
Robustness and Transferability of Adversarial Attacks on Different Image Classification Neural Networks

 , ,
, ,
Abstract
1. Introduction
- We evaluated the robustness of SpinalNet and CCT models against popular targeted and non-targeted attacks;
- We assessed the attack transferability of the non-targeted attacks between VGG, SpinalNet, and CCT.
2. Background
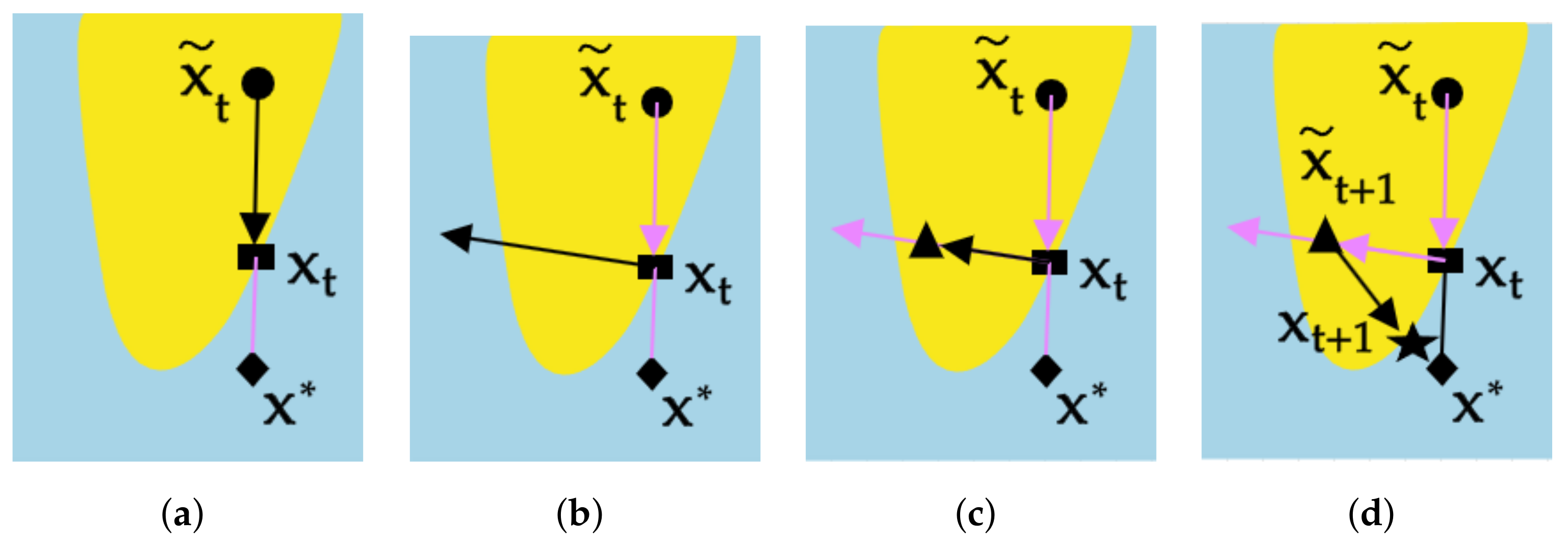
2.1. Generation of the Evasion Attacks
- The norm is used to indicate the number of features altered to create the added perturbation on the images;
- The norm indicates the sum of the added perturbations to the crafted examples;
- The norm specifies the Euclidean distance of the added perturbation to the original image;
- The norm is used to stipulate the maximum added perturbation.
- Minimum norm attack: ensures the minimum magnitude of perturbation;
- Maximum allowable attack: the magnitude of the attack is upper bounded by ;
- Regularization-based attack: tries to simultaneously minimize two objectives such as and .
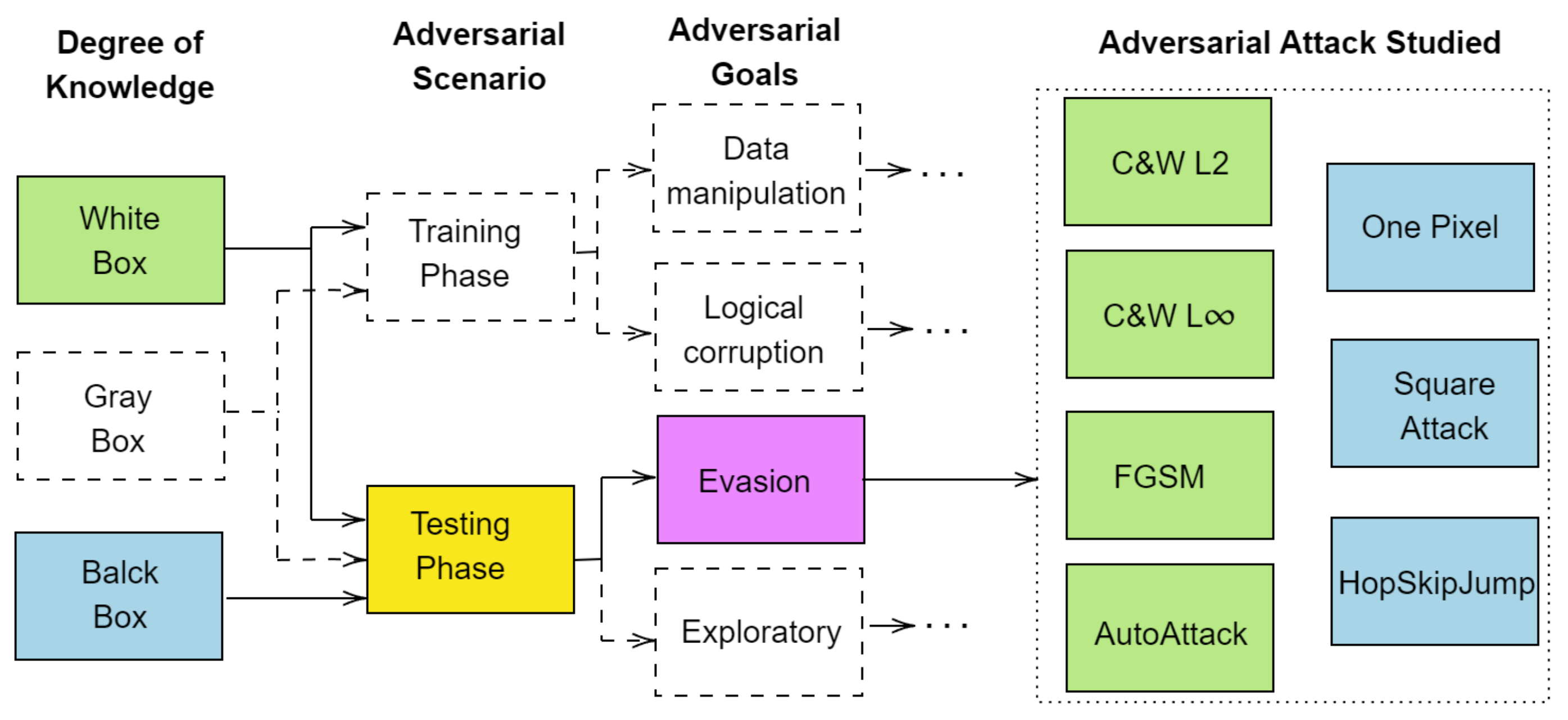
2.2. White-Box Attacks
2.2.1. Carlini and Wagner
2.2.2. Fast Gradient Sign Method
2.2.3. AutoAttack
2.3. Black-Box Attacks
2.3.1. SquareAttack
2.3.2. HopSkipJump
2.3.3. PixelAttack
3. Related Work
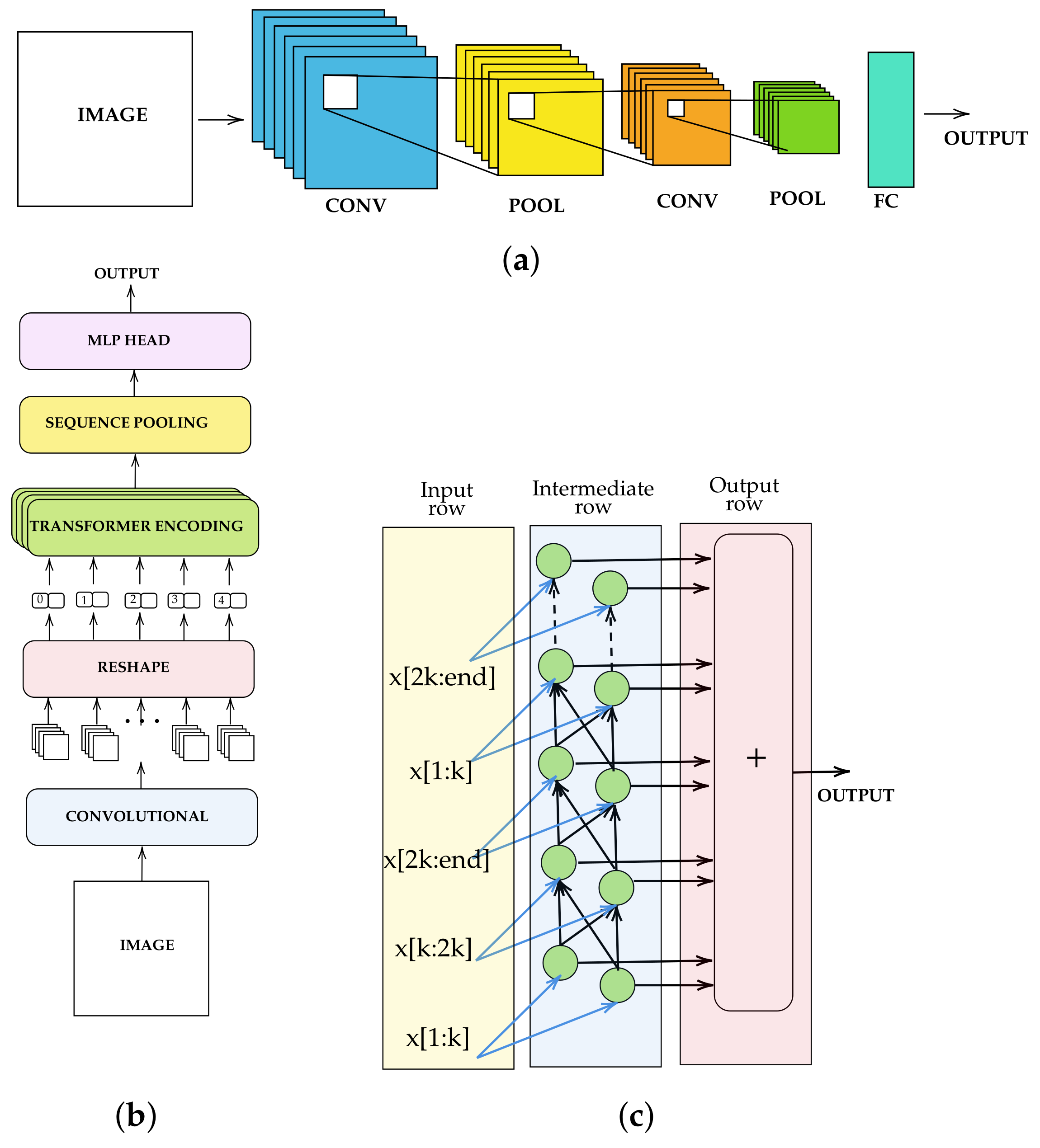
4. Neural Network Models
5. DNN Model Robustness and Transferability Testing Setup
5.1. Data and Models
5.2. Setup
5.2.1. Testing Robustness
5.2.2. Transferability
6. Results and Discussion
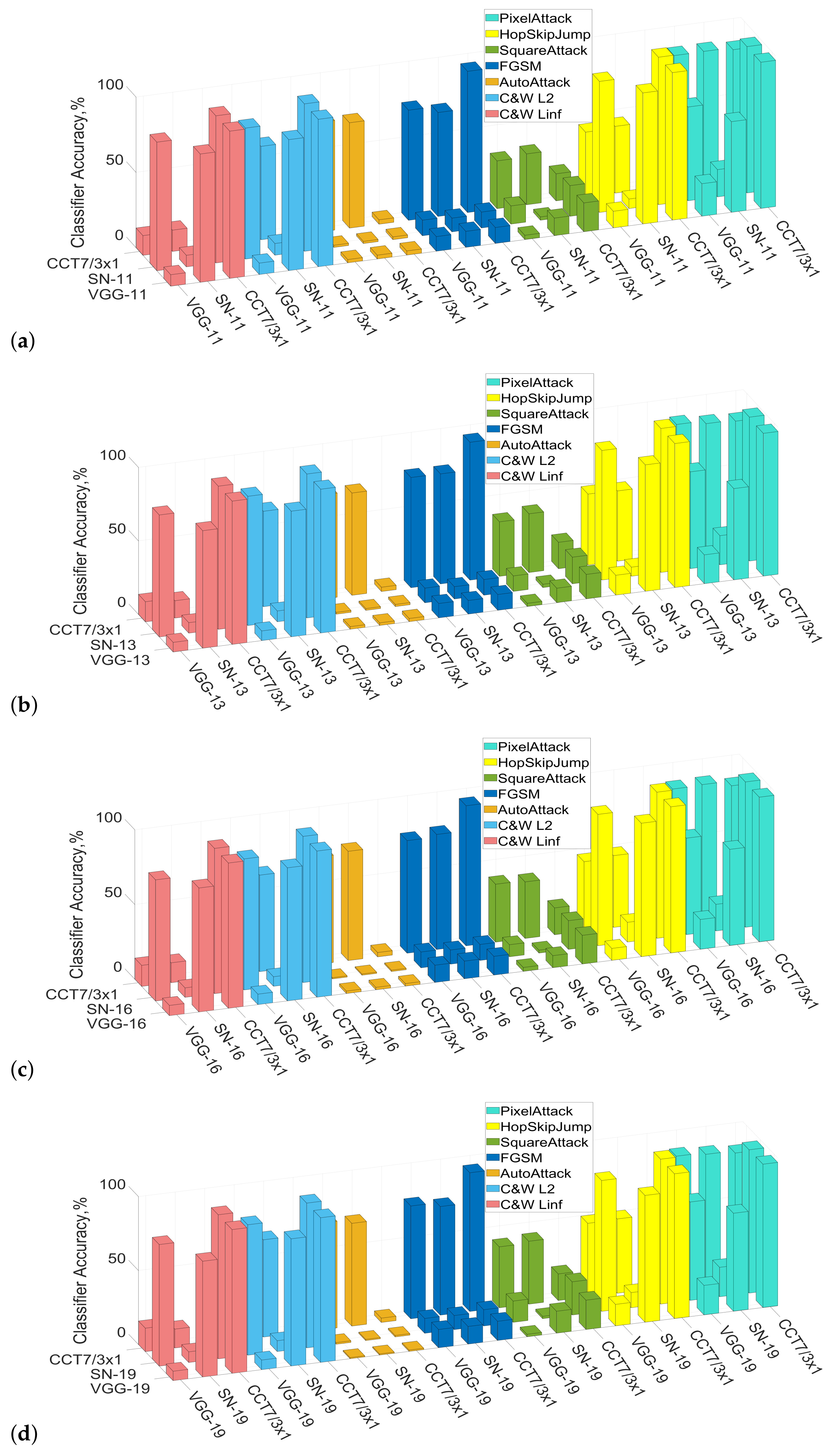
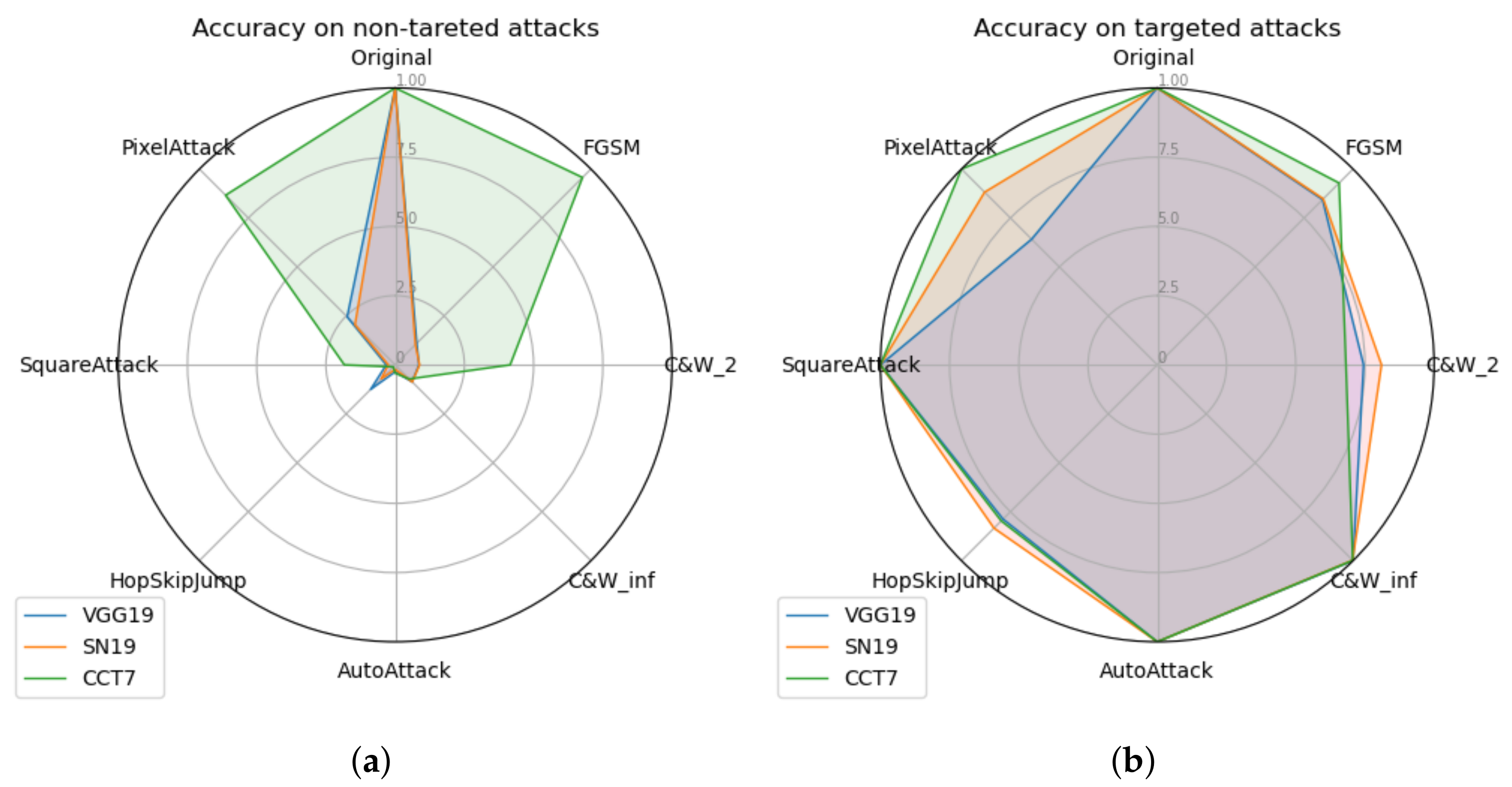
6.1. Robustness
6.2. Transferability
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attack | Accuracy (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| VGG-11 | VGG-13 | VGG-16 | VGG-19 | SN-11 | SN-13 | SN-16 | SN-19 | CCT 7 | |
| Baseline | 87.96 | 89.90 | 89.87 | 90.25 | 88.23 | 88.52 | 90.71 | 88.91 | 98.00 |
| Carlini | 7.62 | 6.57 | 6.86 | 6.37 | 7.69 | 7.13 | 6.35 | 7.21 | 7.06 |
| Carlini | 7.58 | 6.60 | 7.01 | 6.52 | 7.76 | 7.35 | 6.39 | 7.31 | 40.70 |
| AutoAttack | 2.21 | 1.77 | 1.67 | 0.76 | 1.44 | 1.23 | 0.81 | 0.82 | 2.93 |
| FGSM | 9.70 | 9.77 | 11.57 | 12.37 | 9.13 | 8.37 | 9.48 | 9.53 | 93.77 |
| SquareAttack | 2.83 | 2.14 | 2.65 | 1.71 | 2.19 | 2.28 | 1.97 | 1.60 | 17.98 |
| HopSkipJump | 11.02 | 13.48 | 8.00 | 14.52 | 6.33 | 6.16 | 13.19 | 10.22 | 0.99 |
| PixelAttack | 21.57 | 19.62 | 19.72 | 19.94 | 18.10 | 19.84 | 17.81 | 19.89 | 84.89 |
| Attack | Accuracy (%) | |||||
|---|---|---|---|---|---|---|
| Untargeted | Targeted | |||||
| VGG-19 | SN-19 | CCT 7 | VGG-19 | SN-19 | CCT 7 | |
| Baseline | 90.25 | 88.91 | 98.00 | 90.25 | 88.91 | 98.00 |
| Carlini | 6.37 | 7.21 | 7.06 | 67.25 | 73.09 | 61.50 |
| Carlini | 6.52 | 7.31 | 40.70 | 90.25 | 90.03 | 90.10 |
| AutoAttack | 0.76 | 0.82 | 2.93 | 90.00 | 89.25 | 89.55 |
| FGSM | 12.37 | 9.53 | 93.77 | 76.18 | 76.52 | 83.80 |
| SquareAttack | 1.71 | 1.60 | 17.98 | 90.20 | 90.37 | 93.13 |
| HopSkipJump | 14.52 | 10.22 | 0.99 | 71.08 | 72.25 | 71.92 |
| PixelAttack | 19.94 | 19.89 | 84.89 | 57.90 | 79.58 | 90.01 |
Appendix A.2
| Attack | Accuracy (%) | |||||||
|---|---|---|---|---|---|---|---|---|
| SN-11 ↔ VGG-11 | SN-13 ↔ VGG-13 | SN-16 ↔ VGG-16 | SN-19 ↔ VGG-19 | |||||
| Carlini (%) | 85.19 | 85.39 | 79.95 | 82.96 | 82.99 | 81.11 | 78.25 | 82.20 |
| Carlini (%) | 86.98 | 86.98 | 85.47 | 87.92 | 89.10 | 87.72 | 85.99 | 88.16 |
| AutoAttack (%) | 2.53 | 1.45 | 1.77 | 1.24 | 1.68 | 0.81 | 0.77 | 1.09 |
| FGSM (%) | 10.59 | 10.35 | 9.23 | 9.99 | 11.83 | 10.61 | 11.94 | 10.02 |
| SquareAttack (%) | 11.65 | 12.07 | 9.85 | 10.54 | 8.08 | 8.07 | 14.82 | 14.38 |
| HopSkipJump (%) | 87.02 | 86.99 | 85.99 | 88.10 | 89.32 | 87.90 | 85.70 | 88.46 |
| PixelAttack (%) | 60.19 | 62.26 | 62.10 | 65.83 | 64.42 | 64.59 | 66.25 | 66.52 |
| Attack | Accuracy (%) | |||||||
|---|---|---|---|---|---|---|---|---|
| VGG-11 ↔ CCT 7 | VGG-13 ↔ CCT 7 | VGG-16 ↔ CCT 7 | VGG-19 ↔ CCT 7 | |||||
| Carlini | 13.08 | 97.78 | 13.70 | 97.48 | 14.08 | 97.24 | 15.88 | 97.18 |
| Carlini | 60.86 | 97.90 | 64.47 | 97.84 | 62.94 | 97.85 | 65.80 | 97.78 |
| AutoAttack | 72.82 | 2.77 | 70.86 | 2.17 | 71.87 | 1.74 | 72.12 | 0.93 |
| FGSM | 73.13 | 10.57 | 74.97 | 10.72 | 75.37 | 12.56 | 76.24 | 12.97 |
| SquareAttack | 31.72 | 19.16 | 37.08 | 16.64 | 38.77 | 19.21 | 41.23 | 19.83 |
| HopSkipJump | 43.04 | 97.90 | 48.20 | 97.91 | 46.43 | 97.82 | 49.72 | 97.85 |
| PixelAttack | 86.17 | 97.06 | 87.80 | 97.10 | 87.66 | 96.88 | 87.69 | 96.95 |
| SN-11 ↔ CCT 7 | SN-13 ↔ CCT 7 | SN-16 ↔ CCT 7 | SN-19 ↔ CCT 7 | |||||
|---|---|---|---|---|---|---|---|---|
| Carlini (%) | 14.14 | 97.73 | 11.81 | 97.40 | 13.32 | 97.22 | 12.78 | 97.40 |
| Carlini (%) | 62.02 | 97.90 | 64.91 | 97.93 | 64.59 | 97.85 | 65.73 | 97.88 |
| AutoAttack (%) | 69.95 | 1.83 | 69.59 | 1.46 | 73.14 | 0.91 | 69.45 | 0.99 |
| FGSM (%) | 69.00 | 10.57 | 74.83 | 10.64 | 77.01 | 10.71 | 73.41 | 10.98 |
| SquareAttack (%) | 33.78 | 20.37 | 39.95 | 18.10 | 37.84 | 19.23 | 42.54 | 22.45 |
| HopSkipJump (%) | 44.31 | 97.90 | 47.76 | 97.92 | 48.02 | 97.83 | 50.20 | 97.93 |
| PixelAttack (%) | 86.34 | 97.20 | 85.77 | 96.87 | 88.14 | 97.28 | 86.47 | 96.88 |
References
- Sultana, F.; Sufian, A.; Dutta, P. Advancements in image classification using convolutional neural network. In Proceedings of the 2018 Fourth International Conference on Research in Computational Intelligence and Communication Networks (ICRCICN), Kolkata, India, 22–23 November 2018; pp. 122–129. [Google Scholar]
- Han, S.; Kang, J.; Mao, H.; Hu, Y.; Li, X.; Li, Y.; Xie, D.; Luo, H.; Yao, S.; Wang, Y.; et al. Ese: Efficient speech recognition engine with sparse lstm on fpga. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; pp. 75–84. [Google Scholar]
- Bhandare, A.; Sripathi, V.; Karkada, D.; Menon, V.; Choi, S.; Datta, K.; Saletore, V. Efficient 8-bit quantization of transformer neural machine language translation model. arXiv 2019, arXiv:1906.00532. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1765–1773. [Google Scholar]
- Michel, A.; Jha, S.K.; Ewetz, R. A survey on the vulnerability of deep neural networks against adversarial attacks. Prog. Artif. Intell. 2022, 11, 131–141. [Google Scholar] [CrossRef]
- Lin, X.; Zhou, C.; Wu, J.; Yang, H.; Wang, H.; Cao, Y.; Wang, B. Exploratory adversarial attacks on graph neural networks for semi-supervised node classification. Pattern Recognit. 2023, 133, 109042. [Google Scholar] [CrossRef]
- Kaviani, S.; Han, K.J.; Sohn, I. Adversarial attacks and defenses on AI in medical imaging informatics: A survey. Expert Syst. Appl. 2022, 198, 116815. [Google Scholar] [CrossRef]
- Wu, H.; Yunas, S.; Rowlands, S.; Ruan, W.; Wahlström, J. Adversarial driving: Attacking end-to-end autonomous driving. In Proceedings of the 2023 IEEE Intelligent Vehicles Symposium (IV), Anchorage, AK, USA, 4–7 June 2023; pp. 1–7. [Google Scholar]
- Liang, H.; He, E.; Zhao, Y.; Jia, Z.; Li, H. Adversarial attack and defense: A survey. Electronics 2022, 11, 1283. [Google Scholar] [CrossRef]
- Shafahi, A.; Huang, W.R.; Studer, C.; Feizi, S.; Goldstein, T. Are adversarial examples inevitable? arXiv 2018, arXiv:1809.02104. [Google Scholar]
- Carlini, N.; Athalye, A.; Papernot, N.; Brendel, W.; Rauber, J.; Tsipras, D.; Goodfellow, I.; Madry, A.; Kurakin, A. On evaluating adversarial robustness. arXiv 2019, arXiv:1902.06705. [Google Scholar]
- Khamaiseh, S.Y.; Bagagem, D.; Al-Alaj, A.; Mancino, M.; Alomari, H.W. Adversarial deep learning: A survey on adversarial attacks and defense mechanisms on image classification. IEEE Access 2022, 10, 102266–102291. [Google Scholar] [CrossRef]
- Huang, S.; Jiang, H.; Yu, S. Mitigating Adversarial Attack for Compute-in-Memory Accelerator Utilizing On-chip Finetune. In Proceedings of the 2021 IEEE 10th Non-Volatile Memory Systems and Applications Symposium (NVMSA), Beijing, China, 18–20 August 2021; pp. 1–6. [Google Scholar]
- Rathore, P.; Basak, A.; Nistala, S.H.; Runkana, V. Untargeted, targeted and universal adversarial attacks and defenses on time series. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Mahmood, K.; Mahmood, R.; Van Dijk, M. On the robustness of vision transformers to adversarial examples. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 7838–7847. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Kabir, H.; Abdar, M.; Jalali, S.M.J.; Khosravi, A.; Atiya, A.F.; Nahavandi, S.; Srinivasan, D. Spinalnet: Deep neural network with gradual input. arXiv 2020, arXiv:2007.03347. [Google Scholar] [CrossRef]
- Hassani, A.; Walton, S.; Shah, N.; Abuduweili, A.; Li, J.; Shi, H. Escaping the big data paradigm with compact transformers. arXiv 2021, arXiv:2104.05704. [Google Scholar]
- Aldahdooh, A.; Hamidouche, W.; Deforges, O. Reveal of vision transformers robustness against adversarial attacks. arXiv 2021, arXiv:2106.0373. [Google Scholar]
- Nicolae, M.I.; Sinn, M.; Tran, M.N.; Buesser, B.; Rawat, A.; Wistuba, M.; Zantedeschi, V.; Baracaldo, N.; Chen, B.; Ludwig, H.; et al. Adversarial Robustness Toolbox v1. 0.0. arXiv 2018, arXiv:1807.01069. [Google Scholar]
- Wu, F.; Gazo, R.; Haviarova, E.; Benes, B. Efficient project gradient descent for ensemble adversarial attack. arXiv 2019, arXiv:1906.03333. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Gil, Y.; Chai, Y.; Gorodissky, O.; Berant, J. White-to-black: Efficient distillation of black-box adversarial attacks. arXiv 2019, arXiv:1904.02405. [Google Scholar]
- Mani, N. On Adversarial Attacks on Deep Learning Models. Master’s Thesis, San Jose State University, San Jose, CA, USA, 2019. [Google Scholar]
- Liu, X.; Wang, H.; Zhang, Y.; Wu, F.; Hu, S. Towards efficient data-centric robust machine learning with noise-based augmentation. arXiv 2022, arXiv:2203.03810. [Google Scholar]
- Croce, F.; Hein, M. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. In Proceedings of the International Conference on Machine Learning, (ICML), Vienna, Austria, 13–18 July 2020; pp. 2206–2216. [Google Scholar]
- Croce, F.; Hein, M. Minimally distorted adversarial examples with a fast adaptive boundary attack. In Proceedings of the International Conference on Machine Learning, (ICML), Vienna, Austria, 13–18 July 2020; pp. 2196–2205. [Google Scholar]
- Andriushchenko, M.; Croce, F.; Flammarion, N.; Hein, M. Square attack: A query-efficient black-box adversarial attack via random search. In European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2020; pp. 484–501. [Google Scholar]
- Chen, J.; Jordan, M.I.; Wainwright, M.J. Hopskipjumpattack: A query-efficient decision-based attack. In Proceedings of the 2020 Ieee Symposium on Security and Privacy (sp), San Francisco, CA, USA, 18–21 May 2020; pp. 1277–1294. [Google Scholar]
- Su, J.; Vargas, D.V.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef]
- Liu, Y.; Yan, Z.; Tan, J.; Li, Y. Multi-purpose oriented single nighttime image haze removal based on unified variational retinex model. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 1643–1657. [Google Scholar] [CrossRef]
- Liu, Y.; Yan, Z.; Ye, T.; Wu, A.; Li, Y. Single nighttime image dehazing based on unified variational decomposition model and multi-scale contrast enhancement. Eng. Appl. Artif. Intell. 2022, 116, 105373. [Google Scholar] [CrossRef]
- Bakiskan, C.; Cekic, M.; Madhow, U. Early layers are more important for adversarial robustness. In Proceedings of the ICLR 2022 Workshop on New Frontiers in Adversarial Machine Learning, (ADVML Frontiers @ICML), Baltimore, MD, USA, 17–23 July 2022. [Google Scholar]
- Siddiqui, S.A.; Breuel, T. Identifying Layers Susceptible to Adversarial Attacks. arXiv 2021, arXiv:2107.04827. [Google Scholar]
- Renkhoff, J.; Tan, W.; Velasquez, A.; Wang, W.Y.; Liu, Y.; Wang, J.; Niu, S.; Fazlic, L.B.; Dartmann, G.; Song, H. Exploring adversarial attacks on neural networks: An explainable approach. In Proceedings of the 2022 IEEE International Performance, Computing, and Communications Conference (IPCCC), Austin, TX, USA, 11–13 November 2022; pp. 41–42. [Google Scholar]
- Akhtar, N.; Mian, A. Threat of adversarial attacks on deep learning in computer vision: A survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Agrawal, P.; Punn, N.S.; Sonbhadra, S.K.; Agarwal, S. Impact of attention on adversarial robustness of image classification models. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 3013–3019. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Álvarez, E.; Álvarez, R.; Cazorla, M. Exploring Transferability on Adversarial Attacks. IEEE Access 2023, 11, 105545–105556. [Google Scholar] [CrossRef]
- Chen, Z.; Xu, C.; Lv, H.; Liu, S.; Ji, Y. Understanding and improving adversarial transferability of vision transformers and convolutional neural networks. Inf. Sci. 2023, 648, 119474. [Google Scholar] [CrossRef]
- Spinalnet: Deep neural network with gradual input. IEEE Trans. on Artif. Intell. 2022, 4, 1165–1177.
- Kotyan, S.; Vargas, D.V. Adversarial Robustness Assessment: Why both L_0 and L_∞ Attacks Are Necessary. arXiv 2019, arXiv:1906.06026. [Google Scholar]
- Benz, P.; Ham, S.; Zhang, C.; Karjauv, A.; Kweon, I.S. Adversarial robustness comparison of vision transformer and mlp-mixer to cnns. arXiv 2021, arXiv:2110.02797. [Google Scholar]
- Yan, C.; Chen, Y.; Wan, Y.; Wang, P. Modeling low-and high-order feature interactions with FM and self-attention network. Appl. Intell. 2021, 51, 3189–3201. [Google Scholar] [CrossRef]
- Huang, Q.; Katsman, I.; He, H.; Gu, Z.; Belongie, S.; Lim, S.N. Enhancing adversarial example transferability with an intermediate level attack. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 4733–4742. [Google Scholar]
| Type of Attack | ASR (%) Top-1 Error | |||
|---|---|---|---|---|
| FGSM | C&W | C&W | PGD | |
| ViT-S-16 | 47.80 | 99.70 | 100.00 | 90.00 |
| Vit-B-16 | 50.00 | 98.10 | 95.80 | 94.10 |
| ViT-L-16 | 39.80 | 95.90 | 94.80 | 88.40 |
| ResNet50 | 43.80 | 99.50 | 100.00 | 90.70 |
| VGG-16 | 89.00 | 99.90 | 100.00 | 98.90 |
| Attack Method | Norm | Adversarial Knowledge | Search Type | Crafting Adversarial Example | Strength of the Untargeted Attack | ||
|---|---|---|---|---|---|---|---|
| SpinalNet | VGG | CCT | |||||
| FGSM | White-Box | single step gradient-based guided differentiable search | applies the sign function on gradients | ✓✓✓✓✓ | ✓✓✓✓✓ | ✓ | |
| C&W | White-box | iterative gradient-based guided differentiable search | attempts to find a small perturbation while keeping the distance between x and x′ minimal | ✓✓✓✓✓ | ✓✓✓✓✓ | ✓✓ | |
| White-box | iterative gradient-based guided differentiable search | unlike , operates on batches | ✓✓✓✓✓ | ✓✓✓✓✓ | ✓✓✓✓✓ | ||
| SquareAttack | Black-box | score-based iterative non-guided random search | every iteration selects square-shaped updates so that perturbation is located at the boundary of the feasible set | ✓✓✓✓✓✓ | ✓✓✓✓✓✓ | ✓✓✓✓ | |
| AutoPGD | n/a | White-box | iterative gradient-based guided differentiable search | size-free step with exploration (search for good initial point) and exploitation (knowledge accumulation) phases | n/a | n/a | n/a |
| DeepFool | n/a | White-box | iterative guided differentiable search | iteratively searches for adversarial example at the decision boundary between classes | n/a | n/a | n/a |
| AutoAttack | White-box | iterative without any hyperparameter tuning | ensemble of parameter-free attacks | ✓✓✓✓✓✓ | ✓✓✓✓✓✓ | ✓✓✓✓✓✓ | |
| PixelAttack | Black-box | iterative differential evolution | only one pixel is changed | ✓✓✓✓ | ✓✓✓✓ | ✓ | |
| HopSkipJump | Black-box | iterative gradient-based binary search | minimizes distance to the target image while staying at the adversarial side of the boundary | ✓✓✓✓✓ | ✓✓✓✓✓ | ✓✓✓✓✓✓ | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Smagulova, K.; Bacha, L.; Fouda, M.E.; Kanj, R.; Eltawil, A. Robustness and Transferability of Adversarial Attacks on Different Image Classification Neural Networks. Electronics 2024, 13, 592. https://doi.org/10.3390/electronics13030592
Smagulova K, Bacha L, Fouda ME, Kanj R, Eltawil A. Robustness and Transferability of Adversarial Attacks on Different Image Classification Neural Networks. Electronics. 2024; 13(3):592. https://doi.org/10.3390/electronics13030592
Chicago/Turabian StyleSmagulova, Kamilya, Lina Bacha, Mohammed E. Fouda, Rouwaida Kanj, and Ahmed Eltawil. 2024. "Robustness and Transferability of Adversarial Attacks on Different Image Classification Neural Networks" Electronics 13, no. 3: 592. https://doi.org/10.3390/electronics13030592
APA StyleSmagulova, K., Bacha, L., Fouda, M. E., Kanj, R., & Eltawil, A. (2024). Robustness and Transferability of Adversarial Attacks on Different Image Classification Neural Networks. Electronics, 13(3), 592. https://doi.org/10.3390/electronics13030592