

Dynamic Partitioning of Graphs Based on Multivariate Blood Glucose Data—A Graph Neural Network Model for Diabetes Prediction


Abstract
1. Introduction
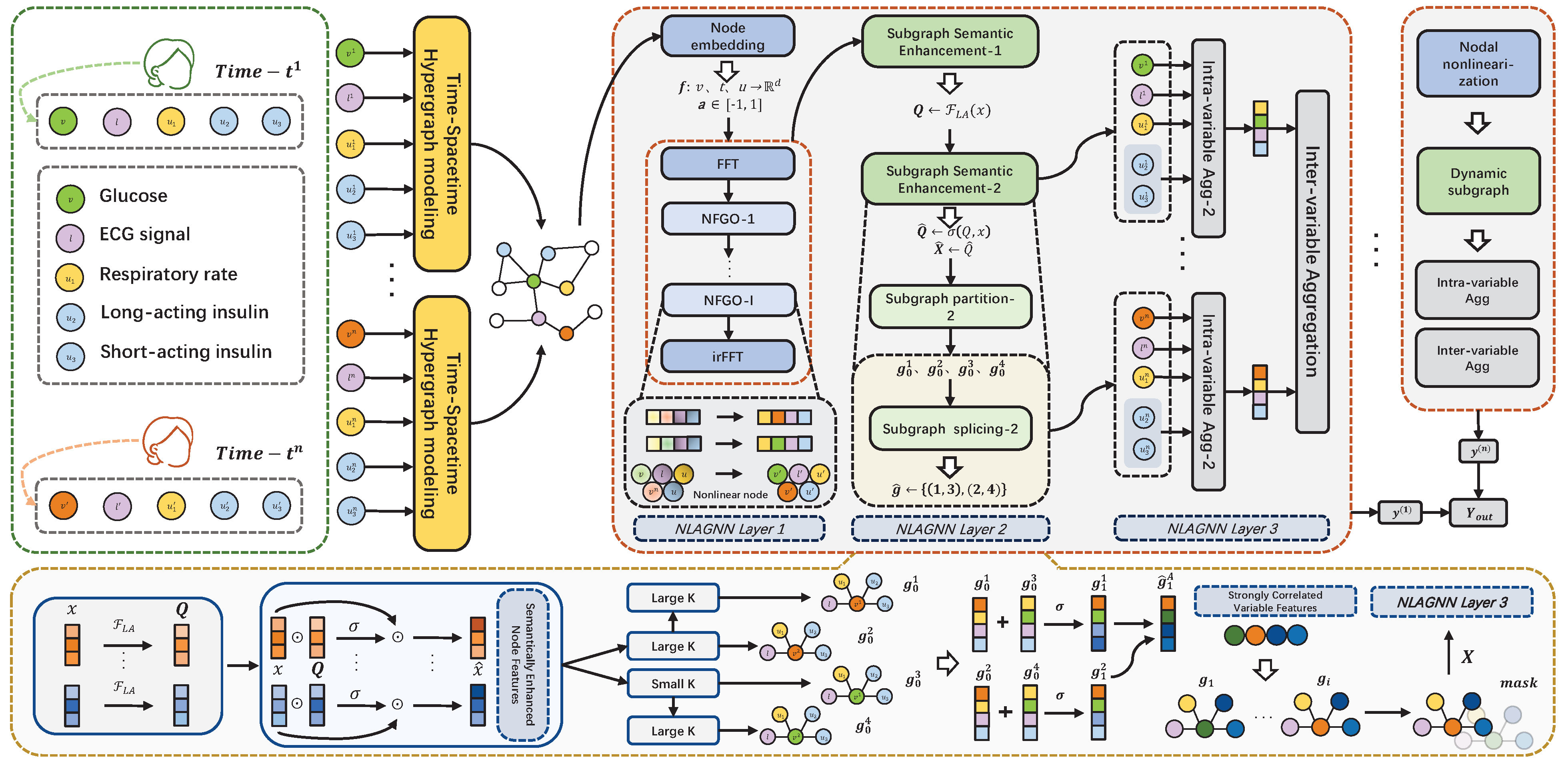
- A novel deep learning network, NLAGNN, is introduced, which represents data as a hypergraph. This approach addresses the challenge of capturing temporal and spatial dynamics in blood glucose data, including patient-specific dependencies. In addition, a novel Non-linear Fourier Graph Neural Operator (NFGO) is introduced, which enhances variables strongly correlated with blood glucose and appropriately masks irrelevant features.
- Accordingly, a dynamic subgraph partitioning approach is devised, which further enhances the semantic information of nodes within regions of strongly correlated variables using different subgraphs in combination with multi-convolutional kernels for adaptive feature selection.
2. Related Work
2.1. Methods of Blood Glucose Forecasting
2.2. Graph Neural Networks for Multivariate Time Series Forecasting
3. Methodology
3.1. Technical Roadmap
- 1.
- To emphasize the importance of spatiotemporal modeling, we represent the variable and time data as a hypergraph structure. In this structure, the central node (blood glucose) is connected to several other variable nodes via hyperedges, representing their relationships through multiple edges extending from the same node.
- 2.
- Our proposed Nonlinear Fourier Graph Neural Operator (NFGO) represents the nodes in the hypergraph nonlinearly, aiming to capture the feature intensities of multiple variables while reducing meaningless noise.
- 3.
- After applying semantic enhancement to the nodes in the hypergraph, we use fuse the convolution to adaptively reconstruct the adjacency matrix weights, dynamically partitioning the hypergraph into multiple subgraphs and extracting features at the subgraph level. Details of this section are found in the second layer of Figure 1.
- 4.
- To effectively aggregate the features obtained from the previous steps, we use intra-variable and inter-variable aggregation methods to reconstruct the feature maps from different pieces of node information across the three branches, thereby predicting the final blood glucose values.
3.2. Nonlinear Node Representation of Hypergraph
| Algorithm 1 Node representation method based on NFGO |
|
3.3. Dynamic Segmentation of Graphs
3.3.1. Subgraph Semantic Enhancement
3.3.2. Large and Small Kernel Fusion Convolution
3.4. Layer Aggregation
3.4.1. Intra-Variable Aggregation
3.4.2. Inter-Variable Aggregation
| Algorithm 2 The Training Algorithm of NLAGNN |
|
4. Experiments
4.1. Dataset
4.2. Experimental Setup
4.2.1. Baseline and Implementation
4.2.2. Metrics
4.2.3. Hyperparameters
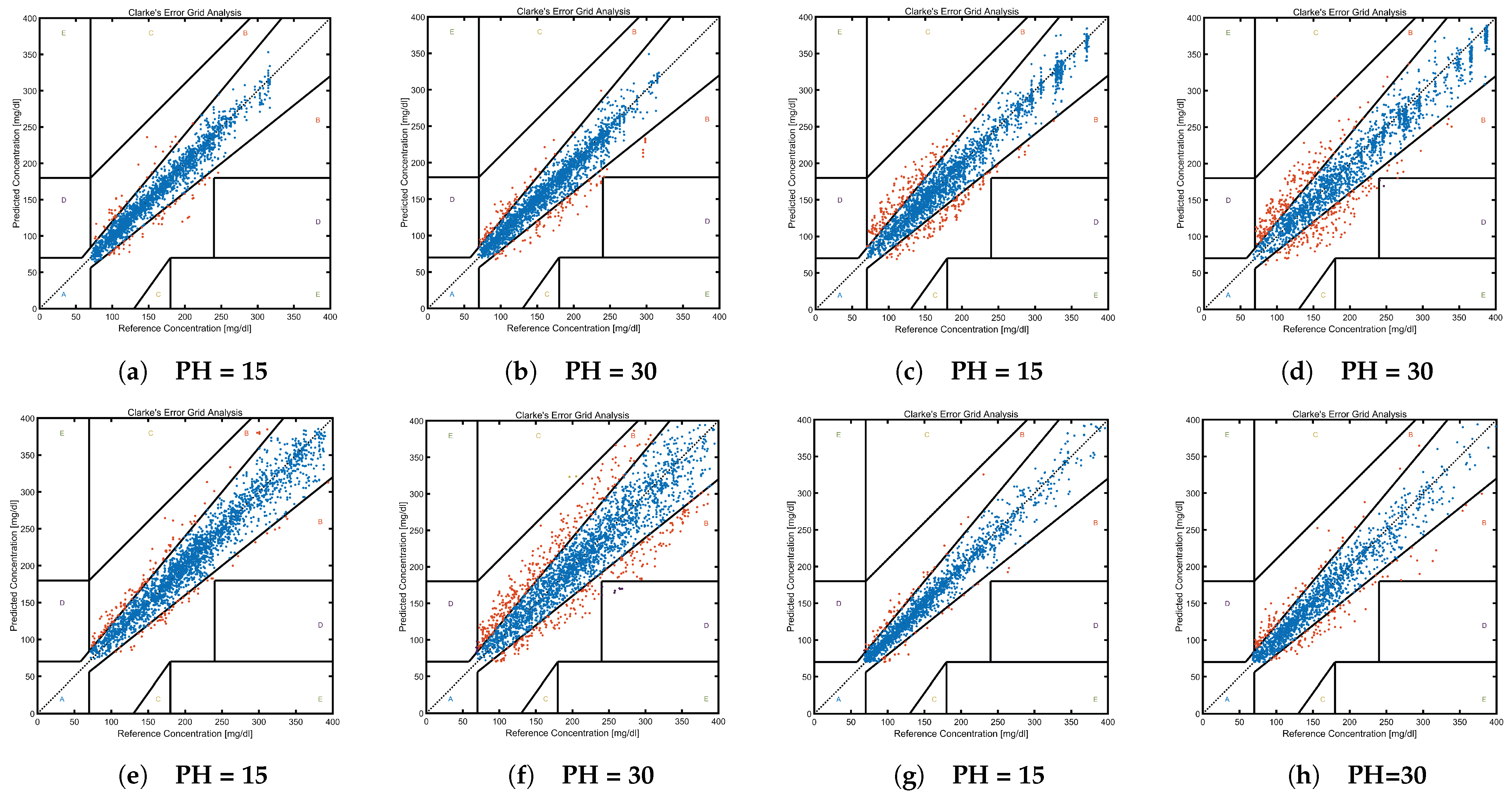
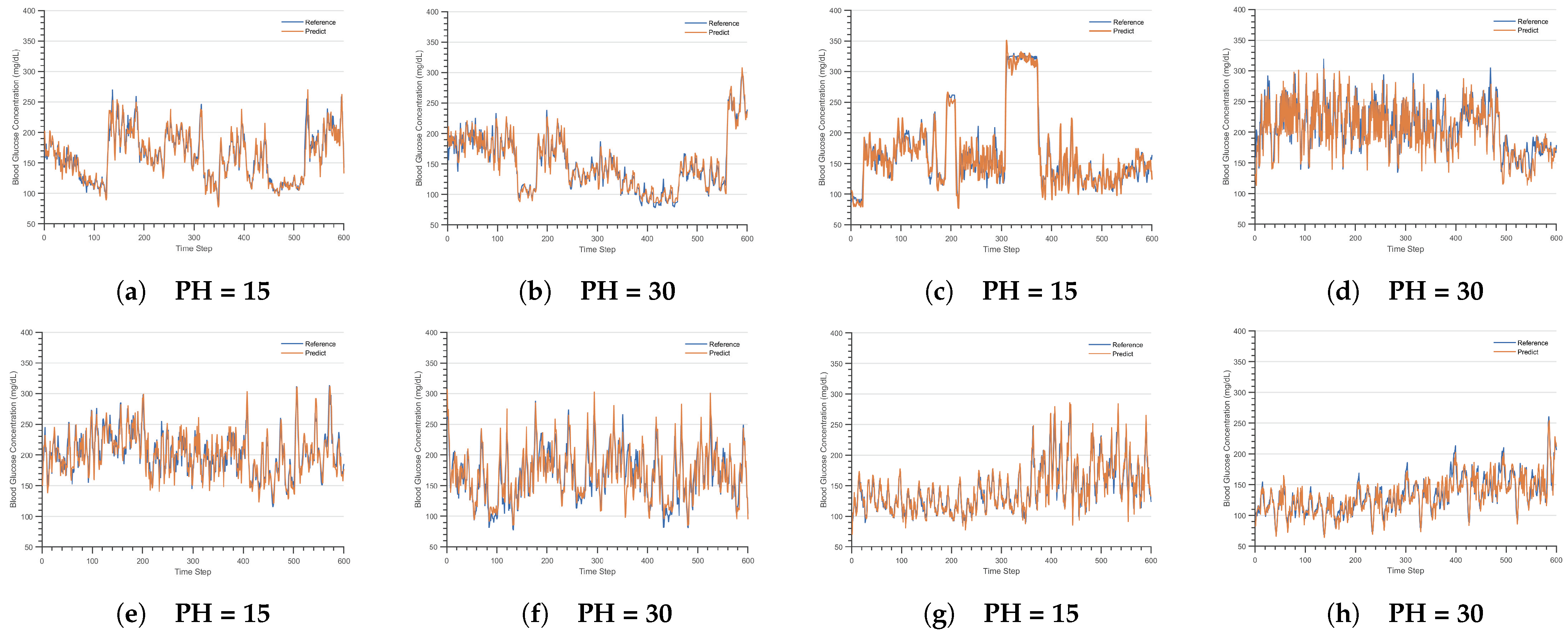
4.2.4. Results and Analysis
4.3. Ablation Study
- Zone A (Acceptable Zone): Predicted values are within ±20% of the reference values or within ±15 mg/dL during hypoglycemia (<70 mg/dL).
- Zone B (Benign Error Zone): Predicted values, though deviating from the reference values, do not significantly influence patient management.
- Zones C, D, and E: These zones indicate critical errors between predicted and reference values, warranting immediate clinical attention.
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- International Diabetes Federation, 10th ed.; IDF Diabetes Atlas: Brussels, Belgium, 2021; Available online: https://www.diabetesatlas.org (accessed on 12 March 2023).
- Dunya, T.; Shaw, J.E.; Magliano, D.J. The burden and risks of emerging complications of diabetes mellitus. Nat. Rev. Endocrinol. 2022, 18, 525–539. [Google Scholar]
- Rodriguez Leon, C.; Banos, O.; Fernandez Mora, O.; Martinez Bedmar, A.; Rufo Jimenez, F.; Villalonga, C. Advances in Computational Intelligence. In Proceedings of the 17th International Work-Conference on Artificial Neural Networks, Ponta Delgada, Portugal, 19–21 June 2023; Springer: Cham, Switzerland, 2023; pp. 563–573. [Google Scholar]
- Rubin-Falcone, H.; Lee, J.; Wiens, J. Forecasting with sparse but informative variables: A case study in predicting blood glucose. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 9650–9657. [Google Scholar]
- Annuzzi, G.; Apicella, A.; Arpaia, P.; Bozzetto, L.; Criscuolo, S.; De Benedetto, E.; Pesola, M.; Prevete, R. Exploring Nutritional Influence on Blood Glucose Forecasting for Type 1 Diabetes Using Explainable AI. IEEE J. Biomed. Health Inform. 2024, 28, 3123–3133. [Google Scholar] [CrossRef]
- Della Cioppa, A.; De Falco, I.; Koutny, T.; Scafuri, U.; Ubl, M.; Tarantino, E. Reducing high-risk glucose forecasting errors by evolving interpretable models for Type 1 diabetes. ASC 2023, 134, 110012. [Google Scholar] [CrossRef]
- Shuvo, M.M.H.; Islam, S.K. Deep Multitask Learning by Stacked Long Short-Term Memory for Predicting Personalized Blood Glucose Concentration. IEEE J. Biomed. Health 2023, 27, 1612–1623. [Google Scholar] [CrossRef] [PubMed]
- Aliberti, A.; Pupillo, I.; Terna, S.; Macii, E.; Di Cataldo, S.; Patti, E.; Acquaviva, A. A Multi-Patient Data-Driven Approach to Blood Glucose Prediction. IEEE Access 2019, 7, 69311–69325. [Google Scholar] [CrossRef]
- Langarica, S.; Rodriguez-Fernandez, M.; Doyle, F.J., III; Núñez, F. A probabilistic approach to blood glucose prediction in type 1 diabetes under meal uncertainties. IEEE J. Biomed. Health Inform. 2023, 27, 5054–5065. [Google Scholar] [CrossRef]
- Zhu, T.; Li, K.; Herrero, P.; Georgiou, P. Personalized blood glucose prediction for type 1 diabetes using evidential deep learning and meta-learning. IEEE Trans. Biomed. Eng. 2022, 70, 193–204. [Google Scholar] [CrossRef] [PubMed]
- Butunoi, B.-P.; Stolojescu-Crisan, C.; Negru, V. Short-term glucose prediction in Type 1 Diabetes. Procedia Comput. Sci. 2024, 238, 41–48. [Google Scholar] [CrossRef]
- Martinsson, J.; Schliep, A.; Eliasson, B.; Mogren, O. Blood glucose prediction with variance estimation using recurrent neural networks. J. Healthc. Inform. Res. 2020, 4, 1–18. [Google Scholar] [CrossRef]
- Khanam, J.J.; Foo, S. A comparison of machine learning algorithms for diabetes prediction. ICT Express 2021, 7, 432–439. [Google Scholar] [CrossRef]
- Ahmed, U.; Issa, G.F.; Khan, M.A.; Aftab, S.; Khan, M.F.; Said, R.A.; Ghazal, T.M.; Ahmad, M. Prediction of diabetes empowered with fused machine learning. IEEE Access 2022, 10, 8529–8538. [Google Scholar] [CrossRef]
- Wang, S.; Chen, Y.; Cui, Z.; Lin, L.; Zong, Y. Diabetes Risk Analysis Based on Machine Learning LASSO Regression Model. J. Theory Pract. Eng. Sci. 2024, 4, 58–64. [Google Scholar]
- Feng, Y.; You, H.; Zhang, Z.; Ji, R.; Gao, Y. Hypergraph neural networks. Proc. AAAI Conf. Artif. Intell. 2019, 33, 3558–3565. [Google Scholar] [CrossRef]
- Diabetes Research in Children Network Study Group. The accuracy of the CGMS™ in children with type 1 diabetes: Results of the Diabetes Research in Children Network (DirecNet) accuracy study. Diabetes Technol. Ther. 2003, 5, 781–789. [Google Scholar] [CrossRef]
- Dubosson, F.; Ranvier, J.-E.; Bromuri, S.; Calbimonte, J.-P.; Ruiz, J.; Schumacher, M. The open D1NAMO dataset: A multi-modal dataset for research on non-invasive type 1 diabetes management. Inform. Med. Unlocked 2018, 13, 92–100. [Google Scholar] [CrossRef]
- Rickels, M.R.; DuBose, S.N.; Toschi, E.; Beck, R.W.; Verdejo, A.S.; Wolpert, H.; Cummins, M.J.; Newswanger, B.; Riddell, M.C.; T1D Exchange Mini-Dose Glucagon Exercise Study Group. Mini-Dose Glucagon as a Novel Approach to Prevent Exercise-Induced Hypoglycemia in Type 1 Diabetes. Diabetes Care 2018, 41, 1909–1916. [Google Scholar] [CrossRef] [PubMed]
- Sirlanci, M.; Levine, M.E.; Low Wang, C.C.; Albers, D.J.; Stuart, A.M. A simple modeling framework for prediction in the human glucose–insulin system. Chaos 2023, 33, 7. [Google Scholar] [CrossRef] [PubMed]
- Harleen, K.; Kumari, V. Predictive modelling and analytics for diabetes using a machine learning approach. Appl. Comput. Inform. 2022, 18, 90–100. [Google Scholar]
- Khadem, H.; Nemat, H.; Elliott, J.; Benaissa, M. Blood Glucose Level Time Series Forecasting: Nested Deep Ensemble Learning Lag Fusion. Bioengineering 2023, 10, 487. [Google Scholar] [CrossRef]
- De Bois, M.; Yacoubi, M.A.E.; Ammi, M. GLYFE: Review and benchmark of personalized glucose predictive models in type 1 diabetes. Med. Biol. Eng. Comput. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Li, K.; Daniels, J.; Liu, C.; Herrero, P.; Georgiou, P. Convolutional Recurrent Neural Networks for Glucose Prediction. IEEE J. Biomed. Health Inform. 2020, 24, 603–613. [Google Scholar] [CrossRef] [PubMed]
- Prendin, F.; Pavan, J.; Cappon, G.; Del Favero, S.; Sparacino, G.; Facchinetti, A. The importance of interpreting machine learning models for blood glucose prediction in diabetes: An analysis using SHAP. Sci. Rep. 2023, 13, 16865. [Google Scholar] [CrossRef] [PubMed]
- Langarica, S.; Rodriguez-Fernandez, M.; Núñez, F.; Doyle, F., III. Meta-learning approach to personalized blood glucose prediction in type 1 diabetes. Control Eng. Pract. 2023, 135, 105498. [Google Scholar] [CrossRef]
- Alhirmizy, S.; Qader, B. Multivariate time series forecasting with LSTM for Madrid, Spain pollution. In Proceedings of the 2019 International Conference on Computing and Information Science and Technology and Their Applications (ICCISTA), Kirkuk, Iraq, 3–5 March 2019; pp. 1–5. [Google Scholar]
- Widiputra, H.; Mailangkay, A.; Gautama, E.J.C. Multivariate CNN-LSTM Model for Multiple Parallel Financial Time-Series Prediction. Complexity 2021, 2021, 9903518. [Google Scholar] [CrossRef]
- Zerveas, G.; Jayaraman, S.; Patel, D.; Bhamidipaty, A.; Eickhoff, C. A transformer-based framework for multivariate time series representation learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Singapore, 14–18 August 2021; pp. 2114–2124. [Google Scholar]
- Yi, K.; Zhang, Q.; Fan, W.; He, H.; Hu, L.; Wang, P.; An, N.; Cao, L.; Niu, Z. FourierGNN: Rethinking multivariate time series forecasting from a pure graph perspective. arXiv 2024, arXiv:2311.06190. [Google Scholar]
- Han, H.; Zhang, M.; Hou, M.; Zhang, F.; Wang, Z.; Chen, E.; Wang, H.; Ma, J.; Liu, Q. STGCN: A spatial-temporal aware graph learning method for POI recommendation. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; pp. 1052–1057. [Google Scholar]
- Cirstea, R.-G.; Guo, C.; Yang, B. Graph Attention Recurrent Neural Networks for Correlated Time Series Forecasting–Full version. arXiv 2021, arXiv:2103.10760. [Google Scholar]
- Zhou, Z.; Huang, Q.; Lin, G.; Yang, K.; Bai, L.; Wang, Y. Greto: Remedying dynamic graph topology-task discordance via target homophily. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Zheng, G. A novel attention-based convolution neural network for human activity recognition. IEEE Sens. J. 2021, 21, 27015–27025. [Google Scholar] [CrossRef]
- Li, C.; Yang, H.; Cheng, L.; Huang, F.; Zhao, S.; Li, D.; Yan, R. Quantitative assessment of hand motor function for post-stroke rehabilitation based on HAGCN and multimodality fusion. IEEE Trans. Neural Syst. Rehabil. 2022, 30, 2032–2041. [Google Scholar] [CrossRef]
- Jiang, R.; Wang, Z.; Yong, J.; Jeph, P.; Chen, Q.; Kobayashi, Y.; Song, X.; Fukushima, S.; Suzumura, T. Spatio-temporal meta-graph learning for traffic forecasting. Proc. AAAI Conf. Artif. Intell. 2023, 37, 8078–8086. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 11106–11115. [Google Scholar]
- Chen, M.; Peng, H.; Fu, J.; Ling, H. Autoformer: Searching transformers for visual recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 12270–12280. [Google Scholar]
- Chen, P.; Zhang, Y.; Cheng, Y.; Shu, Y.; Wang, Y.; Wen, Q.; Yang, B.; Guo, C. Pathformer: Multi-scale transformers with adaptive pathways for time series forecasting. arXiv 2024, arXiv:2402.05956. [Google Scholar]
- Zhang, Y.; Yan, J. Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Liu, Y.; Hu, T.; Zhang, H.; Wu, H.; Wang, S.; Ma, L.; Long, M. itransformer: Inverted transformers are effective for time series forecasting. arXiv 2023, arXiv:2310.06625. [Google Scholar]
- Zhou, T.; Ma, Z.; Wen, Q.; Wang, X.; Sun, L.; Jin, R. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 27268–27286. [Google Scholar]
- Piao, X.; Chen, Z.; Murayama, T.; Matsubara, Y.; Sakurai, Y. Fredformer: Frequency Debiased Transformer for Time Series Forecasting. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; pp. 2400–2410. [Google Scholar]
- Kitaev, N.; Kaiser, Ł.; Levskaya, A. Reformer: The efficient transformer. arXiv 2020, arXiv:2001.04451. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef] [PubMed]
- Cai, W.; Liang, Y.; Liu, X.; Feng, J.; Wu, Y. Msgnet: Learning multi-scale inter-series correlations for multivariate time series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2024; pp. 11141–11149. [Google Scholar]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Chang, X.; Zhang, C. Connecting the dots: Multivariate time series forecasting with graph neural networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Virtual Event, CA, USA, 6–10 July 2020; pp. 753–763. [Google Scholar]
- Xu, N.; Kosma, C.; Vazirgiannis, M. TimeGNN: Temporal Dynamic Graph Learning for Time Series Forecasting. In Proceedings of the International Conference on Complex Networks and Their Applications, Menton Riviera, France, 28–30 November 2023; pp. 87–99. [Google Scholar]
- Han, L.; Chen, X.-Y.; Ye, H.-J.; Zhan, D.-C. SOFTS: Efficient Multivariate Time Series Forecasting with Series-Core Fusion. arXiv 2024, arXiv:2404.14197. [Google Scholar]
- Wu, H.; Hu, T.; Liu, Y.; Zhou, H.; Wang, J.; Long, M. Timesnet: Temporal 2D-variation modeling for general time series analysis. arXiv 2022, arXiv:2210.02186. [Google Scholar]
- Liu, Y.; Li, C.; Wang, J.; Long, M. Koopa: Learning non-stationary time series dynamics with koopman predictors. arXiv 2024, arXiv:2305.18803. [Google Scholar]
- Nie, Y.; Nguyen, N.H.; Sinthong, P.; Kalagnanam, J. A time series is worth 64 words: Long-term forecasting with transformers. arXiv 2022, arXiv:2211.14730. [Google Scholar]
- Huang, Q.; Shen, L.; Zhang, R.; Cheng, J.; Ding, S.; Zhou, Z.; Wang, Y. HDMixer: Hierarchical Dependency with Extendable Patch for Multivariate Time Series Forecasting. Proc. AAAI Conf. Artif. Intell. 2024, 38, 12608–12616. [Google Scholar] [CrossRef]
- Zeng, A.; Chen, M.; Zhang, L.; Xu, Q. Are transformers effective for time series forecasting? Proc. AAAI Conf. Artif. Intell. 2023, 37, 11121–11128. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| 15-min PH | 30-min PH | 60-min PH | 120-min PH | 180-min PH | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pt | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| 01 | 0.020 | 0.033 | 0.023 | 0.038 | 0.029 | 0.049 | 0.044 | 0.076 | 0.055 | 0.095 |
| 02 | 0.030 | 0.052 | 0.031 | 0.053 | 0.045 | 0.075 | 0.067 | 0.112 | 0.073 | 0.124 |
| 04 | 0.053 | 0.127 | 0.067 | 0.141 | 0.077 | 0.154 | 0.099 | 0.188 | 0.113 | 0.213 |
| 05 | 0.045 | 0.079 | 0.048 | 0.086 | 0.060 | 0.100 | 0.090 | 0.142 | 0.106 | 0.194 |
| 06 | 0.023 | 0.041 | 0.029 | 0.045 | 0.035 | 0.056 | 0.055 | 0.085 | 0.068 | 0.105 |
| 07 | 0.037 | 0.104 | 0.045 | 0.117 | 0.055 | 0.139 | 0.085 | 0.182 | 0.110 | 0.230 |
| 08 | 0.030 | 0.064 | 0.035 | 0.067 | 0.040 | 0.077 | 0.059 | 0.100 | 0.073 | 0.123 |
| 15-min PH | 30-min PH | 60-min PH | 120-min PH | 180-min PH | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pt | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| 01 | 0.027 | 0.036 | 0.036 | 0.050 | 0.060 | 0.089 | 0.113 | 0.148 | 0.128 | 0.183 |
| 02 | 0.021 | 0.036 | 0.031 | 0.050 | 0.073 | 0.115 | 0.133 | 0.203 | 0.170 | 0.248 |
| 04 | 0.033 | 0.046 | 0.038 | 0.054 | 0.092 | 0.129 | 0.137 | 0.175 | 0.161 | 0.194 |
| 05 | 0.051 | 0.068 | 0.068 | 0.088 | 0.113 | 0.153 | 0.248 | 0.292 | 0.264 | 0.327 |
| 06 | 0.013 | 0.018 | 0.034 | 0.048 | 0.039 | 0.056 | 0.075 | 0.100 | 0.111 | 0.134 |
| 07 | 0.031 | 0.035 | 0.026 | 0.037 | 0.044 | 0.062 | 0.076 | 0.101 | 0.109 | 0.132 |
| 08 | 0.030 | 0.041 | 0.031 | 0.041 | 0.081 | 0.101 | 0.121 | 0.145 | 0.161 | 0.184 |
| 15-min PH | 30-min PH | 60-min PH | 120-min PH | 180-min PH | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pt | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| 01 | 0.072 | 0.106 | 0.093 | 0.140 | 0.119 | 0.169 | 0.172 | 0.223 | 0.222 | 0.272 |
| 02 | 0.101 | 0.152 | 0.126 | 0.176 | 0.185 | 0.236 | 0.273 | 0.337 | 0.277 | 0.334 |
| 03 | 0.052 | 0.075 | 0.064 | 0.091 | 0.072 | 0.108 | 0.086 | 0.118 | 0.105 | 0.129 |
| 04 | 0.071 | 0.086 | 0.070 | 0.092 | 0.105 | 0.144 | 0.165 | 0.214 | 0.284 | 0.328 |
| 05 | 0.028 | 0.039 | 0.030 | 0.042 | 0.037 | 0.052 | 0.063 | 0.078 | 0.077 | 0.093 |
| 06 | 0.050 | 0.069 | 0.050 | 0.071 | 0.081 | 0.109 | 0.124 | 0.156 | 0.117 | 0.145 |
| 07 | 0.065 | 0.120 | 0.104 | 0.177 | 0.171 | 0.280 | 0.196 | 0.279 | 0.187 | 0.268 |
| 08 | 0.040 | 0.052 | 0.054 | 0.068 | 0.079 | 0.101 | 0.118 | 0.149 | 0.147 | 0.186 |
| 09 | 0.057 | 0.082 | 0.066 | 0.097 | 0.127 | 0.168 | 0.151 | 0.204 | 0.159 | 0.215 |
| 15-min PH | 30-min PH | 60-min PH | 120-min PH | 180-min PH | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pt | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| 01 | 0.024 | 0.038 | 0.032 | 0.053 | 0.048 | 0.091 | 0.076 | 0.125 | 0.087 | 0.150 |
| 02 | 0.021 | 0.028 | 0.036 | 0.050 | 0.062 | 0.085 | 0.072 | 0.100 | 0.068 | 0.083 |
| 03 | 0.034 | 0.055 | 0.038 | 0.056 | 0.050 | 0.067 | 0.078 | 0.098 | 0.089 | 0.110 |
| 04 | 0.078 | 0.094 | 0.096 | 0.122 | 0.174 | 0.223 | 0.303 | 0.365 | 0.243 | 0.302 |
| 05 | 0.045 | 0.063 | 0.060 | 0.084 | 0.094 | 0.123 | 0.178 | 0.222 | 0.190 | 0.232 |
| 06 | 0.018 | 0.024 | 0.024 | 0.033 | 0.050 | 0.061 | 0.124 | 0.156 | 0.185 | 0.231 |
| 07 | 0.036 | 0.048 | 0.051 | 0.069 | 0.092 | 0.124 | 0.148 | 0.191 | 0.189 | 0.234 |
| 08 | 0.022 | 0.028 | 0.041 | 0.049 | 0.055 | 0.071 | 0.091 | 0.112 | 0.080 | 0.101 |
| 09 | 0.037 | 0.054 | 0.058 | 0.084 | 0.092 | 0.126 | 0.134 | 0.175 | 0.115 | 0.149 |
| Methods | Ours | HDMixer | Pathformer | Informer | Crossformer | Koopa | ||||||
| Metric | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| 15 | 0.020 | 0.033 | 0.134 | 0.196 | 0.206 | 0.274 | 0.715 | 1.160 | 0.216 | 0.564 | 0.075 | 0.146 |
| 30 | 0.023 | 0.038 | 0.173 | 0.257 | 0.278 | 0.395 | 0.786 | 1.259 | 0.277 | 0.603 | 0.129 | 0.235 |
| 60 | 0.029 | 0.049 | 0.262 | 0.391 | 0.363 | 0.505 | 0.792 | 1.341 | 0.378 | 0.749 | 0.230 | 0.384 |
| 120 | 0.044 | 0.076 | 0.403 | 0.561 | 0.498 | 0.661 | 0.897 | 1.439 | 0.437 | 0.844 | 0.367 | 0.526 |
| 180 | 0.055 | 0.095 | 0.472 | 0.578 | 0.530 | 0.695 | 0.924 | 1.461 | 0.577 | 1.059 | 0.467 | 0.649 |
| Methods | TimesNet | iTransformer | MSGNet | SOFTS | Reformer | PatchTST | ||||||
| Metric | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| 15 | 0.117 | 0.277 | 0.058 | 0.111 | 0.120 | 0.273 | 0.082 | 0.125 | 0.664 | 1.102 | 0.053 | 0.101 |
| 30 | 0.130 | 0.291 | 0.103 | 0.171 | 0.127 | 0.283 | 0.130 | 0.201 | 0.706 | 1.190 | 0.097 | 0.161 |
| 60 | 0.147 | 0.319 | 0.196 | 0.318 | 0.150 | 0.318 | 0.214 | 0.331 | 0.799 | 1.363 | 0.190 | 0.297 |
| 120 | 0.177 | 0.374 | 0.355 | 0.512 | 0.180 | 0.359 | 0.357 | 0.499 | 0.865 | 1.422 | 0.329 | 0.468 |
| 180 | 0.202 | 0.419 | 0.460 | 0.617 | 0.196 | 0.387 | 0.436 | 0.573 | 0.884 | 1.449 | 0.419 | 0.556 |
| Methods | FEDformer | Autoformer | DLinear | Fredformer | MTGNN | TimeGNN | ||||||
| Metric | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| 15 | 0.162 | 0.339 | 0.263 | 0.396 | 0.144 | 0.264 | 0.117 | 0.176 | 2.355 | 3.814 | 3.497 | 4.776 |
| 30 | 0.180 | 0.356 | 0.270 | 0.421 | 0.191 | 0.332 | 0.160 | 0.242 | 2.733 | 4.161 | 3.662 | 4.935 |
| 60 | 0.177 | 0.377 | 0.251 | 0.428 | 0.244 | 0.421 | 0.265 | 0.390 | 3.315 | 4.684 | 3.872 | 5.220 |
| 120 | 0.174 | 0.388 | 0.244 | 0.435 | 0.348 | 0.595 | 0.405 | 0.554 | 3.778 | 5.138 | 3.879 | 5.262 |
| 180 | 0.200 | 0.423 | 0.276 | 0.486 | 0.433 | 0.739 | 0.352 | 0.445 | 3.833 | 4.893 | 3.858 | 4.921 |
| Methods | Ours | HDMixer | Pathformer | Informer | Crossformer | Koopa | ||||||
| Metric | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| 15 | 0.027 | 0.036 | 0.132 | 0.197 | 0.187 | 0.268 | 0.570 | 0.715 | 0.158 | 0.234 | 0.087 | 0.176 |
| 30 | 0.036 | 0.050 | 0.182 | 0.274 | 0.289 | 0.401 | 0.73 | 0.895 | 0.199 | 0.298 | 0.158 | 0.330 |
| 60 | 0.060 | 0.089 | 0.259 | 0.384 | 0.348 | 0.487 | 0.907 | 1.127 | 0.331 | 0.462 | 0.255 | 0.436 |
| 120 | 0.113 | 0.148 | 0.443 | 0.542 | 0.483 | 0.641 | 1.332 | 1.685 | 0.555 | 0.726 | 0.429 | 0.638 |
| 180 | 0.128 | 0.183 | 0.470 | 0.565 | 0.525 | 0.685 | 1.376 | 1.668 | 0.813 | 1.005 | 0.515 | 0.696 |
| Methods | TimesNet | iTransformer | MSGNet | SOFTS | Reformer | PatchTST | ||||||
| Metric | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| 15 | 0.057 | 0.118 | 0.058 | 0.111 | 0.060 | 0.106 | 0.082 | 0.125 | 0.573 | 0.713 | 0.053 | 0.101 |
| 30 | 0.102 | 0.189 | 0.103 | 0.171 | 0.103 | 0.171 | 0.130 | 0.201 | 0.627 | 0.797 | 0.097 | 0.161 |
| 60 | 0.193 | 0.316 | 0.196 | 0.318 | 0.194 | 0.309 | 0.213 | 0.331 | 0.823 | 1.048 | 0.190 | 0.297 |
| 120 | 0.349 | 0.534 | 0.355 | 0.512 | 0.339 | 0.493 | 0.356 | 0.499 | 0.956 | 1.172 | 0.329 | 0.468 |
| 180 | 0.436 | 0.633 | 0.460 | 0.617 | 0.427 | 0.591 | 0.436 | 0.573 | 1.176 | 1.438 | 0.419 | 0.556 |
| Methods | FEDformer | Autoformer | DLinear | Fredformer | MTGNN | TimeGNN | ||||||
| Metric | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| 15 | 0.242 | 0.388 | 0.320 | 0.470 | 0.217 | 0.278 | 0.109 | 0.162 | 0.522 | 0.781 | 2.475 | 3.249 |
| 30 | 0.272 | 0.414 | 0.394 | 0.567 | 0.267 | 0.345 | 0.165 | 0.247 | 1.157 | 1.578 | 3.524 | 4.572 |
| 60 | 0.316 | 0.494 | 0.376 | 0.554 | 0.382 | 0.485 | 0.284 | 0.418 | 2.212 | 2.790 | 4.675 | 5.968 |
| 120 | 0.410 | 0.618 | 0.419 | 0.605 | 0.602 | 0.760 | 0.403 | 0.561 | 3.793 | 4.712 | 5.435 | 6.867 |
| 180 | 0.318 | 0.596 | 0.403 | 0.613 | 0.772 | 0.967 | 0.370 | 0.454 | 4.108 | 5.003 | 5.249 | 6.688 |
| Methods | Ours | HDMixer | Pathformer | Informer | Crossformer | Koopa | ||||||
| Metric | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| 15 | 0.072 | 0.106 | 0.412 | 0.583 | 0.468 | 0.678 | 0.485 | 0.660 | 0.206 | 0.325 | 0.347 | 0.604 |
| 30 | 0.093 | 0.140 | 0.550 | 0.732 | 0.606 | 0.829 | 0.675 | 0.933 | 0.335 | 0.487 | 0.492 | 0.763 |
| 60 | 0.119 | 0.169 | 0.664 | 0.876 | 0.781 | 1.018 | 0.972 | 1.254 | 0.578 | 0.801 | 0.729 | 0.943 |
| 120 | 0.172 | 0.223 | 0.815 | 1.079 | 0.942 | 1.214 | 1.204 | 1.540 | 0.745 | 0.995 | 0.830 | 1.138 |
| 180 | 0.222 | 0.272 | 0.950 | 1.244 | 1.121 | 1.420 | 1.307 | 1.669 | 0.939 | 1.228 | 0.954 | 1.261 |
| Methods | TimesNet | iTransformer | MSGNet | SOFTS | Reformer | PatchTST | ||||||
| Metric | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| 15 | 0.310 | 0.486 | 0.318 | 0.479 | 0.297 | 0.480 | 0.315 | 0.503 | 0.518 | 0.698 | 0.273 | 0.462 |
| 30 | 0.420 | 0.657 | 0.393 | 0.611 | 0.428 | 0.618 | 0.426 | 0.645 | 0.657 | 0.864 | 0.399 | 0.594 |
| 60 | 0.597 | 0.807 | 0.598 | 0.804 | 0.591 | 0.795 | 0.621 | 0.858 | 0.901 | 1.154 | 0.546 | 0.767 |
| 120 | 0.740 | 1.031 | 0.724 | 0.998 | 0.739 | 1.020 | 0.796 | 1.055 | 1.140 | 1.451 | 0.725 | 0.997 |
| 180 | 0.888 | 1.207 | 0.879 | 1.183 | 0.905 | 1.208 | 0.956 | 1.240 | 1.098 | 1.400 | 0.868 | 1.182 |
| Methods | FEDformer | Autoformer | DLinear | Fredformer | MTGNN | TimeGNN | ||||||
| Metric | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| 15 | 0.577 | 0.755 | 0.498 | 0.676 | 0.364 | 0.494 | 0.208 | 0.287 | 1.068 | 1.514 | 2.892 | 3.737 |
| 30 | 0.731 | 0.913 | 0.657 | 0.876 | 0.448 | 0.613 | 0.313 | 0.434 | 1.994 | 2.638 | 3.914 | 5.028 |
| 60 | 0.848 | 1.061 | 0.904 | 1.143 | 0.579 | 0.790 | 0.519 | 0.675 | 3.166 | 4.035 | 4.689 | 6.028 |
| 120 | 0.977 | 1.241 | 1.011 | 1.295 | 0.743 | 1.002 | 0.663 | 0.882 | 4.288 | 5.457 | 5.122 | 6.505 |
| 180 | 1.029 | 1.303 | 1.074 | 1.361 | 0.837 | 1.112 | 0.837 | 1.074 | 4.666 | 5.954 | 5.143 | 6.582 |
| Methods | Ours | HDMixer | Pathformer | Informer | Crossformer | Koopa | ||||||
| Metric | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| 15 | 0.037 | 0.054 | 0.205 | 0.304 | 0.489 | 0.687 | 0.834 | 1.150 | 0.166 | 0.320 | 0.158 | 0.246 |
| 30 | 0.058 | 0.084 | 0.288 | 0.431 | 0.555 | 0.782 | 0.852 | 1.159 | 0.274 | 0.453 | 0.252 | 0.385 |
| 60 | 0.092 | 0.126 | 0.422 | 0.623 | 0.620 | 0.862 | 0.851 | 1.187 | 0.470 | 0.726 | 0.460 | 0.669 |
| 120 | 0.134 | 0.175 | 0.605 | 0.883 | 0.727 | 0.999 | 0.886 | 1.212 | 0.645 | 0.973 | 0.653 | 0.930 |
| 180 | 0.115 | 0.149 | 0.711 | 1.031 | 0.816 | 1.126 | 0.866 | 1.222 | 0.744 | 1.068 | 0.744 | 1.072 |
| Methods | TimesNet | iTransformer | MSGNet | SOFTS | Reformer | PatchTST | ||||||
| Metric | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| 15 | 0.614 | 0.858 | 0.119 | 0.194 | 0.179 | 0.264 | 0.118 | 0.191 | 0.827 | 1.156 | 0.126 | 0.200 |
| 30 | 0.644 | 0.902 | 0.203 | 0.325 | 0.264 | 0.393 | 0.215 | 0.337 | 0.858 | 1.161 | 0.204 | 0.321 |
| 60 | 0.712 | 0.987 | 0.354 | 0.549 | 0.420 | 0.620 | 0.365 | 0.560 | 0.837 | 1.196 | 0.349 | 0.539 |
| 120 | 0.793 | 1.100 | 0.560 | 0.830 | 0.617 | 0.902 | 0.569 | 0.845 | 0.868 | 1.189 | 0.550 | 0.818 |
| 180 | 0.851 | 1.188 | 0.681 | 0.998 | 0.745 | 1.079 | 0.689 | 1.007 | 0.889 | 1.213 | 0.668 | 0.980 |
| Methods | FEDformer | Autoformer | DLinear | Fredformer | MTGNN | TimeGNN | ||||||
| Metric | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| 15 | 0.630 | 0.844 | 0.392 | 0.533 | 0.277 | 0.365 | 0.161 | 0.240 | 0.630 | 0.957 | 1.591 | 2.170 |
| 30 | 0.680 | 0.909 | 0.468 | 0.635 | 0.363 | 0.480 | 0.248 | 0.369 | 1.234 | 1.719 | 2.249 | 3.388 |
| 60 | 0.716 | 0.981 | 0.567 | 0.784 | 0.487 | 0.660 | 0.377 | 0.562 | 2.202 | 2.912 | 3.173 | 4.294 |
| 120 | 0.808 | 1.125 | 0.760 | 1.061 | 0.634 | 0.875 | 0.566 | 0.820 | 3.064 | 4.109 | 3.370 | 4.496 |
| 180 | 0.857 | 1.208 | 0.884 | 1.217 | 0.708 | 0.987 | 0.660 | 0.941 | 3.198 | 4.308 | 3.323 | 4.359 |
| Method | Ours | Fredformer | SOFTS | Autoformer | FEDformer | DLinear | Crossformer | iTransformer | Informer |
| Params (M) | 0.66 | 8.73 | 1.71 | 1.46 | 1.46 | 7.80 × | 6.61 | 0.80 | 1.66 |
| AvgIT (ms) | 9.20 | 0.02 | 0.05 | 4.74 | 24.00 | 1.16 | 4.78 | 1.02 | 5.50 |
| FLOPs (M) | 59.50 | 1442.07 | 17.13 | 8.76 | 8.77 | 1.76 × | 30.49 | 8.07 | 9.40 |
| Method | Koopa | PatchTST | Reformer | TimesNet | TimeGNN | MTGNN | HDMixer | Pathformer | MSGNet |
| Params (M) | 0.19 | 0.80 | 0.67 | 286.05 | 0.02 | 0.33 | 0.02 | 0.54 | 0.98 |
| AvgIT (ms) | 5.41 | 0.99 | 0.84 | 25.20 | 8.97 | 9.21 | 8.82 × | 1.85 | 9.47 |
| FLOPs (M) | 0.91 | 3.99 | 11.00 | 6223.16 | 3.21 | 45.84 | 1.67 | 7.20 | 55.45 |
| Dataset | D1NAMO-1 | D1NAMO-2 | DirecNet | T1DExchange | ||||
|---|---|---|---|---|---|---|---|---|
| Metric | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| Baseline | 0.083 | 0.149 | 0.070 | 0.093 | 0.199 | 0.230 | 0.040 | 0.060 |
| W/O SSE | 0.019 | 0.030 | 0.031 | 0.043 | 0.079 | 0.117 | 0.021 | 0.033 |
| W/O FCK | 0.019 | 0.032 | 0.032 | 0.045 | 0.080 | 0.119 | 0.037 | 0.043 |
| W/O GAA | 0.019 | 0.030 | 0.027 | 0.036 | 0.077 | 0.119 | 0.026 | 0.039 |
| NLAGNN | 0.018 | 0.029 | 0.025 | 0.034 | 0.072 | 0.106 | 0.018 | 0.024 |
| Dataset | PH | A + B | C + D + E |
|---|---|---|---|
| D1NAMO-1 | 15 | 87.48 + 12.52% | 0 |
| 30 | 83.62 + 16.29% | 00.09% | |
| D1NAMO-2 | 15 | 96.01 + 03.99% | 0 |
| 30 | 93.27 + 06.73% | 0 | |
| DirecNet | 15 | 93.43 + 06.57% | 0 |
| 30 | 80.35 + 19.09% | 00.56% | |
| T1DExchange | 15 | 95.80 + 04.14% | 00.06% |
| 30 | 88.97 + 10.90% | 00.13% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Jiang, X.; Wang, K. Dynamic Partitioning of Graphs Based on Multivariate Blood Glucose Data—A Graph Neural Network Model for Diabetes Prediction. Electronics 2024, 13, 3727. https://doi.org/10.3390/electronics13183727
Li J, Jiang X, Wang K. Dynamic Partitioning of Graphs Based on Multivariate Blood Glucose Data—A Graph Neural Network Model for Diabetes Prediction. Electronics. 2024; 13(18):3727. https://doi.org/10.3390/electronics13183727
Chicago/Turabian StyleLi, Jianjun, Xiaozhe Jiang, and Kaiyue Wang. 2024. "Dynamic Partitioning of Graphs Based on Multivariate Blood Glucose Data—A Graph Neural Network Model for Diabetes Prediction" Electronics 13, no. 18: 3727. https://doi.org/10.3390/electronics13183727
APA StyleLi, J., Jiang, X., & Wang, K. (2024). Dynamic Partitioning of Graphs Based on Multivariate Blood Glucose Data—A Graph Neural Network Model for Diabetes Prediction. Electronics, 13(18), 3727. https://doi.org/10.3390/electronics13183727