
Apple Defect Detection in Complex Environments


Abstract
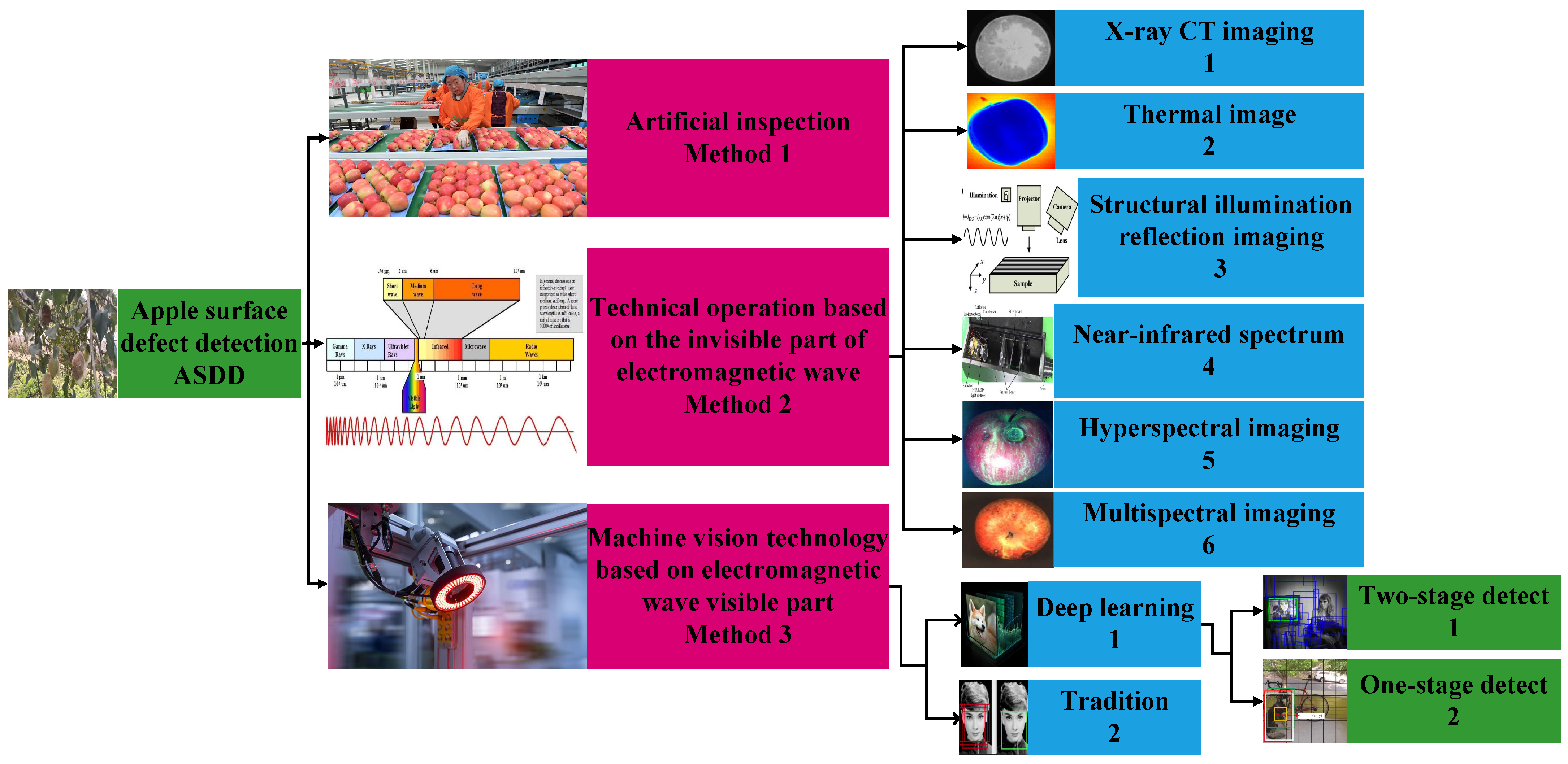
1. Introduction
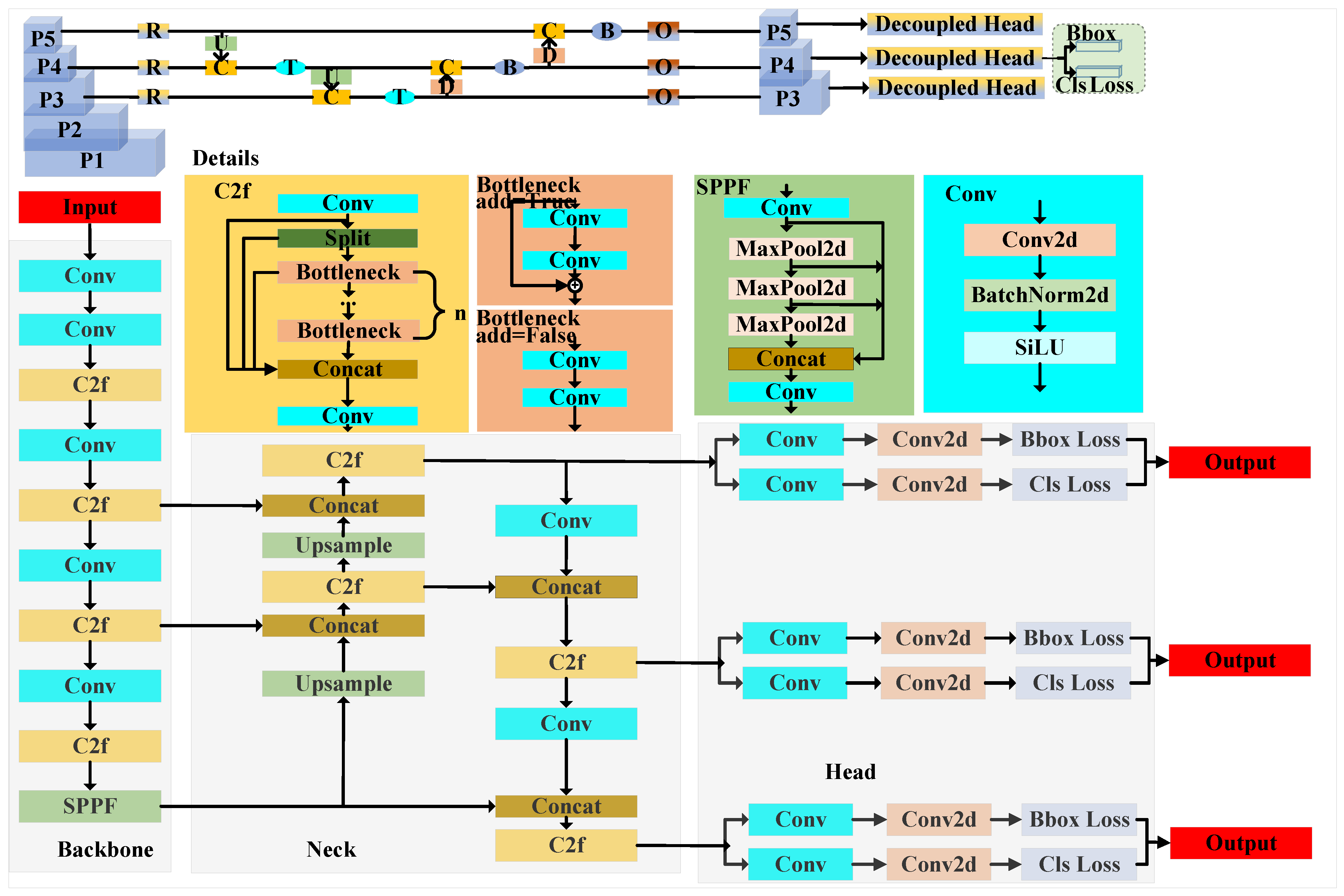
2. Overview of YOLOv8 Target Detection
3. Materials and Methods
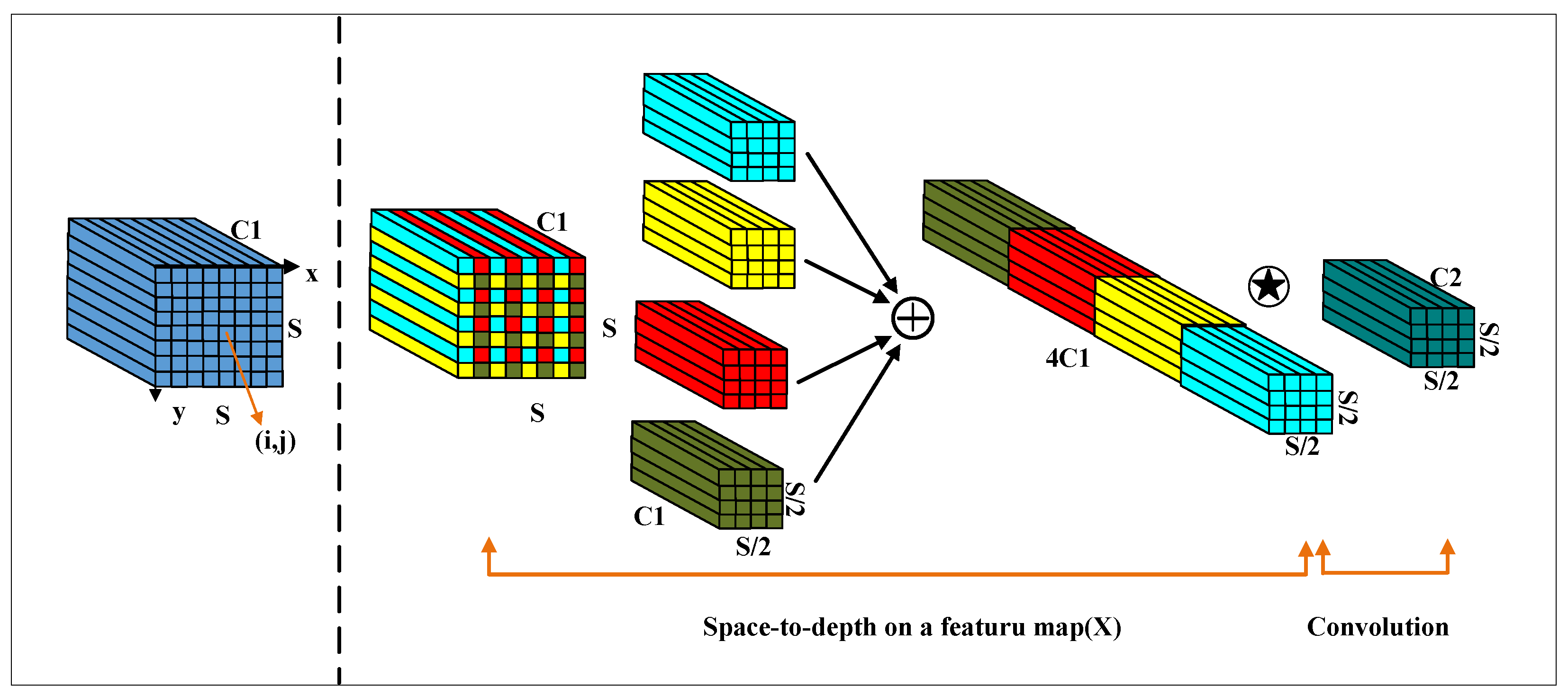
3.1. Tools for Low-Definition and Small Object Recognition
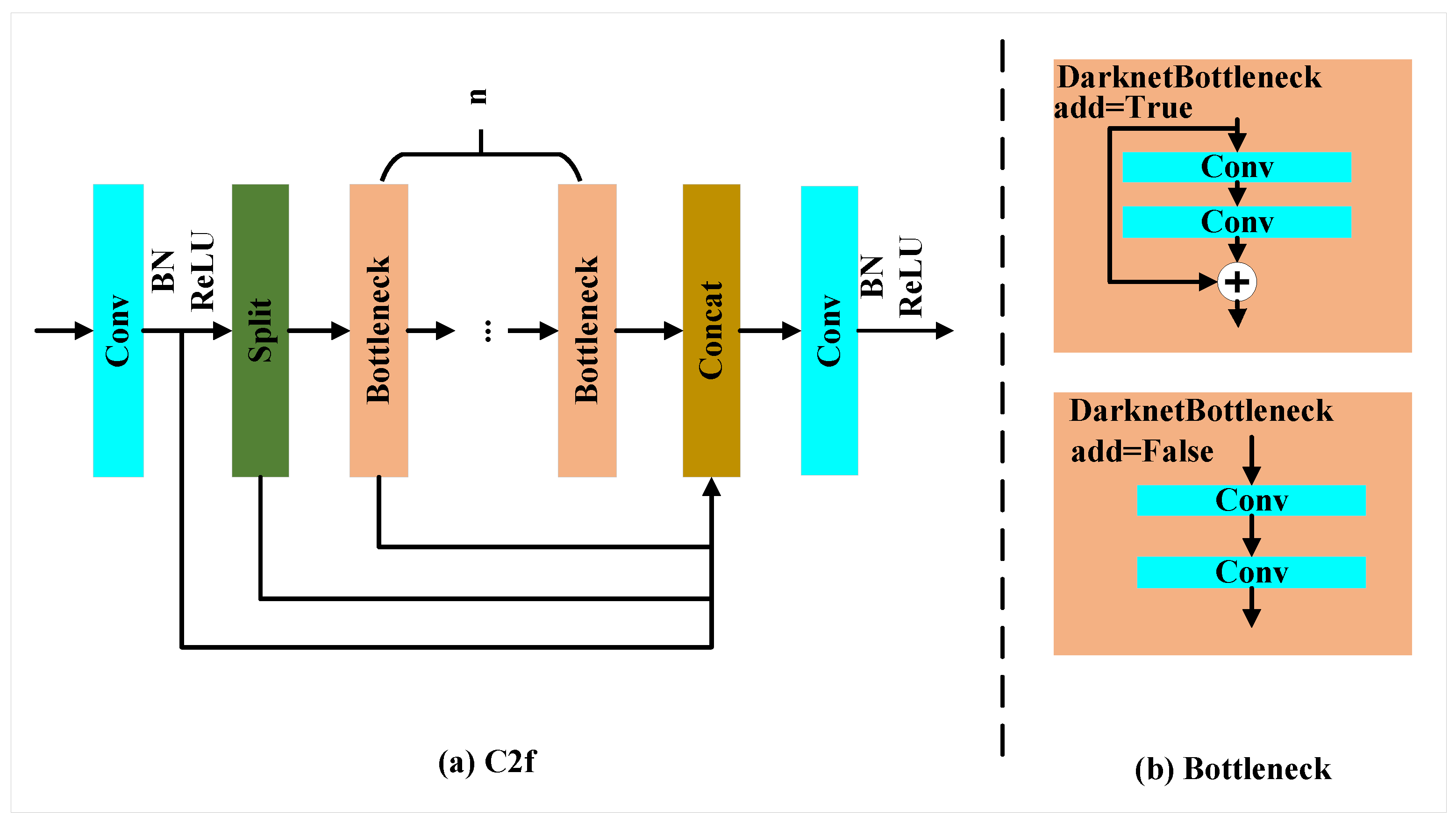
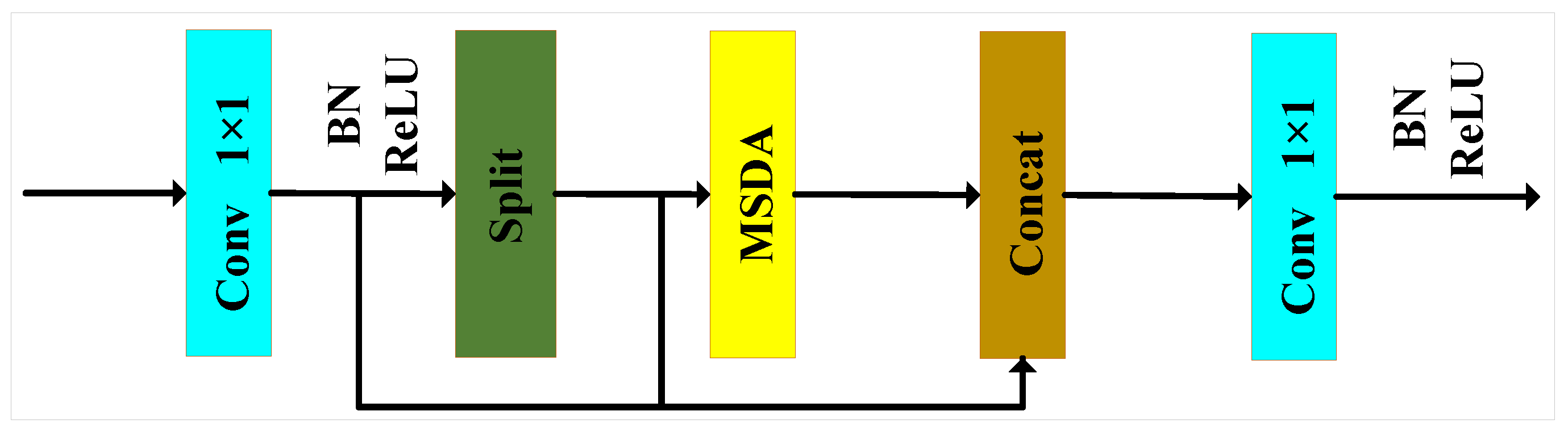
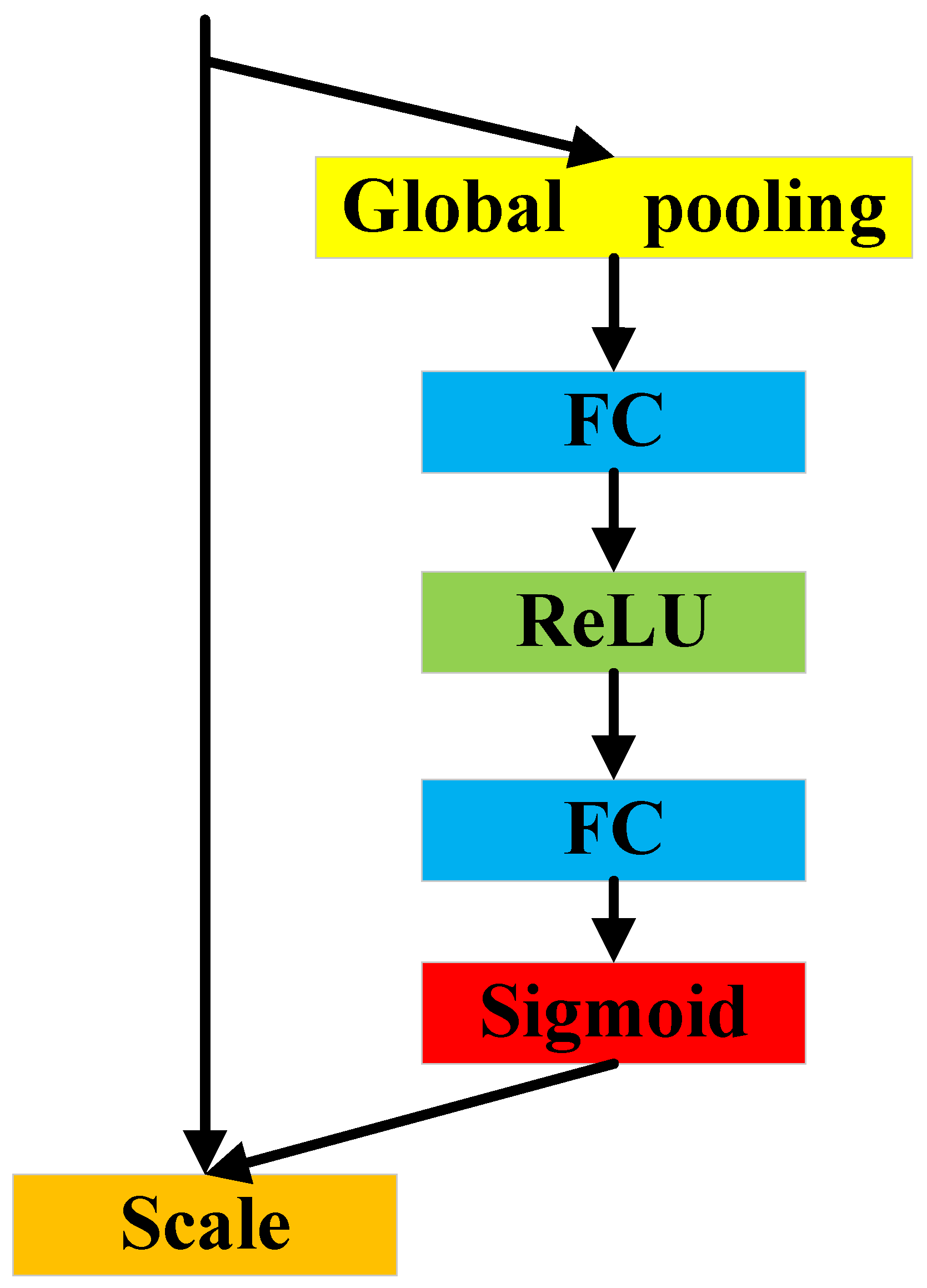
3.2. C2f-MSDA
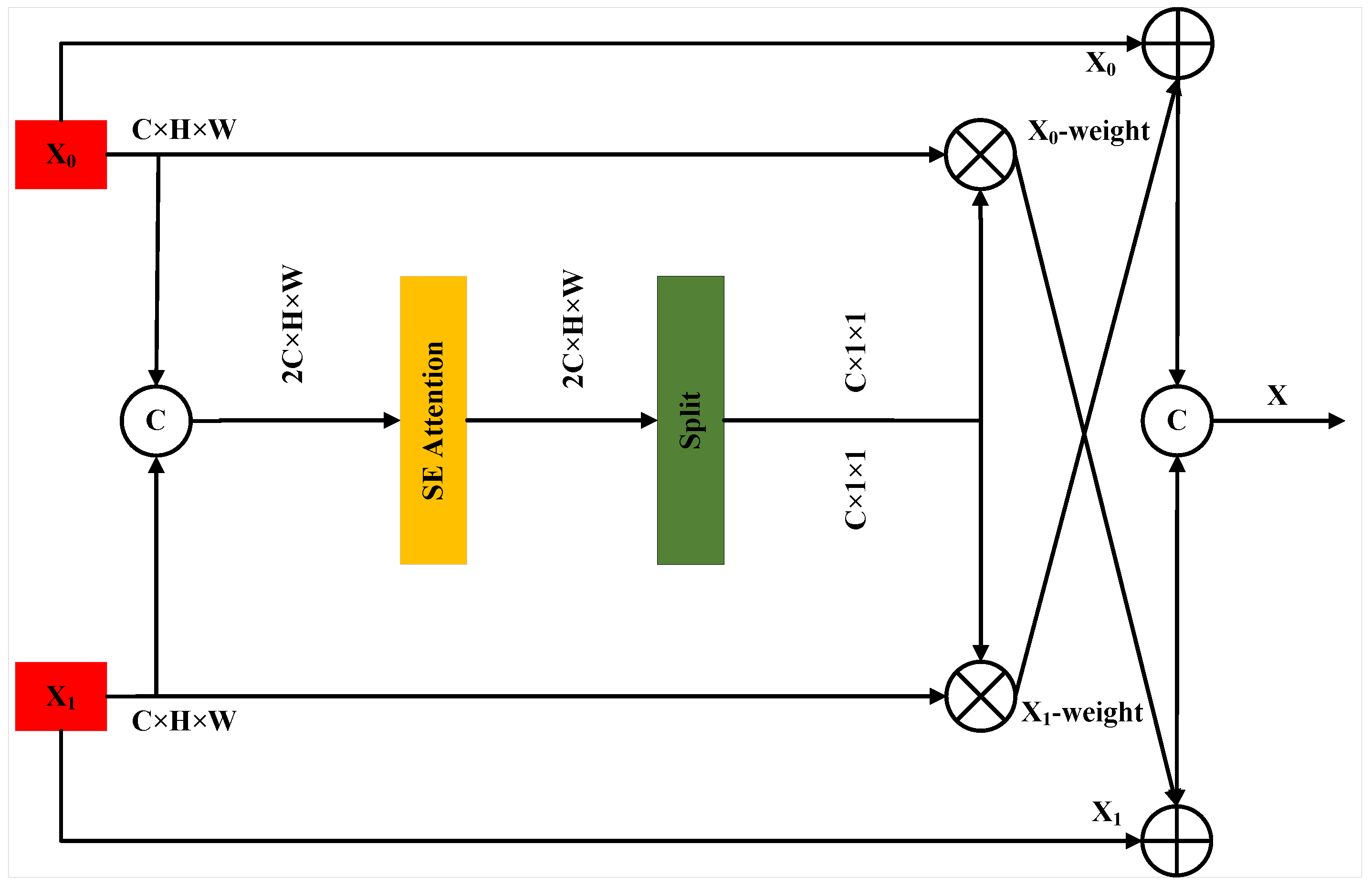
3.3. Context Guided Feature Pyramid Network
3.4. Overall Network Architecture
4. Experimental Results and Analysis
4.1. Experimental Environment and Parameter Configuration
4.2. Data Sets and Preprocessing
4.3. Evaluating Indicator
4.4. Experimental Result
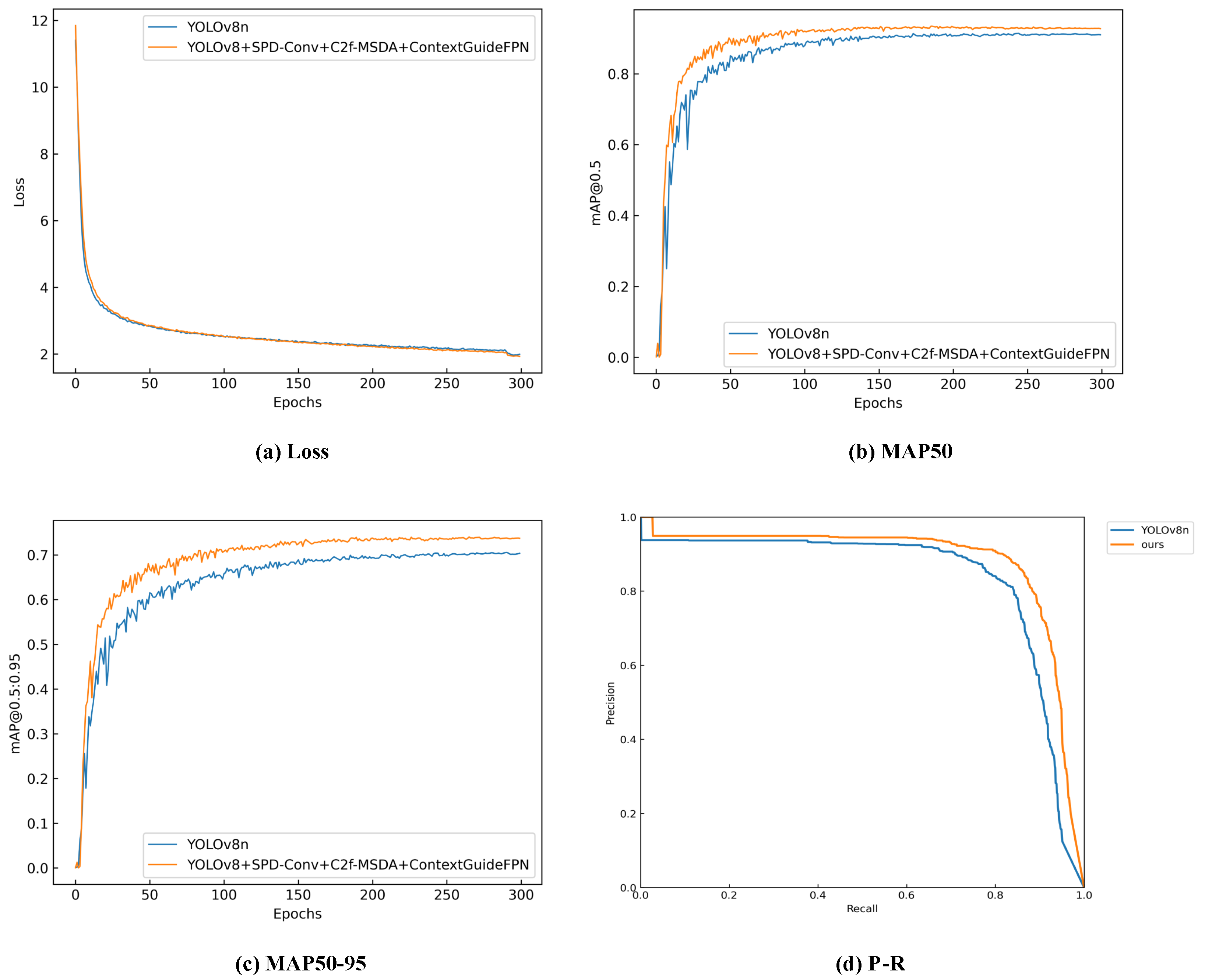
4.4.1. Ablation Experiment
4.4.2. Contrast Test
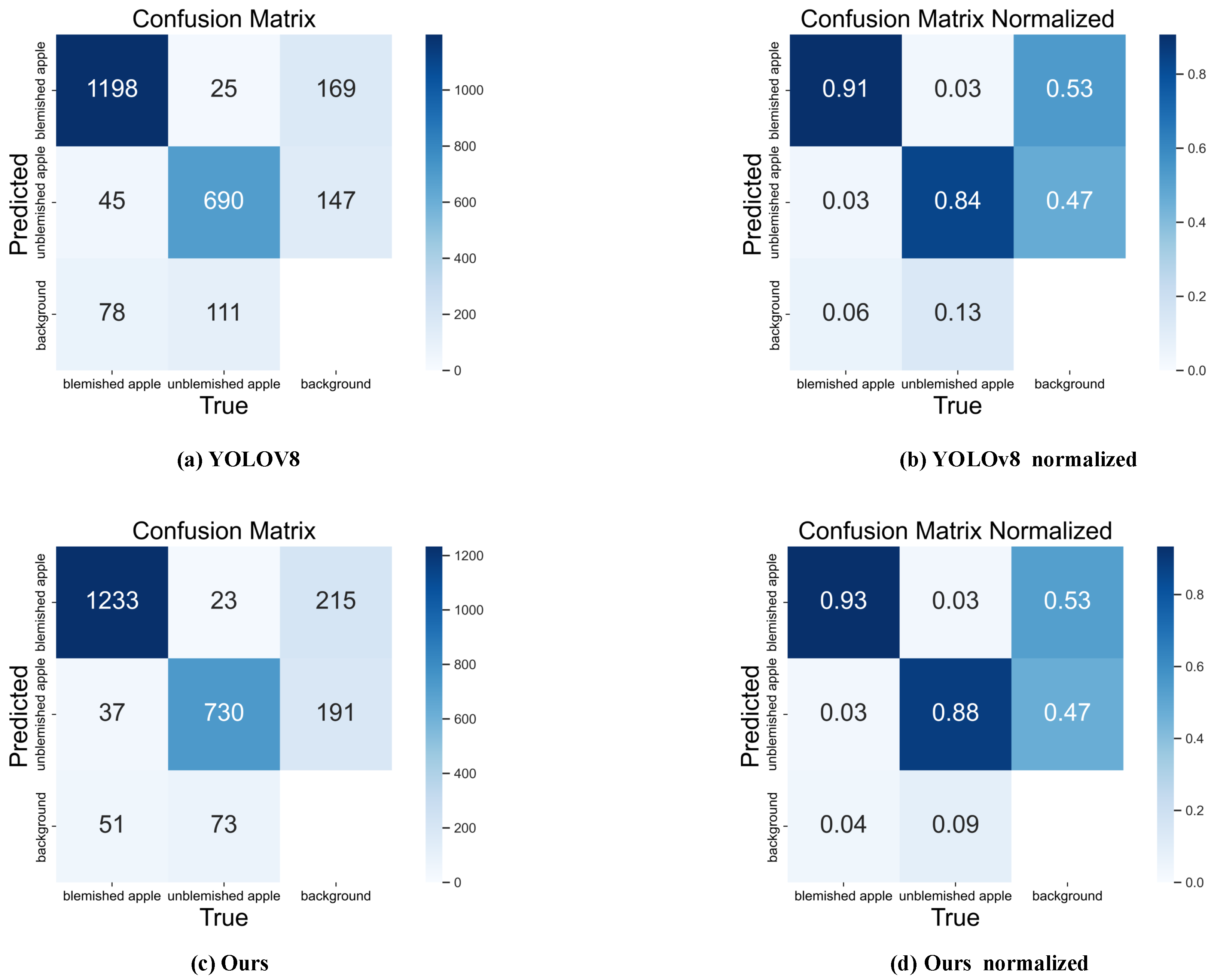
4.4.3. Visualization of Test Results
4.4.4. Verify the Generalization of the Proposed Algorithm
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, W.; Zhang, J.; Guo, B.; Wei, Q.; Zhu, Z. An Apple Detection Method Based on Des-YOLO v4 Algorithm for Harvesting Robots in Complex Environment. Math. Probl. Eng. 2021, 2021, 7351470. [Google Scholar] [CrossRef]
- Gao, X.; Bian, X. Autonomous driving of vehicles based on artificial intelligence. J. Intell. Fuzzy Syst. 2021, 41, 4955–4964. [Google Scholar] [CrossRef]
- Su, W.; Xu, G.; He, Z.; Machica, I.K.; Quimno, V.; Du, Y.; Kong, Y. Cloud-Edge Computing-Based ICICOS Framework for Industrial Automation and Artificial Intelligence: A Survey. J. Circuits Syst. Comput. 2023, 32, 2350168. [Google Scholar] [CrossRef]
- Guo, X.; Shen, Z.; Zhang, Y.; Wu, T. Review on the Application of Artificial Intelligence in Smart Homes. Smart Cities 2019, 2, 402–420. [Google Scholar] [CrossRef]
- Zhong, G. Application and Development of Artificial Intelligence in Medical Field. Digit. Technol. Appl. 2019, 37, 195–196. [Google Scholar]
- Siddiqi, R. Automated apple defect detection using state-of-the-art object detection techniques. SN Appl. Sci. 2019, 1, 1345. [Google Scholar] [CrossRef]
- Herremans, E.; Melado-Herreros, A.; Defraeye, T.; Verlinden, B.; Hertog, M.; Verboven, P.; Val, J.; Fernández-Valle, M.E.; Bongaers, E.; Nicolaï, B.M.; et al. Comparison of X-ray CT and MRI of watercore disorder of different apple cultivars. Postharvest Biol. Technol. 2014, 87, 42–50. [Google Scholar] [CrossRef]
- Doosti-Irani, O.; Golzarian, M.R.; Aghkhani, M.H.; Sadrnia, H.; Doosti-Irani, M. Development of multiple regression model to estimate the apple’s bruise depth using thermal maps. Postharvest Biol. Technol. 2016, 116, 75–79. [Google Scholar] [CrossRef]
- Lu, Y.; Li, R.; Lu, R. Structured-illumination reflectance imaging (SIRI) for enhanced detection of fresh bruises in apples. Postharvest Biol. Technol. 2016, 117, 89–93. [Google Scholar] [CrossRef]
- Jarolmasjed, S.; Zúñiga Espinoza, C.; Sankaran, S. Near infrared spectroscopy to predict bitter pit development in different varieties of apples. J. Food Meas. Charact. 2017, 11, 987–993. [Google Scholar] [CrossRef]
- Zhang, B.; Liu, L.; Gu, B.; Zhou, J.; Huang, J.; Tian, G. From hyperspectral imaging to multispectral imaging: Portability and stability of HIS-MIS algorithms for common defect detection. Postharvest Biol. Technol. 2018, 137, 95–105. [Google Scholar] [CrossRef]
- Mizushima, A.; Lu, R. An image segmentation method for apple sorting and grading using support vector machine and Otsu’s method. Comput. Electron. Agric. 2013, 94, 29–37. [Google Scholar] [CrossRef]
- Ji, Y.; Zhao, Q.; Bi, S.; Shen, T. Apple Grading Method Based on Features of Color and Defect. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 5364–5368. [Google Scholar] [CrossRef]
- Nosseir, A.; Ahmed, S.E.A. Automatic Classification for Fruits’ Types and Identification of Rotten Ones Using k-NN and SVM. Int. J. Online Biomed. Eng. 2019, 15, 47. [Google Scholar] [CrossRef]
- Liang, X.; Jia, X.; Huang, W.; He, X.; Li, L.; Fan, S.; Li, J.; Zhao, C.; Zhang, C. Real-time grading of defect apples using semantic segmentation combination with a pruned YOLO V4 network. Foods 2022, 11, 3150. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Fan, S.; Liang, X.; Huang, W.; Zhang, V.J.; Pang, Q.; He, X.; Li, L.; Zhang, C. Real-time defects detection for apple sorting using NIR cameras with pruning-based YOLOV4 network. Comput. Electron. Agric. 2022, 193, 106715. [Google Scholar] [CrossRef]
- Yu, J.; Fu, R. Lightweight YOLOV5S-Super Algorithm for Multi-Defect Detection in Apples. Eng. Agríc. 2024, 44, e20230175. [Google Scholar] [CrossRef]
- Han, B.; Lu, Z.; Dong, L.; Zhang, J. Lightweight Non-Destructive Detection of Diseased Apples Based on Structural Re-Parameterization Technique. Appl. Sci. 2024, 14, 1907. [Google Scholar] [CrossRef]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, W.; Zhuang, J.; Zhang, R.; Du, X. Detection Technique Tailored for Small Targets on Water Surfaces in Unmanned Vessel Scenarios. J. Mar. Sci. Eng. 2024, 12, 379. [Google Scholar] [CrossRef]
- Sunkara, R.; Luo, T. No more strided convolutions or pooling: A new CNN building block for low-resolution images and small objects. arXiv 2022, arXiv:2208.03641. [Google Scholar]
- Ha, Y.S.; Oh, M.; Pham, M.V.; Lee, J.S.; Kim, Y.T. Enhancements in image quality and block detection performance for Reinforced Soil-Retaining Walls under various illuminance conditions. Adv. Eng. Softw. 2024, 195, 103713. [Google Scholar] [CrossRef]
- Zhu, J.; Hu, T.; Zheng, L.; Zhou, N.; Ge, H.; Hong, Z. YOLOv8-C2f-Faster-EMA: An Improved Underwater Trash Detection Model Based on YOLOv8. Sensors 2024, 24, 2483. [Google Scholar] [CrossRef] [PubMed]
- Jiao, J.; Tang, Y.M.; Lin, K.Y.; Gao, Y.; Ma, A.J.; Wang, Y.; Zheng, W.S. Dilateformer: Multi-scale dilated transformer for visual recognition. IEEE Trans. Multimed. 2023, 25, 8906–8919. [Google Scholar] [CrossRef]
- Tang, L.; Zhang, H.; Xu, H.; Ma, J. Rethinking the necessity of image fusion in high-level vision tasks: A practical infrared and visible image fusion network based on progressive semantic injection and scene fidelity. Inf. Fusion 2023, 99, 101870. [Google Scholar] [CrossRef]
- Zhao, J.; Ren, R.; Wu, Y.; Zhang, Q.; Xu, W.; Wang, D.; Fan, L. SEAttention-residual based channel estimation for mmWave massive MIMO systems in IoV scenarios. Digit. Commun. Netw. 2024; in press. [Google Scholar] [CrossRef]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Redmon, J. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Khanam, R.; Hussain, M. What is YOLOv5: A deep look into the internal features of the popular object detector. arXiv 2024, arXiv:2407.20892. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Wei, X.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Parameter Value |
|---|---|
| Image Size | 640 × 640 × 3 |
| Learning Rate | 0.01 |
| Batch Size | 32 |
| Epochs | 300 |
| Momentum | 0.937 |
| Weight Decay | 0.0005 |
| Optimizer | SGD |
| Acquisition Equipments | Resolution |
|---|---|
| Tello drones | 2592 × 1936 |
| iPhone 13promax | 3024 × 4032 |
| OPPO A32 | 720 × 1600 |
| Redmi note11 | 2400 × 1080 |
| Huawei P30pro | 3648 × 2736 |
| Xiaomi 12S | 2400 × 1080 |
| YOLOv8 | SPD-Conv | C2f-MSDA | CGFPN | mAP50 | mAP50-95 | Parameters/M |
|---|---|---|---|---|---|---|
| ✓ | 0.887 | 0.668 | 3.01 | |||
| ✓ | ✓ | 0.909 | 0.703 | 3.33 | ||
| ✓ | ✓ | 0.898 | 0.684 | 2.65 | ||
| ✓ | ✓ | 0.894 | 0.685 | 3.31 | ||
| ✓ | ✓ | ✓ | 0.911 | 0.707 | 2.97 | |
| ✓ | ✓ | ✓ | ✓ | 0.914 | 0.709 | 3.46 |
| Algorithm | Precision (%) | Recall (%) | mAP0.5 | mAP0.5:0.95 | Params |
|---|---|---|---|---|---|
| Faster R-CNN | 0.744 | 0.654 | 0.694 | – | 136.80 |
| RT-DETR [28] | 0.841 | 0.776 | 0.841 | 0.604 | 3.28 |
| YOLOv3 [29] | 0.854 | 0.869 | 0.893 | 0.693 | 103.69 |
| YOLOv5 [30] | 0.867 | 0.863 | 0.898 | 0.672 | 2.50 |
| YOLOv6 [31] | 0.88 | 0.836 | 0.883 | 0.663 | 4.23 |
| YOLOv8 [20] | 0.857 | 0.858 | 0.887 | 0.668 | 3.01 |
| YOLOv8-C2f-Faster-EMAv3 [24] | 0.876 | 0.844 | 0.893 | 0.669 | 2.65 |
| Ours | 0.883 | 0.871 | 0.914 | 0.709 | 3.46 |
| Algorithm | mAP0.5 | mAP0.5:0.95 | Params | FPS |
|---|---|---|---|---|
| Faster R-CNN | 0.528 | – | 136.80 | 14.58 |
| RT-DETR [28] | 0.624 | 0.367 | 3.28 | 17.00 |
| YOLOv3 [29] | 0.796 | 0.544 | 103.69 | 13.09 |
| YOLOv5 [30] | 0.828 | 0.591 | 2.50 | 43.48 |
| YOLOv6 [31] | 0.831 | 0.559 | 4.23 | 42.37 |
| YOLOv8 [20] | 0.829 | 0.57 | 3.01 | 43.86 |
| YOLOv8-C2f-Faster-EMAv3 [24] | 0.833 | 0.575 | 2.65 | 31.95 |
| Ours | 0.84 | 0.597 | 3.61 | 32.70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shan, W.; Yue, Y. Apple Defect Detection in Complex Environments. Electronics 2024, 13, 4844. https://doi.org/10.3390/electronics13234844
Shan W, Yue Y. Apple Defect Detection in Complex Environments. Electronics. 2024; 13(23):4844. https://doi.org/10.3390/electronics13234844
Chicago/Turabian StyleShan, Wei, and Yurong Yue. 2024. "Apple Defect Detection in Complex Environments" Electronics 13, no. 23: 4844. https://doi.org/10.3390/electronics13234844
APA StyleShan, W., & Yue, Y. (2024). Apple Defect Detection in Complex Environments. Electronics, 13(23), 4844. https://doi.org/10.3390/electronics13234844