
S2S-Sim: A Benchmark Dataset for Ship Cooperative 3D Object Detection


Abstract
1. Introduction
- We proposed the ship cooperative perception dataset S2S-sim. Based on Unity3D, we simulated three typical navigation scenes and constructed a 64-line simulated LiDAR mounted on typical ships to collect data according to the characteristics of real LiDAR sensors. A total of 7000 frames of cooperative sensing data were collected for collaboration within a range of 2 km.
- We proposed a regional clustering fusion-based ship cooperative 3D object-detection method. The method uses region division and clustering to improve the efficiency and accuracy of cooperative data fusion. Compared with existing multi-agent cooperative perception methods, our proposed method achieves the state-of-the-art object-detection performance.
- The S2S-sim dataset proposed in this study is the first ship cooperative perception dataset, serving as a standardized dataset that is easy to use. Meanwhile, the cooperative perception method proposed in this paper is implemented based on the V2V cooperative perception framework, which facilitates research on ship cooperative perception methods as well as the transfer and application of vehicle cooperative perception methods to the domain of ship navigation.
2. Related Work
2.1. Cooperative Perception Datasets
2.2. Multi-Agent Cooperative Perception
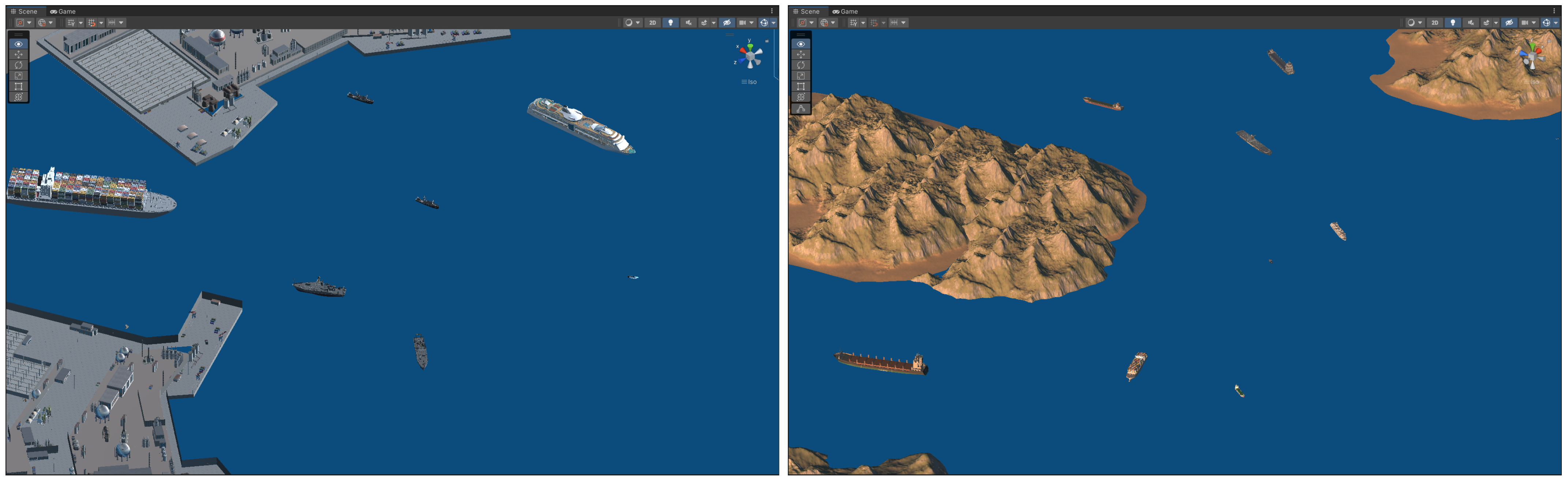
3. S2S-Sim Dataset
3.1. Construction of Ship Navigation Scenarios
3.2. Sensor Simulation and Data Collection
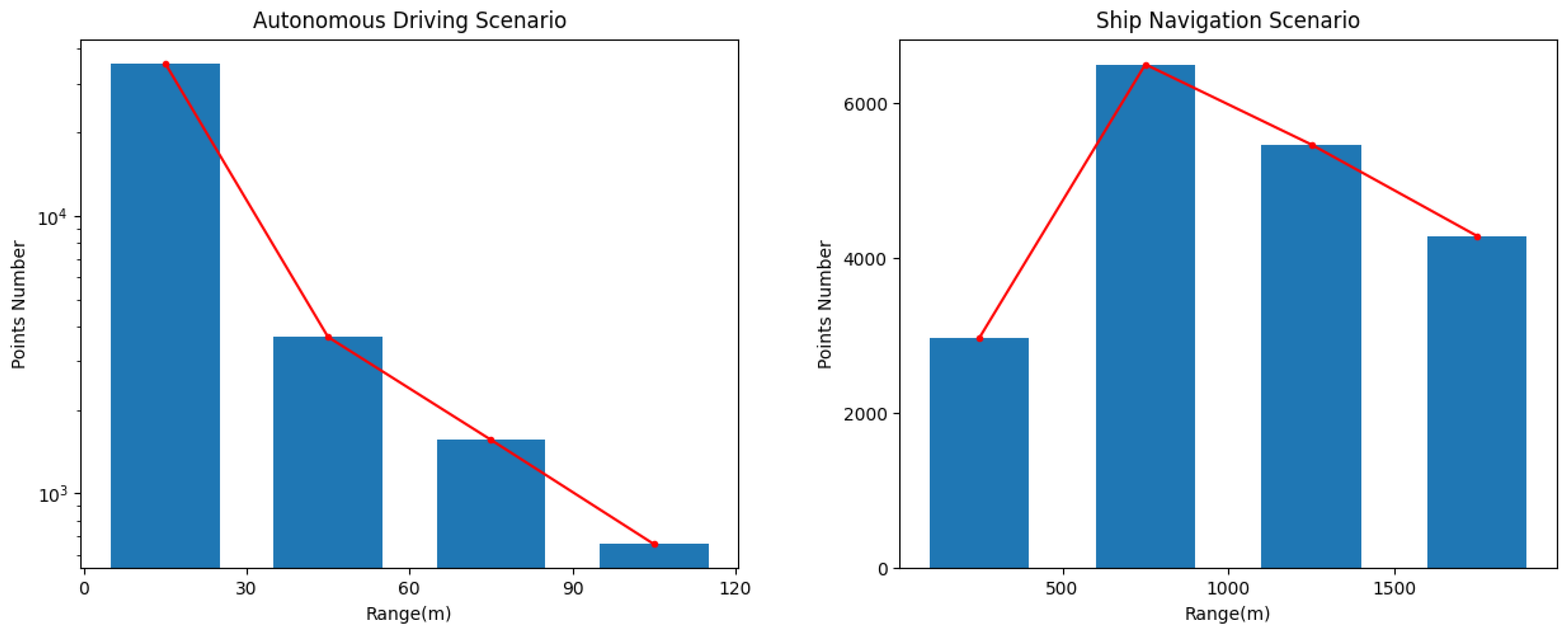
3.3. Dataset Analysis
4. Task and Pipeline
4.1. Ship Cooperative 3D Object Detection
4.1.1. Ship Perception Range and Configuration
4.1.2. Input, Output, and Ground Truth
4.1.3. Evaluation Metrics
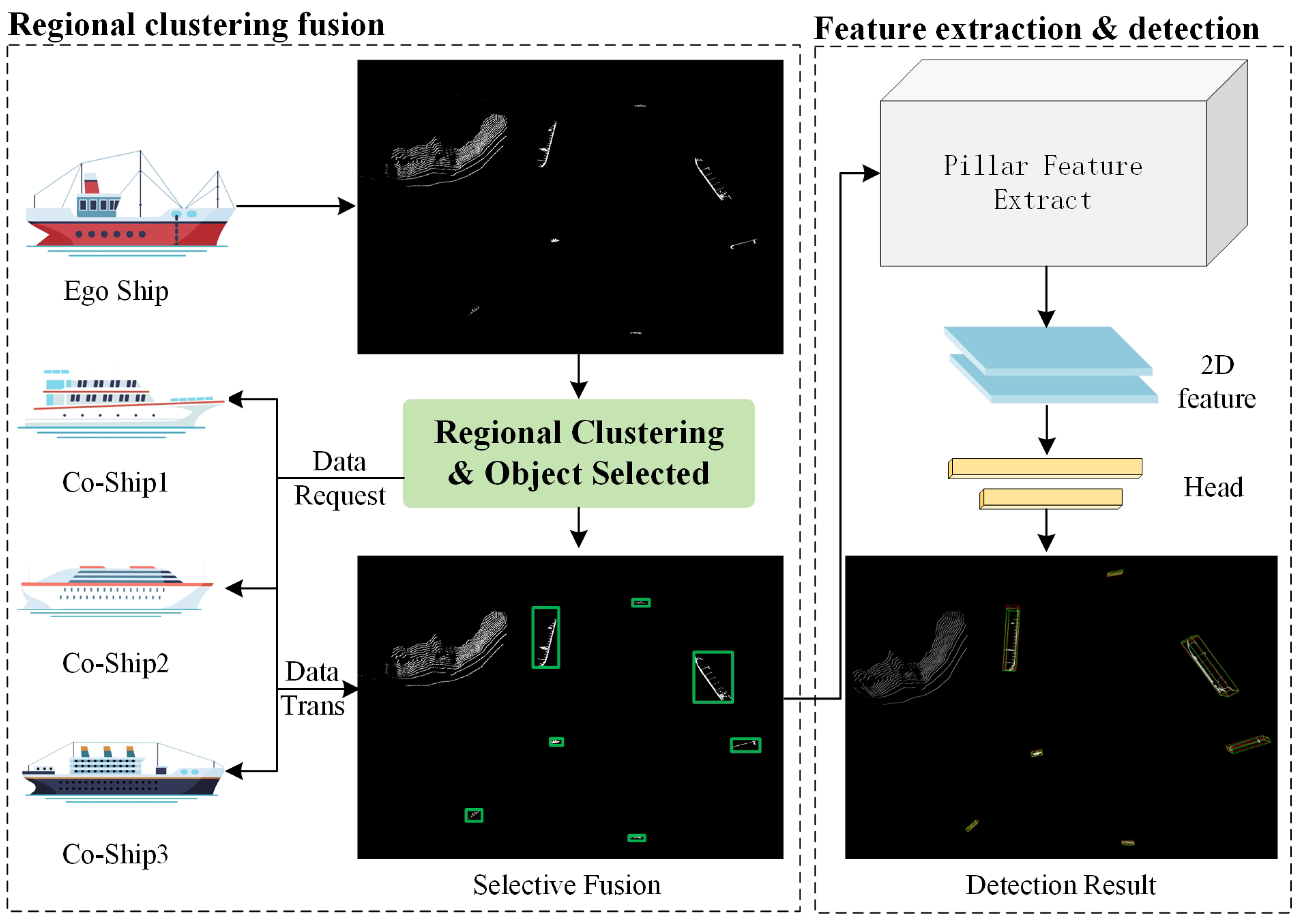
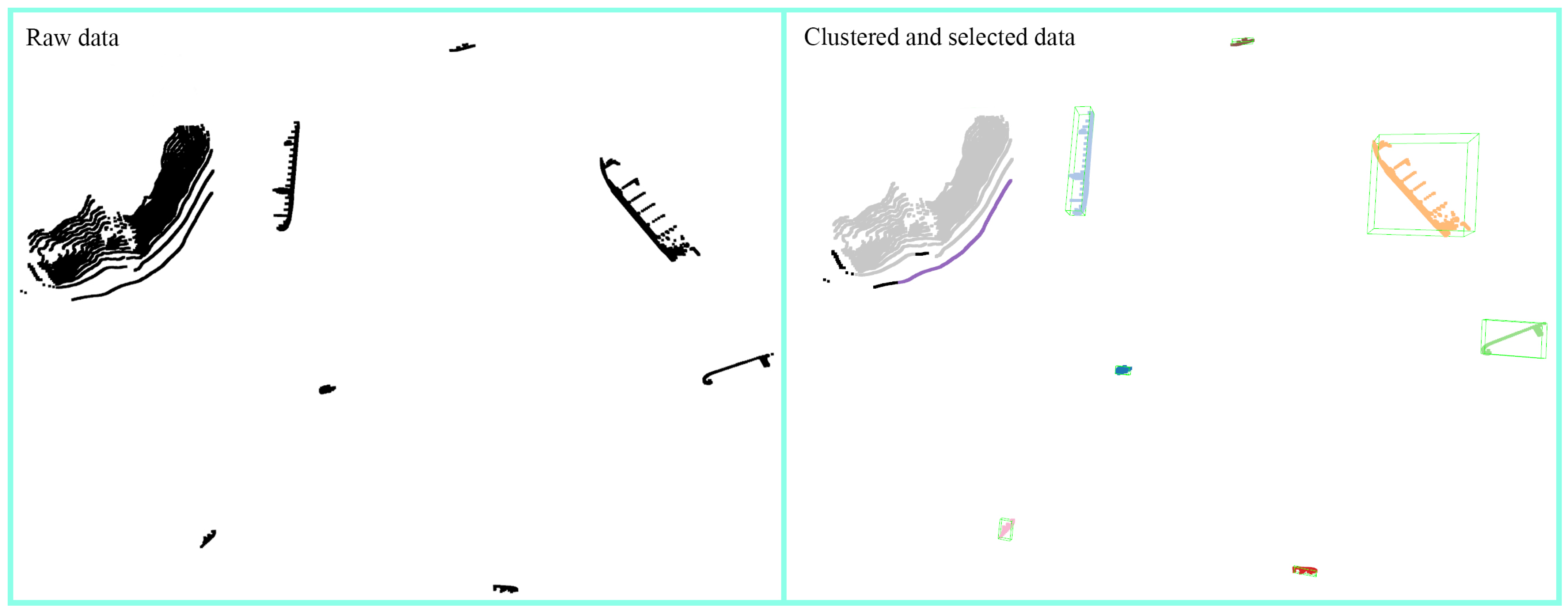
4.2. Regional Clustering Fusion
4.2.1. Motivation
4.2.2. Method
| Algorithm 1 Regional Clustering Fusion |
|
5. Results and Experimental Discussion
5.1. Benchmark Models
5.2. Experiment Details
5.3. Performance and Analysis
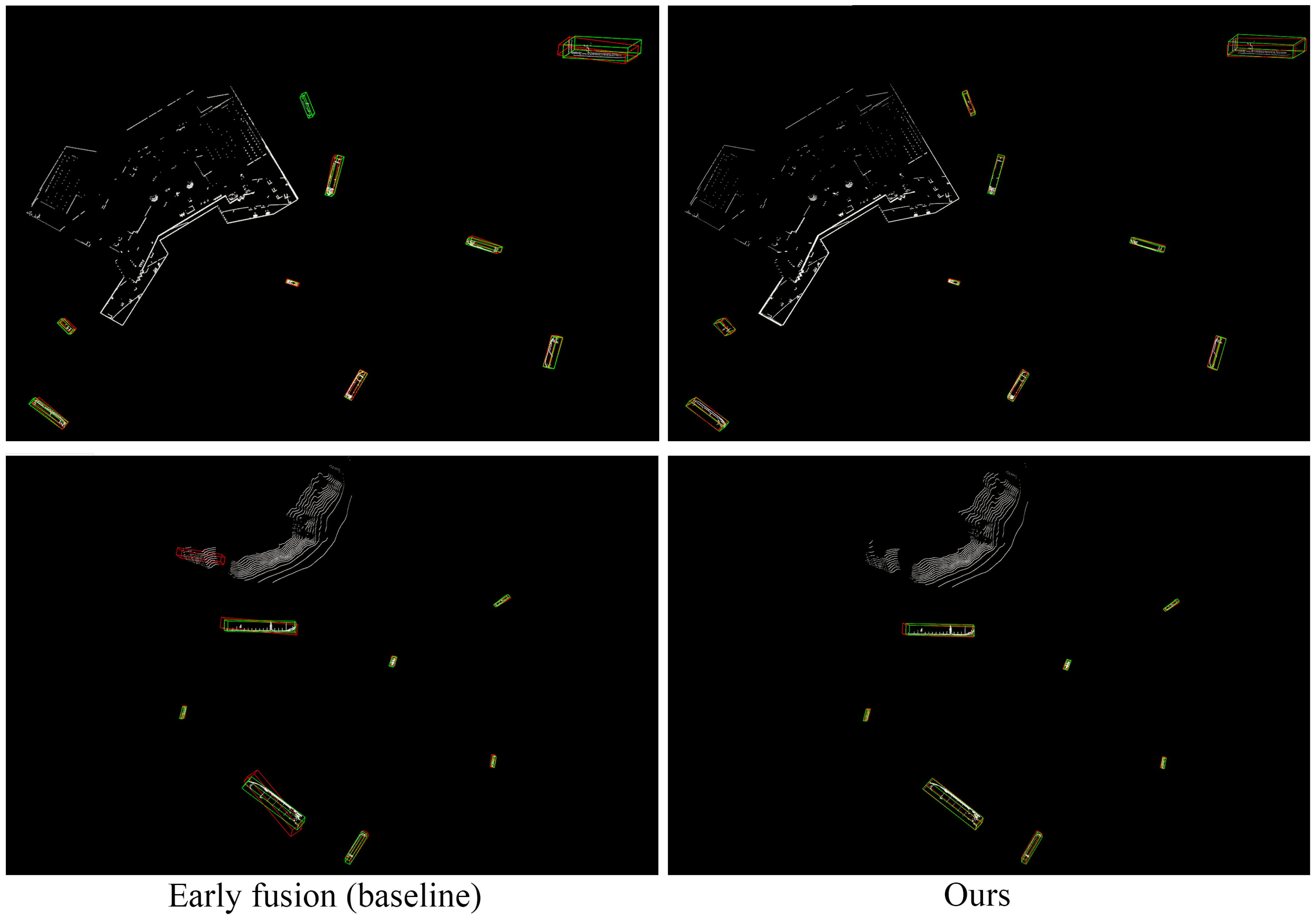
5.3.1. Overall Performance

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Fusion Strategy | 3D Object Detection AP@IoU | ||
|---|---|---|---|---|
| 0.7 | 0.5 | 0.3 | ||
| No fusion | No | 24.86 | 51.96 | 59.75 |
| Early fusion | Early | 37.96 | 70.57 | 78.95 |
| IM fusion | Intermediate | 30.32 | 67.20 | 77.64 |
| Late fusion | Late | 26.17 | 61.99 | 73.81 |
| Fcooper [35] | Intermediate | 43.61 | 73.09 | 80.82 |
| Cobevt [37] | Intermediate | 24.98 | 56.61 | 74.49 |
| Where2comm [40] | Intermediate | 25.22 | 65.57 | 77.38 |
| V2xvit [11] | Intermediate | 29.67 | 57.35 | 67.15 |
| Coalign [36] | Intermediate | 39.11 | 63.87 | 78.27 |
| Ours | Early | 51.09 | 75.29 | 82.14 |
5.3.2. Performance with Different Perception Ranges
5.3.3. Collaborative Efficiency Analysis
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Han, Y.; Zhang, H.; Li, H.; Jin, Y.; Lang, C.; Li, Y. Collaborative perception in autonomous driving: Methods, datasets and challenges. IEEE Intell. Transp. Syst. Mag. 2023, 15, 131–151. [Google Scholar] [CrossRef]
- Sun, X.; Song, S.; Miao, Z.; Tang, P.; Ai, L. LiDAR Point Clouds Semantic Segmentation in Autonomous Driving Based on Asymmetrical Convolution. Electronics 2023, 12, 4926. [Google Scholar] [CrossRef]
- Yang, W.; Sheng, S.; Luo, X.; Xie, S. Geometric relation based point clouds classification and segmentation. Concurr. Comput. Pract. Exp. 2022, 34, e6845. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 3354–3361. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Yahia, Y.; Lopes, J.C.; Lopes, R.P. Computer Vision Algorithms for 3D Object Recognition and Orientation: A Bibliometric Study. Electronics 2023, 12, 4218. [Google Scholar] [CrossRef]
- Yuan, Y.; Cheng, H.; Sester, M. Keypoints-based deep feature fusion for cooperative vehicle detection of autonomous driving. IEEE Robot. Autom. Lett. 2022, 7, 3054–3061. [Google Scholar] [CrossRef]
- Wang, T.H.; Manivasagam, S.; Liang, M.; Yang, B.; Zeng, W.; Urtasun, R. V2vnet: Vehicle-to-vehicle communication for joint perception and prediction. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 605–621. [Google Scholar]
- Xu, R.; Xiang, H.; Xia, X.; Han, X.; Li, J.; Ma, J. Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2583–2589. [Google Scholar]
- Xu, R.; Xiang, H.; Tu, Z.; Xia, X.; Yang, M.H.; Ma, J. V2x-vit: Vehicle-to-everything cooperative perception with vision transformer. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 107–124. [Google Scholar]
- Li, Y.; Ma, D.; An, Z.; Wang, Z.; Zhong, Y.; Chen, S.; Feng, C. V2X-Sim: Multi-agent collaborative perception dataset and benchmark for autonomous driving. IEEE Robot. Autom. Lett. 2022, 7, 10914–10921. [Google Scholar] [CrossRef]
- Xu, R.; Xia, X.; Li, J.; Li, H.; Zhang, S.; Tu, Z.; Meng, Z.; Xiang, H.; Dong, X.; Song, R.; et al. V2v4real: A real-world large-scale dataset for vehicle-to-vehicle cooperative perception. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 13712–13722. [Google Scholar]
- Yu, H.; Luo, Y.; Shu, M.; Huo, Y.; Yang, Z.; Shi, Y.; Guo, Z.; Li, H.; Hu, X.; Yuan, J.; et al. Dair-v2x: A large-scale dataset for vehicle-infrastructure cooperative 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 21361–21370. [Google Scholar]
- Zhang, Q.; Shan, Y.; Zhang, Z.; Lin, H.; Zhang, Y.; Huang, K. Multisensor fusion-based maritime ship object-detection method for autonomous surface vehicles. J. Field Robot. 2023. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, L.; Meng, H.; Zhang, W. LiDAR Simulator for Autonomous Driving in Ocean Scenes. In Proceedings of the 2023 IEEE International Conference on Mechatronics and Automation (ICMA), Harbin, China, 6–9 August 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1082–1087. [Google Scholar]
- Yao, Z.; Chen, X.; Xu, N.; Gao, N.; Ge, M. LiDAR-based simultaneous multi-object tracking and static mapping in nearshore scenario. Ocean. Eng. 2023, 272, 113939. [Google Scholar] [CrossRef]
- Zhou, B.; Xu, H.; Shen, S. Racer: Rapid collaborative exploration with a decentralized multi-uav system. IEEE Trans. Robot. 2023, 39, 1816–1835. [Google Scholar] [CrossRef]
- Kurunathan, H.; Huang, H.; Li, K.; Ni, W.; Hossain, E. Machine learning-aided operations and communications of unmanned aerial vehicles: A contemporary survey. IEEE Commun. Surv. Tutor. 2023. [Google Scholar] [CrossRef]
- Shao, G.; Ma, Y.; Malekian, R.; Yan, X.; Li, Z. A novel cooperative platform design for coupled USV–UAV systems. IEEE Trans. Ind. Inform. 2019, 15, 4913–4922. [Google Scholar] [CrossRef]
- Sun, Z.; Sun, H.; Li, P.; Zou, J. Self-organizing cooperative pursuit strategy for multi-USV with dynamic obstacle ships. J. Mar. Sci. Eng. 2022, 10, 562. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, J.; Ma, D.; Wang, Y.; Feng, C. Multi-robot scene completion: Towards task-agnostic collaborative perception. In Proceedings of the Conference on Robot Learning, Atlanta, GA, USA, 6 November 2023; pp. 2062–2072. [Google Scholar]
- Zhu, Z.; Du, Q.; Wang, Z.; Li, G. A survey of multi-agent cross domain cooperative perception. Electronics 2022, 11, 1091. [Google Scholar] [CrossRef]
- Yu, H.; Yang, W.; Ruan, H.; Yang, Z.; Tang, Y.; Gao, X.; Hao, X.; Shi, Y.; Pan, Y.; Sun, N.; et al. V2X-Seq: A Large-Scale Sequential Dataset for Vehicle-Infrastructure Cooperative Perception and Forecasting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5486–5495. [Google Scholar]
- Axmann, J.; Moftizadeh, R.; Su, J.; Tennstedt, B.; Zou, Q.; Yuan, Y.; Ernst, D.; Alkhatib, H.; Brenner, C.; Schön, S. LUCOOP: Leibniz University Cooperative Perception and Urban Navigation Dataset. In Proceedings of the 2023 IEEE Intelligent Vehicles Symposium (IV), Anchorage, AK, USA, 4–7 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–8. [Google Scholar]
- Arnold, E.; Dianati, M.; de Temple, R.; Fallah, S. Cooperative perception for 3D object detection in driving scenarios using infrastructure sensors. IEEE Trans. Intell. Transp. Syst. 2020, 23, 1852–1864. [Google Scholar] [CrossRef]
- Ngo, H.; Fang, H.; Wang, H. Cooperative Perception With V2V Communication for Autonomous Vehicles. IEEE Trans. Veh. Technol. 2023, 72, 11122–11131. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, L.; Wang, Z.; Zhao, Y.; Zhou, T. Core: Cooperative reconstruction for multi-agent perception. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 8710–8720. [Google Scholar]
- Hu, Y.; Lu, Y.; Xu, R.; Xie, W.; Chen, S.; Wang, Y. Collaboration Helps Camera Overtake LiDAR in 3D Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 9243–9252. [Google Scholar]
- Yang, K.; Yang, D.; Zhang, J.; Li, M.; Liu, Y.; Liu, J.; Wang, H.; Sun, P.; Song, L. Spatio-temporal domain awareness for multi-agent collaborative perception. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 23383–23392. [Google Scholar]
- Ma, Y.; Lu, J.; Cui, C.; Zhao, S.; Cao, X.; Ye, W.; Wang, Z. MACP: Efficient Model Adaptation for Cooperative Perception. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 1–10 January 2024; pp. 3373–3382. [Google Scholar]
- Meng, Z.; Xia, X.; Xu, R.; Liu, W.; Ma, J. HYDRO-3D: Hybrid Object Detection and Tracking for Cooperative Perception Using 3D LiDAR. IEEE Trans. Intell. Veh. 2023, 8, 4069–4080. [Google Scholar] [CrossRef]
- Queralta, J.P.; Taipalmaa, J.; Pullinen, B.C.; Sarker, V.K.; Gia, T.N.; Tenhunen, H.; Gabbouj, M.; Raitoharju, J.; Westerlund, T. Collaborative multi-robot search and rescue: Planning, coordination, perception, and active vision. IEEE Access 2020, 8, 191617–191643. [Google Scholar] [CrossRef]
- Chen, Q.; Tang, S.; Yang, Q.; Fu, S. Cooper: Cooperative perception for connected autonomous vehicles based on 3d point clouds. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–9 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 514–524. [Google Scholar]
- Chen, Q.; Ma, X.; Tang, S.; Guo, J.; Yang, Q.; Fu, S. F-cooper: Feature based cooperative perception for autonomous vehicle edge computing system using 3D point clouds. In Proceedings of the 4th ACM/IEEE Symposium on Edge Computing, Washington, DC, USA, 7–9 November 2019; pp. 88–100. [Google Scholar]
- Lu, Y.; Li, Q.; Liu, B.; Dianati, M.; Feng, C.; Chen, S.; Wang, Y. Robust collaborative 3d object detection in presence of pose errors. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 4812–4818. [Google Scholar]
- Xu, R.; Tu, Z.; Xiang, H.; Shao, W.; Zhou, B.; Ma, J. CoBEVT: Cooperative bird’s eye view semantic segmentation with sparse transformers. arXiv 2022, arXiv:2207.02202. [Google Scholar]
- Qiao, D.; Zulkernine, F. Adaptive feature fusion for cooperative perception using lidar point clouds. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 1186–1195. [Google Scholar]
- Liu, Y.C.; Tian, J.; Glaser, N.; Kira, Z. When2com: Multi-agent perception via communication graph grouping. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4106–4115. [Google Scholar]
- Hu, Y.; Fang, S.; Lei, Z.; Zhong, Y.; Chen, S. Where2comm: Communication-efficient collaborative perception via spatial confidence maps. Adv. Neural Inf. Process. Syst. 2022, 35, 4874–4886. [Google Scholar]
- Liu, C.; Chen, Y.; Chen, J.; Payton, R.; Riley, M.; Yang, S.H. Cooperative perception with learning-based V2V communications. IEEE Wirel. Commun. Lett. 2023, 12, 1831–1835. [Google Scholar] [CrossRef]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]



| LiDAR Type | Real LiDAR | Simulated LiDAR (Ours) |
|---|---|---|
| Beam | 128 | 64 |
| Frequency | 2 Hz | 10 Hz |
| Range | 2n mile | 2 km |
| horizontal FOV | ||
| vertical FOV | to | to |
| error | cm | cm |
| Scenario Type | Percentage (%) | Ship Number | Density (/km2) | Frame/Segment |
|---|---|---|---|---|
| Port | 28.6 | 21.56 | 5.14 | 250 |
| Island | 57.1 | 10.64 | 2.54 | 250 |
| Open water | 14.3 | 11.21 | 2.67 | 250 |
| Method | Fusion Strategy | R = 1 km | R = 1.5 km | R = 2 km |
|---|---|---|---|---|
| No fusion | No | 55.46 | 54.64 | 51.96 |
| Early fusion | Early | 80.45 | 77.25 | 70.57 |
| IM fusion | Intermediate | 36.97 | 52.88 | 67.20 |
| Late fusion | Late | 42.12 | 54.66 | 61.99 |
| Fcooper | Intermediate | 40.65 | 58.02 | 73.09 |
| Cobevt | Intermediate | 25.97 | 41.83 | 56.61 |
| Where2comm | Intermediate | 42.18 | 61.01 | 65.57 |
| V2xvit | Intermediate | 35.61 | 49.14 | 57.35 |
| Coalign | Intermediate | 41.83 | 60.06 | 63.87 |
| Ours | Early | 84.07 | 81.43 | 75.29 |
| Method | Range (km) | AP (%) | Request Data (KB) |
|---|---|---|---|
| Baseline | 1 | 80.45 | 48.24 |
| Ours | 1 | 84.07 | 32.27 |
| Baseline | 1.5 | 77.25 | 86.44 |
| Ours | 1.5 | 81.43 | 46.09 |
| Baseline | 2 | 70.57 | 112.92 |
| Ours | 2 | 75.29 | 51.46 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, W.; Wang, X.; Luo, X.; Xie, S.; Chen, J. S2S-Sim: A Benchmark Dataset for Ship Cooperative 3D Object Detection. Electronics 2024, 13, 885. https://doi.org/10.3390/electronics13050885
Yang W, Wang X, Luo X, Xie S, Chen J. S2S-Sim: A Benchmark Dataset for Ship Cooperative 3D Object Detection. Electronics. 2024; 13(5):885. https://doi.org/10.3390/electronics13050885
Chicago/Turabian StyleYang, Wenbin, Xinzhi Wang, Xiangfeng Luo, Shaorong Xie, and Junxi Chen. 2024. "S2S-Sim: A Benchmark Dataset for Ship Cooperative 3D Object Detection" Electronics 13, no. 5: 885. https://doi.org/10.3390/electronics13050885
APA StyleYang, W., Wang, X., Luo, X., Xie, S., & Chen, J. (2024). S2S-Sim: A Benchmark Dataset for Ship Cooperative 3D Object Detection. Electronics, 13(5), 885. https://doi.org/10.3390/electronics13050885