

Enhancing Software Code Vulnerability Detection Using GPT-4o and Claude-3.5 Sonnet: A Study on Prompt Engineering Techniques



Abstract
1. Introduction
2. Theoretical Background
2.1. Large Language Models and GPT
2.2. Comparison of Claude-3.5 Sonnet and GPT-4o
2.3. Previous Studies on Detecting Code Vulnerabilities through Large Language Models
3. Experimental Design
3.1. Collection of Vulnerable Code
3.2. Collection of Secure Code
3.3. Data Preprocessing
- First prompt (default, cut to the chase): Please evaluate if the above code has a CWE-*** vulnerability. Does this code have a CWE-*** vulnerability? (Yes/No). Please rate your confidence in this answer on a scale from 0 to 100, where 100 means very confident and 0 means not confident at all.
- Second prompt (How to set a tip for a good answer): I’m going to tip $500k for a better solution. Please evaluate if the above code has a CWE-*** vulnerability. Does this code have a CWE-*** vulnerability? (Yes/No). Please rate your confidence in this answer on a scale from 0 to 100, where 100 means very confident and 0 means not confident at all.
- Third prompt (a way to encourage you to think in steps): Please evaluate if the above code has a CWE-*** vulnerability. Does this code have a CWE-*** vulnerability? (Yes/No). Please rate your confidence in this answer on a scale from 0 to 100, where 100 means very confident and 0 means not confident at all. Let’s think step by step.
3.4. Evaluation Method
4. Experimental Results
4.1. Analysis of Confusion matrix for GPT-3.5 Turbo
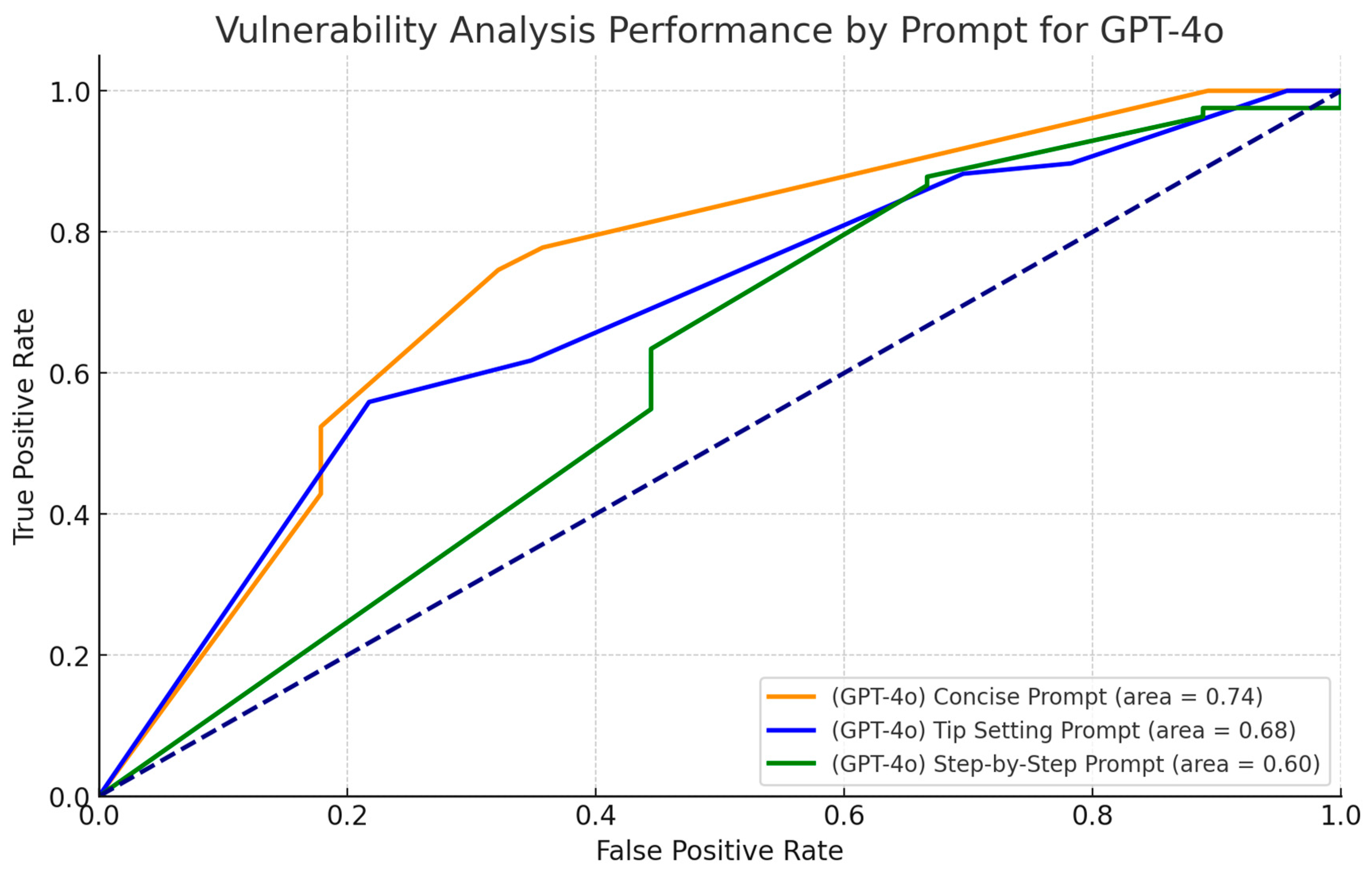
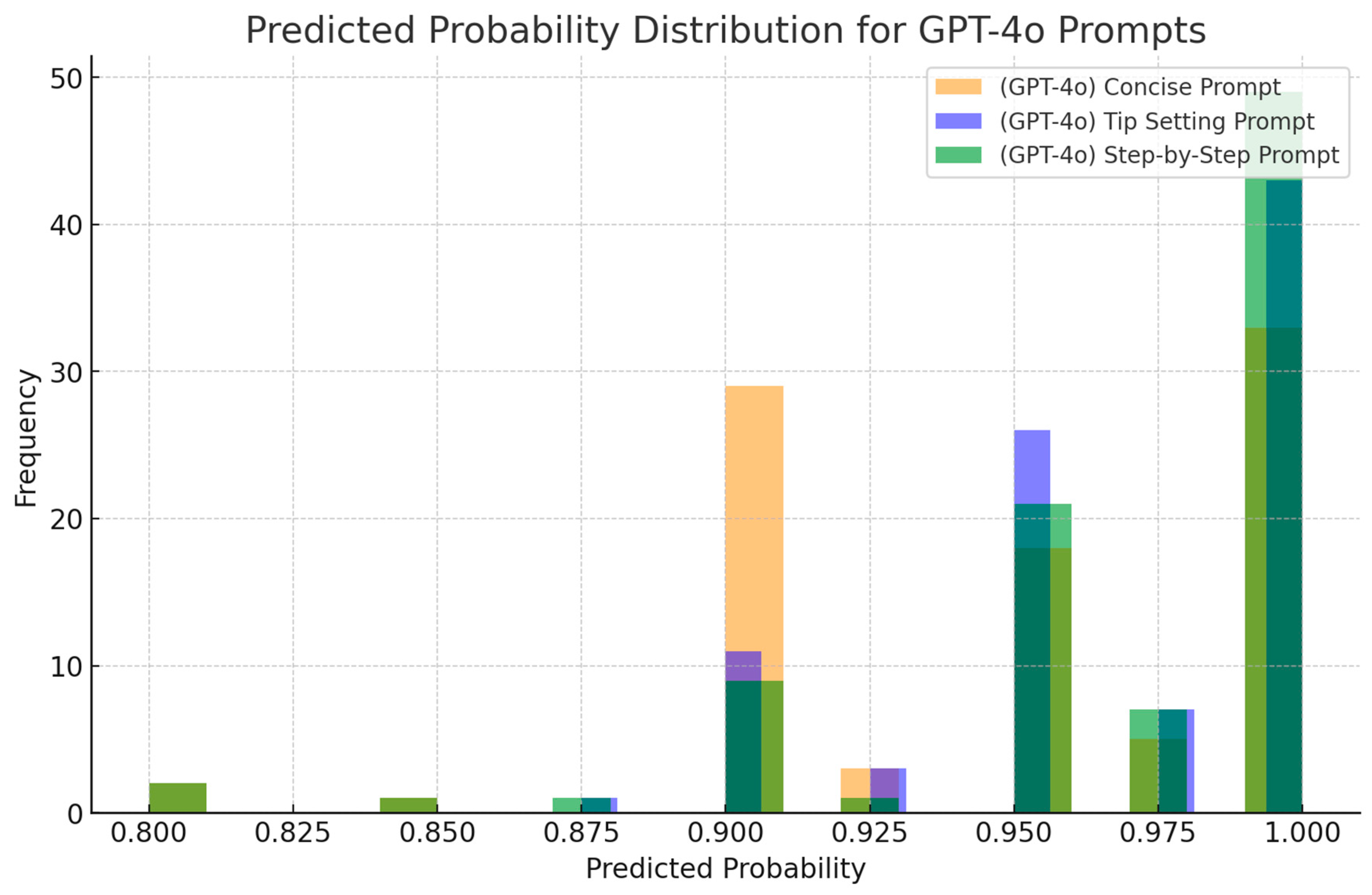
4.2. Analysis of Confusion Matrix for GPT-4o
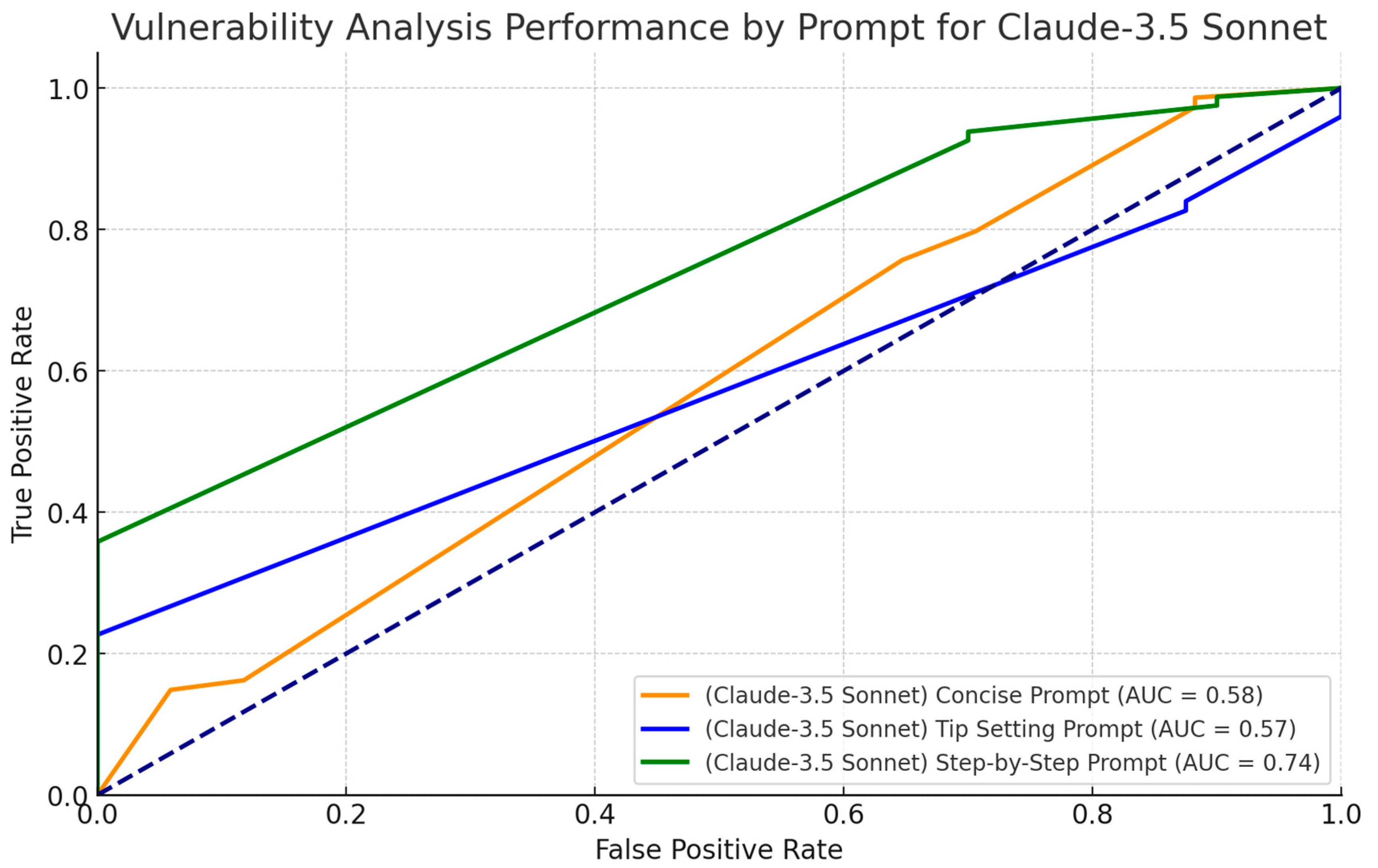
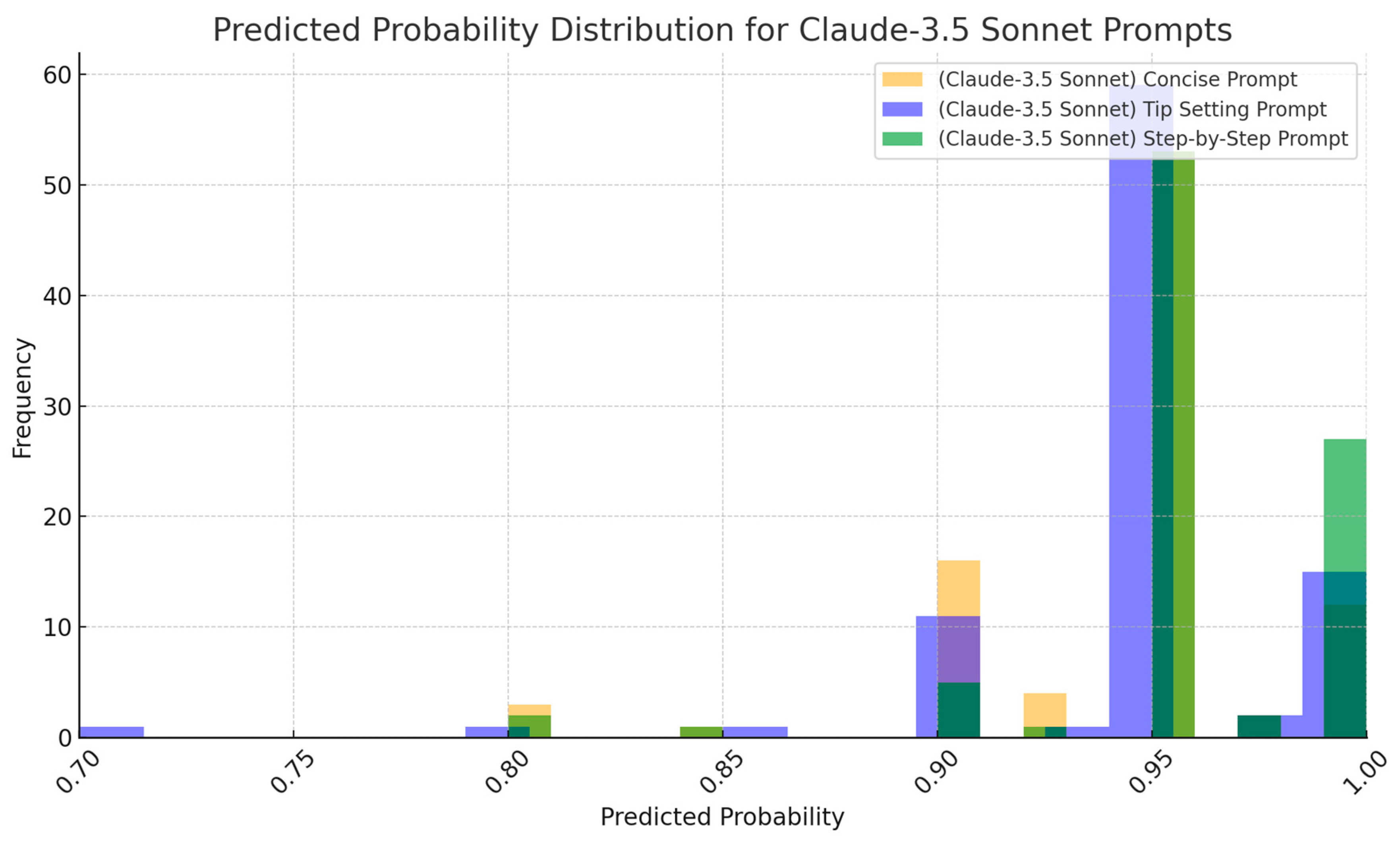
4.3. Analysis of Confusion Matrix for Claude-3.5 Sonnet
4.4. Comparative Performance of the Models
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- The Fourth Industrial Revolution. Available online: https://www.sogeti.com/globalassets/global/special/sogeti-things3en.pdf (accessed on 5 June 2024).
- Lee, M.; Yun, J.J.; Pyka, A.; Won, D.; Kodama, F.; Schiuma, G.; Park, H.; Jeon, J.; Park, K.; Jung, K.; et al. How to Respond to the Fourth Industrial Revolution or the Second Information Technology Revolution? Dynamic New Combinations between Technology, Market, and Society through Open Innovation. J. Open Innov. Technol. Mark. Complex 2018, 4, 21. [Google Scholar] [CrossRef]
- Yang, M.; Zhou, X.; Zeng, J.; Xu, J. Challenges and solutions of information security issues in the age of big data. China Commun. 2016, 13, 193–202. [Google Scholar] [CrossRef]
- Abu Al-Haija, Q. Top-down machine learning-based architecture for cyberattack identification and classification in IoT communication networks. Front. Big. Data 2022, 4, 78292. [Google Scholar] [CrossRef] [PubMed]
- Aslan, Ö.; Aktuğ, S.S.; Ozkan-Okay, M.; Yilmaz, A.A.; Akin, E. A Comprehensive Review of Cyber Security Vulnerabilities, Threats, Attacks, and Solutions. Electronics 2023, 12, 1333. [Google Scholar] [CrossRef]
- Saleous, H.; Ismail, M.; AlDaajeh, S.H.; Madathil, N.; Alrabaee, S.; Choo, K.-K.R.; Al-Qirim, N. COVID-19 pandemic and the cyberthreat landscape: Research challenges and opportunities. Digit. Commun. Netw. 2023, 9, 211–222. [Google Scholar] [CrossRef] [PubMed]
- Jakovljevic, M.; Bjedov, S.; Jaksic, N.; Jakovljevic, I. COVID-19 pandemia and public and global mental health from the perspective of global health security. Psychiatr. Danub. 2020, 32, 6–14. [Google Scholar] [CrossRef] [PubMed]
- Wagner, J.K. Health, housing, and ‘direct threats’ during a pandemic. J. Law Biosci. 2020, 7, lsaa022. [Google Scholar] [CrossRef] [PubMed]
- Internet Crime Complaint Center (IC3). 2023 Internet Crime Report; Federal Bureau of Investigation: Washington, DC, USA, 2023. Available online: https://www.ic3.gov/Media/PDF/AnnualReport/2023_IC3Report.pdf (accessed on 27 June 2024).
- The Evolution of Cyber Threat Intelligence (CTI): 2019 SANS CTI Survey. Available online: https://a51.nl/sites/default/files/pdf/Survey_CTI-2019_IntSights.pdf (accessed on 5 June 2024).
- Jiang, K.; Li, Y.; Feng, L.; Wang, W. Machine Learning in Cybersecurity: A Review. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2017, 7, e1209. [Google Scholar] [CrossRef]
- Liu, L.; Xu, B. Research on information security technology based on blockchain. In Proceedings of the 2018 IEEE 3rd International Conference on Cloud Computing and Big Data Analysis (ICCCBDA), Chengdu, China, 20–22 April 2018; pp. 380–384. [Google Scholar] [CrossRef]
- Prasad, S.G.; Sharmila, V.C.; Badrinarayanan, M.K. Role of Artificial Intelligence based Chat Generative Pre-trained Transformer (ChatGPT) in Cyber Security. In Proceedings of the 2023 2nd International Conference on Applied Artificial Intelligence and Computing (ICAAIC), Salem, India, 4–6 May 2023; pp. 107–114. [Google Scholar] [CrossRef]
- Zhou, X.; Zhang, T.; Lo, D. Large Language Model for Vulnerability Detection: Emerging Results and Future Directions. In Proceedings of the 2024 ACM/IEEE 44th International Conference on Software Engineering: New Ideas and Emerging Results (ICSE-NIER′24), Pittsburgh, PA, USA, 21–29 May 2024; pp. 47–51. [Google Scholar] [CrossRef]
- Chakraborty, S.; Krishna, R.; Ding, Y.; Ray, B. Deep Learning Based Vulnerability Detection: Are We There Yet? IEEE Trans. Softw. Eng. 2022, 48, 3280–3296. [Google Scholar] [CrossRef]
- Bsharat, S.M.; Myrzakhan, A.; Shen, Z. Principled instructions are all you need for questioning LLaMA-1/2, GPT-3.5/4. arXiv 2023, arXiv:16171. Available online: https://arxiv.org/abs/2312.16171 (accessed on 29 May 2024).
- Chiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- OpenAI. Available online: https://openai.com/index/hello-gpt-4o/ (accessed on 29 May 2024).
- Anthropic. Pricing for Claude API. Available online: https://www.anthropic.com/pricing#anthropic-api (accessed on 27 June 2024).
- Anthropic. Claude 3.5 Sonnet News. Available online: https://www.anthropic.com/news/claude-3-5-sonnet (accessed on 27 June 2024).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 62. [Google Scholar] [CrossRef]
- Salloum, S.; Gaber, T.; Vadera, S.; Shaalan, K. Phishing Email Detection Using Natural Language Processing Techniques: A Literature Survey. Procedia Comput. Sci. 2021, 189, 19–28. [Google Scholar] [CrossRef]
- LiveBench. Available online: https://livebench.ai/ (accessed on 29 June 2024).
- Fu, M.; Tantithamthavorn, C.; Nguyen, V.; Le, T. ChatGPT for Vulnerability Detection, Classification, and Repair: How Far Are We? In Proceedings of the 2023 30th Asia-Pacific Software Engineering Conference (APSEC), Seoul, Republic of Korea, 6–9 December 2023; pp. 632–636. [Google Scholar] [CrossRef]
- López Espejel, J.; Ettifouri, E.H.; Yahaya Alassan, M.S.; Chouham, E.M.; Dahhane, W. GPT-3.5, GPT-4, or BARD? Evaluating LLMs reasoning ability in zero-shot setting and performance boosting through prompts. Nat. Lang. Process. J. 2023, 5, 100032. [Google Scholar] [CrossRef]
- Ranaldi, L.; Pucci, G. When Large Language Models contradict humans? Large Language Models’ Sycophantic Behaviour. arXiv 2023, arXiv:2311.09410. [Google Scholar]
- Sosa, D.; Suresh, M.; Potts, C.; Altman, R. Detecting Contradictory COVID-19 Drug Efficacy Claims from Biomedical Literature. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Toronto, Canada, 9–14 July 2023; Association for Computational Linguistics: Baltimore, MD, USA, 2023; pp. 694–713. [Google Scholar]
- CWE. Available online: https://cwe.mitre.org/index.html (accessed on 29 May 2024).
- NIST Software Assurance Reference Dataset (SARD). Available online: https://samate.nist.gov/SARD/ (accessed on 29 May 2024).
- Seacord, R.C. Secure Coding in C and C++, 2nd ed.; Addison-Wesley Professional: Boston, MA, USA, 2013; pp. 1–601. [Google Scholar]
- Ministry of Science and ICT; Korea Internet & Security Agency. Python Secure Coding Guide, 1st ed.; Ministry of Science and ICT: Sejong, Republic of Korea, 2023; pp. 1–176. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GPT-3.5 Turbo | GPT-4 Turbo | GPT-4o | Claude-3.5 Sonnet | |
|---|---|---|---|---|
| Input (1M Tokens) | USD0.5 | USD10 | USD5 | USD3 |
| Output (1M Tokens) | USD1.5 | USD30 | USD15 | USD15 |
| Context Window | 16,000 | 128,000 | 128,000 | 200,000 |
| GPT-3.5 Turbo | GPT-4 | GPT-4 Turbo | GPT-4o | |
|---|---|---|---|---|
| MMLU | 70.0% 5-shot | 86.4% 5-shot | 86.5% 5-shot | 88.7% 5-shot |
| HumanEval | 48.1% 0-shot | 67.0% 0-shot | 87.1% 0-shot | 90.2% 0-shot |
| DROP (F1 score) | 64.1 3-shot | 80.9 3-shot | 86.0 3-shot | 83.4 3-shot |
| GPQA | 28.1% 0-shot | 35.7% 0-shot | 48.0% 0-shot | 53.6% 0-shot |
| MGSM | - | 74.5% 0-shot CoT | 88.5% 0-shot CoT | 90.5% 0-shot CoT |
| Claude-3.5 Sonnet | Claude 3 Opus | GPT-4 Turbo | GPT-4o | |
|---|---|---|---|---|
| MMLU | 88.7% 5-shot | 86.8% 5-shot | 86.5% 5-shot | 88.7% 5-shot |
| HumanEval | 92.0% 0-shot | 84.9% 0-shot | 87.1% 0-shot | 90.2% 0-shot |
| DROP (F1 score) | 87.1 3-shot | 83.1 3-shot | 86.0 3-shot | 83.4 3-shot |
| GPQA | 59.4% 0-shot | 50.4% 0-shot | 48.0% 0-shot | 53.6% 0-shot |
| MGSM | 91.6% 0-shot CoT | 90.7% 0-shot CoT | 88.5% 0-shot CoT | 90.5% 0-shot CoT |
| CWE | Number of Collected Test Cases |
|---|---|
| CWE-20 | 2 |
| CWE-22 | 3 |
| CWE-77 | 1 |
| CWE-79 | 10 |
| CWE-89 | 10 |
| CWE-99 | 5 |
| CWE-119 | 4 |
| CWE-259 | 1 |
| CWE-391 | 1 |
| CWE-457 | 2 |
| CWE-476 | 3 |
| CWE-489 | 1 |
| CWE | Number of Collected Test Cases |
|---|---|
| CWE-78 | 6 |
| CWE-79 | 6 |
| CWE-89 | 5 |
| CWE-121 | 1 |
| CWE-122 | 3 |
| CWE-259 | 6 |
| CWE-367 | 1 |
| CWE-391 | 2 |
| CWE-401 | 1 |
| CWE-412 | 1 |
| CWE-457 | 3 |
| CWE-468 | 1 |
| CWE-476 | 5 |
| CWE-489 | 2 |
| Predicted Class | |||
|---|---|---|---|
| Positive | Negative | ||
| Actual Class | P (Positive) | TP (True Positive) | FN (False Negative) |
| N (Negative) | FP (False Positive) | TN (True Negative) | |
| Predicted Class | |||
|---|---|---|---|
| Positive | Negative | ||
| Actual Class | P (Positive) | 42 | 1 |
| N (Negative) | 40 | 8 | |
| Predicted Class | |||
|---|---|---|---|
| Positive | Negative | ||
| Actual Class | P (Positive) | 43 | 0 |
| N (Negative) | 41 | 7 | |
| Predicted Class | |||
|---|---|---|---|
| Positive | Negative | ||
| Actual Class | P (Positive) | 42 | 1 |
| N (Negative) | 44 | 4 | |
| Accuracy | Precision | Recall | F1 Score | |
|---|---|---|---|---|
| Concise Prompt | 0.5495 | 0.5122 | 0.9767 | 0.6720 |
| Tip Setting Prompt | 0.5495 | 0.5119 | 1.0 | 0.6772 |
| Step-by-Step Prompt | 0.5055 | 0.4884 | 0.9767 | 0.6512 |
| Predicted Class | |||
|---|---|---|---|
| Positive | Negative | ||
| Actual Class | P (Positive) | 36 | 7 |
| N (Negative) | 21 | 27 | |
| Predicted Class | |||
|---|---|---|---|
| Positive | Negative | ||
| Actual Class | P (Positive) | 39 | 4 |
| N (Negative) | 19 | 29 | |
| Predicted Class | |||
|---|---|---|---|
| Positive | Negative | ||
| Actual Class | P (Positive) | 43 | 0 |
| N (Negative) | 9 | 39 | |
| Accuracy | Precision | Recall | F1 Score | |
|---|---|---|---|---|
| Concise Prompt | 0.6923 | 0.6316 | 0.8372 | 0.7200 |
| Tip Setting Prompt | 0.7473 | 0.6724 | 0.9070 | 0.7723 |
| Step-by-Step Prompt | 0.9022 | 0.8302 | 1.0 | 0.9072 |
| Predicted Class | |||
|---|---|---|---|
| Positive | Negative | ||
| Actual Class | P (Positive) | 40 | 3 |
| N (Negative) | 14 | 34 | |
| Predicted Class | |||
|---|---|---|---|
| Positive | Negative | ||
| Actual Class | P (Positive) | 42 | 1 |
| N (Negative) | 15 | 33 | |
| Predicted Class | |||
|---|---|---|---|
| Positive | Negative | ||
| Actual Class | P (Positive) | 42 | 1 |
| N (Negative) | 9 | 39 | |
| Accuracy | Precision | Recall | F1 Score | |
|---|---|---|---|---|
| Concise Prompt | 0.8132 | 0.7407 | 0.9302 | 0.8247 |
| Tip Setting Prompt | 0.8242 | 0.7368 | 0.9767 | 0.8392 |
| Step-by-Step Prompt | 0.8901 | 0.8235 | 0.9767 | 0.8933 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bae, J.; Kwon, S.; Myeong, S. Enhancing Software Code Vulnerability Detection Using GPT-4o and Claude-3.5 Sonnet: A Study on Prompt Engineering Techniques. Electronics 2024, 13, 2657. https://doi.org/10.3390/electronics13132657
Bae J, Kwon S, Myeong S. Enhancing Software Code Vulnerability Detection Using GPT-4o and Claude-3.5 Sonnet: A Study on Prompt Engineering Techniques. Electronics. 2024; 13(13):2657. https://doi.org/10.3390/electronics13132657
Chicago/Turabian StyleBae, Jaehyeon, Seoryeong Kwon, and Seunghwan Myeong. 2024. "Enhancing Software Code Vulnerability Detection Using GPT-4o and Claude-3.5 Sonnet: A Study on Prompt Engineering Techniques" Electronics 13, no. 13: 2657. https://doi.org/10.3390/electronics13132657
APA StyleBae, J., Kwon, S., & Myeong, S. (2024). Enhancing Software Code Vulnerability Detection Using GPT-4o and Claude-3.5 Sonnet: A Study on Prompt Engineering Techniques. Electronics, 13(13), 2657. https://doi.org/10.3390/electronics13132657