1. Introduction
Traffic sign detection and identification is an essential research component in the application of computer vision and image classification in automatic driving and intelligent transportation systems with a wide range of applications. Accurately detecting and recognizing traffic signs can help drivers or automatic driving systems obtain critical information in a timely manner, thus enhancing road safety. Any sign that fails to be accurately recognized may cause the system to make wrong decisions and threaten driving safety. Improving the detection precision and accuracy of small object traffic signs will significantly reduce the number of traffic accidents caused by failing to recognize critical signs. In addition, accurately identifying traffic signs can help traffic management systems optimize vehicle flow and traffic signal control, reduce traffic congestion, and improve road access efficiency. Studies have shown that a system that accurately recognizes traffic signs and responds in a timely manner can optimize traffic flow by 5–10%, especially during peak hours, and help reduce traffic congestion. However, because the current images for traffic sign object detection have problems such as small objects, complex scenes, different sign scales, and scattered objects, there is still a great challenge to accurately and quickly complete the detection of traffic signs.
Traditional traffic sign detection algorithms and deep learning-based object detection algorithms are the two main categories of traffic sign detection methods [
1]. Conventional algorithms for recognizing traffic signs mostly concentrate on feature extraction and categorization. Given the unique shapes and prominent colors, early researchers proposed many traffic sign detection methods based on handcrafted features [
2,
3,
4,
5]. However, these methods are expensive when it comes to human resources and difficult to adapt to current times, and their application in practical tasks is limited.
Deep learning-based object recognition systems now fall into two categories: one-stage detection algorithms and two-stage detection algorithms. A few examples of one-stage detection algorithms include the SSD series [
6], EfficientDet [
7], and the YOLO series [
8,
9,
10,
11,
12,
13]. R-CNN [
14], SPPNet [
15], Fast R-CNN [
16], Faster R-CNN [
17], Mask R-CNN [
18], Cascade R-CNN [
19], and D2Det [
20] are a few examples of two-stage detection methods. Although the accuracy is often lower, one-stage detection algorithms perform faster than two-stage detection algorithms in terms of detection speed. On the other hand, a variety of convolutional neural network training techniques have emerged in recent years, greatly increasing the detection accuracy of one-stage detection methods. For traffic sign identification, the one-stage detection approach has become the standard; however, the YOLO series algorithms offer even quicker and more precise detection.
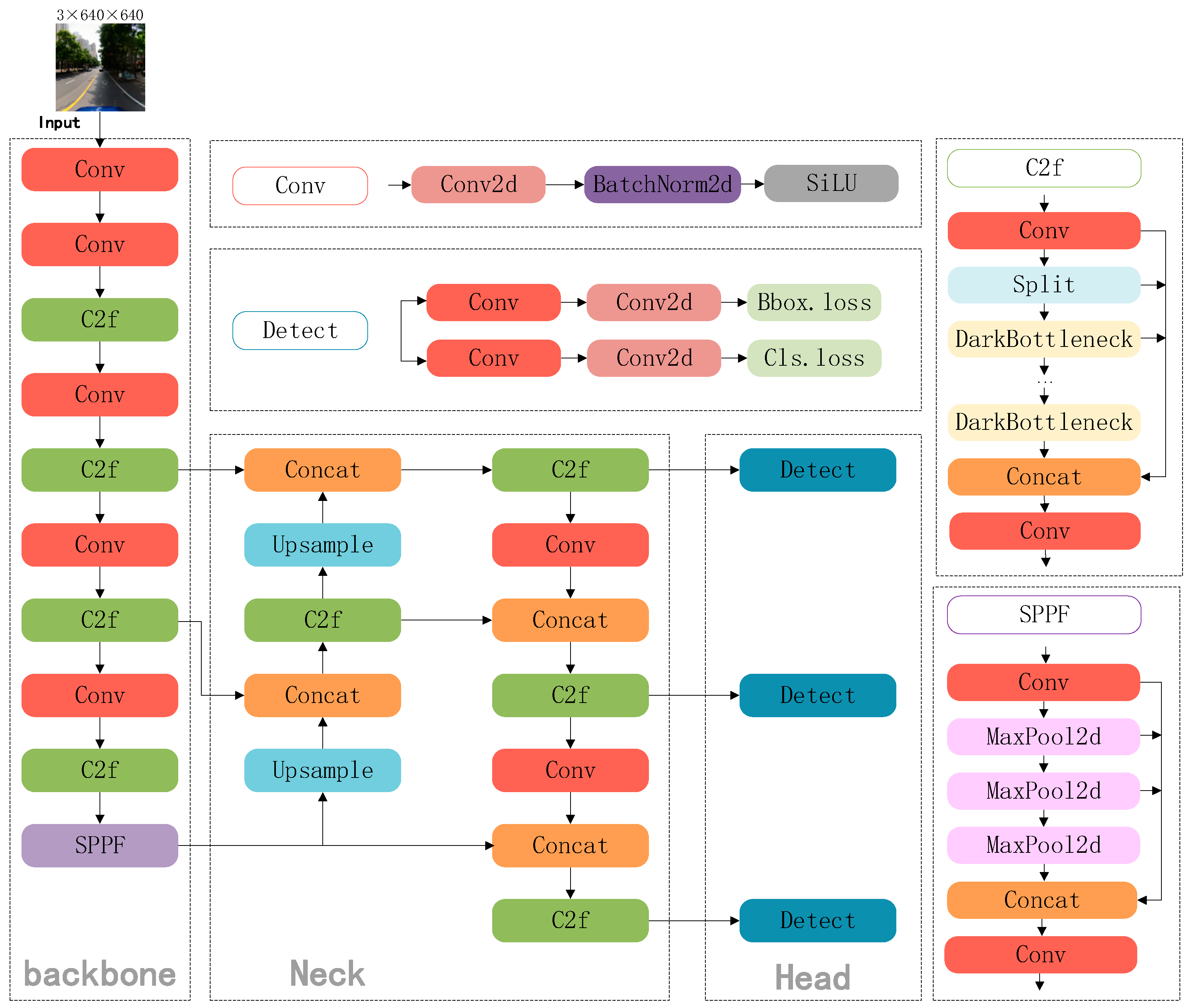
The most recent algorithm in the YOLO family is YOLOv10; as a new version, it introduces many improvements and optimizations, but YOLOv8 still maintains unique advantages. First, YOLOv8 has faster inference and training speed, which makes YOLOv8 more suitable for real-time applications that require fast response. Second, the computing needs and number of model parameters for YOLOv8 are comparatively low, which makes it suitable for running in environments with limited computational resources, and a relatively simple architecture makes it is easier to train and deploy and requires less computational resources and memory. Finally, YOLOv8 has been extensively tested and applied, and has proven its stability and reliability in various real-world scenarios. To overcome the present issues with traffic sign object detection, this work uses YOLOv8s as its foundation and suggests YOLOv8s-DDA, an improved small object detection technique. To tackle issues such as complex traffic sign scenes, small objects, varying object scales, and scattered objects, this paper introduces the C2f-DWR-DRB structure. By incorporating a Dilated Reparam Block (DRB) into the Dilation-wise Residual Module (DWR), the network’s capability to capture multi-scale contextual information is significantly enhanced, while maintaining efficient feature extraction and reducing computational complexity during the inference phase. In the aspect of feature fusion, YOLOv8s-DDA adopts the concepts from ASF-YOLO to improve the neck network, using multi-scale and spatial picture information to improve tiny item detection precision. Furthermore, the Wise-IoU loss function takes the role of the traditional loss function. The dynamic non-monotonic focusing method of Wise-IoU guarantees that anchor boxes obtain the proper gradient gains, which helps to prevent typical problems during deep neural network object identification training such as gradient disappearing or bursting. It is imperative that traffic signs be detected and recognized with high precision because this directly affects the vehicle’s decision-making capacity. Metrics such as mean Average Precision (mAP) are often used to evaluate the performance of detection algorithms, with mAP@0.5 being a standard benchmark where a value above 85% is typically desirable [
21]. Experiments and comparison testing on the TT100K dataset [
22] were carried out to confirm the algorithm’s efficacy. The performance of the proposed the results show that the YOLOv8s-DDA model outperforms the original model, with an increase in mAP@0.5 to 87.2% and a decrease in the quantity of parameters.
The traffic sign detecting system’s detection speed must operate in real time to avoid delays that may lead to accidents, and the processing time for each frame is usually less than 20 ms per frame to ensure high speed and smooth operation [
23]. The improved algorithm achieves an FPS of 125, which means that the processing time for each frame is about 8 ms, which is in line with the requirements for real-time detection. To sum up, when compared to the current mainstream models, the YOLOv8s-DDA algorithm performs better in terms of accuracy and speed of detection. The following are the contributions made by this paper:
In order to solve the multi-scale issues and lower the number of parameters, distributed objects, and complicated scenes in traffic sign detection, the C2f-DWR-DRB structure is presented.
The ASF-YOLO neck network’s implementation greatly improves the ability to detect small objects in traffic signs.
The algorithm’s detection capacity is further enhanced using the Wise-IoU loss function.
3. Methods
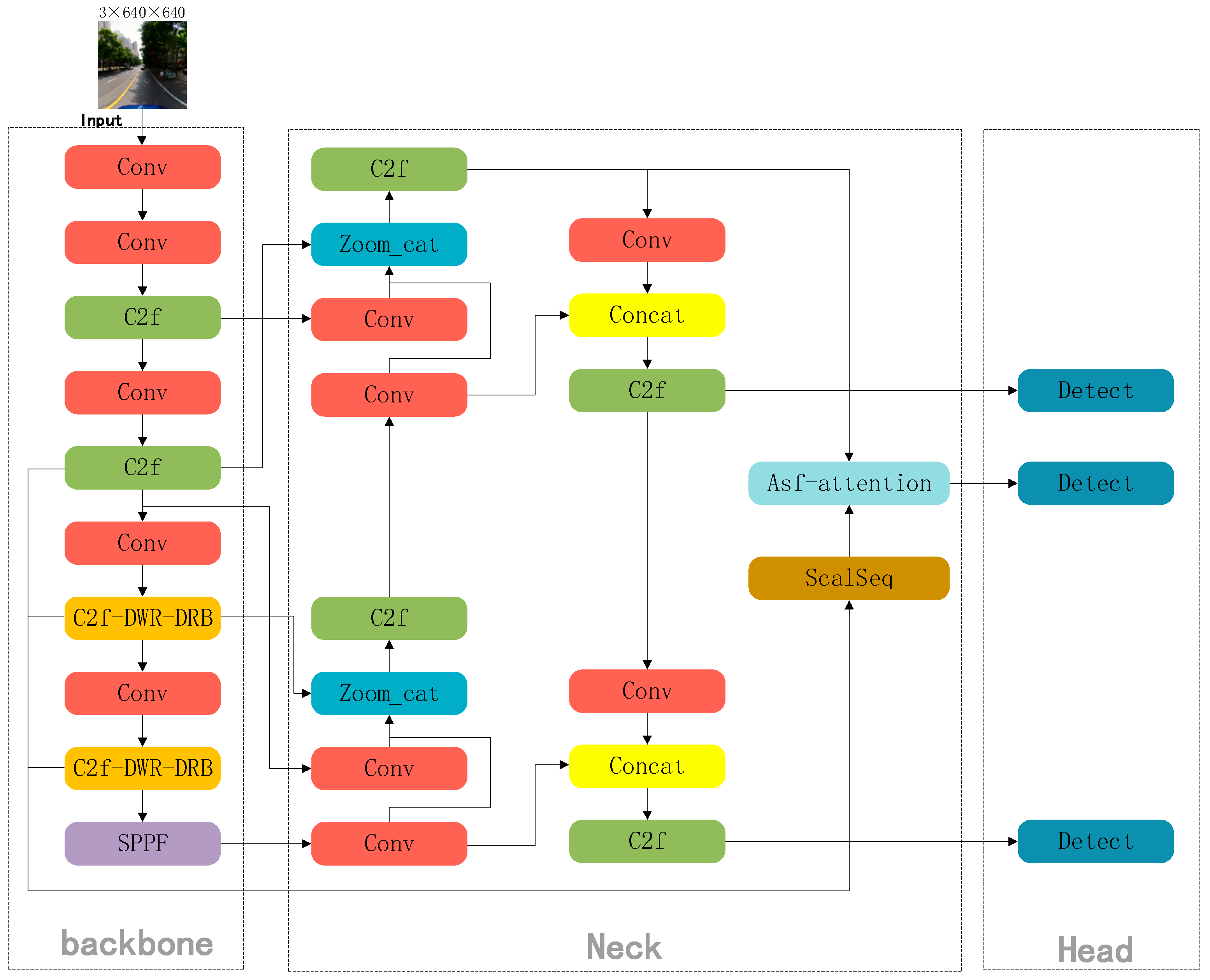
This study proposes YOLOv8s-DDA, a tiny object detection method based on YOLOv8s, to address three elements of traffic sign identification issues: feature extraction, feature fusion, and loss function. First, the C2f-DWR-DRB module enhances the C2f module in YOLOv8s by combining the benefits of dilation convolution, small- and large-kernel convolution, and convolution to reduce the computational complexity of the inference stage and offer a better feature representation while preserving effective feature extraction. Second, the ASF-YOLO network concept is applied to enhance the network’s neck by combining useful data from various scales. This allows for a more thorough comprehension of the visual material and improved processing of small objects and complicated scenery. Ultimately, the original loss function is replaced with the Wise-IoUv3 loss function to direct parameter adjustment. Consequently, training is optimized and the model’s ability to handle samples of different qualities is improved. The total network structure of the improved YOLOv8s-DDA algorithm is shown in
Figure 2.
3.1. C2f-DWR-DRB
The C2f-DWR-DRB module significantly enhances the capacity of the network in multi-scale contextual information capture by introducing the Dilated Reparam Block in the Dilation-wise Residual Module. It integrates the benefits of small- and large-kernel convolution and dilated convolution, and keeps the efficient feature extraction while simplifying the inference stage’s computational complexity, providing higher quality feature representation, and optimizing the computational efficiency of the inference stage. Experimental results show that the C2f-DWR-DRB structure achieves higher accuracy and efficiency in the object detection task, especially when dealing with complex sparse patterns.
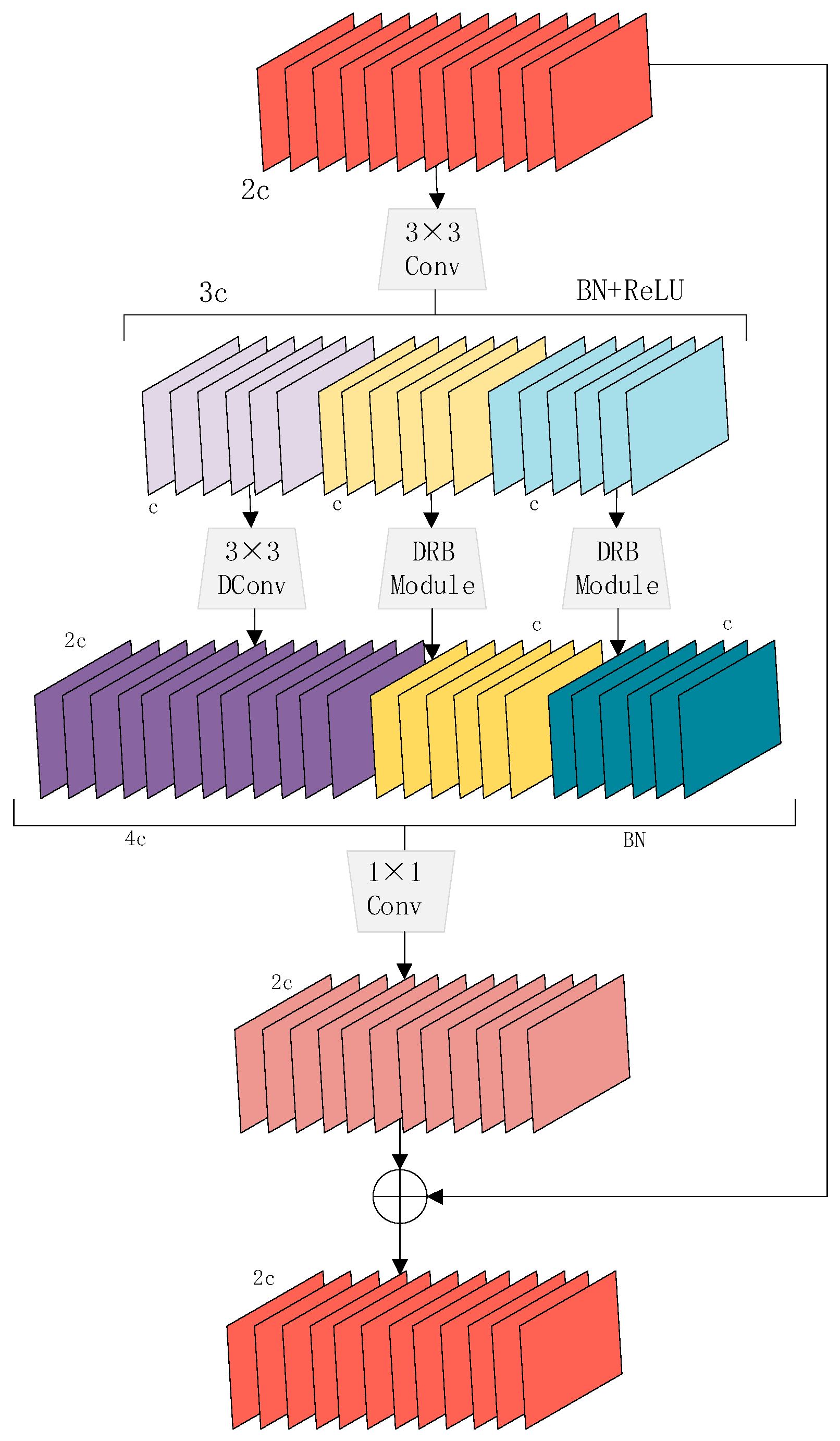
An effective two-step multi-scale context information collecting method is used by the C2f-DWR-DRB module. To reduce the collection challenges, the previous single-step multi-scale context information acquisition strategy is specifically divided into two steps. Step I. region residualization. Residual features are generated from the input features, and in the second stage, morphological filtering is carried out using the set of succinct feature maps produced in this step, which take the shape of areas of different sizes. A 3 × 3 convolution, the Batch Normalization (BN) layer, and the ReLU activation function are used to implement this method. Initial characteristics are extracted using 3 × 3 convolution, and then the region features are activated and condensed using the ReLU activation algorithm. Step II. semantic residualization. Morphological filtering is performed for region features of different sizes using a deep convolution with an expansion rate of 1 and the Dilated Reparam Block. To improve the feature capture capability, we keep the convolution layer with an expansion rate of 1 and replace the convolution layers with an expansion rate of 3 and 5 with the Dilated Reparam Block. Morphological filtering enables the application of only one desirable receptive field to each channel feature, hence preventing possibly redundant receptive fields.
With this two-step approach, the role of deep convolution from complex semantic information acquisition is changed so that it only needs to perform morphological filtering on succinctly expressed feature maps, as shown in
Figure 3. The feature maps in the form of regions simplify the role of deep convolution to morphological filtering, which standardizes the learning process and enables more efficient acquisition of multiscale contextual information. Upon obtaining the multi-scale contextual data, several outputs are combined. To construct the final residuals, each feature map is concatenated, followed by batch normalization and point-by-point convolution that fuses the features together. To provide a more comprehensive and trustworthy feature representation, the final residuals are added to the input feature maps.
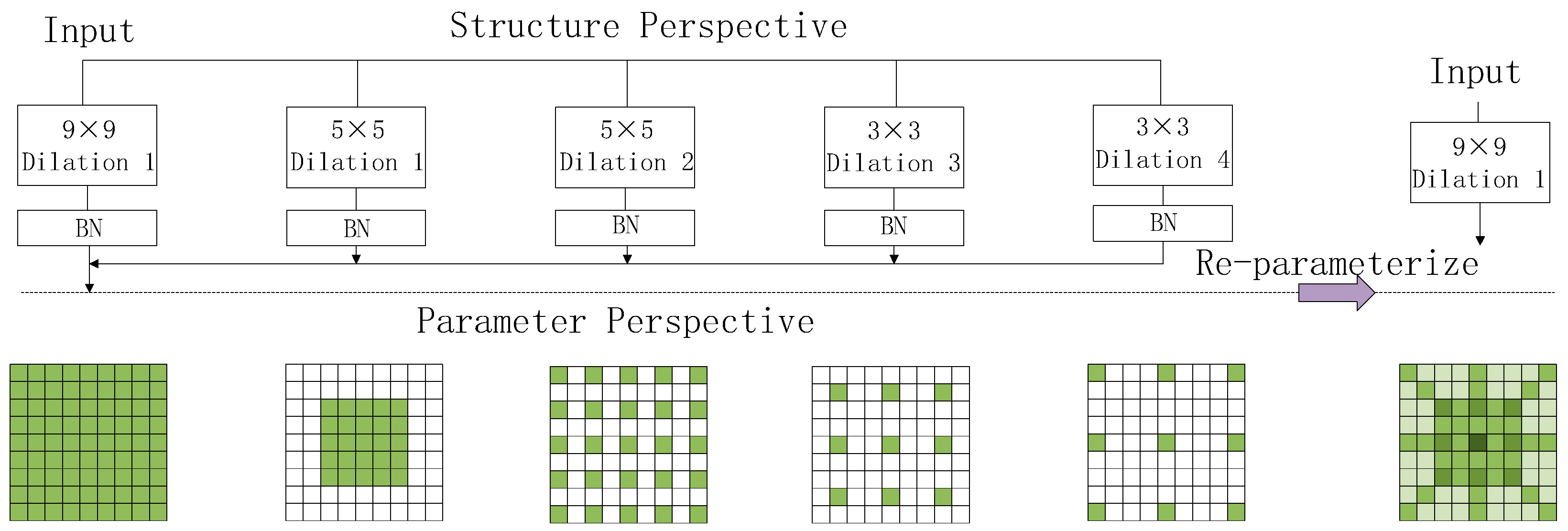
One of them, Dilated Reparam Block, is a dilated convolutional module, as shown in
Figure 4, which enhances the feature extraction capability of convolutional neural networks by combining large-kernel convolution and small-kernel convolution in parallel [
33]. Convolutional kernels of various sizes are used in the design to capture features with sparse patterns and varying spatial scales. Convolutional layers are then combined into a single convolutional layer during the inference stage using the structural reparameterization method, which enhances feature quality while preserving computational efficiency.
The three main hyperparameters are the expansion rate (r), the size of the big kernel (k), and the dimensions of the parallel convolutional layers (k). Four-parallel configurations are denoted as k = 9, r = (1, 2, 3, 4), and k = (5, 5, 3, 3). For higher values of k, additional expansion layers with larger core sizes or expansion rates can be employed. The kernel sizes and expansion rates for the parallel branches are adaptable, with the only condition being that (k − 1) r + 1 < k.
Using multi-scale convolutional kernels, large-kernel convolution is used to capture global patterns, small-kernel convolution is used to capture small-scale patterns, and dilation convolution (with dilation rate) is used to capture sparse patterns, i.e., relationships between distant pixels. The large kernel convolution and dilation convolution layers operate in parallel to extract features separately, and each of them is followed by a BN layer to normalize the outputs, which are then summed up. After training, the network structure is simplified by merging the BN layer into the corresponding convolutional layer. For the dilated convolutional layer, by switching the convolutional operation, the convolutional layer with dilation rate becomes an identical non-dilated convolutional layer, which allows multiple parallel convolutional layers to be merged into a single convolutional layer with a sparse, large kernel, enhancing the efficiency of the inference phase. For example, an expansive convolutional layer with expansion rate r and kernel size k has an equivalent non-expansive convolutional kernel size of (k − 1) r + 1. This design not only enhances the capacity to extract features from convolutional neural networks, but also simplifies the network structure and improves the computational efficiency in the inference stage through the reparameterization method.
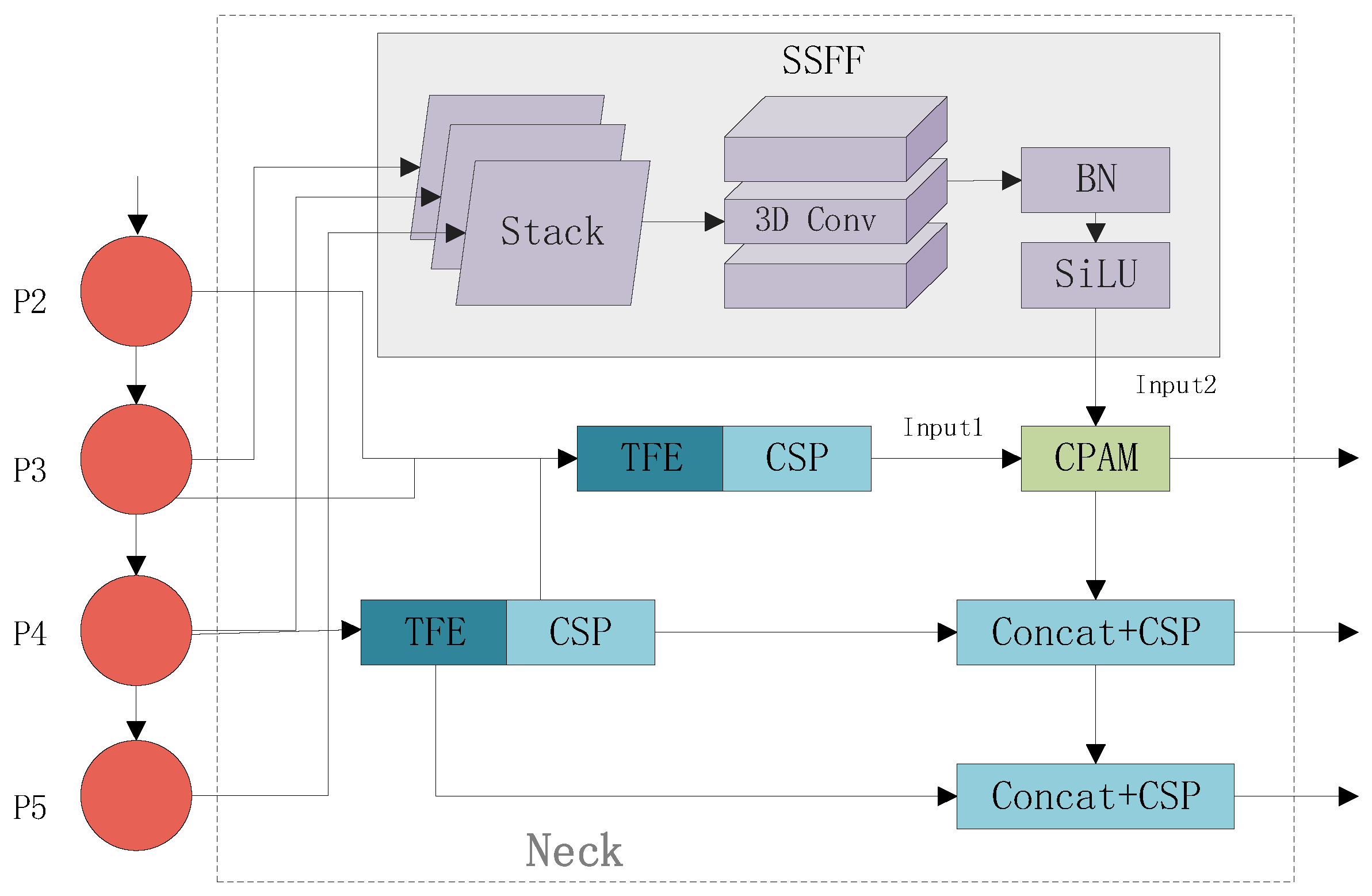
3.2. Improved Neck
The ASF-YOLO model is a cellular image instance segmentation framework that combines spatial and multi-scale features and aims to increase the precision of small object segmentation by combining local and global feature data [
34]. The main components of the neck of the framework include the SSFF module and TFE module, and the positional attention mechanism CPAM, as shown in
Figure 5.
To capture different spatial scale elements of an image, the Scale Sequence Feature Fusion (SSFF) module fuses global or high-level semantic information from multi-scale images. Traditional approaches have addressed the multi-scale challenge by employing a feature pyramid structure for feature fusion, typically using simple additive or concatenation methods. However, the SSFF module enhances this process by effectively combining multi-scale feature maps—melding the high-level details from deeper feature maps with the finer details from shallower ones. It applies Gaussian smoothing to multi-scale feature maps (P3, P4, P5) derived from the backbone network, then horizontally concatenates these maps and extracts their scale-sequence features through 3D convolution. The SSFF module is built on the high-resolution feature map (P3) level since it contains vital information for identifying and segmenting small objects. In order to create scale sequence features, the module merges P4 and P5 using 3D convolution after scaling them to match P3’s size.
The Triple Feature Encoder (TFE) module improves small object detection by capturing localized details and fusing multi-scale features. It enhances recognition of densely packed small objects by analyzing shape and appearance variations across different scales. Initially, the module modifies the feature map channels before processing large-scale feature maps via convolution, followed by downsampling through max pooling and average pooling. For smaller feature maps, upsampling is achieved using nearest neighbor interpolation. Ultimately, the module integrates large, medium, and small feature maps, yielding enhanced feature representations for more accurate detection.
The Channel and Position Attention Mechanism (CPAM) module effectively integrates fine-grained and multi-scale features derived from the SSFF and TFE modules by leveraging both channel-specific and spatial attention mechanisms. The channel attention mechanism assigns importance to individual channels through global average pooling followed by two fully connected layers. Meanwhile, the spatial attention mechanism maintains the spatial structure by applying pooling operations along both the horizontal and vertical dimensions. This dual-attention approach allows CPAM to selectively emphasize crucial spatial and channel-related information, thereby enhancing segmentation accuracy.
The model begins by merging the P3, P4, and P5 feature maps derived from the backbone network. The SSFF module is then employed to combine multi-scale features through 3D convolution, while the TFE module enhances the representation of small objects by concatenating feature maps of different spatial sizes—large, medium, and small. This approach allows for capturing intricate details across scales, significantly improving the model’s ability to detect small objects. Lastly, CPAM is applied to the P3 branch to leverage both high-level multi-scale features and detailed information, ultimately improving detection precision.
3.3. Wise-IoU
The accuracy of object detection within a dataset is evaluated using the Intersection over Union (IoU) metric, which assesses how closely predicted bounding boxes align with actual objects. IoU provides a quantitative measure of the overlap between predicted and ground truth boxes, allowing for the evaluation of the precision of detection. In the object detection task, IoU represents some ratio of predicted boxes to actual boxes with the following formula:
For the base IoU, if the two frames do not intersect, IoU = 0, which does not reflect the magnitude of the distance between the two (overlap). In addition, since no gradient back propagation can be generated when loss = 0, this results in no learning or training.
Object recognition is a fundamental problem in computer vision, and the architecture of the loss function determines how well this task performs. Object identification models can work much better when the bounding box loss function is well-defined. An essential part of the loss function for object detection is the bounding box loss function [
35]. Recent work has mostly assumed high-quality training data and concentrated on enhancing the fitting capabilities of the bounding box loss. However, the object identification training set contains low-quality instances as well. Improving the model’s performance is clearly impacted if the bounding box’s regression is only enhanced on these cases. Focal-EIoU was proposed to solve this problem, but because its focusing mechanism is static, it has not been able to fully use the promise of the non-monotonic focusing mechanism [
36]. From this perspective, Wise-IoU presents a dynamic non-monotonic focusing mechanism that offers an optimum gradient gain allocation approach, and uses the “outlier degree” instead of the IoU to assess anchor frame quality. By doing this, Wise-IoU can concentrate more on medium-quality anchors and enhances the detector’s overall performance. It also lessens the competition from high-quality anchors and the detrimental gradients from low-quality examples. We next describe the mathematical derivation process of Wise-IoU.
Firstly, the distance–attention mechanism (Equation (3)) is constructed to expand the model’s capacity for generalization, reduce the influence of geometric factors when the anchor and object frames overlap, and reduce the interference during the training process. As a result, the Wise-IoU v1 containing the dual attention mechanism is obtained:
The coordinates x and y represent the center of the anchor box, while xgt and ygt represent the center of the ground truth box. Wg and Hg are the width and height of the ground truth box, respectively. To prevent gradients from from negatively impacting convergence, Wg and Hg are removed from the computation graph, as indicated by the superscript * symbol. ∈ [1, e), significantly increasing the for average-quality anchor boxes, while ∈ [0, 1], reducing for high-quality anchor boxes. When there is strong overlap between the object and anchor boxes, the focus shifts to minimizing the distance between their centroids.
Focal Loss [
37] effectively reduces the effect of simple examples on the loss value by constructing a monotonic focusing mechanism based on cross-entropy. This enables the model to focus on difficult cases and improve classification performance.
Similarly, we constructed
and the monotonic focusing coefficient
.
Later training phases see slower convergence because when
declines during model training, the gradient gain also decreases. Thus, as a normalization factor, the mean value of
was introduced:
is the sliding average with momentum m. Dynamically updating the normalization factor keeps the gradient gain overall at a high level, which solves the problem of slow convergence at the late stage of training.
Dynamic non-monotonic FM (focusing mechanism): anchor frame quality is characterized by the outlier, which is defined as:
∈ [0, +∞); a small outlier indicates a high quality of anchor frames, for which we assign smaller gradient gains to make the bounding box regression more concerned with ordinary quality anchor frames. By giving lower gradient gains to anchor frames with high outliers, low-quality examples are successfully prevented from producing large damaging gradients. We create a focusing factor that is not monotonic and utilize it with Wise-IoU v1:
The mapping of outlier β and gradient gain r is controlled by hyperparameters α and δ, respectively. Different models and datasets have different suitable hyperparameters, which need to be adjusted by themselves to find the optimal solution.
Wise-IoU integration with YOLOv8 is crucial. YOLOv8 is renowned for its accuracy and quickness, and Wise-IoU’s subtle gradient adjustments can improve its functionality even further. Throughout the training phase, the anchor frames are guaranteed to acquire the appropriate gradient gains thanks to the dynamic non-monotonic focus mechanism of Wise-IoU. This method helps reduce gradient vanishing or explosion, a common issue while teaching object identification to deep neural networks. Furthermore, Wise-IoU improves YOLOv8’s performance in intricate environments with overlapping objects of various sizes and aspect ratios by highlighting the precision of bounding box predictions. To raise the bar for object identification frameworks and enhance the model’s performance, Wise-IoU is incorporated into YOLOv8.
4. Experiments
4.1. Dataset Description
The TT100K dataset [
22] was compiled and made publicly available by a joint lab at Tsinghua University and Tencent, who downloaded 100,000 high-resolution Street View images in 2048 × 2048 size from Tencent Maps data centers in five different cities in China, including city roads, highways, and countryside roads, covering street scenes in multiple cities in China, as well as a wide range of lighting and weather conditions to meet different application requirements. The dataset contains 30,000 traffic sign instances and 221 different types of road traffic signs. Certain traffic sign categories with few instances are deemed inadequate for ensuring successful model training. Consequently, only 45 traffic sign categories with more than 100 instances were chosen for additional analysis after the dataset was preprocessed to eliminate traffic sign categories with no labels or low frequency of occurrence. According to the definition of small objects by the International Society for Optics and Photonics (SPIE) [
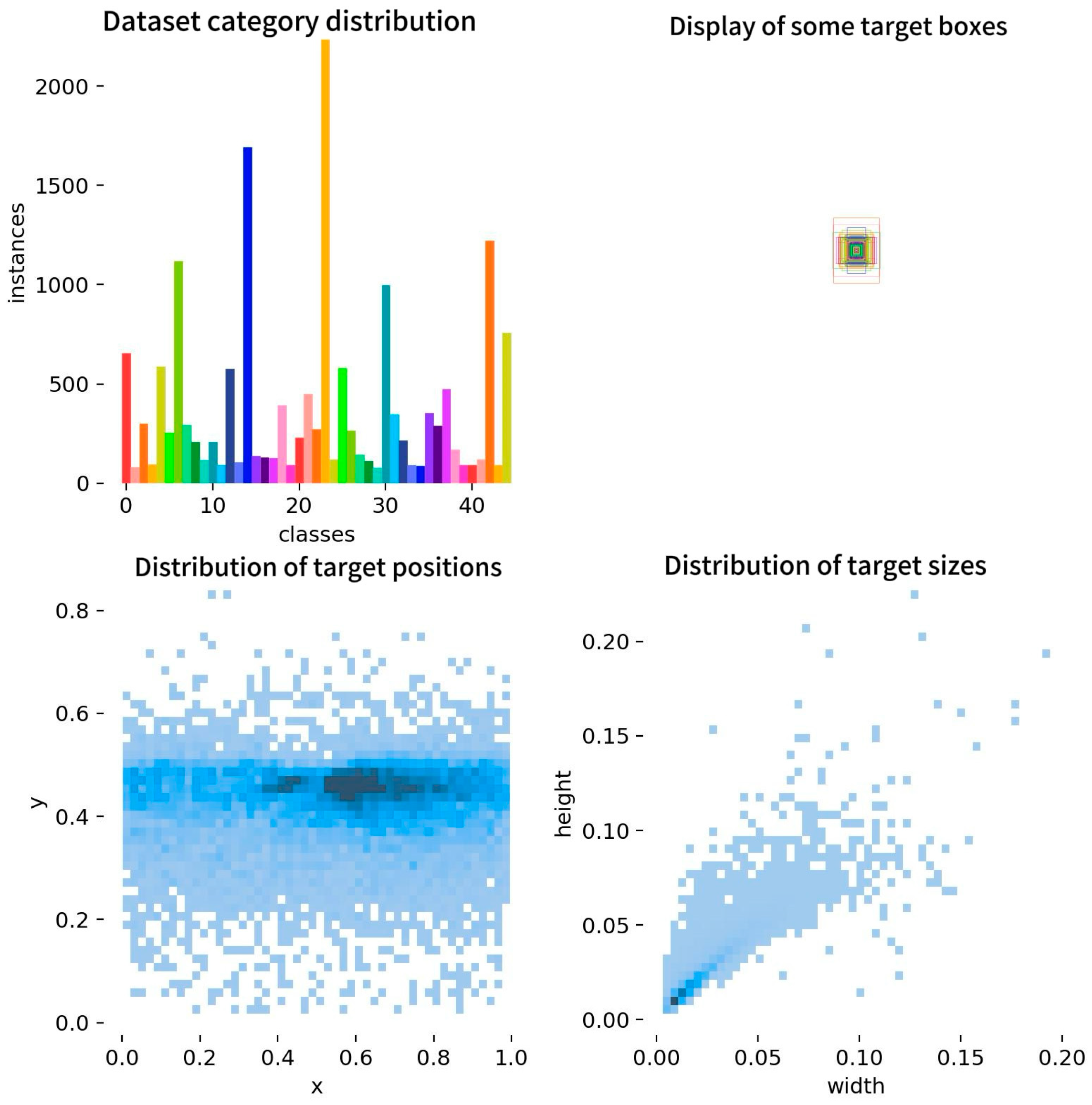
38], small objects make up 84% of the dataset. The training set has 6793 images, the validation set has 1949 images, and the test set has 996 images.
Figure 6 illustrates the dataset category distribution, some of the target boxes, target location distribution, and target size distribution.
Figure 7 shows the partial presentation of the dataset.
4.2. Implementation Details
The TT100K-train dataset is the training set, and the TT100K-val dataset is the validation set. During the training period, the initial learning rate is set to 0.01, and the final learning rate is set to 0.1. The number of threads is set to 8, the batch size is set to 8, and the number of epochs is set to 300. The specific configurations of the experimental environment are shown in
Table 1.
4.3. Evaluation Metrics
The experimental outcomes are evaluated using the following metrics: mAP@0.5, mAP@0.5:0.95, accuracy, and recall. The following formulas apply to all evaluation metrics:
In the formula, TP (True Positive), FP (False Positive), and FN (False Negative) represent the correct identification of a positive class, the incorrect identification of a negative class as positive, and the failure to identify a positive class, respectively.
4.4. Comparison Experiments of Wise-IoU
In order to further examine the impact of the loss function on the accuracy ground of the algorithm, in this paper, under the framework of the YOLOv8s-DDA algorithm, the new loss functions obtained by using different versions of Wise-IoU, and replacing the IoU in Wise-IoUv3 with the EIoU [
39], GIoU [
40], DIoU, CIoU [
41], and SIoU [
42] were used for comparative studies were carried out.
Table 2 displays the outcomes of the experiment.
From the table, after replacing the original IoU of YOLOv8s with Wise-IoUv3, the accuracy of mAP@0.5 and mAP@0.5:0.95 is significantly improved. To further explore the effect of different IoU on the experimental results, further experiments were carried out on Wise-EIoUv3 and so on, and finally the optimal IoU was obtained as Wise-IoUv3.
4.5. Ablation Experiment
In this paper, the YOLOv8s algorithm is used as the basic framework for ablation experiments using the TT100K dataset.
Table 3 displays the ablation experiment findings for the parametric values, precision, recall, and mAP@0.5 and mAP@0.5:0.95.
C2f-DWR-DRB: After replacing the C2f module in the backbone of YOLOv8s with the C2f-DWR-DRB module, the accuracy of the algorithm has been slightly improved, and the number of parameters has been somewhat reduced. The module adopts an efficient two-step multi-scale context information acquisition method, which significantly improves the network’s capability in feature extraction and optimizes the computational efficiency in the inference stage, in which the dilation reparameterization block utilizes convolution kernels with different scales to capture features with different spatial scales and sparse modes. At the same time, multiple convolutional layers are merged into a single one in the inference stage by the structural reparameterization method, so as to improve the feature quality while maintaining the computational efficiency while improving feature quality. The above experiments also verify that the C2f-DWR-DRB module achieves higher accuracy and efficiency in the task of detecting small objects of traffic signs.
ASF: After using the improved neck network structure, mAP@0.5 improved by 2.6%, the number of participants has risen somewhat, but not significantly. This neck network enhances small object detection accuracy by effectively combining both global and local features. It employs the Triple Feature Encoder (TFE) module to merge feature maps of varying scales, enriching the detailed information crucial for recognizing smaller objects. Additionally, the Scale Sequence Feature Fusion (SSFF) module is integrated to strengthen the extraction of multi-scale features. To further enhance feature representation, the Channel and Position Attention Mechanism (CPAM) is introduced, which focuses on essential channels and spatial locations linked to small objects. The combined efforts of SSFF, TFE, and CPAM lead to improved multi-scale feature extraction and more precise detection of small objects. The three components work in conjunction with each other to make the algorithm much more efficient in detecting small objects, and the experimental results validate the effectiveness of the improved neck network.
Wise-IoUv3: After using Wise-IoUv3 instead of the original CIoU in YOLOv8s, there was an improvement of 1.1%. Wise-IoU v3 provides a fine-grained gradient update to further improve the performance of YOLOv8s. This loss function reduces the common problems of gradient vanishing or gradient explosion, and the model’s efficiency can be improved by handling complicated scenarios with overlapping objects of different sizes and aspect ratios.
We utilize
Figure 8 to illustrate the performance increase of YOLOv8s-DDA over the original algorithm. The top four images represent the detection results of the original algorithm YOLOv8s, while the bottom images represent the results of the YOLOv8s-DDA algorithm. It is clear that YOLOv8s-DDA can accurately detect the traffic signs missed by YOLOv8s.
4.6. Comparison of Different Detectors
This study compares the state-of-the-art small object detection algorithm YOLOv8s-DDA to several popular one-stage and two-stage detection methods in order to validate it. After training, the TT100K dataset is selected for testing and comparison, and mAP@0.5 is used as the evaluation metric.
Table 4 displays all the results. The suggested YOLOv8s-DDA algorithm outperforms all others in the traffic sign detection test, according to the results.
4.7. Generalization Experiment
In this paper, we conduct experiments on the publicly available dataset China Traffic Sign Detection Dataset CCTSDB2021 [
47] to verify the generalization ability of YOLOv8s-DDA algorithm on different datasets. CCTSDB2021 is an open-source traffic sign dataset, created by a team of experts from Changsha University of Science and Technology, which contains nearly 20,000 traffic sign images involving nearly 40,000 traffic sign instances. These images are derived from real road driving scenarios in China, and most of them are taken from in-vehicle viewpoints, such as street photography and driving recorders, which provide researchers with valuable data resources of traffic scenarios. The dataset is meticulously categorized by size and scene, and rich road background information is incorporated. The training and test sets contain a total of 17,856 images and their labeling information, and are classified into three categories: prohibition signs, warning signs, and directional signs. According to the experimental results in
Table 5, mAP@0.5 improved by 2.9% and mAP@0.5 improved by 6.1% compared to YOLOv8s. In summary, the YOLOv8s-DDA algorithm not only shows superior performance on the TT100K dataset, but also has high recognition accuracy and strong generalization ability on Chinese traffic sign detection dataset CCTSDB2021.
5. Results
This research presents an improved small object detection algorithm, YOLOv8s-DDA, which is based on YOLOv8s to address the issues with traffic sign object detection and enhance the accuracy of traffic signs in object detection. This algorithm proposes the C2f-DWR-DRB module, which enhances the extraction capability of sparse objects and solves the problems of traffic sign object detection such as signs with different scales and scattered objects. The improved neck network in ASF-YOLO is introduced to enhance the network’s detection ability for small objects by utilizing high-level multi-scale features and detailed features. Finally, Wise-IoUv3 is selected to replace the original IoU through experimental comparison to further enhance the performance of the algorithm.
The experimental results indicate that the improved small object detection algorithm offers advantages such as increased detection accuracy and reduced parameter count. On the TT100K dataset, both mAP@0.5 and mAP@0.5:0.95 of the YOLOv8s-DDA algorithm improved by 4.0%, detection accuracy increased by 2.9%, recall rate increased by 6.4%, and the parameter count was reduced by 5.4%. Additionally, the accuracy on the publicly available Chinese traffic sign detection dataset CCTSDB2021 also improved.
Subsequent investigations will endeavor to enhance the algorithm’s efficacy by augmenting the precision of traffic sign identification. Simultaneously, strategies will be employed to reduce the number of model parameters, aiming for a more lightweight design suitable for deployment on low-power devices. Additionally, comprehensive studies will be conducted on detecting traffic signs under various challenging weather conditions, such as rain, snow, and fog. The goal is to strengthen the algorithm’s robustness and adaptability across diverse environments, ensuring stable and reliable performance in real-world applications.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}