1. Introduction and Related Work
Visual localization and dense 3D reconstruction are high-demand research areas, forming the core technology of a broad range of indoor and outdoor applications. Compared to using a single sensor, multiple sensor-based Simultaneous Localization and Mapping (SLAM) approaches are more robust, as the sensors can be used in a complementary manner for motion estimation. The emerging RGB-D cameras with integrated internal sensors (e.g., Intel Realsense) significantly reduce the hardware cost and have the potential to be widely applied in various scenarios.
SLAM is important for a broad range of applications, such as mobile robotics and Augmented Reality/Virtual Reality (AR/VR). Pursuing an affordable yet robust solution as a trade-off between complexity and accuracy is challenging. In recent years, pioneering research [
1,
2] using a combination of multiple sensors has achieved promising performance in large-scale localization [
3,
4]. For example, the use of a monocular SLAM system [
5] can significantly reduce the hardware cost. However, monocular SLAM is sensitive to initialization, and the scale-drifting problem is hard to mitigate due to the unobservability of depth. To obtain the metric scale, researchers have proposed using a low-cost Inertial Measurement Unit (IMU) as a complement to monocular odometry to improve the motion tracking performance [
6].
There are a variety of sensors that can achieve the state estimation required in the SLAM process, such as the IMU, RGB-D camera, monocular camera, and LiDAR. How to use low-cost sensors to achieve high-precision state estimation is a challenging exploration process. An IMU can provide measurements of the acceleration and angular velocity of the current object, but cannot directly be used to estimate its state. Moreover, the measurements provided by a cheap IMU are not accurate enough for localization, and residuals after IMU pre-integration are inevitable. Visual and inertial fusion makes low-cost state estimation possible. Visual constraints depend on the features of scenarios, and the quality of feature extraction determines whether the estimated depth is reliable. The Vision-Inertial System (VINS), one of the current state-of-the-art models in Vision-aided Inertial Odometry (VIO), is still greatly restricted in featureless scenes. The use of a depth-based odometer has achieved impressive effects in state estimation. The Iterative Closest Point (ICP) algorithm is accurate and fast for point set registration on the same scale, and has been widely used for pose estimation and establishing point correspondences. Note that depth-based systems often suffer from cumulative error, and some of these errors cannot be corrected by loop closure detection.
The IMU is an essential component of navigation, positioning, and motion control. However, IMU-based state estimation cannot avoid the occurrence of drift, including linear horizontal angular drift and exponential positional drift, which limits the use of single sensors. It is widely accepted that monocular SLAM suffers from problematic metric scale estimation. The fusion of visual data with IMU measurements provides a direct solution to this problem. The Multi-State Constraint Kalman Filter (MSCKF) [
7] is a widely used Extended Kalman Filter (EKF) based on the Visual-Inertial Odometry (VIO) method. In this method, six degrees-of-freedom (6DOF) poses, comprising positions and quaternions, are used as state vectors instead of 3D feature positions. The geometric consistency of visual features appearing in multiple frames is used to update the state vector with multiple forms of constraints. However, this approach is not suitable for long-term operation due to the exponential growth of the state vector dimensions in the system, leading to a consequent increase in computational complexity. VINS-Mono [
8] is a state-of-the-art VIO system requiring only a monocular camera and an IMU. This system achieves positioning performance comparable to Open Keyframe-Based Visual-Inertial SLAM (OKVIS) [
9], and is more robust as a full SLAM system. VINS-Mono achieves real-time performance on mobile devices and is, to the best of our knowledge, the first optimization-based VIO that can be deployed on embedded platforms as well. When the camera moves in a straight line in a planar environment, its trajectory is at a constant velocity, resulting in near-zero acceleration. In this case, mainstream VIOs often lead to inaccurate estimates as they are affected by additional unobservable directions. In addition to the effects of IMU noise, high illumination variations and few features can pose additional challenges to the visual tracking process as well.
Notably, the use of available depth information has made significant progress in state estimation. As a seminal work, Kinectfusion [
10], presented by Richard et al., is the first SLAM algorithm for real-time localization and 3D reconstruction using a moving depth camera. The ICP algorithm of Kinectfusion, which is foundational to this approach, traces back to the earlier work by Zhang et al. [
11]. As the system only operates in small scenes (tens of meters) and does not include closed-loop detection, its application is limited to indoor environments. Building on this, an extended Kinectfusion framework, Kintinuous [
12], was proposed much later to enhance scalability. This system updates the 3D model by rolling a circular buffer for more efficient spatial utilization and fuses ICP iterations with photometric constraints for camera pose tracking. Additionally, they integrated the Bags of Binary Words (DBoW) location recognition system [
13] for closed-loop detection, enabling correction for long-term drift (e.g., several hundred meters).
Inspired by surfel-based fusion systems, Thomas et al. have proposed ElasticFusion [
14], a map-centric approach. This system optimizes trajectories using both geometric and photometric constraints. Its reliance on active and inactive models within the same camera frame, which helps to maintain the map distribution, could potentially limit its adaptability in dynamic environments when compared to other SLAM systems. Mur-Artal et al. have introduced ORB-SLAM [
15], a monocular vision-based SLAM approach with high localization accuracy. In their further development, ORB-SLAM2 [
16], they included additional sensor combinations (stereo and RGB-D), thereby increasing the system’s versatility. The use of a co-visibility graph and the DBoW2 [
17] library in the closed-loop module of ORB-SLAM2 enhances its robustness in large environments. However, ORB-SLAM’s performance in environments with limited textures or features can be challenging, an area where depth-based systems like ElasticFusion can offer advantages.
Existing SLAM methods, such as VINS-Mono and depth- or RGB-D-based algorithms (e.g., ORBSLAM2 and ElasticFusion), have their inherent limitations in diverse scenes. VINS-Mono struggles to effectively track feature points in feature-sparse or repetitive environments, which affects bit-position estimation and map construction. Meanwhile, depth-based SLAM algorithms are sensitive to fast motion and may not be able to accurately compute the bit position, especially when RGB images and point cloud data appear blurred or inaccurate. In addition, these methods are limited when dealing with low-textured and repetitively textured scenes and, in environments with significant lighting variations, the instability of colour information may reduce the accuracy of bit-position estimation.
To overcome the limitations of conventional visual inertial odometry systems in dealing with texture-poor environments and illumination variations, as well as to reduce error accumulation due to IMU noise, we propose an approach that combines RGB-D and IMU data. This method utilizes the depth information provided by the RGB-D camera to enhance the accuracy of feature matching and environment reconstruction, especially when visual information is insufficient. The depth data can help the system to better understand the scene structure and reduce the reliance on environmental textures, while providing additional data dimensions to complement the IMU data, thus improving the robustness and accuracy of the overall system. With this fusion, we are able to create a more robust and accurate SLAM system that can adapt to diverse environments and conditions.
The main scientific problem to be addressed in this paper is how to effectively combine depth information from RGB-D cameras and IMU data, in order to improve the performance of SLAM systems in various environments. In particular, how can we ensure accurate feature matching and environment reconstruction in scenes that are texture-poor or have significant lighting variations, while reducing the accumulation of errors caused by IMU noise? Our goal is to develop a SLAM system that can utilize depth data to alleviate the dependence on environmental textures while effectively incorporating IMU data to improve the overall robustness and positioning accuracy of the system.
For the VID-SLAM system presented in this paper, a new state estimation method is proposed to enhance robustness under different environmental conditions by integrating data from RGB-D sensors and IMUs. This integration is part of our Visual-Inertial-Depth SLAM (VID-SLAM) approach, which brings several contributions:
A new formulation that simultaneously estimates the system state by leveraging both registered RGB-D image pairs and inertial measurements.
Robust performance across various challenging environments, utilizing visual-inertial-depth odometry for accurate pose estimation in consecutive frames.
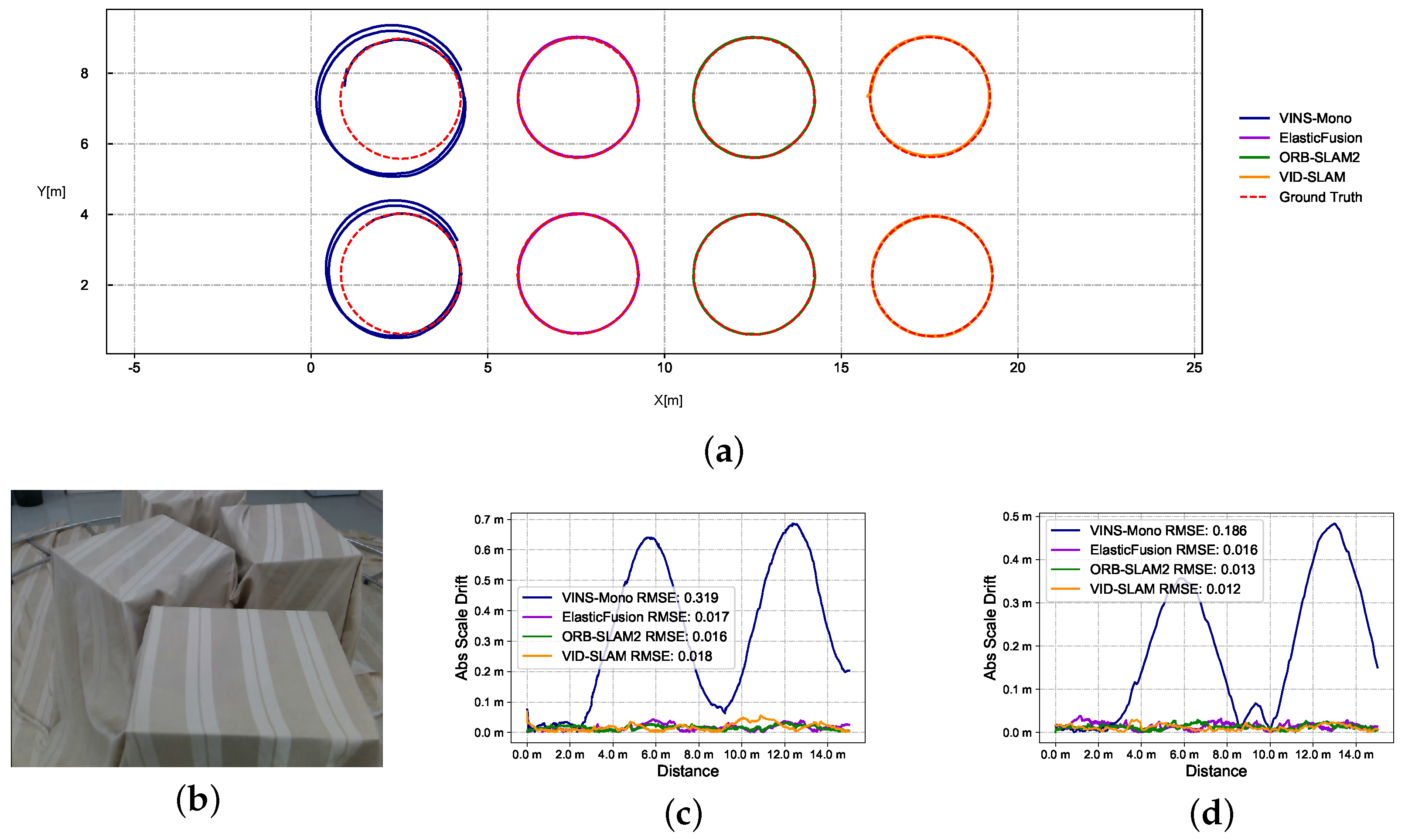
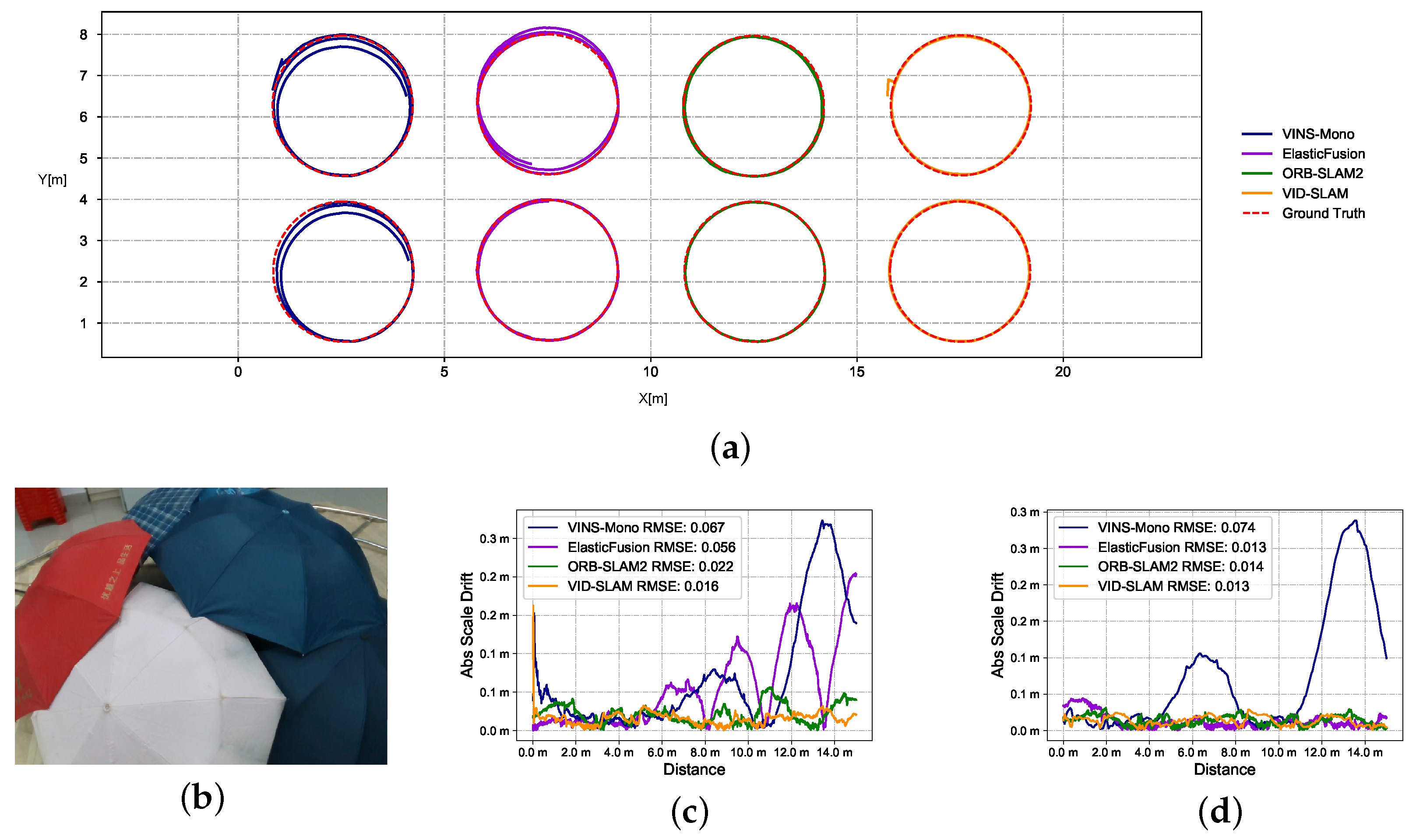
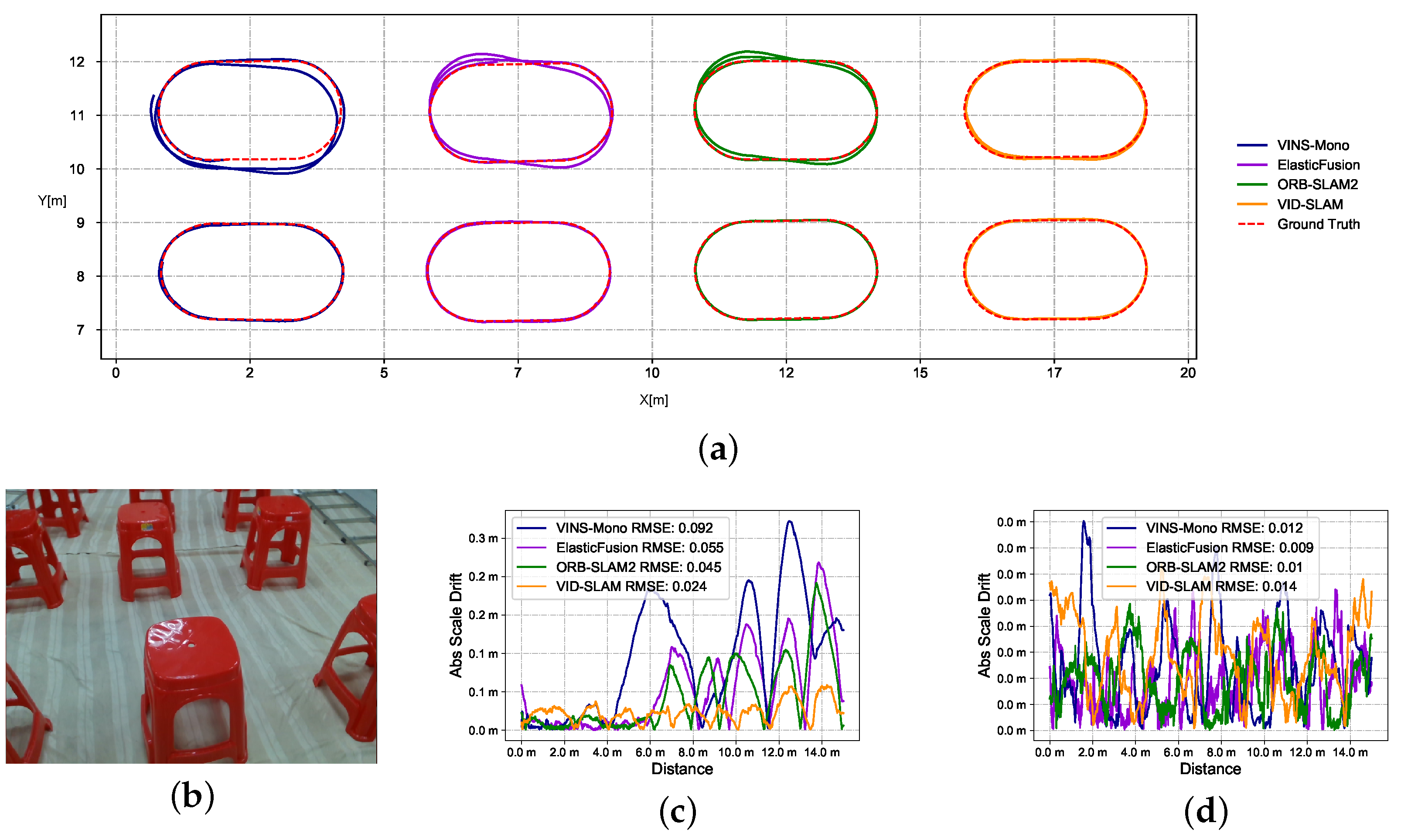
Superior performance compared to advanced existing solutions, validated through extensive experiments on our open-source data sets captured using an Intel Realsense D435i. These data sets encompass RGB images (30 Hz), depth images (25 Hz), and IMU measurements (450 Hz) with fitted ground truth, covering multiple scenarios.
A comprehensive evaluation of the VID-SLAM system using these diverse data sets, demonstrating its improved performance and reliability.
2. Methodology
The pipeline of VID-SLAM is illustrated in
Figure 1. The system starts by receiving an RGB-D image paired with a corresponding sequence of IMU measurements, where the number of IMU measurements corresponds to the duration between consecutive RGB-D frames. These two types of data are processed separately. The IMU measurements undergo pre-integration to estimate the initial state, including position, velocity, and rotation changes, which are important for the initial alignment in the fusion process.
The features extracted from the RGB camera are tracked by the Kanade–Lucas–Tomasi (KLT) [
18] sparse optical flow algorithm. IMU pre-integration [
19] is performed over a certain number of IMU measurements. Then, the ICP algorithm is employed to estimate the rotation
and the translation
between consecutive depth maps.
In the following optimization procedure, the pose graph can be initialized using the pre-processed sensor states.
The optimization module tightly fuses geometric, IMU, and visual constraints to conduct non-linear optimization to search for the best solution. Last but not least, when a loop-closure is detected, the drift can be corrected by performing pose-graph optimization to ensure accurate localization in long-term running.
To be more specific, our approach encompasses four key components: (1) a Measurement Pre-processing Module, which processes raw inputs, converting them into structured data for subsequent processing; (2) the Robust Initialization Procedure, which aligns various measurements and establishes initial values essential for system calibration; (3) a Joint Estimation Module, a core component which integrates three types of constraints—namely visual, inertial, and geometric constraints—to accurately estimate the system’s state; and (4) a Loop Closure Module, which employs pose-graph optimization to correct cumulative errors and ensure the long-term stability of the system.
2.1. Measurement Pre-Processing
The measurement pre-processing used in this research is performed in real-time, and is similar to the pre-processing described in [
8]. The RGB images and inertial measurements must be pre-processed before they can be converted into sensor states for subsequent modules. Specifically, we track visual features between consecutive colour frames and detect new features to improve the robustness of the system. The inertial measurements during the time interval between two consecutive frames will be pre-integrated using a real-time method to obtain a rough estimate of motion.
2.1.1. Visual Pre-Processing
We extract Shi–Tomasi features [
20] from each RGB image and track these feature points using the KLT sparse optical flow algorithm [
18]. As the tracking process contains noisy matches, outlier rejection is implemented using the RANSAC algorithm [
21]. To ensure the accuracy and robustness of localization, new features are detected to maintain a minimum required number of tracked features.
Having visual features extracted and tracked, we need to decide whether the current frame is a new keyframe or not. For the insertion of keyframes, one of the following conditions must be satisfied:
The average parallax from the previous keyframe is set to be higher than a threshold of 0.5 pixels, determined based on empirical testing to balance keyframe frequency and tracking stability.
The system maintains tracking of at least 100 features in the current frame, a threshold chosen for optimal performance in varied environments as observed in preliminary tests.
2.1.2. Inertial Pre-Processing
In this step, we adopt the method from [
8] for pre-integrating IMU measurements to propagate the states of position, velocity, and rotation. This process involves considering the time interval
for IMU measurements and the corresponding image frames at instants
and
. To accurately describe this state propagation, we refer to the following equation, which integrates various factors such as IMU measurements, biases, and gravitational effects over this interval.
where
represents the rotation matrix transitioning from the IMU body coordinate frame to the world coordinate frame at any given time
t. Specifically,
,
, and
denote position, velocity, and rotation, respectively.
is the duration within the time interval
.
and
are the gyroscope and accelerometer measurements from the IMU, respectively, while
and
are their corrections which incorporate the force for countering gravity, bias, and additive noise.
and
are the acceleration and gyroscope biases, respectively.
and
are additive noises, assumed to be Gaussian distributions.
is the gravity vector.
denotes the world frame. Moreover, the formulation incorporates
, a skew-symmetric matrix, which is defined as follows:
2.2. Initialization
In the initialization phase of our Visual-Inertial-Depth Odometer (VIDO) system, accurate estimation of the initial state is important for precise state estimation. This phase involves combining the inertial data from the IMU with the visual data from the RGB-D camera to compute the initial gravity vector (), the gyroscope bias (), and the velocity of the system (). First, we pre-integrate the IMU measurements between consecutive image frames to calculate the relative motion including rotation () and translation (), a process that uses the gyroscope and accelerometer data over the time interval . Meanwhile, a sliding-window-based structure-from-motion (SfM) technique is used to process a series of RGB-D images to estimate the initial camera pose and the geometry of the scene. The key step is to align the SfM results with the IMU pre-integrated data, which adjusts the scale of the trajectories obtained from the visual data and corrects them using the scale-aware properties of the IMU data. This alignment is accomplished by minimising the difference between the IMU pre-integrated results and the pose obtained by SfM, ensuring that our VIDO system has a stable and reliable initial state estimate.
2.3. Joint Estimation
For each new frame, we apply local non-linear optimization to refine the trajectory estimation. To improve the accuracy of localization with multiple sensory information, we proposed a sliding window-based Visual-Inertial-Depth Odometry (VIDO) that formulates a unique tightly coupled fusion of RGB-D and inertial estimates. The state vector of the sliding window is defined as
where
is the IMU state of the
keyframe. The first three items of
are the position, velocity, and rotation of the IMU, while the last two items of
are the acceleration bias and gyroscope bias in the IMU frame.
i and
j, respectively, denote the total numbers of keyframes and features.
denotes the transformation matrix from camera coordinates to IMU body coordinates.
refers to the inverse depth of features stored in the sliding window.
Our residual function consists of four terms: the sum of prior, the ICP errors, the IMU residual, and visual re-projection errors. We minimize the residuals to obtain the optimal estimation:
where
and
and
are the prior information from marginalization.
is the set of matched points between consecutive depth images,
is the set of all IMU measurements, and
is the set of features observed at least twice in the current sliding window.
,
and
are the residuals of individual constraints. More details about these two residuals are provided in the subsequent sections.
and
are the corresponding covariance metrics. Ceres Solver [
22] was used to solve this optimization task.
2.3.1. Geometric Constraint
Given two consecutive depth images, we estimate the relative transformation matrix between these images using the ICP algorithm. To improve the registration performance, we use a point-to-plane formulation [
23], defined as
where
is the transformation matrix, defined as
Here, and are matched 3D points from the respective depth images. is the corresponding normal of the previous frame (). The matrix and vector represent the rotation and translation from the coordinate system of the previous depth image () to the current depth image ().
2.3.2. IMU Constraint
Given IMU measurements
and
within two consecutive frames, the residual of IMU pre-integration is defined as
where
is the rotation matrix from the world coordinate system to the IMU body coordinate system.
is the time interval between two consecutive frames.
,
, and
are the IMU pre-integration terms, which represent the integral prediction of the acceleration and angular velocity measured by the IMU from one frame to the next. These pre-integration terms are used to predict the changes in the IMU state (including position, velocity, and attitude) during this time period.
2.3.3. Visual Constraint
Similar to VINS, the re-projection error is defined on a unit sphere. Given a unit vector that is back-projected from the pixel coordinates of the feature , and the corresponding 3D point that is predicted by transforming its first observation in the frame to the frame, we can define the visual residual r on the tangent plane of .
Bundle Adjustment (BA) is known to be a gold standard method which can produce jointly optimal 3D structures by refining a visual re-construction [
24]. The re-projection errors of BA are defined on a generalized image plane for the most part. However, its traditional formulation may be less suitable for fisheye cameras, which require specialized calibration. Based on the main ideas of BA, we define the re-projection errors as our visual residual on a unit sphere, given as follows.
According to the pinhole camera model [
25], the projection function
projects 3D points onto the 2D plane as follows:
where
and
are the camera’s intrinsic parameters, which are estimated through initial camera calibration and are assumed to be fixed throughout the keyframe sequence.
Given the
feature
observed at least twice since its first appearance in the
image, the corresponding 3D point in the unit sphere can be obtained as follows if this feature appears in the
image:
where
and
are pixel coordinates of feature
observed in the
image.
turns pixel coordinates into a unit vector.
With the pixel coordinates of feature
observed in the
image, we can obtain the corresponding 3D point in the world frame as follows:
where
is the transformation matrix from the
body frame to the world frame.
consists of the rotation matrix
and translation matrix
.
, as used in (
3), is the inverse depth of feature
.
Similarly, we can predict the coordinates of the same 3D point in the
body frame as follows:
We can summarize the expression of the prediction by referring to Equations (
11)–(
13):
In summary, we define our reprojection error as follows:
where
and
are two orthogonal bases that can be found easily on the tangent plane of
.
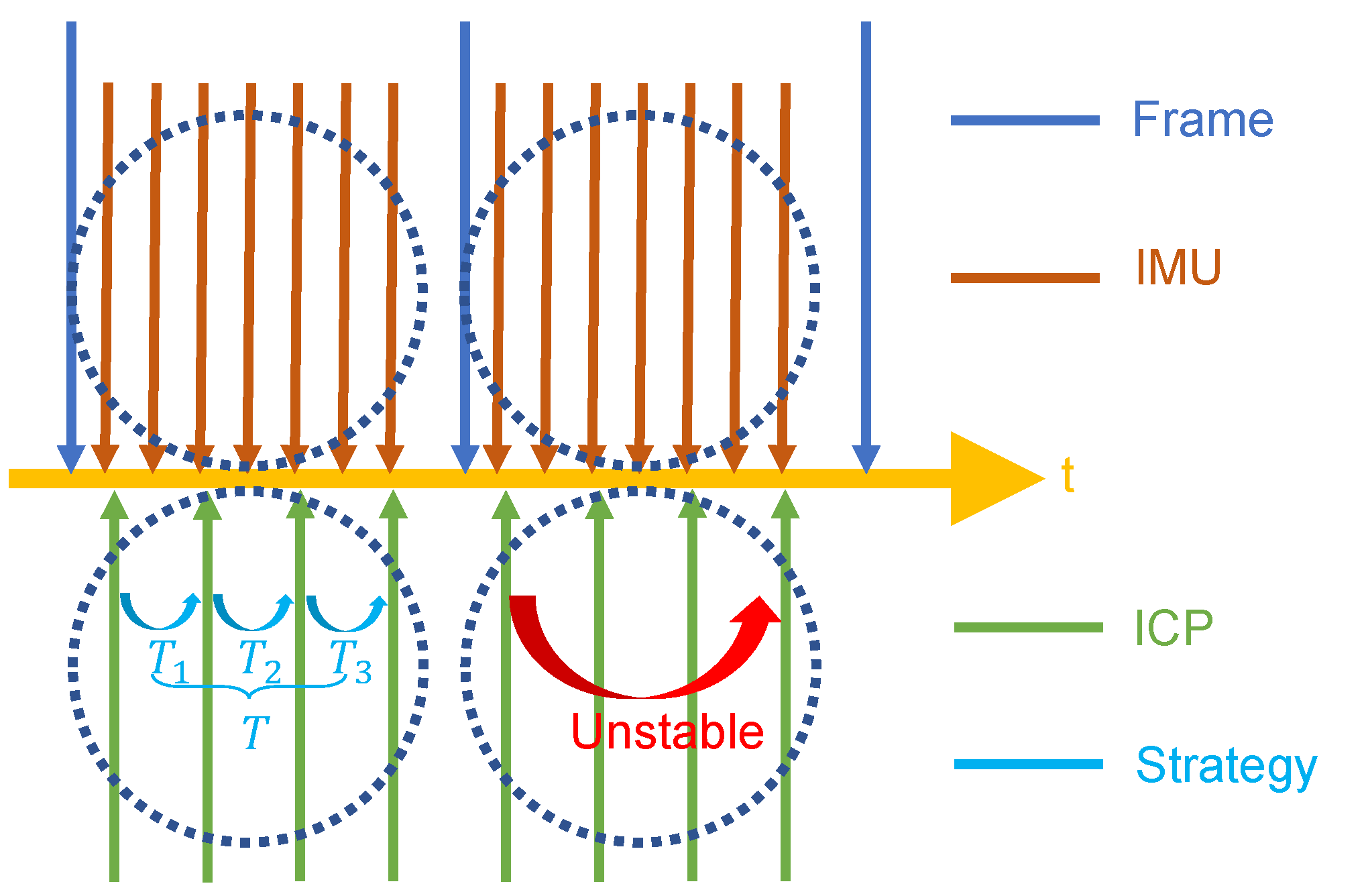
As shown in
Figure 2, IMU pre-integration is performed over all measurements between every several RGB frames. ICP is applied to register every neighbouring frame.
To ensure real-time performance, we limit the number of iterations, as the system is designed for real-time deployment. As detailed in
Section 3, this limitation allows us to perform fast estimation between two consecutive depth images. However, estimating motion between distant depth images with different 3D structures may affect the accuracy and computational cost.
2.4. Loop-Closure Detection
As accumulated drift is inevitable in the long-term running of SLAM systems, an approach based on Bag-of-Words (BoW) [
26] is integrated to detect loop-closures. This approach queries the visual database with visual words (BRIEF descriptors [
27] in our system) and returns loop candidates with the consistency verification.
If the current frame is selected as a keyframe, we extract BRIEF descriptors to validate loop closure. Pose-graph optimization is then performed to correct the accumulated drift after a validated loop closure.
It is worth noting that the loop-closure detection module is optional if the platform has limited computational resources. Thanks to the tightly coupled fusion strategy, our approach can achieve satisfactory localization performance in various environments even without loop-closure detection.










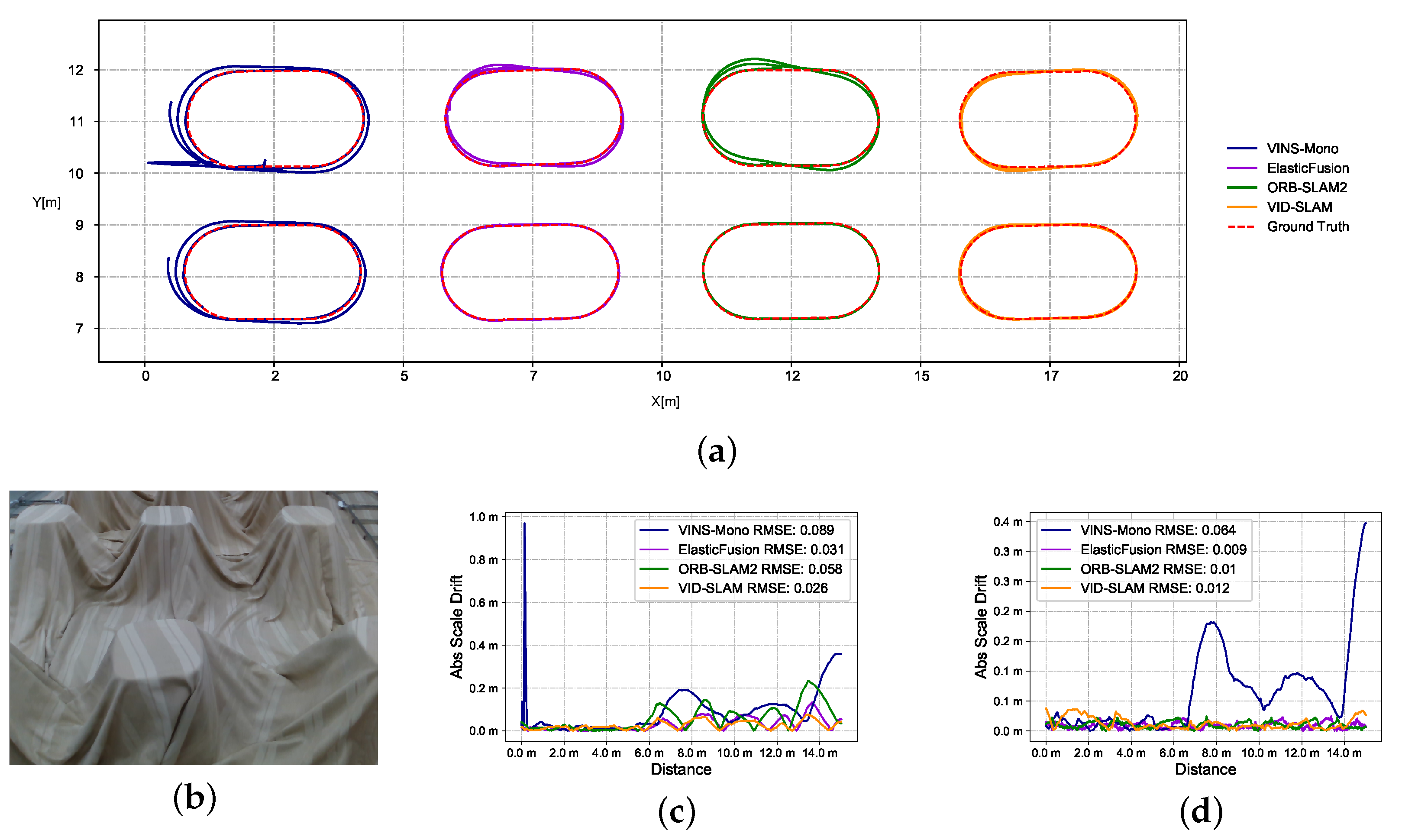

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}