unsupervised domain adaptation on 3D object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 6354–6371. [Google Scholar] [CrossRef] [PubMed]
- Hu, Q.; Liu, D.; Hu, W. Density-insensitive unsupervised domain adaption on 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Yuwono, Y.D. Comparison of 3D Object Detection Methods for People Detection in Underground Mine. Master’s Thesis, Colorado School of Mines, Golden, CO, USA, 2022. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Mao, J.; Niu, M.; Jiang, C.; Liang, H.; Chen, J.; Liang, X.; Li, Y.; Ye, C.; Zhang, W.; Li, Z.; et al. One million scenes for autonomous driving: Once dataset. arXiv 2021, arXiv:2106.11037. [Google Scholar]
- Lei, J.; Song, J.; Peng, B.; Li, W.; Pan, Z.; Huang, Q. C2FNet: A coarse-to-fine network for multi-view 3D point cloud generation. IEEE Trans. Image Process. 2022, 31, 6707–6718. [Google Scholar] [CrossRef]
- Peng, B.; Chen, L.; Song, J.; Shen, H.; Huang, Q.; Lei, J. ZS-SBPRnet: A zero-shot sketch-based point cloud retrieval network based on feature projection and cross-reconstruction. IEEE Trans. Ind. Inform. 2023, 19, 9194–9203. [Google Scholar] [CrossRef]
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D object proposal generation and detection from point cloud. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. STD: Sparse-to-dense 3D object detector for point cloud. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–3 November 2019. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3DSSD: Point-based 3D single stage object detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020. [Google Scholar]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-end learning for point cloud based 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Yu, C.; Peng, B.; Huang, Q.; Lei, J. PIPC-3Ddet: Harnessing perspective information and proposal correlation for 3D point cloud object detection. IEEE Trans. Circuits Syst. Video Technol. 2023, accepted. [Google Scholar] [CrossRef]
- Liu, Z.; Tang, H.; Lin, Y.; Han, S. Point-voxel cnn for efficient 3D deep learning. In Proceedings of the International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Chen, Y.; Liu, S.; Shen, X.; Jia, J. Fast point r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–3 November 2019. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. PV-RCNN: Point-voxel feature set abstraction for 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020. [Google Scholar]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Domain adaptive faster r-cnn for object detection in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Saito, K.; Ushiku, Y.; Harada, T.; Saenko, K. Strong-weak distribution alignment for adaptive object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Huang, S.W.; Lin, C.T.; Chen, S.P.; Wu, Y.Y.; Hsu, P.H.; Lai, S.H. Auggan: Cross domain adaptation with gan-based data augmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chen, Z.; Luo, Y.; Wang, Z.; Baktashmotlagh, M.; Huang, Z. Revisiting domain-adaptive 3D object detection by reliable, diverse and class-balanced pseudo-labeling. In Proceedings of the IEEE International Conference on Computer Vision, Paris, France, 2–6 October 2023. [Google Scholar]
- Peng, B.; Lin, G.; Lei, J.; Qin, T.; Cao, X.; Ling, N. Contrastive multi-view learning for 3D shape clustering. IEEE Trans. Multimed. 2024; accepted. [Google Scholar] [CrossRef]
- Yue, G.; Cheng, D.; Li, L.; Zhou, T.; Liu, H.; Wang, T. Semi-supervised authentically distorted image quality assessment with consistency-preserving dual-branch convolutional neural network. IEEE Trans. Multimed. 2022, 25, 6499–6511. [Google Scholar] [CrossRef]
- Peng, B.; Zhang, X.; Lei, J.; Zhang, Z.; Ling, N.; Huang, Q. LVE-S2D: Low-light video enhancement from static to dynamic. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 8342–8352. [Google Scholar] [CrossRef]
- Tranzatto, M.; Miki, T.; Dharmadhikari, M.; Bernreiter, L.; Kulkarni, M.; Mascarich, F.; Andersson, O.; Khattak, S.; Hutter, M.; Siegwart, R.; et al. Cerberus in the darpa subterranean challenge. Sci. Robot. 2022, 7, eabp9742. [Google Scholar] [CrossRef] [PubMed]
- Agha, A.; Otsu, K.; Morrell, B.; Fan, D.D.; Thakker, R.; Santamaria-Navarro, A.; Kim, S.K.; Bouman, A.; Lei, X.; Edlund, J.; et al. NeBula: Quest for robotic autonomy in challenging environments; Team costar at the darpa subterranean challenge. arXiv 2021, arXiv:2103.11470. [Google Scholar]
- Buratowski, T.; Garus, J.; Giergiel, M.; Kudriashov, A. Real-time 3D mapping inisolated industrial terrain with use of mobile robotic vehicle. Electronics 2022, 11, 2086. [Google Scholar] [CrossRef]
- Wei, X.; Zhang, H.; Liu, S.; Lu, Y. Pedestrian detection in underground mines via parallel feature transfer network. Pattern Recognit. 2020, 103, 107195. [Google Scholar] [CrossRef]
- Patel, M.; Waibel, G.; Khattak, S.; Hutter, M. LiDAR-guided object search and detection in subterranean environments. In Proceedings of the IEEE International Symposium on Safety, Security, and Rescue Robotics, Seville, Spain, 8–10 November 2022. [Google Scholar]
- Wang, J.; Yang, P.; Liu, Y.; Shang, D.; Hui, X.; Song, J.; Chen, X. Research on improved yolov5 for low-light environment object detection. Electronics 2023, 12, 3089. [Google Scholar] [CrossRef]
- Darpa Subterranean (SubT) Challenge. Available online: https://www.darpa.mil/program/darpa-subterranean-challenge (accessed on 15 January 2024).
- Khattak, S.; Nguyen, H.; Mascarich, F.; Dang, T.; Alexis, K. Complementary multi–modal sensor fusion for resilient robot pose estimation in subterranean environments. In Proceedings of the International Conference on Unmanned Aircraft Systems, Athens, Greece, 1–4 September 2020. [Google Scholar]
- Tai, L.; Paolo, G.; Liu, M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Wang, B.; Liu, Z.; Li, Q.; Prorok, A. Mobile robot path planning in dynamic environments through globally guided reinforcement learning. IEEE Robot. Autom. Lett. 2020, 5, 6932–6939. [Google Scholar] [CrossRef]
- Zhao, K.; Song, J.; Luo, Y.; Liu, Y. Research on game-playing agents based on deep reinforcement learning. Robotics 2022, 11, 35. [Google Scholar] [CrossRef]
- OpenPCDet: An Open-Source Toolbox for 3D Object Detection from Point Clouds. Available online: https://github.com/open-mmlab/OpenPCDet (accessed on 15 January 2024).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning |
|---|---|
| Point clouds of the source domain | |
| Annotations of | |
| Point clouds of the target domain | |
| Initial prediction results of the target domain with 3D bounding boxes and confidence scores | |
| High-quality pseudo labels | |
| Low-quality pseudo labels | |
| Annotated instances sampled from the source domain with 3D bounding boxes and enclosing points | |
| Sampled instances after filtering | |
| Pseudo labels of transferred instances with 3D bounding boxes and confidence scores | |
| Whole pseudo labels of the target domain with 3D bounding boxes b and confidence scores s | |
| w | Confidence weights of pseudo labels |
| Method | IoU = 0.50 | IoU = 0.25 | ||
|---|---|---|---|---|
| (%) | (%) | (%) | (%) | |
| Source Only | 13.61 | 25.12 | 51.22 | 52.65 |
| SN | 14.36 | 24.18 | 50.27 | 53.45 |
| ST3D | 16.34 | 28.06 | 54.54 | 57.55 |
| ST3D++ | 17.20 | 27.69 | 50.09 | 52.59 |
| ReDB | 14.28 | 29.90 | 53.36 | 55.86 |
| Ours | 21.07 | 33.15 | 61.20 | 64.78 |
| Method | IoU = 0.50 | IoU = 0.25 | ||
|---|---|---|---|---|
| (%) | (%) | (%) | (%) | |
| Source Only | 11.06 | 23.67 | 51.04 | 51.81 |
| SN | 10.22 | 24.03 | 52.89 | 56.79 |
| ST3D | 15.31 | 34.15 | 60.23 | 61.77 |
| ST3D++ | 16.04 | 33.13 | 65.08 | 67.08 |
| ReDB | 14.01 | 34.00 | 66.28 | 67.97 |
| Ours | 18.66 | 35.99 | 73.45 | 75.65 |
| Method | IoU = 0.50 | IoU = 0.25 | ||
|---|---|---|---|---|
| (%) | (%) | (%) | (%) | |
| w/o ITSUS and w/o PSCLM | 17.20 | 27.69 | 50.09 | 52.59 |
| w/o ITSUS | 18.96 | 31.72 | 52.99 | 56.23 |
| w/o PSCLM | 18.77 | 32.29 | 53.55 | 57.60 |
| Ours | 21.07 | 33.15 | 61.20 | 64.78 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Zheng, Z.; Qin, T.; Xu, L.; Zhang, X. Domain Adaptive Subterranean 3D Pedestrian Detection via Instance Transfer and Confidence Guidance. Electronics 2024, 13, 982. https://doi.org/10.3390/electronics13050982
Liu Z, Zheng Z, Qin T, Xu L, Zhang X. Domain Adaptive Subterranean 3D Pedestrian Detection via Instance Transfer and Confidence Guidance. Electronics. 2024; 13(5):982. https://doi.org/10.3390/electronics13050982
Chicago/Turabian StyleLiu, Zengyun, Zexun Zheng, Tianyi Qin, Liying Xu, and Xu Zhang. 2024. "Domain Adaptive Subterranean 3D Pedestrian Detection via Instance Transfer and Confidence Guidance" Electronics 13, no. 5: 982. https://doi.org/10.3390/electronics13050982
APA StyleLiu, Z., Zheng, Z., Qin, T., Xu, L., & Zhang, X. (2024). Domain Adaptive Subterranean 3D Pedestrian Detection via Instance Transfer and Confidence Guidance. Electronics, 13(5), 982. https://doi.org/10.3390/electronics13050982