
Enhanced In-Network Caching for Deep Learning in Edge Networks

Abstract
1. Introduction
- Based on the multi-queue model, an in-network collaborative caching model of multi-edge cache nodes is established to simulate the in-network cache replacement process of edge cache nodes.
- In the period of model training, based on the constraints of maximizing cache utilization, a stochastic gradient descent algorithm is designed to find the optimal number of edge cache nodes.
- The sim4DistrDL-based simulation results demonstrate that the hit rate of cached training data can be improved and the proposed scheme can efficiently support the training process of deep learning models at the edge.
2. Related Work
3. In-Network Cache Modeling for Deep Learning in Edge Networks
3.1. Cached Data Replacement Model for Edge Nodes
3.2. Cache Deployment Optimization for In-Network Caching
| Algorithm 1 ESGD algorithm |
|
4. Simulation and Results Analysis
4.1. Simulation Environment
4.2. Simulation Dataset
4.3. Evaluation Index
4.4. Simulation Competition Scheme
4.5. Simulation Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hazra, A.; Rana, P.; Adhikari, M.; Amgoth, T. Fog computing for next-generation internet of things: Fundamental, state-of-the-art and research challenges. Comput. Sci. Rev. 2023, 48, 100549. [Google Scholar] [CrossRef]
- Chi, H.R.; Wu, C.K.; Huang, N.-F.; Tsang, K.-F.; Radwan, A. A survey of network automation for industrial internet-of-things towards industry 5.0. IEEE Trans. Ind. Inform. 2023, 19, 2065–2077. [Google Scholar] [CrossRef]
- Cherukuri, B.R. Edge computing vs. cloud computing: A comparative analysis for real-time ai applications. Int. J. Multidiscip. Res. 2024, 6, 1–17. [Google Scholar] [CrossRef]
- Mahbub, M.; Shubair, R.M. Contemporary advances in multi-access edge computing: A survey of fundamentals, architecture, technologies, deployment cases, security, challenges, and directions. J. Netw. Comput. Appl. 2023, 219, 103726. [Google Scholar] [CrossRef]
- Men, J.; Feng, L.; Chen, X.; Tian, L. Atmospheric correction under cloud edge effects for geostationary ocean color imager through deep learning. ISPRS J. Photogramm. Remote Sens. 2023, 201, 38–53. [Google Scholar] [CrossRef]
- Lu, Y.; Lin, Q.; Chi, H.; Chen, J.-Y. Automatic incident detection using edge-cloud collaboration based deep learning scheme for intelligent transportation systems. Appl. Intell. 2023, 53, 24864–24875. [Google Scholar] [CrossRef]
- Liu, G.; Dai, F.; Xu, X.; Fu, X.; Dou, W.; Kumar, N.; Bilal, M. An adaptive dnn inference acceleration framework with end–edge–cloud collaborative computing. Future Gener. Comput. Syst. 2023, 140, 422–435. [Google Scholar] [CrossRef]
- Li, R.; Ouyang, T.; Zeng, L.; Liao, G.; Zhou, Z.; Chen, X. Online optimization of dnn inference network utility in collaborative edge computing. IEEE/ACM Trans. Netw. 2024, 32, 4414–4426. [Google Scholar] [CrossRef]
- Geng, H.; Zeng, D.; Li, Y.; Gu, L.; Chen, Q.; Li, P. Plays: Minimizing dnn inference latency in serverless edge cloud for artificial intelligence-of-things. IEEE Internet Things J. 2024, 11, 37731–37740. [Google Scholar] [CrossRef]
- Sada, A.B.; Khelloufi, A.; Naouri, A.; Ning, H.; Aung, N.; Dhelim, S. Multi-agent deep reinforcement learning-based inference task scheduling and offloading for maximum inference accuracy under time and energy constraints. Electronics 2024, 13, 2580. [Google Scholar] [CrossRef]
- Yang, L.; Gan, Y.; Chen, J.; Cao, J. Autosf: Adaptive distributed model training in dynamic edge computing. IEEE Trans. Mob. Comput. 2024, 23, 6549–6562. [Google Scholar] [CrossRef]
- Hua, H.; Li, Y.; Wang, T.; Dong, N.; Li, W.; Cao, J. Edge computing with artificial intelligence: A machine learning perspective. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Wu, C.; Peng, Q.; Xia, Y.; Jin, Y.; Hu, Z. Towards cost-effective and robust ai microservice deployment in edge computing environments. Future Gener. Comput. Syst. 2023, 141, 129–142. [Google Scholar] [CrossRef]
- Pandey, R.; Uziel, S.; Hutschenreuther, T.; Krug, S. Towards deploying dnn models on edge for predictive maintenance applications. Electronics 2023, 12, 639. [Google Scholar] [CrossRef]
- Heidari, A.; Navimipour, N.J.; Unal, M.; Zhang, G. Machine learning applications in internet-of-drones: Systematic review, recent deployments, and open issues. ACM Comput. Surv. 2023, 55, 1–45. [Google Scholar] [CrossRef]
- Jiang, X.; Hou, P.; Zhu, H.; Li, B.; Wang, Z.; Ding, H. Dynamic and intelligent edge server placement based on deep reinforcement learning in mobile edge computing. Ad Hoc Netw. 2023, 145, 103172. [Google Scholar] [CrossRef]
- Abdulazeez, D.H.; Askar, S.K. Offloading mechanisms based on reinforcement learning and deep learning algorithms in the fog computing environment. IEEE Access 2023, 11, 12555–12586. [Google Scholar] [CrossRef]
- Yu, H.; Yu, D.; Wang, C.; Hu, Y.; Li, Y. Edge intelligence-driven digital twin of cnc system: Architecture and deployment. Robot. Comput.-Integr. Manuf. 2023, 79, 102418. [Google Scholar] [CrossRef]
- Nie, Q.; Tang, D.; Liu, C.; Wang, L.; Song, J. A multi-agent and cloud-edge orchestration framework of digital twin for distributed production control. Robot. Comput.-Integr. Manuf. 2023, 82, 102543. [Google Scholar] [CrossRef]
- Liu, C.; Liu, K.; Ren, H.; Xu, X.; Xie, R.; Cao, J. Rtds: Real-time distributed strategy for multi-period task offloading in vehicular edge computing environment. Neural Comput. Appl. 2023, 35, 12373–12387. [Google Scholar] [CrossRef]
- Raeisi-Varzaneh, M.; Dakkak, O.; Habbal, A.; Kim, B.-S. Resource scheduling in edge computing: Architecture, taxonomy, open issues and future research directions. IEEE Access 2023, 11, 25329–25350. [Google Scholar] [CrossRef]
- Aghapour, Z.; Sharifian, S.; Taheri, H. Task offloading and resource allocation algorithm based on deep reinforcement learning for distributed ai execution tasks in iot edge computing environments. Comput. Netw. 2023, 223, 109577. [Google Scholar] [CrossRef]
- Liang, Q.; Hanafy, W.A.; Ali-Eldin, A.; Shenoy, P. Model-driven cluster resource management for ai workloads in edge clouds. ACM Trans. Auton. Adapt. Syst. 2023, 18, 1–26. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, H.; Xu, Y.; Jiang, Z.; Liu, J. Coopfl: Accelerating federated learning with dnn partitioning and offloading in heterogeneous edge computing. Comput. Netw. 2023, 220, 109490. [Google Scholar] [CrossRef]
- Shu, Z.; Deng, X.; Wang, L.; Gui, J.; Wan, S.; Zhang, H.; Min, G. Relay-assisted edge computing framework for dynamic resource allocation and multiple-access tasks processing in digital divide regions. IEEE Internet Things J. 2024, 11, 35724–35741. [Google Scholar] [CrossRef]
- Nugroho, A.K.; Shioda, S.; Kim, T. Optimal resource provisioning and task offloading for network-aware and federated edge computing. Sensors 2023, 23, 9200. [Google Scholar] [CrossRef]
- Lin, Z.; Zhu, G.; Deng, Y.; Chen, X.; Gao, Y.; Huang, K.; Fang, Y. Efficient parallel split learning over resource-constrained wireless edge networks. IEEE Trans. Mob. Comput. 2024, 23, 9224–9239. [Google Scholar] [CrossRef]
- Pu, Y.; Li, Z.; Yu, J.; Lu, L.; Guo, B. An elastic framework construction method based on task migration in edge computing. Softw. Pract. Exp. 2024, 54, 1811–1830. [Google Scholar] [CrossRef]
- Chen, Y.; Luo, X.; Liang, P.; Han, J.; Xu, Z. Priority-based dag task offloading and secondary resource allocation in iot edge computing environments. Computing 2024, 106, 3229–3254. [Google Scholar] [CrossRef]
- Liao, L.; Lai, Y.; Yang, F.; Zeng, W. Online computation offloading with double reinforcement learning algorithm in mobile edge computing. J. Parallel Distrib. Comput. 2023, 171, 28–39. [Google Scholar] [CrossRef]
- Huang, B.; Wang, L.; Liu, X.; Huang, Z.; Yin, Y.; Zhu, F.; Wang, S.; Deng, S. Reinforcement learning based online scheduling of multiple workflows in edge environment. IEEE Trans. Netw. Serv. Manag. 2024, 21, 5691–5706. [Google Scholar] [CrossRef]
- Wang, X.; Shen, M.; Yang, K. On-edge high-throughput collaborative inference for real-time video analytics. IEEE Internet Things J. 2024, 11, 33097–33109. [Google Scholar] [CrossRef]
- Albonesi, D.H. Selective cache ways: On-demand cache resource allocation. In Proceedings of the MICRO-32. Proceedings of the 32nd Annual ACM/IEEE International Symposium on Microarchitecture, Haifa, Israel, 16–18 November 1999; pp. 248–259. [Google Scholar]
- Suh, G.E.; Devadas, S.; Rudolph, L. Analytical cache models with applications to cache partitioning. In Proceedings of the ACM International Conference on Supercomputing 25th Anniversary Volume, Munich, Germany, 10–13 June 2014; pp. 323–334. [Google Scholar]
- Kennedy, R.K.; Khoshgoftaar, T.M.; Villanustre, F.; Humphrey, T. A parallel and distributed stochastic gradient descent implementation using commodity clusters. J. Big Data 2019, 6, 16. [Google Scholar] [CrossRef]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the COMPSTAT’2010: 19th International Conference on Computational Statistics, Paris, France, 22–27 August 2010; Keynote, Invited and Contributed Papers. Springer: Berlin/Heidelberg, Germany, 2010; pp. 177–186. [Google Scholar]
- Chih-Chung, C. Libsvm: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Liu, X.; Xu, Z.; Qin, Y.; Tian, J. A discrete-event-based simulator for distributed deep learning. In Proceedings of the 2022 IEEE Symposium on Computers and Communications (ISCC), Rhodes, Greece, 30 June–3 July 2022; pp. 1–7. [Google Scholar]
- Liu, S.; Liu, Z.; Xu, Z.; Liu, W.; Tian, J. Hierarchical decentralized federated learning framework with adaptive clustering: Bloom-filter-based companions choice for learning non-iid data in iov. Electronics 2023, 12, 3811. [Google Scholar] [CrossRef]
- Liu, X.; Dong, Z.; Xu, Z.; Liu, S.; Tian, J. Enhanced decentralized federated learning based on consensus in connected vehicles. arXiv 2022, arXiv:2209.10722. [Google Scholar]
- Lang, K. Newsweeder: Learning to filter netnews. In Machine Learning Proceedings 1995; Prieditis, A., Russell, S., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 1995; pp. 331–339. [Google Scholar]

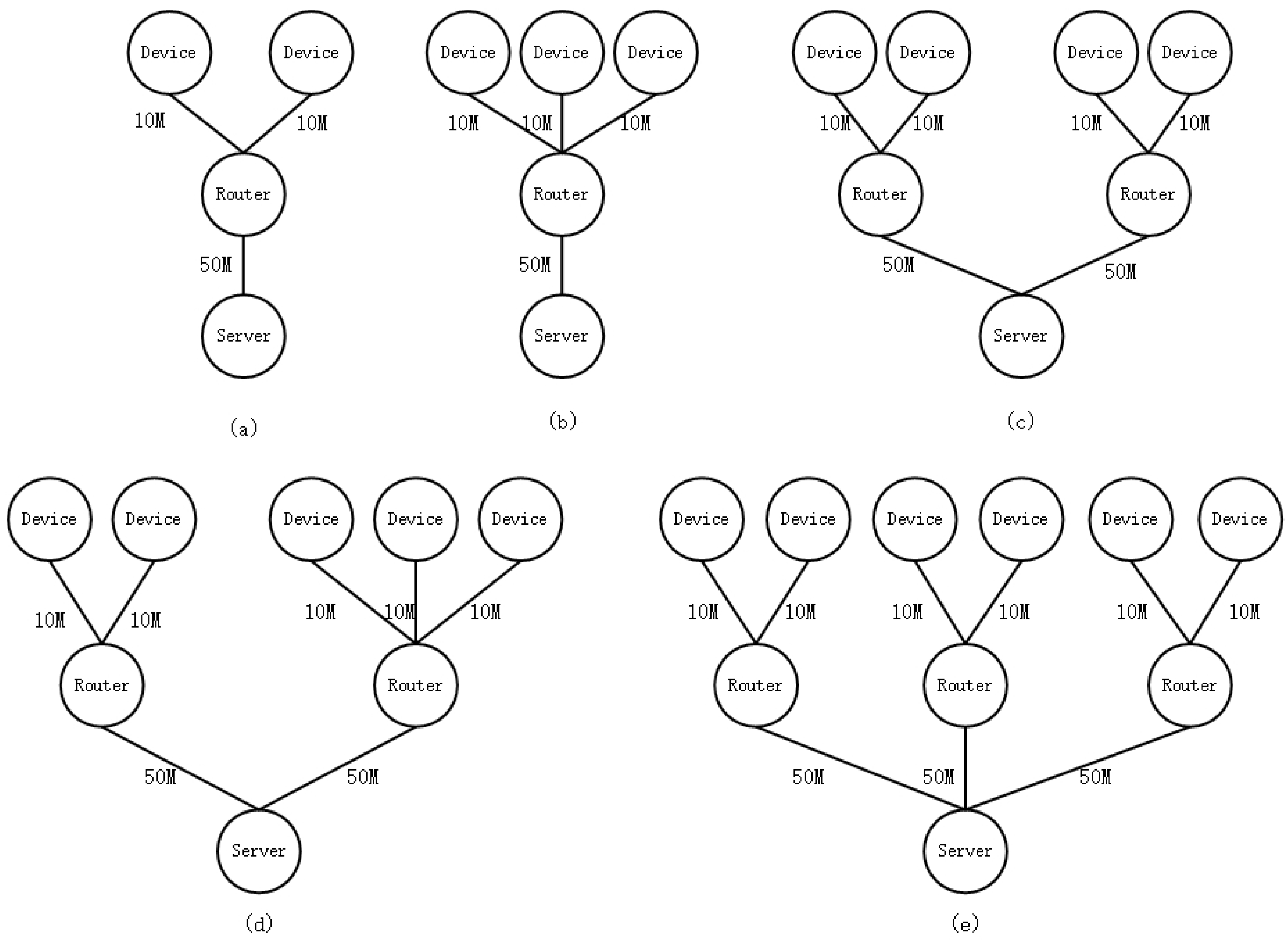


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| D | the maximum capacity of a single edge node |
| average arrival speed | |
| average response time | |
| steady-state probability | |
| the steady-state probability of the i-th node | |
| c | the number of deployed edge nodes |
| replacement strength of an edge cache node | |
| average sojourn time | |
| average queue length | |
| h | awaiting the limiting value of the average queue length |
| Topic | Topic Number | Number of Files |
|---|---|---|
| comp. graphics | 1 | 400 |
| comp. windows.x | 2 | 400 |
| misc. forsale | 3 | 400 |
| rec. autos | 4 | 400 |
| rec. sport. baseball | 5 | 400 |
| sci. electronic | 6 | 400 |
| sci. space | 7 | 400 |
| talk. politics. guns | 8 | 400 |
| talk. religion. misc | 9 | 400 |
| Scheme | Step |
|---|---|
| MPC | 1. Rank the popularity of content |
| 2. Sorter caches the most popular content | |
| 3. Cache content in nodes | |
| UC | 1. Ignore differences in content popularity |
| 2.The caching probability of content is uniformly distributed | |
| 3. Cache content in nodes |
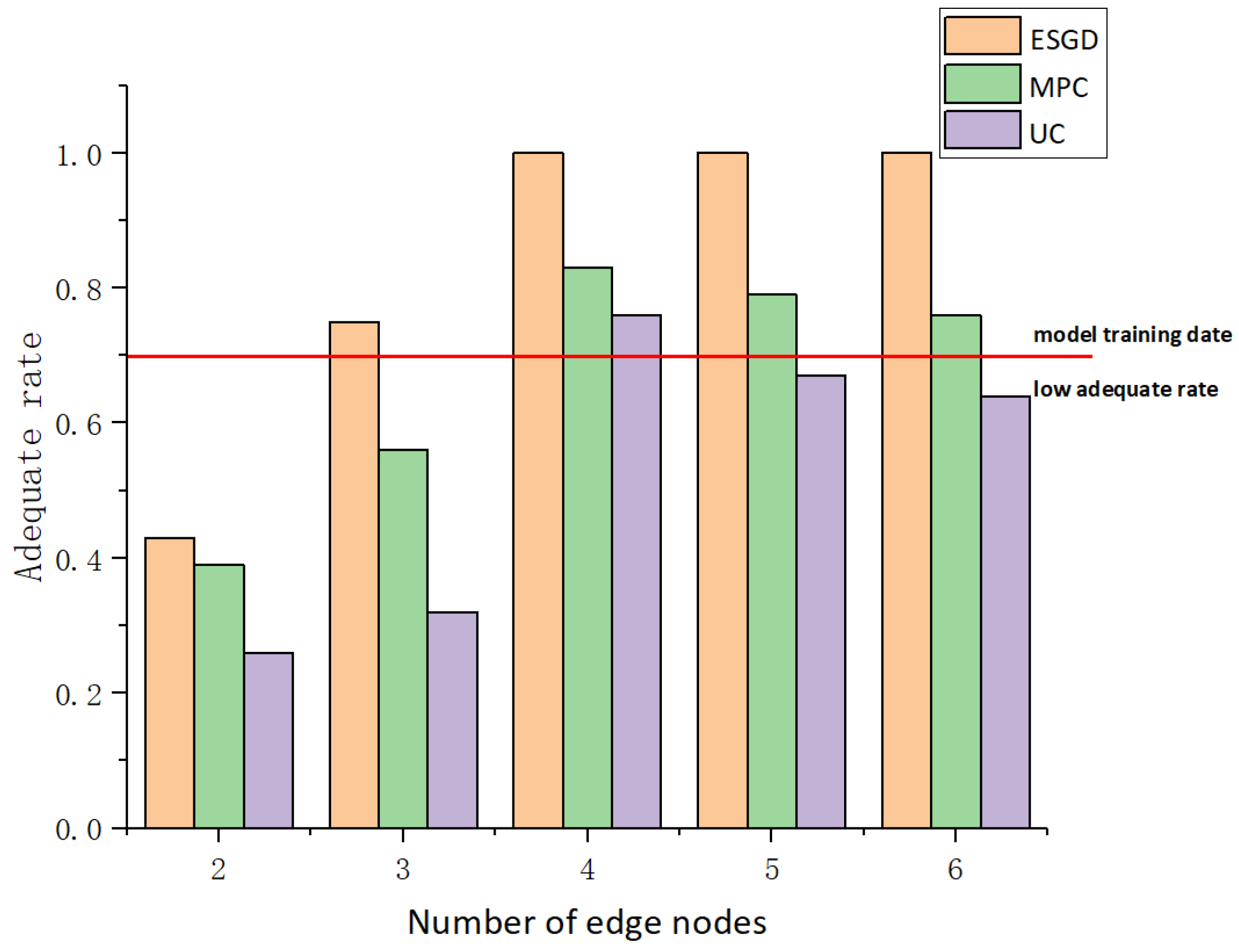
| Number of Nodes | Adequate Rate | Hit Rate |
|---|---|---|
| 2 | 53% | 43% |
| 3 | 63% | 75% |
| 4 | 87% | 100% |
| 5 | 84% | 100% |
| 6 | 71% | 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Liu, W.; Zhang, L.; Tian, J. Enhanced In-Network Caching for Deep Learning in Edge Networks. Electronics 2024, 13, 4632. https://doi.org/10.3390/electronics13234632
Zhang J, Liu W, Zhang L, Tian J. Enhanced In-Network Caching for Deep Learning in Edge Networks. Electronics. 2024; 13(23):4632. https://doi.org/10.3390/electronics13234632
Chicago/Turabian StyleZhang, Jiaqi, Wenjing Liu, Li Zhang, and Jie Tian. 2024. "Enhanced In-Network Caching for Deep Learning in Edge Networks" Electronics 13, no. 23: 4632. https://doi.org/10.3390/electronics13234632
APA StyleZhang, J., Liu, W., Zhang, L., & Tian, J. (2024). Enhanced In-Network Caching for Deep Learning in Edge Networks. Electronics, 13(23), 4632. https://doi.org/10.3390/electronics13234632