
RMBCC: A Replica Migration-Based Cooperative Caching Scheme for Information-Centric Networks

Abstract
1. Introduction
- Replica placement: RMBCC does not participate in the replica placement process directly. Instead, it can be integrated with any advanced on-path caching strategy to ensure low overhead of the cache decision process.
- Proactive cache purging: In addition to regular replica replacement, RMBCC also introduces a proactive cache purging function for local replica management, which proactively evicts replicas based on specific rules to free up storage space.
- Independent Replica Migration: RMBCC filters the replicas evicted from the local cache (including replicas generated by the replica replacement and cache purging process) and migrates the replicas that are still worth caching to neighboring nodes with sufficient cache resources through node cooperation.
- Cooperation cost control: RMBCC controls the number of migrated replicas by filtering the evicted replicas, and limits the cooperation scope of nodes through migration distance constraints and hop-by-hop migration request propagation, so as to avoid incurring excessive transmission costs. Additionally, the data of the migrated replicas can be selectively transmitted at off-peak times to avoid network congestion and make full use of the idle bandwidth.
2. Related Work
2.1. On-Path Caching
2.2. Off-Path Caching
2.3. Hybrid Caching
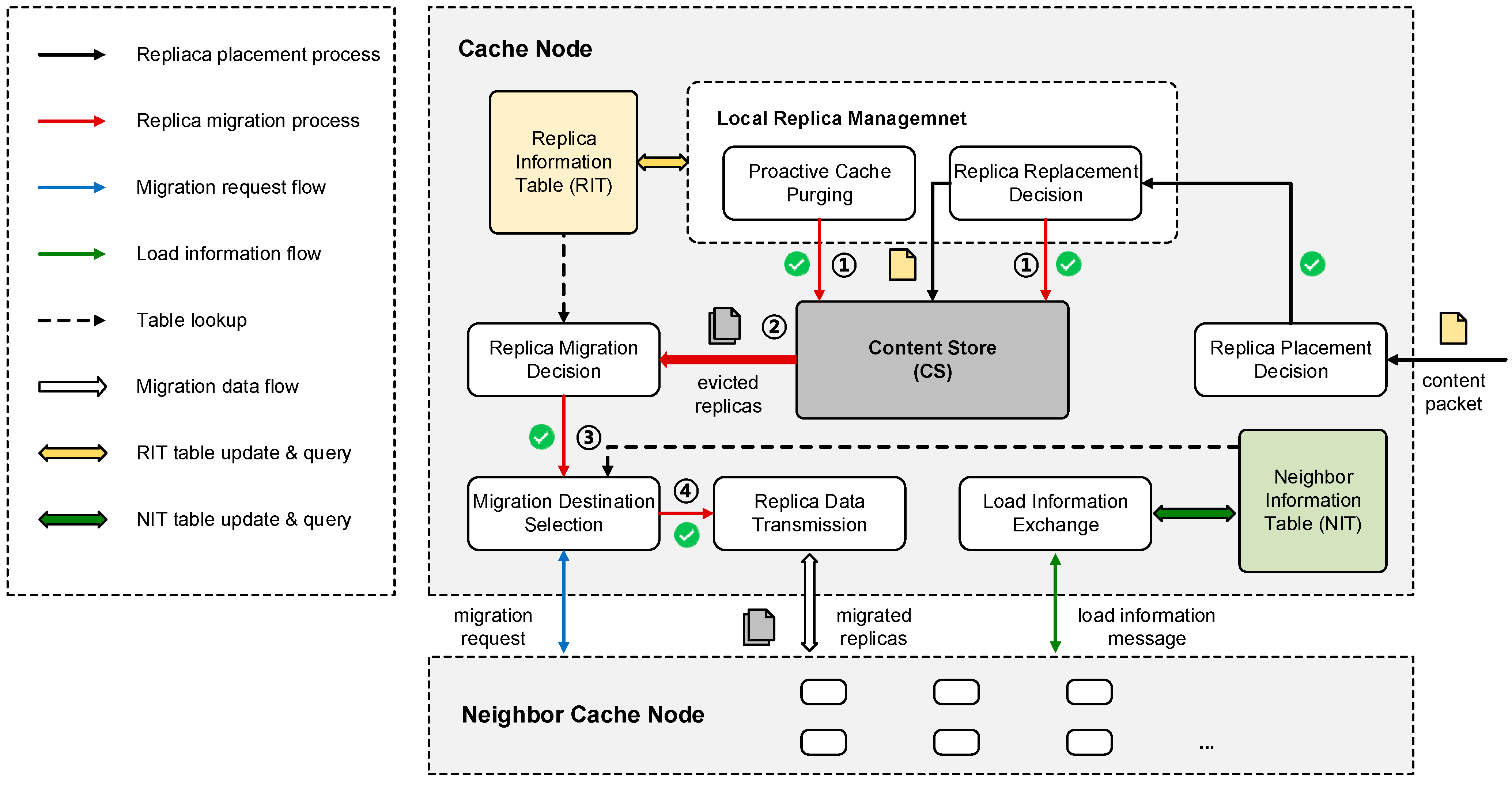
3. Replica Migration-Based Cooperative Caching (RMBCC) Scheme
3.1. Overview
3.2. Replica Migration Decision
| Algorithm 1: Replica_migration_decision |
| Input: Cache node: ; Cache occupancy threshold: Output: Migration decision result: Initialization: , ,
|
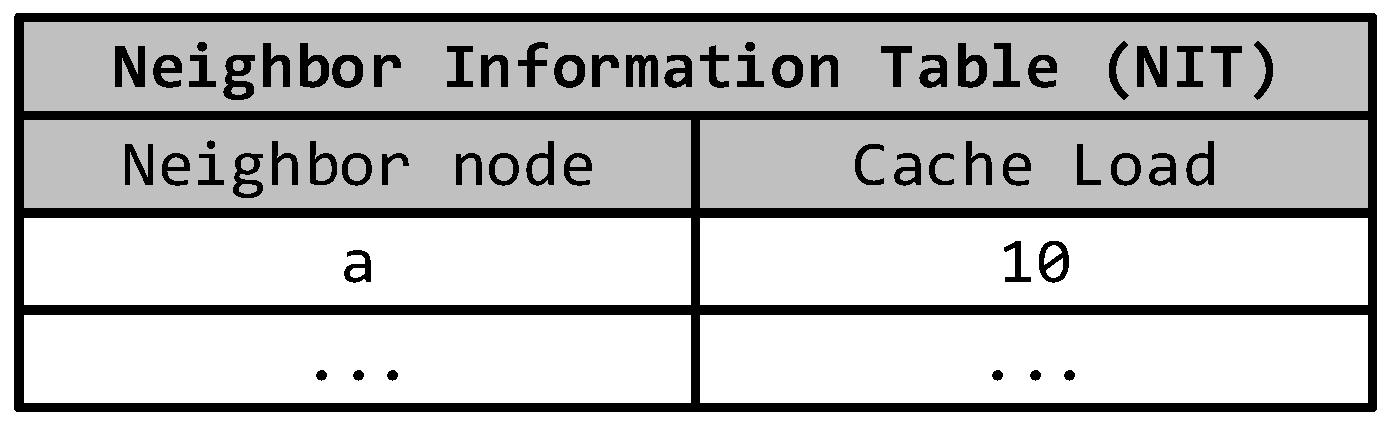
3.3. Migration Destination Selection
| Algorithm 2: Migration_destination_selection |
| Input: Migration source node: ; Evicted replica: ; Output: Destination node: ; Initialization:
|
4. Performance Evaluation
4.1. Simulation Set-Up
4.2. Evaluation Metrics
- (1)
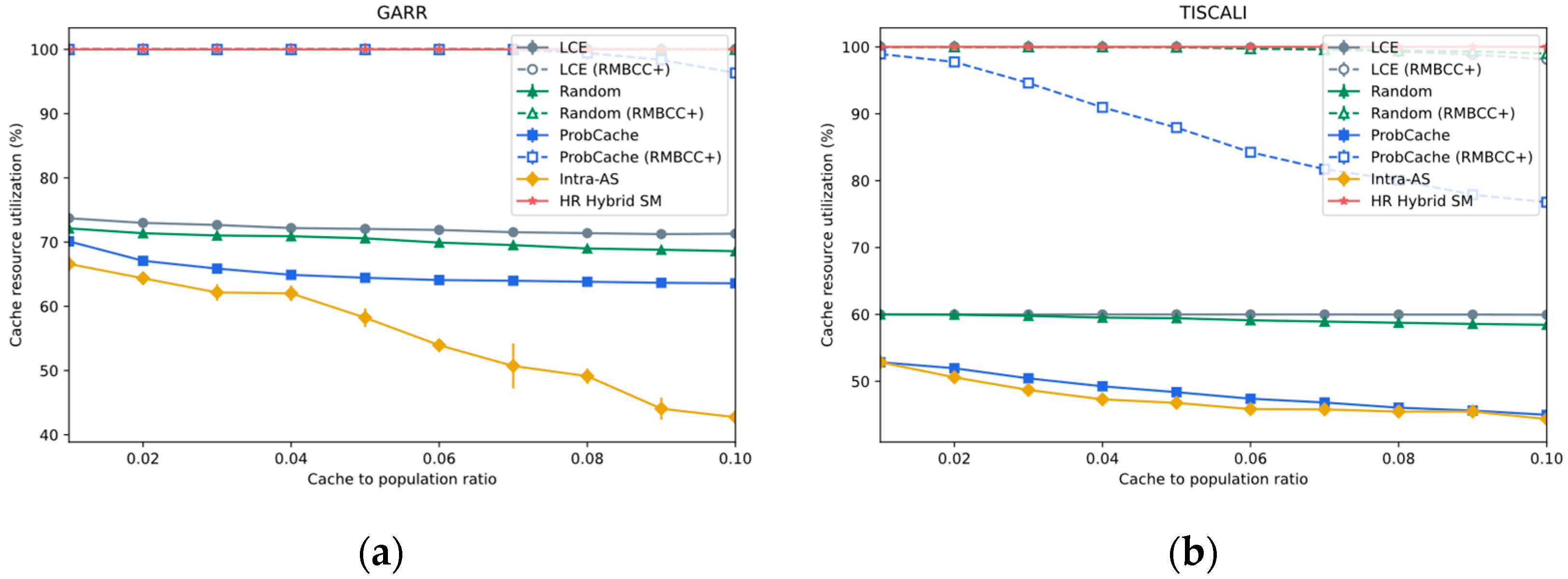
- Cache Resource Utilization
- (2)
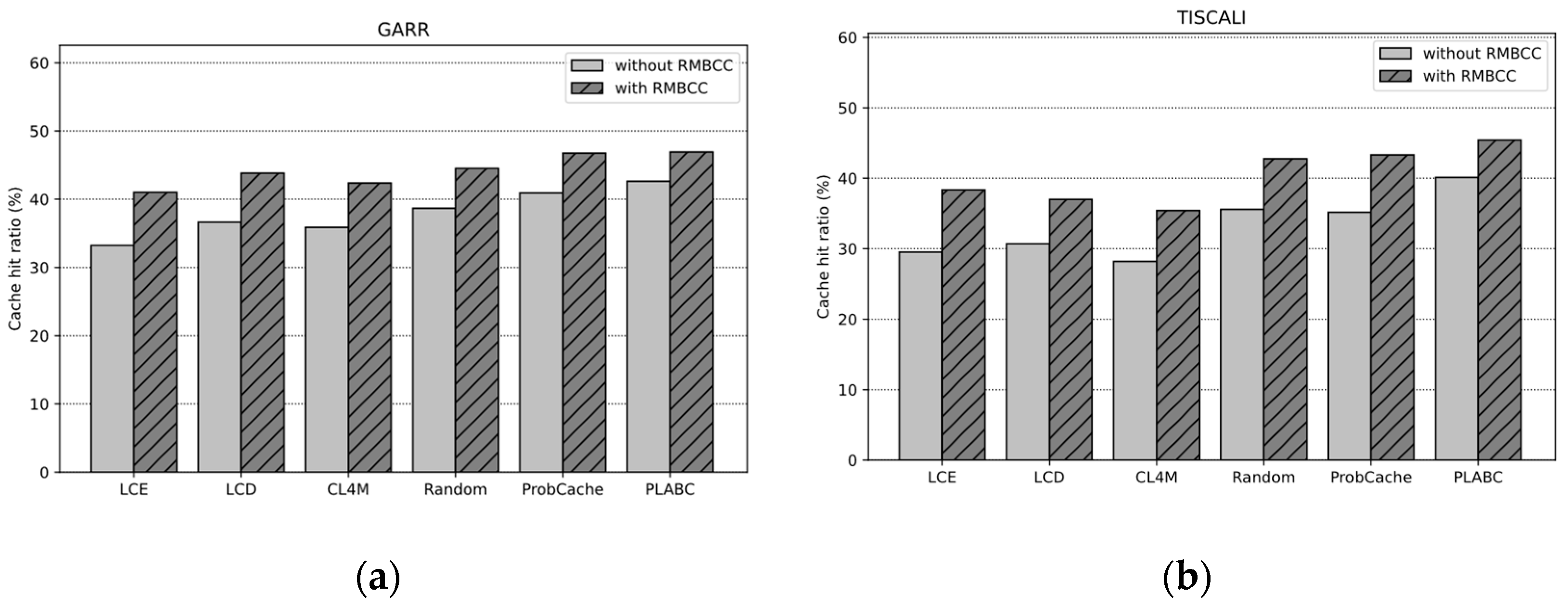
- Cache Hit Ratio
- (3)
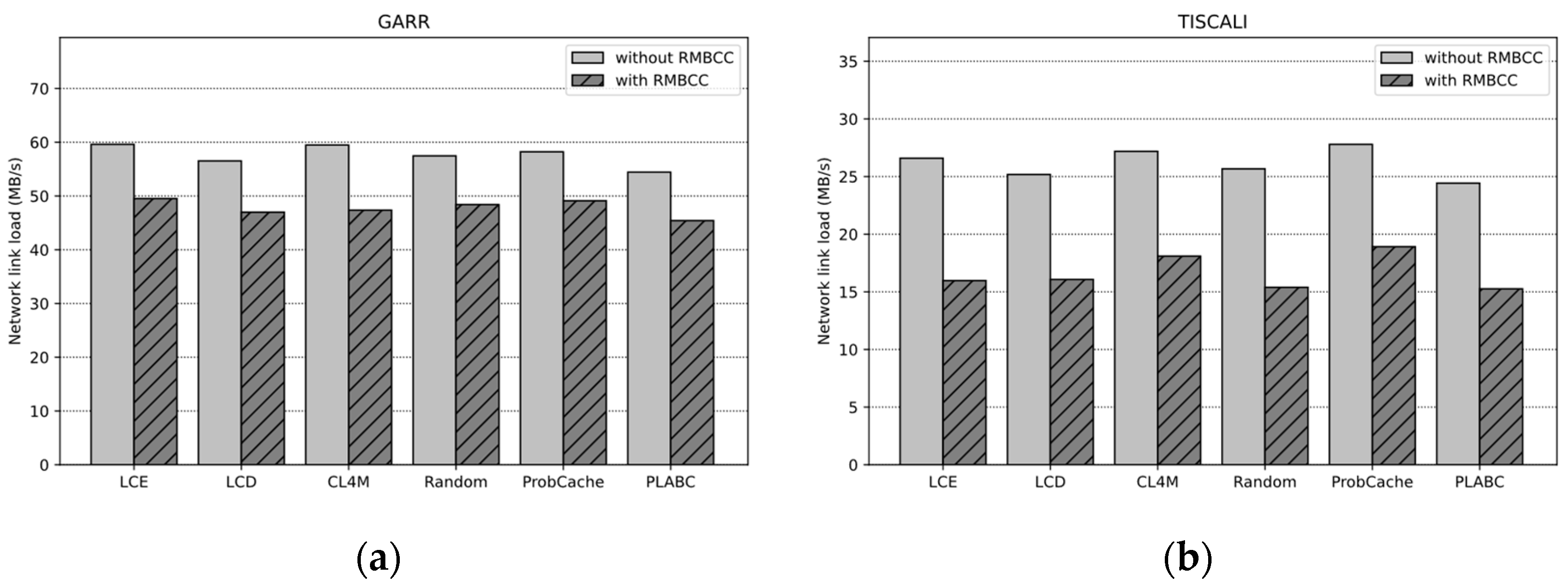
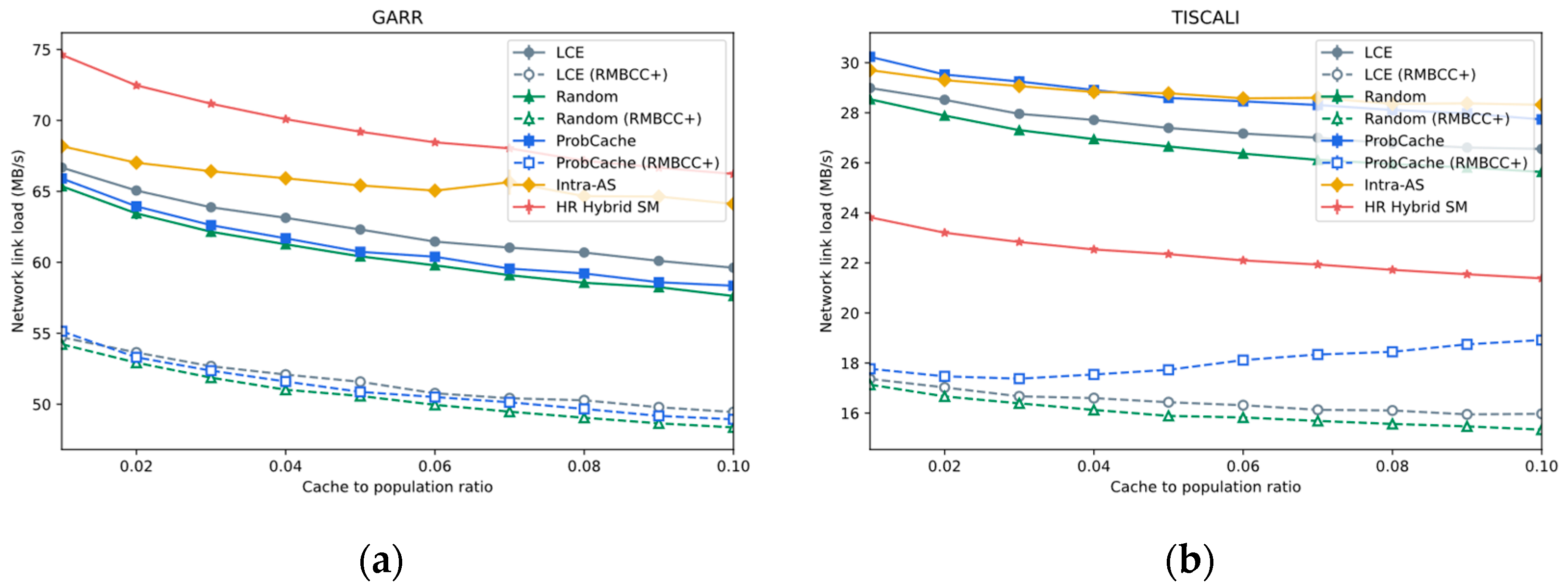
- Network Link Load
- (4)
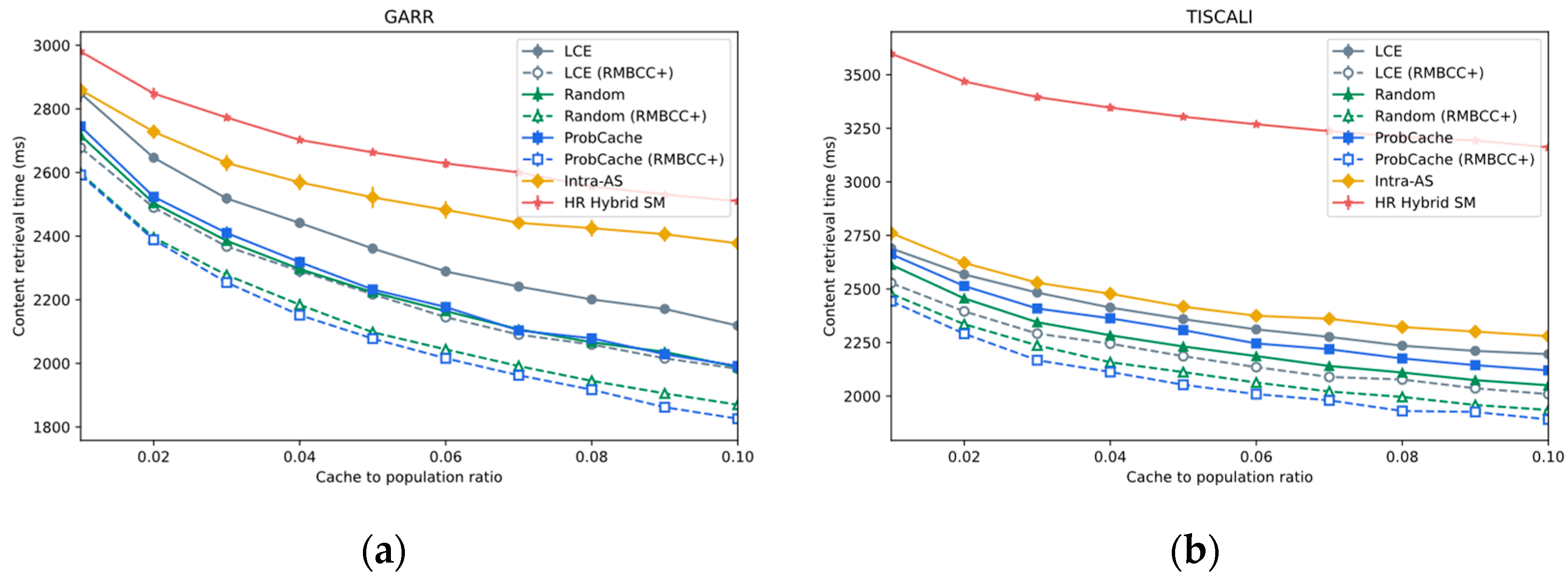
- Content Retrieval Time
4.3. Results and Discussion
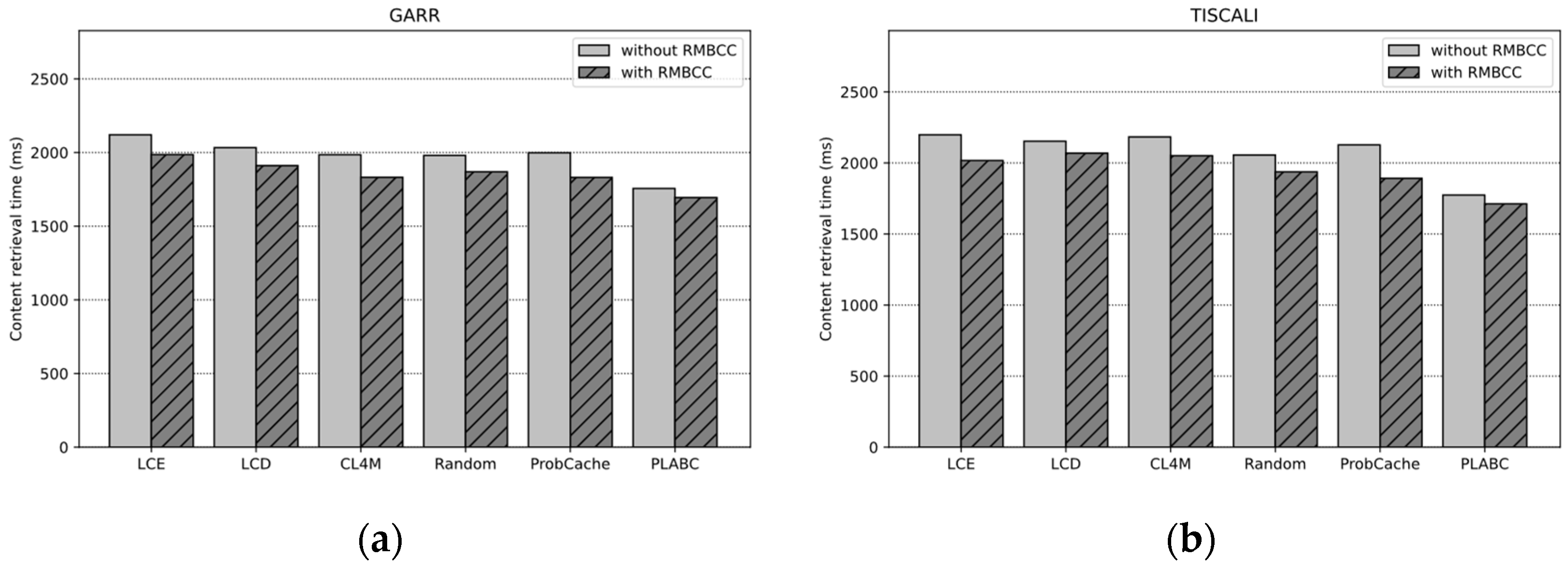
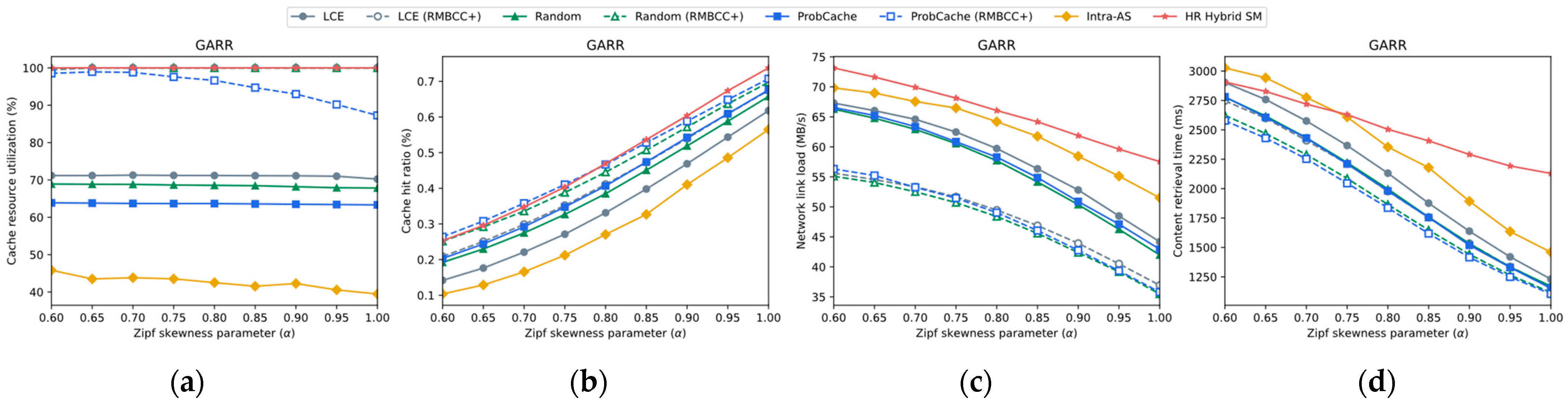
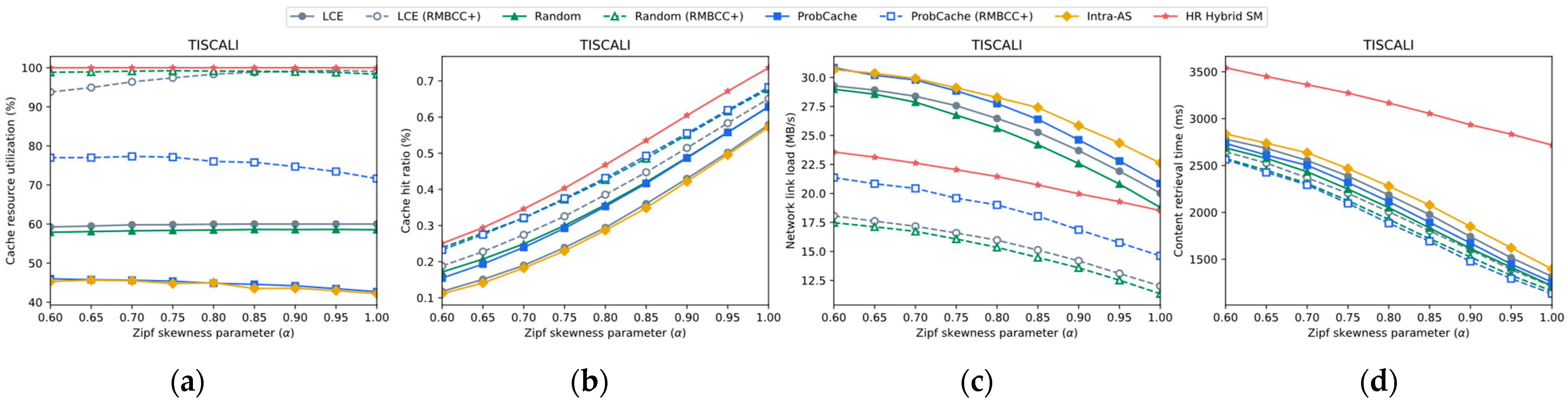
4.3.1. Impact of Base On-Path Caching Strategies
4.3.2. Impact of Varying Cache Size
4.3.3. Impact of Varying Content Popularity Distribution
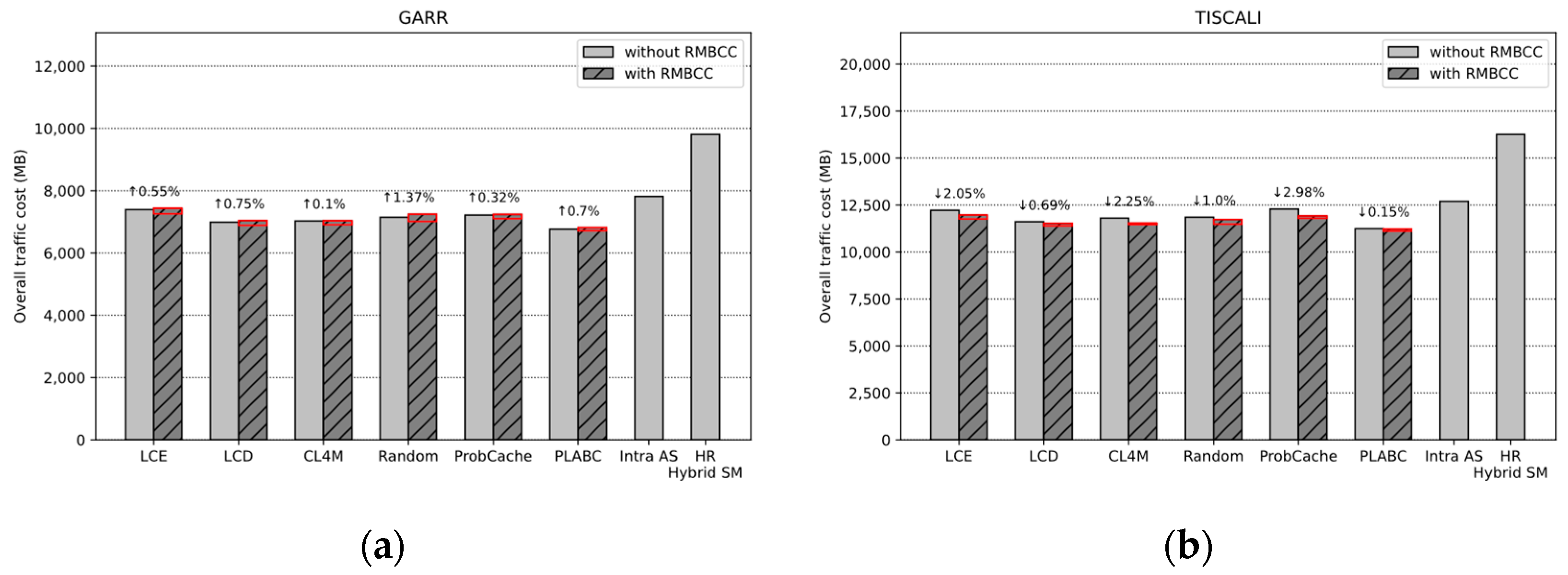
4.3.4. Overhead Analysis
- (1)
- RMBCC improves the overall cache hit ratio, thus reducing the response distance of requests (i.e., in Equation (12)) and the resulting traffic cost;
- (2)
- RMBCC filters the evicted replicas through the migration decision process and limits the migration distance to reduce the traffic generated by replica migration. This corresponds to in Equation (12);
- (3)
- RMBCC sets the distance range for load information exchange to 1 (i.e., in Equation (9)), thereby reducing the cost of exchanging information with neighbor nodes. In addition, since the exchange message is very small and only contains its own load value, the overall cost of this part is also very low, which corresponds to the item in Equation (12);
4.3.5. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ICN | Information-Centric Networking |
| NDN | Named Data Networking |
| CDNs | Content Delivery Networks |
| P2P | Point-to-Point Network |
| QoS | Quality of Service |
| QoE | Quality of Experience |
| LCE | Leave Copy Everywhere |
| LCD | Leave Copy Down |
| LRU | Least Recently Used |
| IoT | Internet of Things |
| CS | Content Store |
| RIT | Replica Information Table |
| NIT | Neighbor Information Table |
| TTL | Time to Live |
| ISP | Internet Service Provider |
References
- López-Ardao, J.C.; Rodríguez-Pérez, M.; Herrería-Alonso, S. Recent Advances in Information-Centric Networks (ICNs). Future Internet 2023, 15, 392. [Google Scholar] [CrossRef]
- Jacobson, V.; Smetters, D.K.; Thornton, J.D.; Plass, M.F.; Briggs, N.H.; Braynard, R.L. Networking Named Content. In Proceedings of the 5th International Conference on Emerging Networking Experiments and Technologies, Rome, Italy, 1–4 December 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 1–12. [Google Scholar]
- Carofiglio, G.; Morabito, G.; Muscariello, L.; Solis, I.; Varvello, M. From Content Delivery Today to Information Centric Networking. Comput. Netw. 2013, 57, 3116–3127. [Google Scholar] [CrossRef]
- Pruthvi, C.N.; Vimala, H.S.; Shreyas, J. A Systematic Survey on Content Caching in ICN and ICN-IoT: Challenges, Approaches and Strategies. Comput. Netw. 2023, 233, 109896. [Google Scholar] [CrossRef]
- Ahlgren, B.; Dannewitz, C.; Imbrenda, C.; Kutscher, D.; Ohlman, B. A Survey of Information-Centric Networking. IEEE Commun. Mag. 2012, 50, 26–36. [Google Scholar] [CrossRef]
- Rossi, D.; Rossini, G. On Sizing CCN Content Stores by Exploiting Topological Information. In Proceedings of the 2012 Proceedings IEEE INFOCOM Workshops, Orlando, FL, USA, 25–30 March 2012; pp. 280–285. [Google Scholar]
- Wang, Y.; Li, Z.; Tyson, G.; Uhlig, S.; Xie, G. Design and Evaluation of the Optimal Cache Allocation for Content-Centric Networking. IEEE Trans. Comput. 2016, 65, 95–107. [Google Scholar] [CrossRef]
- Chu, W.; Dehghan, M.; Lui, J.C.S.; Towsley, D.; Zhang, Z.-L. Joint Cache Resource Allocation and Request Routing for In-Network Caching Services. Comput. Netw. 2018, 131, 1–14. [Google Scholar] [CrossRef]
- Pires, S.; Ziviani, A.; Sampaio, L.N. Contextual Dimensions for Cache Replacement Schemes in Information-Centric Networks: A Systematic Review. PeerJ Comput. Sci. 2021, 7, e418. [Google Scholar] [CrossRef] [PubMed]
- Khandaker, F.; Oteafy, S.; Hassanein, H.S.; Farahat, H. A Functional Taxonomy of Caching Schemes: Towards Guided Designs in Information-Centric Networks. Comput. Netw. 2019, 165, 106937. [Google Scholar] [CrossRef]
- Zhang, Z.; Lung, C.-H.; Wei, X.; Chen, M.; Chatterjee, S.; Zhang, Z. In-Network Caching for ICN-Based IoT (ICN-IoT): A Comprehensive Survey. IEEE Internet Things J. 2023, 10, 14595–14620. [Google Scholar] [CrossRef]
- Lee, M.; Song, J.; Cho, K.; Pack, S.; “Taekyoung” Kwon, T.; Kangasharju, J.; Choi, Y. Content Discovery for Information-Centric Networking. Comput. Netw. 2015, 83, 1–14. [Google Scholar] [CrossRef]
- Liu, H.; Azhandeh, K.; de Foy, X.; Gazda, R. A Comparative Study of Name Resolution and Routing Mechanisms in Information-Centric Networks. Digit. Commun. Netw. 2019, 5, 69–75. [Google Scholar] [CrossRef]
- Zhang, M.; Luo, H.; Zhang, H. A Survey of Caching Mechanisms in Information-Centric Networking. IEEE Commun. Surv. Tutor. 2015, 17, 1473–1499. [Google Scholar] [CrossRef]
- Zhang, L.; Afanasyev, A.; Burke, J.; Jacobson, V.; Claffy, K.; Crowley, P.; Papadopoulos, C.; Wang, L.; Zhang, B. Named Data Networking. SIGCOMM Comput. Commun. Rev. 2014, 44, 66–73. [Google Scholar] [CrossRef]
- Chai, W.K.; He, D.; Psaras, I.; Pavlou, G. Cache “Less for More” in Information-Centric Networks. In NETWORKING 2012; Bestak, R., Kencl, L., Li, L.E., Widmer, J., Yin, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 27–40. [Google Scholar]
- Psaras, I.; Chai, W.K.; Pavlou, G. Probabilistic In-Network Caching for Information-Centric Networks. In Proceedings of the Second Edition of the ICN Workshop on Information-Centric Networking—ICN’12, Helsinki Finland, 17 August 2012; ACM Press: New York, NY, USA, 2012; p. 55. [Google Scholar]
- Ming, Z.; Xu, M.; Wang, D. Age-Based Cooperative Caching in Information-Centric Networking. In Proceedings of the 2014 23rd International Conference on Computer Communication and Networks (ICCCN), Shanghai, China, 4–7 August 2014; pp. 1–8. [Google Scholar]
- Ren, J.; Qi, W.; Westphal, C.; Wang, J.; Lu, K.; Liu, S.; Wang, S. MAGIC: A Distributed MAx-Gain In-Network Caching Strategy in Information-Centric Networks. In Proceedings of the 2014 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 27 April–2 May 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 470–475. [Google Scholar]
- Gill, A.S.; D’Acunto, L.; Trichias, K.; van Brandenburg, R. BidCache: Auction-Based In-Network Caching in ICN. In Proceedings of the 2016 IEEE Globecom Workshops (GC Wkshps), Washington, DC, USA, 4–8 December 2016; pp. 1–6. [Google Scholar]
- Badov, M.; Seetharam, A.; Kurose, J.; Firoiu, V.; Nanda, S. Congestion-Aware Caching and Search in Information-Centric Networks. In Proceedings of the 1st ACM Conference on Information-Centric Networking, Paris, France, 24–26 September 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 37–46. [Google Scholar]
- Nguyen, D.; Sugiyama, K.; Tagami, A. Congestion Price for Cache Management in Information-Centric Networking. In Proceedings of the 2015 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Hong Kong, China, 26 April–1 May 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 287–292. [Google Scholar]
- Carofiglio, G.; Mekinda, L.; Muscariello, L. LAC: Introducing Latency-Aware Caching in Information-Centric Networks. In Proceedings of the 2015 IEEE 40th Conference on Local Computer Networks (LCN), Clearwater Beach, FL, USA, 26–29 October 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 422–425. [Google Scholar]
- Yokota, K.; Sugiyama, K.; Kurihara, J.; Tagami, A. RTT-Based Caching Policies to Improve User-Centric Performance in CCN. In Proceedings of the 2016 IEEE 30th International Conference on Advanced Information Networking and Applications (AINA), Crans-Montana, Switzerland, 23–25 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 124–131. [Google Scholar]
- Dutta, N.; Patel, S.K.; Faragallah, O.S.; Baz, M.; Rashed, A.N.Z. Caching Scheme for Information-Centric Networks with Balanced Content Distribution. Int. J. Commun. Syst. 2022, 35, e5104. [Google Scholar] [CrossRef]
- Hamdi, M.M.F.; Chen, Z.; Radenkovic, M. Mitigating Cache Pollution Attack Using Deep Learning in Named Data Networking (NDN). In Intelligent Computing; Arai, K., Ed.; Springer Nature Switzerland: Cham, Switzerland, 2024; pp. 432–442. [Google Scholar]
- Iqbal, S.M.d.A.; Asaduzzaman. Cache-MAB: A Reinforcement Learning-Based Hybrid Caching Scheme in Named Data Networks. Future Gener. Comput. Syst. 2023, 147, 163–178. [Google Scholar] [CrossRef]
- Barakat, C.; Kalla, A.; Saucez, D.; Turletti, T. Minimizing Bandwidth on Peering Links with Deflection in Named Data Networking. In Proceedings of the 2013 Third International Conference on Communications and Information Technology (ICCIT), Beirut, Lebanon, 19–21 June 2013; pp. 88–92. [Google Scholar]
- Saino, L.; Psaras, I.; Pavlou, G. Hash-Routing Schemes for Information Centric Networking. In Proceedings of the 3rd ACM SIGCOMM Workshop on Information-Centric Networking—ICN ’13, Hong Kong, China, 12 August 2013; ACM Press: New York, NY, USA, 2013; p. 27. [Google Scholar]
- Sourlas, V.; Psaras, I.; Saino, L.; Pavlou, G. Efficient Hash-Routing and Domain Clustering Techniques for Information-Centric Networks. Comput. Netw. 2016, 103, 67–83. [Google Scholar] [CrossRef]
- Saha, S.; Lukyanenko, A.; Ylä-Jääski, A. Cooperative Caching through Routing Control in Information-Centric Networks. In Proceedings of the 2013 Proceedings IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 100–104. [Google Scholar]
- Zhang, G.; Wang, X.; Gao, Q.; Liu, Z. A Hybrid ICN Cache Coordination Scheme Based on Role Division between Cache Nodes. In Proceedings of the 2015 IEEE Global Communications Conference (GLOBECOM), San Diego, CA, USA, 6–10 December 2015; pp. 1–6. [Google Scholar]
- Wang, S.; Bi, J.; Wu, J.; Vasilakos, A.V. CPHR: In-Network Caching for Information-Centric Networking with Partitioning and Hash-Routing. IEEE/ACM Trans. Netw. 2016, 24, 2742–2755. [Google Scholar] [CrossRef]
- Lanlan, R.U.I.; Jiahui, K.; Haoqiu, H.; Hao, P. Domain-orientated Coordinated Hybrid Content Caching and Request Search in Information-centric Networking. J. Electron. Inf. Technol. 2017, 39, 2741–2747. [Google Scholar] [CrossRef]
- Kamiyama, N.; Murata, M. Dispersing Content Over Networks in Information-Centric Networking. IEEE Trans. Netw. Serv. Manag. 2019, 16, 521–534. [Google Scholar] [CrossRef]
- Nguyen, X.N.; Saucez, D.; Turletti, T. Efficient Caching in Content-Centric Networks Using OpenFlow. In Proceedings of the 2013 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Turin, Italy, 14–19 April 2013; pp. 67–68. [Google Scholar]
- Sourlas, V.; Gkatzikis, L.; Flegkas, P.; Tassiulas, L. Distributed Cache Management in Information-Centric Networks. IEEE Trans. Netw. Serv. Manag. 2013, 10, 286–299. [Google Scholar] [CrossRef]
- Salah, H.; Strufe, T. CoMon: An Architecture for Coordinated Caching and Cache-Aware Routing in CCN. In Proceedings of the 2015 12th Annual IEEE Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2015; pp. 663–670. [Google Scholar]
- Mick, T.; Tourani, R.; Misra, S. MuNCC: Multi-Hop Neighborhood Collaborative Caching in Information Centric Networks. In Proceedings of the 3rd ACM Conference on Information-Centric Networking, Kyoto, Japan, 26–28 September 2016; ACM: New York, NY, USA, 2016; pp. 93–101. [Google Scholar]
- Wang, J.M.; Zhang, J.; Bensaou, B. Intra-AS Cooperative Caching for Content-Centric Networks. In Proceedings of the 3rd ACM SIGCOMM Workshop on Information-Centric Networking, Hong Kong, China, 12 August 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 61–66. [Google Scholar]
- Yang, Y.; Song, T.; Zhang, B. OpenCache: A Lightweight Regional Cache Collaboration Approach in Hierarchical-Named ICN. Comput. Commun. 2019, 144, 89–99. [Google Scholar] [CrossRef]
- Chaudhary, P.; Hubballi, N.; Kulkarni, S.G. eNCache: Improving Content Delivery with Cooperative Caching in Named Data Networking. Comput. Netw. 2023, 237, 110104. [Google Scholar] [CrossRef]
- Mori, K.; Kamimoto, T.; Shigeno, H. Push-Based Traffic-Aware Cache Management in Named Data Networking. In Proceedings of the 2015 18th International Conference on Network-Based Information Systems, Taipei, Taiwan, 2–4 September 2015; pp. 309–316. [Google Scholar]
- Rath, H.K.; Panigrahi, B.; Simha, A. On Cooperative On-Path and Off-Path Caching Policy for Information Centric Networks (ICN). In Proceedings of the 2016 IEEE 30th International Conference on Advanced Information Networking and Applications (AINA), Crans-Montana, Switzerland, 23–25 March 2016; pp. 842–849. [Google Scholar]
- Fang, W.; Chen, S.; Jiang, Y.; Rem, Z. The Hotspot Control and Content Dispatch Caching Algorithm in Content-Centric Networking. Acta Electron. Sin. 2017, 45, 1182–1188. [Google Scholar] [CrossRef]
- Luo, X.; An, Y. A Proactive Caching Scheme Based on Content Concentration in Content-Centric Networks. Int. Arab J. Inf. Technol. 2019, 16, 1003–1012. [Google Scholar]
- Hua, Y.; Guan, L.; Kyriakopoulos, K.G. A Fog Caching Scheme Enabled by ICN for IoT Environments. Future Gener. Comput. Syst. 2020, 111, 82–95. [Google Scholar] [CrossRef]
- Nour, B.; Khelifi, H.; Moungla, H.; Hussain, R.; Guizani, N. A Distributed Cache Placement Scheme for Large-Scale Information-Centric Networking. IEEE Netw. 2020, 34, 126–132. [Google Scholar] [CrossRef]
- Wu, T.; Zheng, Q.; Shi, Q.; Yang, F.; Xu, Z. NCR-BN Cooperative Caching for ICN Based on Off-Path Cache. In Proceedings of the 2022 5th International Conference on Hot Information-Centric Networking (HotICN), Guangzhou, China, 24–26 November 2022; pp. 42–47. [Google Scholar]
- Imai, S.; Leibnitz, K.; Murata, M. Statistical Approximation of Efficient Caching Mechanisms for One-Timers. IEEE Trans. Netw. Serv. Manag. 2015, 12, 595–604. [Google Scholar] [CrossRef]
- Saino, L.; Psaras, I.; Pavlou, G. Icarus: A Caching Simulator for Information Centric Networking (ICN). In Proceedings of the 7th International ICST Conference on Simulation Tools and Techniques, Lisbon, Portugal, 17–19 March 2014; ICST (Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering): Brussels, Belgium, 2014; pp. 66–75. [Google Scholar]
- Spring, N.; Mahajan, R.; Wetherall, D. Measuring ISP Topologies with Rocketfuel. SIGCOMM Comput. Commun. Rev. 2002, 32, 133–145. [Google Scholar] [CrossRef]
- Breslau, L.; Cao, P.; Fan, L.; Phillips, G.; Shenker, S. Web Caching and Zipf-like Distributions: Evidence and Implications. In Proceedings of the IEEE INFOCOM ’99. Conference on Computer Communications. Proceedings. Eighteenth Annual Joint Conference of the IEEE Computer and Communications Societies. The Future is Now (Cat. No.99CH36320), New York, NY, USA, 21–25 March 1999; Volume 1, pp. 126–134. [Google Scholar]
- Wang, J.; Cheng, G.; You, J.; Sun, P. SEANet: Architecture and Technologies of an On-site, Elastic, Autonomous Network. J. Netw. New Media 2020, 9, 1–8. [Google Scholar]
- Zhang, F.; Zhang, Y.; Raychaudhuri, D. Edge Caching and Nearest Replica Routing in Information-Centric Networking. In Proceedings of the 2016 IEEE 37th Sarnoff Symposium, Newark, NJ, USA, 19–21 September 2016; pp. 181–186. [Google Scholar]
- Yan, M.; Luo, M.; Chan, C.A.; Gygax, A.F.; Li, C.; Chih-Lin, I. Energy-Efficient Content Fetching Strategies in Cache-Enabled D2D Networks via an Actor-Critic Reinforcement Learning Structure. IEEE Trans. Veh. Technol. 2024, 1–11. [Google Scholar] [CrossRef]
- Chao, Y.; Ni, H.; Han, R. A Path Load-Aware Based Caching Strategy for Information-Centric Networking. Electronics 2022, 11, 3088. [Google Scholar] [CrossRef]
- Fayazbakhsh, S.K.; Lin, Y.; Tootoonchian, A.; Ghodsi, A.; Koponen, T.; Maggs, B.; Ng, K.C.; Sekar, V.; Shenker, S. Less Pain, Most of the Gain: Incrementally Deployable ICN. SIGCOMM Comput. Commun. Rev. 2013, 43, 147–158. [Google Scholar] [CrossRef]
- Gupta, D.; Rani, S.; Singh, A.; Rodrigues, J.J.P.C. ICN Based Efficient Content Caching Scheme for Vehicular Networks. IEEE Trans. Intell. Transp. Syst. 2023, 24, 15548–15556. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Network topology | GARR/TISCALI |
| Bandwidth of intra-network links | 1 Gbps |
| Bandwidth of access links | 100 Mbps |
| Cache placement | Uniform |
| Content size | 10 MB |
| Content popularity distribution | Zipf () |
| Number of contents | |
| Number of requests | |
| Request distribution | Poisson |
| Request rate | 200 req/s |
| Strategies | Characteristics |
|---|---|
| LCE | Cache a copy of the content at each node on the content delivery path |
| LCD | Cache only at the next hop node of the service node |
| CL4M | Cache at the intermediate node with the largest betweenness centrality |
| Random | Cache at a randomly selected node on the content delivery path |
| ProbCache | Cache at each hop node according to the dynamically calculated probability |
| PLABC | Cache at the node with the largest utility value on the content delivery path |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chao, Y.; Ni, H.; Han, R. RMBCC: A Replica Migration-Based Cooperative Caching Scheme for Information-Centric Networks. Electronics 2024, 13, 2636. https://doi.org/10.3390/electronics13132636
Chao Y, Ni H, Han R. RMBCC: A Replica Migration-Based Cooperative Caching Scheme for Information-Centric Networks. Electronics. 2024; 13(13):2636. https://doi.org/10.3390/electronics13132636
Chicago/Turabian StyleChao, Yichao, Hong Ni, and Rui Han. 2024. "RMBCC: A Replica Migration-Based Cooperative Caching Scheme for Information-Centric Networks" Electronics 13, no. 13: 2636. https://doi.org/10.3390/electronics13132636
APA StyleChao, Y., Ni, H., & Han, R. (2024). RMBCC: A Replica Migration-Based Cooperative Caching Scheme for Information-Centric Networks. Electronics, 13(13), 2636. https://doi.org/10.3390/electronics13132636