

Statement-Grained Hierarchy Enhanced Code Summarization


Abstract
1. Introduction
- We are the first to explore the use of a statement-grained hierarchy graph for the extraction of global hierarchical structural properties. This graph is integrated with the code token sequence to represent code semantics for source code summarization.
- We propose a novel model, SHT, which incorporates the statement-grained hierarchy graph and token sequence to generate code summaries. This model uniquely combines two encoders for sequence and graph learning within the Transformer framework.
- Our approach is evaluated on two source code summarization benchmark datasets against baseline models, surpassing previous works and achieving new state-of-the-art results. Additionally, the ablation study and human evaluation further validate our strategy for code comprehension in code summarization.
2. Background
2.1. Transformer
2.2. Self-Attention
2.3. Relation-Aware Self-Attention
3. Problem Formulation
4. Proposed Approach
4.1. Data Processing
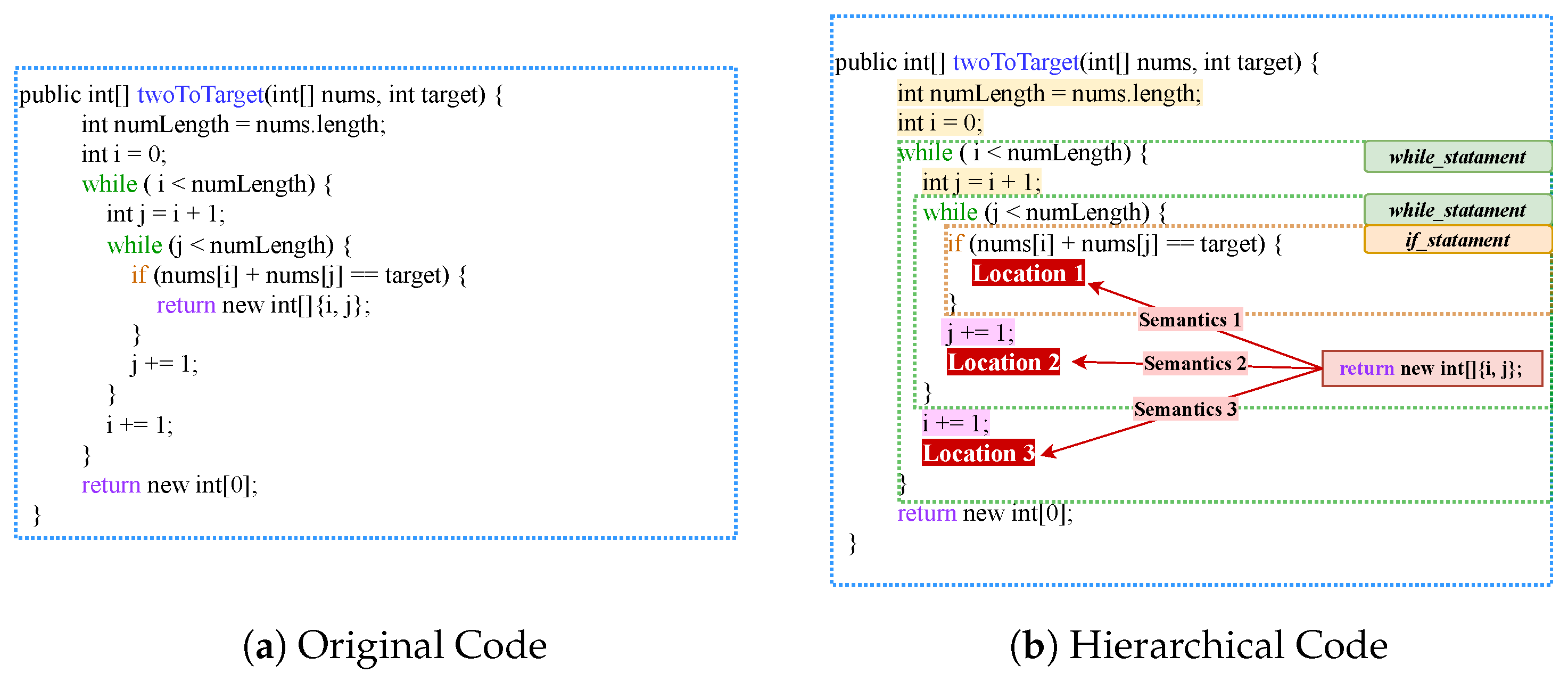
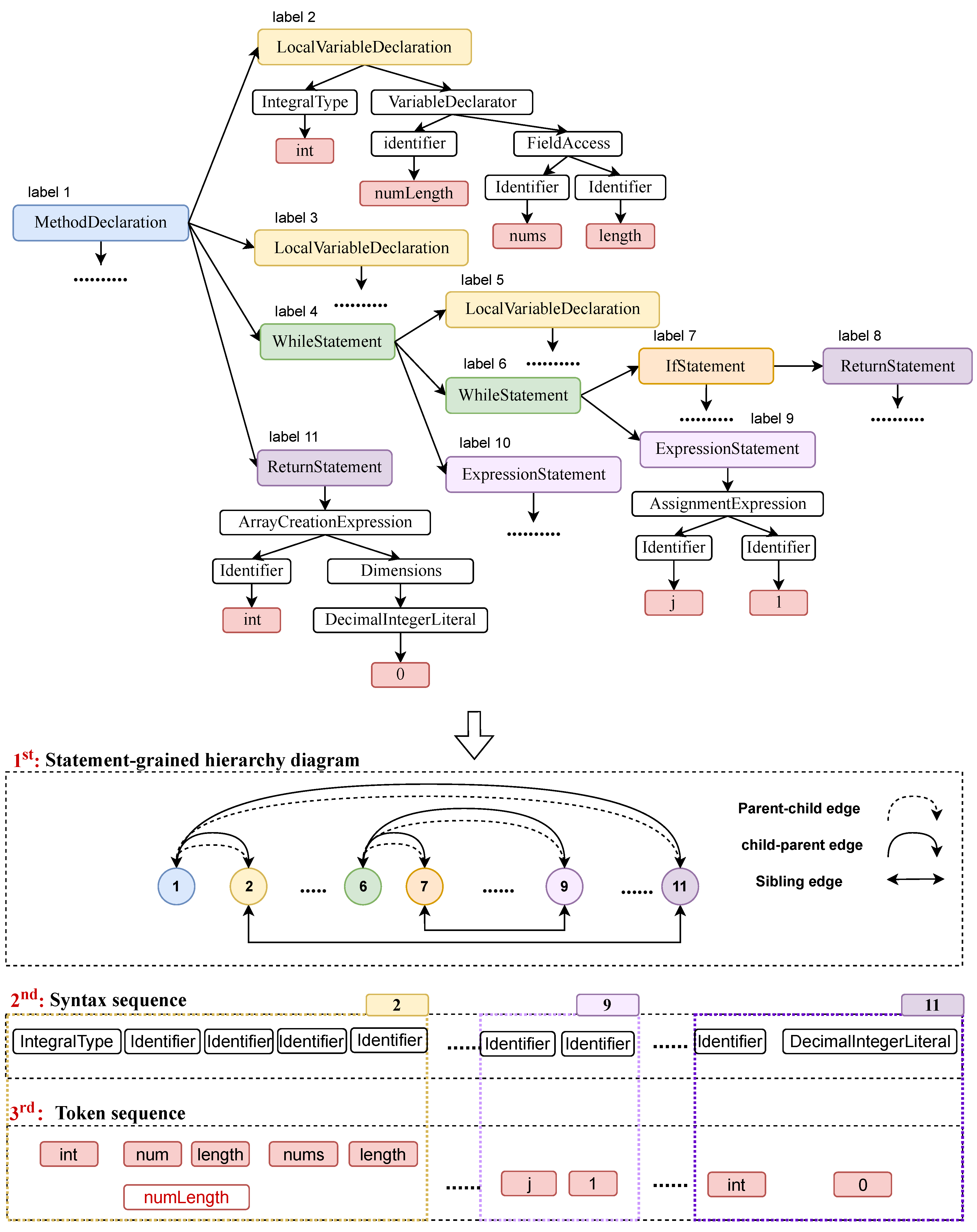
4.1.1. Construction of Statement-Grained Hierarchical Graph
4.1.2. Construction of Token and Syntax Sequences
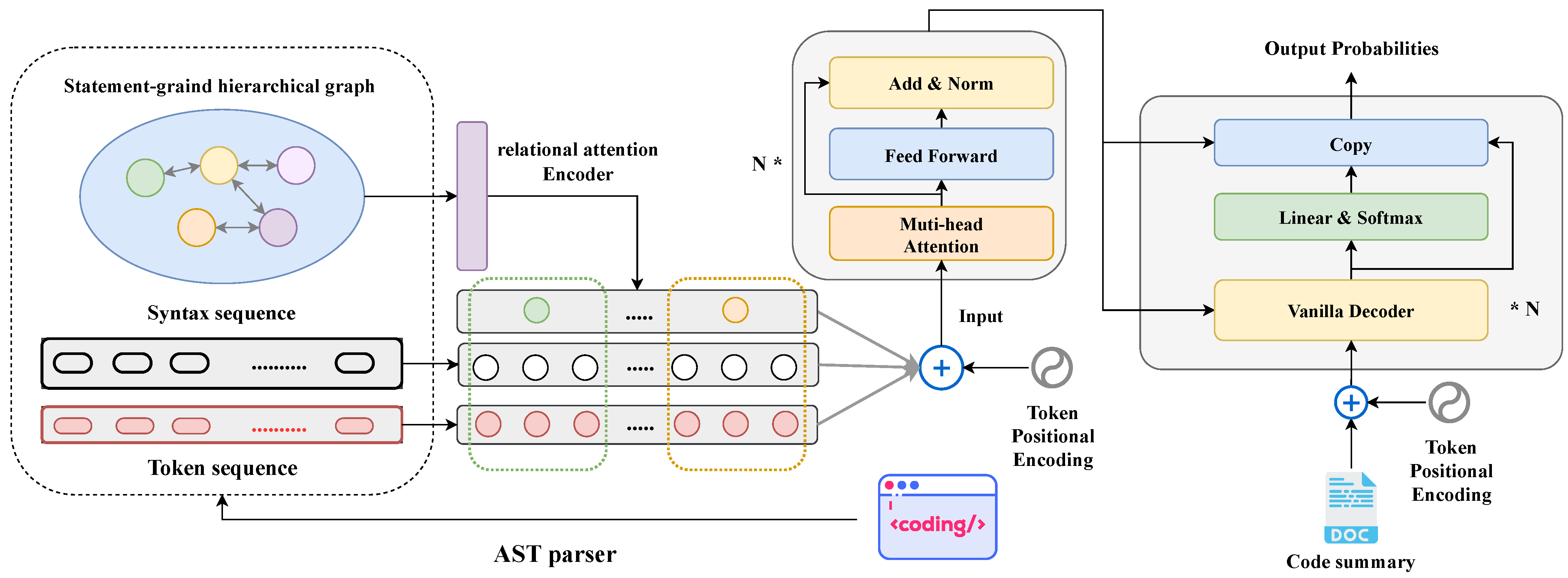
4.2. Statement-Grained Hierarchy Transformer
4.2.1. Relational Attention-Based Hierarchical Graph Encoder
4.2.2. Sequence Encoder
4.2.3. Decoder with Copy Machine
5. Experiment
5.1. Experiment Setup
Evaluation Datasets
5.2. Metrics
- BLEU calculates the n-gram precision overlap between two texts, serving as an accuracy measure. It indicates the proportion of generated text that corresponds to the reference text.
- METEOR, a recall-oriented metric, reflects the percentage of correctly generated content in comparison to the reference summary.
- ROUGE-L quantifies the longest common subsequence (LCS) between the reference and the generated code summary. It serves as a recall metric and provides additional insights not captured by the BLEU scores alone.
5.3. Comparison Baselines
- CODE-NN [5]: the first data-driven source code summarization model. It views source code as a sequential text and utilizes LSTM, a sequential model for the generation of source code summaries.
- HDeepCom [29]: a neural machine translation (NMT)-based code summarization model that converts the AST into a sequence by employing a structure-based traversal (SBT) method. It then feeds this sequence into a sequence-to-sequence model for comment generation.
- ASTattGRU [35]: this is a dual learning framework that jointly trains code summarization and code generation tasks, aiming to enhance both aspects simultaneously.
- NeuralCodeSum [6]: this is a Transformer-based code summarization model that leverages relative position information among code tokens to enhance the summary generation process.
- CAST [26]: this is a hybrid code summarization model that combines a tree-based Recursive Variational Neural Network (RvNN) and a basic code token encoder to capture both the code structure and sequence. It incorporates a hybrid mechanism in the decoding phase to combine inputs for the generation of descriptive summaries.
- TPTrans [36]: a Transformer-based code summarization model that captures the pairwise path information in the AST and integrates path encodings in the Transformer for concise summary generation.
5.4. Parameter Configurations
5.5. Main Results
5.5.1. Comparisons with Baselines
5.5.2. Ablation Study
5.5.3. Human Evaluation
5.5.4. Qualitative Analysis
6. Related Work
7. Limitations
- Dataset limitations: While numerous public datasets are available for the code summarization task, our model evaluation was confined to only two public Java datasets. Consequently, these datasets may not fully represent other programming languages, potentially limiting the scalability of our model. In future work, we plan to experiment with more large-scale datasets encompassing diverse programming languages. We anticipate that our model could be extended to other languages capable of being parsed into ASTs with minimal adaptation.
- Hyperparameter settings in deep learning: The configuration of the dimensions plays a pivotal role in influencing the outcomes of a deep learning model. We conducted a limited-range grid search focusing on the learning rate and batch size to optimize our model’s performance. To mitigate the impact of varying hyperparameter settings among baseline models, we compared our performance against the best results reported in previous works for these baselines.
- Biases of human evaluation: We incorporated human evaluation by inviting five participants to assess the quality of 50 code–summary pairs, selected randomly. It is important to acknowledge that the outcomes of human annotations can be influenced by various factors, including the participants’ programming experience and their comprehension of the evaluation criteria. Recognizing this potential for bias, future iterations of our study will seek to involve a larger number of skilled software developers for the evaluation of an expanded set of code–summary pairs. Additionally, to further enhance the reliability of our findings, each code–summary pair will be reviewed by a minimum of five participants.
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wan, Y.; Zhao, Z.; Yang, M.; Xu, G.; Ying, H.; Wu, J.; Yu, P.S. Improving automatic source code summarization via deep reinforcement learning. In Proceedings of the Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, 3–7 September 2018; pp. 397–407. [Google Scholar]
- Xia, X.; Bao, L.; Lo, D.; Xing, Z.; Hassan, A.E.; Li, S. Measuring program comprehension: A large-scale field study with professionals. IEEE Trans. Softw. Eng. 2017, 44, 951–976. [Google Scholar] [CrossRef]
- Stapleton, S.; Gambhir, Y.; LeClair, A.; Eberhart, Z.; Weimer, W.; Leach, K.; Huang, Y. A human study of comprehension and code summarization. In Proceedings of the 28th International Conference on Program Comprehension, Seoul, Republic of Korea, 13–15 July 2020; pp. 2–13. [Google Scholar]
- Liu, S.; Chen, Y.; Xie, X.; Siow, J.; Liu, Y. Retrieval-augmented generation for code summarization via hybrid gnn. arXiv 2020, arXiv:2006.05405. [Google Scholar]
- Iyer, S.; Konstas, I.; Cheung, A.; Zettlemoyer, L. Summarizing source code using a neural attention model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 2073–2083. [Google Scholar]
- Ahmad, W.U.; Chakraborty, S.; Ray, B.; Chang, K.W. A transformer-based approach for source code summarization. arXiv 2020, arXiv:2005.00653. [Google Scholar]
- Allamanis, M.; Barr, E.T.; Devanbu, P.; Sutton, C. A survey of machine learning for big code and naturalness. ACM Comput. Surv. CSUR 2018, 51, 1–37. [Google Scholar] [CrossRef]
- Shido, Y.; Kobayashi, Y.; Yamamoto, A.; Miyamoto, A.; Matsumura, T. Automatic source code summarization with extended tree-lstm. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Harer, J.; Reale, C.; Chin, P. Tree-transformer: A transformer-based method for correction of tree-structured data. arXiv 2019, arXiv:1908.00449. [Google Scholar]
- Hu, X.; Li, G.; Xia, X.; Lo, D.; Jin, Z. Deep code comment generation. In Proceedings of the 26th Conference on Program Comprehension, Gothenburg, Sweden, 27 May–3 June 2018; pp. 200–210. [Google Scholar]
- Alon, U.; Brody, S.; Levy, O.; Yahav, E. code2seq: Generating sequences from structured representations of code. arXiv 2018, arXiv:1808.01400. [Google Scholar]
- Allamanis, M.; Brockschmidt, M.; Khademi, M. Learning to represent programs with graphs. arXiv 2017, arXiv:1711.00740. [Google Scholar]
- Fernandes, P.; Allamanis, M.; Brockschmidt, M. Structured neural summarization. arXiv 2018, arXiv:1811.01824. [Google Scholar]
- Cheng, J.; Fostiropoulos, I.; Boehm, B. GN-Transformer: Fusing Sequence and Graph Representation for Improved Code Summarization. arXiv 2021, arXiv:2111.08874. [Google Scholar]
- Hellendoorn, V.J.; Sutton, C.; Singh, R.; Maniatis, P.; Bieber, D. Global relational models of source code. In Proceedings of the International Conference on Learning Representations, New Orleans, LO, USA, 6–9 May 2019. [Google Scholar]
- Zügner, D.; Kirschstein, T.; Catasta, M.; Leskovec, J.; Günnemann, S. Language-agnostic representation learning of source code from structure and context. arXiv 2021, arXiv:2103.11318. [Google Scholar]
- Zhang, K.; Li, Z.; Jin, Z.; Li, G. Implant Global and Local Hierarchy Information to Sequence based Code Representation Models. arXiv 2023, arXiv:2303.07826. [Google Scholar]
- Kitaev, N.; Klein, D. Constituency parsing with a self-attentive encoder. arXiv 2018, arXiv:1805.01052. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Song, K.; Wang, K.; Yu, H.; Zhang, Y.; Huang, Z.; Luo, W.; Duan, X.; Zhang, M. Alignment-enhanced transformer for constraining nmt with pre-specified translations. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8886–8893. [Google Scholar]
- Zhao, X.; Wang, L.; He, R.; Yang, T.; Chang, J.; Wang, R. Multiple knowledge syncretic transformer for natural dialogue generation. In Proceedings of the The Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 752–762. [Google Scholar]
- Tang, Z.; Shen, X.; Li, C.; Ge, J.; Huang, L.; Zhu, Z.; Luo, B. AST-trans: Code summarization with efficient tree-structured attention. In Proceedings of the 44th International Conference on Software Engineering, Pittsburgh, PA, USA, 25–27 May 2022; pp. 150–162. [Google Scholar]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-attention with relative position representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Diao, C.; Loynd, R. Relational attention: Generalizing transformers for graph-structured tasks. arXiv 2022, arXiv:2210.05062. [Google Scholar]
- Chai, L.; Li, M. Pyramid Attention For Source Code Summarization. Adv. Neural Inf. Process. Syst. 2022, 35, 20421–20433. [Google Scholar]
- Shi, E.; Wang, Y.; Du, L.; Zhang, H.; Han, S.; Zhang, D.; Sun, H. Cast: Enhancing code summarization with hierarchical splitting and reconstruction of abstract syntax trees. arXiv 2021, arXiv:2108.12987. [Google Scholar]
- Vinyals, O.; Fortunato, M.; Jaitly, N. Pointer networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar]
- Hu, X.; Li, G.; Xia, X.; Lo, D.; Lu, S.; Jin, Z. Summarizing source code with transferred api knowledge. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI-18, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Hu, X.; Li, G.; Xia, X.; Lo, D.; Jin, Z. Deep code comment generation with hybrid lexical and syntactical information. Empir. Softw. Eng. 2020, 25, 2179–2217. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Text Summarization Branches Out; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004; pp. 74–81. [Google Scholar]
- Liu, Z.; Xia, X.; Treude, C.; Lo, D.; Li, S. Automatic generation of pull request descriptions. In Proceedings of the 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), San Diego, CA, USA, 10–15 November 2019; pp. 176–188. [Google Scholar]
- Nie, L.Y.; Gao, C.; Zhong, Z.; Lam, W.; Liu, Y.; Xu, Z. Coregen: Contextualized code representation learning for commit message generation. Neurocomputing 2021, 459, 97–107. [Google Scholar] [CrossRef]
- LeClair, A.; Haque, S.; Wu, L.; McMillan, C. Improved code summarization via a graph neural network. In Proceedings of the 28th International Conference on Program Comprehension, Seoul, Republic of Korea, 13–15 July 2020; pp. 184–195. [Google Scholar]
- Peng, H.; Li, G.; Wang, W.; Zhao, Y.; Jin, Z. Integrating tree path in transformer for code representation. Adv. Neural Inf. Process. Syst. 2021, 34, 9343–9354. [Google Scholar]
- Libovickỳ, J.; Helcl, J.; Mareček, D. Input combination strategies for multi-source transformer decoder. arXiv 2018, arXiv:1811.04716. [Google Scholar]
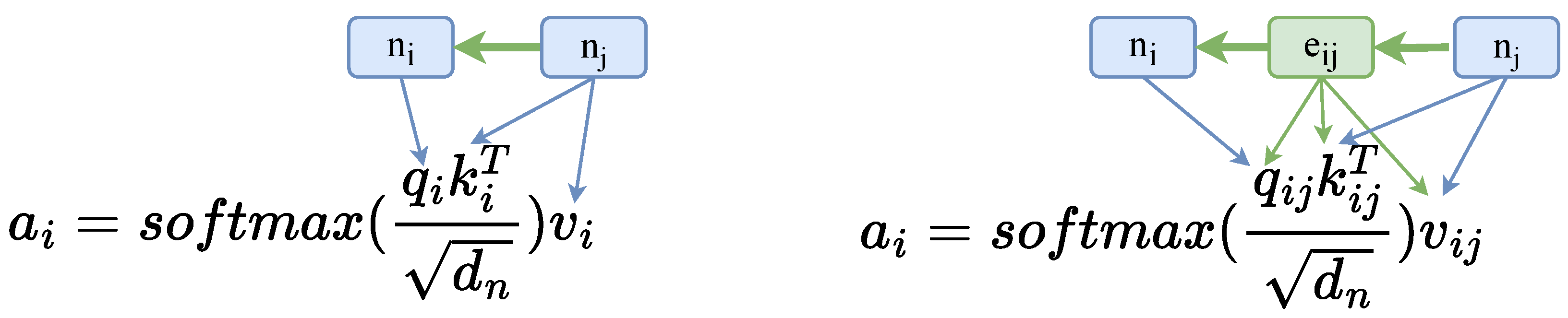

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | TL-CodeSum | EMSE-Deepcom |
|---|---|---|
| #train | 66,928 | 283,741 |
| #validation | 8366 | 12,226 |
| #test | 8366 | 12,226 |
| #/Avg.# tokens in code | 20,162/120.10 | 47,939/93.93 |
| #/Avg.# tokens in summary | 25,619/17.76 | 26,145/11.24 |
| Approaches | Input | Backbone | TL-CodeSum | EMSE-Deepcom | ||||
|---|---|---|---|---|---|---|---|---|
| BLEU | ROUGE-L | METEOR | BLEU | ROUGE-L | METEOR | |||
| CodeNN [5] | Code | LSTM | 22.22 | 33.14 | 14.08 | 28.45 | 43.51 | 17.89 |
| HDeepcom [29] | AST | GRU | 23.32 | 33.94 | 13.76 | 32.19 | 49.03 | 21.53 |
| ASTattGRU [35] | AST | GRU | 30.78 | 39.94 | 17.35 | 33.40 | 49.76 | 22.20 |
| NeuralCodeSum [6] | Code | Transformer | 40.63 | 52.00 | 24.85 | 37.13 | 54.87 | 25.05 |
| CAST [26] | AST | Transformer | 43.76 | 54.09 | 27.15 | 37.19 | 54.87 | 25.07 |
| TPTrans [36] | AST | Transformer | 44.50 | 55.08 | 27.88 | 37.25 | 54.99 | 25.02 |
| SHT | AST | Transformer | 45.76 | 55.70 | 28.22 | 38.85 | 56.02 | 25.90 |
| Approach | BLEU | ROUGE | METEOR |
|---|---|---|---|
| SHT | 45.76 | 55.70 | 28.22 |
| w/o token | 42.33 | 53.27 | 26.89 |
| w/o syntax | 45.38 | 55.03 | 27.63 |
| token-grained hierarchy | 45.08 | 55.17 | 27.90 |
| concatenation | 45.42 | 55.36 | 28.06 |
| Approach | Similarity | Conciseness | Readability |
|---|---|---|---|
| SHT | 3.52 | 3.17 | 3.34 |
| NeuralCodeSum | 2.51 | 2.72 | 2.34 |
| CAST | 3.11 | 2.90 | 2.97 |
| TPTrans | 3.20 | 3.17 | 3.34 |
| Source Code |
| private void sendRemainingParts(Client client, String[] strings){ for(int i = NUM_; i < strings.length; ++i){ client.appendMessage(strings[i]); } } |
| Summaries: |
| Reference: send the remaining parts of a string array to a client |
| SHT: send the remaining elements of a string array to a client |
| SHT w/o syntax: Sends array remaining strings to client |
| token-grained hierarchy: send remaining string array to a client |
| Source Code |
| public boolean containsValue (Object value){ Entry tab [] = table; if(value == null){ for (int i = tab. length; i -- > NUM_ ;) for (Entry e = tab[i]; e! = null; e = e.next) if(e.value == null) return BOOL_; } else { for (int i = tab.length; i -- > NUM_;) for (Entry e = tab[i]; e! = null; e = e.next) if( value.equals (e.value)) return BOOL_; } return BOOL_; } |
| Summaries: |
| Reference: check whether a given value exists in a collection of objects |
| SHT: check whether a given value exists in a collection of objects |
| SHT w/o syntax: search entries for value, returns predefined value |
| token-grained hierarchy: search entries for value, returns predefined value |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Jin, D.; Wang, Y.; Gong, Y. Statement-Grained Hierarchy Enhanced Code Summarization. Electronics 2024, 13, 765. https://doi.org/10.3390/electronics13040765
Zhang Q, Jin D, Wang Y, Gong Y. Statement-Grained Hierarchy Enhanced Code Summarization. Electronics. 2024; 13(4):765. https://doi.org/10.3390/electronics13040765
Chicago/Turabian StyleZhang, Qianjin, Dahai Jin, Yawen Wang, and Yunzhan Gong. 2024. "Statement-Grained Hierarchy Enhanced Code Summarization" Electronics 13, no. 4: 765. https://doi.org/10.3390/electronics13040765
APA StyleZhang, Q., Jin, D., Wang, Y., & Gong, Y. (2024). Statement-Grained Hierarchy Enhanced Code Summarization. Electronics, 13(4), 765. https://doi.org/10.3390/electronics13040765