

Augmenting Large Language Models with Rules for Enhanced Domain-Specific Interactions: The Case of Medical Diagnosis



Abstract
1. Introduction
- The domain space of AI–user interaction is associated with rules of dialogue to be followed, as detailed later in the paper in Table 1 in Section 4.1. This provides a theoretical basis for the evaluation of the performance and the assessment of an LLM’s ability to remain within these constraints, which aim to simulate real-time/real-world interactions. The process is systemized and generalized to reach a measurable conclusion on the LLM answers, within a domain-specific context and a dialogue-defined space.
- Using NLP algorithms, we define the blueprint of domain-specific knowledge and the domain-specific content that is relevant to the user. This enhances the AI–user interaction experience within a medical context.
- A methodology is introduced, represented through a process diagram, aimed at defining generative AI processes and functions with a rule-augmented approach for the prototyping of AI-empowered systems.
- The system, which utilizes the GPT-4 engine, has undergone extensive evaluation through multiple-choice questions that focus on symptomatology in the field of general pathology.
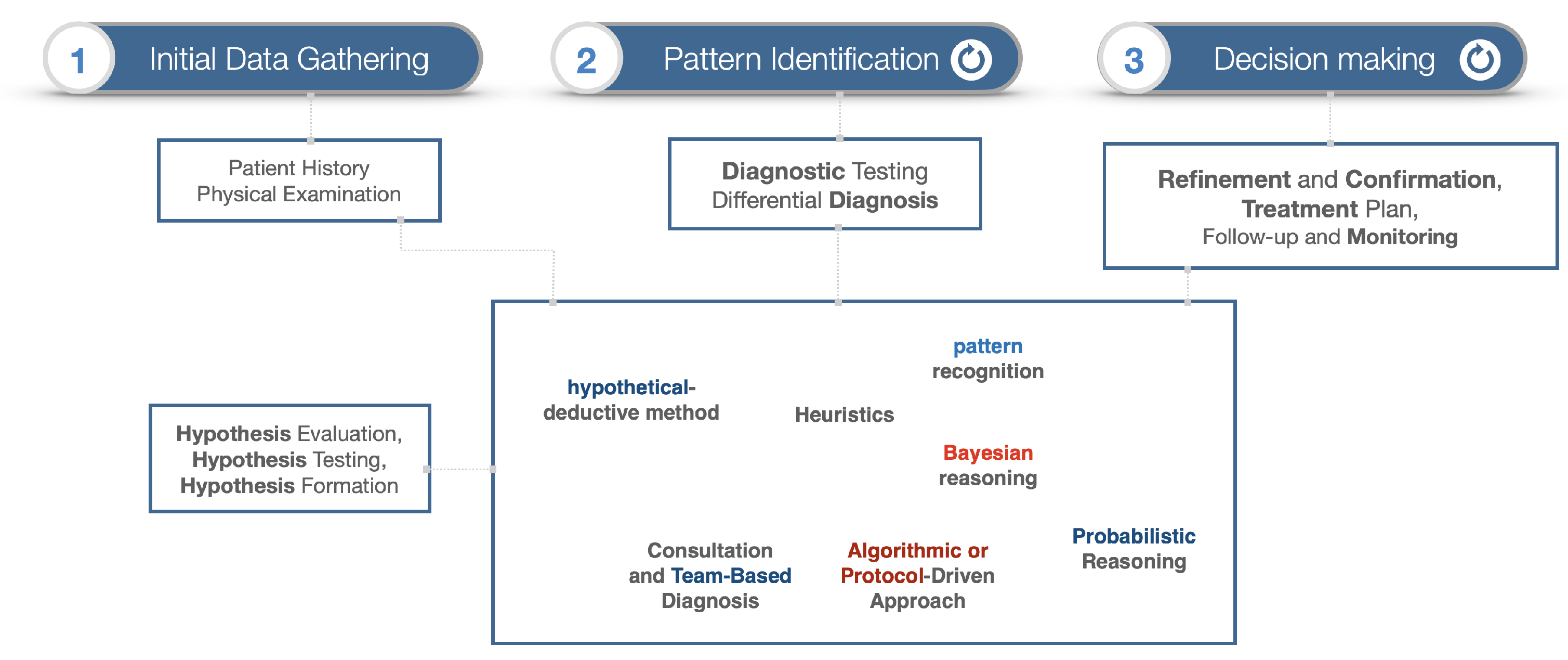
2. Background Theories and Context
2.1. Natural Language Processing
- NLP using pattern matching and substitution: These initial NLP systems depend on manually crafted rules and lexicons. An iconic example is the ELIZA chatbot [23], created in 1964. ELIZA was one of the first programs capable of attempting the Turing test.
- ML models: This category encompasses traditional models like naive Bayes, support vector machines (SVM), and decision trees, commonly applied in text classification and sentiment analysis.
- Neural networks: Inspired by the human brain, these models include recurrent neural networks (RNNs) and convolutional neural networks (CNNs), suitable for tasks needing an understanding of a language’s sequential nature.
- Embedding models: These models produce dense vector representations of words or larger text units, capturing semantic meanings. Notable examples include Word2Vec, GloVe, and FastText [24].
- Sequence-to-sequence models: Capable of transforming input sequences into output sequences, these models are integral to machine translation and text summarization, often based on an encoder–decoder architecture with attention mechanisms [25].
- Large language models (LLMs): LLMs are designed to perform a wide range of NLP tasks, from translation to question answering and to text generation, without needing task-specific training data. LLMs are further discussed in the following section.
2.2. Large Language Models (LLMs)
- Markov Models: Based on the principle named after mathematician Andrey Markov, these probabilistic models assume that the probability of each subsequent state depends only on the current state. Their application is particularly notable in sequential tasks like language modeling.
- Hidden Markov Models (HMMs): An extension of Markov models, HMMs include hidden states and observable outputs. They find applications in NLP tasks, notably in part-of-speech tagging and named entity recognition.
- Conditional Random Fields (CRFs): These are statistical frameworks used in NLP to model the probability of outputs given specific inputs. Unlike HMMs, CRFs take into account the entire sequence of words, thereby yielding more accurate results.
- n-gram Models: These models predict the next item in a sequence by considering the previous (n − 1) items. Predicated on the assumption that a word’s probability is dependent solely on its preceding words, n-gram models are prevalent in areas like speech recognition and machine translation.
- Latent Dirichlet Allocation (LDA) is a generative statistical model that allows sets of observations to be explained by unobserved groups. In NLP, these groups or topics help us to understand why data parts are similar, positing each document as a topic mixture with each word attributed to a document’s topic.
2.3. Problems with NLP and Evaluation Pipeline
- Bias: LLMs learn and reproduce the biases that exist in their training datasets [28].
- Lack of explainability: Generative AI systems typically do not provide explicit explanations for the conclusions that they reach or the answers that they provide [29,30]. Explainable AI (XAI) ensures that users comprehend the characteristics of the utilized models and provide a transparent representation of the used algorithms that generate a response, a classification, or a recommendation. Considering user ability and adding personalization in XAI is also an important factor that can increase transparency and lead to the greater adoption of AI-empowered systems [31]. Current GAI systems lack explainability, particularly in terms of personalized explanations.
- Real-time validation: The responses are not derived from real-time information. Instead, they are based on the dataset that was used to train the model that typically contains information from a period up to the date of the training of the tool [27].
- Limitations in mathematical operations: This limitation is partially addressed using Python modules for calculations and by providing updated models more frequently.
- Content—token size limitation: This limitation is partially addressed by increasing the token size limits and charging higher usage costs.
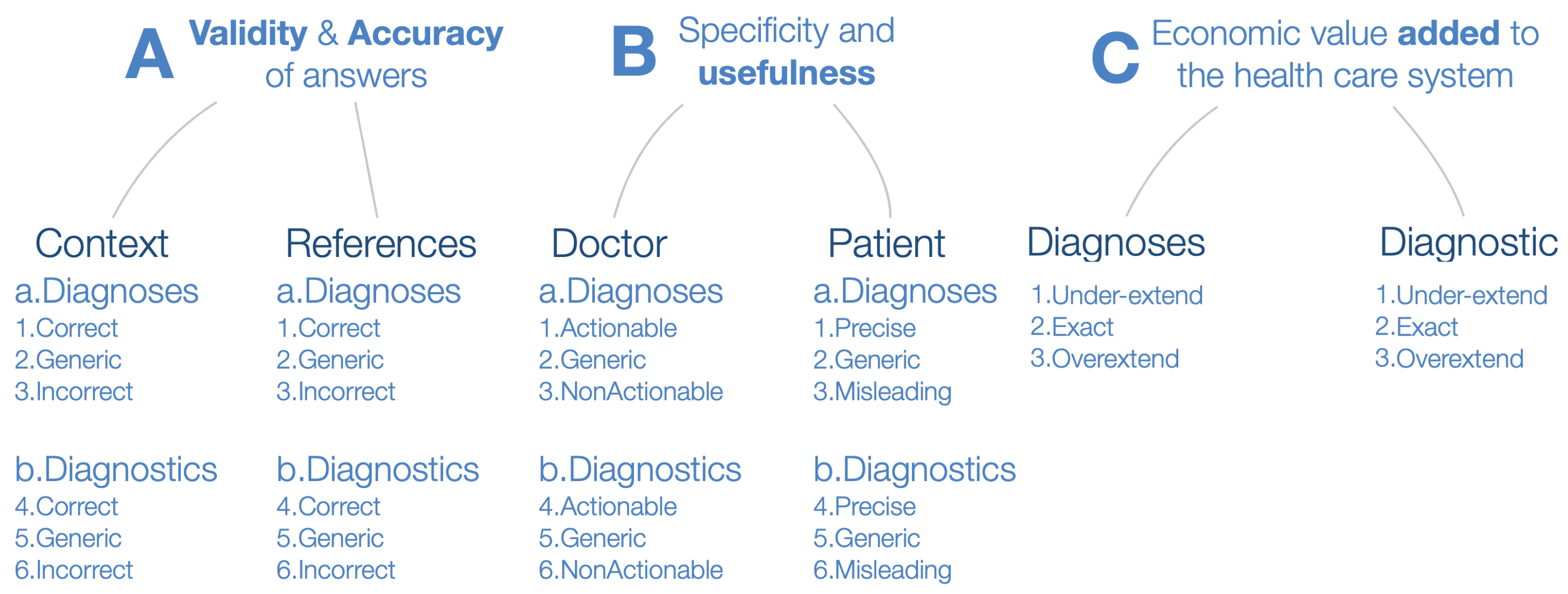
- correct (3), generic (2), or incorrect (1);
- actionable (3), generic (2), or non-actionable (1);
- precise (3), generic (2), or misleading (1);
- under-extended (2), exactly aligned (1), or over-extended (1).
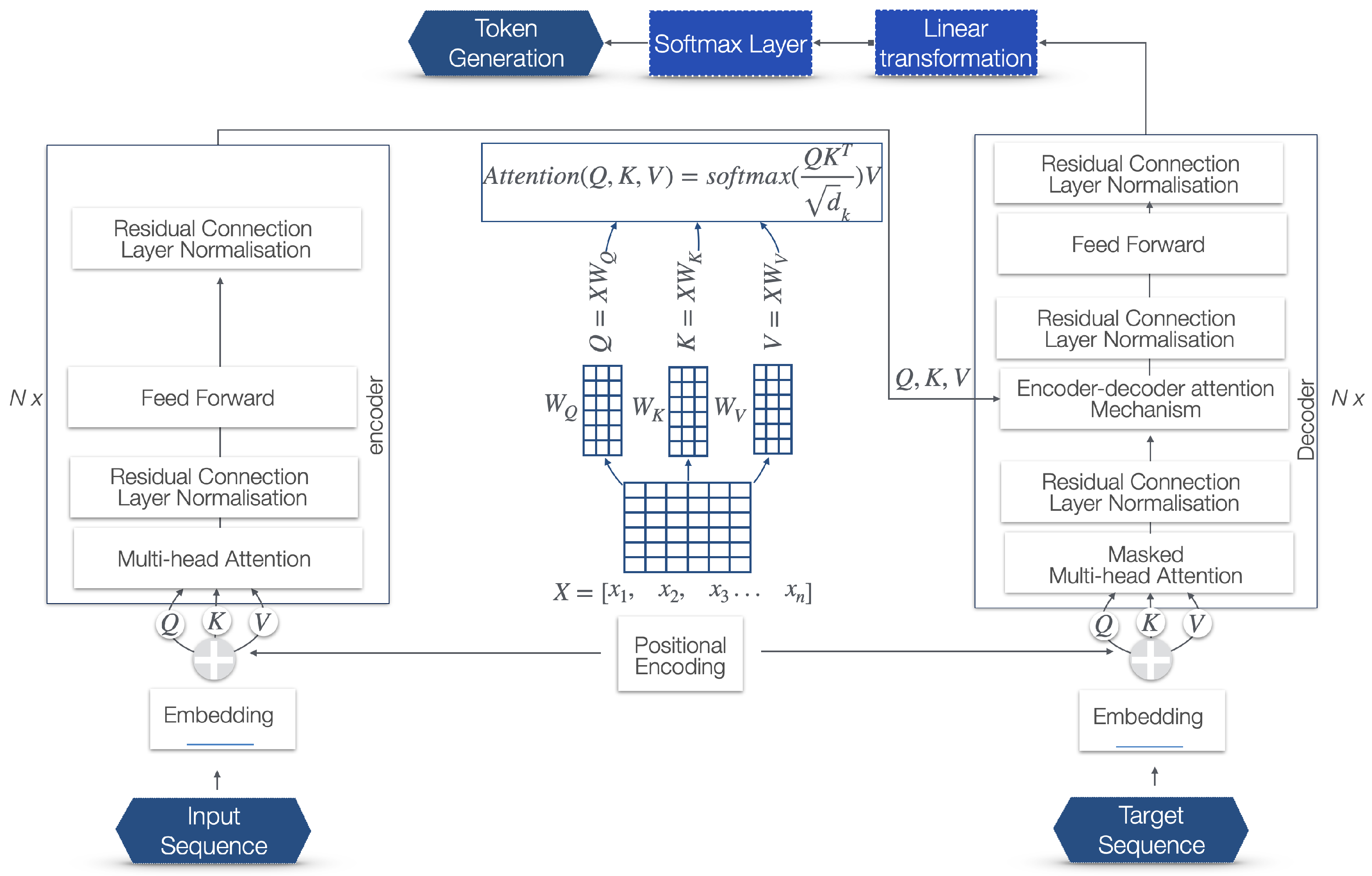
2.4. Transformers and Attention Mechanism
- Encoder: The left part of the diagram represents the encoder, which processes the input data. The input sequence is processed through multiple layers of multi-head attention and feed-forward networks, with each of these layers followed by the residual connection and linear normalization steps.
- –
- Embeddings: The numerical representations of words, phrases, or other types of data. In the case of LLMs, they represent words or tokens. Each word or token is mapped to a vector of real numbers that captures semantic and syntactic information about the word. The words with similar meanings or used in similar contexts will have similar vector representations.
- *
- Input Sequence Embedding: Input tokens’ conversion into vectors of a fixed dimension.
- –
- Positional Encoding: Adds information about the positional order of the respective words of the sequence.
- –
- Multi-Head Attention: Applies self-attention multiple times in parallel to capture different aspects of the data. This allows joint attention to information from different representation subspaces, referred to as heads, at different positions. Using multiple heads, the model captures different types of dependencies from different representational spaces. For example, one head might learn to pay attention to syntactic dependencies, while another might learn semantic dependencies. The mathematical representation of this is as follows. Let us we denote the linear transformations that produce the queries, keys, and values for head i with , , , respectively, and the output linear transformation with . Then, the multi-head attention operation MultiHead can be defined aswhere each head is computed asand Attention is the scaled dot-product attention function:Here, is the dimensionality of the key vectors, while the division by is the scaling factor.
- Q, K, V: The input to the multi-head attention layer is first linearly transformed into three different sets of vectors: queries (Q), keys (K), and values (V). This is done for each attention head using different, learned linear projections.
- Scaled dot-product attention: For each head, the scaled dot-product attention is independently calculated. The dot product is computed between each query and all keys, which results in a score that represents how much focus to place on other parts of the input for each word. These scores are scaled down by the dimensionality of the keys (typically the square root of the key dimension) to stabilize the gradients during training. A softmax function is applied to the scaled scores to obtain the weights on the values.
- Attention output: The softmax weights are then used to create a weighted sum of the value vectors. This results in an output vector for each head that is a combination of the input values, weighted by their relevance to each query.
- Concatenation: The output vectors from all heads are concatenated. Since each head may learn to attend to different features, concatenating them combines the different learned representation subspaces.
- Linear transformation: The concatenated output undergoes a linear transformation to produce the final product of the multi-head attention layer.
- Feed-forward network: A fully connected feed-forward network is applied to each position separately and identically.
- Residual connection and linear normalization: Applies residual connections and layer normalization.
- Decoder: The right part of the diagram represents the decoder that generates the output.
- –
- Target sequence embedding: Converts target tokens into vectors and shifts them to the right.
- –
- Masked multi-head attention: Prevents positions from attending to subsequent positions during training.
- –
- Encoder–decoder attention mechanism: Attends to the encoder’s output and the decoder’s input. The keys (K) and values (V) come from the output of the encoder. The similarity between the queries and keys is calculated. This involves taking the dot product of the queries with the keys, scaling it (usually by dividing by the square root of the dimension of the key vectors), and then applying a softmax function to obtain the weights for the values.
- –
- Feed-forward network: Following the attention mechanisms, there is a feed-forward network. It consists of two linear transformations with a ReLU activation in between.
- –
- Residual connection and linear normalization: Applies residual connections and layer normalization.
- –
- Linear transformation before softmax: In the final layer of the decoder, the Transformer model applies a linear transformation to the output of the previous layer. This linear transformation, typically a fully connected neural network layer (often referred to as a dense layer), projects the decoder’s output to a space whose dimensionality is equal to the size of the vocabulary.
- –
- Softmax function: After this linear transformation, a softmax function is applied to these projected values, which creates a probability distribution over the vocabulary based on the positional attributes.
- –
- Token selection: The probability distribution for each potential token is analyzed considering the context of the sequence. This analysis determines which tokens are most likely to be the appropriate next elements in the sequence. The token selection can be done using various strategies like greedy decoding, sampling, or beam search.
- –
- Token generation: Based on this probability distribution, tokens are generated as the output for each position in the sequence.
- –
- Sequence construction: The selected tokens are combined to form the output text sequence. This can involve converting sub-word tokens back into words and dealing with special tokens such as those that represent the start and end of a sentence.
- –
- Post-processing: Post-processing is performed, based on syntactical, grammatical, and language rules.
2.5. Telehealth
2.6. The State of Primary Care
2.7. NuhealhtSoft: An AI-Empowered Software Platform for Medical Exam Classification and Health Recommendations
3. System Overview of Med|Primary AI Assistant
- engineer prompts based on domain specification;
- extract semantically important words and associated with external services and classifiers and external sensors; and
- create an evaluation basis, to ensure alignment with domain specifications and requirements based on the dialogue’s theoretical context.
3.1. System Description
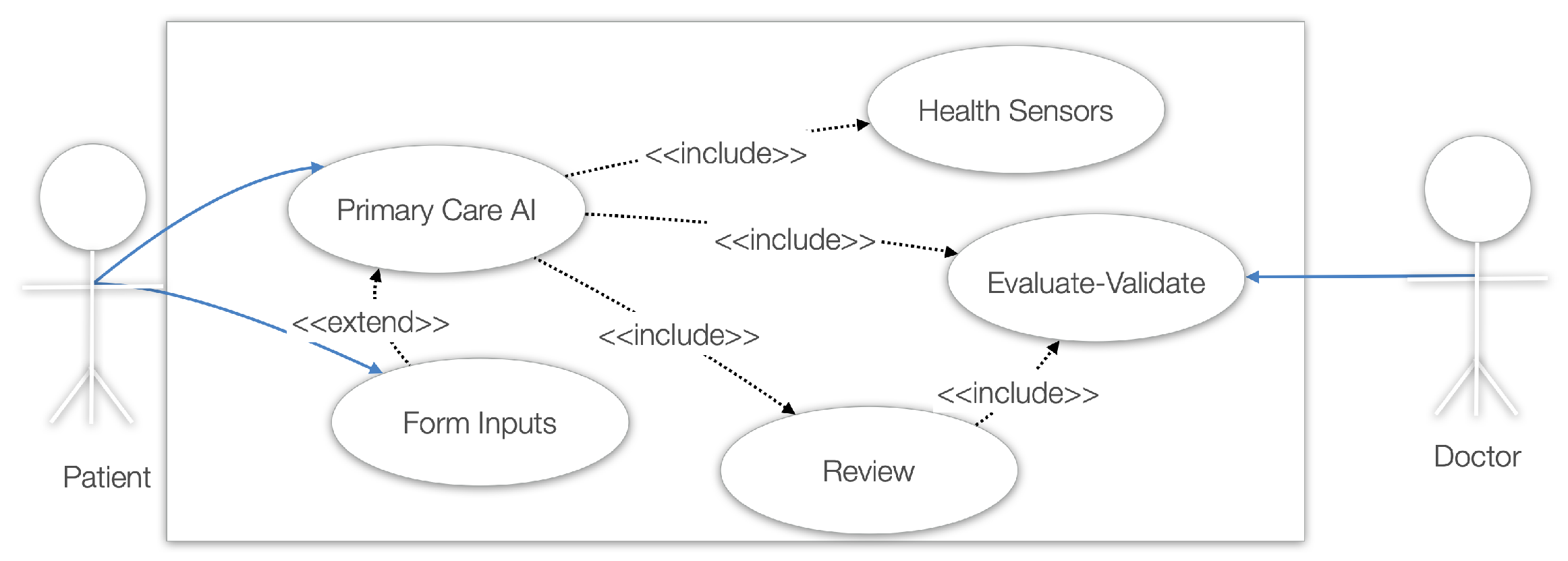
3.2. Use Cases
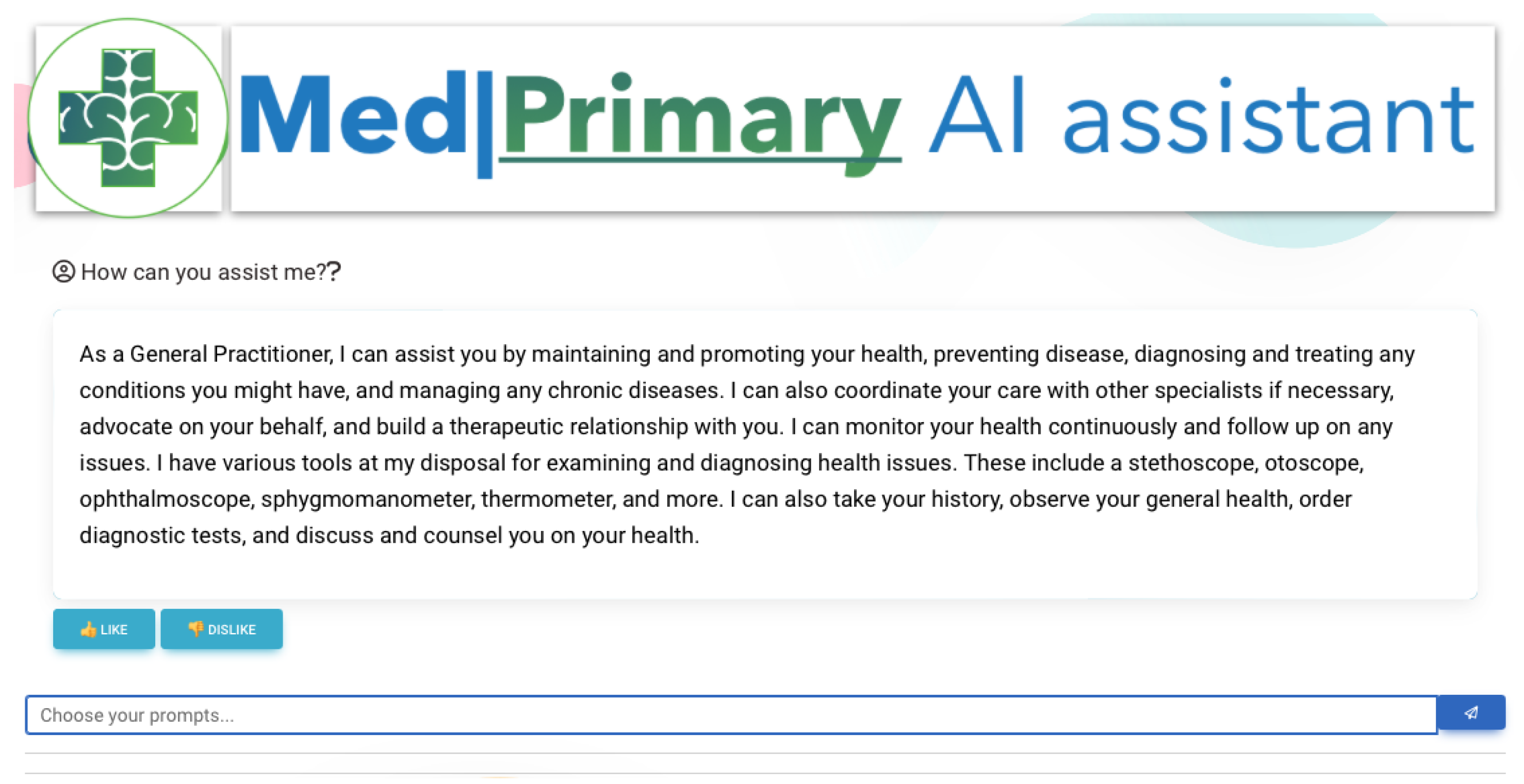
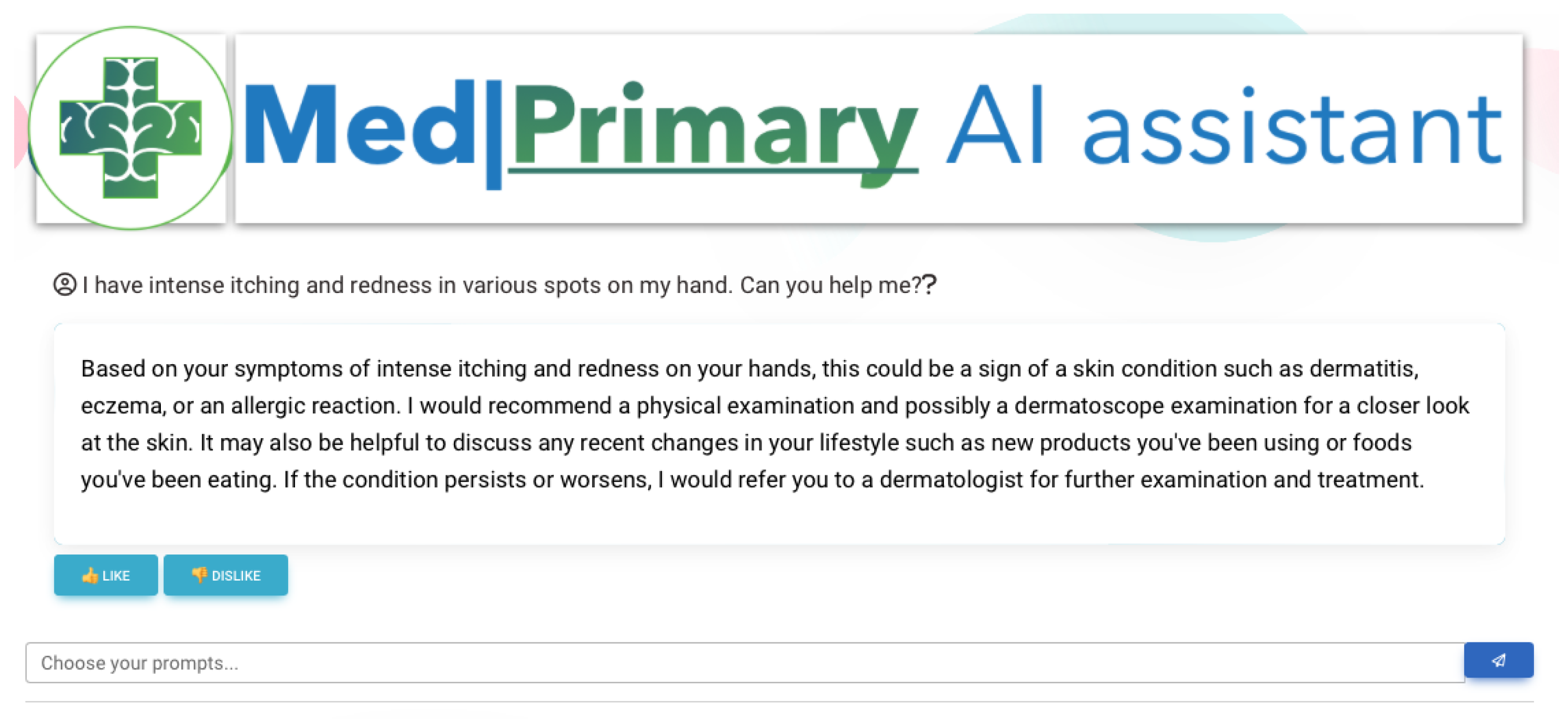
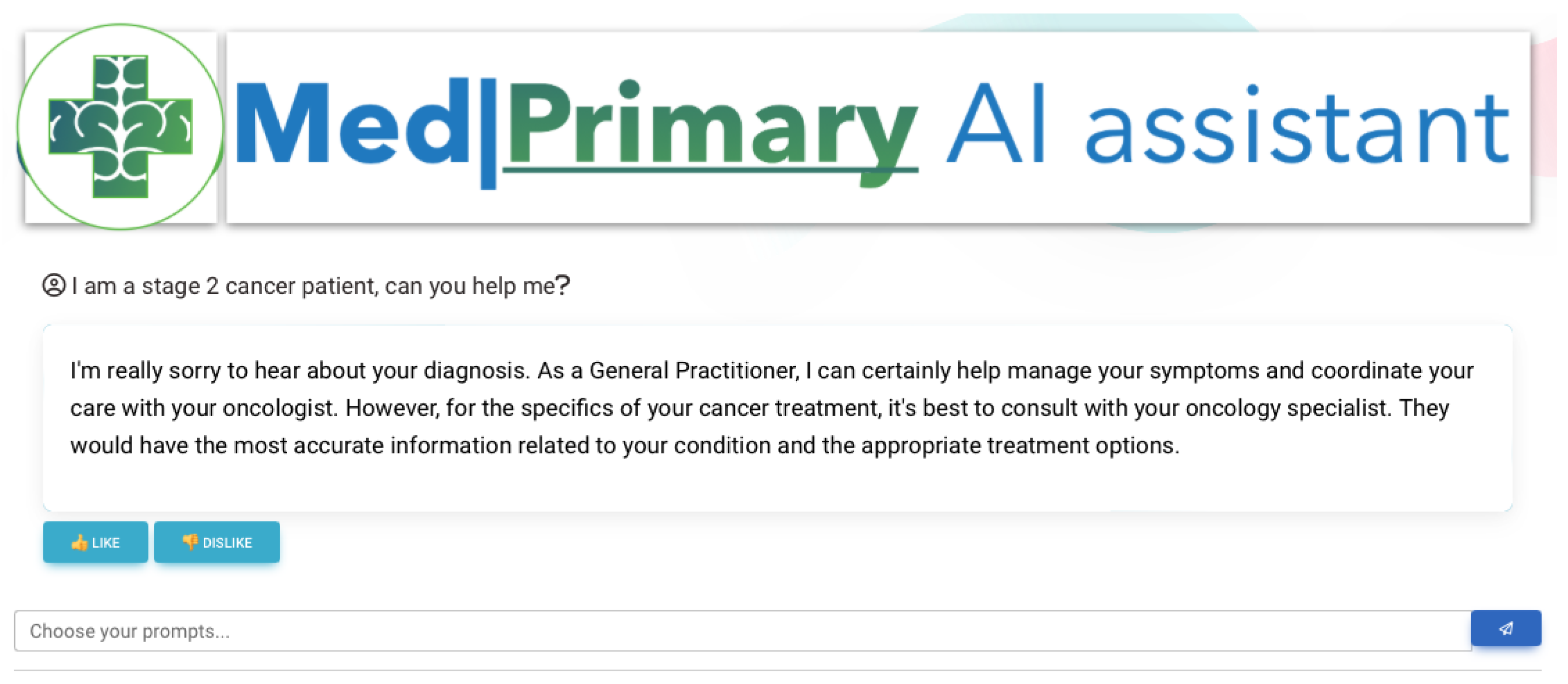
- The first is by freely (without constraints and rules) providing symptoms and descriptions of their health state and obtaining a series of diagnoses, proposed diagnostic exams, or a referral to a medical specialist. While, in this case, the patient has no constraints, using specific knowledge input, the LLM will provide assistance if the user’s input is not useful for the LLM to complete its predefined tasks and objectives.
- The second is by using a more constrained and step-by-step approach, for the LLM to obtain a more comprehensive background on the user’s symptomatology and age. In both cases, data can be retrieved by health sensors and analyzed by the included analytical and machine learning services [41].
4. System Architecture Analysis
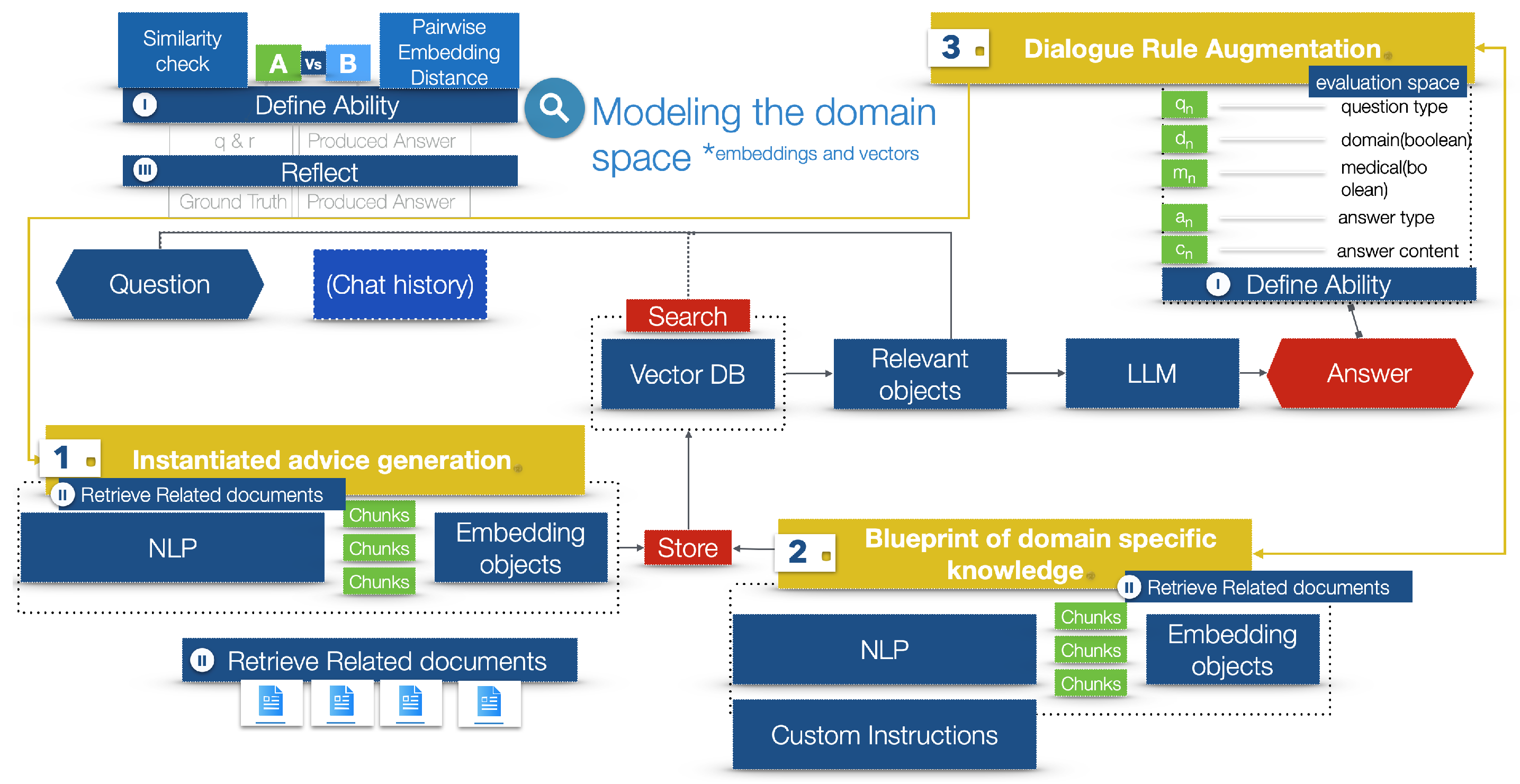
4.1. Modeling the Domain Space
- Questions
- (a)
- Informational: Query for specific information.
- (b)
- Instructional: Query related to specific task, i.e., a command to do something.
- (c)
- Reflective: To confirm or clarify previous statements.
- (d)
- Rhetorical: Are not meant to be answered and are rather used for emphasis.
- (e)
- Open-ended: Are meant to encourage a detailed response or discussion.
- (f)
- Closed-ended: Can be answered with a a yes or no.
- Answers
- (a)
- Direct: Provide a straightforward response.
- (b)
- Elaborated: Provide additional context and information beyond what was requested.
- (c)
- Clarifying: Aim at requiring clarity, where a query is ambiguous.
- (d)
- Reflected: Ensure that the question is answered in a way that mimics the question’s sentiment.
- (e)
- Deferred: When an answer cannot be provided and the one that provides it offers guidance on where or how to find it.
- (f)
- Non-Answers: When the choice is to not answer.
4.2. Domain Settings
- provide a basis for evaluating the performance;
- assess the model’s ability to remain within constraints that aim to simulate real-time communication protocols.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Question (q) | Domain (d) | Medical (m) | Answer (a) | Answer Content (c) | Use Case Examples |
|---|---|---|---|---|---|
| Open Ended | Yes | Yes | Direct or Elaborated | Define Ability (Ab), Reflect (Re) | Figure 7 |
| Informational | Yes | Yes | Direct or Elaborated | Define Ability (Ab), Reflect (Re) | Figure 8 |
| Any | No | Yes | (deferred) Refer To Specialist | Define Ability (Ab), Reflect (Re) | Figure 9 |
| Any | No | No | (deferred) Dialogue Reset | Define Ability (Ab), Reflect (Re) | Figure 10 |
- Question q.
- Domain d.
- Medical m.
- Answer a.
- Answer content c: Derived from the `instantiated advice generation’ (2) and the ’blueprint of domain-specific knowledge’ (1).
- Retrieve documents r: Sourced from (1) and (2) to show basis of produced answer.
- Process I (ability assessment): To define ability, we compare the answer produced by the LLM (a) to the ground truth (i.e., the correct answer) using similarity checks and pairwise embedding distance algorithms. This involves retrieving the documents (r) on which the answer was based.
- Process III (reflective capacity): The reflective capacity is calculated by applying similarity checks and pairwise embedding distance algorithms between a composite of the question (q) and answer type (a) and the answer content (c) produced by the LLM.
| Algorithm 1 Evaluation process based on rules. |
|
- Creation of embeddings
- (a)
- Training: Embeddings are usually created through supervised or unsupervised learning on large text corpora. At this stage, the model’s trained weights are used to create vectors.
- (b)
- Dimensionality: The vectors usually have hundreds of dimensions. Dimensionality reduction techniques (like PCA or t-SNE) can be applied for visualization.
- (c)
- Contextualization: Traditional embeddings (Word2Vec, GloVe) do not consider the context, meaning that they represent a word with the same vector regardless of its usage. Modern embeddings (BERT, GPT) are contextual, adjusting the representation based on the word’s usage in a sentence.
- (d)
- Transfer Learning: Pre-trained embeddings can be fine-tuned on a smaller dataset for specific tasks, leveraging the general language understanding learned during pre-training while adapting to the nuances of the task at hand.
- (e)
- Evaluation: The quality of embeddings is usually evaluated based on their performance in downstream NLP tasks like text classification, sentiment analysis, or named entity recognition.
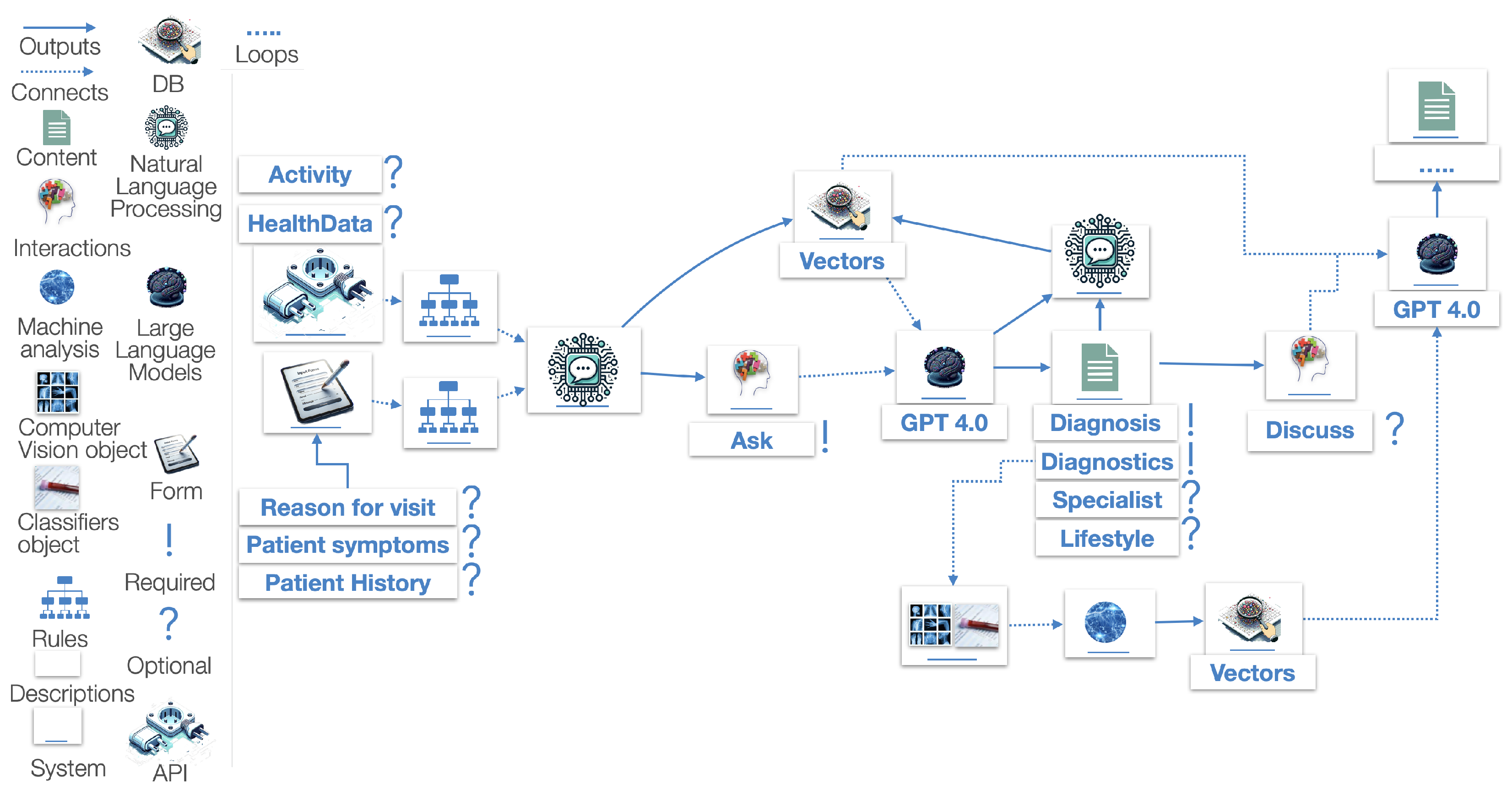
Using the created embeddings, the following processes are the splitting, chunking, and storage of the information in vector databases, which would either define the instantiated advice generation or the blueprint of domain-specific knowledge. - Vector stores are databases that specialize in storing, indexing, and querying high-dimensional vectors. These vectors can represent various types of data, such as images, text, or other complex data types, transformed into numerical representations [48]. They are extremely useful for a similarity search, which, in Figure 6, is the red rectangle named search, pointing to the vector database.
- A search is the process of retrieving documents stored in the vector store, either from the instantiated advice generation or the blueprint of domain-specific knowledge, based on a similarity threshold, manually defined. The higher the similarity threshold, the more restrictive the rules; thus, less documents are returned for processing.
| Algorithm 2 Q&A Chain |
|
4.3. System Architecture
4.3.1. Micro Level
- Outputs: Information exchange.
- Connects: Implies dependency.
- DB: Type of database procedure.
- Content: Generation of data.
- Interactions: User interaction, which leads to a generation.
- Natural Language Processing: Any NLP process.
- Large Language Model: LLM processing or LLM API call.
- Computer Vision Object: ML process related to computer vision.
- Classifier Object: ML process related to classification.
- Machine Analysis: ML service output in textual or numeric format.
- Rules: Rules that are used to augment the system and limit malfunctions.
- White Box: Description space for processes.
- White Box with Blue Line: Defines a function or system.
- Form: A type of user input form, in a predefined context, i.e., using questionnaires or pre-selected inputs.
- !: Required described process.
- ?: Optional described process.
- API: External communication process.
- Three Dots (...): Indicates a loop or a repetitive–iterative process.
4.3.2. Macro Level
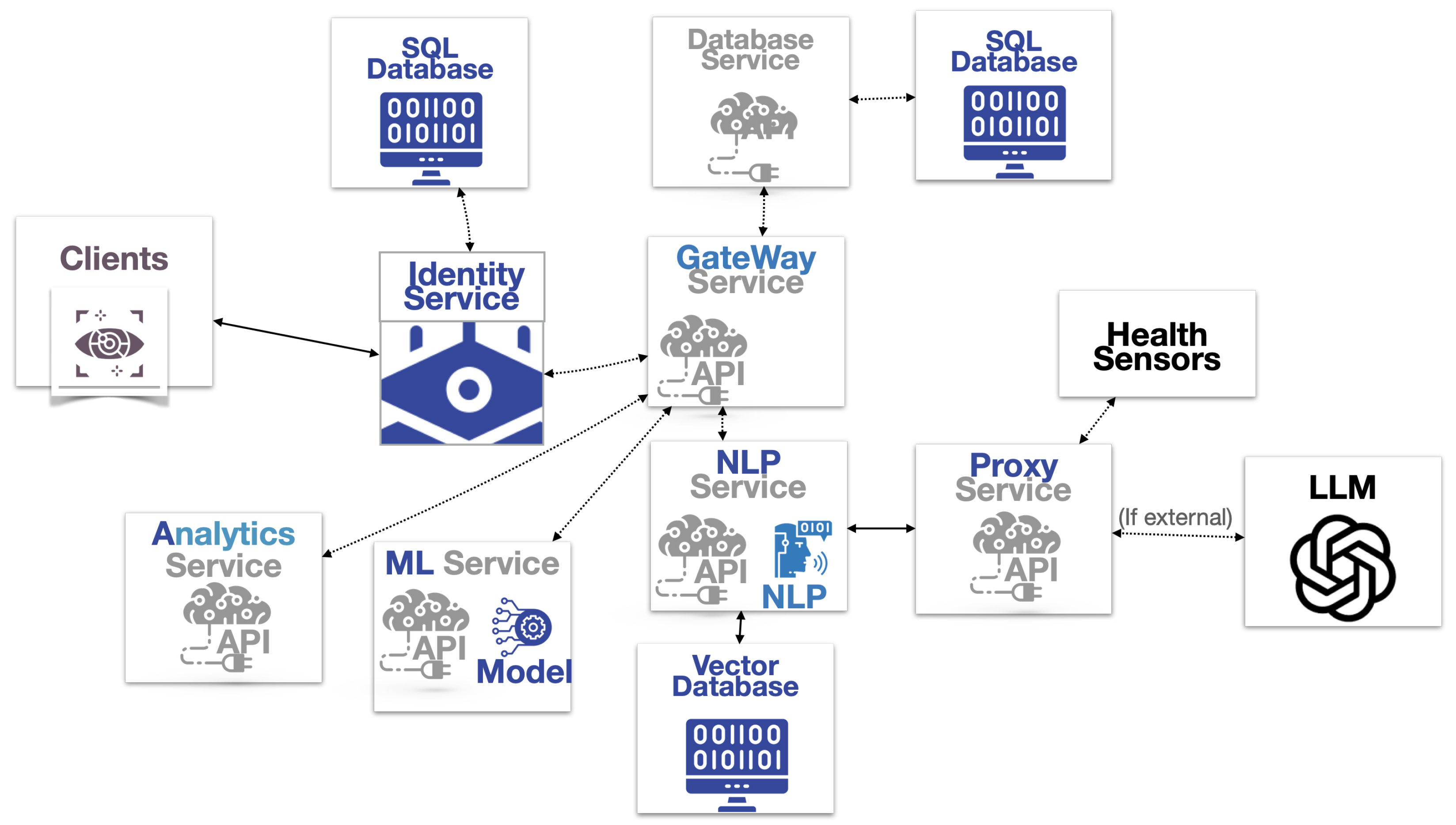
- Client: The user interface that provides the main space for the patients to interact.
- Identity Service: The authorization and authentication infrastructure that validates the client based on user profiles stored in the first SQL database.
- Gateway Service: Acts as an intermediary that processes and routes requests from clients to various services within a system.
- –
- Database service.
- –
- Analytics service: the component that is dedicated to analyzing data and generating insights, related to health metrics and diagnostic examinations.
- –
- ML service: a packaged component that provides machine learning capabilities to the system. This module can be integrated into existing systems to add features like prediction, classification, and anomaly detection based on extreme value theory.
- –
- NLP Service: the software module that encompasses the required processing features.
- *
- Vector database: type of database designed specifically to handle vectors, and, more specifically, in this case, the transposition to incoming embedding data.
- –
- Proxy service: intermediary for requests from other APIs seeking resources from other servers. In this case, it handles communication with external health sensors and LLM engines.
- *
- Health sensors: APIs provided by wearable manufacturers like Fitbit or Apple HealthKit or medical devices used in clinical settings.
- *
- LLMs: APIs of powerful natural language processing engines for question and answering.
4.4. Services Simulating a General Practitioner
4.4.1. Blood Exam Analyzer
4.4.2. External Sensors
- Heart Rate: Continuous heart rate monitoring, including resting heart rate and abnormal heart rate alerts.
- Sleep: Tracks sleep patterns, including sleep stages (light, deep, REM) and sleep quality.
- Stress: Measures stress levels throughout the day.
- Steps and Floors Climbed: Tracks daily step count and floors climbed using an altimeter.
- Calories Burned: Estimates calories burned through various activities.
- Intensity Minutes: Tracks vigorous activity minutes as per health recommendations.
- Body Battery: Monitors body energy levels to suggest the best times for activity and rest.
- Pulse Oximetry: Measures blood oxygen saturation, which can be essential at high altitudes or for tracking sleep issues.
- Respiration Rate: Monitors breathing rate throughout the day and night.
- Women’s Health: Tracks menstrual cycle or pregnancy.
- VO2 Max: Estimates the maximum volume of oxygen that can be utilized during intense exercise.
- GPS Tracking: Offers detailed tracking for outdoor activities, including pace, distance, and routes.
- Activity Profiles: Multiple sports profiles for tracking different activities like running, swimming, cycling, golfing, and more.
- Incident Detection: Some models offer incident detection during certain activities, which can send one’s location to emergency contacts if a fall is detected.
- Mobility Metrics: Monitors how fast one walks, the timing of each step, and how often one stands up.
| Listing 1. Garmin Health snapshot. Extracted and transformed into json file. |
 |
Algorithm External Sensors
- get_weekly_data: Collects data for the past 7 days using a provided data retrieval function.
- daily_snapshot: Collects last data using a data retrieval function.
Pseudocode
4.5. Prototype—Use Cases
4.5.1. Use Case 1
4.5.2. Use Case 2
4.5.3. Use Case 3
4.5.4. Use Case 4
5. System Evaluation
- [A.] Cytoskeletal intermediate filament loss
- [B.] Decreased intracellular pH from anaerobic glycolysis
- [C.] Increased free radical formation
- [D.] Mitochondrial swelling
- [E.] Nuclear chromatin clumping
- [F.] Reduced protein synthesis
6. Discussion of Results and Future Research
- Cost Analysis: Understanding the financial implications of deploying and using this AI system in healthcare is vital. This involves assessing the initial setup costs, ongoing operational expenses, and the potential financial benefits or savings that it might bring to healthcare providers and patients. This analysis will help to determine the economic feasibility and scalability of the system.
- Value-Based Care: This aspect focuses on comparing the costs and outcomes of care provided by different healthcare providers, considering both automated systems like the one proposed and traditional care methods. Key elements include the following.
- –
- Evaluating Effectiveness of Interventions: This involves measuring the impact of healthcare interventions on patient outcomes such as mortality rates, morbidity rates, and improvements in health-related quality of life. The AI system’s role in facilitating timely interventions and improving these outcomes needs to be examined.
- –
- Patient Perspectives on Effectiveness: Assessing the value of care from the patient’s point of view is crucial. This involves gathering and analyzing patient feedback to understand their experiences and satisfaction with the care provided, both through traditional means and the AI system.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ML | Machine Learning |
| AI | Artificial Intelligence |
| XAI | Explainable Artificial Intelligence |
| GAI | Generative Artificial Intelligence |
| LLM | Large Language Model |
| NLP | Natural Language Processing |
| EHR | Electronic Health Records |
| HMM | Hidden Markov Models |
| CRF | Conditional Random Fields |
| LDA | Latent Dirichlet Allocation |
| RAG | Retrieval-Augmented Generation |
References
- Trebble, T.M.; Hansi, N.; Hydes, T.; Smith, M.A.; Baker, M. Process mapping the patient journey: An introduction. BMJ 2010, 341, c4078. [Google Scholar] [CrossRef]
- Gualandi, R.; Masella, C.; Viglione, D.; Tartaglini, D. Exploring the hospital patient journey: What does the patient experience? PLoS ONE 2019, 14, e0224899. [Google Scholar] [CrossRef] [PubMed]
- McCarthy, S.; O’Raghallaigh, P.; Woodworth, S.; Lim, Y.L.; Kenny, L.C.; Adam, F. An integrated patient journey mapping tool for embedding quality in healthcare service reform. J. Decis. Syst. 2016, 25, 354–368. [Google Scholar] [CrossRef]
- Panagoulias, D.P.; Virvou, M.; Tsihrintzis, G.A. Nuhealthsoft: A Nutritional and Health Data Processing Software Tool from a patient’s perspective. In Proceedings of the 2022 16th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Dijon, France, 19–21 October 2022; pp. 386–393. [Google Scholar]
- Balogh, E.P.; Miller, B.T.; Ball, J.R. Improving Diagnosis in Health Care; The National Academies Press: Washington, DC, USA, 2015. [Google Scholar]
- Pham, T.; Tran, T.; Phung, D.; Venkatesh, S. Predicting healthcare trajectories from medical records: A deep learning approach. J. Biomed. Inform. 2017, 69, 218–229. [Google Scholar] [CrossRef]
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef] [PubMed]
- Xiao, C.; Choi, E.; Sun, J. Opportunities and challenges in developing deep learning models using electronic health records data: A systematic review. J. Am. Med. Inform. Assoc. 2018, 25, 1419–1428. [Google Scholar] [CrossRef] [PubMed]
- Davenport, T.; Kalakota, R. The potential for artificial intelligence in healthcare. Future Healthc. J. 2019, 6, 94. [Google Scholar] [CrossRef] [PubMed]
- Panagoulias, D.P.; Sotiropoulos, D.N.; Tsihrintzis, G.A. SVM-Based Blood Exam Classification for Predicting Defining Factors in Metabolic Syndrome Diagnosis. Electronics 2022, 11, 857. [Google Scholar] [CrossRef]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Taori, R.; Gulrajani, I.; Zhang, T.; Dubois, Y.; Li, X.; Guestrin, C.; Liang, P.; Hashimoto, T.B. Stanford Alpaca: An Instruction-Following LLaMA Model. 2023. Available online: https://github.com/tatsu-lab/stanford_alpaca (accessed on 1 January 2024).
- Panagoulias, D.; Palamidas, F.; Virvou, M.; Tsihrintzis, G.A. Evaluating the potential of LLMs and ChatGPT on medical diagnosis and treatment. In Proceedings of the 14th IEEE International Conference on Information, Intelligence, Systems, and Applications (IISA2023), Volos, Greece, 10–12 July 2023. [Google Scholar]
- Gordon, E.B.; Towbin, A.J.; Wingrove, P.; Shafique, U.; Haas, B.; Kitts, A.B.; Feldman, J.; Furlan, A. Enhancing patient communication with Chat-GPT in radiology: Evaluating the efficacy and readability of answers to common imaging-related questions. J. Am. Coll. Radiol. 2023. [Google Scholar] [CrossRef] [PubMed]
- Floyd, W.; Kleber, T.; Pasli, M.; Qazi, J.; Huang, C.; Leng, J.; Ackerson, B.; Carpenter, D.; Salama, J.; Boyer, M. Evaluating the Reliability of Chat-GPT Model Responses for Radiation Oncology Patient Inquiries. Int. J. Radiat. Oncol. Biol. Phys. 2023, 117, e383. [Google Scholar] [CrossRef]
- Gilson, A.; Safranek, C.W.; Huang, T.; Socrates, V.; Chi, L.; Taylor, R.A.; Chartash, D. How does ChatGPT perform on the United States medical licensing examination? The implications of large language models for medical education and knowledge assessment. JMIR Med. Educ. 2023, 9, e45312. [Google Scholar] [CrossRef]
- Locke, S.; Bashall, A.; Al-Adely, S.; Moore, J.; Wilson, A.; Kitchen, G.B. Natural language processing in medicine: A review. Trends Anaesth. Crit. Care 2021, 38, 4–9. [Google Scholar] [CrossRef]
- Kreimeyer, K.; Foster, M.; Pandey, A.; Arya, N.; Halford, G.; Jones, S.F.; Forshee, R.; Walderhaug, M.; Botsis, T. Natural language processing systems for capturing and standardizing unstructured clinical information: A systematic review. J. Biomed. Inform. 2017, 73, 14–29. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Weizenbaum, J. ELIZA—A computer program for the study of natural language communication between man and machine. Commun. ACM 1966, 9, 36–45. [Google Scholar] [CrossRef]
- Wang, B.; Wang, A.; Chen, F.; Wang, Y.; Kuo, C.C.J. Evaluating word embedding models: Methods and experimental results. Apsipa Trans. Signal Inf. Process. 2019, 8, e19. [Google Scholar] [CrossRef]
- Chiu, C.C.; Sainath, T.N.; Wu, Y.; Prabhavalkar, R.; Nguyen, P.; Chen, Z.; Kannan, A.; Weiss, R.J.; Rao, K.; Gonina, E.; et al. State-of-the-art speech recognition with sequence-to-sequence models. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4774–4778. [Google Scholar]
- OpenAI. Better Language Models and Their Implications; OpenAI: San Francisco, CA, USA, 2019. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Bolukbasi, T.; Chang, K.W.; Zou, J.Y.; Saligrama, V.; Kalai, A.T. Man is to computer programmer as woman is to homemaker? In Debiasing word embeddings. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 4349–4357. [Google Scholar]
- Gunning, D.; Stefik, M.; Choi, J.; Miller, T.; Stumpf, S.; Yang, G. XAI—Explainable artificial intelligence. Sci. Robot. 2019, 37, eaay7120. [Google Scholar] [CrossRef] [PubMed]
- Holzinger, A.; Goebel, R.; Fong, R.; Moon, T.; Müller, K.R.; Samek, W. xxAI-beyond explainable artificial intelligence. In Proceedings of the xxAI-Beyond Explainable AI: International Workshop, Held in Conjunction with ICML 2020, Vienna, Austria, 18 July 2020; Revised and Extended Papers. Springer: Berlin/Heidelberg, Germany, 2022; pp. 3–10. [Google Scholar]
- Panagoulias, D.P.; Sarmas, E.; Marinakis, V.; Virvou, M.; Tsihrintzis, G.A.; Doukas, H. Intelligent Decision Support for Energy Management: A Methodology for Tailored Explainability of Artificial Intelligence Analytics. Electronics 2023, 12, 4430. [Google Scholar] [CrossRef]
- Panagoulias, D.; Palamidas, F.; Virvou, M.; Tsihrintzis, G.A. Evaluation of ChatGPT-supported diagnosis, staging and treatment planning for the case of lung cancer. In Proceedings of the 20th ACS/IEEE International Conference on Computer Systems and Applications, AICSSA 2023, Giza, Egypt, 4–7 December 2023. [Google Scholar]
- Blandford, A.; Wesson, J.; Amalberti, R.; AlHazme, R.; Allwihan, R. Opportunities and challenges for telehealth within, and beyond, a pandemic. Lancet Glob. Health 2020, 8, e1364–e1365. [Google Scholar] [CrossRef] [PubMed]
- Snoswell, C.L.; Chelberg, G.; De Guzman, K.R.; Haydon, H.H.; Thomas, E.E.; Caffery, L.J.; Smith, A.C. The clinical effectiveness of telehealth: A systematic review of meta-analyses from 2010 to 2019. J. Telemed. Telecare 2023, 29, 669–684. [Google Scholar] [CrossRef] [PubMed]
- Kraft, A.D.; Quimbo, S.A.; Solon, O.; Shimkhada, R.; Florentino, J.; Peabody, J.W. The health and cost impact of care delay and the experimental impact of insurance on reducing delays. J. Pediatr. 2009, 155, 281–285. [Google Scholar] [CrossRef] [PubMed]
- Martin, D.; Miller, A.P.; Quesnel-Vallée, A.; Caron, N.R.; Vissandjée, B.; Marchildon, G.P. Canada’s universal health-care system: Achieving its potential. Lancet 2018, 391, 1718–1735. [Google Scholar] [CrossRef] [PubMed]
- Goodair, B.; Reeves, A. Outsourcing health-care services to the private sector and treatable mortality rates in England, 2013–20: An observational study of NHS privatisation. Lancet Public Health 2022, 7, e638–e646. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.; Kim, S.; Park, J. Exploring avoidable, preventable, treatable mortality trends and effect factors by income level. Eur. J. Public Health 2023, 33, ckad160-1115. [Google Scholar] [CrossRef]
- Treatable Mortality in Europe: Time Series. Available online: https://www.statista.com/statistics/1421315/treatable-mortality-in-europe-time-series (accessed on 18 December 2023).
- NuhealtSoft Suite. Available online: https://www.diskinside.com/nuhealthsoft/ (accessed on 8 January 2024).
- Panagoulias, D.P.; Virvou, M.; Tsihrintzis, G.A. Rule-Augmented Artificial Intelligence-empowered Systems for Medical Diagnosis using Large Language Models. In Proceedings of the 2023 IEEE 35th International Conference on Tools with Artificial Intelligence (ICTAI), Atlanta, GA, USA, 6–8 November 2023. [Google Scholar]
- Gorsky, P.; Caspi, A.; Chajut, E. The “theory of instructional dialogue”: Toward a unified theory of instructional design. In Understanding Online Instructional Modeling: Theories and Practices; IGI Global: Hershey, PA, USA, 2008; pp. 47–69. [Google Scholar]
- Wilson, D.C. Chapter Three: A Framework for Clarifying. In A Guide to Good Reasoning: Cultivating Intellectual Virtues; McGraw-Hill College: New York, NY, USA, 2020. [Google Scholar]
- García-Carrión, R.; López de Aguileta, G.; Padrós, M.; Ramis-Salas, M. Implications for social impact of dialogic teaching and learning. Front. Psychol. 2020, 11, 140. [Google Scholar] [CrossRef]
- Mitchell, M.L.; Henderson, A.; Groves, M.; Dalton, M.; Nulty, D. The objective structured clinical examination (OSCE): Optimising its value in the undergraduate nursing curriculum. Nurse Educ. Today 2009, 29, 398–404. [Google Scholar] [CrossRef] [PubMed]
- Majumder, M.A.A.; Kumar, A.; Krishnamurthy, K.; Ojeh, N.; Adams, O.P.; Sa, B. An evaluative study of objective structured clinical examination (OSCE): Students and examiners perspectives. Adv. Med Educ. Pract. 2019, 10, 387–397. [Google Scholar] [CrossRef] [PubMed]
- Customizing Conversational Memory. Available online: https://python.langchain.com/docs/modules/memory/conversational_customization (accessed on 29 September 2023).
- Vector Stores-LlamaIndex. Available online: https://gpt-index.readthedocs.io/en/v0.7.8/core_modules/data_modules/storage/vector_stores.html (accessed on 20 November 2023).
- Panagoulias, D.P.; Sotiropoulos, D.N.; Tsihrintzis, G.A. An Extreme Value Analysis-Based Systemic Approach in Healthcare Information Systems: The Case of Dietary Intake. Electronics 2023, 12, 204. [Google Scholar] [CrossRef]
- The Internet Pathology Laboratory for Medical Education. Available online: https://webpath.med.utah.edu/webpath.html (accessed on 15 December 2023).


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Panagoulias, D.P.; Virvou, M.; Tsihrintzis, G.A. Augmenting Large Language Models with Rules for Enhanced Domain-Specific Interactions: The Case of Medical Diagnosis. Electronics 2024, 13, 320. https://doi.org/10.3390/electronics13020320
Panagoulias DP, Virvou M, Tsihrintzis GA. Augmenting Large Language Models with Rules for Enhanced Domain-Specific Interactions: The Case of Medical Diagnosis. Electronics. 2024; 13(2):320. https://doi.org/10.3390/electronics13020320
Chicago/Turabian StylePanagoulias, Dimitrios P., Maria Virvou, and George A. Tsihrintzis. 2024. "Augmenting Large Language Models with Rules for Enhanced Domain-Specific Interactions: The Case of Medical Diagnosis" Electronics 13, no. 2: 320. https://doi.org/10.3390/electronics13020320
APA StylePanagoulias, D. P., Virvou, M., & Tsihrintzis, G. A. (2024). Augmenting Large Language Models with Rules for Enhanced Domain-Specific Interactions: The Case of Medical Diagnosis. Electronics, 13(2), 320. https://doi.org/10.3390/electronics13020320