

Computing Unit and Data Migration Strategy under Limited Resources: Taking Train Operation Control System as an Example


Abstract
1. Introduction
- (1)
- A hierarchical architecture of computing units and data abstraction is formed under limited computing resources. It abstracts real systems into a data-processing-and- transmission model, which is composed of nodes, components, data, and data flow;
- (2)
- A resource consumption calculation method is created. The method establishes a data migration model and lists migration criteria under resource constraints. The attributes of resource consumption, i.e., a combination of CPU usage, RAM occupancy, and network bandwidth demand, are added to the critical computing path;
- (3)
- A computing unit and data migration method is proposed. This method optimizes the resource cost by placing associate components/data from non-critical paths to the critical paths and transforms the path between nodes into the path within nodes.
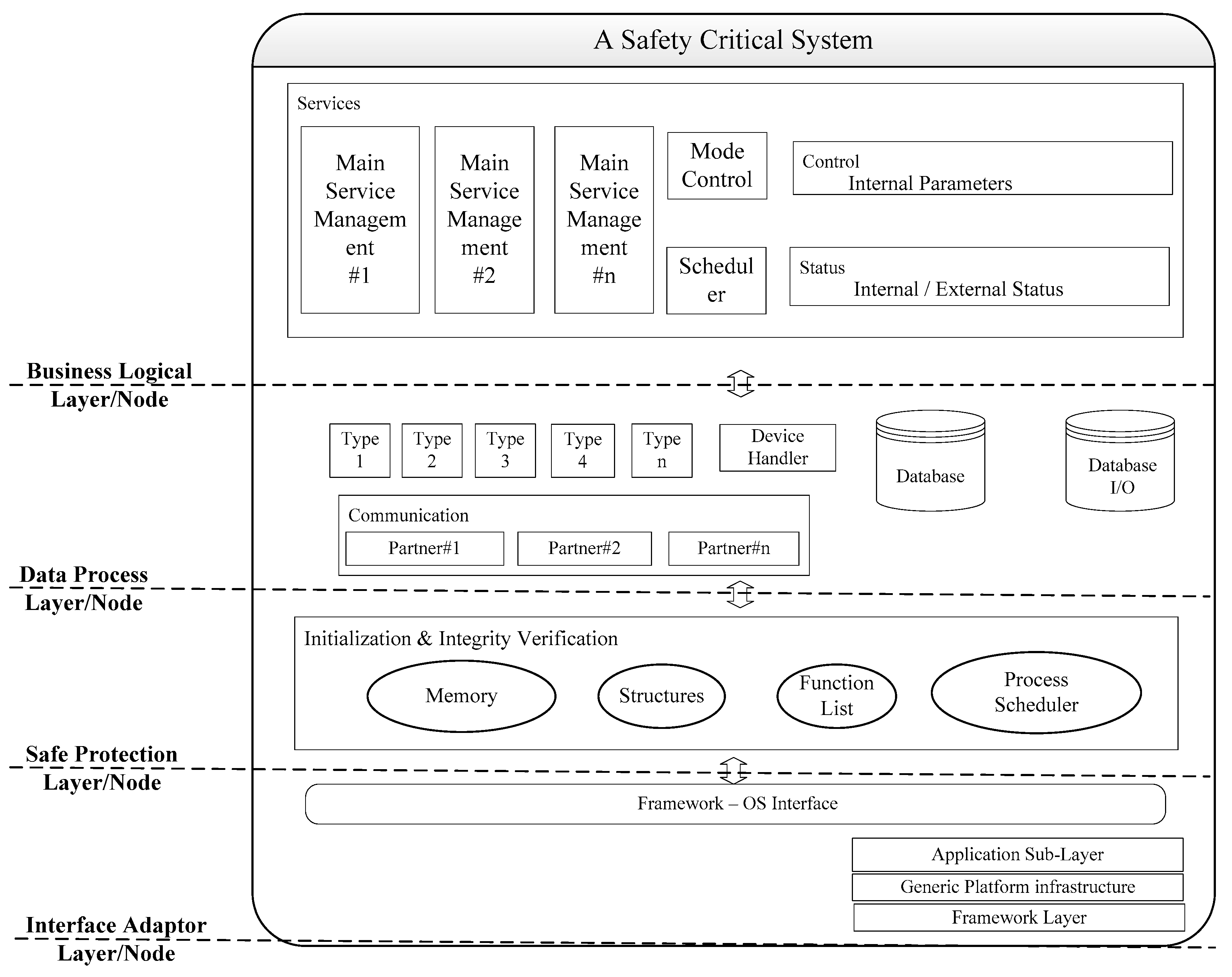
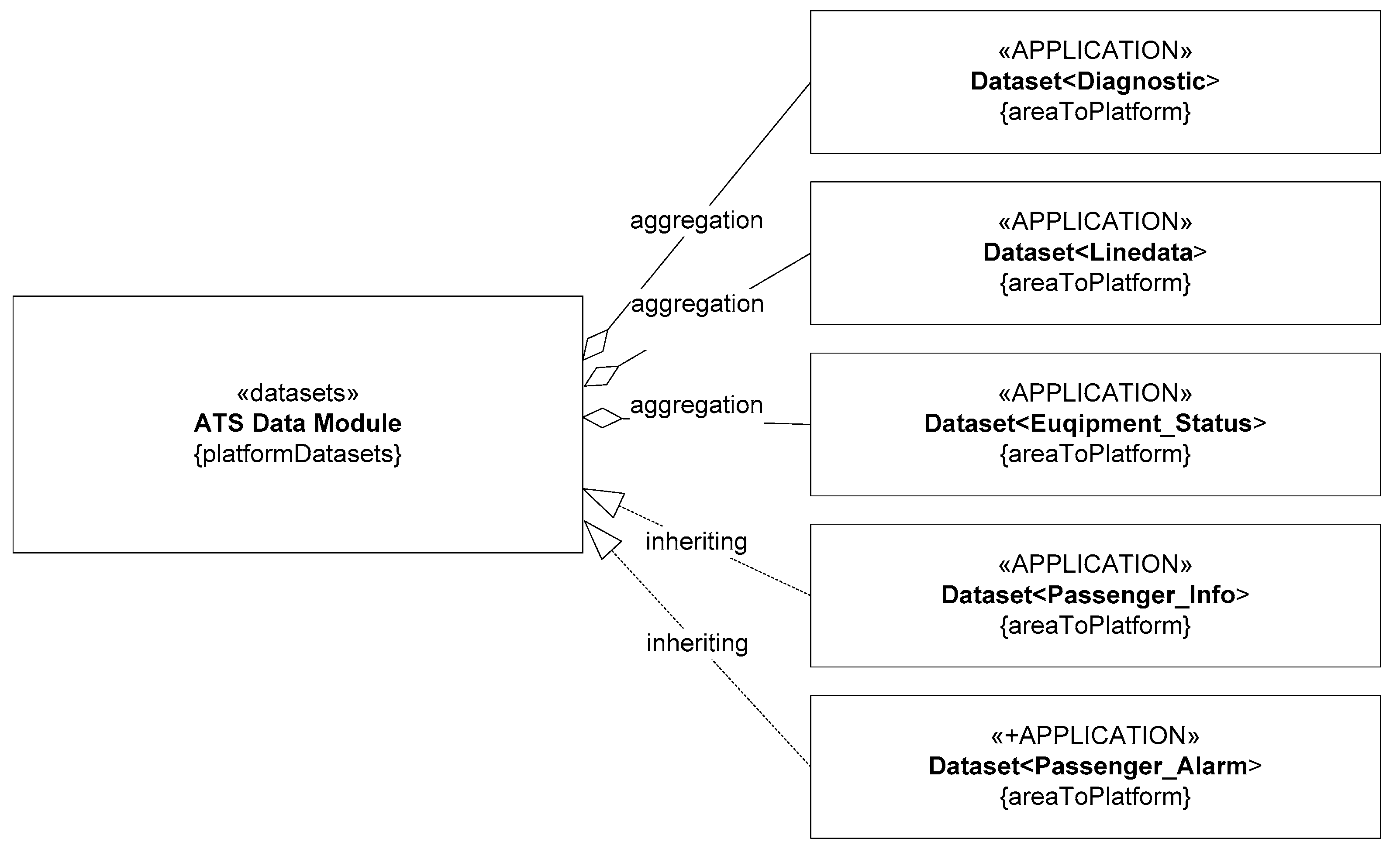
2. System Abstraction
2.1. Hierarchical Architecture of Computing Units
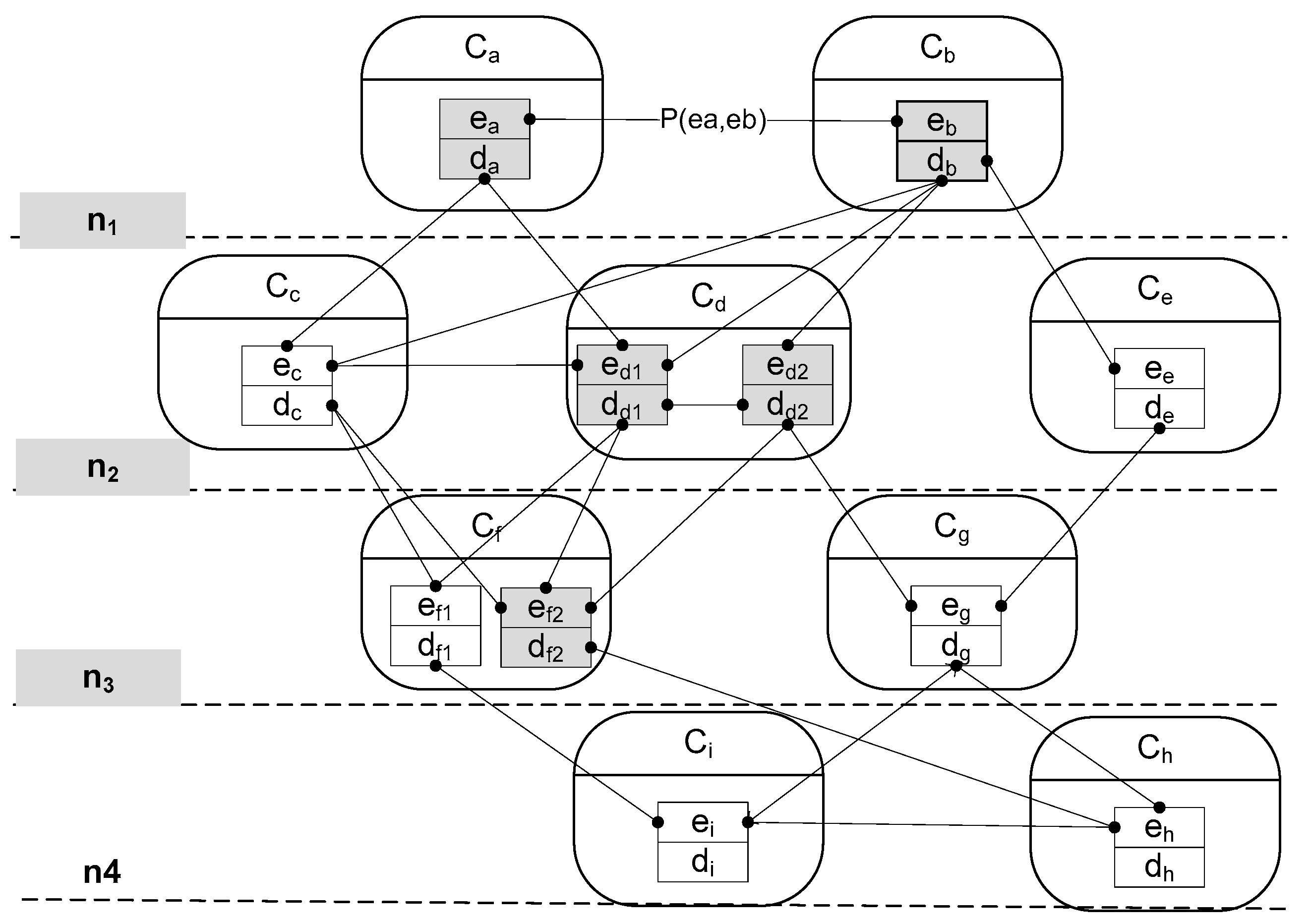
2.2. Object Definition and Analysis
2.3. Computing-Resources Consumption on Computing Path
3. Component and Data Migration Model under Limited Resources
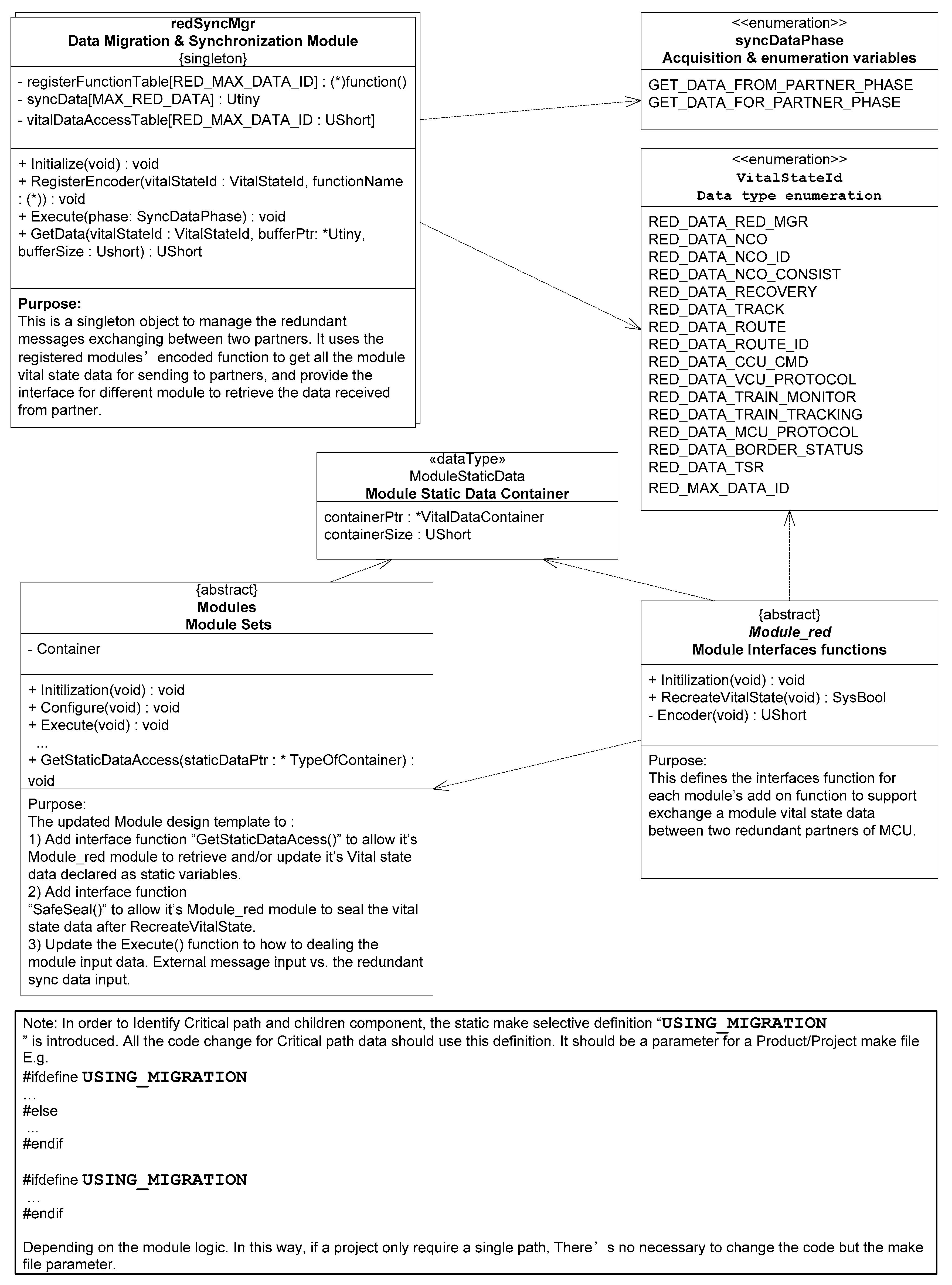
3.1. Component and Data Migration Model
3.2. Objective Function Analysis
- (1)
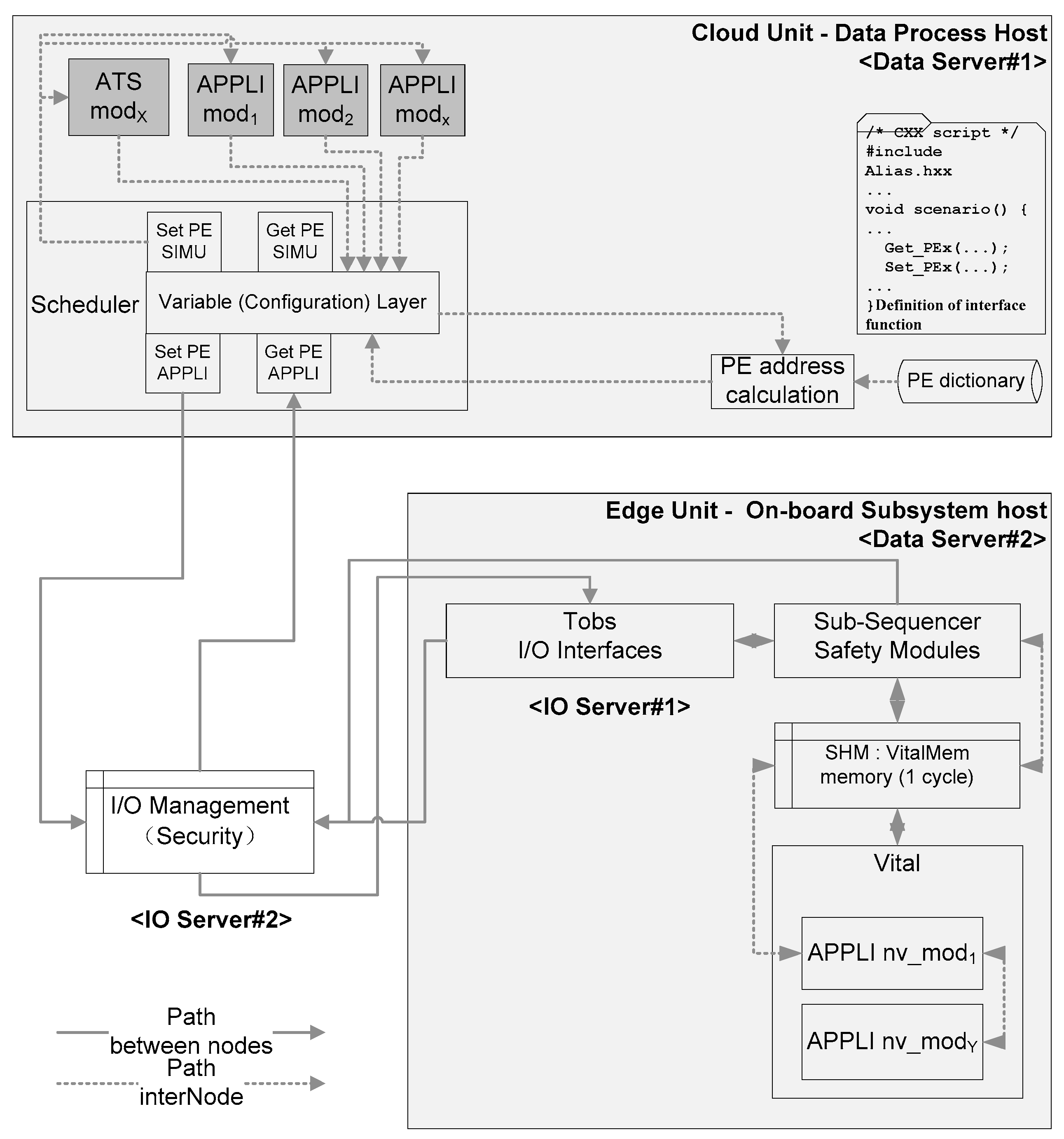
- Within limited resources, data should be preferentially moved to nodes with low resource occupancy, which shortens the path. According to Equation (13), if we need to optimize computing resources while the total amount of resources is fixed, a feasible way is to put components and data from the non-critical paths to the critical paths in case the critical path node has sufficient computing resources, and vice versa. In this way, the redundant computing resources can be fully used, and it also reduces the tension of computing resources of non-critical path nodes. The conclusion is consistent with the “High Cohesion” theory in software engineering system design method [28]. A case in point is that in the cloud–edge-computing architecture, a large amount of data and related components can be uploaded onto the cloud platform [29,30] as a non-critical path, while the business parameters with safety-critical but small data can be put on the edge server, with real-time security-logic-computing components, which is a critical path.
- (2)
- When the path number of internal nodes converted from inter-nodes is greater than the path number of inter-nodes converted from internal nodes, the overall computing resource consumption will be reduced. For example, according to Equation (12), the communication cost of components in the node is an in-line function, its CPU consumption depends on the Interrupt Request (IRQ), and, thus, the assigned time slice from the CPU is extremely low compared to the application-calculated time slice. Similarly, the memory consumption is usually limited within related heaps or stacks, so their resource consumption is minimal. On the contrary, the communication time between nodes, such as the transmission time between different subsystems, often takes up more computing resources. As an example, it is proven that a simplified interface design in distributed architecture has significantly improved computing efficiency [31,32]. This conclusion is consistent with the “Low Coupling” theory in software-engineering system design methods [28].
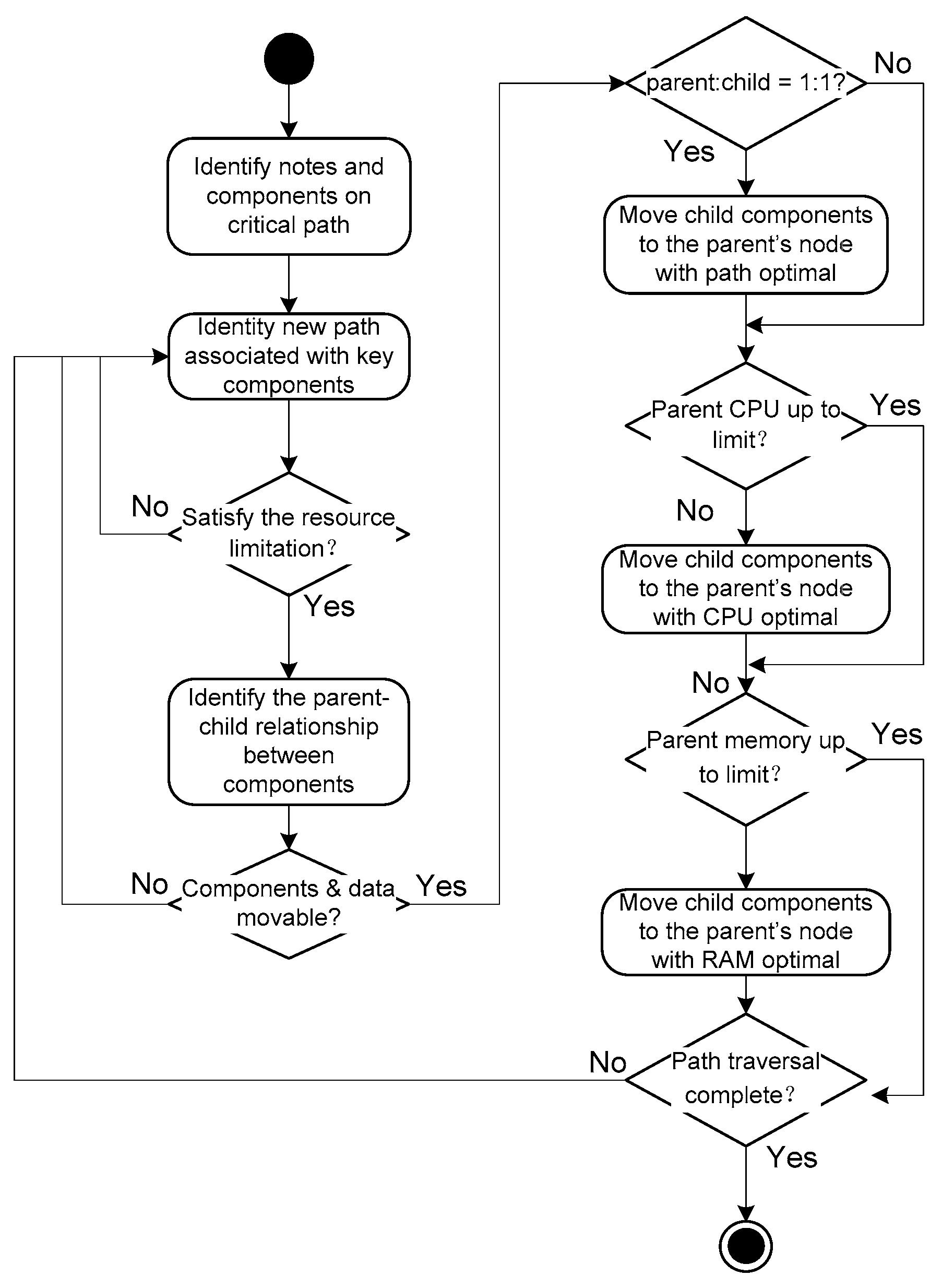
4. Basic Migration Rules and Strategies
4.1. Basic Migration Rules
- (1)
- According to Equation (9), the original consumption after migration does not exceed the peak value.
- (2)
- According to Definition 4, all components related to the critical path should be included in the critical path.
- (3)
- According to Equation (8), the resource consumption after migration should be less than the one before migration.
4.2. Migration Strategy
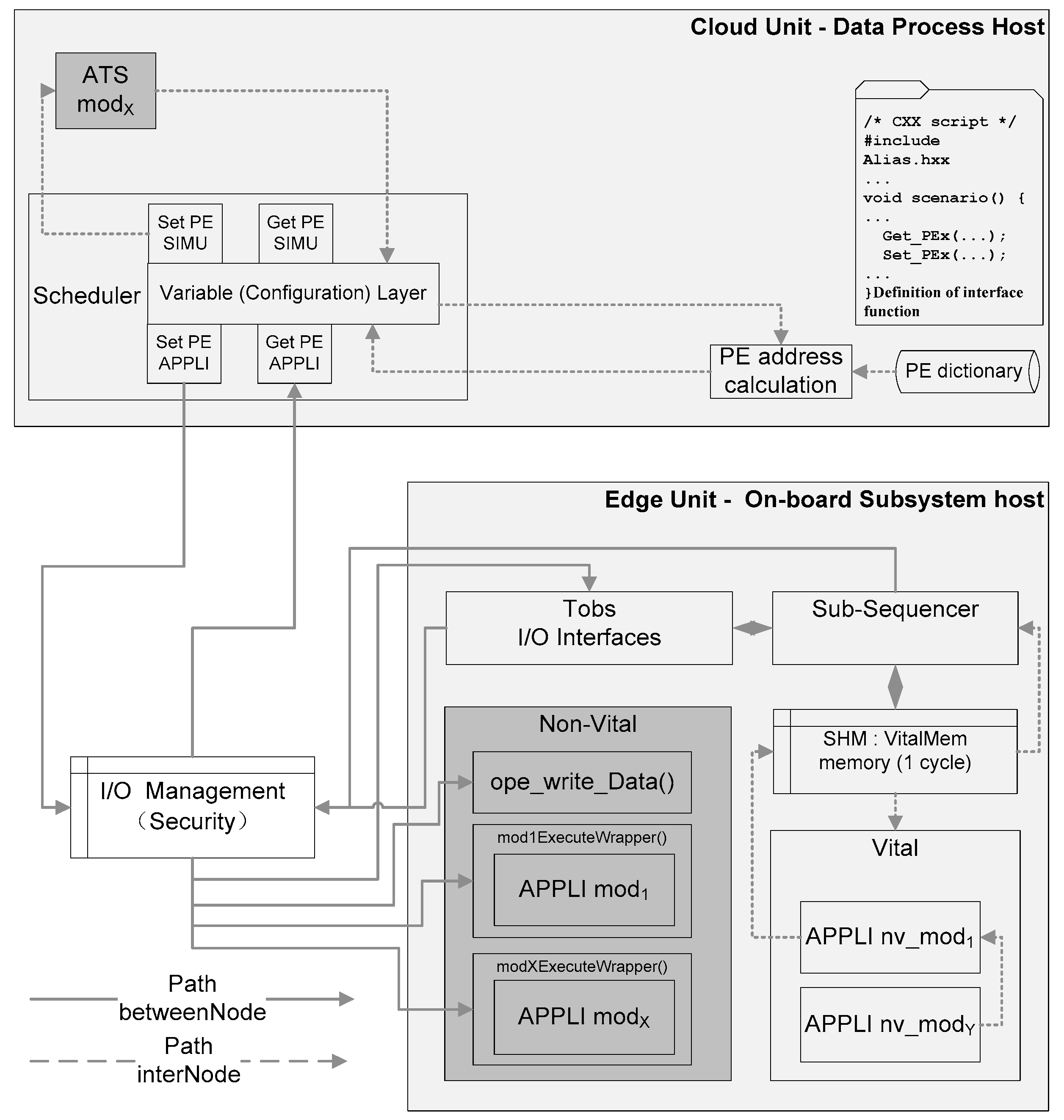
5. Practical Analysis and Model Validation
5.1. Practicability Analysis
5.2. Strategy Validation and Data Analysis
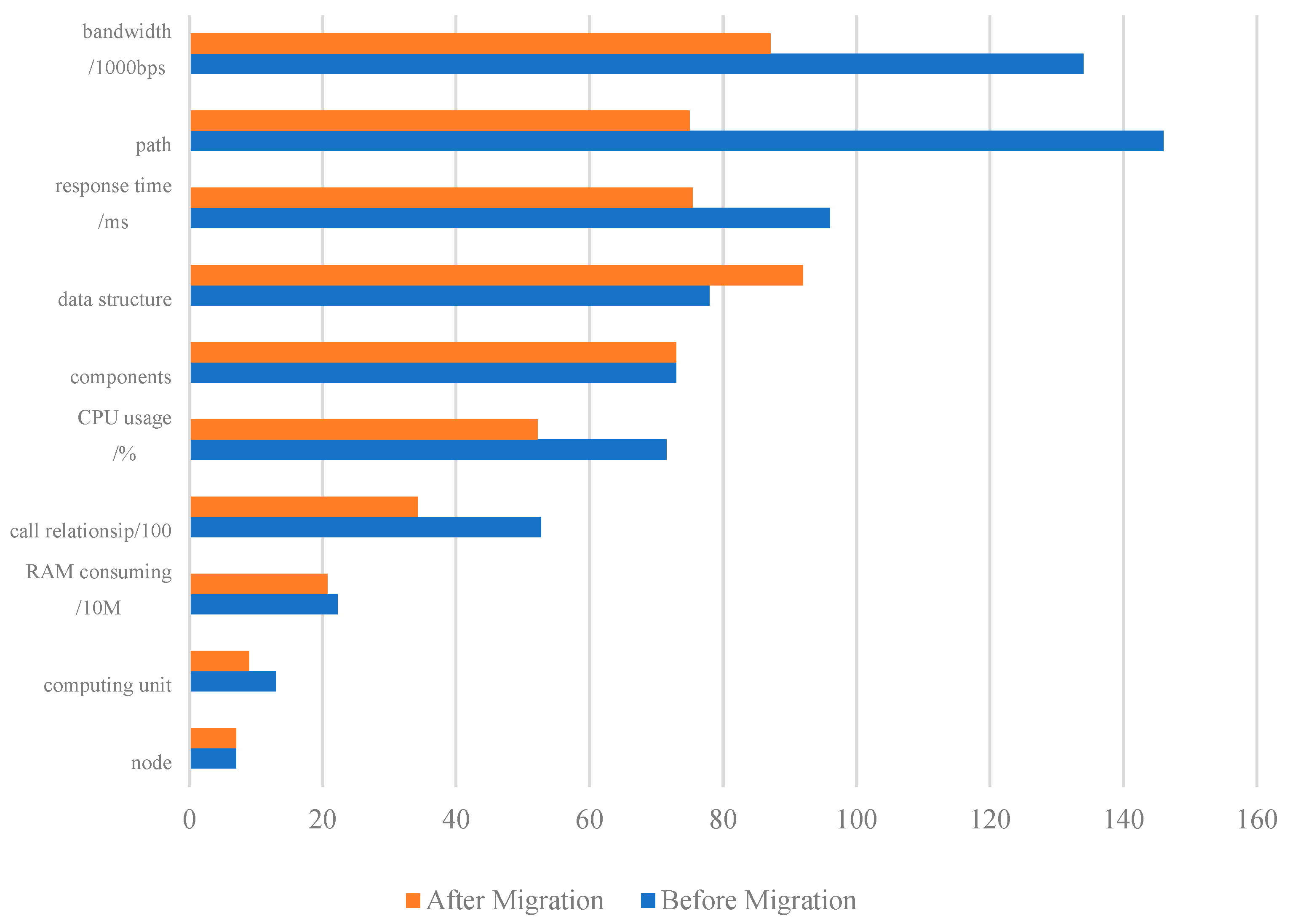
- (1)
- The initial setting of this test is not to change the functional modules, system architecture, and total computing resources; so, the node (i.e., number of subsystems) and components (i.e., number of functional modules) remain unchanged before and after migration;
- (2)
- Due to the migration and consolidation of components, the number of logical set units of components decreased from 13 to 9. The number of paths (i.e., call relationships including non-critical paths) is reduced from 146 to 75;
- (3)
- Due to the subdivision of data interface functions after migration, the data structure related to the interface is split from 78 to 92;
- (4)
- CPU utilization is reduced by 27%, memory usage is reduced by 6.8%, and the network bandwidth is decreased by 35%.
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Moon, J.; Hong, D.; Kim, J.; Kim, S.; Woo, S.; Choi, H.; Moon, C. Enhancing autonomous driving robot systems with edge computing and LDM platforms. Electronics 2024, 13, 2740. [Google Scholar] [CrossRef]
- Xu, L.; Liu, Y.; Fan, B.; Xu, X.; Mei, Y.; Feng, W. An improved gravitational search algorithm for task offloading in a mobile edge computing network with task priority. Electronics 2024, 13, 540. [Google Scholar] [CrossRef]
- Siemens. Siemens Transportation develops 5G+cloud signal system solutions, enabling urban rail transit in all directions. Urban Rail Transit 2020, 10, 54. [Google Scholar] [CrossRef]
- Meng, C.; Liu, W.; Yang, Q.; Zhao, Y.; Guo, Y. Research on operation optimization of edge data center under the background of ‘multi-station integration’. Adv. Eng. Sci. 2020, 52, 49–55. [Google Scholar] [CrossRef]
- Hu, J.; Wang, G.; Xu, X. Task migration strategy with energy optimization in mobile edge computing. Comput. Sci. 2020, 47, 260–265. [Google Scholar] [CrossRef]
- Tang, X.; Zhao, Q.; Fu, Y.; Zhu, Z.; Ding, Z. Research of hybrid resource scheduling framework of heterogeneous clusters for dataflow. J. Softw. 2022, 33, 4704–4726. [Google Scholar] [CrossRef]
- Sun, D.; Zhang, G.; Yang, S.; Zheng, W.; Khan, S.U. Re-Stream: Real-time and energy-efficient resource scheduling in big data stream computing environments. Inf. Sci. 2015, 319, 92–112. [Google Scholar] [CrossRef]
- Yang, S.; Cheng, H.; Dang, Y. Resource allocation and load balancing strategy in cloud-fog hybrid computing based on cluster-collaboration. J. Electron. Inf. Technol. 2023, 45, 2423–2431. [Google Scholar] [CrossRef]
- Li, M.; Mao, Y.; Tu, Z.; Wang, X.; Xu, S. Server-reliability task offloading strategy based on deep deterministic policy gradient. Comput. Sci. 2022, 49, 271–279. [Google Scholar]
- Liu, H. An UAV-assisted edge computing resource allocation strategy for 5G communication in IOT environment. J. Robot. 2022, 2022, 9397783. [Google Scholar] [CrossRef]
- Pu, Y.; Yu, J.; Lu, L.; Li, Z.; Bian, C.; Liao, B. Energy-efficient strategy based on executor reallocation and data migration in storm. J. Softw. 2021, 32, 2557–2579. [Google Scholar] [CrossRef]
- Nunome, A.; Hirata, H. Performance evaluation of data migration policies for a distributed storage system with dynamic tiering. Int. J. Networked Distrib. Comput. 2019, 8, 1–8. [Google Scholar] [CrossRef]
- Wang, D.; Huang, C. Distributed cache memory data migration strategy based on cloud computing. Concurr. Comput. Pract. Exp. 2019, 31, e4828. [Google Scholar] [CrossRef]
- Qiu, S.; Zhao, J.; Yana, L.; Dai, J.; Chen, F. Digital-twin-assisted edge-computing resource allocation based on the whale optimization algorithm. Sensors 2022, 22, 9546. [Google Scholar] [CrossRef]
- Xiao, J.; Gao, Q.; Yang, Z.; Cao, Y.; Wang, H.; Feng, Z. Multi-round auction-based resource allocation for edge computing: Maximizing social welfare. Future Gener. Comput. Syst. 2023, 140, 365–375. [Google Scholar] [CrossRef]
- Cheng, Z.; Zhang, J.; Song, T.; Hu, J. Contract-based scheme for computational resource allocation in cloud-assisted parked vehicular edge computing. Phys. Commun. 2022, 55, 101916. [Google Scholar] [CrossRef]
- Su, Z.; He, G.; Li, Z. Using grasshopper optimization algorithm to solve 0-1 knapsack computation resources allocation problem in mobile edge computing. In Proceedings of the 34th Conference on Control and Decision-making in China 2022, Hefei, China, 21–23 May 2022; pp. 559–564. [Google Scholar] [CrossRef]
- Chen, J.; Chang, Z.; Guo, W. Resource allocation and computation offloading for wireless powered mobile edge computing. Sensors 2022, 22, 6002. [Google Scholar] [CrossRef]
- Gaurav, B.; Dinesh, K.; Prakash, V.D. BARA: A blockchain-aided auction-based resource allocation in edge computing enabled industrial internet of things. Future Gener. Comput. Syst. 2022, 135, 333–347. [Google Scholar] [CrossRef]
- Praveena, A.; Vijayarajan, V. An efficient mobility prediction model for resource allocation in mobile cloud computing. Int. J. Knowl. Based Intell. Eng. Syst. 2021, 25, 149–157. [Google Scholar] [CrossRef]
- Kanwar, K.; Kaushal, S.; Kumar, H.; Gupta, G.; Khari, M. BCDCN: A new edge centrality measure to identify and rank critical edges pertaining to SIR diffusion in complex networks. Soc. Netw. Anal. Min. 2022, 12, 49. [Google Scholar] [CrossRef]
- Gupta, M.; Srivastava, S.; Chaudhary, G.; Khari, M.; Fuente, J.P. Voltage regulation using probabilistic and fuzzy controlled dynamic voltage restorer for oil and gas industry. International Journal of Uncertainty. Fuzziness Knowl. Based Syst. 2020, 28, 49–64. [Google Scholar] [CrossRef]
- Florian, H.; Zoltán, S. Connectivity of orientations of 3-edge-connected graphs. Eur. J. Comb. 2021, 94, 103292. [Google Scholar] [CrossRef]
- Pishgoo, B.; Azirani, A.A.; Raahemi, B. A hybrid distributed batch-stream processing approach for anomaly detection. Inf. Sci. 2020, 543, 309–327. [Google Scholar] [CrossRef]
- Sun, D.; Zhang, G.; Zheng, W. Big data stream computing: Technologies and instances. J. Softw. 2014, 25, 839–862. [Google Scholar] [CrossRef]
- He, Y.; Wang, Y.; Qiu, C.; Lin, Q.; Li, J. Blockchain-based edge computing resource allocation in IOT: A deep reinforcement learning approach. IEEE Internet Things J. 2021, 8, 2226–2237. [Google Scholar] [CrossRef]
- Huang, H.; Zhong, Y.; He, J.; Huang, T.; Jiang, W. Joint wireless and computational resource allocation for ultra-dense mobile-edge computing networks. KSII Trans. Internet Inf. Syst. 2020, 14, 3134–3155. [Google Scholar] [CrossRef]
- Teig, Ø. High cohesion and low coupling: The office mapping factor. In Communicating Process Architectures 2007; McEwan, A., Schneider, S., Ifill, W., Welch, P., Eds.; Concurrent Systems Engineering Series; IOS Press: Amsterdam, The Netherlands, 2007; Volume 65, pp. 313–322. ISBN 978-1-58603-767-3. Available online: http://www.teigfam.net/oyvind/pub/CPA2007/paper.pdf (accessed on 10 July 2022).
- Feng, J.; Yu, F.R.; Pei, Q.; Du, J.; Zhu, L. Joint optimization of radio and computational resources allocation in blockchain-enabled mobile edge computing systems. IEEE Trans. Wirel. Commun. 2020, 19, 4321–4334. [Google Scholar] [CrossRef]
- Uchaikin, R.A.; Uchaikin, R.; Orlov, S.P. Optimization-simulation approach to the computational resource allocation in a mechanical engineering enterprise. J. Phys. Conf. Ser. 2020, 1679, 32015. [Google Scholar] [CrossRef]
- Han, Q.; Fang, X. Resource allocation schemes of edge computing in Wi-Fi network supporting multi-AP coordination. Comput. Syst. Appl. 2022, 31, 309–319. [Google Scholar] [CrossRef]
- Li, X.; Zhou, Z.; Chen, L.; Zhu, J. Task offloading and cooperative scheduling for heterogeneous edge resources. J. Comput. Res. Dev. 2023, 60, 1296–1307. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, Z.; You, J.; Wang, Y.; Zhao, X. Unloading strategy of edge computing in emergency management scenario. Comput. Eng. Des. 2022, 43, 2549–2556. [Google Scholar] [CrossRef]
- Zhou, T.; Hu, H.; Zeng, X. Cooperative computation offloading and resource management based on improved genetic algorithm in NOMA-MEC systems. J. Electron. Inf. Technol. 2022, 44, 3014–3023. [Google Scholar] [CrossRef]
- Zhang, Y.; Cheng, Y. Joint optimization of edge computing and caching in NDN. J. Commun. 2022, 43, 164–175. [Google Scholar]
- Chen, Q.; Kuang, Z. Task offloading and service caching algorithm based on DDPG in edge computing. Comput. Eng. 2021, 47, 26–33. [Google Scholar] [CrossRef]
- Huang, Y.; Zheng, C.; Zhang, Z.; You, X. Research on mobile edge computing and caching in massive wireless communication network. J. Commun. 2021, 42, 44–61. [Google Scholar] [CrossRef]
- Vimal, S.; Khari, M.; Dey, N.; Crespo, R.G.; Robinson, Y.H. Enhanced resource allocation in mobile edge computing using reinforcement learning based MOACO algorithm for IIOT. Comput. Commun. 2020, 151, 355–364. [Google Scholar] [CrossRef]
- Son, L.H.; Chiclana, F.; Kumar, R.; Mittal, M.; Khari, M.; Chatterjee, J.M.; Baik, S.W. ARM–AMO: An efficient association rule mining algorithm based on animal migration optimization. Knowl. Based Syst. 2018, 154, 68–80. [Google Scholar] [CrossRef]
- Wang, Z.; Hou, R. Joint caching and computing resource allocation for task offloading in vehicular networks. IET Commun. 2020, 14, 3820–3827. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Set | Instance | Description | Expression in the Model | Definition |
|---|---|---|---|---|
| Computing Unit | Definition 1 | |||
| Node | Definition 1 | |||
| Element of Computing Unit (component) | Definition 2 | |||
| Data | Definition 3 | |||
| Resource, i.e., CPU, RAM, communication consumption | Definition 5 | |||
| Data flow computing path | Definition 4 | |||
| Edge (data flow) | Definition 2 |
| No. | Data Type * | Business Layer | NOT Participate in Real-Time Calculations | Low Impact on Fail-Safe Principle | Data Quantity/Bytes | Belongs to Logic Operation | Belongs to Data Computing |
|---|---|---|---|---|---|---|---|
| 1 | OS parameters | x | x | x | 0.223 K | √ | |
| 2 | Framework parameters | x | x | x | 15.012 K | √ | |
| 3 | Main clock | x | x | x | 0.101 K | √ | |
| 4 | IRQ | x | x | x | 0.332 K | √ | |
| 5 | Diagnostic parameters | x | √ | √ | 18.556 K | √ | |
| 6 | Com-configuration parameters | x | x | x | 5.105 K | √ | |
| 7 | GEBR braking rate | √ | x | x | 0.214 K | √ | |
| 8 | Data protection macro | √ | x | x | 0.101 K | √ | |
| 9 | CPU occupancy | x | x | x | 0.109 K | √ | |
| 10 | RAM occupancy | x | x | x | 0.176 K | √ | |
| 11 | Line data | √ | √ | √ | 128.241 M | √ | |
| 12 | External equipment status | √ | √ | x | 26.442 M | √ | |
| 13 | PIS data | √ | √ | √ | 770.009 M | √ | |
| 14 | PAS data | √ | √ | √ | 14.500 M | √ |
| Configuration Items | Onboard Control System |
|---|---|
| OS Environment | RedHat Linux 5.3 TAS O/S 2.1.0.2 GNU C++ Compiler/Linker 4.4.5-plf2.0 Doxygen/UMLDox 1.7.6.1 |
| HW Configuration | 1.86 GHz, 4 MB L2 cache, 1066 MHz Front Side Bus 3 GB RAM 160 GB Hard Disk Drive 4 NIC ports2×2 dual ports or 1 × 4 ports Ethernet adapter 2×dual port serial adapters for MPU |
| Applications Location | Node Nr. | Private Cloud | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| CPU | CPU Load Setting | RAM Setting | RAM Load Setting | Hard Disk Volume | HD Usage Setting | Shared RAM Setting | Shared RAM Usage Setting | ||||
| Avg | Peak | Avg | Peak | ||||||||
| Data Server | 2 | 16-core | 30% | 70% | 32 GB | 30% | 70% | 300 GB×2 | 30% | 2 TB | 50% |
| IO Server | 2 | 16-core | 30% | 70% | 32 GB | 30% | 70% | 300 GB×2 | 30% | ||
| Station (Cloud desktop) | 6 | 8-core | 30% | 70% | 4 GB | 30% | 70% | 1 TB | 30% | ||
| No. * | Resident Memory | Migrated? | Host | Peak Memory Consuming | Peak CPU Consuming | Data Transfer Consuming | |||
|---|---|---|---|---|---|---|---|---|---|
| Before % | After % | Before % | After % | Before kbps | After kbps | ||||
| 1 | 0.223 K | NO | Edge | 0.4013 | 0.4123 | 1.164 | 1.163 | 0.00 | 0.00 |
| 2 | 15.012 K | NO | Edge | 1.1290 | 1.1516 | 2.625 | 3.643 | 0.00 | 0.00 |
| 3 | 0.101 K | NO | Edge | 0.8671 | 0.8064 | 0.877 | 0.991 | 0.00 | 0.00 |
| 4 | 0.332 K | NO | Edge | 0.5527 | 0.5582 | 0.538 | 0.544 | 0.00 | 0.00 |
| 5 | 18.556 K | YES | Cloud | 2.6345 | 2.3472 | 2.456 | 1.221 | 0.00 | 16.00 |
| 6 | 5.105 K | NO | Edge | 1.6151 | 2.5041 | 0.976 | 1.911 | 0.00 | 0.00 |
| 7 | 0.214 K | YES | Cloud | 0.2889 | 0.0096 | 0.243 | 0.211 | 0.00 | 16.00 |
| 8 | 0.101 K | NO | Edge | 0.2661 | 0.3006 | 3.196 | 4.323 | 0.00 | 0.00 |
| 9 | 0.109 K | NO | Edge | 0.5212 | 0.5175 | 2.223 | 2.222 | 0.00 | 0.00 |
| 10 | 0.176 K | NO | Edge | 0.5207 | 0.5763 | 3.350 | 3.011 | 0.00 | 0.00 |
| 11 | 128.241 M | YES | Cloud | 2.9427 | 1.9921 | 16.425 | 9.989 | 32.00 | 17.00 |
| 12 | 26.442 M | YES | Cloud | 3.2364 | 2.8911 | 6.321 | 3.667 | 20.00 | 12.70 |
| 13 | 770.009 M | YES | Cloud | 5.2563 | 4.9724 | 20.025 | 13.321 | 66.00 | 12.70 |
| 14 | 14.500 M | YES | Cloud | 2.0231 | 1.7031 | 11.115 | 6.006 | 16.00 | 12.70 |
| Items | Before Migration | After Migration | Change Rate |
|---|---|---|---|
| Node | 7 | 7 | 0% (−) |
| Computing unit | 13 | 9 | 30.77% (↓) |
| RAM consuming (unit:10 M) | 22.255 | 20.742 | 6.80% (↓) |
| Call relationship (unit:100 pairs) | 52.7 | 34.2 | 35.10% (↓) |
| CPU usage (/%) | 71.53 | 52.22 | 27.00% (↓) |
| Components | 73 | 73 | 0% (-) |
| Data structure | 78 | 92 | 17.95% (↑) |
| Response time (ms) | 96.03 | 75.48 | 21.40% (↓) |
| Path | 146 | 75 | 48.63% (↓) |
| Bandwidth (kbps) | 134 | 87.1 | 35.00% (↓) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, J.; Sun, L.; Chu, P.; Yu, Y. Computing Unit and Data Migration Strategy under Limited Resources: Taking Train Operation Control System as an Example. Electronics 2024, 13, 4328. https://doi.org/10.3390/electronics13214328
Yuan J, Sun L, Chu P, Yu Y. Computing Unit and Data Migration Strategy under Limited Resources: Taking Train Operation Control System as an Example. Electronics. 2024; 13(21):4328. https://doi.org/10.3390/electronics13214328
Chicago/Turabian StyleYuan, Jianjun, Laiping Sun, Pengzi Chu, and Yi Yu. 2024. "Computing Unit and Data Migration Strategy under Limited Resources: Taking Train Operation Control System as an Example" Electronics 13, no. 21: 4328. https://doi.org/10.3390/electronics13214328
APA StyleYuan, J., Sun, L., Chu, P., & Yu, Y. (2024). Computing Unit and Data Migration Strategy under Limited Resources: Taking Train Operation Control System as an Example. Electronics, 13(21), 4328. https://doi.org/10.3390/electronics13214328