
Real-Time Object Detection and Tracking Based on Embedded Edge Devices for Local Dynamic Map Generation



Abstract

1. Introduction
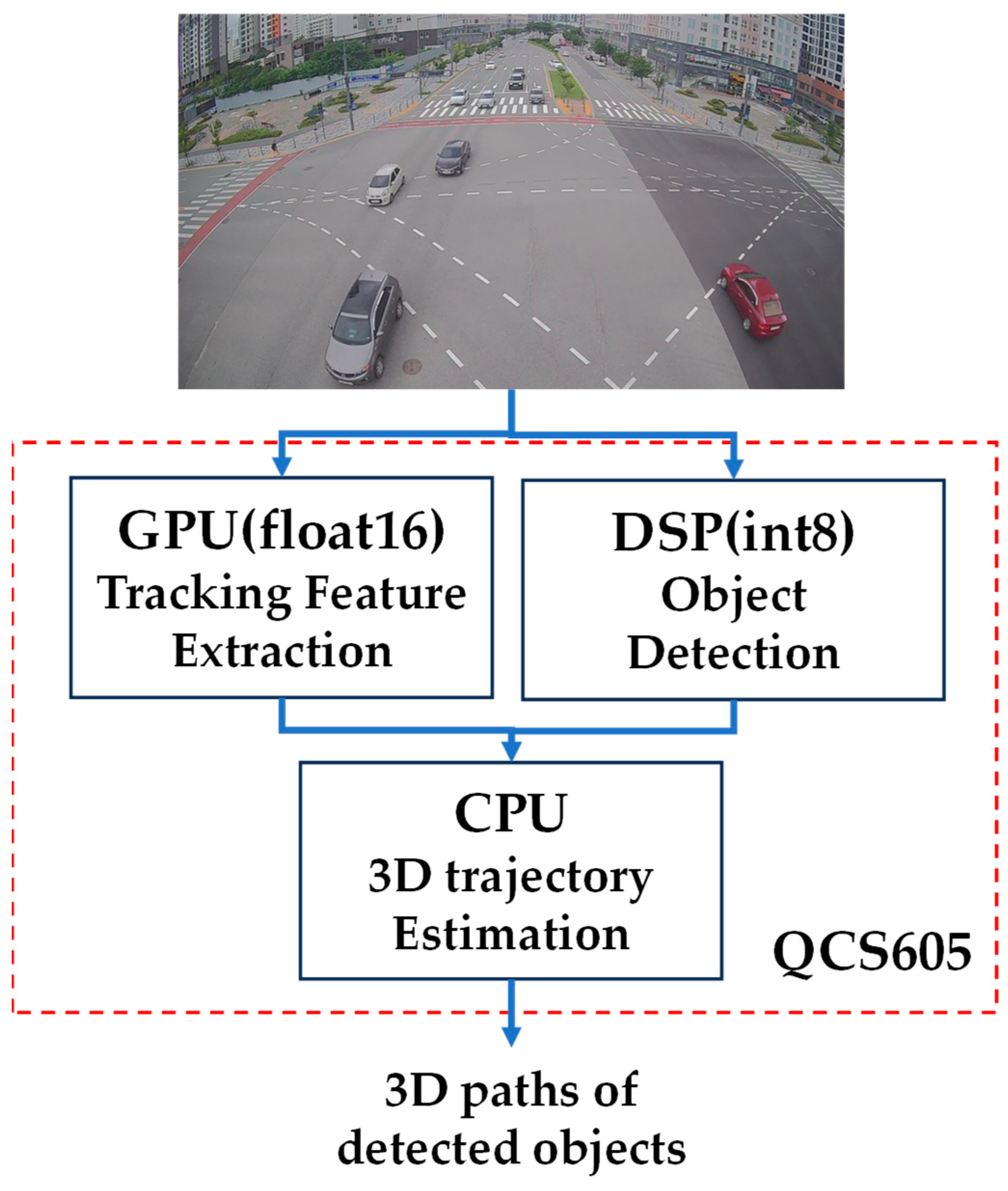
2. Overview of the Proposed Camera System
2.1. Hardware Overview
2.2. Software Overview
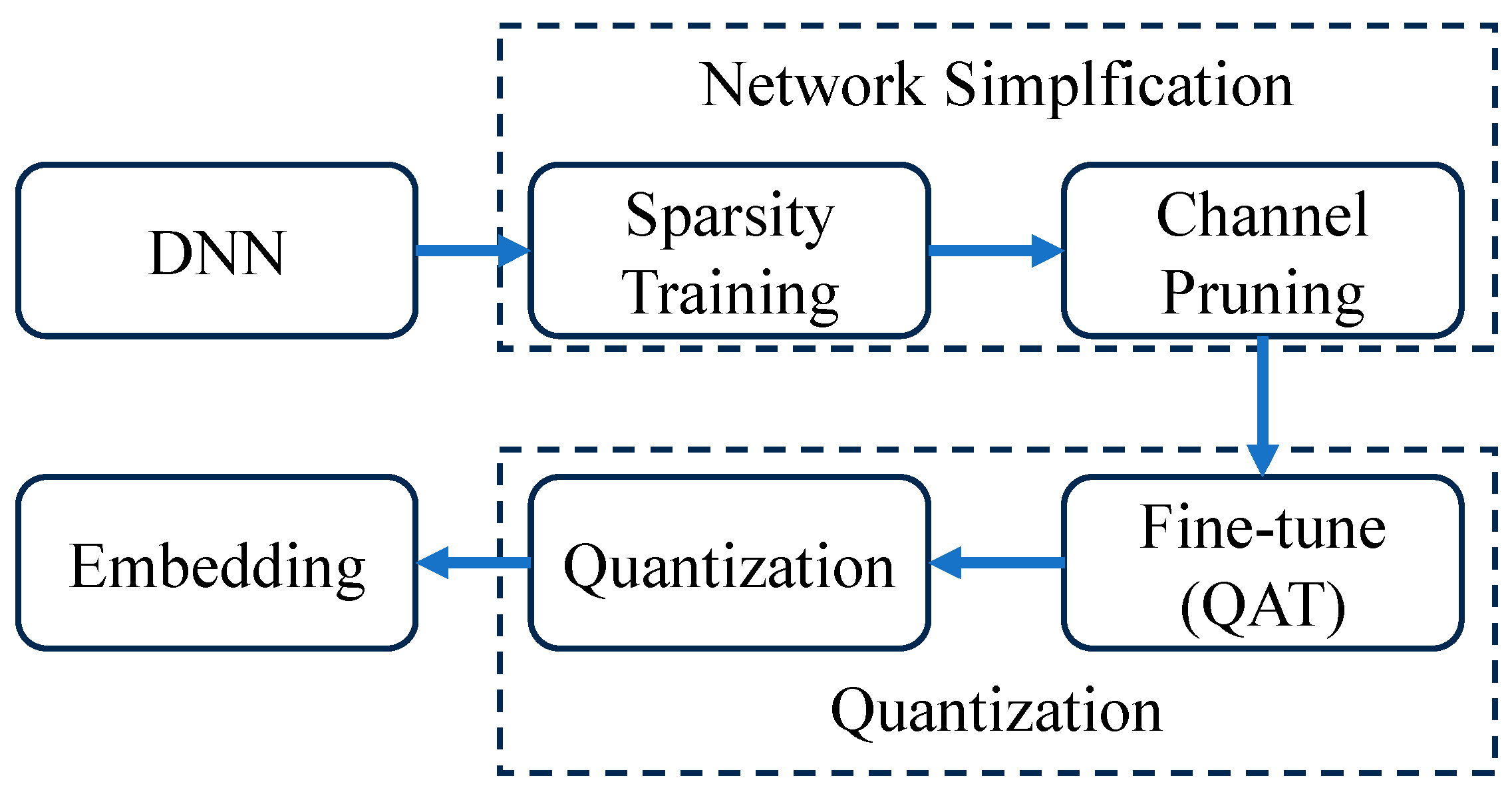
3. Object Detection Network on DSP
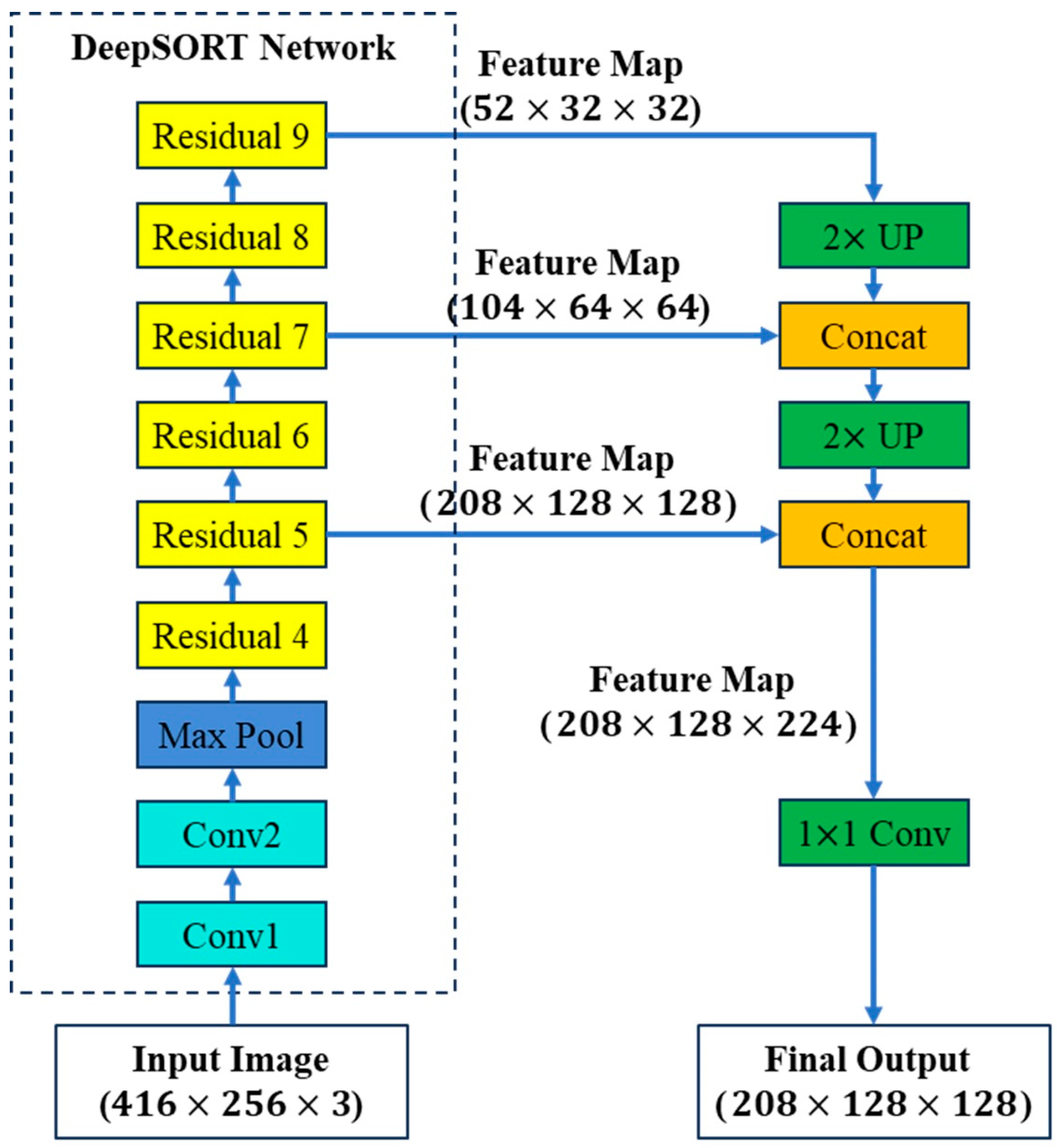
4. Tracking Feature Extraction Network on GPU
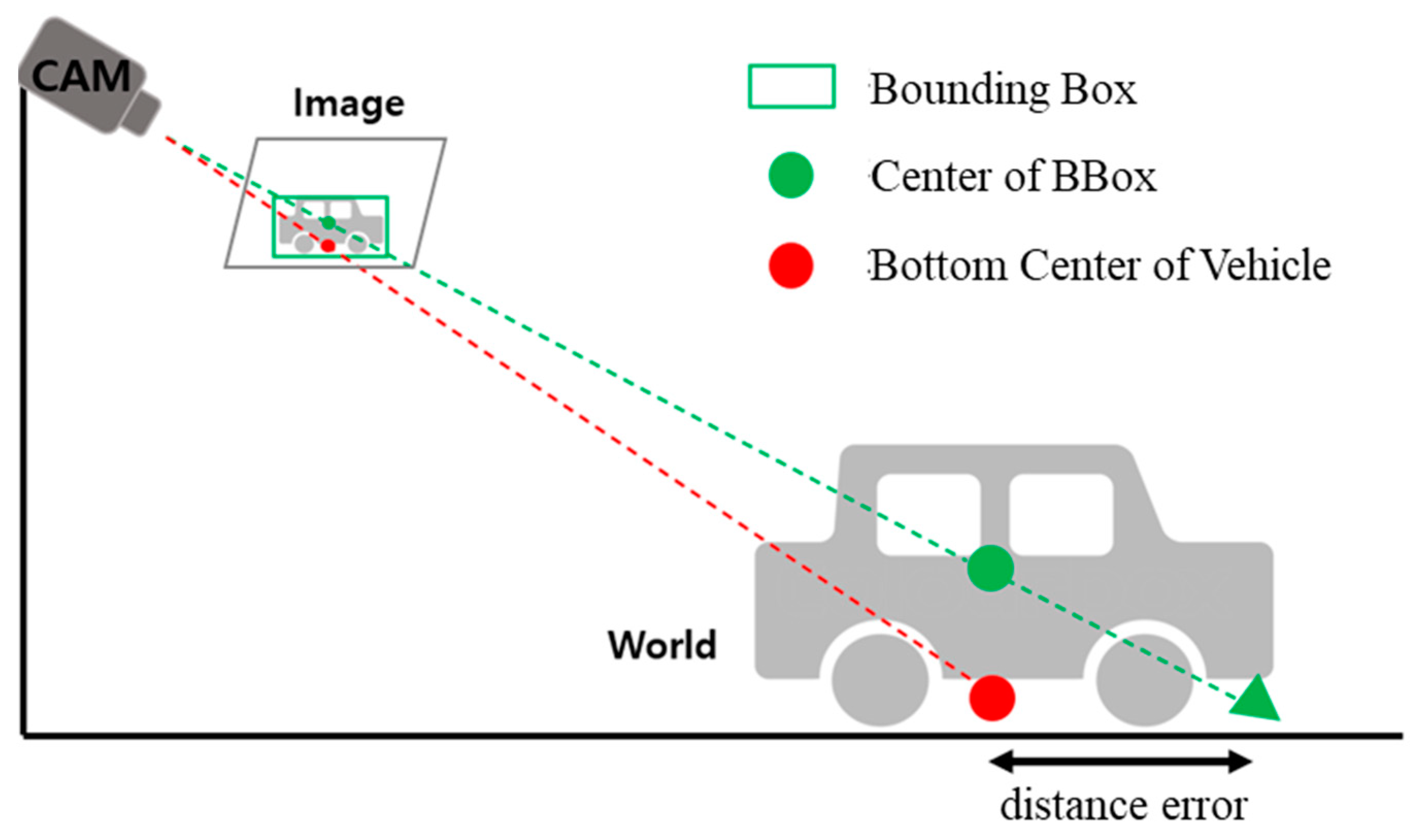
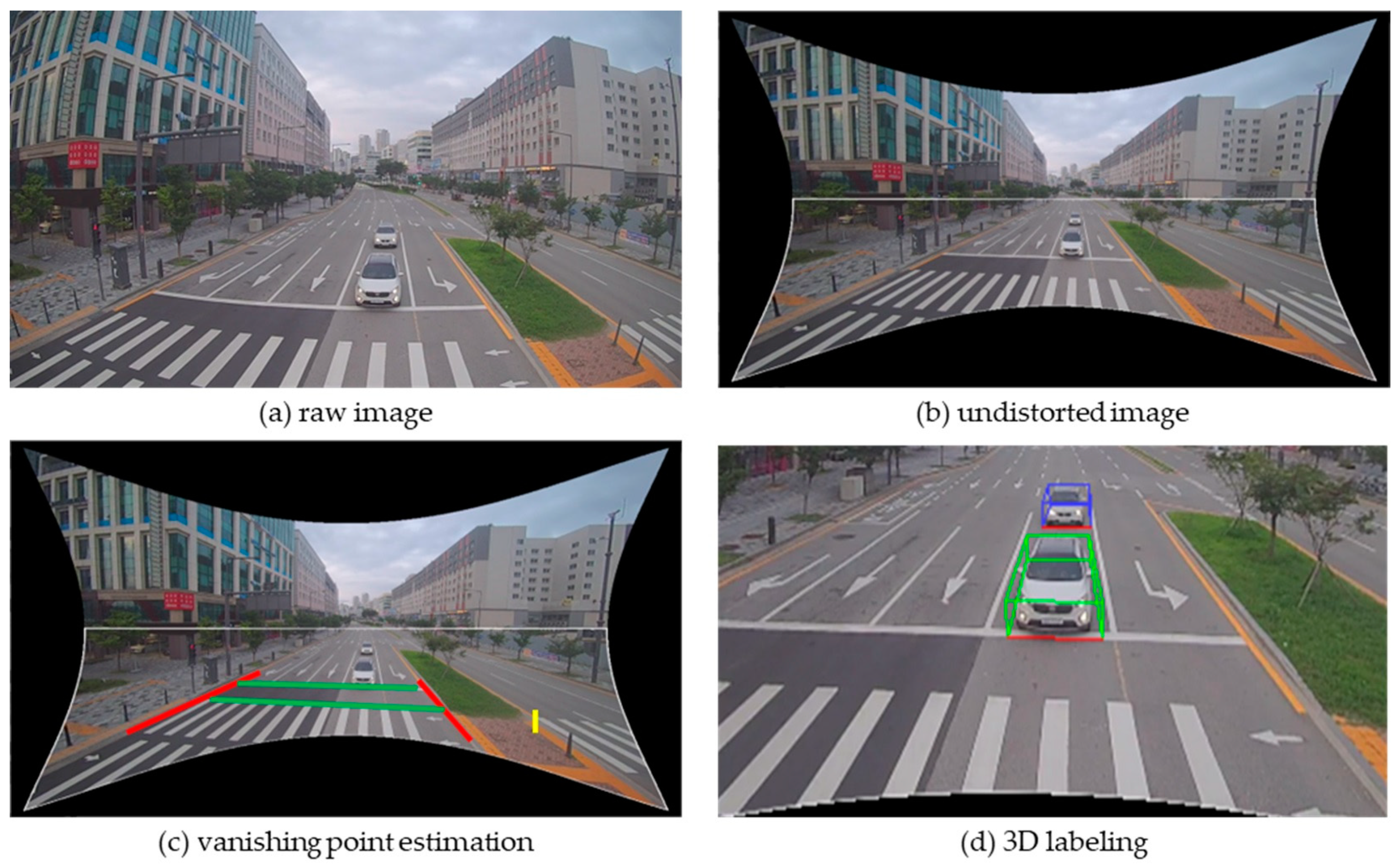
5. Three-dimensional Trajectory Estimation on CPU
6. Experimental Results
6.1. Detector Performance Evaluation
6.2. Tracker Performance Evaluation
7. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- TR 102 863—V1.1.1; Intelligent Transport Systems (ITS); Vehicular Communications; Basic Set of Applications; Local Dynamic Map (LDM); Rationale for and Guidance on Standardization. ETSI: Sophia Antipolis, France, 2011.
- Damerow, F.; Puphal, T.; Flade, B.; Li, Y.; Eggert, J. Intersection Warning System for Occlusion Risks Using Relational Local Dynamic Maps. IEEE Intell. Transp. Syst. Mag. 2018, 10, 47–59. [Google Scholar] [CrossRef]
- Carletti, C.M.R.; Raviglione, F.; Casetti, C.; Stoffella, F.; Yilma, G.M.; Visintainer, F.; Risma Carletti, C.M. S-LDM: Server Local Dynamic Map for 5G-Based Centralized Enhanced Collective Perception. SSRN 2023. [Google Scholar] [CrossRef]
- Qualcomm QCS605 SoC|Next-Gen 8-Core IoT & Smart Camera Chipset|Qualcomm. Available online: https://www.qualcomm.com/products/technology/processors/application-processors/qcs605 (accessed on 29 September 2022).
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A Survey of Modern Deep Learning Based Object Detection Models. Digit. Signal Process. 2021, 126, 103514. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020. [Google Scholar] [CrossRef]
- Choi, K.; Wi, S.M.; Jung, H.G.; Suhr, J.K. Simplification of Deep Neural Network-Based Object Detector for Real-Time Edge Computing. Sensors 2023, 23, 3777. [Google Scholar] [CrossRef] [PubMed]
- Wojke, N.; Bewley, A.; Paulus, D. Simple Online and Realtime Tracking with a Deep Association Metric. arXiv 2017. [Google Scholar] [CrossRef]
- Kim, G.; Jung, H.G.; Suhr, J.K. CNN-Based Vehicle Bottom Face Quadrilateral Detection Using Surveillance Cameras for Intelligent Transportation Systems. Sensors 2023, 23, 6688. [Google Scholar] [CrossRef] [PubMed]
- Caprile, B.; Torre, V. Using Vanishing Points for Camera Calibration; Springer: Berlin/Heidelberg, Germany, 1990; Volume 4. [Google Scholar]
- RoadGaze Hardware Specification. Available online: http://withrobot.com/en/ai-camera/roadgaze/ (accessed on 2 February 2024).
- MIPI CSI-2. Available online: https://www.mipi.org/specifications/csi-2 (accessed on 2 February 2024).
- Yurdusev, A.A.; Adem, K.; Hekim, M. Detection and Classification of Microcalcifications in Mammograms Images Using Difference Filter and Yolov4 Deep Learning Model. Biomed. Signal Process. Control 2023, 80, 104360. [Google Scholar] [CrossRef]
- Dlamini, S.; Chen, Y.-H.; Jeffrey Kuo, C.-F. Complete Fully Automatic Detection, Segmentation and 3D Reconstruction of Tumor Volume for Non-Small Cell Lung Cancer Using YOLOv4 and Region-Based Active Contour Model. Expert Syst. Appl. 2023, 212, 118661. [Google Scholar] [CrossRef]
- YOLOv4. Available online: https://docs.nvidia.com/tao/tao-toolkit/text/object_detection/yolo_v4.html (accessed on 6 March 2023).
- Getting Started with YOLO V4. Available online: https://www.mathworks.com/help/vision/ug/getting-started-with-yolo-v4.html (accessed on 16 February 2024).
- Zhang, B.; Zhang, J. A Traffic Surveillance System for Obtaining Comprehensive Information of the Passing Vehicles Based on Instance Segmentation. IEEE Trans. Intell. Transp. Syst. 2021, 22, 7040–7055. [Google Scholar] [CrossRef]
- Mauri, A.; Khemmar, R.; Decoux, B.; Haddad, M.; Boutteau, R. Real-Time 3D Multi-Object Detection and Localization Based on Deep Learning for Road and Railway Smart Mobility. J. Imaging 2021, 7, 145. [Google Scholar] [CrossRef] [PubMed]
- Li, P. RTM3D: Real-Time Monocular 3D Detection from Object Keypoints for Autonomous Driving. arXiv 2020. [Google Scholar] [CrossRef]
- Zhu, M.; Zhang, S.; Zhong, Y.; Lu, P.; Peng, H.; Lenneman, J. Monocular 3D Vehicle Detection Using Uncalibrated Traffic Cameras through Homography. arXiv 2021. [Google Scholar] [CrossRef]
- Kannala, J.; Brandt, S.S. A Generic Camera Model and Calibration Method for Conventional, Wide-Angle, and Fish-Eye Lenses. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1335–1340. [Google Scholar] [CrossRef] [PubMed]
- Bouguet, J.-Y. Complete Camera Calibration Toolbox for Matlab. In Jean-Yves Bouguet’s Homepage; 1999; Available online: http://robots.stanford.edu/cs223b04/JeanYvesCalib/ (accessed on 1 January 2024).
- Cipolla, R.; Drummond, T.; Robertson, D. Camera Calibration from Vanishing Points in Image OfArchitectural Scenes. In Proceedings of the 1999 British Machine Vision Conference, Nottingham, UK, 1 January 1999. [Google Scholar]
- Li, N.; Pan, Y.; Chen, Y.; Ding, Z.; Zhao, D.; Xu, Z. Heuristic Rank Selection with Progressively Searching Tensor Ring Network. arXiv 2020. [Google Scholar] [CrossRef]
- Yin, M.; Sui, Y.; Liao, S.; Yuan, B. Towards Efficient Tensor Decomposition-Based DNN Model Compression with Optimization Framework. arXiv 2021. [Google Scholar] [CrossRef]
- Liang, T.; Glossner, J.; Wang, L.; Shi, S.; Zhang, X. Pruning and Quantization for Deep Neural Network Acceleration: A Survey. arXiv 2021. [Google Scholar] [CrossRef]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning Efficient Convolutional Networks through Network Slimming. arXiv 2017. [Google Scholar] [CrossRef]
- Masana, M.; Van De Weijer, J.; Herranz, L.; Bagdanov, A.D.; Alvarez, J.M. Domain-Adaptive Deep Network Compression. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yang, J.; Zou, H.; Cao, S.; Chen, Z.; Xie, L. MobileDA: Toward Edge-Domain Adaptation. IEEE Internet Things J. 2020, 7, 6909–6918. [Google Scholar] [CrossRef]
- Liu, C.; Zoph, B.; Neumann, M.; Shlens, J.; Hua, W.; Li, L.-J.; Fei-Fei, L.; Yuille, A.; Huang, J.; Murphy, K. Progressive Neural Architecture Search. arXiv 2017. [Google Scholar] [CrossRef]
- White, C.; Neiswanger, W.; Savani, Y. BANANAS: Bayesian Optimization with Neural Architectures for Neural Architecture Search. arXiv 2019. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple Online and Realtime Tracking. arXiv 2016. [Google Scholar] [CrossRef]
- Ondrasovic, M.; Tarabek, P. Siamese Visual Object Tracking: A Survey. IEEE Access 2021, 9, 110149–110172. [Google Scholar] [CrossRef]
- Chen, F.; Wang, X.; Zhao, Y.; Lv, S.; Niu, X. Visual Object Tracking: A Survey. Comput. Vis. Image Underst. 2022, 222, 103508. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A. Deep Cosine Metric Learning for Person Re-Identification. arXiv 2018. [Google Scholar] [CrossRef]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Ling, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The Vision Meets Drone Object Detection in Image Challenge Results. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. arXiv 2019. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2016. [Google Scholar] [CrossRef]
- Triki, N.; Ksantini, M.; Karray, M. Traffic Sign Recognition System Based on Belief Functions Theory. In Proceedings of the ICAART 2021—13th International Conference on Agents and Artificial Intelligence, Virtual Event, 4–6 February 2021; SciTePress: Setúbal, Portugal, 2021; Volume 2, pp. 775–780. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Major Components | Items | Specification |
|---|---|---|
| Main Board | QCS605 | CPU: Kyro 300: 64 bit-8 cores, up 2.5 GHz |
| DSP: 2 Hexagon Vector Processor, Hexagon 685 | ||
| GPU: Adreno 615 | ||
| Memory | 4 GB LPDDR4, eMMC 64 GB | |
| OS | Android | |
| Size | ||
| Carrier Board | Interface | Exterior: Ethernet, Camera: MIPI |
| Power | 15 w (PoE or DC Adaptor) | |
| Data Transfer | CODEC: H.264 Protocol: RTSP | |
| Size | ||
| Camera | Sensor | Sony IMX334(CMOS) M12 Mount, Rolling shutter |
| FOV | 34.4°~128° | |
| Resolution |
| Network | Dataset | Input Size | mAP (%) | BFLOPs |
|---|---|---|---|---|
| YOLOv4 | Visdrone2019-Det | 20.62 | 59.75 | |
| SCOD | 86.69 | 36.79 | ||
| Modified YOLOv4 | Visdrone2019-Det | 25.79 | 63.77 | |
| SCOD | 89.47 | 39.22 |
| Dataset | Pruning Rate (%) | mAP (%) | Parameter | BFLOPs |
|---|---|---|---|---|
| Visdrone2019-Det | 0 | 25.79 | 48.0 M | 63.77 |
| 50 | 27.38 | 15.1 M | 38.45 | |
| 70 | 26.99 | 6.49 M | 27.28 | |
| SCOD | 0 | 89.47 | 48.0 M | 39.22 |
| 50 | 89.98 | 12.7 M | 19.25 | |
| 70 | 89.56 | 6.48 M | 13.23 |
| DB | FOV | Sequences ID | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | Total | ||
| Train | N | 810 (11) | 690 (12) | 1020 (7) | 930 (12) | 780 (8) | 900 (10) | 611 (8) | 5741 (68) | ||||||
| W | 990 (30) | 1020 (25) | 630 (26) | 899 (22) | 659 (20) | 990 (33) | 5098 (156) | ||||||||
| Test | N | 1080 (7) | 900 (7) | 509 (4) | 604 (10) | 795 (19) | 695 (7) | 4583 (54) | |||||||
| W | 630 (15) | 900 (22) | 660 (17) | 450 (15) | 2640 (69) | ||||||||||
| Tracker | NFOV Sequences | WFOV Sequences | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MOTA (%) | FN | FP | IDsw | BFLOPs | MOTA (%) | FN | FP | IDsw | BFLOPs | |
| DeepSORT | 41.24 | 2688 | 1885 | 56 | 0.59 x N | 87.04 | 277 | 361 | 21 | 1.18 x N |
| Modified DeepSORT | 41.54 | 2726 | 1817 | 62 | 10.66 | 87.35 | 271 | 358 | 14 | 10.66 |
| Pruning Rate | BFLOPs | NFOV Sequences | WFOV Sequences | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MOTA (%) | FN | FP | IDsw | MOTA (%) | FN | FP | IDsw | ||
| 0 | 10.66 | 41.54 | 2726 | 1817 | 62 | 87.35 | 271 | 358 | 14 |
| 50 | 4.32 | 39.74 | 2772 | 1913 | 62 | 87.49 | 264 | 349 | 23 |
| 70 | 2.99 | 40.73 | 2879 | 1732 | 58 | 87.37 | 263 | 360 | 19 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, K.; Moon, J.; Jung, H.G.; Suhr, J.K. Real-Time Object Detection and Tracking Based on Embedded Edge Devices for Local Dynamic Map Generation. Electronics 2024, 13, 811. https://doi.org/10.3390/electronics13050811
Choi K, Moon J, Jung HG, Suhr JK. Real-Time Object Detection and Tracking Based on Embedded Edge Devices for Local Dynamic Map Generation. Electronics. 2024; 13(5):811. https://doi.org/10.3390/electronics13050811
Chicago/Turabian StyleChoi, Kyoungtaek, Jongwon Moon, Ho Gi Jung, and Jae Kyu Suhr. 2024. "Real-Time Object Detection and Tracking Based on Embedded Edge Devices for Local Dynamic Map Generation" Electronics 13, no. 5: 811. https://doi.org/10.3390/electronics13050811
APA StyleChoi, K., Moon, J., Jung, H. G., & Suhr, J. K. (2024). Real-Time Object Detection and Tracking Based on Embedded Edge Devices for Local Dynamic Map Generation. Electronics, 13(5), 811. https://doi.org/10.3390/electronics13050811