1. Introduction
In modern technology, developing specialized fault detection and diagnosis (FDD) systems for industrial applications has emerged as a vital endeavor [
1]. Manufacturing processes and industrial operations have been revolutionized by the advent of Industry 4.0 (I4.0), characterized by the integration of advanced technologies, including artificial intelligence (AI), the Internet of Things (IoT), and big data analytics. Digital transformation establishes opportunities and challenges for maintenance. Additionally, it optimizes complex industrial systems.
Large learning models (LLMs) represent a remarkable breakthrough in AI [
2], transforming organizational decision making, problem resolution strategies, and operational efficiency. Trained on vast amounts of textual data, these models have exhibited noteworthy capabilities in understanding context, generating human-like text and carrying out a wide range of language-based tasks. Their impact extends to network systems, which address challenges of complex configurations and heterogeneous infrastructure management [
3]. Although LLMs have been successfully applied in various domains, their potential for industrial FDD systems is still largely unexplored.
Existing FDD approaches are mainly dependent on traditional machine learning (ML) techniques [
4], expert systems [
5], or statistical methods [
6]. The current methods often face difficulties in handling the intricacy and various fault scenarios in modern industrial systems. Additionally, they tend to concentrate on particular data types or predetermined fault patterns, which constrains their ability to adapt to new or unanticipated faults [
7]. The crucial obstacles in FDD research are the incorporation of multimodal data and the capability to analyze different data types.
In our proposed work, these gaps are addressed via a novel multimodal FDD framework that uses LLMs, which offers several key contributions. First, an LLM-based FDD method is proposed using GPT-4-Preview, which enhances the scalability, generalizability, and efficiency of complex systems and various fault scenarios. Second, by generating synthetic datasets using LLMs, we enrich the knowledge base and enhance the accuracy of FDD in imbalanced scenarios. Third, the approach optimizes the diagnosis accuracy and overall performance of the framework. Fourth, we introduce a hybrid architecture that integrates online and offline processing, which combines real-time data streams with fine-tuned LLMs for dynamic, accurate, and context-aware fault detection suitable to I4.0 environments. This comprehensive approach aims to overcome traditional FDD challenges and advance the field toward more adaptive and efficient fault diagnosis systems. In the following sections, a comprehensive literature review is presented, our methodology and system design are detailed, the results of our case study and model comparisons are discussed, and the implications of our findings for future developments in industrial FDD systems and I4.0 technologies are explored.
2. Background, Taxonomy, and Related Research
In recent years, FDD has seen remarkable advancements, particularly with multimodal LLMs (MM-LLMs) emerging as cutting-edge technology. These advanced AI-based systems were created to integrate and process various data types, including text, images, audio, and video, which makes them more applicable across multiple industrial contexts. The rapid evolution of LLMs, exemplified by ChatGPT’s ability to handle diverse tasks and its unprecedented adoption rate [
8], further demonstrates their potential for industrial applications.
Several studies have explored the use of LLMs and MMLLMs in FDD. For instance, combining fuzzy logic with ChatGLM2-6B has potential in electrical equipment fault diagnosis, enhancing the adaptability and accuracy of fault diagnosis mechanisms [
9]. Likewise, integrating knowledge graphs with LLMs has been applied to compressor fault diagnosis, which demonstrates significant improvements in fault detection accuracy [
10]. Prompt engineering approaches have also been investigated for spacecraft fault diagnosis, which highlights the potential of LLMs in managing complex multi-level fault scenarios [
11]. Moreover, the use of LLMs in aviation assembly and autonomous driving in mines emphasizes the versatility and effectiveness of these models in diverse industrial applications [
12,
13,
14].
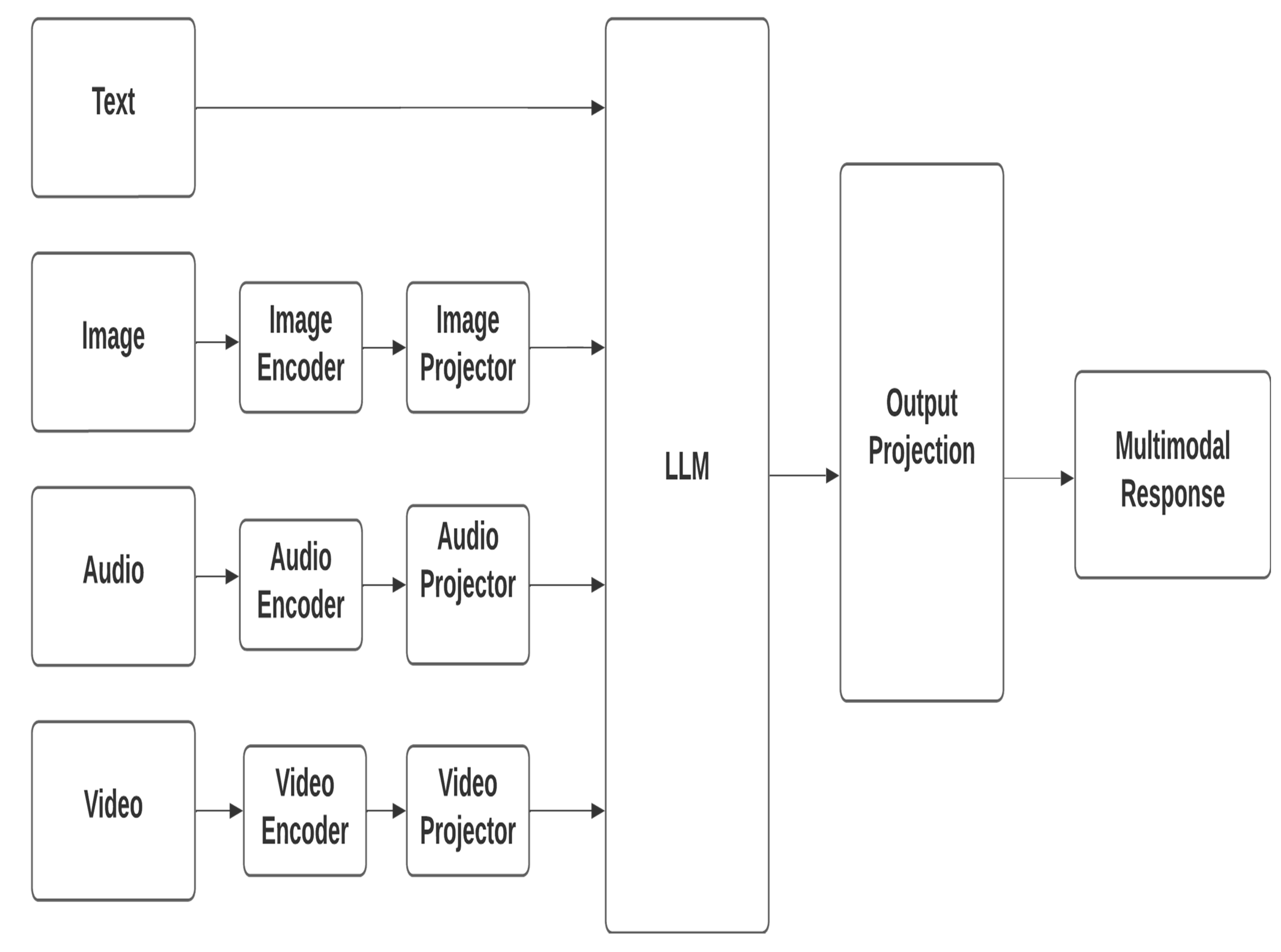
Figure 1 illustrates the architecture of MM-LLMs, which consists of four key components: a modality encoder, which encodes inputs from various modalities to obtain corresponding features; an input projector, which aligns these features with the text feature space via methods such as linear projectors, a multilayer perceptron, and cross-attention mechanisms; the LLM backbone, which processes the representations to perform semantic understanding, reasoning, and decision making; and an output projector, which maps signal token representations into features that are comprehensible to the modality generator, which produces outputs in distinct modalities via latent diffusion models. Examples of MM-LLMs include Flamingo, which integrates NFNetF6 and Chinchilla for visual and textual processing; BLIP2, which combines CLIP and Flan-T5 for image-text tasks; and LLaVA, which employs CLIP and Vicuna for visual question answering. The training pipeline is divided into multimodal pre-training, which focuses on aligning modalities using X-Text datasets, and multimodal instruction tuning, which fine-tunes pre-trained MM-LLMs with instruction-formatted datasets to enhance their zero-shot performance and generalization [
15].
This comprehensive architecture enables MM-LLMs to effectively integrate multiple modalities, leveraging pre-trained models to optimize computational efficiency and improve performance across various multimodal tasks.
Given the novelty and potential of MM-LLM-based FDD systems, a comprehensive search was carried out using the Scopus database to acquire references for related studies. To narrow down the search, the following query was employed, focusing on the terms “fault diagnosis” and “fault diagnostics” within the title or abstract: TITLE-ABS-KEY (“fault diagnosis” OR “fault diagnostics”) AND PUBYEAR > 2018 AND PUBYEAR < 2025 AND (LIMIT-TO (SRCTYPE, “j”)) AND (LIMIT-TO (LANGUAGE, “English”)) AND ( LIMIT-TO ( SUBJAREA, “ENGI”) OR LIMIT-TO (SUBJAREA, “COMP”)). The search was further refined to include publications from 2019 to 2024, ensuring the most recent and relevant findings. To maintain a high standard of research, only journal articles (indicated by “j”) were considered, and the language was restricted to English. Moreover, the subject areas were limited to Engineering (“ENGI”) and Computer Science (“COMP”), aligning with the theme of industrial fault diagnostic support systems. A total of 11,655 documents were identified using this approach.
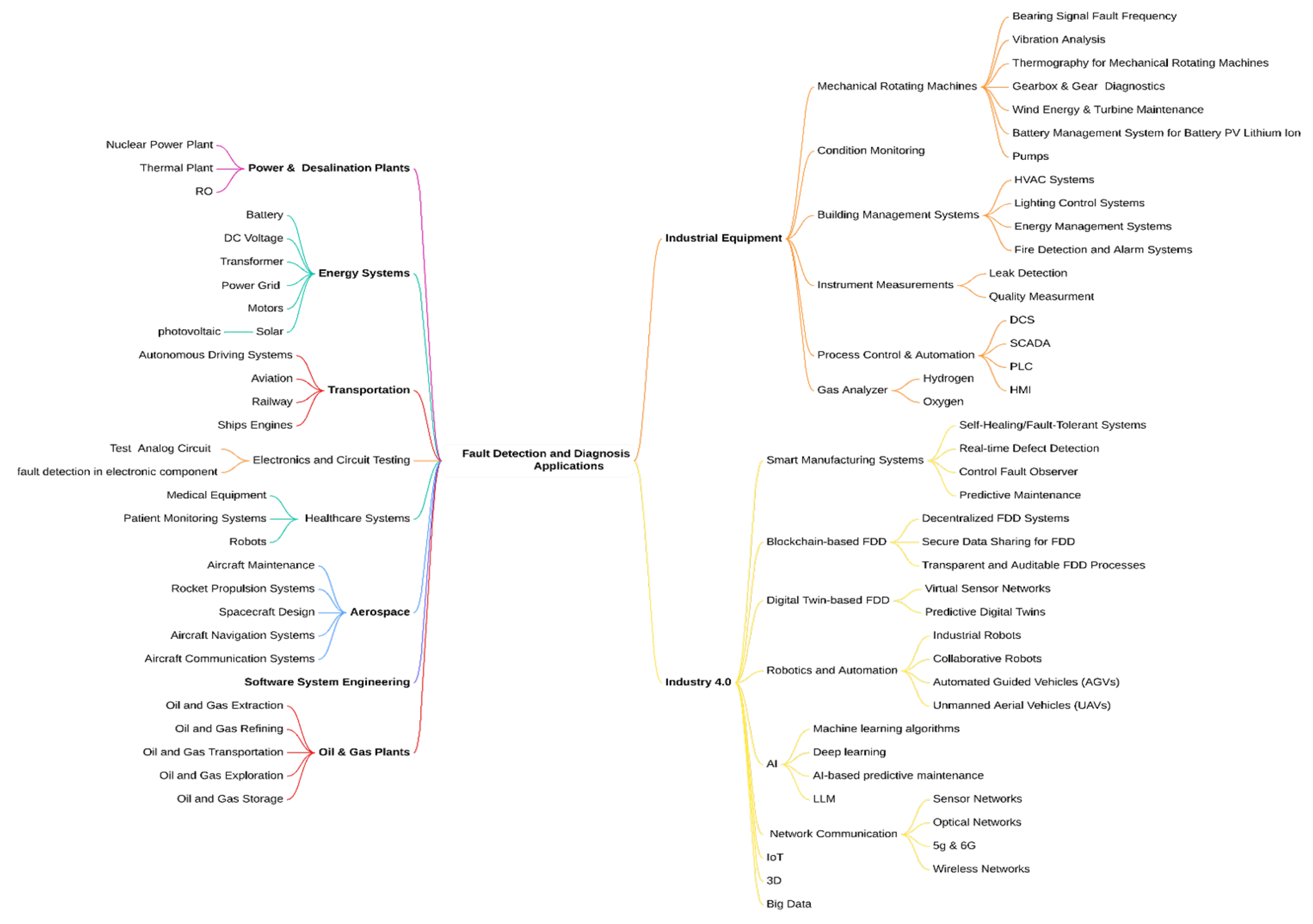
Subsequently, comprehensive and insightful taxonomies in FDD in terms of methods and applications were utilized, as shown in
Figure 2 and
Figure 3, respectively. The color coding helps readers quickly distinguish between different methodological categories in fault detection and diagnosis. In
Figure 2, the purple lines represent quantitative methods branches, red lines highlight data-driven approaches, and blue lines indicate qualitative methods. In
Figure 3, green lines highlights energy system applications, orange lines show industrial equipment branches, yellow emphasizes Industry 4.0 applications, and purple lines indicate power plant applications. With the use of BERTopic and GPT-4, this comprehensive review was essential because of the limited number of articles that explicitly address MM-LLM-based FDD, highlighting its status as an emerging technology and emphasizing the need for further research in this promising area. The resulting taxonomies provide a structured and easily navigable overview of the diverse FDD methods and their potential applications across various industrial sectors.
2.1. Industrial Equipment
In mechanical rotating machines, attention mechanisms and deep learning (DL) techniques, including deep convolutional neural networks (DCNNs) and transfer learning, enhance bearing fault diagnosis [
4,
6,
7]. The data-driven condition monitoring of industrial equipment has been reviewed, with a focus on various ML models [
16]. A Bayesian network model was proposed for the IoT-based fault diagnosis of intelligent instruments [
17]. Industrial equipment heavily depends on FDD methods, such as instrumentation [
17], gas analyzers, and oxygen monitoring [
18]. Process control applications, including SCADA [
19], PLCs [
20], and HMIs [
21] integrate FDD algorithms with a hybrid customized chatbot HMI using ChatGPT for swift equipment information retrieval [
22]. In the realm of hydraulic systems, a novel sensor fault estimation scheme for hydraulic servo actuators was proposed by Djordjevic et al. [
23] using sliding mode observers, and its effectiveness was shown via simulations. This approach addresses the difficulties of nonlinear systems and uncertainties in industrial hydraulic equipment. Tao et al. [
24] introduced a semi-supervised fault diagnosis method using a dynamic graph attention network with fuzzy K-nearest neighbors (KNNs) for planetary gearboxes. This method effectively addresses the challenge of limited labeled data in gearbox fault diagnosis, which achieves over 99% accuracy with very few labeled samples and outperforms traditional classification networks.
Additionally, a new multi-source partial transfer network model addresses real-world challenges in machinery fault diagnostics, including unknown label spaces and incomplete fault-type coverage. In employing class-level weight mechanisms and particle swarm optimization, the model combines shared feature extraction with domain-specific modules for fault diagnosis and adaptation. It was verified across six datasets, and its effectiveness in industrial equipment fault diagnosis was presented [
25].
2.2. Industry 4.0
I4.0 integrates AI, data mining, and IoT to revolutionize manufacturing. DL, particularly CNNs, has the potential for FDD in smart manufacturing [
26]. Digital twin collaboration aids in the auto-detection of erratic data at Energy 4.0 [
27]. A novel approach that combines circular economy, data mining, and AI has been proposed for FDD [
28]. Transfer learning has emerged as a valuable technique for predictive maintenance [
29]. Innovations have been developed in 3D printing fault diagnostics [
30,
31] and optimized CNN approaches for industrial robotics [
32]. Data security in industrial fault diagnosis is addressed by blockchain-based decentralized, federated transfer learning [
33]. Recent advancements in IoT-based fault diagnosis include an industrial IoT platform with an EML for transformer monitoring [
34], an IoT-based system using a one-dimensional (1D) CNN for PV plant monitoring [
35], and preprocessing techniques with DL models for industrial IoT (IIoT) devices [
36]. These approaches have shown improved accuracy, efficiency, and cybersecurity in fault diagnosis across various industrial applications.
In the context of fault estimation and fault-tolerant control, Wang et al. [
37] proposed a Q-learning-based approach using an iterative learning control framework. This method addresses the obstacles posed by unknown faults that vary with both the time and trial axes in repetitive tasks, exhibiting the effectiveness of adapting to changing faults and maintaining control performance in MIMO systems.
In the era of big data and advanced networking, the diagnosis of fiber optic cable faults in communication networks has become critical. A combined GAN-CNN approach obtained 98.5% accuracy in addressing these faults [
38]. DL enhances fault location and network maintenance efficiency [
39].
A Bayesian network-based mechanism ensures efficient real-time fault diagnosis in communication systems [
40]. For I4.0, a framework integrating LSTM, CNN, and GNN effectively handled heterogeneous data for fault detection [
41]. Advanced orchestration techniques utilizing self-organizing maps and root cause analysis improve fault detection in 5G infrastructure and beyond [
42]. A deep neural network-based method accurately diagnoses faults in millimeter-wave active phased arrays for 5G and 6G radios [
43]. Moreover, a new federated learning framework known as FedCAE was proposed for edge-cloud collaboration in machine fault diagnosis. In this approach, the challenge of data islands is addressed by allowing multiple data owners to contribute to model training without sharing raw data, thereby exhibiting promising results in bearing fault diagnosis [
44]. Furthermore, a comprehensive roadmap for performance-supervised plant-wide process monitoring in Industry 4.0 has been developed. This roadmap highlights the need to evaluate the impact of detected faults on plant-wide performance and proposes a technical route embedded in the cyber–physical–social system framework, which addresses key research questions and future directions in process monitoring [
45].
2.3. Power Plants
FDD techniques are indispensable in thermal and nuclear power plants. Advancements have focused on intelligent methods, which include model-based, data-driven, and statistical approaches [
46], which are applied to crucial equipment, including boilers, turbines, and heat exchangers. A robust soft sensor for estimating heat exchanger fouling in combustion thermal power plants was developed [
47]. In nuclear power plants and photovoltaic systems, ML-based fault diagnosis techniques, such as KNNs, support vector machines (SVMs), bagged trees, and ensemble methods, detect faults in pressurized water reactors [
48].
2.4. Electronic Systems
Numerous advanced techniques have been developed for the fault diagnosis and monitoring of electronic systems. SVMs have been applied for fault diagnosis in analog circuits [
49]. FRA-based parameter estimation has also been utilized to diagnose faults in three-phase voltage-source inverters [
50]. Recent advancements include the application of transformer-based networks for consumer electronic sensor fault diagnosis in the Internet of Everything era, addressing the challenges posed by environmental factors [
51]. In microelectronic manufacturing, a novel hierarchical tree–DCNN structure has been proposed to address unbalanced data diagnosis in flexible integrated circuit substrates, improving the efficiency and accuracy of traditional human visual interpretation methods [
52]. Moreover, joint self-attention mechanisms and residual networks have been used for the automated monitoring of intelligent sensors in consumer electronics, showing the potential for enhanced fault detection and classification in complex electronic systems [
53].
2.5. Energy Sector
Recent advancements in energy sector fault diagnosis include enhanced methods for lithium-ion batteries [
54], low-voltage direct current networks [
55], and transformers [
56]. CNNs perform superior power grid fault diagnosis [
57], whereas KG-CNN enhances the motor fault diagnosis [
58]. Photovoltaic systems benefit from infrared thermography and ML [
59]. Advanced models such as GPT-4 are being explored for building energy management and fault diagnosis systems [
60]. For integrated energy systems, a novel multiscale spatial–temporal graph neural network was proposed to address compound fault diagnosis with small sample sizes. This approach employs multiscale graph operators and gated recurrent units to learn label-specific fault features, hence mitigating the challenge of limited compound fault samples [
61].
In high-voltage circuit breaker fault diagnosis, a new method combining variational mode decomposition energy entropy and an SVM has been developed. This approach, validated on a 35 kV SF6 circuit breaker, effectively identifies faults, including actuator issues, buffer spring invalidity, and loose base screws [
62].
2.6. Transportation
FDD systems are important for transportation, autonomous driving, aviation, railways, and ship engines. In autonomous driving, CNN-based information fusion aids in sensor fault detection [
63]. Aviation utilizes biomimetic pattern recognition [
64] and deep neural networks [
65] for fault diagnosis. Railways benefit from hybrid methods [
66] and RP-CNN [
67] for track and wheel fault diagnosis. Digital twin-based methods [
68] and advanced fault feature extraction techniques [
69] optimize condition monitoring and fault diagnosis for ships.
2.7. Healthcare Systems
FDD systems have advanced in various applications. A hybrid HMM-SVM approach enables sensor fault diagnosis in IoT-based healthcare systems [
70]. For medical IoT devices, a lightweight autoencoder with KernelSHAP and an ANN classifies anomalies [
71]. Medical equipment failure prediction benefits from an optimized least squares SVM algorithm, which demonstrates high accuracy for ECG equipment and incubators [
72]. The integration of LLMs has further enhanced healthcare FDD systems, offering improved data management and diagnostic decision-making capabilities [
73]. Recent advancements include the development of hierarchical health assessment models for equipment with uncertain fault diagnosis results. Based on Bayesian networks, these models can assess health states at different hierarchical levels by incorporating identified and uncertain fault diagnosis results. This approach has been successfully employed in complex safety-critical systems, including diesel engine combustion systems, showing its potential for more comprehensive health monitoring and risk avoidance in medical equipment [
74].
2.8. Aerospace
Various innovative approaches have been developed for aerospace FDD applications. A PWM harmonic current-based method detects inter-turn short-circuit faults in FTPMSM drives [
75]. For liquid rocket engines, fault diagnosis methods can be categorized as signal processing, model-driven, and AI-based approaches [
76]. The LSTM-GAN method effectively detected faults in LOX/kerosene rocket engines [
77]. A hybrid AI technique, BGOA-EANNs, is superior for aerospace health diagnosis [
78]. The EMFFI approach, which employs bispectrum technology, SURF, LDA, and random forest (RF), attains a high accuracy in gearbox fault diagnosis for aerospace systems [
79].
2.9. Software System Engineering
For software fault diagnosis, diverse ML, XAI, and data mining methods have been developed. ChatGPT-based fault diagnosis using execution traces enhances the identification of bug causes [
80]. Data mining algorithms debug and compare software performance metrics [
81]. A combination of adaptive tracing, fault injection, and graph convolutional networks demonstrates superior accuracy in fault diagnosis for various software systems [
82]. Among the ML models evaluated for software fault diagnosis, XGBR showed the best performance in terms of accuracy and error metrics [
83].
Table 1 and
Table 2 provide a comprehensive overview of related studies on FDD systems using various models. It details the models employed, their application domains, and sectors of implementation and evaluates them based on ML and DL paradigms. Moreover, the table examines the relevance of I4.0 technologies and their real-time capabilities, generality, and support for multimodal data. The applications range from industrial equipment and power plants to healthcare and aerospace, which reflects the diverse applicability of these models. These studies highlight the diverse range of FDD methods and their broad applicability in various industries. However, its challenges, including generalizability, multimodality, applicability to I4.0, and real-time detection and diagnosis, require further exploration. The novelty of the proposed work lies in addressing these gaps by developing a robust multimodality FDD model that accounts for various types of data from different device applications while utilizing the LLM capability.
3. Methodology and Design
In this section, the methodology and design of the proposed multimodal LLM-based FDD system, which harnesses the power of multimodal architectures and LLMs, is discussed. The integration of these technologies aims to offer tailored and insightful diagnostic support solutions in the context of the I4.0 transformation and diagnostics for industrial systems. This section contains two main subsections: the design and dataset acquisition.
3.1. A Multimodality Framework and Architecture
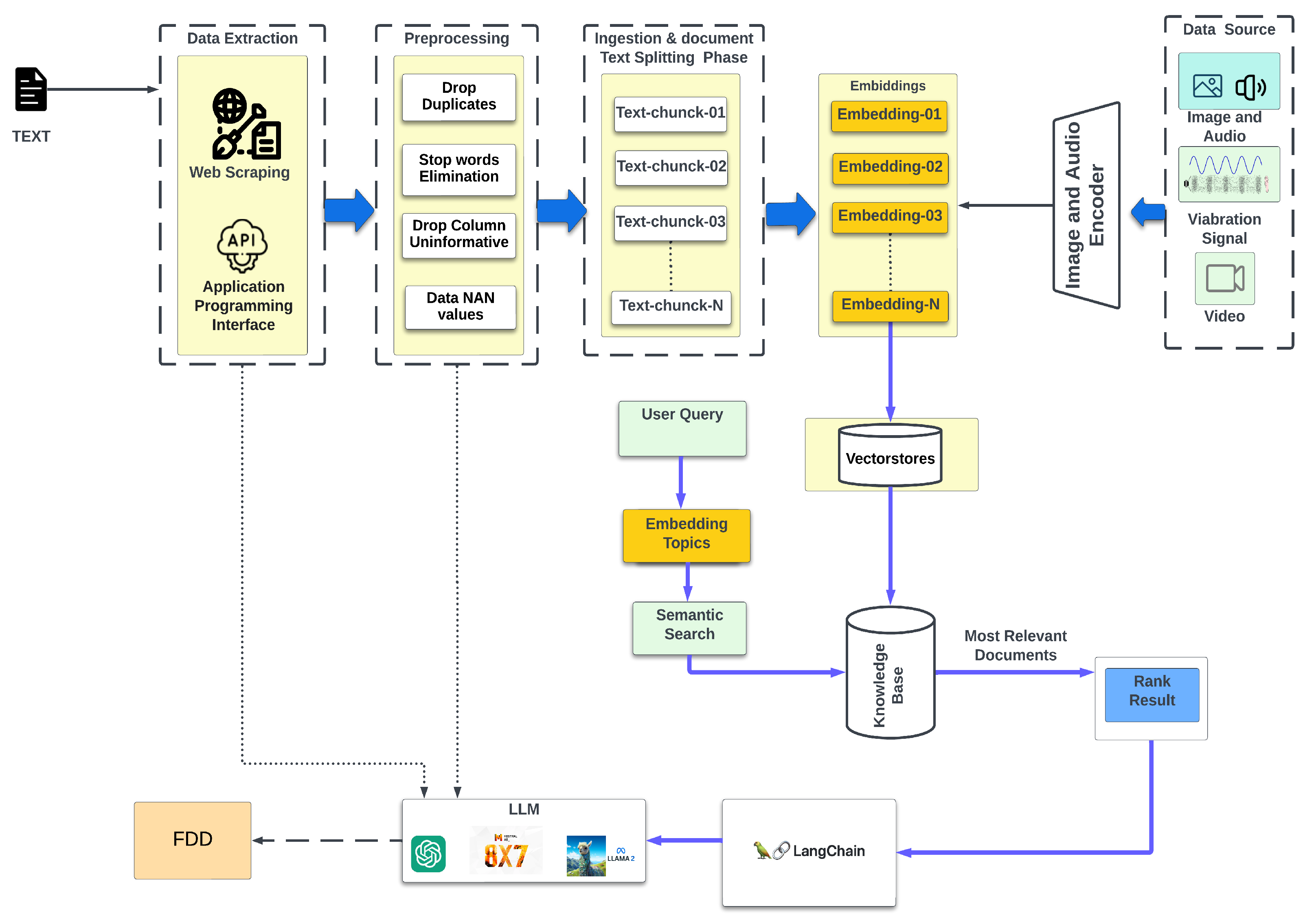
Figure 4 presents the proposed MM LLM-based FDD architecture. This novel approach integrates multimodal data sources and advanced ML techniques, mainly focusing on LLMs. The MM-LLM-based FDD framework proposes stages that enable effective FDD in complex systems, which is promising for revolutionizing the industrial domain.
The initial stage involves data sourcing and the collection of diverse data types, including images, audio, vibration signals, video, and text. These multimodal data were extracted via web scraping and application programming interfaces (APIs). LLMs can be utilized for data collection and processing.
In the preprocessing stage, the extracted data undergo various transformations to improve their quality and prepare them for further analysis. This includes drop duplication, stop word elimination, deep column transformations, and the handling of missing values. LLMs can be effectively utilized to enhance these tasks and improve the accuracy of duplicate removal, context-aware stop word elimination, and the intelligent handling of missing data.
The ingestion phase involves embedding techniques for converting text chunks into numerical representations that capture semantic or similarity relationships. These embeddings facilitate the effective utilization of LLMs in subsequent FDD stages. The knowledge base incorporates keywords, topics, embedding topics, and semantic or similarity search capabilities. Leveraging LLMs such as Llama 2 [
84], GPT [
85], and Mistral [
86], the framework extracts relevant information from embedded text chunks, enabling the identification of key insights and patterns for FDD.
The FDD component integrates state-of-the-art techniques such as LangChain [
87] or Llamindex [
88], a framework for building applications with language models. These techniques, which work in harmony with LLMs, can accurately detect and diagnose faults within the system. The accuracy and relevance of FDD components were assessed. Unsatisfactory results lead to iterative refinement, which loops back to the data-sourcing step, whereas satisfactory results are saved for decision making and fault management. This feedback mechanism guarantees the framework’s long-term efficacy and ongoing improvement. The proposed framework offers generality, flexibility, and scalability to various domains. Its integration of advanced preprocessing, a comprehensive knowledge base, and multimodality LLM ensures adaptability to diverse fault scenarios. This design significantly improves the accuracy and performance. With the LLM-based approach, a substantial improvement can be obtained over traditional methods.
3.2. Dataset Acquisition for LLM-Based FDD System
Our multimodal FDD system utilizes a comprehensive data acquisition approach that integrates diverse fault data, contextual information, and enriched technical knowledge. The dataset includes raw fault data, operational parameters, environmental conditions, maintenance records, and expert insights. Our data acquisition strategy encompasses two main types of sources.
3.2.1. Siemens Industry Online Support Forum
This primary source provides rich discussions on various Siemens products [
89], including the SIMATIC S5/STEP 5, SIMATIC 505, and SINUMERIK CNC systems. We extracted 240,000 rows across 22 columns from the SIMODRIVE converter system and SIMATIC S7 series, significantly improving the knowledge base of the FDD system.
3.2.2. Diverse Industrial Equipment Manufacturers
To ensure comprehensive training data diversity, we collected fault codes, descriptions, and corrective actions from multiple industrial control system manufacturers. As listed in
Table 3, the dataset comprises 1398 fault records gathered from major manufacturers, including Allen Bradley Studio 5000 Logix Designer (420 records), ABB Symphony Control (315 records), CLICK PLUS PLC (298 records), and Yokogawa Centum (365 records). These records encompass a wide range of industrial control system faults, from basic controller errors to complex system diagnostics. Each fault record contains detailed information, including fault codes, diagnostic procedures, corrective actions, equipment model specifications, and required technical expertise levels. The data collection spans various fault types, including controller faults, I/O faults, program faults, motion faults, CPU diagnostics, communication errors, system faults, and analog input issues. Prior to integration, the data underwent standardization preprocessing to ensure consistent terminology and format across different manufacturers. This comprehensive multi-vendor dataset strengthens our LLM-based framework’s capability to handle diverse industrial environments and fault scenarios effectively.
3.3. Data Preprocessing and Diversity
Data preprocessing involves multiple stages to ensure data quality and standardization. The initial preprocessing focused on redundancy removal through automated duplicate detection, eliminating repeated fault discussions, and similar troubleshooting procedures across our dataset. We implemented fault code standardization to ensure consistency across different data sources, which was particularly crucial for Siemens support forum data, where multiple format variations existed for the same fault codes. This standardization process maintained the technical accuracy while creating a uniform format for fault identification and classification.
The key information extraction phase concentrated on identifying critical troubleshooting steps, diagnostic procedures, and corrective actions. We implemented semantic parsing to structure the information hierarchically based on fault severity, complexity, and resolution requirements. The extracted data underwent validation against the original manufacturer documentation to ensure the accuracy and completeness of the technical information.
To enhance data quality, we utilized LLMs for contextual data cleaning and semantic categorization of fault descriptions. This process standardized technical terminology across different manufacturers while maintaining manufacturer-specific diagnostic information. The preprocessing ensured that each fault record, regardless of its source, contained a unique fault identifier, comprehensive fault description with symptoms, required diagnostic steps, and detailed corrective actions with verification procedures. This framework was consistently applied across all manufacturer data, including Allen Bradley, ABB, CLICK, and Yokogawa, preserving the technical integrity of manufacturer-specific characteristics while ensuring format uniformity essential for effective industrial fault diagnosis.
3.4. Hybrid LLM-Based Architectures for Online and Offline FDD Systems
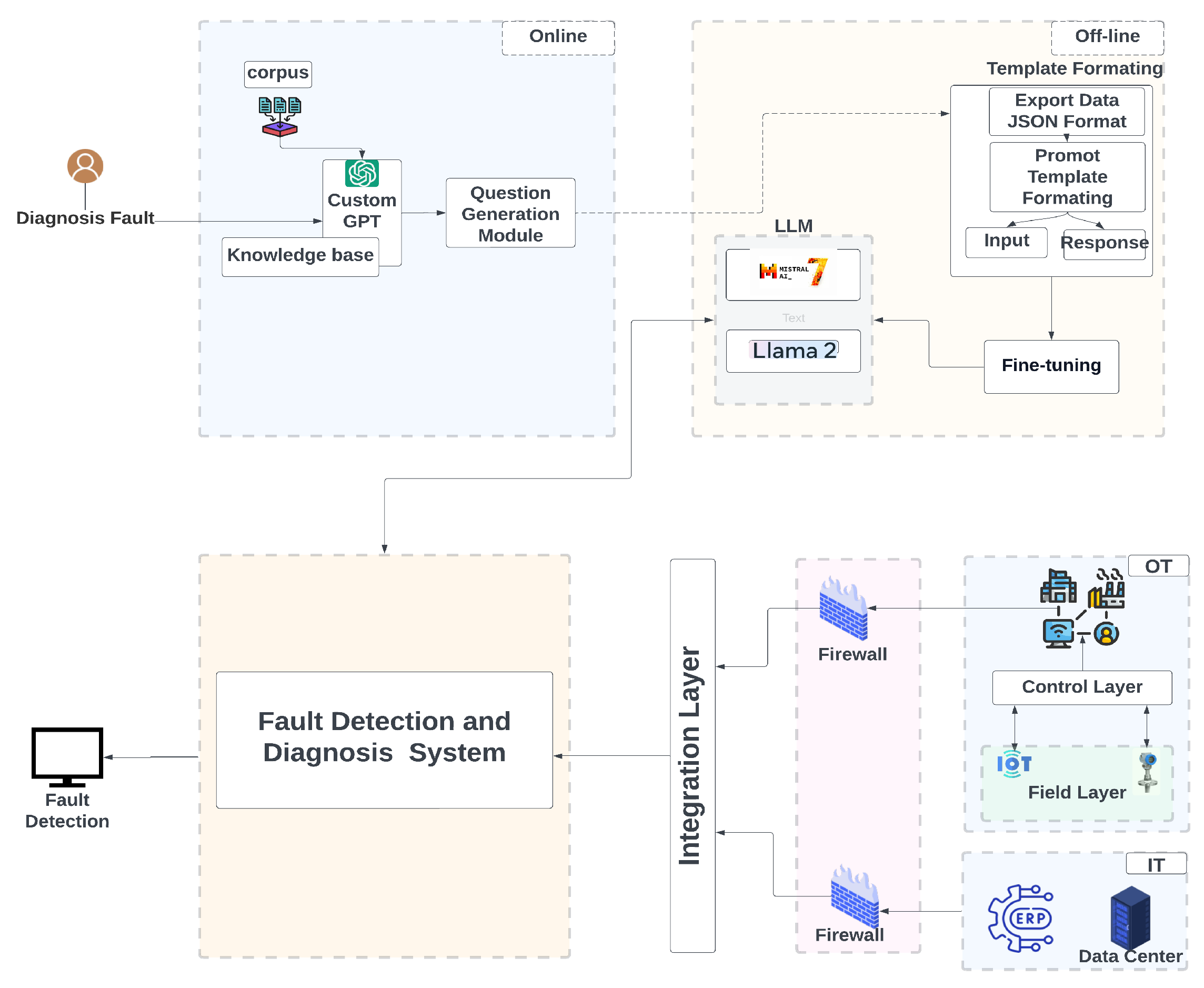
Figure 5 shows a hybrid LLM-based FDD architecture that optimizes FDD systems by integrating online and offline models and improving diagnostic capabilities, data privacy, and cybersecurity. The system processes unstructured data, generates embeddings, and utilizes a custom GPT model for query handling. Semantic indexing facilitates efficient knowledge retrieval. Offline LLMs, including Llama 2 and Mistral 7B, are fine-tuned with synthetic data to improve performance and address security concerns. The integration layer incorporates real-time data from various industrial sources, which enriches the diagnostic process. The architecture manages IT and operational technology (OT) complexities and ensures secure data flow through firewalls. This hybrid approach leverages real-time data integration and offline LLM processing, advancing the FDD system’s capability to handle real-time data and enhancing fault detection accuracy in I4.0 environments.
3.5. Security Framework and Implementation
In the context of Industry 4.0 environments, security considerations for LLM-based FDD systems are crucial due to the sensitive nature of industrial data. A comprehensive security framework should address data protection through multiple layers. The first layer should focus on API security, ensuring secure authentication and encryption for interactions with models like GPT-4-Preview, alongside data preprocessing mechanisms to anonymize sensitive information before transmission. This approach helps protect proprietary industrial information while maintaining diagnostic accuracy.
Network security represents another critical aspect, particularly the segregation of operational technology (OT) and information technology (IT) networks. This separation, achieved through demilitarized zones (DMZ) and industrial firewalls, helps prevent unauthorized access while enabling secure data exchange for diagnostic purposes. Traffic monitoring and anomaly detection systems can provide additional security layers without impacting system performance.
Knowledge base protection forms the third crucial component, requiring the secure storage of diagnostic information and comprehensive audit logging. The framework should support encrypted storage and secure update mechanisms while ensuring system accessibility for authorized users. This aspect is particularly important for maintaining the integrity of fault diagnostic data while enabling efficient system operation.
4. Evaluation
In this section, a comprehensive approach for assessing the performance and effectiveness of the proposed LLM-based FDD system is outlined. The metrics used for the evaluation include inference relevance accuracy, response time, and a custom performance score (PS) that combines accuracy and speed. This section describes our methodology for categorizing diagnostic questions into simple, medium, and complex types, thereby providing a nuanced understanding of a system’s capabilities across various fault scenarios. Additionally, the comparative process analysis between different LLMs, including ChatGPT4, Mixtral 8x7B, Llama 2, and our proposed FDD GPT-4-Preview model, is explained.
Moreover, a comparative analysis of conventional FDD and LLM-based FDD was applied. In this subsection, traditional FDD methods against the LLM-based approach are evaluated using the same performance metrics. The comparative analysis helps emphasize the advancements and potential improvements offered by integrating LLMs into FDD systems. By analyzing both approaches, we aimed to determine the specific benefits and limitations of LLM-based systems over conventional methods.
Additionally, the effectiveness of handling hybrid architecture performance in real-time and offline processing is evaluated. This includes assessing how well the system manages the immediate fault diagnosis needs versus a more detailed, offline analysis. In the section, the manner in which we assessed the system’s adaptability to different industrial contexts and its potential impact on I4.0 implementations is also addressed. By detailing these evaluation methods, we aimed to provide a clear and rigorous framework for understanding the strengths and limitations of the proposed FDD system.
4.1. Comparative Analysis of Different Models
In this section, four LLMs are thoroughly examined, all of which were implemented into the FDD system: ChatGPT4, Mixtral 8x7B, Llama 2, and our proposed model using GPT-4-Preview. Our assessment considered various metrics, which include inference relevance, response time, and PSs. Using these metrics, we systematically compared LLMs via quantitative measurements and evaluated their strengths and weaknesses.
4.1.1. Assessment Metrics
This study selected performance evaluation indicators to comprehensively assess LLM use in FDD systems. The proposed metrics included inference relevance categories, response time measurements, and a composite PS, providing a balanced assessment of accuracy and efficiency. The inference relevance categories (irrelevant, generic, relevant, precise) enable the detailed analysis of output quality, whereas the response time metrics address the critical aspect of real-time performance. The PS formula, which combines response quality and speed with adjustable weights for different response categories, allows for flexible prioritization based on specific industrial requirements, demonstrating the adaptability of our research to various contexts. We employed three key metrics to evaluate the model performance.
Inference Relevance
There are four categories of relevance metrics in fault diagnosis systems: relevant, irrelevant, generic, and precise. Relevant responses accurately address the specifics of the fault query, effectively understand the fault context, and provide solutions from a knowledge base. Irrelevant responses fail to address the fault, indicating the misinterpretation or retrieval of unrelated information. Precise responses deliver detailed and specific solutions that directly address faults using the targeted information. Although correct, generic responses lack the specificity of precise responses and offer broader and more general information. Equations (
1)–(
4) are employed to calculate the average inference relevance accuracy by summing the counts for each response type and dividing it by the total number of responses.
The average value for generic inference relevance, denoted as
, is calculated using (
1), summing all individual counts of generic responses, represented as
, where
refers to each generic response generated by the model and
m is the total number of results in the dataset. The average value for irrelevant inference relevance, denoted as
, was calculated using (
2), where
represents the summation of all individual irrelevant responses from the model, and
m is the total number of results in the dataset. Each
refers to an individual irrelevant response generated by the model. This calculation measures the tendency of the model to generate irrelevant responses across the dataset. The average value for the relevant inference relevance, represented as
, was determined using (
3), where
is the total sum of all relevant responses provided by the model, and
m is the total number of results in the dataset. Each
corresponds to the individual relevant response generated by the model. This formula effectively quantifies the ability of a model to produce responses that accurately address specific fault queries in a dataset. Equation (
4) calculates the precise answer, in which
is the total sum of all precise responses provided by the model, and
m is the total number of results in the dataset. Each
refers to the precise response of the model.
Response Time Analysis
Our model performance evaluation analyzed the maximum and minimum response times across all the models. These metrics provide insights into the extremes of response latency, which helps us to understand the range of performance variability. To quantify these measures, (
6) and (
7) were employed:
represents the maximum response time observed across all models, and denotes the minimum response time. Function returns the highest value in response times, whereas determines the lowest value. These equations allow us to establish the upper and lower bounds of the response time performance, which is crucial for the assessment of the efficiency and consistency of model responses.
4.1.2. Fault Categorization
We suggest organizing diagnostics to assess the troubleshooting requirements of different LLM industrial equipment models, incorporating both complexity levels and token utilization patterns. The questions were divided into three levels based on their computational demands and token consumption: simple (512–650 tokens), medium (845–1100 tokens), and complex (1280–2048 tokens). Simple diagnostic questions involve basic tests or common issues that can be identified and resolved with minimal technical expertise, such as addressing fault code T18, typically requiring around 580 tokens for processing. Medium diagnostic questions necessitate a more detailed examination, averaging 950 tokens, and potentially involve several steps or specific system knowledge, as observed with fault code T17, where specific runtime diagnostics must be conducted initially. Complex diagnostic questions entail extensive troubleshooting, consuming up to 2048 tokens, requiring an intricate understanding of the system’s inner workings and multiple diagnostic procedures. For instance, diagnosing a CPU fault in a Siemens S7-1500 system, as detailed in
Table 4, involves comprehensive diagnostic procedures to isolate and resolve the issue, which reflects the high level of complexity involved and demands maximum token allocation. This categorization enables efficient resource allocation and queue prioritization within API constraints while maintaining diagnostic accuracy across different complexity levels.
4.2. Comparative Analysis Between Conventional and LLM-Based FDD
In this subsection, the methodology for comparing a conventional FDD system based on traditional ML algorithms with the proposed LLM-based FDD system is outlined. The comparison is grounded in quantitative metrics, including accuracy, precision, recall, F1 score, and computational efficiency. To compare their effectiveness in classifying fault clusters, we utilized three models, namely, logistic regression (LR), RF, and a neural network (NN). The conventional ML-based FDD system was trained on Siemens PLC semantic S7 datasets with five fault categories (CPU/processor issues, power issues, input/output issues, communication issues, and other issues). To measure accuracy, we assessed the proportion of correct predictions made using the model out of the total number of predictions, providing an overall perspective on its performance across all fault categories. It was calculated using (
8) in which
= true positives,
= true negatives,
= false positives, and
= false negatives.
To measure precision, we evaluated the accuracy of positive predictions by focusing on the ratio of true positives to the total number of positive predictions, which include both true and false positives. The precision was calculated using (
9).
When evaluating the effectiveness of a model, recall (or sensitivity) measures its ability to correctly determine all relevant instances of a fault. This metric captures the ratio of true positive predictions to the total number of actual positives, including both true and false negatives. This was calculated using (
10).
The data and resource requirements for LLM-based and traditional FDD methods vary significantly, as shown in
Table 5. LLM-based approaches can leverage large volumes of unstructured data from diverse sources, excelling at processing natural language. At the same time, traditional methods are typically dependent on structured numerical data from sensors and predefined fault codes. LLMs are pre-trained on vast general knowledge and then fine-tuned for specific tasks, reducing domain-specific training data needs. By contrast, traditional ML models necessitate extensive labeled training data for each fault type and system. LLMs demand significant computational power, especially for training and real-time inference, whereas conventional methods are generally less computationally intensive. Nevertheless, LLMs offer greater adaptability to new fault types or systems through fine-tuning or prompt engineering, whereas traditional models often require retraining from scratch. LLMs provide natural language explanations, enhancing interpretability, and can integrate information across modalities more seamlessly.
5. Results and Discussion
In this section, the findings from our comparative study of four LLMs, namely, ChatGPT-4, Mixtral 8x7B, Llama 2, and our proposed FDD using the GPT-4-Preview model, are presented and analyzed. We evaluated their performance in the context of FDD applications, focusing on three key metrics: inference relevance, response time, and overall PS. This section also assesses the effectiveness of our proposed hybrid architecture in creating a dynamic and responsive FDD system in both online and offline systems. Moreover, we compared conventional FDD methods and our LLM-based approach in terms of accuracy and response time, underscoring the advancements and potential benefits of employing large language models for FDD.
5.1. Comparative Analysis of LLMs: Assessment Metrics and Practical Use Cases
We conducted a comparative analysis of various LLMs, which include ChatGPT 4, Mixtral 8x7B, Llama 2, and the proposed FDD GPT-4-Preview. The core objective was to evaluate the efficacy of these models in generating contextual questions derived from a specified knowledge base. Our methodology involved the systematic injection of 10 uniquely constructed questions into each LLM and the proposed models to assess their ability to produce relevant, irrelevant, precise, and generic responses.
5.1.1. A Comparison of Different LLMs
In the analysis of the comparative language models, as shown in
Table 6 and
Table 7, the GPT-4-Preview showed superior performance, which generates correct answers with 60% precision. This marks a significant improvement in the specificity of the responses compared with other models, as exemplified in
Table 8(a), where a precise response is provided for fault code T04:C31. ChatGPT 4 balanced specific and vague responses at 40% each but lacked precision, as shown in
Table 8(b), in which an irrelevant response is given for the same fault code. Llama 2 and Mixtral 8x7B models demonstrated the quickest response times but suffered in contextual relevance, with the highest rate of irrelevant responses at 50%. Llama 2 had the highest generic response rate of 40%, which indicates a more generalized understanding of prompts, as shown in
Table 9(b). GPT-4-Preview had a lower rate of irrelevant responses (20%), which suggests better contextual understanding. Although Mixtral 8x7B provided the fastest response times, this speed may come at the cost of contextual accuracy, although it still manages to provide relevant responses, as shown in
Table 9(a). Conversely, GPT-4-Preview offered more concise and accurate responses with moderate delay times, which indicates precise comprehension of complex inputs.
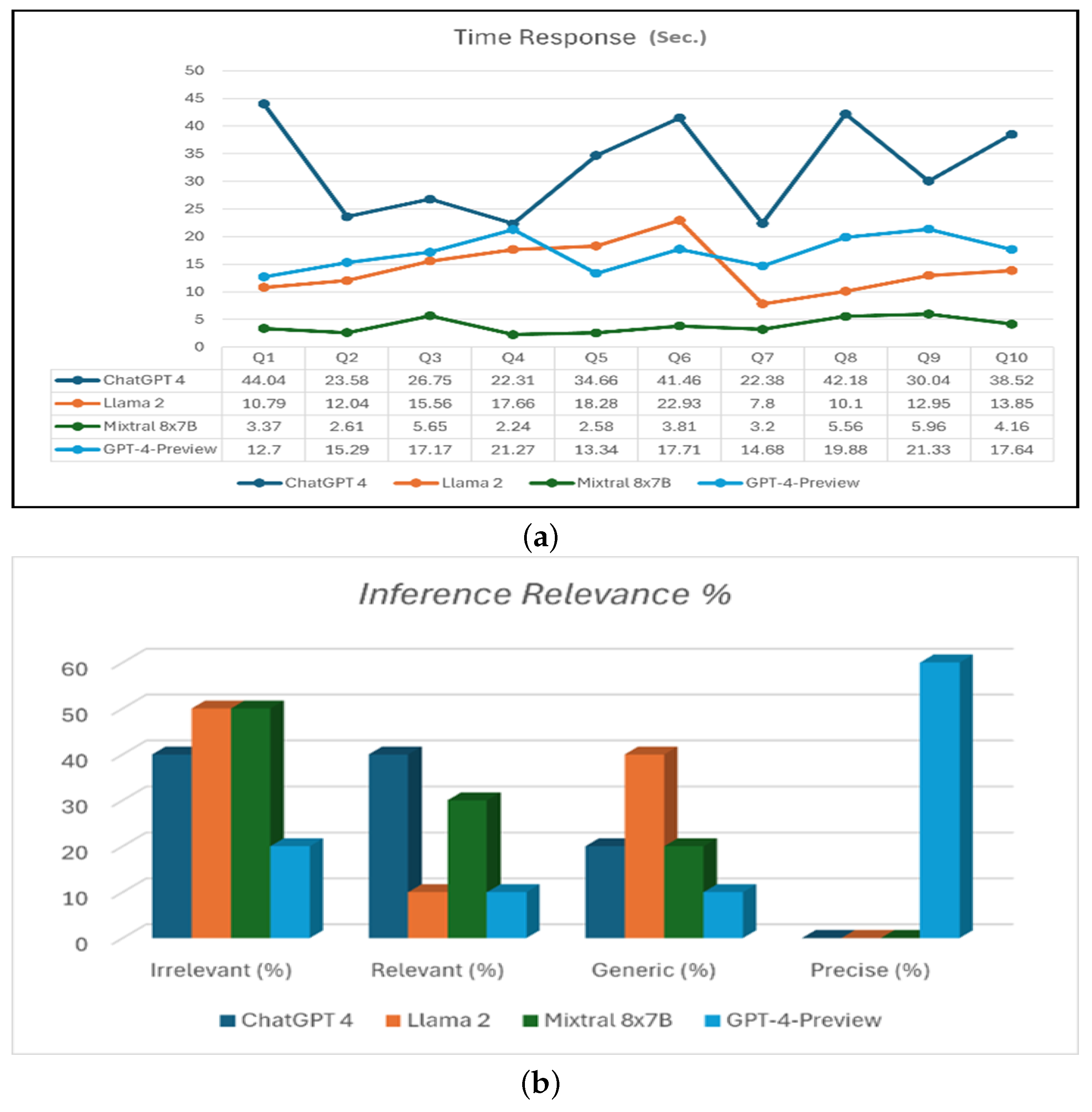
The response time analysis revealed significant variations. ChatGPT 4 presented a maximum response time (
) of 44.04 s and a minimum response time (
) of 22.31 s, which suggests deeper analysis but slower processing. Llama 2 improved this, with a (
) of 22.93 s and (
) of 7.8 s, showing enhanced efficiency. Mixtral 8x7B was notably fast, with a (
) of only 5.96 s and (
) of 2.24 s, showing rapid response generation. GPT-4-Preview balanced comprehensiveness and speed with a (
) of 21.33 s and (
) of 12.7 s.
Figure 6 illustrates response times, inference relevance, and PSs across 10 questions (Q1–Q10) for various LLMs. ChatGPT 4 consistently showed the highest response times, often exceeding 40 s, mainly for Q1, Q6, and Q8. Mixtral 8x7B maintained the lowest response times, staying below 6 s. Llama 2 and GPT-4-Preview exhibited moderate response times, with Llama 2 typically performing faster than GPT-4-Preview.
Table 6 summarizes the comparative analysis based on inference relevance categories and response time ranges. GPT-4-Preview showed higher precision in inference relevance, whereas Mixtral 8x7B excelled in minimum response time. Nevertheless, Mixtral 8x7B’s speed did not translate to inference relevance, as it shared the highest percentage of irrelevant responses with Llama 2. This suggests that although Mixtral 8x7B and Llama 2 process queries rapidly, GPT-4-Preview provides more accurate responses at the cost of slightly longer processing times. As a result of PS calculations for all models, ChatGPT 4(PS = 0.804) has the lowest PS, which indicates that it may be slower and less relevant than the other LLMs. Llama 2 (PS = 0.935) performs better than ChatGPT 4 but is not the best among the given models. Mixtral 8x7B (PS = 1.504) has a higher PS, which indicates that it is more efficient and relevant in its responses than the other two models. GPT-4-Preview (PS = 3.255) demonstrated the highest PS, which signifies superior efficiency and relevance in its responses. These results are summarized in
Figure 6c, which illustrates the LLM PSs.
In terms of scalability, our analysis of token consumption across different query complexities reveals that GPT-4-Preview maintains consistent performance despite the increased load. Simple queries (512–650 tokens) process in 13.77 s; medium queries (845–1100 tokens), in 17.38 s; and complex queries (1280–2048 tokens), in 21.33 s, showing a linear scaling pattern with the token count. This predictable scaling enables effective resource planning and queue management in industrial applications.
The feasibility of implementing the LLM-based FDD method in the industrial domain is substantiated by the results, both from the implementation and computational perspectives. Through existing APIs and open source frameworks, the integration of models such as GPT-4-Preview, ChatGPT 4, Mixtral 8x7B, and Llama 2 is achievable. The observed performance metrics, particularly the superior precision of GPT-4-Preview, indicate that model customization via fine-tuning, enriching the knowledge base, or prompt engineering is feasible and highly effective for FDD tasks. The range of response times (12.7–21.33 s) showed a trade-off between accuracy and computational efficiency. The PS metric exemplifies this trade-off, in which GPT-4-Preview’s higher PS of 3.255 justifies a suitable mode selection for critical industrial applications.
5.1.2. A Comparative Review of Results: LLM Versus Conventional FDD
In our quantitative analysis, we evaluated the performance of conventional and LLM-based FDD models across several key metrics. In
Table 10, the three traditional ML models (LR, RF, and NN) are compared with our proposed FDD GPT-4-Preview model. The results reveal a notable trade-off between response time and accuracy.
Conventional models showed superior speed, with LR leading at 0.0526 s, RF at 0.3445 s, and NN at 2.7168 s. By contrast, our GPT-4-Preview model requires 9.3 s for response. However, this increased processing time was offset by the model’s exceptional accuracy of 96.3%, surpassing that of the next best performer, RF, by 5.94 percentage points.
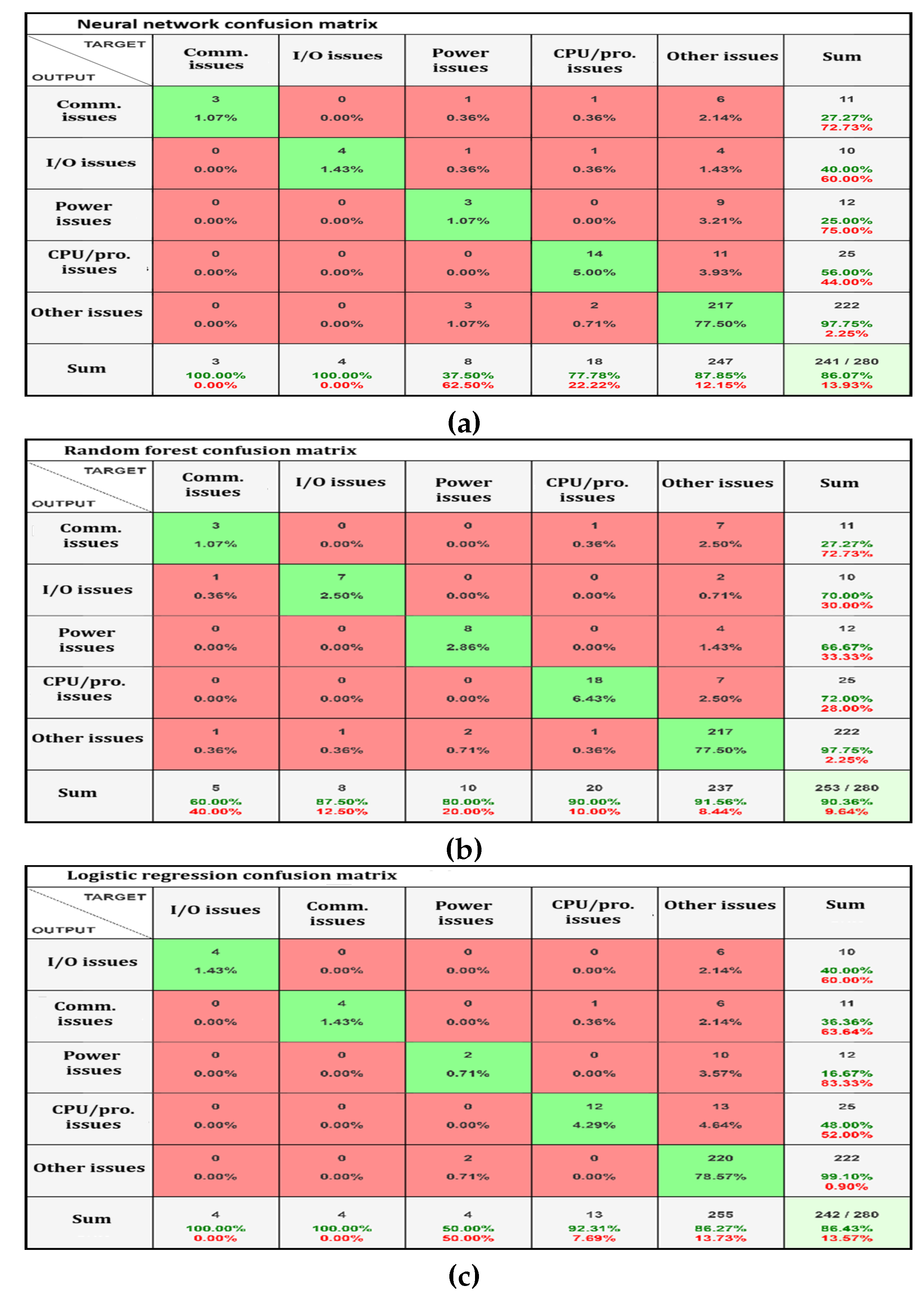
Examining the confusion matrices provides further insight into the strengths and weaknesses of each model. As shown in
Figure 7a, the NN model demonstrates strong performance in identifying “Other Issues” (97.75% accuracy) and moderate success with “I/O issues” (40% accuracy). However, it struggles with “Communication Issues” (27.27% accuracy) and “Power Issues” (25% accuracy), which indicates potential areas for improvement.
Figure 7b illustrates the RF performance model, which shows improved results across most categories compared to the NN. It excels in identifying “I/O issues” (70% accuracy) and “Power Issues” (66.67% accuracy). The model maintained high accuracy for “Power Issues” (97.75%) while showing significant improvement in “CPU/Prc. Issues” (72% accuracy).
The LR model, as shown in
Figure 7c, exhibits mixed results. It performs exceptionally well in identifying “Power Issues” (99.10% accuracy) but struggles with “Power Issues” (16.67% accuracy) and “CPU/Prc. Issues” (48% accuracy). Its performance on “I/O issues” (40% accuracy) and “Communication Issues” (36.36% accuracy) is moderate.
Although these traditional models offer rapid response times, their variable performance across different fault categories highlights the challenges in achieving consistent accuracy across all fault types. Beyond this quantitative measure, the GPT-4-Preview model, despite its longer processing times, offers superior overall accuracy and enhanced explainability. Our adaptable LLM-based approach can address new fault types through fine-tuning or knowledge-based utilization.
Traditional ML models (NN, RF, and LR) require rigorous training, testing, and validation. LLM-based FDD demonstrates superior contextual understanding when compared with conventional models. The combination of high accuracy, interpretability, and adaptability makes the GPT-4-Preview model particularly valuable for complex industrial diagnosis scenarios.
5.2. Use Case: Fine-Tuned LLM-Based Multistage FDD Process Workflow
Figure 8 shows the use case of the multistage process workflow to address user queries regarding equipment faults that employ a custom GPT model and Llama 2 to enhance diagnostic precision. In this workflow, a user initiates a query regarding a specific fault code, which is processed by the custom GPT model accessing a vector index constructed from a comprehensive document corpus of unstructured data, such as device manuals and fault records. The system’s question generator module formulates pertinent questions to refine the context and extract detailed information from the knowledge base.
Then, these refined data were fine-tuned using the Llama 2 model to ensure the accuracy of FDD. The system subsequently generates a detailed response encompassing diagnostic information, recommended resolution steps, and the associated equipment model details. For instance, a query regarding fault code 17.31 for the Siemens STEP device would result in a response that identifies the fault as a minor diagnostic fault, provides steps to resolve the issue, and specifies the related equipment model. This use case demonstrates the integration of advanced AI models into FDD systems, significantly enhancing the accuracy and timeliness of fault diagnostics and recommendations, thereby supporting robust industrial operations. The system generates answers using both the base and fine-tuned models, highlighting the difference in accuracy between them. The process begins when the user enters a query. Custom GPT processes the user’s query by accessing the vector index and retrieving relevant information from the corpus, as shown in
Figure 8. As part of refining the response, the system includes a question generator module that formulates relevant questions based on the initial user query, ensuring that detailed and relevant information is gathered from the knowledge base.
Figure 9 presents a table of questions and answers that are likely utilized as training data for fine-tuning. The system generates answers using both the base and fine-tuned models, emphasizing the difference in accuracy between them.
Figure 10 shows the base model answer, irrelevant to the fine-tuned model’s response.
Furthermore, the system allows users to upload a JSON data file to fine-tune the model. The interface indicates the progress and completion of the fine-tuning process, as shown in
Figure 11a,b, giving the user complete control of the fine-tuning process. The fine-tuned Llama 2 model then processes this refined data further, enhancing the diagnostic accuracy and relevance of the system’s responses. With the integration of these components, the workflow ensures that the FDD system can provide precise and contextually relevant responses.
5.3. Parameter Tuning and PS Optimization
Optimizing the performance of the proposed method requires a systematic approach to parameter tuning, focusing on maximizing the PS. Key strategies include reducing the average response time () by selecting appropriate LLMs, employing effective preprocessing techniques, using high-quality datasets for fine-tuning, and optimizing vector database configurations. Fine-tuning is critical, as parameters such as the learning rate, number of epochs, and batch size significantly affect model performance. Moreover, the choice of embedding technique and its dimensionality can significantly influence the quality of fault representation and retrieval efficiency from the vector database. The indexing method and similarity search algorithms within the vector database must be carefully considered to achieve an optimal balance between speed and accuracy.
5.4. Limitations and Challenges of LLM-Based FDD
Despite the GPT-4-Preview model achieving a 96.3% accuracy in fault diagnosis, outperforming conventional models, several limitations were determined. A significant challenge lies in the model’s lack of true understanding and commonsense reasoning. In approximately 3.7% of cases, the model produced responses that were syntactically correct but contextually inaccurate. Moreover, instances of hallucination were observed, where the model generated irrelevant or factually incorrect responses in approximately 10% of cases.
Our analysis revealed specific biases in the GPT-4-Preview model’s fault diagnosis capabilities. When handling ambiguous cases, the model demonstrated a tendency to attribute faults more frequently to CPU/processor issues rather than input/output issues, indicating a systematic bias in fault classification. Bias manifestation occurs primarily through hallucination in complex fault scenarios, over-attribution to common fault types, and inconsistent response patterns in ambiguous cases. While our current implementation demonstrates high overall accuracy, addressing these biases is crucial for industrial applications.
Future implementations should consider training data diversification with balanced fault type representation, the implementation of post-generation validation, and prompt engineering optimization for balanced fault attribution. These bias patterns indicate the importance of human oversight in critical diagnostic decisions, particularly in cases where the model shows uncertainty or inconsistent response patterns. The integration of human expertise with AI capabilities remains essential for ensuring reliable fault diagnosis in industrial settings.
Computationally, fine-tuning a GPT-4 model on a dataset comprising 52,464 words (approximately 69,952 tokens), including fault data from diverse industrial equipment manufacturers over 10 epochs, is computationally intensive. With an NVIDIA V100 GPU, this operation is estimated to take around 3 h. Moreover, the fine-tuning process incurs significant financial costs due to the resources required for computation and model optimization. For resource-constrained environments, several optimization approaches could be considered. The local preprocessing and caching of common fault patterns could reduce dependency on external API calls. Token optimization strategies could allocate resources based on fault complexity: simple (512–650 tokens), medium (845–1100 tokens), and complex diagnoses (1280–2048 tokens). Such approaches would enable smaller enterprises to balance diagnostic capability with resource constraints.
Context management emerged as a significant challenge, but we were able to overcome it. We were initially limited by the model’s token window size of 8192 tokens. However, we integrated tools, including LangChain and LlamaIndex, which enable dynamic document retrieval and sophisticated text-splitting and vector storage techniques.
Finally, reliability in real-time diagnosis is still a significant area for improvement. The model exhibited inconsistent response times, with the most extended delay recorded at 21.27 s for specific fault scenarios. Such variability, especially in real-time industrial applications, can negatively impact reliability, which highlights the need to optimize both model selection and response strategies to meet the strict timing demands of industrial FDD systems.
While our framework demonstrates adaptability across multiple industrial systems, its performance in novel environments requires further validation. Future work should focus on expanding the training dataset diversity and implementing continuous learning mechanisms to improve generalization to unseen fault scenarios.
6. Conclusions
In conclusion, in this research, a novel approach to FDD in industrial systems is presented, leveraging LLMs and multimodal data analysis within Industry 4.0. Our proposed multimodal framework, which incorporates diverse data sources, has significantly advanced industrial diagnostics. Specifically, our FDD GPT-4-Preview model showed superior performance with 96.3% accuracy in fault diagnosis, surpassing traditional methods such as RF (90.36%) and NNs (86.07%).
The proposed FDD GPT-4-Preview model achieved a PS of 3.255, significantly outperforming other models such as Mixtral 8x7B (1.504) and ChatGPT 4 (0.804). It also demonstrated superior performance in relevant diagnostic information across various fault scenarios, with 60% of the responses classified as precise compared to 0% for other models. This study significantly contributes to the application of AI techniques in industrial settings. The proposed framework is a substantial step toward developing more sophisticated diagnostic support tools, offering a 5.94-percentage-point improvement in accuracy over the next best conventional model while providing enhanced explainability through natural language responses.
By contrast, a hybrid architecture was proposed that combines real-time data streams with fine-tuned LLMs to effectively create a dynamic and responsive FDD system. Our fine-tuned model consistently outperformed the base model, which exhibits enhanced accuracy and contextual understanding in fault diagnosis scenarios.
Although the results are promising, further research is necessary to fully realize the potential of LLM-based FDD systems in various industrial contexts. To enhance data security and confidentiality in industrial settings, future work should explore integrating emerging technologies, including blockchain. The decentralization and immutability of blockchain could provide a robust foundation for securing sensitive diagnostic data and ensuring the integrity of FDD processes.
Moreover, fostering vital collaboration between humans and machines through human-in-the-loop systems can further enhance the outcomes of LLM-based diagnostics. This collaborative approach leverages human expertise to validate and refine AI-generated insights, potentially leading to more accurate and contextually appropriate fault diagnosis. Through combining advanced AI techniques with secure data management and human oversight, more trustworthy and effective FDD systems that meet the complex demands of Industry 4.0 environments can be created.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}