
SOAMC: A Semi-Supervised Open-Set Recognition Algorithm for Automatic Modulation Classification


Abstract
1. Introduction
- •
- We propose a semi-supervised open-set modulation recognition algorithm called SOAMC, which performs label propagation on a large number of unlabeled samples. This approach effectively addresses the challenge of automatic modulation classification and recognition in open environments, relying only on a small number of labeled samples.
- •
- We design an adaptive enhancement module that leverages data augmentation and adaptive modulation techniques to significantly enhance the robustness of the pre-trained model. Experimental results demonstrate that this module effectively improves the model’s recognition accuracy, even when only a small number of labeled samples are available.
- •
- We propose an open-set feature embedding strategy that effectively utilizes a minimal number of labeled samples to achieve accurate classification in open-set modulation recognition. The effectiveness of the proposed algorithm is validated through simulation experiments.
2. Related Works
2.1. Semi-Supervised Learning
2.2. Data Augmentation
2.3. Automatic Modulation Classification Utilizing Deep Learning
3. Method
3.1. Adaptive Enhancement Module
3.1.1. Data Augmentation
| Algorithm 1 Adaptive Enhancement Module |
|
3.1.2. Threshold Adjustment
3.2. Open-Set Feature Embedding
3.3. Graph Neural Network
4. Experiment
4.1. Simulation Verification
4.1.1. Simulation Setup
4.1.2. Simulation Results
4.2. Comparative Experiment
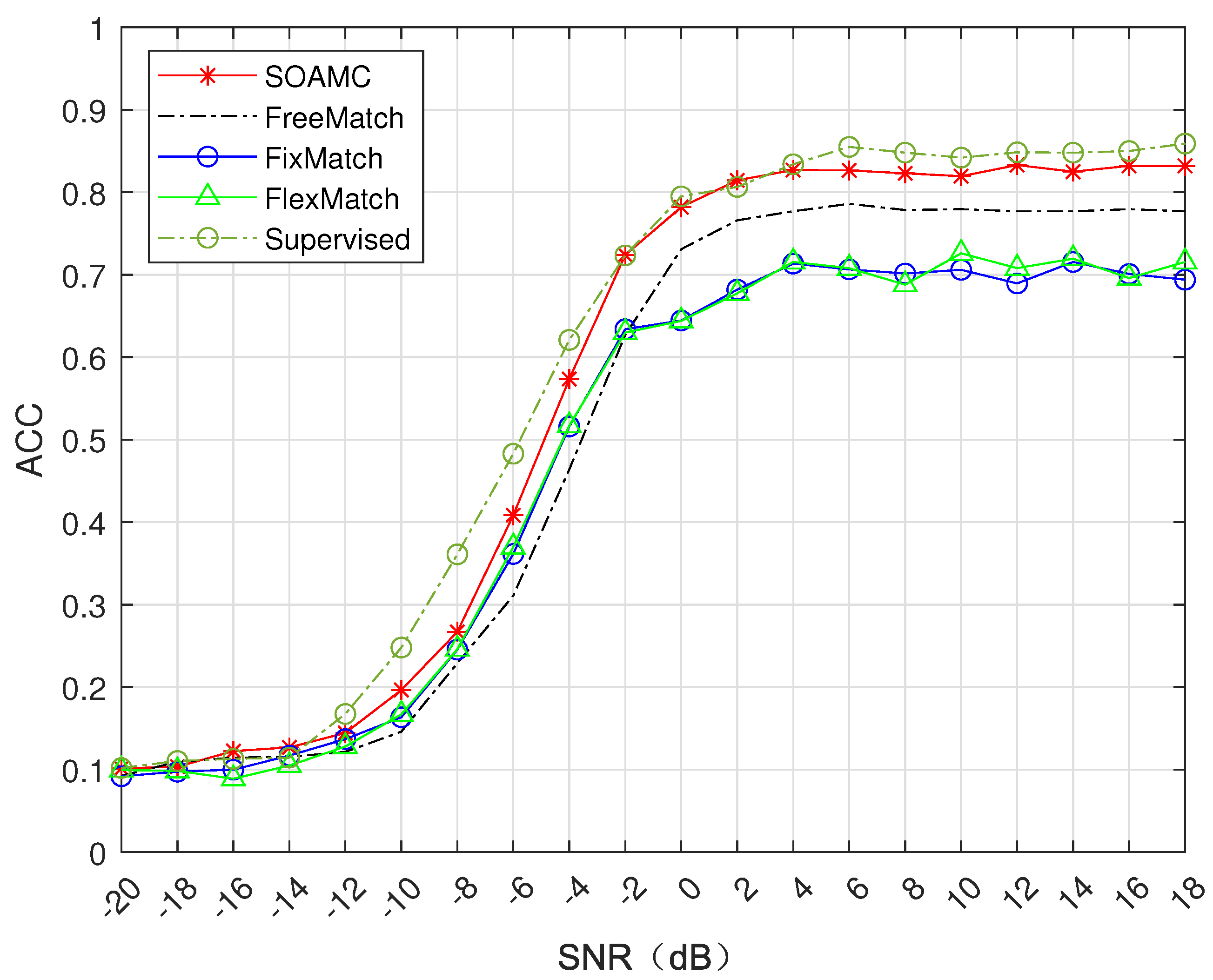
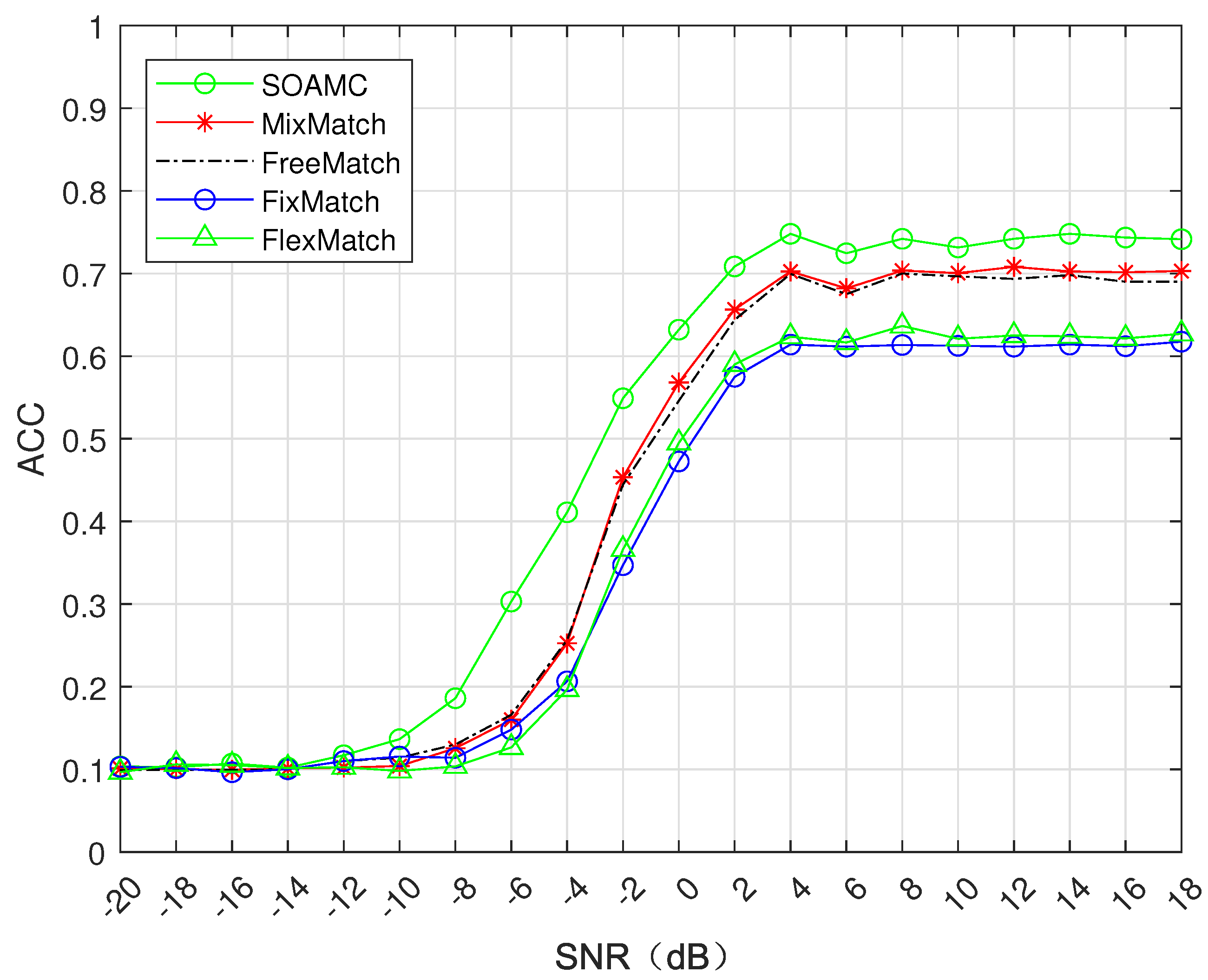
4.2.1. Public Dataset Validation
4.2.2. Self-Made Dataset Verification
4.3. Complexity Analysis
5. Conclusions
- •
- This paper presents a novel approach to open-set recognition and semi-supervised modulation signal classification, aiming to improve the accuracy of classifying known samples while developing robust rejection mechanisms for samples from unknown classes. However, the subsequent processing and interpretability of rejected samples remain underexplored. Future work could benefit from a deeper investigation into extending open-set recognition tasks by incorporating new class discovery techniques, which would enhance the system’s ability to manage previously unseen modulation types.
- •
- Furthermore, while the proposed method demonstrates strong performance when a small number of unknown category samples are manually labeled, exploring alternative approaches to identify unknown data without relying on manual labeling is a compelling avenue for future research. This would involve developing fully automated mechanisms to recognize unknown categories, expanding the applicability of the method in more dynamic and real-time communication environments.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dobre, O.A.; Abdi, A.; Bar-Ness, Y.; Su, W. Survey of automatic modulation classification techniques: Classical approaches and new trends. IET Commun. 2007, 1, 137–156. [Google Scholar] [CrossRef]
- Xu, J.L.; Su, W.; Zhou, M. Likelihood-ratio approaches to automatic modulation classification. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2010, 41, 455–469. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, C.; Gan, C.; Sun, S.; Wang, M. Automatic modulation classification using convolutional neural network with features fusion of SPWVD and BJD. IEEE Trans. Signal Inf. Process. Netw. 2019, 5, 469–478. [Google Scholar] [CrossRef]
- Zheng, S.; Hu, J.; Zhang, L.; Qiu, K.; Chen, J.; Qi, P.; Zhao, Z.; Yang, X. FM-Based Positioning via Deep Learning. IEEE J. Sel. Areas Commun. 2024, 42, 2568–2584. [Google Scholar] [CrossRef]
- Zheng, S.; Yang, Z.; Shen, F.W.; Zhang, L.; Zhu, J.; Zhao, Z.; Yang, X. Deep Learning-Based DOA Estimation. IEEE Trans. Cogn. Commun. Netw. 2024, 10, 819–835. [Google Scholar] [CrossRef]
- Qi, P.; Jiang, T.; Xu, J.; He, J.; Zheng, S.; Li, Z. Unsupervised Spectrum Anomaly Detection with Distillation and Memory Enhanced Autoencoders. IEEE Internet Things J. 2024. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Zhou, Z.H. Semi-supervised learning. Mach. Learn. 2021, 315–341. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, Q.; Wu, J.; Pan, S.; Chen, Y. Time series feature learning with labeled and unlabeled data. Pattern Recognit. 2019, 89, 55–66. [Google Scholar] [CrossRef]
- Simao, M.; Mendes, N.; Gibaru, O.; Neto, P. A review on electromyography decoding and pattern recognition for human-machine interaction. IEEE Access 2019, 7, 39564–39582. [Google Scholar] [CrossRef]
- Lee, D.H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Workshop on Challenges in Representation Learning; ICML: San Diego, CA, USA, 2013; pp. 1–6. [Google Scholar]
- Zou, Y.; Yu, Z.; Liu, X.; Kumar, B.; Wang, J. Confidence regularized self-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5982–5991. [Google Scholar]
- Mukherjee, S.; Awadallah, A.H. Uncertainty-aware self-training for text classification with few labels. arXiv 2020, arXiv:2006.15315. [Google Scholar]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.A.; Cubuk, E.D.; Kurakin, A.; Li, C.L. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Adv. Neural Inf. Process. Syst. 2020, 33, 596–608. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 702–703. [Google Scholar]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, T.; Le, Q. Unsupervised data augmentation for consistency training. Adv. Neural Inf. Process. Syst. 2020, 33, 6256–6268. [Google Scholar]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends® Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning (still) requires rethinking generalization. Commun. ACM 2021, 64, 107–115. [Google Scholar] [CrossRef]
- Gui, G.; Huang, H.; Song, Y.; Sari, H. Deep learning for an effective nonorthogonal multiple access scheme. IEEE Trans. Veh. Technol. 2018, 67, 8440–8450. [Google Scholar] [CrossRef]
- Zhang, Y.; Doshi, A.; Liston, R.; Tan, W.t.; Zhu, X.; Andrews, J.G.; Heath, R.W. DeepWiPHY: Deep learning-based receiver design and dataset for IEEE 802.11 ax systems. IEEE Trans. Wirel. Commun. 2020, 20, 1596–1611. [Google Scholar] [CrossRef]
- Ghasemzadeh, P.; Banerjee, S.; Hempel, M.; Sharif, H. A novel deep learning and polar transformation framework for an adaptive automatic modulation classification. IEEE Trans. Veh. Technol. 2020, 69, 13243–13258. [Google Scholar] [CrossRef]
- Lyu, Z.; Wang, Y.; Li, W.; Guo, L.; Yang, J.; Sun, J.; Liu, M.; Gui, G. Robust automatic modulation classification based on convolutional and recurrent fusion network. Phys. Commun. 2020, 43, 101213. [Google Scholar] [CrossRef]
- Weng, L.; He, Y.; Peng, J.; Zheng, J.; Li, X. Deep cascading network architecture for robust automatic modulation classification. Neurocomputing 2021, 455, 308–324. [Google Scholar] [CrossRef]
- Zhang, H.; Nie, R.; Lin, M.; Wu, R.; Xian, G.; Gong, X.; Yu, Q.; Luo, R. A deep learning based algorithm with multi-level feature extraction for automatic modulation recognition. Wirel. Netw. 2021, 27, 4665–4676. [Google Scholar] [CrossRef]
- Shang, J.; Sun, Y. Predicting the hosts of prokaryotic viruses using GCN-based semi-supervised learning. BMC Biol. 2021, 19, 250. [Google Scholar] [CrossRef]
- Ju, Y.; Gao, Z.; Wang, H.; Liu, L.; Pei, Q.; Dong, M.; Mumtaz, S.; Leung, V.C.M. Energy-efficient cooperative secure communications in mmwave vehicular networks using deep recurrent reinforcement learning. IEEE Trans. Intell. Transp. Syst. 2024, 25, 14460–14475. [Google Scholar] [CrossRef]
- Ju, Y.; Cao, Z.; Chen, Y.; Liu, L.; Pei, Q.; Mumtaz, S.; Dong, M.; Guizani, M. Noma-assisted secure offloading for vehicular edge computing networks with asynchronous deep reinforcement learning. IEEE Trans. Intell. Transp. Syst. 2024, 25, 2627–2640. [Google Scholar] [CrossRef]
- Li, C.; Guan, L.; Wu, H.; Cheng, N.; Li, Z.; Shen, X.S. Dynamic spectrum control-assisted secure and efficient transmission scheme in heterogeneous cellular networks. Engineering 2022, 17, 220–231. Available online: https://www.sciencedirect.com/science/article/pii/S2095809921002666 (accessed on 17 October 2024). [CrossRef]
- Han, H.; Ma, W.; Zhou, M.; Guo, Q.; Abusorrah, A. A novel semi-supervised learning approach to pedestrian reidentification. IEEE Internet Things J. 2020, 8, 3042–3052. [Google Scholar] [CrossRef]
- Khonglah, B.; Madikeri, S.; Dey, S.; Bourlard, H.; Motlicek, P.; Billa, J. Incremental semi-supervised learning for multi-genre speech recognition. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 7419–7423. [Google Scholar]
- O’Shea, T.J.; Corgan, J.; Clancy, T.C. Unsupervised representation learning of structured radio communication signals. In Proceedings of the 2016 First International Workshop on Sensing, Processing and Learning for Intelligent Machines (SPLINE), Aalborg, Denmark, 6–8 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–5. [Google Scholar]
- O’Shea, T.J.; West, N.; Vondal, M.; Clancy, T.C. Semi-supervised radio signal identification. In Proceedings of the 2017 19th International Conference on Advanced Communication Technology (ICACT), Pyeongchang, Republic of Korea, 19–22 February 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 33–38. [Google Scholar]
- O’shea, T.J.; West, N. Radio machine learning dataset generation with gnu radio. In Proceedings of the GNU Radio Conference, Boulder, CO, USA, 12–16 September 2016; Volume 1. [Google Scholar]
- Zhang, M.; Zeng, Y.; Han, Z.; Gong, Y. Automatic modulation recognition using deep learning architectures. In Proceedings of the 2018 IEEE 19th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Kalamata, Greece, 25–28 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- Zheng, S.; Qi, P.; Chen, S.; Yang, X. Fusion methods for CNN-based automatic modulation classification. IEEE Access 2019, 7, 66496–66504. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, Y.; He, Z.; Nie, J.; Zhang, W. A novel attention cooperative framework for automatic modulation recognition. IEEE Access 2020, 8, 15673–15686. [Google Scholar] [CrossRef]
- Huynh-The, T.; Pham, Q.V.; Nguyen, T.V.; Nguyen, T.T.; Ruby, R.; Zeng, M.; Kim, D.S. Automatic modulation classification: A deep architecture survey. IEEE Access 2021, 9, 142950–142971. [Google Scholar] [CrossRef]
- Zhang, B.; Wang, Y.; Hou, W.; Wu, H.; Wang, J.; Okumura, M.; Shinozaki, T. Flexmatch: Boosting semi-supervised learning with curriculum pseudo labeling. Adv. Neural Inf. Process. Syst. 2021, 34, 18408–18419. [Google Scholar]
- Wang, Y.; Chen, H.; Heng, Q.; Hou, W.; Fan, Y.; Wu, Z.; Wang, J.; Savvides, M.; Shinozaki, T.; Raj, B.; et al. Freematch: Self-adaptive thresholding for semi-supervised learning. arXiv 2022, arXiv:2205.07246. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Type | Modulation Type | Number of Data |
|---|---|---|
| Known Category | BPSK, QPSK, 8PSK, 16QAM, 2FSK, 4FSK, 8FSK, 4CPM, 4PAM, 16PAM. | 30 per SNR |
| Unknown Category | 32QAM, OOK, 8ASK, FM | 10 per SNR |
| Layers | Output Size | Configuration |
|---|---|---|
| Convolution 1 | Conv,32, | |
| Convolution 2 | Conv,64, | |
| Residual Block 1 | ||
| Residual Block 2 | ||
| Residual Block 3 | ||
| Residual Block 4 | ||
| Residual Block 5 | ||
| Residual Block 6 | ||
| Pooling Layer | Global average pool | |
| Classification | 128 | Fully connected layer |
| 64 | Fully connected layer | |
| M | Fully connected layer |
| Metrics | Ours | FlexMatch |
|---|---|---|
| Multiplication and division | 38,410,112 | 44,308,907 |
| Addition and subtraction | 38,467,456 | 44,308,907 |
| Comparator | 212,864 | 258,145 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Di, C.; Ji, J.; Sun, C.; Liang, L. SOAMC: A Semi-Supervised Open-Set Recognition Algorithm for Automatic Modulation Classification. Electronics 2024, 13, 4196. https://doi.org/10.3390/electronics13214196
Di C, Ji J, Sun C, Liang L. SOAMC: A Semi-Supervised Open-Set Recognition Algorithm for Automatic Modulation Classification. Electronics. 2024; 13(21):4196. https://doi.org/10.3390/electronics13214196
Chicago/Turabian StyleDi, Chengliang, Jinwei Ji, Chao Sun, and Linlin Liang. 2024. "SOAMC: A Semi-Supervised Open-Set Recognition Algorithm for Automatic Modulation Classification" Electronics 13, no. 21: 4196. https://doi.org/10.3390/electronics13214196
APA StyleDi, C., Ji, J., Sun, C., & Liang, L. (2024). SOAMC: A Semi-Supervised Open-Set Recognition Algorithm for Automatic Modulation Classification. Electronics, 13(21), 4196. https://doi.org/10.3390/electronics13214196