



Beam Prediction for mmWave V2I Communication Using ML-Based Multiclass Classification Algorithms

 , ,
, ,
Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
3.1. Dataset Description
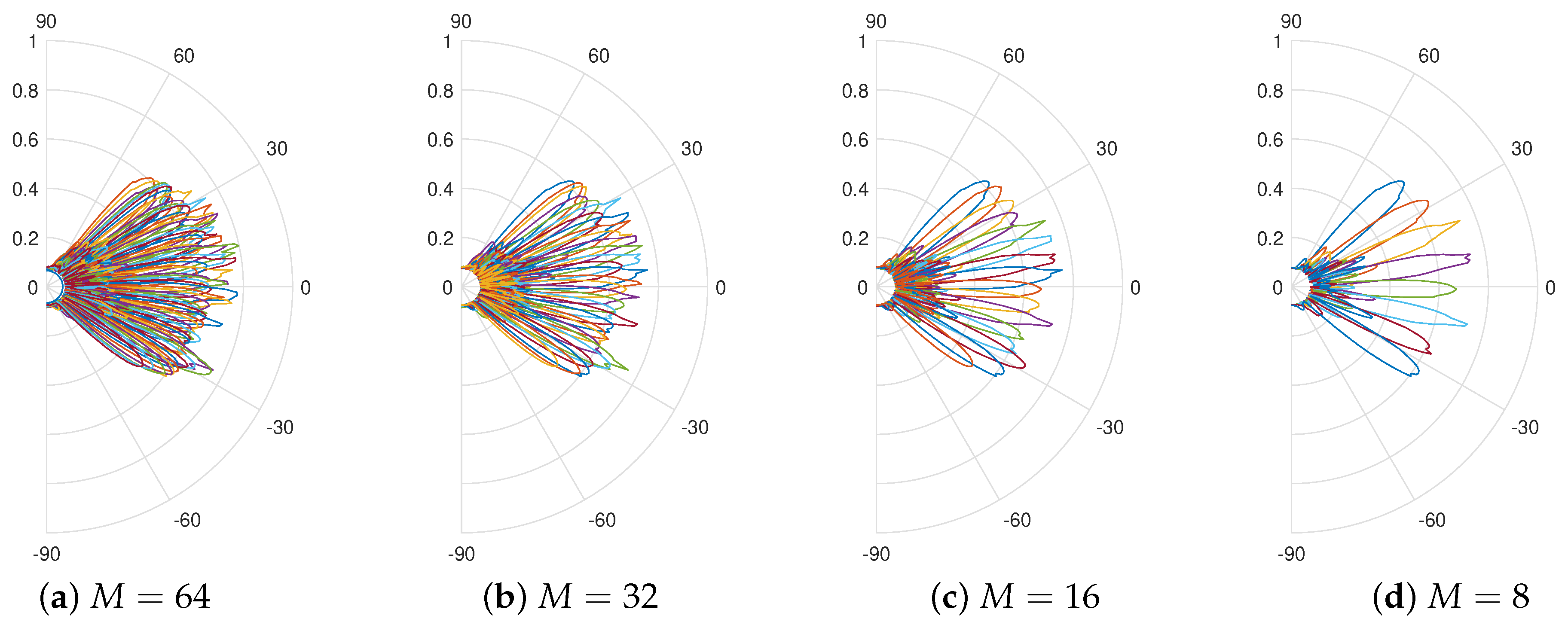
3.2. Codebook Sizes and Data Split Ratios
3.3. ML Classification Algorithms
3.3.1. Nearest Neighbours
3.3.2. Support Vector Machines
3.3.3. Decision Trees
3.3.4. Naïve Bayes
3.4. Performance Evaluation Metrics
- Accuracy: This is a widely used metric for multi-class classification that can be directly derived from the confusion matrix using Equation (1). It represents the probability that the model’s prediction is accurate (i.e., how much of the predictions match the ground truths) [31].where TP is true positives, TN is true negatives, FP is false positives, and FN is false negatives.
- Precision: This measures the model’s ability to identify instances of a particular class correctly. It is the number of correctly classified positive samples (i.e., true positives) divided by the number of samples labeled by the system as positive, as given by Equation (2). It indicates how much we can trust the model when it predicts samples as positive.
- Recall: This measures the model’s ability to identify all instances of a particular class. It is the number of the correctly classified positive samples divided by the number of positive samples in the data, as given by Equation (3). It measures the ability of the model to find all the positive samples in the dataset [31]. Recall is also known as the true positive rate (TPR) or sensitivity.
- Specificity: This measures the model’s ability to identify negative instances of a particular class. It is the number of the correctly classified negative samples divided by the sum of the true negatives and false positives in the data, as given by Equation (4) [31]. Specificity is also known as the true negative rate (TNR)
- F1-score: This metric provides a comprehensive assessment of a classification model’s performance, taking into account both the ability to correctly identify positive instances (precision) and the ability to capture all positive instances (recall). It aggregates the precision and recall measures under the concept of harmonic mean, and its formula can be interpreted as a weighted average between precision and recall [31]. F1-score is evaluated using Equation (5). The F1-score ranges from 0 to 1, where a score of 1 indicates perfect precision and recall while a score of 0 indicates poor performance. In practice, F1-score values closer to 1 are desirable, as they indicate a well-balanced trade-off between precision and recall.
4. Performance Evaluation Results
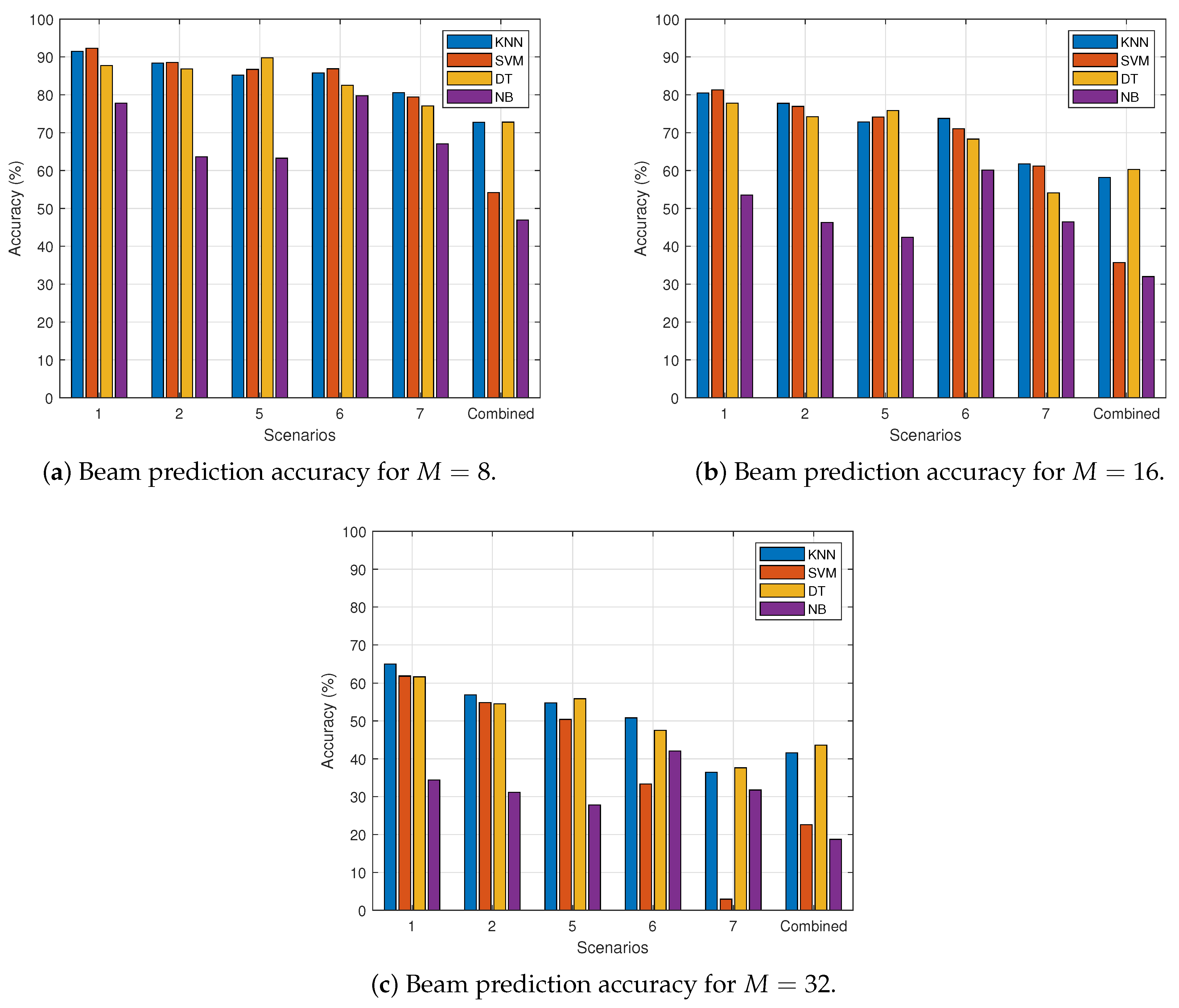
4.1. Impact of Codebook Size
4.2. Impact of Dataset Split Ratio
4.3. Confusion Matrices for the Combined Scenario
- The number of samples or datapoints used in both works are slightly different. For example, the datapoints used in [16] for Scenarios 1, 6, and 7 are 2667, 1011, and 897, respectively (as in Figure 1 of [16]), as against the corresponding 2441, 915, and 854 samples in the publicly-released dataset used in this work, as presented in Table 2 and available in [19]. The number of samples used for Scenarios 2 and 5 are unavailable in [16].
- The combined results in [16] are averaged over nine scenarios, while the combined results in this work are averaged over five scenarios.
- In [16], the GPS coordinates are employed directly as ML features, while the coordinates are converted first to cartesian coordinates in this work as part of the preprocessing steps before being used as the ML features.
5. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ballesteros, C.; Montero, L.; Ramírez, G.A.; Jofre-Roca, L. Multi-antenna 3D pattern design for millimeter-wave vehicular communications. Veh. Commun. 2022, 35, 100473. [Google Scholar] [CrossRef]
- Decarli, N.; Guerra, A.; Giovannetti, C.; Guidi, F.; Masini, B.M. V2X Sidelink Localization of Connected Automated Vehicles. IEEE J. Sel. Areas Commun. 2024, 42, 120–133. [Google Scholar] [CrossRef]
- Heng, Y.; Andrews, J.G. Machine Learning-Assisted Beam Alignment for mmWave Systems. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019. [Google Scholar]
- Va, V.; Shimizu, T.; Bansal, G.; Heath, R.W. Online Learning for Position-Aided Millimeter Wave Beam Training. IEEE Access 2019, 7, 30507–30526. [Google Scholar] [CrossRef]
- Busari, S.A.; Khan, M.A.; Huq, K.M.S.; Mumtaz, S.; Rodriguez, J. Millimetre-wave massive MIMO for cellular vehicle-to-infrastructure communication. IET Intell. Transp. Syst. 2019, 13, 983–990. [Google Scholar] [CrossRef]
- Attaoui, W.; Bouraqia, K.; Sabir, E. Initial Access & Beam Alignment for mmWave and Terahertz Communications. IEEE Access 2022, 10, 35363–35397. [Google Scholar] [CrossRef]
- Sun, C.; Zhao, L.; Cui, T.; Li, H.; Bai, Y.; Wu, S.; Tong, Q. AI model Selection and Monitoring for Beam Management in 5G-Advanced. IEEE Open J. Commun. Soc. 2024, 5, 38–40. [Google Scholar] [CrossRef]
- Choi, J.; Va, V.; Gonzalez-Prelcic, N.; Daniels, R.; Bhat, C.R.; Heath, R.W. Millimeter-Wave Vehicular Communication to Support Massive Automotive Sensing. IEEE Commun. Mag. 2016, 54, 160–167. [Google Scholar] [CrossRef]
- Yang, Z.; Chen, M.; Wong, K.; Poor, H.V.; Cui, S. Federated Learning for 6G: Applications, Challenges, and Opportunities. Engineering 2022, 8, 33–41. [Google Scholar] [CrossRef]
- Ali, S.; Saad, W.; Rajatheva, N.; Chang, K.; Steinbach, D.; Sliwa, B.; Wietfeld, C.; Mei, K.; Shiri, H.; Zepernick, H.; et al. 6G White Paper on Machine Learning in Wireless Communication Networks. arXiv 2020, arXiv:2004.13875. [Google Scholar]
- Burghal, D.; Abbasi, N.A.; Molisch, A.F. A Machine Learning Solution for Beam Tracking in mmWave Systems. In Proceedings of the 2019 53rd IEEE Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 3–6 November 2019; pp. 173–177. [Google Scholar]
- Wang, Y.; Klautau, A.; Ribero, M.; Soong, A.C.K.; Heath, R.W. MmWave Vehicular Beam Selection with Situational Awareness Using Machine Learning. IEEE Access 2019, 7, 87479–87493. [Google Scholar] [CrossRef]
- Arvinte, M.; Tavares, M.; Samardzija, D. Beam Management in 5G NR using Geolocation Side Information. In Proceedings of the 2019 53rd IEEE Annual Conference on Information Sciences and Systems (CISS), Baltimore, MD, USA, 20–22 March 2019; pp. 1–6. [Google Scholar]
- Jiang, S.; Charan, G.; Alkhateeb, A. LiDAR Aided Future Beam Prediction in Real-World Millimeter Wave V2I Communications. IEEE Wirel. Commun. Lett. 2023, 12, 212–216. [Google Scholar] [CrossRef]
- Echigo, H.; Cao, Y.; Bouazizi, M.; Ohtsuki, T. A Deep Learning-Based Low Overhead Beam Selection in mmWave Communications. IEEE Trans. Veh. Technol. 2021, 70, 682–691. [Google Scholar] [CrossRef]
- Morais, J.; Bchboodi, A.; Pezeshki, H.; Alkhateeb, A. Position-Aided Beam Prediction in the Real World: How Useful GPS Locations Actually are? In Proceedings of the 2023 IEEE International Conference on Communications, Rome, Italy, 28 May–1 June 2023; pp. 1824–1829. [Google Scholar]
- Charan, G.; Osman, T.; Hredzak, A.; Thawdar, N.; Alkhateeb, A. Vision-Position Multi-Modal Beam Prediction Using Real Millimeter Wave Datasets. In Proceedings of the 2022 IEEE International Conference on Communications, Austin, TX, USA, 10–13 April 2022; pp. 2727–2731. [Google Scholar] [CrossRef]
- Makadia, O.B.; Patel, D.K.; Shah, K.D.; Raval, M.S.; Zaveri, M.; Merchant, S.N. Millimeter-Wave Vehicle-to-Infrastructure Communications for Autonomous Vehicles: Location-Aided Beam Forecasting in 6G. In Proceedings of the 2024 16th International Conference on COMmunication Systems & NETworkS (COMSNETS), Bengaluru, India, 3–7 January 2024; pp. 1100–1105. [Google Scholar] [CrossRef]
- A Large-Scale Real-World Multi-Modal Sensing and Communication Dataset for 6G Deep Learning Research. Available online: https://www.deepsense6g.net/ (accessed on 10 April 2024).
- Alkhateeb, A.; Charan, G.; Osman, T.; Hredzak, A.; Morais, J.; Demirhan, U.; Srinivas, N. DeepSense 6G: A Large-Scale Real-World Multi-Modal Sensing and Communication Dataset. IEEE Commun. Mag. 2023, 61, 122–128. [Google Scholar] [CrossRef]
- Roberts, I.P. MIMO for MATLAB: A Toolbox for Simulating MIMO Communication Systems in MATLAB. January 2021. Available online: http://mimoformatlab.com (accessed on 15 May 2024).
- Cervantes, J.; Garcia-Lamont, F.; Rodrıguez-Mazahua, L.; Lopez, A. A comprehensive survey on support vector machine classification: Applications, challenges and trends. Neurocomputing 2020, 408, 189–215. [Google Scholar] [CrossRef]
- Platt, J.C.; Cristianini, N.; Shawe-Taylor, J. Large Margin DAGs for Multiclass Classification. In Advances in Neural Information Processing Systems 12 (NIPS 1999); MIT Press: Cambridge, MA, USA, 1999; pp. 547–553. [Google Scholar]
- Pilario, K.E. Binary and Multi-Class SVM. MATLAB Central File Exchange. Available online: https://www.mathworks.com/matlabcentral/fileexchange/65232-binary-and-multi-class-svm (accessed on 10 April 2024).
- Rokach, L.; Maimon, O. Decision Trees. In Data Mining and Knowledge Discovery Handbook; Springer: New York, NY, USA, 2005; pp. 165–192. [Google Scholar]
- Song, Y.Y.; Lu, Y. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 45, 130–135. [Google Scholar]
- Fletcher, S.; Islam, M.Z. Decision Tree Classification with Differential Privacy: A Survey. ACM Comput. Surv. 2019, 52, 83. [Google Scholar] [CrossRef]
- Guleria, K.; Sharma, S.; Kumar, S.; Tiwari, S. Early prediction of hypothyroidism and multiclass classification using predictive machine learning and deep learning. Meas. Sens. 2022, 24, 100482. [Google Scholar] [CrossRef]
- Farid, D.M.; Rahman, M.M.; Al-Mamuny, M.A. Efficient and scalable multi-class classification using Naïve Bayes tree. In Proceedings of the 2014 International Conference on Informatics, Electronics & Vision (ICIEV), Dhaka, Bangladesh, 23–24 May 2014; pp. 1–4. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Margherita, G.; Enrico, B.; Giorgio, V. Metrics for Multi-Class Classification: An Overview. arXiv 2020, arXiv:2008.05756. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario * Number | Time & Weather | Total Samples | Number of Samples | |||||
|---|---|---|---|---|---|---|---|---|
| 80:20 Split | 70:30 Split | 60:40 Split | ||||||
| Train (80%) | Test (20%) | Train (70%) | Test (30%) | Train (60%) | Test (40%) | |||
| 1 | Day, Clear | 2411 | 1929 | 482 | 1688 | 723 | 1447 | 964 |
| 2 | Night, Clear | 2974 | 2380 | 594 | 2082 | 892 | 1784 | 1190 |
| 5 | Night, Rainy | 2300 | 1840 | 460 | 1610 | 690 | 1380 | 920 |
| 6 | Day, Clear | 915 | 732 | 183 | 641 | 274 | 549 | 366 |
| 7 | Day, Clear | 854 | 684 | 170 | 598 | 256 | 512 | 342 |
| Combined | Mixed | 9454 | 7564 | 1890 | 6618 | 2836 | 5672 | 3782 |
| 64 Beams | 32 Beams | 16 Beams | 8 Beams |
|---|---|---|---|
| 1, 2 | 1 | 1 | 1 |
| 3, 4 | 2 | ||
| 5, 6 | 3 | 2 | |
| 7, 8 | 4 | ||
| 9, 10 | 5 | 3 | 2 |
| 11, 12 | 6 | ||
| 13, 14 | 7 | 4 | |
| 15, 16 | 8 | ||
| 17, 18 | 9 | 5 | 3 |
| 19, 20 | 10 | ||
| 21, 22 | 11 | 6 | |
| 23, 24 | 12 | ||
| 25, 26 | 13 | 7 | 4 |
| 27, 28 | 14 | ||
| 29, 30 | 15 | 8 | |
| 31, 32 | 16 | ||
| 33, 34 | 17 | 9 | 5 |
| 35, 36 | 18 | ||
| 37, 38 | 19 | 10 | |
| 39, 40 | 20 | ||
| 41, 42 | 21 | 11 | 6 |
| 43, 44 | 22 | ||
| 45, 46 | 23 | 12 | |
| 47, 48 | 24 | ||
| 49, 50 | 25 | 13 | 7 |
| 51, 52 | 26 | ||
| 53, 54 | 27 | 14 | |
| 55, 56 | 28 | ||
| 57, 58 | 29 | 15 | 8 |
| 59, 60 | 30 | ||
| 61, 62 | 31 | 16 | |
| 63, 64 | 32 |
| Predicted Beams’ Misclassification (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ||
| 1 | * | 7.30 | 0.33 | 1.66 | 0.33 | 0.66 | |||
| 2 | 12.77 | * | 12.41 | 0.36 | |||||
| Ground | 3 | 1.16 | 7.54 | * | 10.50 | 0.58 | |||
| Truth | 4 | 0.55 | 19.67 | * | 18.58 | 1.64 | |||
| Beams | 5 | 0.48 | 0.96 | 16.35 | * | 15.59 | 1.44 | ||
| 6 | 0.48 | 0.96 | 17.70 | * | 18.66 | 3.83 | |||
| 7 | 0.45 | 3.62 | 16.72 | * | 12.67 | ||||
| 8 | 1.43 | 7.86 | 17.14 | * | |||||
| Algorithm | Accuracy | Precision | Recall | Specificity | F1-Score |
|---|---|---|---|---|---|
| KNN | 0.7275 | 0.7102 | 0.7098 | 0.9494 | 0.7100 |
| SVM | 0.5418 | 0.5288 | 0.5032 | 0.8918 | 0.5157 |
| DT | 0.7280 | 0.7119 | 0.7107 | 0.9494 | 0.7113 |
| NB | 0.4693 | 0.4849 | 0.4297 | 0.8620 | 0.4556 |
| Algorithm | Accuracy | Precision | Recall | Specificity | F1-Score |
|---|---|---|---|---|---|
| KNN | 0.5820 | 0.5462 | 0.5407 | 0.9543 | 0.5435 |
| SVM | 0.3571 | 0.3369 | 0.2998 | 0.8823 | 0.3175 |
| DT | 0.6032 | 0.5753 | 0.5716 | 0.9582 | 0.5735 |
| NB | 0.3201 | 0.3000 | 0.2739 | 0.8564 | 0.2863 |
| Algorithm | Accuracy | Precision | Recall | Specificity | F1-Score |
|---|---|---|---|---|---|
| KNN | 0.4158 | 0.3828 | 0.3623 | 0.9552 | 0.3723 |
| SVM | 0.2260 | 0.1686 | 0.1527 | 0.8765 | 0.1603 |
| DT | 0.4360 | 0.4035 | 0.3798 | 0.9587 | 0.3913 |
| NB | 0.1873 | 0.2013 | 0.1798 | 0.8632 | 0.1900 |
| Scenario | ||||||
|---|---|---|---|---|---|---|
| Number | [16] | This Work | [16] | This Work | [16] | This Work |
| 1 | 0.7134 | 0.6494 | 0.8617 | 0.8050 | 0.9024 | 0.9149 |
| 2 | 0.6002 | 0.5690 | 0.7899 | 0.7778 | 0.8805 | 0.8838 |
| 5 | 0.5591 | 0.5478 | 0.7473 | 0.7283 | 0.8402 | 0.8522 |
| 6 | 0.6391 | 0.5082 | 0.7943 | 0.7377 | 0.9063 | 0.8579 |
| 7 | 0.4182 | 0.3647 | 0.6253 | 0.6177 | 0.7623 | 0.8059 |
| Combined | 0.5250 | 0.4159 | 0.5815 | 0.5820 | 0.8020 | 0.7275 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Biliaminu, K.K.; Busari, S.A.; Rodriguez, J.; Gil-Castiñeira, F. Beam Prediction for mmWave V2I Communication Using ML-Based Multiclass Classification Algorithms. Electronics 2024, 13, 2656. https://doi.org/10.3390/electronics13132656
Biliaminu KK, Busari SA, Rodriguez J, Gil-Castiñeira F. Beam Prediction for mmWave V2I Communication Using ML-Based Multiclass Classification Algorithms. Electronics. 2024; 13(13):2656. https://doi.org/10.3390/electronics13132656
Chicago/Turabian StyleBiliaminu, Karamot Kehinde, Sherif Adeshina Busari, Jonathan Rodriguez, and Felipe Gil-Castiñeira. 2024. "Beam Prediction for mmWave V2I Communication Using ML-Based Multiclass Classification Algorithms" Electronics 13, no. 13: 2656. https://doi.org/10.3390/electronics13132656
APA StyleBiliaminu, K. K., Busari, S. A., Rodriguez, J., & Gil-Castiñeira, F. (2024). Beam Prediction for mmWave V2I Communication Using ML-Based Multiclass Classification Algorithms. Electronics, 13(13), 2656. https://doi.org/10.3390/electronics13132656