1. Introduction
As a welding method with high energy input, K-TIG welding plays a crucial role in the field of medium–thick plate welding. Medium–thick material plates, like titanium alloy, duplex stainless steel, and low carbon steel, can perform a single-sided weld and a double-sided form in a single pass without opening grooves [
1,
2,
3]. It is often combined with robots for automatic welding in practical industrial production, but it is still difficult to achieve precise real-time regulation during the complex welding process. To improve the intelligent automation level of welding technology, scholars have paid much attention to monitoring the welding process [
4].
Welding process monitoring is a key component in intelligent welding [
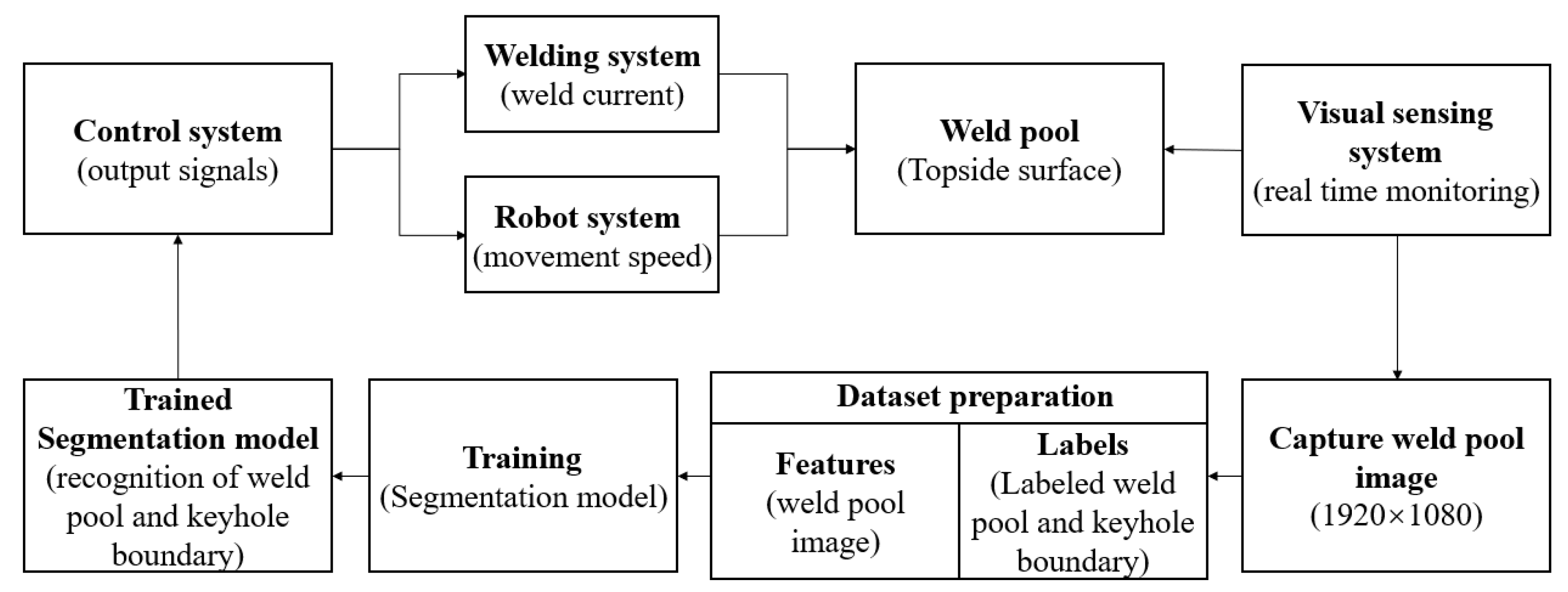
5]. During the welding process, the molten pool contains a wealth of welding quality information. By observing the shapes and characteristics of the molten pool, skilled welders can adjust the welding parameters in real time to maintain good welding quality. However, the shape of the molten pool is dynamic, and it is a very subjective task to monitor its formation manually. To realize the closed-loop control of intelligent welding, visual sensing technology can be used to simulate the welders in monitoring the morphological change in the molten pool and obtain its shape parameters, which are used as indirect control variables fed back to the control system so that the welding parameters can be adjusted to greatly improve welding quality and efficiency. Visual sensing technology is considered to be the most promising welding sensing technology due to its advantages of convenient operation, strong anti-interference, mass information, high-speed acquisition, and non-contact with the workpiece.
In the visual monitoring of K-TIG welding, image processing is an indispensable step through which to obtain the surface morphology of the weld pool and keyhole clearly and accurately. It is typically required to go through the following four stages in image processing: the selection of the region of interest (ROI), the preprocessing of the image, the segmentation of the image, and feature extraction [
6,
7,
8]. Its most crucial and challenging part is image segmentation, which can be used to segment the captured objects, like the weld pool, keyhole, weld line, arc, and the like [
9]. At present, image segmentation methods for molten pools can be divided into two categories, including methods based on traditional image algorithms and those based on active contour models [
10]. Liu et al. [
11] analyzed the results of six different edge detection operators and finalized the Canny operator (with a threshold between 0.1 and 0.5) to obtain ideal edge features for a molten pool. Chen et al. [
12] utilized a traditional image algorithm to extract the molten pool’s width, trailing length, and surface height, which were used as the input signals of the data-driven model to predict the backside width. Liu et al. [
13] proposed an active contour model to extract the edges of the groove accurately, and the accuracy of the model was proven by the experiment results. These methods have the obvious advantages of low computational complexity and high efficiency, which make it possible to obtain stable and accurate segmentation results under certain tasks. However, during the K-TIG welding process, the size, shape, and position of the weld pool and keyhole are affected by different welding process parameters, which leads to difficulty in the segmentation of the molten pool image within the actual welding environment [
14]. Furthermore, the segmentation methods mentioned above have the problem of poor segmentation performance due to the interference from the complex reflection characteristics of the molten pool’s surface, the intense light intensity of the arc light, and the other noise sources in the environment.
With the rapid development of deep learning, image semantic segmentations based on the convolutional neural network (CNN) have made significant progress, and various semantic segmentation models have also appeared, one after another. Because of its two characteristics of local connection and weight sharing, the CNN can make the network deeper and obtain higher accuracy in complex tasks by greatly reducing the parameters of the network model. The fully convolutional network (FCN), proposed in 2015 [
15], improved based on CNN. The FCN is a seminal contribution to deep learning for semantic segmentation, which establishes a general network model framework. It leverages the feature map generated by the final convolutional layer in the CNN to perform up-sampling, and it classifies and predicts each pixel throughout this procedure. However, the network of the FCN is relatively large, it is not sensitive to the details of the image, and the target boundary is blurred due to the low correlation between pixels. To improve the accuracy of segmentation results, many researchers have tried a variety of methods. Peng et al. [
16] proposed an improved global convolutional network method, which uses large separable filters to reduce the number of parameters and optimize the segmentation boundary. PSPNet [
17], developed by Zhao, extracts appropriate global features for scene parsing and semantic segmentation tasks. It uses a pyramid pooling module to combine local and global information and proposes an optimization strategy with moderate supervision loss. The DeepLab model [
18,
19,
20,
21] is a deep convolutional neural network (DCNN) model proposed by Chen et al. Its core concept is to use atrous convolution, which can not only clearly control the resolution of the response when calculating the feature response but also expand the receptive field of the convolutional kernel, as well as integrate more feature information without increasing the number of parameters and calculations.
In recent years, some researchers have attempted to apply deep learning models to the monitoring of the K-TIG welding process. Xia et al. [
22] designed a novel visual monitoring system for K-TIG welding, employing an XVC-1000e camera to observe the weld pool and keyhole. The residual network (ResNet) was developed for welding state classification based on the molten pool image, achieving an impressive recognition rate of 98% in experiments. To guarantee a good welding seam tracking effect, Chen et al. [
23] proposed an image processing algorithm using Mask-RCNN to accurately identify the keyhole entrance and weld centerline. The accuracy of the algorithm was verified by experiments, and the inference speed was 1.53 frames per second. Wang et al. [
24] introduced a segmentation-LSTM model, segmenting the regions of the weld pool and keyhole. Deployed in an embedded system, this model achieved a running time of 50 ms. The above research results show that although these models have shown excellent performance, their model structures were too large and complex, resulting in slow processing speeds and high memory usage. Moreover, challenges persisted in accurately segmenting the weld pool and keyhole areas, with room for improvement in the accuracy and stability of the weld pool and keyhole edge.
To address these issues, an improved DeepLabV3+ model is put forward, aiming to boost processing speed and improve the accuracy and robustness of image segmentation. A visual sensing system with a high-dynamic-range (HDR) camera was designed and implemented to capture weld pool and keyhole images simultaneously, reducing interference from strong arc light. MobileNetV2 serves as the backbone network where its atrous rates are adjusted to diminish model parameters and computational complexity to classify each pixel in the molten pool image and extract the information of the weld pool and keyhole quickly and efficiently from the image. The proposed model lays a solid foundation for the practical application of proven deep learning techniques in the K-TIG welding process control.
3. Design of Segmentation Model
3.1. Improved DeepLabV3+ Model
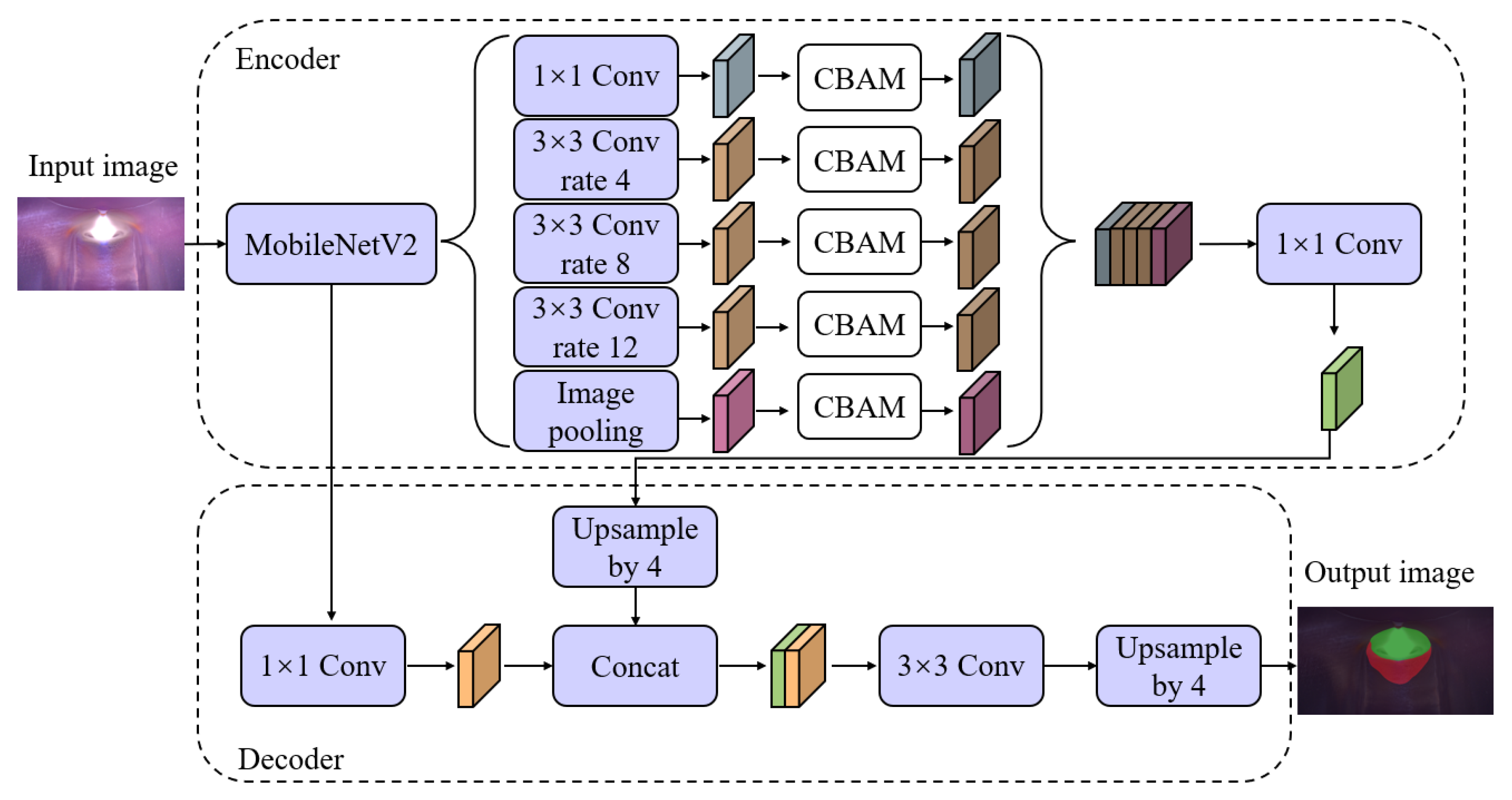
The DeepLabV3+ model is improved based on DeepLabV1-3, which has achieved good results in public datasets such as Pascal VOC and CitySpace. The DeepLabV3+ model consists of an encoder and decoder. The encoder part includes the Xception network, atrous spatial pyramid pooling (ASPP) module, and 1 × 1 convolutional layer. The ASPP module is comprised of a 1 × 1 ordinary convolution layer, three atrous convolution layers with different atrous rates, and a pooling layer. Two feature maps with different levels are produced by the Xception network of the encoder after extracting the features of the input image. The features of the low-level feature map are extracted in the ASPP module, which is spliced in the channel dimension and compressed through the 1 × 1 convolution to obtain a feature map with high-level semantic information. In the decoder part, first, the 1 × 1 convolution is used to adjust the channel dimension of the high-level feature map. After that, the adjusted feature map can fuse with the feature maps upsampled by four times. Subsequently, the fused feature map employs a 3 × 3 convolution to recover spatial information and then is upsampled four times to enhance the target boundary, producing the final segmentation result.
In the experiment, the complicated structure of the Xception network will result in some blurring and confusion problems in detail extraction for the weld pool and keyhole. The large number of parameters in Xception necessitates a significant investment of time and computing power, so MobileNetV2 is selected as the backbone feature extraction network. MobileNetV2, with fewer parameters and faster training speed, accelerates feature extraction in molten pool images. This facilitates improved detail capture for the weld pool and keyhole, rendering it more suitable for molten pool extraction tasks. At the same time, given the differing characteristics of the weld pool and keyhole, it is not suitable to apply the DeepLabV3+ model directly to the molten pool segmentation. The improved DeepLabV3+ model architecture is shown in
Figure 5.
3.2. MobileNetV2 Network
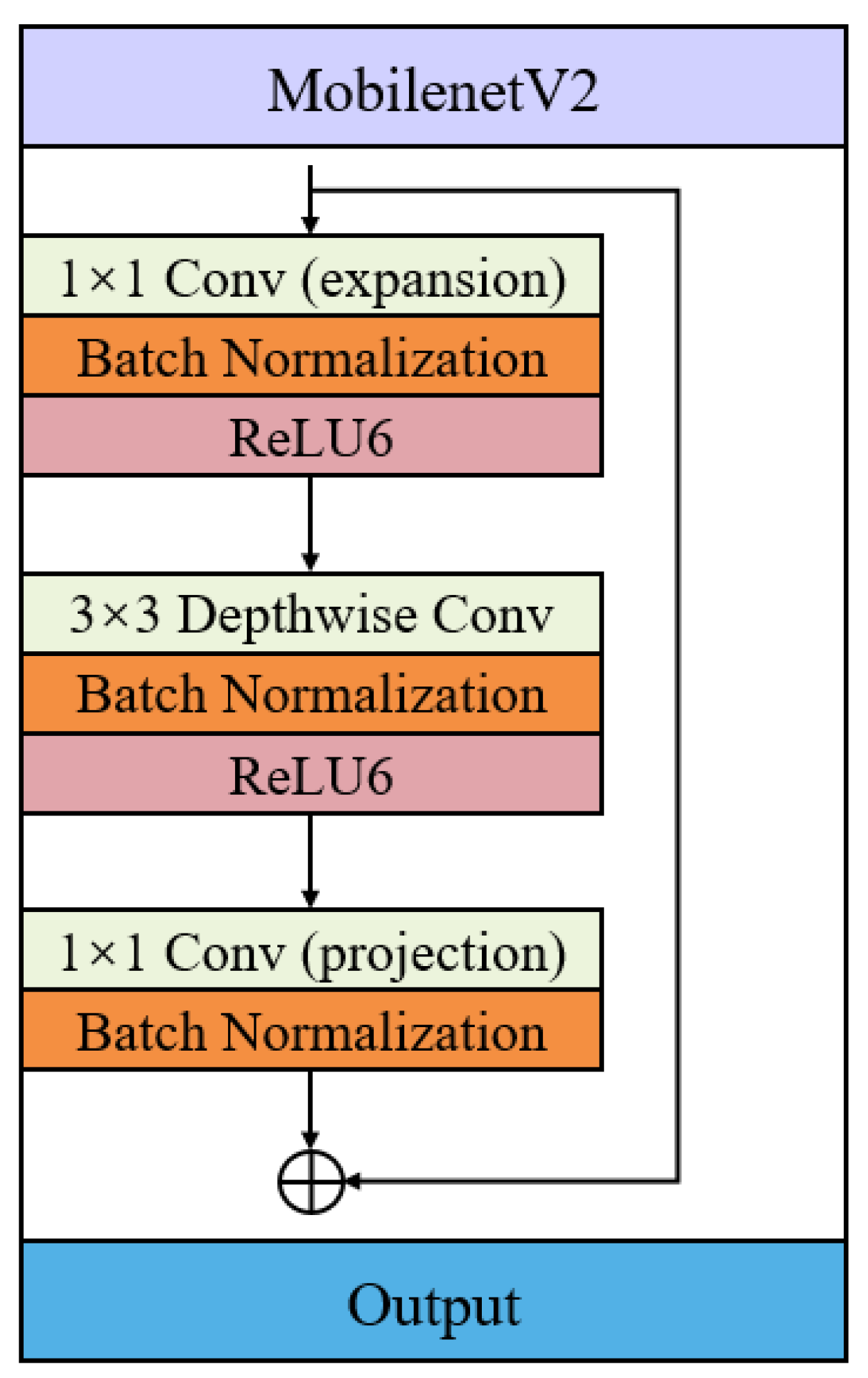
MobileNetV2 is used as the backbone feature extraction network, and its network structure is shown in
Figure 6. MobileNetV2 adopts an inverted residual block structure, which gives the network a good ability for feature extraction while maintaining a small number of parameters and computational complexity. First, the dimension of the input feature map is expanded by 1 × 1 convolution, followed by the utilization of ReLU6 for feature non-linearization. Then, 3 × 3 depthwise separable convolution and the ReLU6 activation function are employed to comprehensively extract and non-linearize features. Finally, feature fusion and dimensionality reduction are carried out through 1 × 1 convolution.
3.3. The Optimization of ASPP Module
In the DeepLabV3 + model, the ASPP module plays a crucial role in capturing multi-scale context information from the image. It achieves this by utilizing convolution kernels of different scales to optimize segmentation results and enhance segmentation accuracy. Therefore, the ASPP in this paper used three atrous convolutional layers with varying atrous rates to extract information from the weld pool and keyhole. If a larger atrous rate is selected, the receptive field expansion can reduce the loss of feature information during the convolution process. However, it may result in misidentification as the background and poor extraction effects when the receptive field exceeds the size of the weld pool or keyhole to be extracted. With the increase of the atrous rate, the attenuation of the expansion convolution becomes invalid when it is greater than 24, leading to a loss of the resolution in the feature map and subsequent loss of detailed information at the boundaries of the weld pool and keyhole. Conversely, if the atrous rate is too small, the receptive field becomes smaller than the feature area, and too much local information will be obtained, which will lead to the loss of global information. To address these considerations and leverage the characteristics of different scales and irregular edges of the weld pool and keyhole, this paper optimized the parameters through multiple experiments and finally reduced the atrous rate appropriately. The atrous rates in the ASPP were adjusted to 4, 8, and 12, striking a balance to improve the model’s recognition ability for molten pool images.
3.4. Attention Module
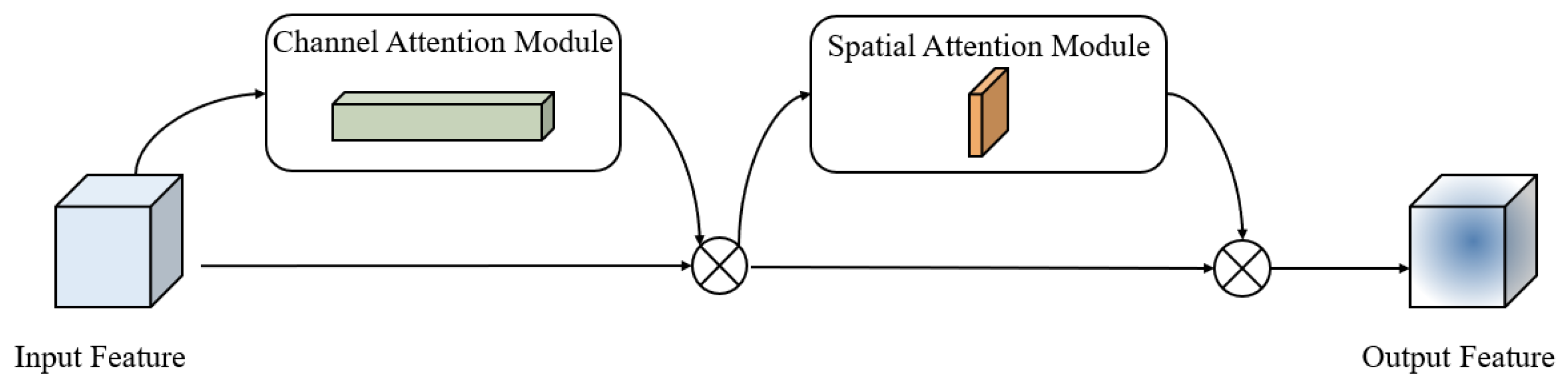
The CBAM is a lightweight attention module proposed by Woo et al. [
25]. It infers the attention weights independently along the two dimensions: channel and space. The resulting weights are then multiplied by the input feature to adaptively adjust the features. The introduction of CBAM into the CNN can greatly improve the performance of the model, and it brings a very small number of parameters and computations, which can be embedded into most networks. The structure is shown in
Figure 7.
The CBAM is composed of a channel attention module and a spatial attention module. In the channel attention module, a pooling module is formed by the mean-pooling and max-pooling via parallel connection. Two feature maps, including the maximum and average information, are derived through the pooling module. Subsequently, both feature maps pass through a Multilayer Perceptron (MLP), in which the first fully connected layer reduces dimensionality to mitigate computational complexity while the second fully connected layer elevates dimensionality. The outputs from the MLP are summed, and the channel weights are generated by the Sigmoid activation function. These weights are then multiplied with the input features to adjust the feature response of each channel, generating the input feature needed for the spatial attention module. In the spatial attention module, mean-pooling and max-pooling operations are applied to the feature map produced by the channel attention module. The results are combined to form a two-channel feature map, which is then converted into a single-channel feature map through convolutional operations. The Sigmoid activation function generates spatial weights, which are multiplied with the input feature map, weighting the feature response at each spatial location to obtain the final feature map.
The excessive atrous rate of the ASPP module will make the model unable to extract the feature information well, which will also affect the correlation between the local features of the molten pool and reduce the segmentation accuracy. Specifically, the CBAM attention module is introduced after each atrous convolution in the ASPP module, therefore adjusting the weight of the feature channel and enhancing the perception of edge features in the weld pool and keyhole.
4. Training and Results
The proposed improved DeepLabV3+ network is implemented in the PyTorch framework. The training was conducted in a computer environment with support for the Intel i7-9750H CPU (Intel Corporation, Santa Clara, CA, USA) and NVIDIA GTX 1650 (Nvidia Corporation, Santa Clara, CA, USA) graphics card. To expedite training and ensure quick convergence, the network was initialized with pretraining weights and then finetuned through transfer learning. Transfer learning is divided into two stages. In the first stage, the parameters of the network model were initialized on the Pascal VOC dataset. By freezing the batch normalization layer of the ASPP module and decoder part, it was not updated during feature migration, which can reduce the model error, ensure the migration effect, and obtain the pretraining weight. The second stage involved training on the dataset of the molten pool. Since the features extracted by the backbone network, MobileNetV2 was common in the whole model. The backbone network was frozen at the beginning of training to speed up the model training and prevent the weights from being destroyed during the training process. In later training epochs, the backbone network was unfrozen to participate in the training of the entire model. The model was trained for 100 epochs with a batch size of 8, utilizing the stochastic gradient descent (SGD) algorithm with 0.9 momentum and a weight decay of 1 × 10−4. The learning rate was 1 × 10−4.
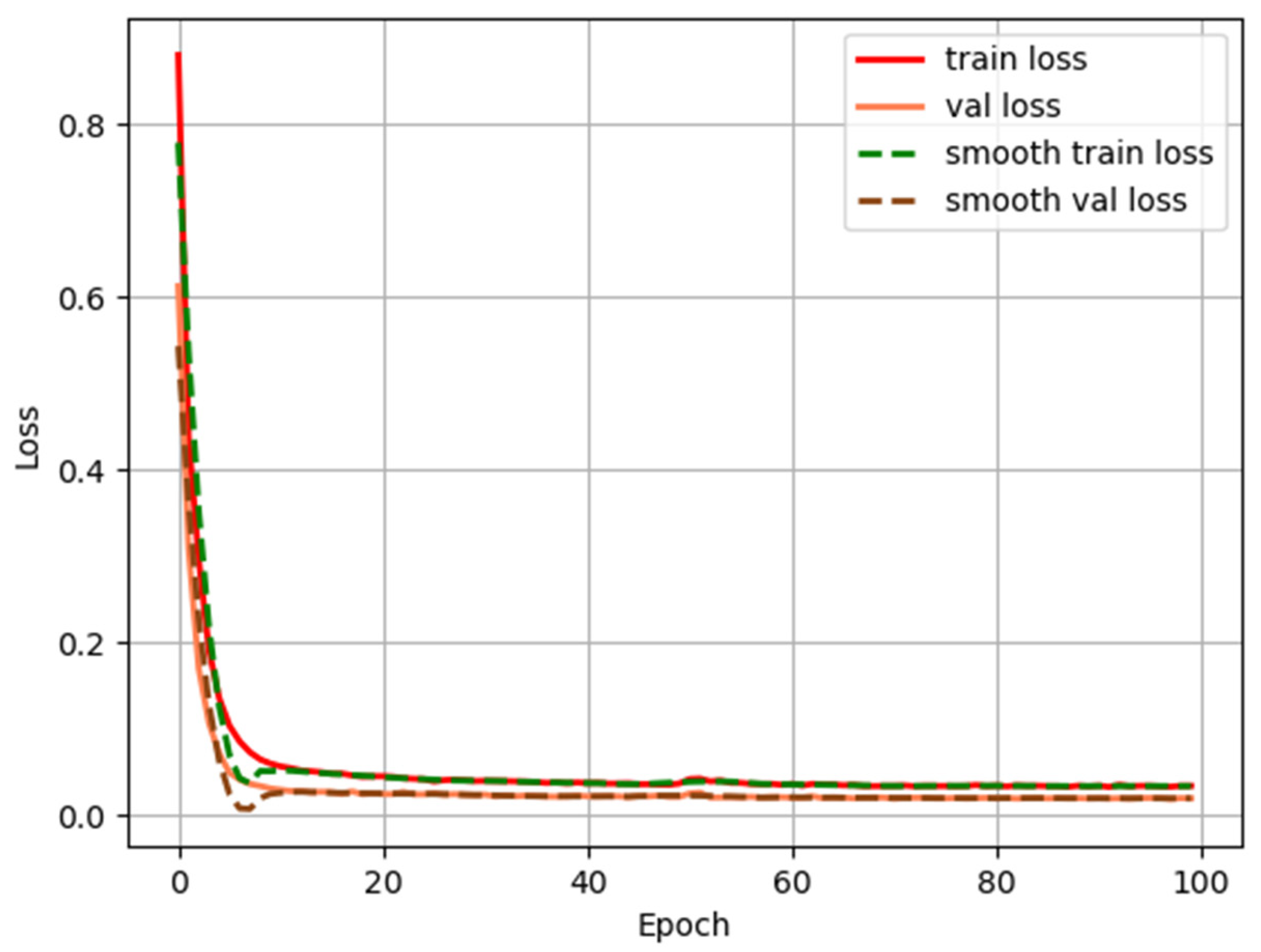
After 100 epochs of training, the change in the loss value during model training and validation is shown in
Figure 8. As we can see in the figure, with the increase in training time, both training and validation loss curves rapidly converge and then stay stable. When the time of training reaches 60, the loss value reaches 0.03. To assess the effectiveness of the DeepLabV3+ network, the mean intersection over union (MIOU) was adopted to calculate and evaluate the percentage overlap between the target and prediction, which is defined in Equation (1).
where
K denotes the number of target categories,
is the number of pixels predicted correctly,
is the number of pixels of class
predicted to be class
,
is the number of pixels of class
predicted to be class
. The MIOU of the model for the segmentation of the molten pool image is up to 89.89%.
The best-performing network model from the verification set was employed for testing on additional molten pool images. The images before and after the segmentation are shown in
Figure 9. It can be observed in the figure that the boundaries of the weld pool and keyhole are successfully recognized by the trained DeepLabV3+ network. The network can process the images at 103 frames per second, i.e., the inference time of a single image is only 9.62 ms. Such a speed ensures efficient deployment and application for monitoring the K-TIG welding process.
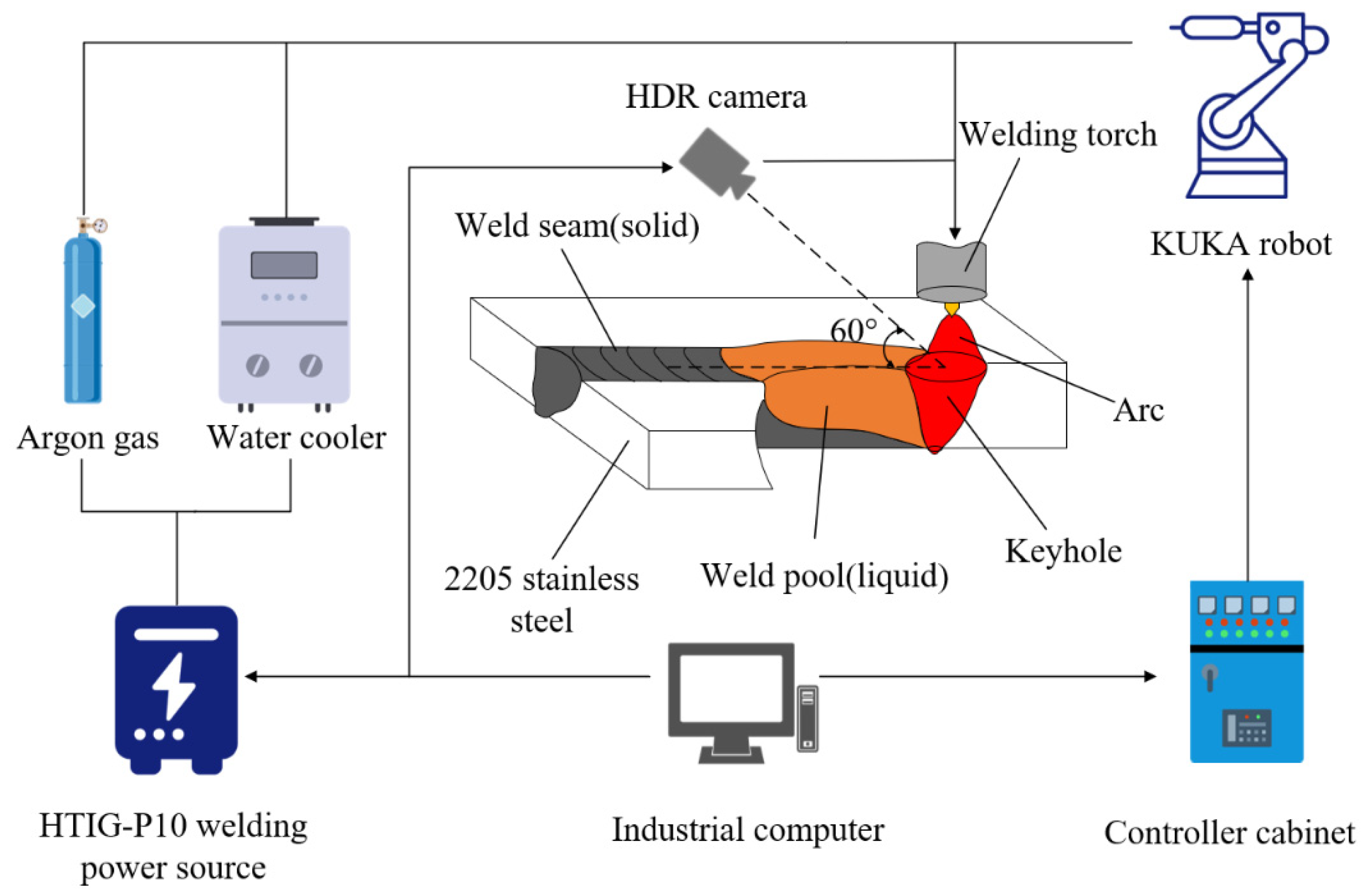
The trained model was deployed in the K-TIG experiment system, as shown in
Figure 1. During welding, the molten pool images were collected by the HDR camera and were transferred to the industrial computer, where the trained model was then applied to segment the weld pool and keyhole. Due to the camera’s low frame rate, it will cause problems with duplicated frames. Therefore, before processing, it is necessary to determine whether the images acquired by the camera are the same from the pixel level. Although the hardware limitations affected the model performance display to a very great degree, the results demonstrated that the proposed model achieved a better balance between segmentation accuracy and speed, in which the average frame rate of online detection is about 28 frames per second.
5. Conclusions
In this paper, aiming at the engineering requirements of weld pool image segmentation in K-TIG welding, a low-parameter and lightweight DeepLabV3+ network was built. Based on the DeepLabV3+ model, the Xception backbone network is replaced with the MobileNetV2 backbone network, significantly reducing the number of parameters of the model and minimizing its dependence on hardware conditions, therefore accelerating the convergence speed of the network. The segmentation speed of the molten pool reaches 103 frames per second, with an MIOU value of 89.89%, which realizes real-time high-precision segmentation. The improved model in this paper reduces manual participation in the manufacturing process, offering significant benefits in terms of reducing the defective rate of the project, cutting costs, and enhancing the safety of the project. Furthermore, for melt pool monitoring in K-TIG welding, the improved model enables more precise segmentation of the weld pool and keyhole, extracting their contour edges comprehensively and obtaining characteristic parameters, such as area and length-width ratio, which can be instrumental in monitoring welding quality and provide a research basis for the subsequent realization of the closed-loop control in K-TIG welding.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}