
Evolution of Siamese Visual Tracking with Slot Attention
 ,
,
Abstract
1. Introduction
- We build a tracking network incorporating the Slot Attention module, which enhances the extraction of nonlinear feature information, leading to better performance in scenarios where objects exhibit sudden transformations or blurriness.
- Our method for training a network that reuses the attention module considerably reduces the parameters, leading to a noticeable decrease in memory consumption.
- Our experiments on various datasets demonstrate that our SiamSlot outperforms other state-of-the-art tracking networks under the same network size.
2. Related Work
2.1. Improvement in the Siamese Network Backbone Network
2.2. Improvement in the Siamese Network Feature Association
2.3. Improvement in the Siamese Network Head Network
3. Algorithm
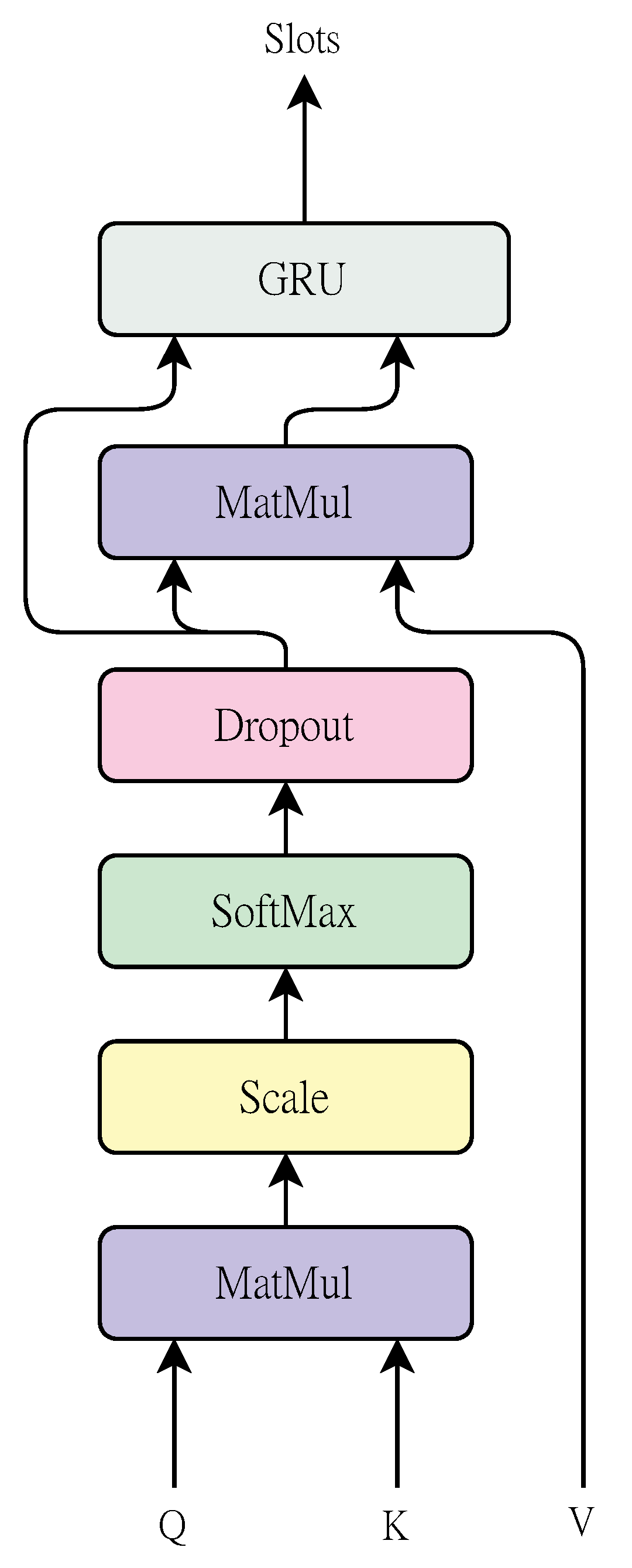
3.1. Slot Attention
| Algorithm 1: Streamline of Slot Attention. The inputs correspond to the key, query, and value vectors in Transformer, respectively. Each vector is a set of D-dimensional vectors. We use the search image features to initialize the k, v vectors. The slots vector is initialized with template image features. In the experiment, we set the number of iterations as T. |
 |
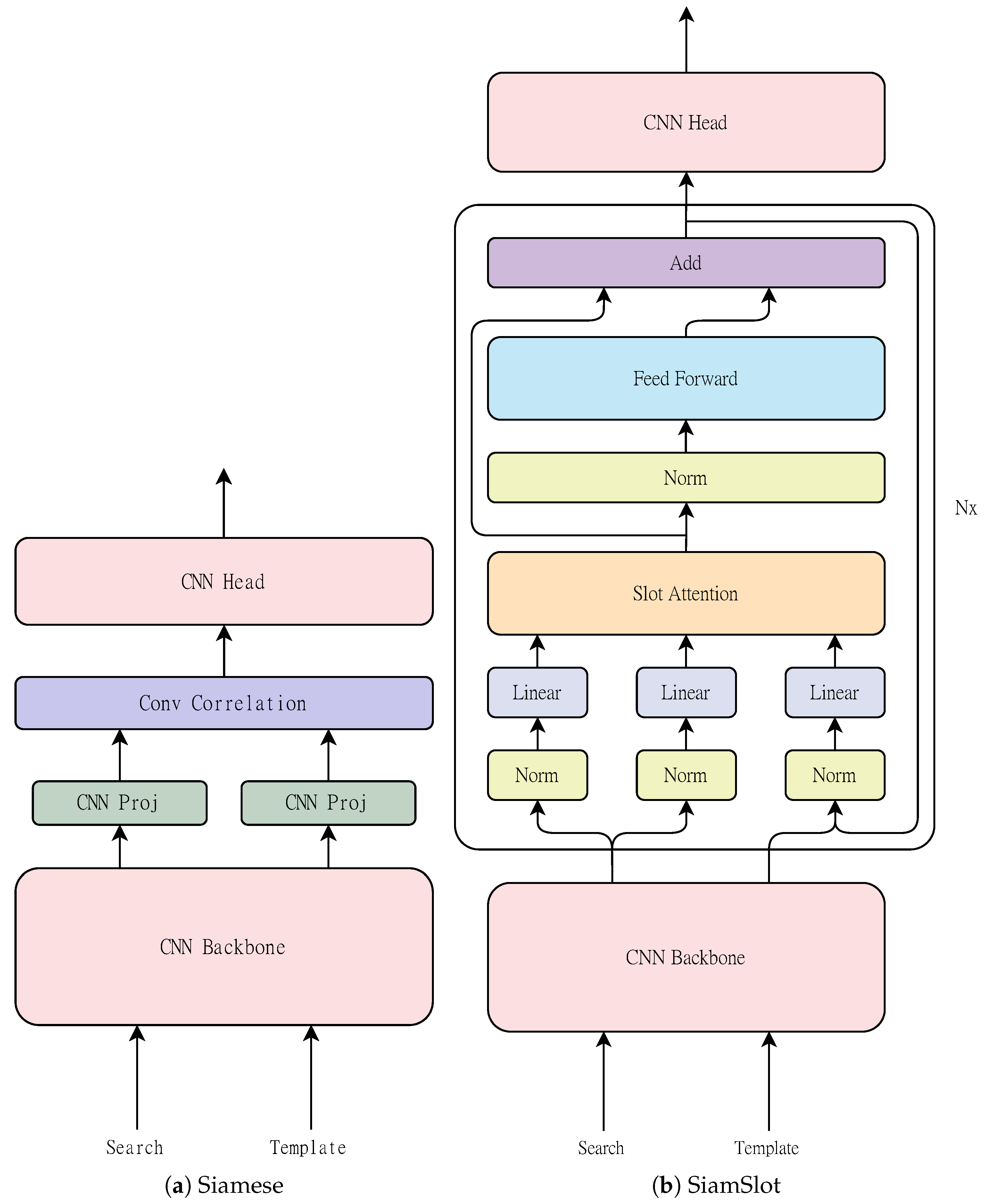
3.2. Siamese Trackers
4. Experiment
4.1. Implementation Details
- Experimental setting. We implemented the tracking network using Python 3.8 and PyTorch 1.12.1 and conducted experiments on a single Nvidia GeForce RTX 3090 GPU.
- Dataset setting. Our training dataset consisted of LaSOT [22], GOT-10k [13], ILSVRCVID [23], and COCO [24]. For the video dataset, we selected image pairs from two random frames within the same video sequence, with a maximum interval of 80 frames. To enhance the diversity of the training samples, we additionally incorporated the COCO object detection dataset, where each image pair was derived from each object to be detected. Moreover, we employed data augmentation techniques, including scaling, luminance variations, and vertical and horizontal flips, to expand the training dataset.
- Training setting. We utilized a pre-trained AlexNet model in PyTorch as the backbone network. To optimize the model performance, we selected Adam [25] as the optimizer. In total, we trained the network for 4000 epochs, with the Slot Attention and prediction network undergoing 4000 epochs of training, while the backbone network was frozen in the beginning for 200 epochs and then began training. Each epoch sampled 30,000 image pairs for training. Both the template and search images were resized to 255 pixels before being fed into the network. We applied a weight decay of 5 × 10−4 and a momentum of 0.9. We employed the cosine decay learning rate strategy to adjust the learning rate during training. The initial learning rate of the backbone network was set to 1 × 10−5, while different learning rates were applied to the Slot Attention module according to its number of stacked modules. The relationship between the number and learning rate is shown in Table 1.
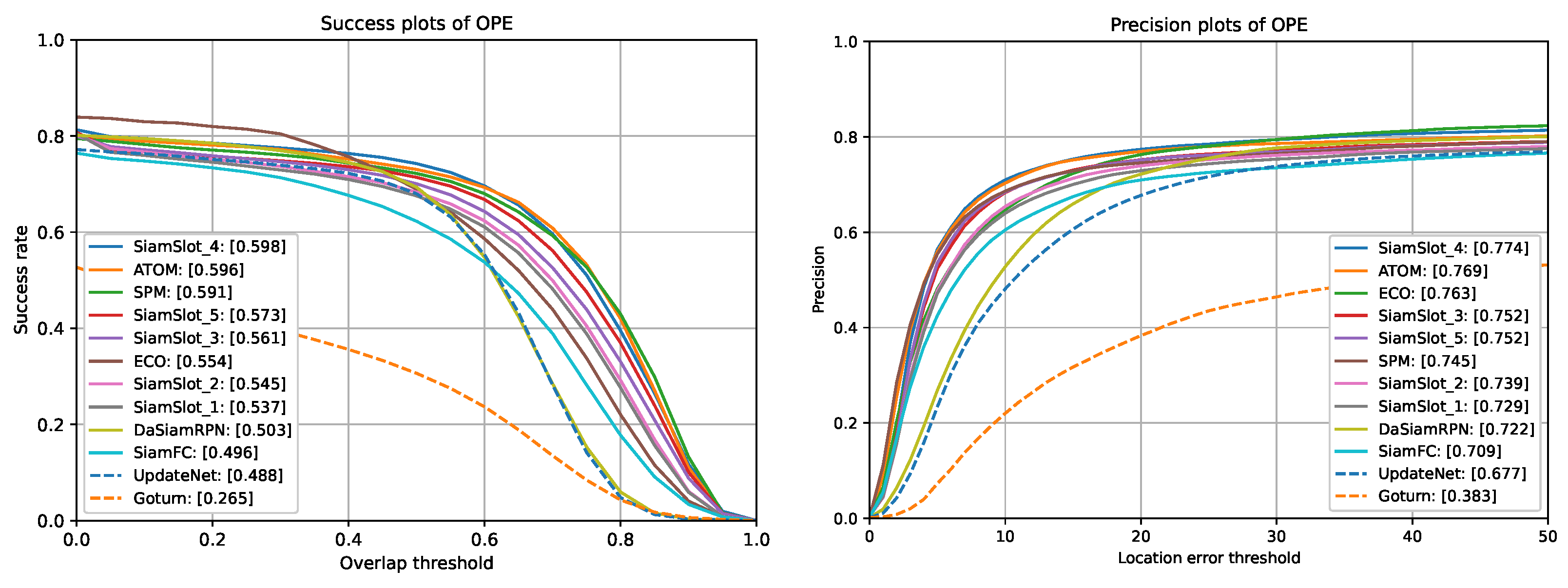
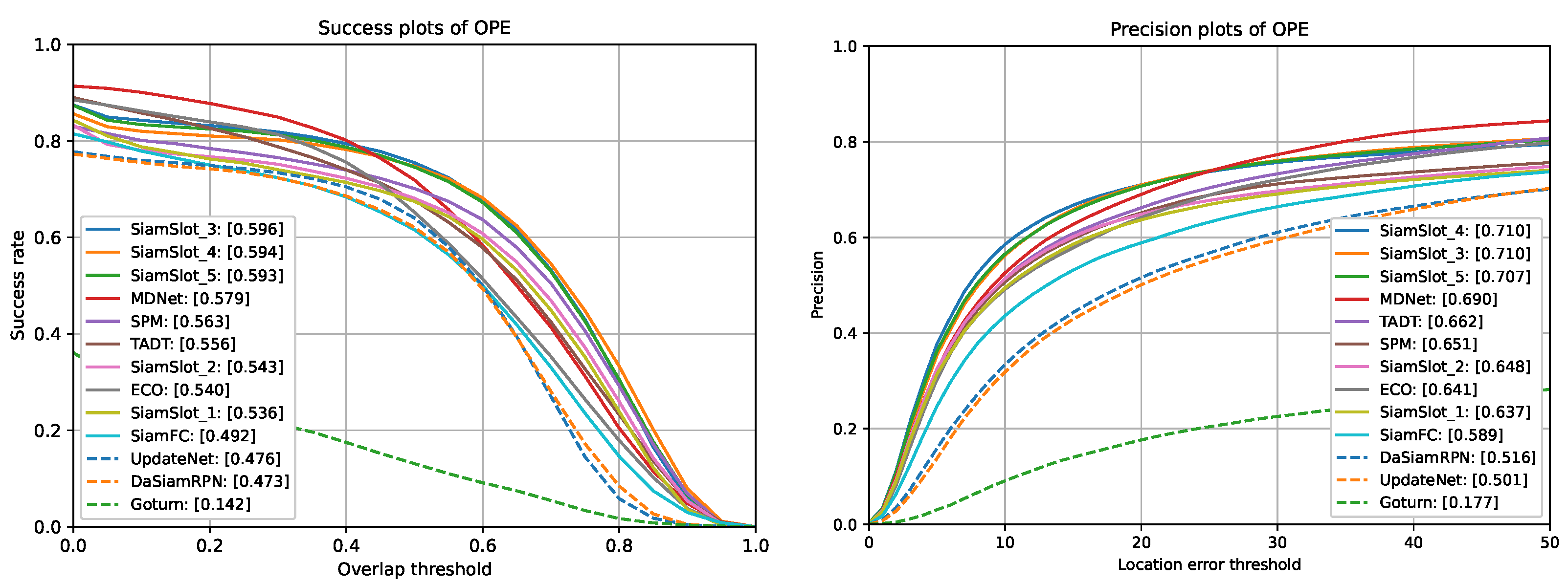
4.2. Comparison on Multiple Benchmarks
4.3. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the Computer Vision—ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 850–865. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Cananda, 7–12 December 2015. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4282–4291. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and wider siamese networks for real-time visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4591–4600. [Google Scholar]
- Yi, K.; Gan, C.; Li, Y.; Kohli, P.; Wu, J.; Torralba, A.; Tenenbaum, J.B. Clevrer: Collision events for video representation and reasoning. arXiv 2019, arXiv:1910.01442. [Google Scholar]
- Kulkarni, T.D.; Gupta, A.; Ionescu, C.; Borgeaud, S.; Reynolds, M.; Zisserman, A.; Mnih, V. Unsupervised learning of object keypoints for perception and control. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Locatello, F.; Weissenborn, D.; Unterthiner, T.; Mahendran, A.; Heigold, G.; Uszkoreit, J.; Dosovitskiy, A.; Kipf, T. Object-centric learning with slot attention. Adv. Neural Inf. Process. Syst. 2020, 33, 11525–11538. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-aware siamese networks for visual object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]
- Wang, N.; Zhou, W.; Wang, J.; Li, H. Transformer meets tracker: Exploiting temporal context for robust visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1571–1580. [Google Scholar]
- Bhat, G.; Danelljan, M.; Gool, L.V.; Timofte, R. Learning discriminative model prediction for tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6182–6191. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8126–8135. [Google Scholar]
- Huang, L.; Zhao, X.; Huang, K. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1562–1577. [Google Scholar] [CrossRef] [PubMed]
- Ye, B.; Chang, H.; Ma, B.; Shan, S.; Chen, X. Joint feature learning and relation modeling for tracking: A one-stream framework. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 341–357. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. SiamCAR: Siamese fully convolutional classification and regression for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6269–6277. [Google Scholar]
- Yan, B.; Peng, H.; Fu, J.; Wang, D.; Lu, H. Learning spatio-temporal transformer for visual tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10448–10457. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. Lasot: A high-quality benchmark for large-scale single object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5374–5383. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Kristan, M.; Matas, J.; Leonardis, A.; Felsberg, M.; Pflugfelder, R.; Kamarainen, J.K.; Čehovin Zajc, L.; Drbohlav, O.; Lukezic, A.; Berg, A.; et al. The seventh visual object tracking VOT2019 challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Yang, T.; Chan, A.B. Learning dynamic memory networks for object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 152–167. [Google Scholar]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Yang, T.; Chan, A.B. Visual tracking via dynamic memory networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 360–374. [Google Scholar] [CrossRef]
- Li, X.; Ma, C.; Wu, B.; He, Z.; Yang, M.H. Target-aware deep tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1369–1378. [Google Scholar]
- Zhang, L.; Gonzalez-Garcia, A.; Weijer, J.V.D.; Danelljan, M.; Khan, F.S. Learning the model update for siamese trackers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4010–4019. [Google Scholar]
- Held, D.; Thrun, S.; Savarese, S. Learning to track at 100 fps with deep regression networks. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 749–765. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. Atom: Accurate tracking by overlap maximization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4660–4669. [Google Scholar]
- Wang, G.; Luo, C.; Xiong, Z.; Zeng, W. Spm-tracker: Series-parallel matching for real-time visual object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3643–3652. [Google Scholar]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. Eco: Efficient convolution operators for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6638–6646. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. A benchmark and simulator for uav tracking. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 445–461. [Google Scholar]
- Kiani Galoogahi, H.; Fagg, A.; Huang, C.; Ramanan, D.; Lucey, S. Need for speed: A benchmark for higher frame rate object tracking. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1125–1134. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| module numbers | 1 | 2 | 3 | 4 | 5 |
| initial learning rate | 9 × 10−4 | 7 × 10−4 | 5 × 10−4 | 4 × 10−4 | 3 × 10−4 |
| Tracker | Accuracy | Robustness | EAO |
|---|---|---|---|
| DaSiamRPN [9] | 0.495 | 2.262 | 0.189 |
| MemTrack [27] | 0.477 | 2.260 | 0.207 |
| SiamFC [1] | 0.467 | 2.625 | 0.177 |
| MDNet [28] | 0.503 | 1.355 | 0.200 |
| MemDTC [29] | 0.478 | 1.989 | 0.223 |
| TADT [30] | 0.508 | 1.725 | 0.175 |
| UpdateNet [31] | 0.465 | 1.525 | 0.188 |
| GOTURN [32] | 0.396 | 4.464 | 0.136 |
| SiamRPNX [26] | 0.508 | 1.746 | 0.219 |
| SiamSlot_1 | 0.479 | 1.819 | 0.210 |
| SiamSlot_2 | 0.512 | 1.722 | 0.230 |
| SiamSlot_3 | 0.523 | 1.431 | 0.241 |
| SiamSlot_4 | 0.522 | 1.785 | 0.210 |
| SiamSlot_5 | 0.523 | 1.616 | 0.204 |
| Tracker | Accuracy | Robustness | EAO |
|---|---|---|---|
| SiamConv | 0.472 | 3.080 | 0.148 |
| SiamSlot_1 | 0.479 | 1.819 | 0.210 |
| SiamSlot_2 | 0.512 | 1.722 | 0.230 |
| SiamSlot_3 | 0.523 | 1.431 | 0.241 |
| SiamSlot_4 | 0.522 | 1.785 | 0.210 |
| SiamSlot_5 | 0.523 | 1.616 | 0.204 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Ye, X.; Wu, D.; Gong, J.; Tang, X.; Li, Z. Evolution of Siamese Visual Tracking with Slot Attention. Electronics 2024, 13, 586. https://doi.org/10.3390/electronics13030586
Wang J, Ye X, Wu D, Gong J, Tang X, Li Z. Evolution of Siamese Visual Tracking with Slot Attention. Electronics. 2024; 13(3):586. https://doi.org/10.3390/electronics13030586
Chicago/Turabian StyleWang, Jian, Xiangzhou Ye, Dongjie Wu, Jinfu Gong, Xinyi Tang, and Zheng Li. 2024. "Evolution of Siamese Visual Tracking with Slot Attention" Electronics 13, no. 3: 586. https://doi.org/10.3390/electronics13030586
APA StyleWang, J., Ye, X., Wu, D., Gong, J., Tang, X., & Li, Z. (2024). Evolution of Siamese Visual Tracking with Slot Attention. Electronics, 13(3), 586. https://doi.org/10.3390/electronics13030586