6.1. Dataset
The educational dataset xAPI was adopted in the experiments.
xPAI [
22] (
https://www.kaggle.com/datasets/aljarah/xAPI-Edu-Data, accessed on 10 November 2023) is a student academic performance dataset collected from a learning management system. It consists of 480 student records. Sixteen features are contained in the dataset, including gender, nationality, place of birth, stage ID, grade ID, section ID, topic, semester, relation, raised hands, visited resources, announcements view, discussion, parent answering survey, parent school satisfaction, and student absence days. The label used in xAPI is ’class’, including three classifications: low-level, middle-level, and high-level.
xAPI contains text data that are hard to process directly with the proposed algorithm. Thus, text data are replaced with numeric data. For example, the feature ’student absence days’ includes two kinds of text data, which are ’under-7 ’ and ’above-7’. Thus, ’under-7’ is replaced by ’1’ and ’above-7’ is replaced by ’0’. Statistical information of the xAPI educational dataset is given in
Table 2. Some statistical information is shown in
Figure 1.
Figure 1a illustrates the distribution of student nationalities. The figure shows that Kuwait and Jordan have the highest representation, with 179 and 172 individuals, respectively.
Figure 1b presents the students’ birthplaces. Kuwait and Jordan, with 180 and 176 individuals, respectively, emerged as the most prevalent birthplaces.
Figure 1c illustrates the distribution of students across different grade levels. The figure indicates that G-02 has the highest number of students, with 147 individuals, while G-01 and G-03 have no students.
Figure 1d showcases the subjects the students are studying, referred to as course topics. The most popular subjects include IT, French, Arabic, Science, and English. The popularity of these subjects may be indicative of students’ interests, future career choices, or the curriculum offered by the school.
Figure 1e displays the frequency of student participation in class by raising their hands. The figure reveals that 90 individuals raised their hands between 10 and 20 times, 80 individuals raised their hands between 70 and 80 times, and 66 individuals raised their hands between 80 and 90 times.
Figure 1f displays the frequency of student access to course content. The figure reveals that 107 students accessed the course content between 80 and 89 times, 76 students accessed it between 90 and 99 times, and 63 students accessed it between 0 and 9 times.
Figure 1g presents the frequency of students viewing new announcements. The figure indicates that 78 students viewed the announcements between 10 and 19 times, 72 students viewed them between 0 and 9 times, and 63 students viewed them between 20 and 29 times.
Figure 1h showcases the frequency of student participation in discussion groups. The figure shows that 77 students participated in discussions between 11 and 20 times, 69 students participated between 31 and 40 times, and 66 students participated between 21 and 30 times.
6.2. Experimental Settings
Using Algorithm 2, a feature selection matrix can be obtained. The feature selection matrix indicates the importance of each feature. By calculating and sorting in descending order, a ranking of the importance of the characteristics can be obtained.
After selecting different numbers for the most important features, the four classifiers K-Nearest neighbors (KNN), decision tree (Dtree), random forest (RF), and support vector machine (SVM) are adopted to measure the performance of the proposed method.
6.2.1. Comparison Methods
To demonstrate the effectiveness of the proposed SFSGLR, three feature selection methods are adopted to compare with SFSGLR, and they are introduced briefly as follows:
Unsupervised discriminate feature selection (UDFS) [
32]: UDFS is a unsupervised feature selection method based on linear discrimination, with a
norm in the feature selection matrix to enhance sparseness.
Non-negative discriminant feature selection (NDFS) [
37]: NDFS is a unsupervised feature selection method based on non-negative spectral analysis and
norm regularization.
Semi-supervised feature selection via rescaled linear regression (SFSRLR) [
35]: This is a semi-supervised feature selection method with linear regression and a
norm.
6.2.2. Classifiers
In this paper, four classification techniques are employed to assess the factors that influenced students’ performance or grade level. The methods used for classification included K-nearest neighbors (KNN), decision tree (Dtree), random forest (RF), and support vector machine (SVM).
K-nearest neighbors (KNN) is an instance-based classification algorithm that determines the class of a new sample based on the distance between the samples [
38]. It selects the nearest
K samples as a reference, and determines the category of the new sample based on the majority voting principle.
The automated rule discovery technique known as decision tree (Dtree) [
39] analyzes and learns from training data, producing a series of branching decisions that classify the data based on the values of different feature attributes.
Random forest (RF) [
40] represents an ensemble learning method that accomplishes classification by constructing numerous decision trees and combining their outcomes. This widely used machine learning algorithm harnesses the diversity and collective knowledge of multiple decision trees to enhance prediction accuracy and robustness. The ultimate classification decision is reached by aggregating the predictions from all individual trees, typically through a majority voting mechanism.
Support vector machine (SVM) [
29] is a binary classification algorithm that aims to find an optimal hyperplane in a high-dimensional feature space, to separate different classes of data points. The key idea is to map the data into a high-dimensional feature space and transform a nonlinear problem into a linearly separable or approximately linearly separable problem.
6.2.3. Evaluation Metrics
Four widely used evaluation metrics are adopted to measure the performance of the classification: accuracy (ACC), Fscore, precision and recall. They are formulated as follows:
where
is the parameter for Fscore and always equals to 1, while TP, TN, FP, and FN denote true negative, true positive, false positive, and false negative, respectively. For all of the four metrics, a larger value means a better performance.
6.3. Student Performance Characteristic Analysis
In the student performance characteristics experiments, the proposed algorithm is adopted to sort the importance of the different features for the students’ academic performance.
Figure 2d shows the ranking of the most important features.
Of all the features, f11 influences the students’ performance most, making up about 30% of the importance. f11 denotes times of visited resources, which means how many times a student visited course contents. Next, f10 and f7 are of equal importance, with each accounting for approximately 15% of the total importance. f10 and f7 represent the number of times a student raises his or her hand in class and course topics, respectively. In addition, it is found that the importance of f1, f14, f8, and f15 are all lower than 1%. Thus, they were not important for the students’ academic performance.
The 16 features have different tendencies and they can be divided into five categories. The first category is personal features, including f1 (gender) and f16 (student absence days). The second category is a social-related category, including f2 (nationality), f3 (place of birth), and f9 (relation). The third category is a school-related category, including f4 (stage ID), f5 (grade ID), f6 (section ID), f7 (topic), and f8 (semester). The fourth is a behavioral category, including f10 (times of raising hands), f11 (times of visiting resources), f12 (times of announcements), and f13 (times of discussions). The fifth is a family-related category, including f14 (parents answering survey) and f15 (student absence days).
The top four most important features are f11, f10, f7, and f12. And the top eight most important features are f11, f10, f7, f12, f5, f6, f13, and f2. This means that all the behavioral characteristics are significant for the student’s performance.
Figure 2 shows a comparison of the student’s performance characteristics ranking with different methods. Differently from the proposed SFSGLR, the importance matrices of the other methods are more sparse. The proposed method adopts the Frobenius norm for the feature selection matrix, while the others adopts the
norm. As
Figure 2 shows, the importance values of most of the features with the comparison methods were close to 0. This is not convenient for comparing the importance between features. With UDFS, the top five most important features are f15 (33.28%), f4 (31.7%), f9 (18.36%), f1 (14.95%), and f5 (1.66%). For NDFS, the top four most important features are f10 (31.56%), f13 (25.4%), f11 (22.06%), and f12 (20.97%). NDFS also indicates that the behavioral characteristics are important for the features. The feature selection matrix for SFSRLR seems overly sparse, with only two important values of features being larger than 1%. With SFSRLR, the top two most important features are f12 (69.17%) and f13 (30.61%). In SFSRLR, the behavioral characteristics also makes up the greatest percentage of importance.
Table 3 shows the classification results with the different methods and the number of features on xAPI with 50% labeled data. The feature selection methods aims to extract the most important features, and xAPI has only 16 features in total. Thus, the classification results with few most important features reflect the performance of the methods. With respect to ACC, the proposed SFSGLR performs the best of the four methods. While using 1 most important feature, SFSGLR+RF outperforms UDFS+RF, NDGS+RF, and SFSRLR+RF by approximately 18.2%, 3.9%, and 6.0%, respectively. When using 3 most important features, SFSGLR+RF outperforms UDFS+RF, NDGS+RF, and SFSRLR+RF by approximately 19%, 10%, and 8.1%, respectively. This indicates that the proposed SFSGLR selects the correct features.
6.4. Student Performance Characteristics Analysis for Different Topics
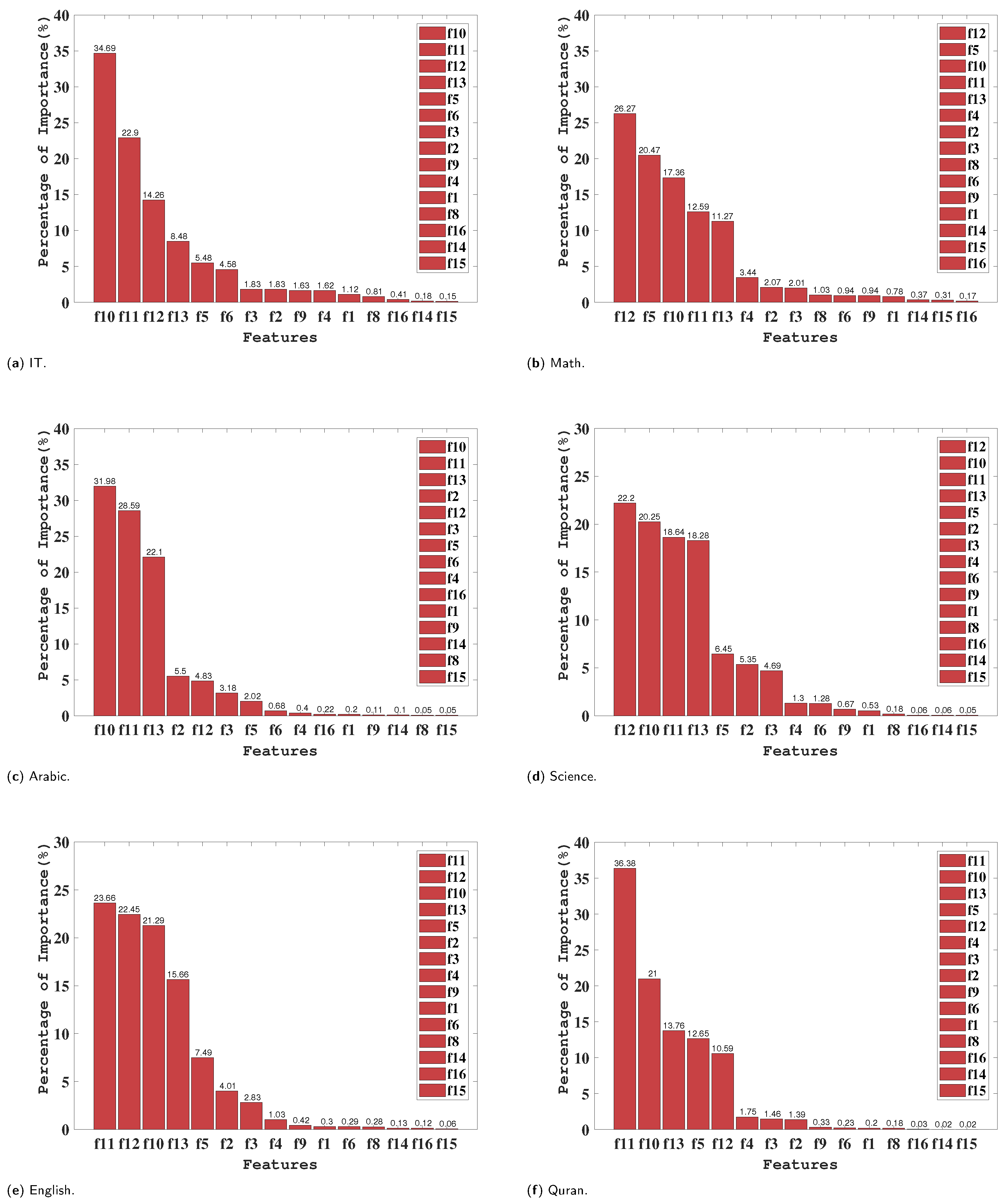
The top four most important features are f11, f10, f7, and f12, with f11, f10, and f12 all being behavioral characteristics, and f7 being a school-related characteristic. Thus, in this section, the content in f7 (topic) is used as a basis to select the importance of each feature under different topics. The results are shown in
Figure 3 and
Figure 4. Based on the figures, the importance of each feature for different topics can be observed. And through further analysis, a deeper understanding of these results could be gained.
For the IT, Arabic, and Spanish topics, the number of times of times students raised hands (f10) accounts for the highest importance. This indicates that students’ active participation in class discussions has a greater impact on their academic performance in these topics.
In five topics, English, Quran, French, History, and Chemistry, the number of times students accesses a particular course content (f11) emerges as the most important characteristic. This indicates that in these subjects, in-depth learning and exploration of course materials play a crucial role in students’ academic performance. Regularly accessing course resources and materials helps students better understand concepts, retain knowledge, and apply it to real-world problems. Within the domains of math and science, the paramount factor is the frequency of students checking for new announcements (f12). This underscores that, in these subjects, students’ attention to updated information and course announcements significantly influences their academic performance.
Conversely, in the realms of biology and geology, the most critical characteristic is the frequency of student participation in discussion groups (f13). This implies that students can enhance their understanding of course concepts and gain more learning benefits through active engagement in group discussions.
To summarize, the varying importance of different characteristics across different topics highlights the diverse influences on students’ academic performance. Nevertheless, a closer examination of the figures reveals that f10, f11, f12, and f13 consistently hold higher rankings for importance across these twelve topics. This suggests that these four characteristics generally play a pivotal role in shaping students’ academic performance.
These findings emphasize the importance of active participation in class discussions, in-depth study of course contents, attention to updated information, and participation in discussion groups. Educators can use this information to develop teaching strategies. This could help to improve students’ academic performance and foster their academic development.
6.5. Performance with Different Numbers of Selected of Features
After sorting in descending order, the ranking of the importance of characteristics can be obtained. In order to demonstrate the effectiveness of the proposed SFSGLR algorithm, four classifiers are adopted to measure the performance after selecting different numbers of the features.
In general, when more features are selected for classifying, the classifiers obtain a better performance. In
Table 4, the classification results are shown. A 10-fold cross-validation is performed, and the mean and standard deviation of the results are recorded. While selecting the two most important features, SFSGLR+KNN has around 94% the performance of selecting all 16 features. SFSGLR+DTree, SFSGLR+RF, and SFSGLR+SVM have approximately 79%, 74%, and 86% in this case, respectively. While selecting the four most important features, SFSGLR+KNN has around 91% the performance of selecting all 16 features. SFSGLR+DTree, SFSGLR+RF, and SFSGLR+SVM have approximately 84%, 85%, and 86% in this case, respectively. Therefore, the performance of the proposed SFSGLR in selecting important features is superior.
Figure 5 shows the classification performance of SFSGLR with four classifiers. It can be seen that when increasing the number of selected features, the classification performance increased gradually. On xAPI, SFSGLR+RF performs best and SFSGLR+KNN performs worst. When selecting eight features, SFSGLR+RF shows around an 17%, 8%, and 11% improvement compared with SFSGLR+KNN, SFSGLR+DTree, and SFSGLR+SVM, respectively.
6.7. Parameter Sensitivity Analysis
In the proposed method,
is used to control the
and
is used to control the manifold regularization. In the experiments, the percentage of labeled data is set to 50%, and SVM is adopted to obtain the classification performance. The grid search method is adopted to tune the parameters, which means that
and
are selected from the set of [0.001, 0.01, 0.1, 1, 10, 100]. In
Figure 7, the classification performance between the different
and the number of selected features when fixing
are shown.
Figure 8 shows the classification performance between different
and the number of selected features when fixing
. It is shown that both
and
are not very sensitive in the range [0.001, 0.1]. In addition, the proposed method obtains the best performance when the values of
and
are selected in the range of [0.01, 0.1]. Generally, the recommended selections of
and
are in the interval [0.01, 0.1].












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}