Abstract
Existing approaches for image deraining often rely on synthetic or unpaired real-world rainy datasets, leading to sub-optimal generalization ability when processing the complex and diverse real-world rain degradation. To address these challenges, we propose a novel iterative semantic-guided detail fusion model with implicit neural representations (INR-ISDF). This approach addresses the challenges of complex solution domain variations, reducing the usual negative impacts found in these situations. Firstly, the input rainy images are processed through implicit neural representations (INRs) to obtain normalized images. Residual calculations are then used to assess the illumination inconsistency caused by rain degradation, thereby enabling an accurate identification of the degradation locations. Subsequently, the location information is incorporated into the detail branch of the dual-branch architecture, while the normalized images obtained from the INR are used to enhance semantic processing. Finally, we use semantic clues to iteratively guide the progressive fusion of details to achieve improved image processing results. To tackle the partial correspondence between real rain images and the given ground truth, we propose a two-stage training strategy that utilizes adjustments in the semantic loss function coefficients and phased freezing of the detail branch to prevent potential overfitting issues. Extensive experiments verify the effectiveness of our proposed method in eliminating the degradation in real-world rainy images.
1. Introduction
Images captured in outdoor rainy conditions often suffer from various forms of degradation, such as raindrops, rain streaks, and fog. These degradations pose significant obstacles to subsequent image processing tasks [1,2,3]. Convolutional neural networks (CNNs) have significantly advanced the field of a broad spectrum of image processing tasks [4], notably including image deraining [5,6,7,8,9], ushering in an era marked by unprecedented efficiency, speed, and automation.
Due to the potential presence of multi-scale degradation in images, some approaches employ cross-scale and fusion methods [10,11] to capture and utilize features of different scales. The Laplacian pyramid is also widely applied to explore multi-scale features [12,13]. However, convolution-based approaches frequently face challenges in effectively modeling the complex interactions among widely distributed but interconnected degradations. This limitation is primarily due to the constrained receptive field of convolutional kernels, which hampers their capacity to capture long-range dependencies [14]. Recent studies [15,16] have employed deeper network architectures or operations similar to dilated convolutions to expand the receptive field. Nevertheless, these approaches often only add to the network’s complexity without effectively establishing cross-scale long-range feature connections, which can increase the risk of overfitting [17].
To overcome these limitations and better manage multitasking recovery, transformers, which are capable of establishing long-range dependencies, have shown remarkable results [18,19,20,21,22]. In the context of multitask rain removal, structural search [23] has been employed to identify potentially optimal model architectures for various types of degradation. However, pre-designed limited structures often struggle to handle the diverse types of degradation effectively. Other studies have leveraged uncertainty [20,24] to enhance the identification of raindrop locations in rainy images. For instance, a sparse sampling transformer with uncertainty-driven ranking [20] can selectively focus on key positions in the image. These methods do not directly address the fitting of degradation locations and lack a specific focus on restoring the original semantic information in the image, leading to suboptimal performance when dealing with variable forms of degradation. Additionally, obtaining pairwise images from real scenes for training is challenging in these approaches. Consequently, most researchers rely on synthetic rain maps to facilitate training. The advantage of this approach is the ease of acquiring fully matched pairwise images for loss computation, enabling straightforward pixel-by-pixel comparisons. However, it has notable drawbacks:
- The degradation forms, shapes, and distributions of synthetic rain maps are significantly less diverse and complex than those found in real rain maps. As a result, networks trained on synthetic data often exhibit reduced robustness when faced with actual rain conditions.
- Pixel-by-pixel comparisons between the output image and ground truth tend to cause overfitting, preventing the network from effectively learning the degradation patterns and semantic information inherent in real scenes.
To address the limitations associated with overly simplistic degradation patterns in synthetic maps, Zhang et al. [25] developed the paired dataset JRSRD-real, which consists of real rain maps to mitigate the inaccuracies introduced by artificial rain lines and raindrops. This approach is designed to improve the network’s generalization capability and enhance its performance in real-world scenarios. However, when comparing synthetic maps with real images, differences in lighting, shadows, and local details, arising from temporal disparities between the images, are inevitable. These discrepancies can introduce representation deviations.
To address the issues of incomplete matching in real images and domain deviation caused by various degradations, we propose a iterative semantic-guided detail fusion model named INR-ISDF. The description of our algorithmic process is as follows: Firstly, we leverage implicit neural representation (INR) to obtain a normalized output, enhancing the model’s capability to handle diverse degradations encountered in practical scenarios. Next, we assess the disparity between the input image and the neurally fitted image, serving as a crucial reference for the spatial region-enhanced attention mask, which in turn guides the input weights of the detail branch more effectively. Subsequently, we perform semantic and detail extraction at three scales, applying semantic-aware loss functions to regulate the performance of the semantic extraction process. This approach encourage the semantic branch to isolate and extract semantic information free from degradation, comparing its outputs with those obtained from real images using an identical semantic extraction framework. During the fusion phase, iterative semantic information guides the progressive integration of details, thereby ensuring the recovery quality of image details. Finally, a unified decoder is employed to obtain multi-scale residuals of the restored image, with these multi-scale processing results contributing to the loss constraints.
The contributions of this paper are as follows:
- (1)
- We utilize neural representations to obtain normalized degraded images and measure the gap between the fitted and original images to derive a degradation position indication matrix that guides detail extraction.
- (2)
- A semantic loss function is computed using a specialized semantic information extraction branch, which is designed to better capture partially obscured semantic information within the image content.
- (3)
- An iterative semantic-guided detail fusion module that progressively introduces details guided by the inherent information within the image itself, facilitating detail integration.
- (4)
- We present an effective training strategy for handling imperfectly matched real images, leveraging the semantic loss function and freezing the detail branch to prevent overfitting issues that may arise from pixel-wise comparisons.
2. Related Work
2.1. Single Image Deraining
Single-image deraining is both a significant and challenging problem. Early traditional algorithms [26,27] addressed rain-induced image degradation by leveraging prior knowledge. However, these priors often relied on specific assumptions, limiting the ability of traditional methods to handle complex real-world scenarios [17,28,29].
In recent years, learning-based methods have achieved superior results compared with traditional algorithms for single-image rain removal. Recognizing the uncertainty in raindrop positions within real rain images, Shao et al. [24] incorporated uncertainty modeling to enhance raindrop removal. In the same year, Quan et al. [23] presented an attention-based framework that simultaneously addresses rain streaks and raindrops. To adapt to the differences between these two types of degradation, Quan et al. employed an adaptive architecture search to find the optimal structure. Chen et al. [20] leveraged uncertainty-driven sparse sampling transformers to concurrently address raindrop and rain line artifacts. Sparse sampling, a technique that selectively attends to critical locations within the image, not only reduces the network’s parameters but also enhances focus on areas prone to degradation. Meanwhile, Chen et al. [30] incorporated a learnable top-k selection operator, which retains the most salient features within the transformer’s query, enabling superior feature aggregation. Recently, Chen et al. [22] introduced a multi-scale, end-to-end transformer architecture that harnesses the power of multi-scale representations through a closed-loop bidirectional operation. This approach optimizes the utilization of information across various scales, effectively capturing degradation patterns. However, a commonality among these methods lies in their primary focus on simulating degradation and targeting uncertain degradation locations, often overlooking the restoration of stable semantic information.
In this paper, we explore the unexplored potential of utilizing the transformer’s inherent flexibility in representing multi-scale features to extract and harness semantic information. We propose a novel approach that marries the degraded features with semantic cues, aiming to enhance the overall performance of rain removal techniques while preserving crucial semantic details.
2.2. Transformer and Attention
Inspired by the remarkable achievements of Transformer in natural language processing (NLP) and advanced visual tasks [31,32,33], Transformer has also gained widespread adoption in the field of image restoration [20,30,34] due to its flexibility and its ability to serve as a communication tool that attends to information across spatial dimensions. Among the various approaches for image deraining, techniques such as information sparsification [20], extraction of the top-k most salient features [30], and end-to-end multi-scale collaborative representation [22] have emerged as promising directions. These methods prioritize retaining the most crucial information while minimizing the number of parameters required, aiming to achieve a balance between performance and efficiency. Typically, weights are optimized through learning procedures, and the required parameters are selectively chosen through sorting mechanisms. On this basis, we utilize the brightness variation differences induced by implicit neural representations to derive pixel-level masks. This approach enables precise sorting and facilitates the acquisition of pixel-level masks that serve as learning references during the normalization process, ultimately enhancing the effectiveness of image deraining.
2.3. Neural Representation for Image Restoration
Implicit neural representations, a novel and robust technology, represent continuous signals using coordinate-based multi-layer perceptrons (MLPs). In image processing tasks, they are utilized to describe images and have been widely applied in areas such as image compression [35], 3D image tasks [36,37], and video processing [38,39]. Recently, in image restoration, Chen et al. [22] employed implicit neural representations to improve the continuous function representation of common rain degradation effects. Furthermore, Yang et al. [40] utilized the controllable fitting capabilities of implicit neural representations to address the challenge of low-light image enhancement. Building on these advancements, our model leverages the normalization characteristics of neural representations in terms of brightness [40] to identify potential attention regions and extract semantic information from these regions.
3. Proposed Method
3.1. Architecture
The structure of our INR-ISDF is depicted in Figure 1. Given a naturally rain-degraded image as input, the first step involves performing implicit neural representation, computing the difference and score between the normalized output and the real rainy image to obtain a degradation location mask. In the second step, a dual-branch structure is employed to separately extract detail and semantic information, with the semantic information guiding the progressive integration of detail information for comprehensive feature fusion. The third step involves decoding the features and connecting them with the residual of the input rainy image to produce the final clean image.
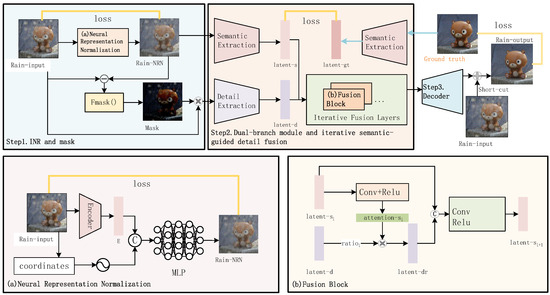
Figure 1.
The overview of our INR-ISDF network, which includes three main steps. Step1. Implicit neural representation and mask extraction. Step2. Dual-branch structure and semantic information-guided detail feature fusion. Step3. Decoding output.
3.2. Mask Based on Implicit Neural Representations
Motivation. Images captured under genuine rainy conditions inherently exhibit a mixture of various degradations, which are particularly characterized by differing luminance distributions. As shown in Figure 2, this phenomenon is evident in the luminance channel of rainy images, displaying distinct distribution patterns corresponding to different types of degradations. The distribution positions of these diverse degradations tend to approximate randomness, presenting a challenge for processing within a unified framework. Drawing inspiration from Yang et al. [40], our experimental results reveal that utilizing implicit neural representations (INRs) not only normalizes luminance deviations across image sets but also harmonizes luminance variations within different degradation regions of individual images. Consequently, we have developed a modified version of INR (illustrated in Figure 1) as a preliminary normalization strategy, aimed at addressing luminance inconsistencies arising from multiple degradation sources.
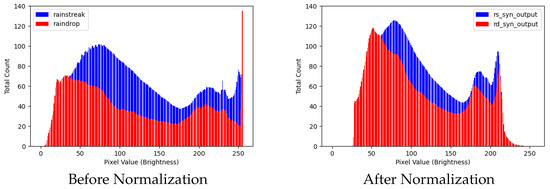
Figure 2.
Comparision of pixel value distributions in the Y channel of multiple degraded rainy images before (left) and after INR normalization (right). The degraded rainy image samples are sourced from the RainDS dataset [23] and include both rain streak and raindrop degradations. It is evident that after INR normalization, the luminance disparities have been somewhat normalized.
We perform preliminary feature extraction on the input degraded image to obtain a feature map , where H and W denote the image resolution. The coordinate information of the image is represented as , with 2 indicating the horizontal and vertical coordinates. Leveraging both features and coordinate information to represent the degraded image D, as depicted in the neural representation module of Figure 1, we fuse the coordinates and features through a multi-layer perceptron (MLP) to output the image, formulated as follows:
where represents the pixel position, and is the fitted RGB value of the degraded image at that position.
Spatial Region Enhancement Attention Mask. Distinct from [40], we further exploit the results of the implicit neural representation by translating the implicit brightness suppression process into an explicit spatial distribution, thereby guiding the model to acquire precise location masks of degradations. We compute , representing the absolute difference between the normalized result and the original degraded image. To derive the attention mask, we employ a nonlinear scoring method, where a predefined hyperparameter is used to select positions with large discrepancies, assigning a value of 1 to the mask at those locations. Specifically, the calculation is as follows:
where represents a learnable variance parameter and denotes the computed discrepancy score. is subsequently derived from the , serving as a spatial regional attention mask that facilitates the network to focus more intently on potential degraded areas. The visualization of the intermediate attention outputs during the testing process is presented in Figure 3. It can be observed that the degradation of raindrops and rain streaks attains higher attention.

Figure 3.
The visualization of intermediate results of the attention mask on the RainDS-real [23].
3.3. Iterative Semantic-Guided Detail Fusion Module
As depicted in Figure 1, the proposed module features a dual-path structure, comprising concurrent semantic and detail branches, both adhering to a consistent multi-scale framework. The semantic branch ingests the , which has undergone neural representation-based luminance normalization, while the detail branch processes the original input image , enhanced with the to emphasize intricate features:
To effectively integrate the features derived from the semantic and detail branches, namely and , we devise an iterative process guided by semantic information, incrementally incorporating a greater proportion of detail features in each iteration. This iterative fusion process is illustrated in the Figure 1.
During the first iteration, the output of the semantic branch serves as a guiding signal. For the semantic guidance at the iteration, we compute a channel attention map , which subsequently modulates the detail features, yielding a weighted contribution:
where denotes the scaling factor for the current iteration. The original semantic guidance is then concatenated with the weighted detail features ; and a standard convolutional module, utilizing a combination of convolutional and related operations (including ReLU activation and a final sigmoid activation), to produce the updated semantic guidance for the next iteration:
In this manner, we progressively enhance the utilization of detail information by incrementally increasing the attributed to the detail branch. Furthermore, we conduct experiments investigating the influence of iteration count on the fusion outcome, with the detailed results being presented in Section 4.
3.4. Loss Function
Our INR-ISDF calculates semantic loss and fitting loss to leverage the controllable fitting capability of INR. The overall loss function of the network is defined as follows:
where represents the ground truth and represents the predicted result corresponding to the ground truth. calculates the L1 loss between and . calculates the semantic perceptual loss between the input rainy image and the original image, specifically defined as follows:
which quantifies the difference between the semantic representations extracted by the model’s semantic branch during inference on the rainy image and the corresponding representations when the ground truth image is fed into the same branch.
4. Experiments
4.1. Implementation Specifications
Our model is trained on an NVIDIA GeForce RTX 4060 GPU with a total of 2000 epochs, utilizing input images cropped to a resolution of pixels. The network architecture comprises a 3-level encoder-decoder structure, where each level possesses a channel depth of 16, 32, and 64, respectively, processing patches with edge lengths of 128, 64, and 32. The hidden layer iterations are set to 3, and the hyperparameter for mask computation is tuned to 0.6. The loss function incorporates sparsity terms with and values of 0.3 and 0.5, respectively.
To manage the learning rate, we employ the Adam optimizer with an initial learning rate of 0.0007, which gradually decays to through a cosine annealing schedule. Data augmentation techniques, including random rotation and horizontal flipping, are applied to enrich the dataset and enhance the model’s performance.
The training strategy for real-world datasets. Given the fact that paired images in real-world datasets do not perfectly match pixel-by-pixel, we leverage the dual-branch architecture of our proposed INR-ISDF algorithm. In the initial 1500 epochs, we leverage a synthetic dataset to refine the detail-oriented branch, where the pixel-wise comparison loss function is employed to achieve precise detail matching. Subsequently, for the remaining 500 epochs, we switch to the real-world dataset, where we freeze the detail-oriented branches and instead concentrate on fine-tuning the model using semantically relevant loss functions. To support this approach, we adjust the hyperparameters, setting the coefficient for the semantic loss function to 0.5 during the first 1500 epochs and increasing it to 1 for the final 500 epochs.
4.2. Datasets
4.2.1. RainDS
The RainDS dataset [23] encompasses both synthetic and real-world images. Each subset comprises paired images with three degradation combinations: rain streaks only, raindrops only, and a mixture of both. Specifically, RainDS-Syn contains 3600 image pairs, of which 3000 are utilized for network training, while the remaining 600 pairs are reserved for testing. RainDS-Real, on the other hand, comprises 750 image pairs, with 450 used for training and 300 for testing purposes.
4.2.2. Real-World Rainy Images Dataset
The Real-World Rainy Images Dataset [41] features high diversity in image content, rain intensity, direction, and other factors. This dataset includes a total of 50 images and is used exclusively for testing purposes.
4.2.3. RSDV
RSVD dataset [42] employs Unreal Engine and video enhancement techniques to create realistic and diverse snowy and foggy images. This dataset comprises 80 training videos and 30 testing videos, with each set containing anywhere from 30 to 200 video frames. A subset of image pairs from these scenes has been carefully selected for training and testing purposes, with 5786 image pairs allocated to the training dataset and 266 image pairs designated for the testing dataset.
4.2.4. RainDS-Low-Light
To further evaluate the model’s genuine deraining capability under varying lighting conditions or camera sensitivity settings, we simulated different intensities of low-light scenarios on the previously mentioned RainDS-real dataset [23], resulting in our RainDS-low-light dataset. Specifically, we applied gamma transformation and linear scaling to the rainy images to simulate low-light conditions, with gamma adjustment values being set to 0.5, 0.6, 0.7, and 0.8. Our RainDS-low-light dataset comprises 600 image pairs for training and 392 image pairs for testing.
4.3. Comparisons to Existing Methods
Table 1 presents the results of the comparative experiments. Our INR-ISDF demonstrates exceptional performance in terms of both peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM) on both the RainDS-syn and RainDS-real datasets. Notably, our method exhibits a more significant improvement in real-world images compared with synthetic ones, demonstrating that our network is tailored to address more realistic rainy weather degradations.

Table 1.
Comparison of image deraining results on the RainDS datasets [23]. All model-based algorithms have been retrained under the same conditions. Our proposed INR-ISDF method achieves the top performance, showcasing a substantial improvement over existing approaches in addressing real-world rainy scenarios.
Furthermore, we provide the visual comparisons on the RainDS-real dataset [23], including DRSformer [30], GT-Rain [45], NAFNet [46], NeRD-Rain [22], Restormer [19], UDR-Former [20], and our INR-ISDF approach in Figure 4 and Figure 5. It can be observed that our proposed method reconstructs rain-free images with the lowest error compared with the other methods.

Figure 4.
Visual comparison of real-world rain image restoration on RainDS-real [23], including using NeRD-Rain [22], Restormer [19], UDR-Former [20], and our proposed INR-ISDF. The left column displays the unprocessed rainy images, while the right column presents the corresponding ground truth.

Figure 5.
Visual comparison of real-world rain image restoration on RainDS-real [23], including using DRSformer [30], GT-Rain [45], NAFNet [46], and our proposed INR-ISDF. The left column displays the unprocessed rainy images, while the right column presents the corresponding ground truth.
To validate the performance of our network on real-world rainy images, we conducted tests using the unpaired Real-World Rainy Images Dataset [41]. As depicted in Figure 6, the visual outcomes clearly demonstrate that our network outperforms other state-of-the-art methods in terms of rain removal while preserving finer details and color fidelity when processing real rainy images.

Figure 6.
Visual comparison of the Real-World Rainy Images Dataset [41], including NAFNet [46], NeRD-Rain [22], Restormer [19], UDR-Former [20], and our proposed INR-ISDF method. The left column displays the unprocessed rainy images.
In addition, to validate the robustness and scalability of the proposed INR-ISDF algorithm, we conducted experiments on both the RSVD dataset [42] and the RainDS-low-light dataset, which we constructed based on the RainDS dataset [23]. Figure 7 and Figure 8 present visual exemplars that demonstrate the algorithm’s performance in challenging environments. Additionally, Table 2 showcases the quantitative results of our INR-ISDF algorithm compared with the state-of-the-art, evaluated on the RSVD dataset. These tests demonstrate the algorithm’s capability to effectively handle diverse and demanding visual inputs.

Figure 7.
Visual examples showcasing the effectiveness of our INR-ISDF method on the RainDS-low-light dataset, which is derived from the RainDS dataset [23]. The odd-numbered rows display the original degraded images. The even-numbered rows present the corresponding results achieved by our INR-ISDF method.

Figure 8.
Visual examples showcasing the effectiveness of our INR-ISDF method on the RSVD snowy dataset [42]. The odd-numbered rows display the original degraded images. The even-numbered rows present the corresponding results achieved by our INR-ISDF method.
Table 2.
Comparison of image desnowing results on the RSVD dataset [42].
4.4. Ablation Studies
Table 3 demonstrates the impact of the number of iterations for the INR module, mask operation, and recurrent iteration module on the network performance. The results of the ground truth image are presented on the right side of Table 3, while the visual representation is showcased in Figure 9. Table 4 presents the impact of our specific design choices in loss functions on network performance. Ablation experiments were conducted on the RainDS-real dataset by individually setting the coefficients for , for , and both and to zero. These experiments elucidate the individual contributions of each loss component to the overall performance. Analysis of the experimental results reveals that the proposed components and loss function significantly enhance the restoration of real-world images.
Table 3.
Ablation study of the individual components. Every proposed component plays an indispensable role in real-world rainy image restoration.

Figure 9.
Visual comparison of real-world rain image restoration on RainDS-real [23]. The sequence from left to right showcases the rain-image, baseline, integration of three IF-Block modules, enhancement with an INR module, our proposed INR-ISDF (INR + IF-Block × 3), and ground truth.
Table 4.
Ablation study of the and .
Furthermore, we conducted experiments with iteration counts ranging from 0 to 6. When the iteration count is 0, dimension matching is directly achieved through concatenation and dimensionality reduction operations. The experimental results on the RainDS-real dataset, as illustrated in Figure 10, demonstrate that the utilization of semantic features by the iterative module attains an overall optimal performance at three iterations. Notably, excessive iterations may lead to the loss of semantic information, underscoring the indispensability of semantic information for image restoration.
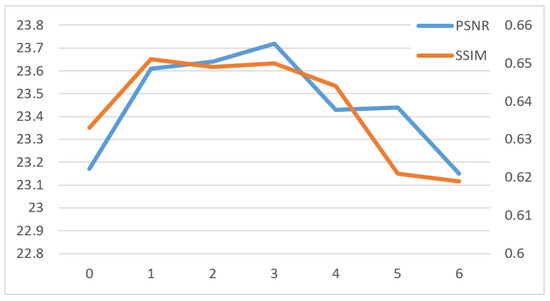
Figure 10.
Image restoration results from 0 to 6 iterations, with iterations indicated on the horizontal axis. The left vertical axis (blue curve) represents the peak signal-to-noise ratio (PSNR), which peaks at iteration 3. The right vertical axis (orange curve) denotes the structural similarity index measure (SSIM), which achieves its best score at iteration 1.
5. Conclusions
In this work, our proposed INR-ISDF approach innovatively harnesses the controllable fitting capabilities of INR to provide normalization effects and positioning references for various types of rain degradation. Through the iterative fusion of detail and semantic branches, we uncover relatively definitive semantic information amidst the uncertain degradation fitting, thereby guiding the restoration of image quality to a superior level. Extensive experiments conducted on multiple real-world rain image datasets demonstrate that the INR-ISDF method outperforms state-of-the-art methods in its performance within these authentic datasets. Despite its effectiveness, the model struggles with maintaining detail and color recovery under low-light and extreme rain conditions and has real-time processing limitations due to Transformer complexity. Future work will focus on expanding data diversity with semi-supervised learning and optimizing the network for real-time efficiency.
Author Contributions
Conceptualization, Z.W. and L.X.; methodology, L.X.; validation, Z.W., W.R. and X.Y.; resources, T.C.; data curation, P.Z. and Y.C.; writing—original draft preparation, L.X. and Z.W.; writing—review and editing, Z.W., W.R., and X.Y.; visualization, Y.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National R&D Program of China (Grant No. 2023YFB2504703), the Shaanxi International S&T Cooperation Program Project (2024GH-YBXM-24), the National Natural Science Foundation of China (52172379), and the Fundamental Research Funds for the Central Universities (300102242901).
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Conflicts of Interest
Authors Zijian Wang, Wen Rong and Xinpeng Yao were employed by the company Shandong Hi-Speed Group Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Jiang, Y.; Zhu, B.; Zhao, X.; Deng, W. Pixel-wise content attention learning for single-image deraining of autonomous vehicles. Expert Syst. Appl. 2023, 224, 119990. [Google Scholar] [CrossRef]
- Chen, X.; Wei, C.; Yang, Y.; Luo, L.; Biancardo, S.A.; Mei, X. Personnel trajectory extraction from port-like videos under varied rainy interferences. IEEE Trans. Intell. Transp. Syst. 2024, 25, 6567–6579. [Google Scholar] [CrossRef]
- Munsif, M.; Khan, S.U.; Khan, N.; Baik, S.W. Attention-based deep learning framework for action recognition in a dark environment. Hum. Centric Comput. Inf. Sci 2024, 14, 1–22. [Google Scholar]
- Munsif, M.; Afridi, H.; Ullah, M.; Khan, S.D.; Alaya Cheikh, F.; Sajjad, M. A Lightweight Convolution Neural Network for Automatic Disasters Recognition. In Proceedings of the 2022 10th European Workshop on Visual Information Processing (EUVIP), Lisbon, Portugal, 11–14 September 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Yi, Q.; Li, J.; Dai, Q.; Fang, F.; Zhang, G.; Zeng, T. Structure-preserving deraining with residue channel prior guidance. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4238–4247. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Multi-stage progressive image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14821–14831. [Google Scholar]
- Jiang, K.; Wang, Z.; Yi, P.; Chen, C.; Huang, B.; Luo, Y.; Ma, J.; Jiang, J. Multi-scale progressive fusion network for single image deraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8346–8355. [Google Scholar]
- Sivaanpu, A.; Thanikasalam, K. A Dual CNN Architecture for Single Image Raindrop and Rain Streak Removal. In Proceedings of the IEEE 2022 7th International Conference on Information Technology Research (ICITR), Moratuwa, Sri Lanka, 7–8 December 2022; pp. 1–6. [Google Scholar]
- Huang, J.; Liu, Y.; Zhao, F.; Yan, K.; Zhang, J.; Huang, Y.; Zhou, M.; Xiong, Z. Deep fourier-based exposure correction network with spatial-frequency interaction. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 163–180. [Google Scholar]
- Wang, C.; Xing, X.; Wu, Y.; Su, Z.; Chen, J. Dcsfn: Deep cross-scale fusion network for single image rain removal. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1643–1651. [Google Scholar]
- Wang, C.; Wu, Y.; Su, Z.; Chen, J. Joint self-attention and scale-aggregation for self-calibrated deraining network. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2517–2525. [Google Scholar]
- Wang, C.; Pan, J.; Wu, X.M. Online-updated high-order collaborative networks for single image deraining. In Proceedings of the AAAI Conference on Artificial Intelligence, Pomona, CA, USA, 24–28 October 2022; Volume 36, pp. 2406–2413. [Google Scholar]
- Babar, K.; Yaseen, M.U.; Al-Shamayleh, A.S.; Imran, M.; Al-Ghushami, A.H.; Akhunzada, A. LPN-IDD: A Lightweight Pyramid Network for Image Deraining and Detection. IEEE Access 2024, 12, 37103–37119. [Google Scholar] [CrossRef]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Guo, Q.; Sun, J.; Juefei-Xu, F.; Ma, L.; Xie, X.; Feng, W.; Liu, Y.; Zhao, J. Efficientderain: Learning pixel-wise dilation filtering for high-efficiency single-image deraining. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 1487–1495. [Google Scholar]
- Yang, H.; Zhou, D.; Li, M.; Zhao, Q. A two-stage network with wavelet transformation for single-image deraining. Vis. Comput. 2023, 39, 3887–3903. [Google Scholar] [CrossRef]
- Ragini, T.; Prakash, K.; Cheruku, R. DeTformer: A Novel Efficient Transformer Framework for Image Deraining. Circuits Syst. Signal Process. 2024, 43, 1030–1052. [Google Scholar] [CrossRef]
- Chen, X.; Pan, J.; Dong, J.; Tang, J. Towards unified deep image deraining: A survey and a new benchmark. arXiv 2023, arXiv:2310.03535. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Chen, S.; Ye, T.; Bai, J.; Chen, E.; Shi, J.; Zhu, L. Sparse Sampling Transformer with Uncertainty-Driven Ranking for Unified Removal of Raindrops and Rain Streaks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 13106–13117. [Google Scholar]
- Wang, C.; Pan, J.; Wang, W.; Dong, J.; Wang, M.; Ju, Y.; Chen, J. Promptrestorer: A prompting image restoration method with degradation perception. Adv. Neural Inf. Process. Syst. 2023, 36, 8898–8912. [Google Scholar]
- Chen, X.; Pan, J.; Dong, J. Bidirectional Multi-Scale Implicit Neural Representations for Image Deraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 25627–25636. [Google Scholar]
- Quan, R.; Yu, X.; Liang, Y.; Yang, Y. Removing Raindrops and Rain Streaks in One Go. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 9147–9156. [Google Scholar]
- Shao, M.W.; Li, L.; Meng, D.Y.; Zuo, W.M. Uncertainty Guided Multi-Scale Attention Network for Raindrop Removal From a Single Image. IEEE Trans. Image Process. 2021, 30, 4828–4839. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Li, D.; Luo, W.; Ren, W. Dual Attention-in-Attention Model for Joint Rain Streak and Raindrop Removal. IEEE Trans. Image Process. 2021, 30, 7608–7619. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Xu, Y.; Ji, H. Removing rain from a single image via discriminative sparse coding. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3397–3405. [Google Scholar]
- Li, Y.; Tan, R.T.; Guo, X.; Lu, J.; Brown, M.S. Rain streak removal using layer priors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2736–2744. [Google Scholar]
- Li, Y.; Lu, J.; Chen, H.; Wu, X.; Chen, X. Dilated Convolutional Transformer for High-Quality Image Deraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Vancouver, BC, Canada, 17–24 June 2023; pp. 4199–4207. [Google Scholar]
- Wang, H.; Xie, Q.; Zhao, Q.; Li, Y.; Liang, Y.; Zheng, Y.; Meng, D. RCDNet: An Interpretable Rain Convolutional Dictionary Network for Single Image Deraining. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 8668–8682. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Li, H.; Li, M.; Pan, J. Learning a Sparse Transformer Network for Effective Image Deraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 5896–5905. [Google Scholar]
- Xia, C.; Wang, X.; Lv, F.; Hao, X.; Shi, Y. Vit-comer: Vision transformer with convolutional multi-scale feature interaction for dense predictions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 5493–5502. [Google Scholar]
- Shen, X.; Yang, Z.; Wang, X.; Ma, J.; Zhou, C.; Yang, Y. Global-to-Local Modeling for Video-Based 3D Human Pose and Shape Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2023; pp. 8887–8896. [Google Scholar]
- Liu, Y.; Schiele, B.; Vedaldi, A.; Rupprecht, C. Continual Detection Transformer for Incremental Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 23799–23808. [Google Scholar]
- Li, Y.; Fan, Y.; Xiang, X.; Demandolx, D.; Ranjan, R.; Timofte, R.; Van Gool, L. Efficient and Explicit Modelling of Image Hierarchies for Image Restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 18278–18289. [Google Scholar]
- Strümpler, Y.; Postels, J.; Yang, R.; Gool, L.V.; Tombari, F. Implicit neural representations for image compression. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 74–91. [Google Scholar]
- Zheng, M.; Yang, H.; Huang, D.; Chen, L. Imface: A nonlinear 3d morphable face model with implicit neural representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20343–20352. [Google Scholar]
- Barron, J.T.; Mildenhall, B.; Tancik, M.; Hedman, P.; Martin-Brualla, R.; Srinivasan, P.P. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 5855–5864. [Google Scholar]
- Biswal, M.; Shao, T.; Rose, K.; Yin, P.; Mccarthy, S. StegaNeRV: Video Steganography using Implicit Neural Representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 888–898. [Google Scholar]
- Lu, Y.; Wang, Z.; Liu, M.; Wang, H.; Wang, L. Learning spatial-temporal implicit neural representations for event-guided video super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1557–1567. [Google Scholar]
- Yang, S.; Ding, M.; Wu, Y.; Li, Z.; Zhang, J. Implicit Neural Representation for Cooperative Low-light Image Enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 12918–12927. [Google Scholar]
- Zhang, H.; Sindagi, V.; Patel, V.M. Image de-raining using a conditional generative adversarial network. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3943–3956. [Google Scholar] [CrossRef]
- Chen, H.; Ren, J.; Gu, J.; Wu, H.; Lu, X.; Cai, H.; Zhu, L. Snow Removal in Video: A New Dataset and A Novel Method. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 13165–13176. [Google Scholar]
- Gu, S.; Meng, D.; Zuo, W.; Zhang, L. Joint convolutional analysis and synthesis sparse representation for single image layer separation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1708–1716. [Google Scholar]
- Xiao, J.; Fu, X.; Liu, A.; Wu, F.; Zha, Z.J. Image De-raining Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 12978–12995. [Google Scholar] [CrossRef] [PubMed]
- Ba, Y.; Zhang, H.; Yang, E.; Suzuki, A.; Pfahnl, A.; Chandrappa, C.C.; de Melo, C.M.; You, S.; Soatto, S.; Wong, A.; et al. Not Just Streaks: Towards Ground Truth for Single Image Deraining. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer Nature: Cham, Switzerland, 2022; pp. 723–740. [Google Scholar]
- Chen, L.; Chu, X.; Zhang, X.; Sun, J. Simple baselines for image restoration. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 17–33. [Google Scholar]
- Li, B.; Liu, X.; Hu, P.; Wu, Z.; Lv, J.; Peng, X. All-in-one image restoration for unknown corruption. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17452–17462. [Google Scholar]
- Chen, Z.; He, Z.; Lu, Z.M. DEA-Net: Single Image Dehazing Based on Detail-Enhanced Convolution and Content-Guided Attention. IEEE Trans. Image Process. 2024, 33, 1002–1015. [Google Scholar] [CrossRef] [PubMed]
- Gao, T.; Wen, Y.; Zhang, K.; Zhang, J.; Chen, T.; Liu, L.; Luo, W. Frequency-Oriented Efficient Transformer for All-in-One Weather-Degraded Image Restoration. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 1886–1899. [Google Scholar] [CrossRef]
- Chen, S.; Ye, T.; Liu, Y.; Chen, E. SnowFormer: Context interaction transformer with scale-awareness for single image desnowing. arXiv 2022, arXiv:2208.09703. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17683–17693. [Google Scholar]
- Dudhane, A.; Thawakar, O.; Zamir, S.W.; Khan, S.; Khan, F.S.; Yang, M.H. Dynamic Pre-training: Towards Efficient and Scalable All-in-One Image Restoration. arXiv 2024, arXiv:2404.02154. [Google Scholar]
- Özdenizci, O.; Legenstein, R. Restoring vision in adverse weather conditions with patch-based denoising diffusion models. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10346–10357. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).