Abstract
Literature has a strong cultural imprint and regional color, including poetry. Natural language itself is part of the poetry style. It is interesting to attempt to use one language to present poetry in another language style. Therefore, in this study, we propose a method to fine-tune a pre-trained model in a targeted manner to automatically generate French-style modern Chinese poetry and conduct a multi-faceted evaluation of the generated results. In a five-point scale based on human evaluation, judges assigned scores between 3.29 and 3.93 in seven dimensions, which reached 80.8–93.6% of the scores of the Chinese versions of real French poetry in these dimensions. In terms of the high-frequency poetic imagery, the consistency of the top 30–50 high-frequency poetic images between the poetry generated by the fine-tuned model and the French poetry reached 50–60%. In terms of the syntactic features, compared with the poems generated by the baseline model, the distribution frequencies of three special types of words that appear relatively frequently in French poetry increased by 12.95%, 15.81%, and 284.44% per 1000 Chinese characters in the poetry generated by the fine-tuned model. The human evaluation, poetic image distribution, and syntactic feature statistics show that the targeted fine-tuned model is helpful for the spread of language style. This fine-tuned model can successfully generate modern Chinese poetry in a French style.
1. Introduction
In the 19th century, philosopher Georg Wilhelm Friedrich Hegel listed architecture, sculpture, painting, music, and poetry as the five canonical arts of humankind in his book Lectures on Aesthetics (Vorlesungen über die Ästhetik). As the fifth art, poetry is the quintessence of language and is a pearl that will never be absent from the literature of various countries. Different linguistic and cultural backgrounds create different styles of poetry. When reading an exotic poem, we can feel the charming exotic atmosphere. Even if the foreign poem has been translated into the reader’s mother tongue, the reader can still feel the difference from their native culture. Even without knowing whether a poem has been translated, the reader may guess the original language and nationality of the author through the poem’s linguistic style—vocabulary, syntax, imagery, and rhetoric. All these elements constitute the language style of a poem. In the past, readers who wanted to read exotic poems could only rely on human translators to translate foreign poems into their own languages, or local poets could have imitated the foreign language style when they were inspired to create poetry. Today, with the emergence and development of large language models (LLMs) [1,2,3], readers may not have to wait long. If one can transfer a specific “language style” by fine-tuning the language model, one can generate poetry with a specific language style.
The greatest difference between human beings and other intelligent creatures on Earth is that human beings can articulate, comprehend, and disseminate knowledge through structured language, expressing complex logical concepts. The development and manifestation of all aspects of human civilization, from science and engineering to humanities and arts, are inseparable from language. Language abstracts objectively existing things into concepts, and, in turn, the concepts in language can help us understand the real world. Philosopher Ludwig Wittgenstein once said, “The limits of my language mean the limits of my world”. In ancient societies, humans knew nothing about unnamed plants, and a polymath living in the third century BCE could not understand what a portable phone meant; hence, the boundary of languages is to some extent equal to the boundary of human civilization. The poems created by human poets are rooted in historical soil, and their expression is often limited by the author’s common sense, culture, imagination, and background of the times. However, when the language style is disseminated through the targeted fine-tuning of large models, the output of poetry is not a simple reproduction and imitation. It is no longer limited by the shackles of the poet. It is freer and easier to let the imagination run wild and generate breakthrough language that did not exist before. The “emergence” of its language broadens the boundary of human language.
In the field of natural language processing (NLP), the culturally interesting study of poetry generation, like machine translation, has moved from generation based on rules and templates [4,5] to generation based on statistical machine learning [6,7] and then to generation based on neural networks [8,9]. Currently, poetry generation based on pre-trained large language models [10,11,12,13] has greatly improved in quality. France and China are both countries with profound cultural heritage. There are two reasons for choosing French poetry as the source of style and Chinese as the form of poetry presentation: on the one hand, many poetry schools have been born throughout the history of French literature, and a large number of outstanding poets have emerged who are deeply loved by Chinese readers. On the other hand, French is an inflectional language belonging to the Latin part of the Indo-European language family, and Chinese is an analytic language belonging to the Chinese part of the Sino-Tibetan language family. French and Chinese have distinct differences both in language and cultural background, and people can obviously feel a foreign atmosphere when reading poetry in other language styles. Therefore, in this work, we generate Chinese modern poetry based on a pre-trained large language model, fine-tune it for the French language style, and apply human feedback reinforcement learning for further training to generate Chinese modern poetry with a distinctive French style.
The remainder of this paper is organized as follows: Section 2 reviews the related work on poetry generation and reinforcement learning and explains why this research content and the related methods were chosen. Section 3 introduces our proposed method for generating French-style Chinese modern poetry. Section 4 introduces the experiments. Section 5 offers the experimental and evaluation results from various perspectives. Finally, Section 6 concludes the paper and proposes future work.
2. Related Work
2.1. Poetry Generation
Researchers from all over the world have explored and studied poetry generation in Chinese [14,15], English [16,17,18], French [18,19], Spanish [4,20], Portuguese [21], Arabic [12,13,22], and many other languages. According to the different styles of generated poetry, it can be divided into “modern poetry generation” and “classical poetry generation”. According to the content of the generated poetry, it can be divided into “generating poems on specified themes” and “generating poems in the style of a specific poet”. There are quite detailed divisions in the forms of Chinese poetry: the forms of pre-Tang poetry (古体诗) and regulated verse (近体诗) belong to classical poetry, written in ancient Chinese, with restrictions on rhyme, the tones of Chinese characters, and the number of characters; modern poetry (现代诗) is written in modern Chinese, and there are no specific requirements for rhyme, tone, and word count. Researchers have conducted many studies on the generation of Chinese classical poetry [7,9,14,15,23,24,25] but have paid relatively little attention to the generation of modern Chinese poetry [26]. Most of the research content focuses on the embodiment of Chinese internal poetic images and emotions. To our knowledge, however, there has been little research on using Chinese to generate poetry in other language and cultural styles. Therefore, we decided to make this literary attempt using fine-tuning methods for the pre-trained model to “transplant” the style of French poetry to Chinese poetry, hoping to use style propagation to obtain some creative results.
French was chosen as the source of language style in this study because French has a rich literary heritage, and the cultural background it carries is different from Chinese and is quite recognizable. In terms of the choice of poetry form, modern Chinese has a richer vocabulary than ancient Chinese and has more words that can express modern and foreign concepts. Therefore, “Chinese Modern Poetry” written in modern Chinese was our first choice for presenting French-style Chinese poetry.
2.2. Background and Operation of Large Language Models (LLMs)
Large language models have revolutionized natural language processing by leveraging vast amounts of data and computational power to generate human-like text. These models, such as GPT-3, are built using transformer architectures, which allow the efficient processing and generation of text by capturing long-range dependencies in language [27]. The development and fine-tuning of LLMs involve several critical steps, each contributing to the model’s ability to understand and generate coherent and contextually appropriate text.
LLMs, such as GPT-3, are pre-trained on diverse and extensive datasets containing text from a wide range of sources, including books, articles, and websites. This pre-training phase enables the model to learn the statistical properties of a language, including grammar, syntax, semantics, and even some level of common-sense reasoning. The pre-trained model can then be fine-tuned for specific tasks, such as poetry generation, by training it on domain-specific datasets [28]. Fine-tuning adjusts the model’s parameters to better suit the nuances and styles required for the target application [29].
The operation of LLMs involves several key components and steps: (1) Pre-training: During the pre-training phase, the model is trained on a large corpus of text using unsupervised learning techniques. The primary objective is to minimize the difference between the predicted and actual next words in a sequence, a process known as language modeling. This step equips the model with a broad understanding of language [1,30]. (2) Fine-tuning: After pre-training, the model undergoes fine-tuning on a more specific dataset relevant to the desired application. For instance, to generate French-style modern Chinese poetry, the model is fine-tuned using a dataset comprising modern Chinese translations of works by French poets. This step allows for the model to capture specific styles, themes, and linguistic patterns [31]. (3) Human Feedback Collection: This step presents multiple samples generated by the model to human evaluators who label these samples based on their quality and adherence to the desired style. This feedback is used to create a reward model that predicts human preferences, guiding the model to generate higher-quality text [32]. (4) Reward Model Training: The reward model is trained using the feedback collected from human evaluators. This model assigns a score to each generated text sample, indicating its quality. The reward model helps in refining the text generation process by providing a quantitative measure of text quality [33]. (5) Reinforcement Learning: Using the reward model, the LLM is further fine-tuned. This step involves adjusting the model’s parameters to maximize the reward, ensuring that the generated text aligns closely with human preferences and desired stylistic attributes. By following these steps, LLMs can be optimized to generate high-quality and stylistically consistent text [34].
2.3. Reinforcement Learning from Human Feedback
Reinforcement Learning (RL) [35] is a widely used machine learning method in the field of artificial intelligence. Since it was proposed in 1961, in addition to poetry generation [14], reinforcement learning has been used in many fields such as medical care [36,37], industry [38], robots [39], and games [40,41]. Reinforcement learning does not rely on explicit instructions but learns through repeated interactions with the environment and can better cope with various uncertain environments. However, traditional reinforcement learning also has its limitations. First, the real environment contains complex changes, making it difficult to accurately define reward or penalty functions in advance. Second, in some scenarios for human users, the results learned by the computer may deviate from the user’s true intention. The new reinforcement learning method, Reinforcement Learning from Human Feedback (RLHF) [34], proposed in recent years introduces manual guidance into machine learning, which effectively overcomes the limitations of traditional reinforcement learning. RLHF learns reward models from human feedback such as ratings, corrections, and preferences in order to optimize reinforcement learning. Integrating human feedback into reinforcement learning is like a ship having a navigation satellite. The satellite can correct the ship that deviates from the route and provide an appropriate follow-up route, which can improve both efficiency and safety.
The connection between natural language and human beings is close. Once RLHF was proposed, it quickly became popular in the field of natural language processing. In recent years, RLHF has been used to fine-tune large language models [42,43] and generate book summaries [44] and has performed well in improving the quality of the output results and reducing dirty data and inappropriate content.
Unlike news, weather forecasts, or instructions, which have fixed formats and vocabulary categories, poetry, as an art form full of romance and imagination, has all-encompassing themes, rich content, and complex rhetoric and is full of symbols, metaphors, and allusions. Regardless of whether one uses Unsupervised Learning (UL), Supervised Learning (SL), or traditional reinforcement learning, it is difficult to achieve good performance in this highly open language generation. The new reinforcement learning method, RLHF, has excellent performance on tasks without fixed standards; so, we applied this method when fine-tuning the pre-trained model to enhance the expression of the French style in modern Chinese poetry.
3. Method
3.1. Model Architecture
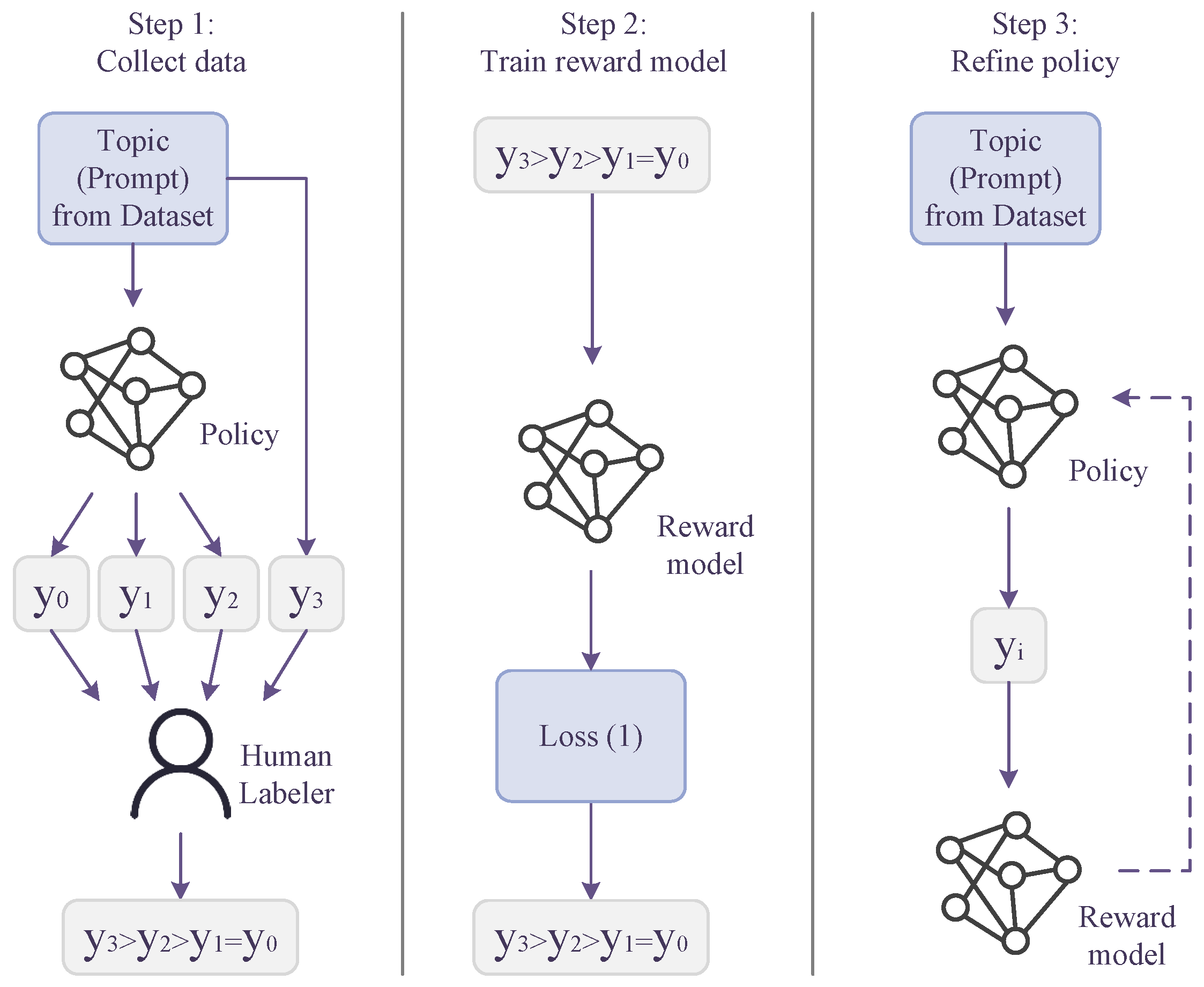
Our model primarily operates in three steps: collecting human feedback, training reward models, and refining policy, as depicted in Figure 1. Initially, we begin with a pre-trained instance of GPT-3 and further enhance the model through supervised learning using a dataset containing modern Chinese translations of works by various French poets.
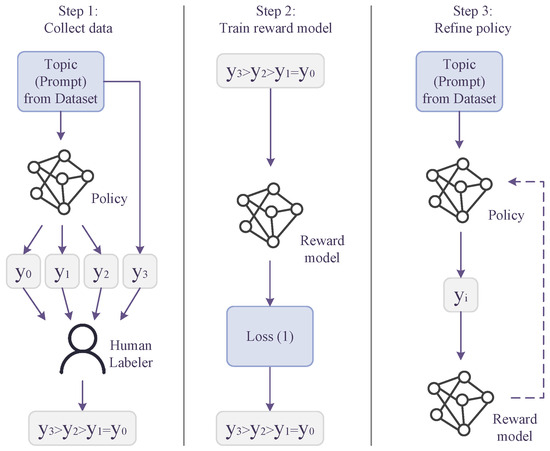
Figure 1.
The model architeture. First, we collect dataset samples through human feedback and rank candidate outputs. In the second step, we train the reward model r using the defined loss. Lastly, the model utilizes Proximal Policy Optimization (PPO) to train policy with rewards from r.
3.2. Collecting Human Feedback
In the first stage, we presented four samples with respect to topic x to the labelers for selection. One sample was drawn from a dataset of modern Chinese translations of works by French poets, while the other three were generated using a language model as a strategy for acquiring these samples.
There were several reasons for using three y samples. First, having multiple generated samples helps capture the diversity of the model’s output. By presenting multiple samples generated by the language model, we could more comprehensively evaluate the model’s performance under different conditions. This diversity allowed for evaluators to see variations in the model’s output, thus making more reliable quality judgments. Second, multiple samples provide richer data and enhance the training effect of the model. In training reward models, more samples mean more comparison pairs and ranking information, which are crucial for model optimization. By comparing multiple samples, the model can better learn what kind of output meets expectations, thus improving the overall generation quality. Lastly, comparing multiple samples can reduce the bias caused by the randomness of a single sample.
We chose three y samples to strike a balance between diversity and manageability. Including more samples (e.g., four or five) can increase the complexity and cognitive load for evaluators, potentially leading to fatigue and less reliable judgments. Additionally, more samples would require significantly more computational resources and time for both the generation and evaluation processes. Therefore, the use of three samples ensured that we captured sufficient diversity without overwhelming the evaluators or overextending computational resources.
Human evaluators ranked these samples based on a set of guidelines, specifying the relative quality of each sample. These guidelines included aspects such as language fluency, poetic expression, grammatical accuracy, and adherence to the original French style. The evaluators’ feedback was stored in a human feedback dataset , providing references for subsequent model optimization.
A graphical representation of the process is shown in Step 1 of Figure 1. In this way, we systematically collected high-quality human feedback, helping the model to progressively improve the quality and stylistic consistency of the generated poetry. The key to this stage was the subjective judgment of human evaluators, which filtered out the most fitting samples, thus providing valuable data for training the reward models.
3.3. Training the Reward Models
Next, we proceeded to train a reward model to anticipate the human-preferred outcomes. Specifically, samples gathered during the human feedback phase were utilized for training the reward model, aiming to forecast whether the new poetry samples resonated with the preferences of human labelers. An illustrative overview of this process is depicted in Step 2 of Figure 1.
In particular, we defined a reward function, denoted as . This function was expected to assign higher values to completions ranked higher by human evaluators and lower values to those ranked lower, with respect to prompt x. Consequently, we optimized the following objective function:
Here, represents the preferred completion out of the pair of and , and S is the dataset of human comparisons. The loss function aims to maximize the probability that the reward model correctly identifies the higher-ranked completion over the lower-ranked completion .
To train the reward model, we employed dataset S composed of pairs where each pair reflected human judgments on the relative quality of two samples. Reward function was designed to predict the quality of sample y given topic x. Sigmoid function ensured that the output was a probability, indicating how much more likely it was that was preferred over .
The optimization process involved iteratively adjusting the parameters of the reward model to minimize the loss function defined above. The gradient descent algorithm is typically used for this purpose, allowing for us to find the parameter values that best align the model’s predictions with human preferences. The gradients of the loss function were computed, and this gradient was used to update the parameters of the reward model, thereby refining its ability to predict the human-preferred outcomes.
Through this training process, the reward model became increasingly adept at discerning the qualities that made the poetry samples resonate with human evaluators. This trained reward model was then used in the subsequent step to refine the policy of the language model, ensuring that the generated poetry aligned more closely with human preferences.
3.4. Refining the Policy with Reinforcement Learning
Finally, our aim was to fine-tune a large model (policy) denoted as . Initially, this policy was set to . We refined through reinforcement learning, utilizing the reward model from the preceding step to ensure its effectiveness in generating Chinese poems resembling the style of French poetry. To prevent the significant deviation of learned policy from initial policy , we introduced regularization term as penalty. Thus, we conducted reinforcement learning on the reward model using the following equation:
Here, hyperparameter controls the extent of deviation allowed for the large model. It serves as an entropy bonus, preventing the policy from straying too far from the effective range of the initial policy , which is crucial to our style transfer task. We relied on the KL term to encourage coherence and thematic consistency, as we relied on the human evaluators to assess the style.
To optimize our policy, we utilized Proximal Policy Optimization (PPO), a popular algorithm in reinforcement learning known for its stability and efficiency. PPO works by iteratively improving the policy through gradient updates, ensuring that each update does not move the policy too far from the previous one, thus maintaining stability. The process of refining the policy involves several critical steps.
Policy is parameterized by , determining the probability of taking action y given state x, denoted as . PPO uses advantage function to evaluate how much better taking action y in state x is compared to the average action. Advantage function plays a crucial role in this process. It measures the relative value of a particular action taken in a given state compared to the average value of all possible actions in that state. By using the advantage function, we provided a clearer signal for learning, emphasizing actions that led to better outcomes than expected. In our work, the advantage function is defined as
where is the actual reward and is the state value function, representing the expected cumulative reward from state .
Next, the probability ratio was calculated as
Here, is the current policy, and is the old policy. This ratio compares the probability of the action under the current policy to that under the old policy.
Then, PPO was designed to prevent large destabilizing updates by introducing mechanisms, including clipped probability ratios. To ensure stable policy updates, we define the clipped objective function as
where clips probability ratio to range , and is a small constant that controls the extent of the policy update.
Policy parameters were updated by maximizing the clipped objective function, typically using gradient ascent methods. This objective function balances between making significant updates when the advantage is large and making conservative updates when the change is too drastic.
The connection between the PPO process and the minimization of can be understood as follows. By optimizing advantage function , PPO indirectly works towards maximizing the expected cumulative reward, which corresponds to minimizing negative reward function . The clipped objective function ensures that the policy updates are stable and do not result in drastic changes. This stability is crucial for effectively minimizing , as it prevents the policy from oscillating or diverging. By using the advantage function and probability ratio, PPO balances exploration and exploitation, ensuring that the policy not only seeks immediate rewards but also explores better actions to minimize in the long run. Thus, PPO optimizes the policy by using a clipped objective function to make stable updates, leveraging the advantage function to guide these updates; it effectively works towards minimizing reward function , aligning the policy with the goal of achieving optimal performance.
In our poetry generation task, PPO was used to optimize the model’s policy, ensuring it generated poems that aligned with the desired style. By repeatedly updating the policy using the PPO algorithm, guided by the reward model and regularization terms, we ensured the final policy produced high-quality stylistically consistent poetry.
In summary, the overall training process of our model is as follows:
- Collect dataset samples by gathering human feedback and candidate outputs . Human labelers are asked to rank all four .
- Train the reward model r using the loss defined in Equation (1) on the dataset samples obtained in the previous step.
- Utilize Proximal Policy Optimization (PPO) to train , where the reward is defined by Equation (2).
4. Experiments
4.1. Datasets
We fine-tuned the 175 billion-parameter version of GPT-3 for poetry generation and evaluation on a widely available French poetry dataset. Additionally, we gathered a new dataset, which we used as a quality assessment system. This dataset consisted of modern Chinese translations [45,46,47,48] of works by French poets (comprising 108,000 characters), meticulously proofread and corrected. The poems in the dataset were categorized into seven types based on content and annotated word by word according to 22 grammatical categories. We considered both the original Chinese word classes and syntactic structures and the specific word classes and structures in foreign languages to effectively incorporate foreign language styles during model training. The distribution of poem types in the dataset is presented in Table 1.

Table 1.
Distribution of poetry types in the dataset.
4.2. Human Data Collection
Our prompt dataset primarily comprised text prompts submitted to the GPT API. Each natural language prompt typically defines the task directly through natural language instructions (e.g., “Write a Chinese lyrical poem with a French style”); however, it may also be indirectly specified through a few examples (e.g., providing a summary of modern Chinese translations of works by French poets and then prompting the model to generate a poem) or implicit continuation (e.g., providing the beginning of a French poem).
To create our comparison dataset and conduct primary evaluations, we assembled a contract annotation team of approximately 10 individuals, all native Chinese speakers with a deep understanding of French literature and a strong appreciation for poetry. Our objective was to select annotators proficient in identifying poems in the French style. In each case, our annotators endeavored to grasp the user’s intent behind the prompt and evaluated the result based on their best judgment and the guidelines provided by us, as follows.
Guidelines: We asked the annotators to select their favorite poem based on the following criteria:
- Relevance to the theme;
- Consistency of content (logical coherence);
- Creativity;
- Form, vocabulary, syntax, figurative language, idioms, and allusions.
To effectively incorporate foreign language styles during model training, the annotations considered both the original Chinese word classes and syntactic structures and the specific word classes and structures in foreign languages.
5. Results and Evaluation
We used the following three methods to evaluate the generated results: human evaluation, poetic image coincidence overlap statistics, and syntactic feature proximity.
5.1. Human Evaluation
A total of 26 human evaluators participated in the human evaluation, all of whom were native Chinese speakers familiar with French literature and who had a good appreciation of poetry. In order to ensure the objectivity of the evaluation results, we mixed the Chinese versions of the real French poet’s works into the generated poems for evaluation as a reference group. The selected works were all poems of a poet who is not well-known in China to ensure that the evaluators had not read these works before. Therefore, the human evaluators did not know in advance which of the poems were generated poems and which were works of human poets.
To ensure a comprehensive evaluation, we compared our model with the state-of-the-art poetry generation method, SPG [49]. This advanced method incorporates mutual information to enhance the fluency and coherence of generated poems. The 70 poems evaluated included 20 poems generated by the pre-trained model without fine-tuning, 20 poems generated by the model after fine-tuning, 20 poems generated by SPG, and 10 Chinese versions of works by French poets. The average length of these 70 poems was 17.34 lines, with an average of 11.33 Chinese characters per line. The evaluators independently scored the 70 poems. The comparison of verses generated by the baseline pre-trained model and the fine-tuned pre-trained model is shown in Table 2.
Table 2.
Examples of generated verses and their translations.
In the past, researchers often used the four-dimension evaluation method [8,11,22,23,24] (I. Fluency II. Coherence III. Meaning IV. Poeticness) and the six-dimension evaluation method [17,50,51] (I. How typical is the text as a poem? II. How understandable is it? III. How good is the language? IV. Does the text evoke mental images? V. Does the text evoke emotions? VI. How much does the subject like the text?) to evaluate generative poetry involving a single language. However, since the generated poetry in this experiment involved two languages—the language of the style source and the language used for the style presentation—we designed a seven-dimension evaluation method to evaluate the generated results in a more targeted manner. These seven dimensions were “grammar, logicality, rhetoric, creativity, depth, style, and human-likeness”.
The scoring of each perspective was presented on a five-point Likert Scale, and the standards are shown in Table 3.
Table 3.
Evaluation Dimensions and Evaluation Criteria.
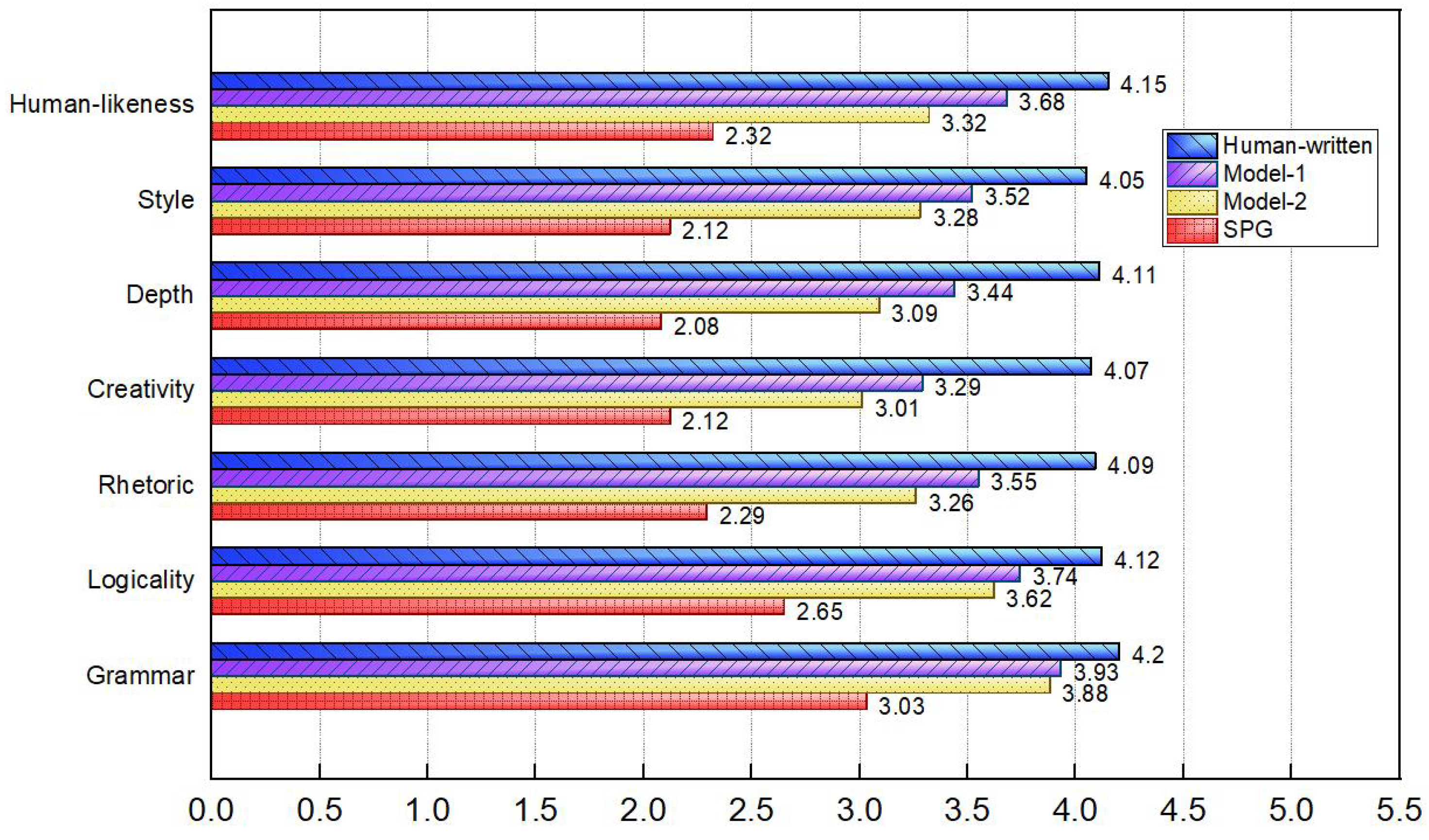
We obtained a total of 12,740 rating data from 26 judges on 70 poems in seven dimensions. The calculated average values of each dimension are shown in Figure 2. Among them, Human-written represents the score of the human poets’ works in this dimension, Model-2 represents the score of the poems generated by the original pre-trained model, and Model-1 represents the score of the poems generated by the fine-tuned pre-trained model.
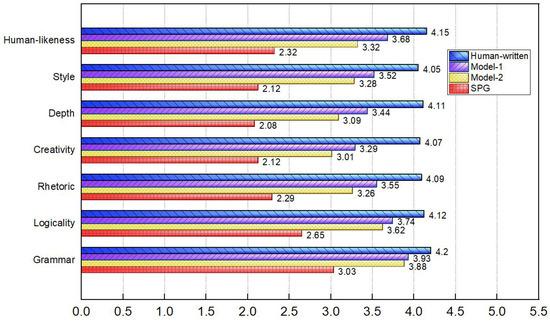
Figure 2.
Human evaluation results of poems generated by the baseline pre-trained model, poems generated by the fine-tuned pre-trained model, and human-written poems.
The results of Cronbach and McDonald’s that are higher than 0.8 indicate that the reliability is very high, and results between 0.7 and 0.8 indicate that the reliability is high. As shown in Table 4, the Cronbach index calculated from our human evaluation data was between 0.822 and 0.936, and the McDonald’s index was between 0.802 and 0.947, which shows that the human evaluation data were reliable.
Table 4.
Reliability of human evaluation results.
Our comparison with the SPG demonstrated the effectiveness of our algorithm, showcasing superior performance across multiple dimensions. We can see from the average scores of the human evaluation that the poems generated by the fine-tuned pre-trained model reached above “average” (i.e., >3 points) in each evaluation dimension and were better than the baseline model in all evaluation dimensions. Among them, the “grammar” and “logicality” dimensions of increased by 0.05 points and 0.12 points, respectively. This may be because the baseline model already performed well on these basic aspects; so, there was less room for improvement. In the advanced dimensions “rhetoric” and “creativity”, the average scores increased by 0.29 points and 0.28 points, respectively. In terms of the high-order dimensions of “depth”, “style”, and “human-likeness”, the average scores increased by 0.35 points, 0.24 points, and 0.36 points, respectively. This shows that the fine-tuning of the pre-trained model helped to improve the performance of the generated poetry in terms of rhetoric, creativity, and depth. It significantly improved the approximation of the target language style and was closer to human-written poetry from the reader’s perspective. The fine-tuned pre-trained model generated poems whose human evaluation scores in the seven dimensions of grammar, logicality, rhetoric, creativity, depth, style, and human-likeness, respectively, reached 93.6%, 90.8%, 86.8%, 80.8%, 83.7%, 86.9%, and 88.7% of the scores of real poets’ works. It performed well in terms of grammar, logicality, rhetoric, style, and being human-like; however, it still lacked creativity and depth.
5.2. Poetic Image Evaluation
“Poetic imagery” has strong cultural and regional characteristics and has an important influence on poetry style. Common images in poetry vary from language to language. France has been deeply influenced by Christian culture in history, and religious and mythological images such as “Dieu (God)”, “paradis (heaven)”, “enfer (hell)”, “ange (angel)”, and “diable (devil)” often appear in French but are rarely encountered in Chinese poetry. Regional flora and fauna often serve as important images in poetry, presenting a unique cultural beauty. For example, the unique image expression “青纱帐 (green curtain)” appears in Chinese poetry, which is used to represent the large areas of tall and dense crops in the fields; as shown in Table 5, in the poem “L’Adieu” by French poet Guillaume Apollinaire, a kind of cold-resistant European flower “bruyère (heather)” is used as the main poetic image to express loneliness and sadness and to enhance the atmosphere of parting.
Table 5.
Example of poetic images in French poetry.
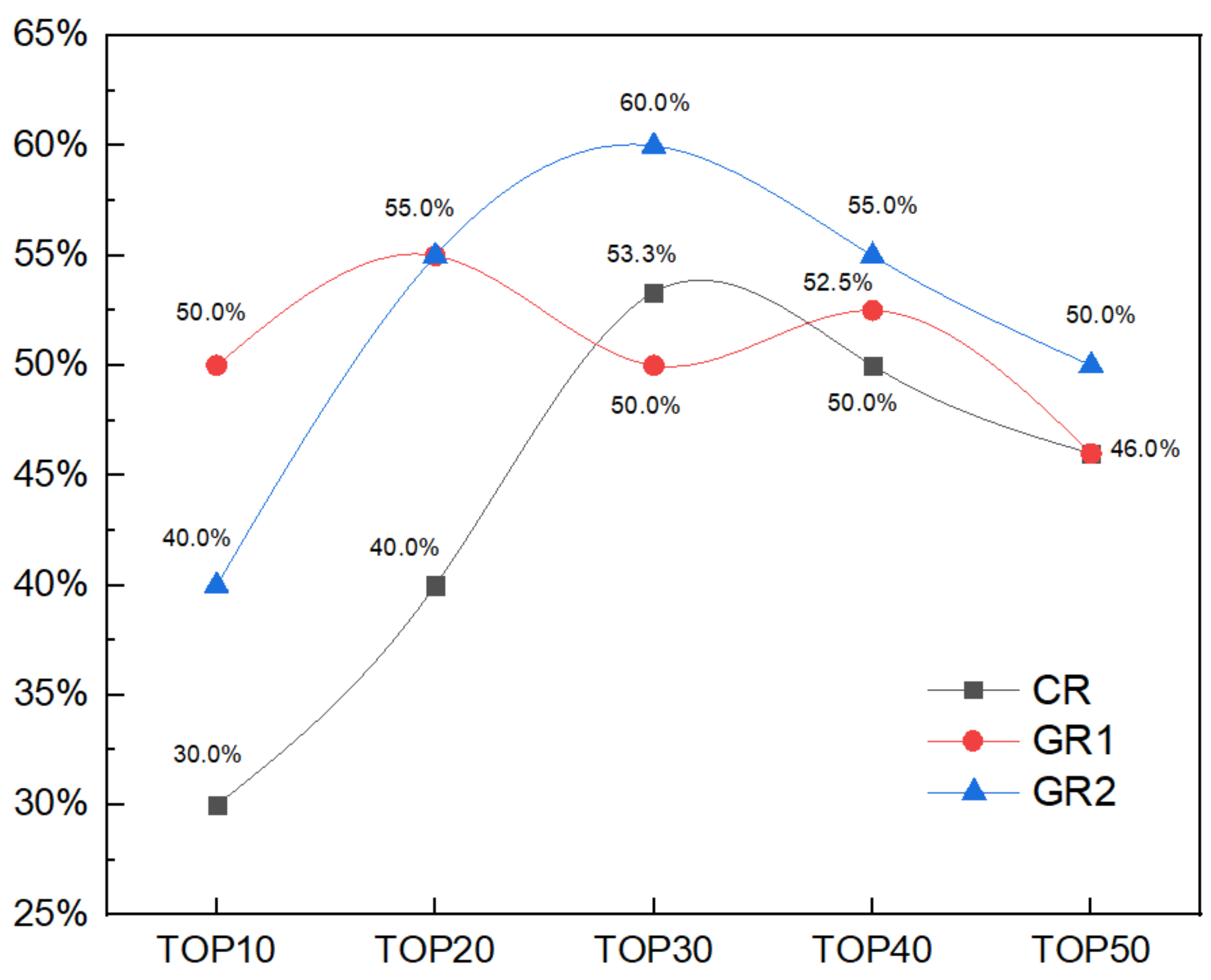
Since poetic imagery is an important component of poetic style, we gathered statistics on the poetic image distribution of the generated poetry to evaluate the degree of presentation of the language style in the generated poetry. As a reference group, we counted the top 50 high-frequency poetic images in 200 works by 80 modern Chinese poets and the top 50 high-frequency poetic images in 302 works by 18 famous French poets. Then, we used the baseline model and the fine-tuned pre-trained model to generate 50 poems, respectively, and we counted the top 50 high-frequency poetic images. Finally, we calculated the consistency of the top 10 to top 50 high-frequency poetic images between Chinese poetry and French poetry, French poetry and the poetry generated by the baseline model, and French poetry and the poetry generated by the fine-tuned pre-trained model. The calculation results of the poetic image consistency are shown in Figure 3, in which the poetic image consistency between Chinese poetry and French poetry is represented by CR, the poetic image consistency between French poetry and the poetry generated by the baseline model is represented by GR1, and the poetic image consistency between French poetry and the poetry generated by the fine-tuned pre-trained model is represented by GR2.
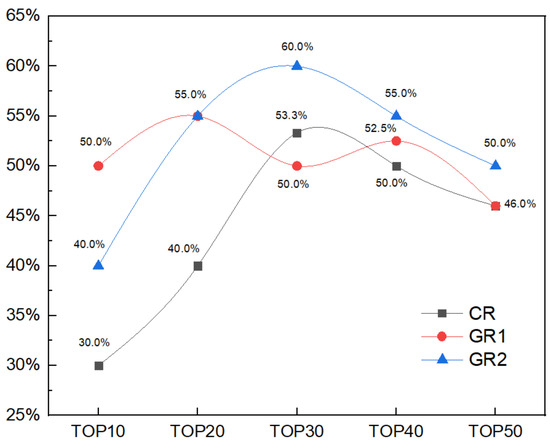
Figure 3.
Consistency of high-frequency poetic images between Chinese poetry and French poetry, French poetry and poetry generated by the baseline model, French poetry and poetry generated by the fine-tuned pre-trained model.
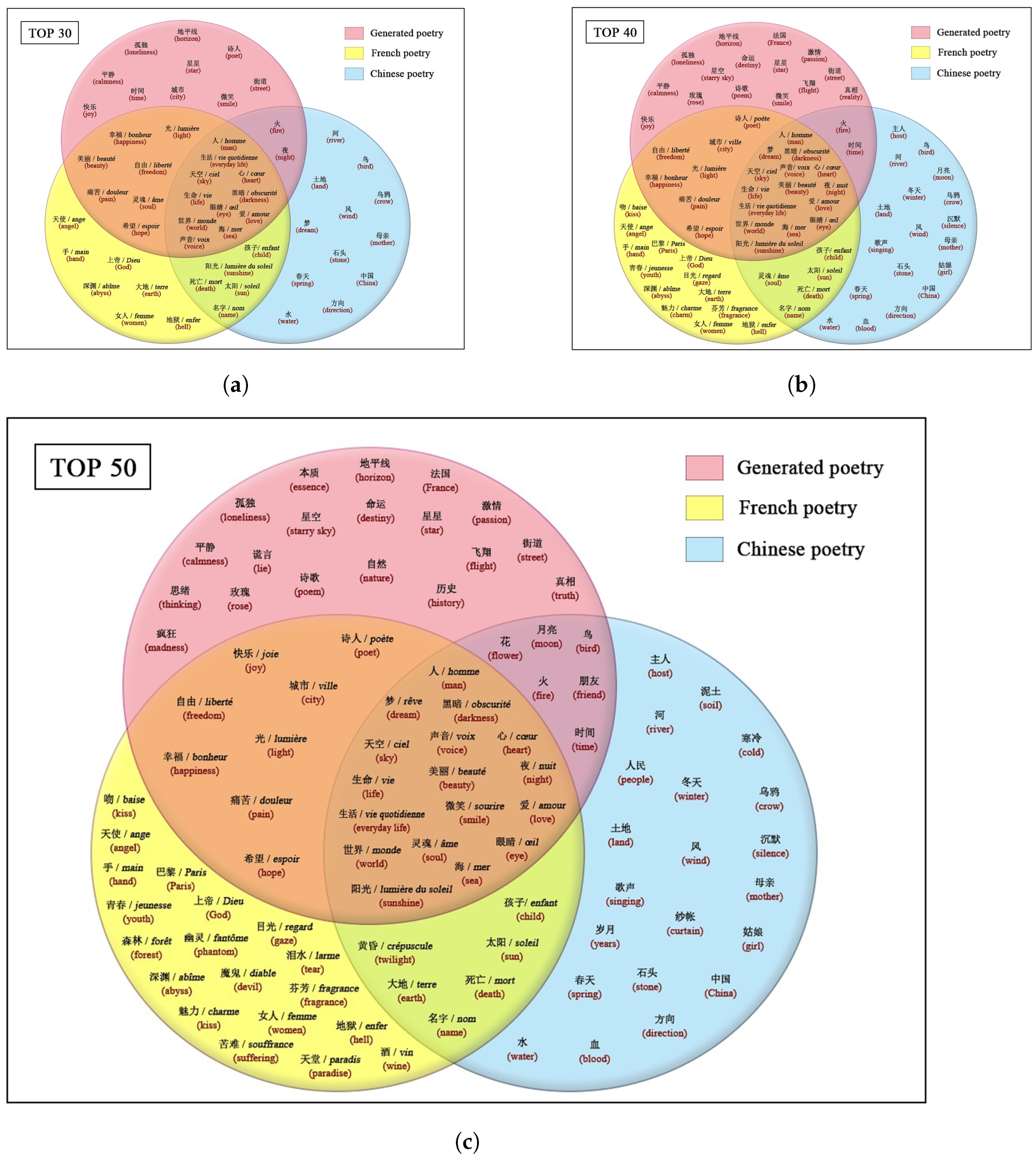
According to Figure 3, the CR was between 30% and 53.5%, the GR1 was between 46% and 55%, and the GR2 was between 40% and 60%. Among them, the GR1 was higher than the CR at three points: TOP10, TOP20, and TOP40, while the GR2 was higher than the CR at every point (i.e., TOP10, TOP20, TOP30, TOP40, and TOP50). In addition, except for the GR2 being lower than and equal to GR1 at the TOP10 and TOP20 points, respectively, it was higher than the GR1 at the TOP30-50 points. Compared with the baseline model, the GR2 improved in these by 20%, 4.8% and 8.7%, respectively. This shows that fine-tuning training can effectively enhance the presentation of the French style in generated poetry.
Figure 4a–c shows the distribution of the high-frequency images of Chinese poetry, French poetry, and French-style Chinese poetry generated by the fine-tuned pre-trained model.
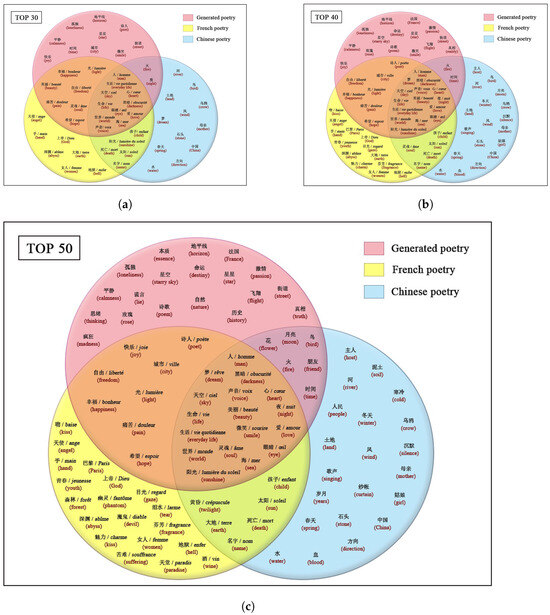
Figure 4.
Distribution of high-frequency poetic images in French poetry, Chinese poetry, and poetry generated by fine-tuned pre-trained model. (a) Distribution of top 30 high-frequency poetic images; (b) Distribution of top 40 high-frequency poetic images; (c) Distribution of top 50 high-frequency poetic images.
5.3. Syntactic Feature Evaluation
The style of language is not only defined by specific meanings, but it is also closely related to syntactic structure. When appreciating some translated literary, film, and television works, even if the content is ordinary and there is no semantic expression with clear content differences, we can still distinguish the original language of the sentence through sentence structure. The translation method that significantly transplants the syntactic structure of the foreign language is often called “translationese”. In the field of poetry translation, the “translationese” of excessively copying foreign syntax makes the sentences clumsy, eccentric, and difficult to understand. However, if the scale of the “translationese” can be grasped well, it can express the exotic style without damaging the meaning, the readability, and the coherence of the verses.
Based on the above, we identified the following three important characteristics of French that differ from Chinese in terms of the frequency of specific types of vocabulary.
I. In French, personal pronouns generally cannot be omitted; however, in Chinese, personal pronouns are often omitted, as shown in Table 6.
Table 6.
Examples of the occurrence and omission of personal pronouns in French poetry and Chinese poetry.
II. Nouns in French usually appear together with articles. Most singular things are preceded by an indefinite article (French: un/une) indicating the number one, making “one” appear more frequently. In Chinese, in addition to numerals, there are often quantifiers involved in modifying the nouns. When the numeral before the noun is one (Chinese: 一), the numeral is often omitted, and only the quantifier is retained; so, the frequency of “one” is lower, as shown in Table 7.
Table 7.
Examples of the occurrence and omission of numeral “one” in French poetry and Chinese poetry.
III. The second-person singular honorific vous is used more frequently in French poetry. In comparison, the second-person singular honorific 您 and 君 appear less frequently in Chinese poems written in modern Chinese, as shown in Table 8.
Table 8.
Examples of the use of second-person singular honorifics in French poetry and Chinese poetry.
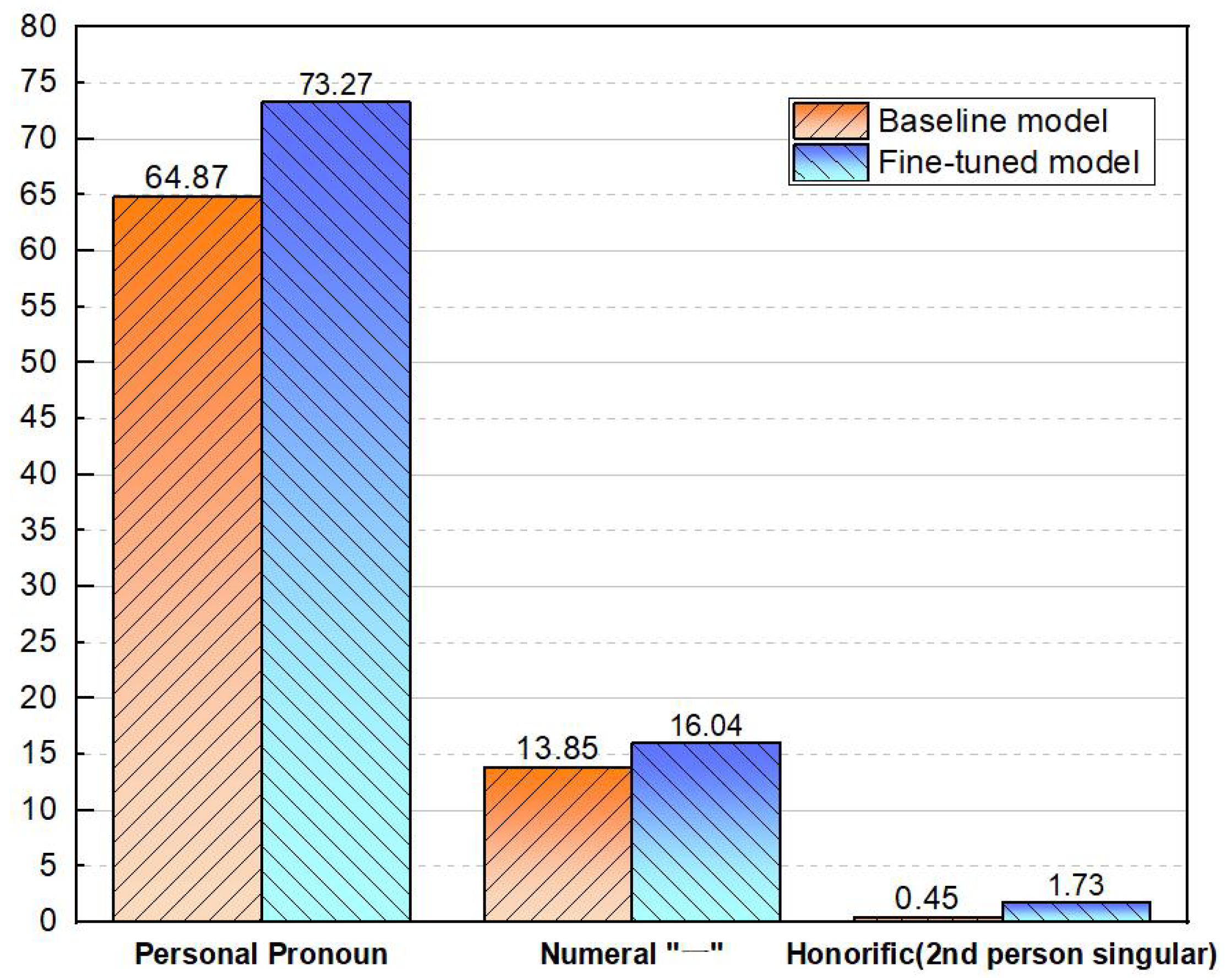
As can be seen in Figure 5, the poems generated by the fine-tuned model had an increase in the frequency of personal pronouns, the frequency of the numeral “一(a/an/one)”, and the frequency of second-person honorifics. Compared with the baseline model, the frequency of these three features increased by 12.95%, 15.81%, and 284.44% per thousand characters, respectively. Therefore, the fine-tuned poetry generation model was closer to the French language style in these details without affecting the semantic expression of modern Chinese.
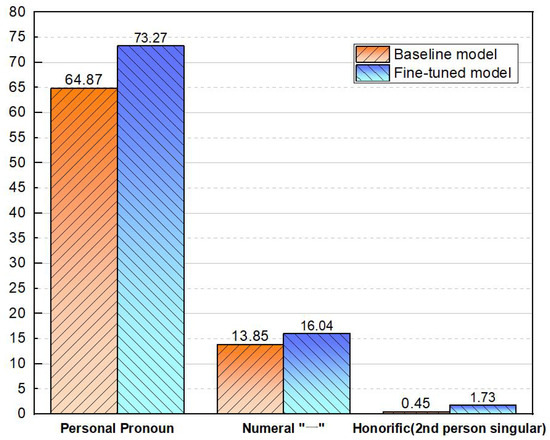
Figure 5.
Proportion of personal pronoun, numeral “一”, and second-person singular honorifics per 1000 Chinese characters in poems generated by the baseline pre-trained model and in poems generated by the fine-tuned pre-trained model.
6. Conclusions
In this paper, we proposed a method to fine-tune a pre-trained model in a targeted manner to automatically generate French-style modern Chinese poetry and conduct a multi-faceted evaluation of the generated results. In a human evaluation using a five-point scale, judges assigned scores between 3.29 and 3.93 in the seven dimensions of grammar, logicality, rhetoric, creativity, depth, style, and being human-like, which reached 80.8–93.6% of the scores of Chinese versions of real French poetry in these dimensions. In terms of the high-frequency poetic imagery, the consistency of the top 30–50 high-frequency poetic images between the poetry generated by the fine-tuned model and the French poetry reached 50–60%. In terms of the syntactic features, compared with the poems generated by the baseline model, the distribution frequencies of three special types of words that appear relatively frequently in French poetry increased by 12.95%, 15.81%, and 284.44% per 1000 Chinese characters in the poetry generated by the fine-tuned model. The human evaluation, poetic image distribution, and syntactic feature statistics show that the targeted fine-tuning of the pre-trained model is helpful for the spread of the language style. This fine-tuned model can successfully generate modern Chinese poetry in a French style.
Through human evaluation, we found that the model performed well in basic dimensions, such as grammar and logicality; however, it still had a large gap with real poets’ works in terms of creativity and depth. In the future, we will continue studying ways to improve the performance of the model in these weak aspects.
Author Contributions
Methodology, L.Z. and Y.Z.; Software, L.Z.; Data curation, L.Z.; Writing—original draft, L.Z.; Writing—review & editing, D.Z. and Y.Z.; Supervision, D.Z., Y.Z. and G.W.; Project administration, G.W.; Funding acquisition, D.Z. and G.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work was financed by the Educational Department of Liaoning Province in China under scientific research project number LJKR0002.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A robustly optimized BERT pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Gervas, P. WASP: Evaluation of different strategies for the automatic generation of Spanish verse. In Proceedings of the AISB00 Symposium on Creative & Cultural Aspects of AI, Birmingham, UK, 17–20 April 2000; p. 93100. [Google Scholar]
- Oliveira, H.G. PoeTryMe: A versatile platform for poetry generation. In Proceedings of the ECAI 2012 Workshop on Computational Creativity, Concept Invention, and General Intelligence (C3GI), Montpellier, France, 27 August 2012. [Google Scholar]
- Jiang, L.; Zhou, M. Generating Chinese couplets using a statistical mt approach. In Proceedings of the 22nd International Conference on Computational Linguistics, Manchester UK, 18–22 August 2008; p. 377384. [Google Scholar]
- He, J.; Zhou, M.; Jiang, L. Generating Chinese classical poems with statistical machine translation models. Proc. Twenty-Sixth AAAI Conf. Artif. Intell. 2012, 26, 1650–1656. [Google Scholar] [CrossRef]
- Yan, R. i, Poet: Automatic poetry composition through recurrent neural networks with iterative polishing schema. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-16), New York, NY, USA, 9–15 July 2016; pp. 2238–2244. [Google Scholar]
- Wang, Z.; He, W.; Wu, H.; Wu, H.; Li, W.; Wang, H.; Chen, E. Chinese Poetry Generation with Planning based Neural Network. In Proceedings of the COLING 2016, 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 1051–1060. [Google Scholar]
- Hämäläinen, M.; Alnajjar, K.; Poibeau, T. Modern French poetry generation with RoBERTa and GPT-2. In Proceedings of the 13th International Conference on Computational Creativity (ICCC), Bozen-Bolzano, Italy, 27 June–1 July 2022; pp. 12–16. [Google Scholar]
- Beheitt, M.E.G.; Hmida, M.B.H. Automatic Arabic poem generation with GPT-2. In Proceedings of the 14th International Conference on Agents and Artificial Intelligence (ICAART 2022), Virtual Event, 3–5 February 2022; Volume 2, pp. 366–374. [Google Scholar]
- Nehal, E.; Mervat, A.; Maryam, E.; Mohamed, A. Generating Classical Arabic Poetry using Pre-trained Models. In Proceedings of the Seventh Arabic Natural Language Processing Workshop (WANLP), Abu Dhabi, United Arab Emirates, 8 December 2022; pp. 53–62. [Google Scholar]
- Beheitt, M.E.G.; Moez, B.H. Effectiveness of Zero-shot Models in Automatic Arabic Poem Generation. Jordanian J. Comput. Inf. Technol. 2023, 9, 21–35. [Google Scholar] [CrossRef]
- Yi, X.; Sun, M.; Li, R.; Li, W. Automatic Poetry Generation with Mutual Reinforcement Learning. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3143–3153. [Google Scholar]
- Chen, H.; Yi, X.; Sun, M.; Li, W.; Yang, C.; Guo, Z. Sentiment-controllable Chinese poetry generation. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 4925–4931. [Google Scholar]
- Ghazvininejad, M.; Shi, X.; Choi, Y.; Knight, K. Generating topical poetry. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1183–1191. [Google Scholar]
- Shihadeh, J.; Ackerman, M. EMILY: An Emily Dickinson machine. In Proceedings of the 11th International Conference on Computational Creativity (ICCC’20), Coimbra, Portugal, 7–11 September 2020; pp. 243–246. [Google Scholar]
- Tim, V.D.C. Automatic Poetry Generation from Prosaic Text. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 2471–2480. [Google Scholar]
- Popescu-Belis, A.; Atrio, À.; Minder, V.; Xanthos, A.; Luthier, G.; Mattei, S.; Rodriguez, A. Constrained language models for interactive poem generation. In Proceedings of the 13th Conference on Language Resources and Evaluation (LREC 2022), Marseille, France, 20–25 June 2022; pp. 3519–3529. [Google Scholar]
- Oliveira, H.G.; Hervás, R.; Díaz, A.; Gervás, P. Adapting a generic platform for poetry generation to produce Spanish poems. In Proceedings of the 5th International Conference on Computational Creativity (ICCC), Charlotte, NC, USA, 17–21 June 2014; pp. 63–71. [Google Scholar]
- Gonçalo Oliveira, H. Automatic generation of creative text in Portuguese: An overview. Lang Resour. Eval. 2024, 58, 7–41. [Google Scholar] [CrossRef] [PubMed]
- Talafha, S.; Rekabdar, B. Arabic poem generation with hierarchical recurrent attentional network. In Proceedings of the 2019 IEEE 13th International Conference on Semantic Computing (ICSC), Newport Beach, CA, USA, 30 January–1 February 2019; pp. 316–323. [Google Scholar]
- Zhang, X.; Lapata, M. Chinese poetry generation with recurrent neural networks. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 670–680. [Google Scholar]
- Yi, X.; Li, R.; Sun, M. Generating Chinese classical poems with RNN encoder-decoder. In Proceedings of the Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data, Nanjing, China, 13–15 October 2017; pp. 211–223. [Google Scholar]
- Gao, T.; Xiong, P.; Shen, J. A new automatic Chinese poetry generation model based on neural network. In Proceedings of the 2020 IEEE World Congress on Services (SERVICES), Beijing, China, 18–23 October 2020; pp. 41–44. [Google Scholar]
- Liu, Z.; Fu, Z.; Cao, J.; De Melo, G.; Tam, Y.C.; Niu, C.; Zhou, J. Rhetorically controlled encoder-decoder for modern Chinese poetry generation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1992–2001. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv 2019, arXiv:1910.10683. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Virtual, 6–12 December 2020. [Google Scholar]
- Stiennon, N.; Ouyang, L.; Wu, J.; Ziegler, D.M.; Lowe, R.; Voss, C.; Radford, A.; Amodei, D.; Christiano, P. Learning to Summarize with Human Feedback. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Virtual, 6–12 December 2020. [Google Scholar]
- Ziegler, D.M.; Stiennon, N.; Wu, J.; Brown, T.B.; Radford, A.; Amodei, D.; Christiano, P.; Irving, G. Fine-Tuning Language Models from Human Preferences. arXiv 2019, arXiv:1909.08593. [Google Scholar]
- Christiano, P.F.; Leike, J.; Brown, T.; Martic, M.; Legg, S.; Amodei, D. Deep Reinforcement Learning from Human Preferences. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Minsky, M. Steps toward artificial intelligence. Proc. IRE 1961, 49, 8–30. [Google Scholar] [CrossRef]
- Coronato, A.; Naeem, M.; De Pietro, G.; Paragliola, G. Reinforcement learning for intelligent healthcare applications: A survey. Artif. Intell. Med. 2020, 109, 101964. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.; Suescun, J.; Schiess, M.C.; Jiang, X. Computational medication regimen for Parkinson’s disease using reinforcement learning. Sci. Rep. 2021, 11, 9313. [Google Scholar] [CrossRef] [PubMed]
- Nian, R.; Liu, J.; Huang, B. A review on reinforcement learning: Introduction and applications in industrial process control. Comput. Chem. Eng. 2020, 139, 106886. [Google Scholar] [CrossRef]
- Brunke, L.; Greeff, M.; Hall, A.W.; Yuan, Z.; Zhou, S.; Panerati, J.; Schoellig, A.P. Safe learning in robotics: From learning-based control to safe reinforcement learning. Annu. Rev. Control. Robot. Auton. Syst. 2022, 5, 411–444. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Souchleris, K.; Sidiropoulos, G.K.; Papakostas, G.A. Reinforcement Learning in Game Industry—Review, Prospects and Challenges. Appl. Sci. 2023, 13, 2443. [Google Scholar] [CrossRef]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. In Proceedings of the Advances in Neural Information Processing Systems 35, New Orleans, LA, USA, 28 November–9 December 2022; pp. 27730–27744. [Google Scholar]
- Askell, A.; Bai, Y.; Chen, A.; Drain, D.; Ganguli, D.; Henighan, T.; Jones, A.; Joseph, N.; Mann, B.; DasSarma, N.; et al. A general language assistant as a laboratory for alignment. arXiv 2021, arXiv:2112.00861. [Google Scholar]
- Wu, J.; Ouyang, L.; Ziegler, D.M.; Stiennon, N.; Lowe, R.; Leike, J.; Christiano, P. Recursively summarizing books with human feedback. arXiv 2021, arXiv:2109.10862. [Google Scholar]
- Collection of Foreign Poems in Different Schools; Li, H., Translator; Baihua Literature and Art Publishing House: Tianjin, China, 1992. [Google Scholar]
- Eluard. Selected Poems of Eluard; Luo, D., Translator; People’s Literature Publishing House: Beijing, China, 2020. [Google Scholar]
- Rimbaud. Rimbaud Poetry Complete Works; Ge, L.; Liang, D., Translators; Beijing Yanshan Publishing House: Beijing, China, 2016. [Google Scholar]
- Baudelaire. Les Fleurs du Mal; Wen, A., Translator; Jilin Publishing Group: Changchun, China, 2009. [Google Scholar]
- Yang, C.; Sun, M.; Yi, X.; Li, W. Stylistic Chinese Poetry Generation via Unsupervised Style Disentanglement. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3960–3969. [Google Scholar]
- Toivanen, J.M.; Toivonen, H.; Valitutti, A.; Gross, O. Corpus-based generation of content and form in poetry. In Proceedings of the 3rd International Conference on Computational Creativity, Dublin, Ireland, 30 May–1 June 2012; pp. 175–179. [Google Scholar]
- Hämäläinen, M.; Alnajjar, K. Generating modern poetry automatically in Finnish. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 5999–6004. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).