
Few-Shot Image Segmentation Using Generating Mask with Meta-Learning Classifier Weight Transformer Network

 , ,
, ,  ,
,  ,
,  ,
,
Abstract
1. Introduction
- Proposing improvements to enhance the accuracy of few-shot image segmentation models.
- Integrating meta-learning with few-shot image segmentation models to enable excellent performance on new category targets.
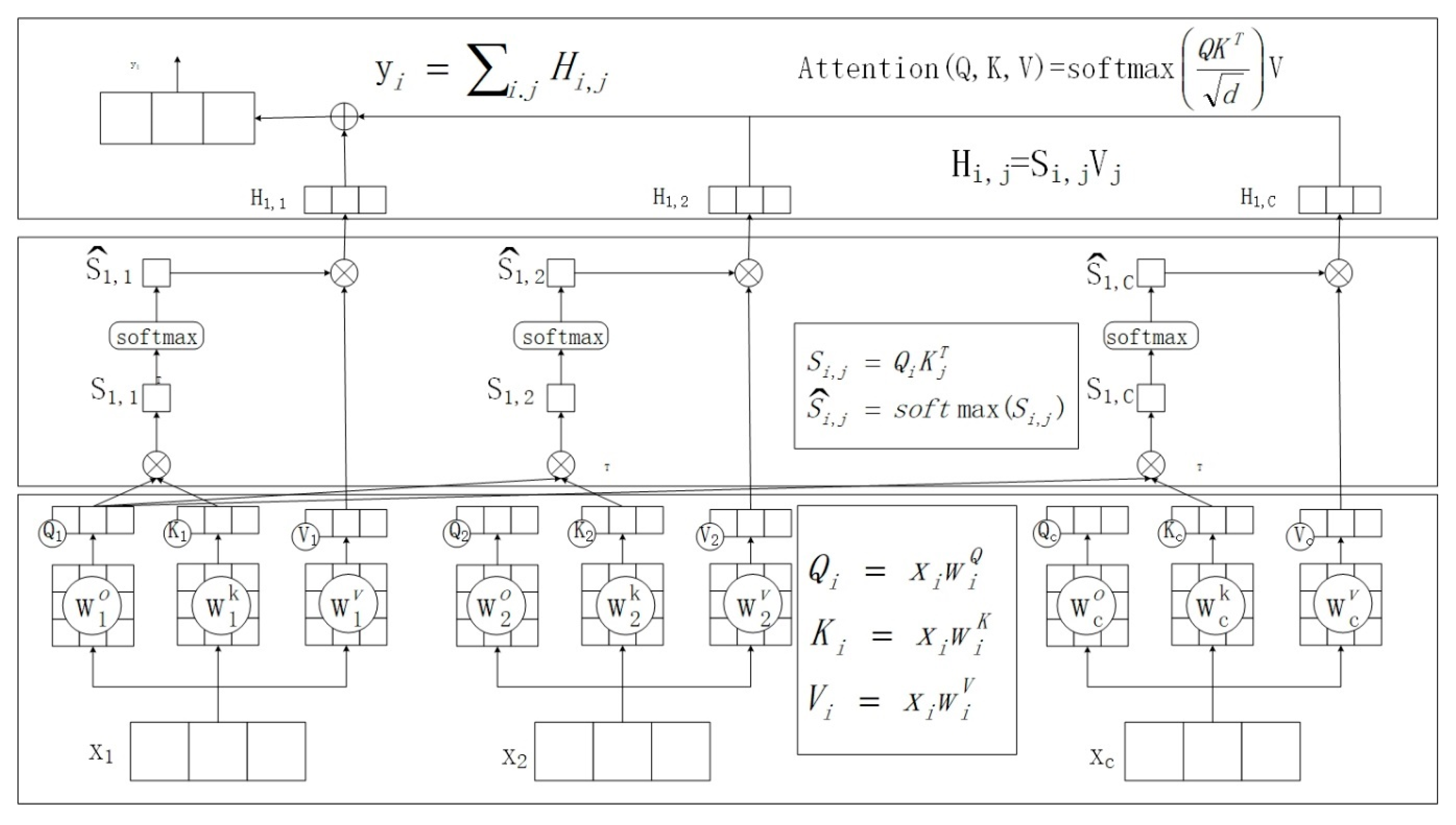
2. Attention Mechanism
2.1. Self-Attention Mechanism
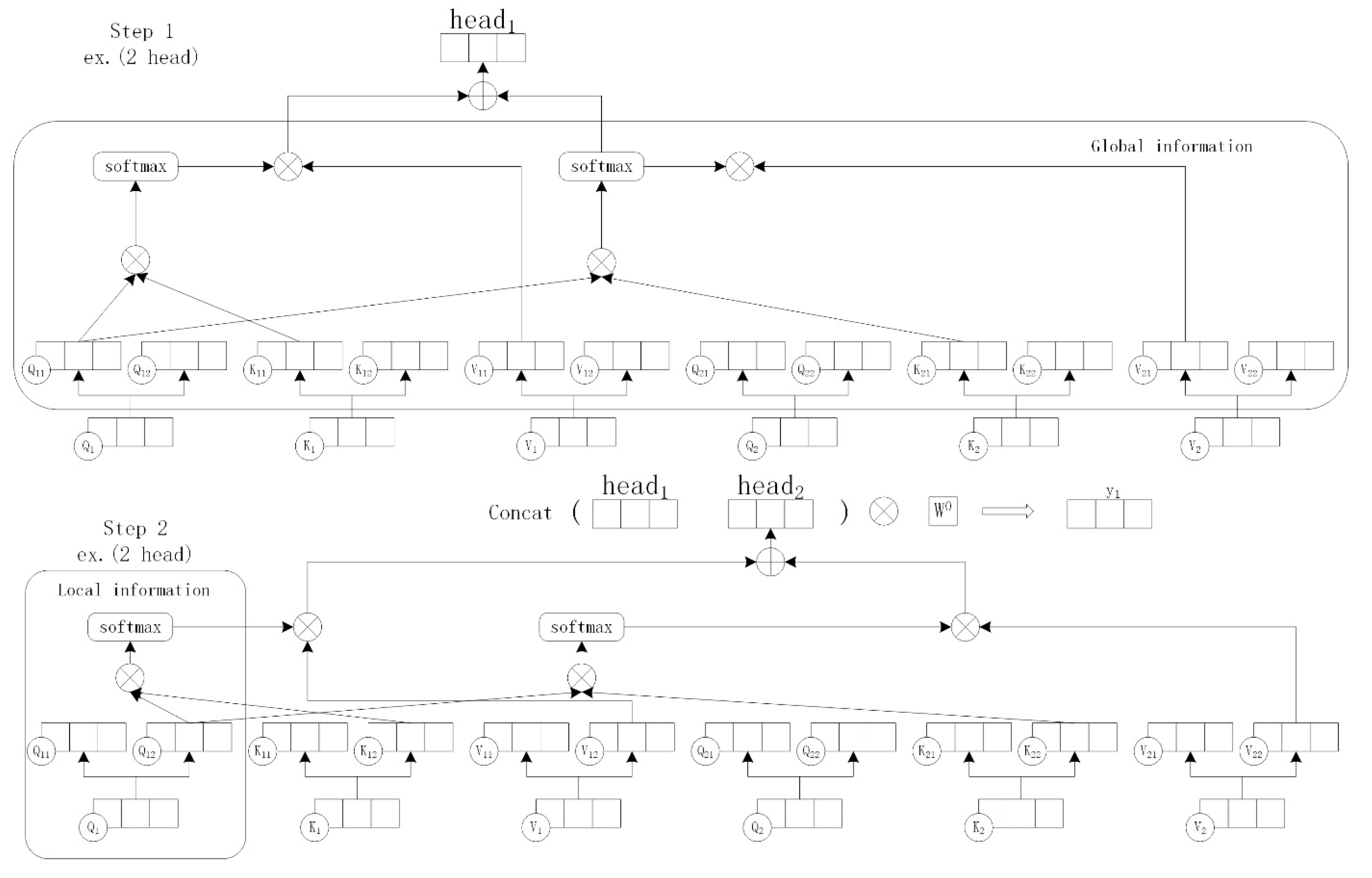
2.2. Multi-Head Self-Attention Mechanism
3. Meta-Learning and Few-Shot Learning Background
3.1. Meta-Learning
3.1.1. Gradient-Based Meta-Learning
| Algorithm 1. Model-Agnostic Meta-Learning Algorithm: |
| Require: : distribution over task Require: , :step size hyperparameters 1: randomly initialize 0 2: while not done do 3: Sample batch of task 4: for all do 5: Sample K data points from 6: Evaluate using D 7: Compute adapted parameters with gradient descent: 8: Sample data points from , for the meta-update 9: end for 10: Update using each D_i^’ 11: end while |
- Sample batch of tasks: Randomly sample one or more batches of training tasks from meta-training, and then sample training data from each task.
- Evaluate gradient and compute adapted parameters: Compute the gradient for each task and its corresponding labels in the training data and update the model parameters accordingly.
- Update the model: With the newly updated model parameters for each task using the meta-training data, validate using the meta-training test data sampled calculate the loss for all tasks, update the original model parameters, and store the model.
3.1.2. Metric-Based Meta-Learning
| Algorithm 2. Training Episode Loss Computation for Prototypical Networks. N is the Number of Examples in the Training Set, K is the Number of Classes in the Training Set, Nc < K is the Number of Classes per Episode, Ns is the Number of Support Examples per Class, NQ is the Number of Query Examples per Class. RANDOMSAMPLE(S, N) Denotes a Set of N Elements Chosen Uniformly at Random from Set S, without Replacement. |
| Input: Training set , where each . Dk denotes the subset of D containing all elements such that . Output: The loss J for a randomly generated training episode. 1: Select class indices for episode 2: for k in do 3: Select support examples 4: Select query examples 5: Compute prototype from support examples 6: end for 7: 8: for k in do Initialize loss 9: for in do 10: Update loss 11: end for 12: end for |
3.2. Few-Shot Learning
3.3. Image segmentation
3.3.1. Semantic Segmentation
3.3.2. Few-Shot Image Segmentation
4. Experimental Results
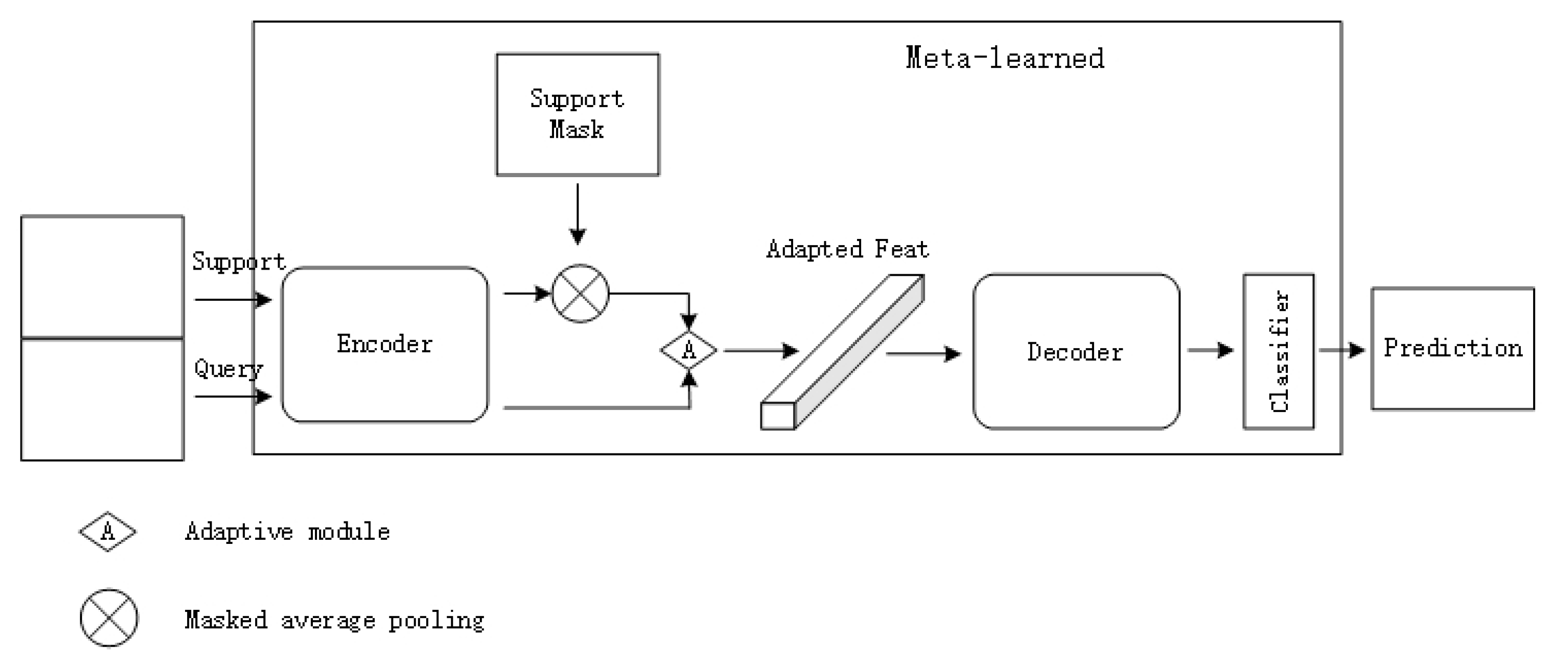
4.1. System Architecture
4.1.1. CWT Architecture with Partial Network Updates
| Algorithm 3. Meta-Training |
| Require: D(T): 60 classes’ data for meta-training Require: feature extractor, Pyramid Pooling Module: pre-trained on D(T) 1: for all epochs: 2: Sample support image and query image from D(T) 3: Extract support feature by feature extractor and Pyramid Pooling Module 4: for i in range(200) 5: Use support feature training the Pyramid Pooling Module, Conv Block1, classifier 6: end for 7: Extract query feature by feature extractor and Pyramid Pooling Module 8: Calculate the new query weights by classifier weight transformer 9: Make convolution of query feature and new query weights and predict result 10: Compute the loss 11: Update classifier weight transformer parameters 12: end for |
- This experiment uses a dataset with a total of 80 classes, which are divided into four branches, each containing 20 classes. During training, three branches, totaling 60 classes, are used. The query image serves as the segmentation target.
- The feature extractor utilizes a pre-trained backbone. Parameters are frozen during both training and testing and are not updated.
- Taking the five-shot experiment as an example, for each class, five annotated images are randomly sampled as support images to train the PPM, Conv Block1, and classifier in Figure 3.
- One annotated image is randomly sampled as the query image. It undergoes feature extraction through the feature extractor and the PPM and Conv Block1 trained with support images. Then, it is used to train the classifier weight transformer in Figure 3.
- Finally, the model parameters of the classifier weight transformer are stored.
| Algorithm 4. Meta-Testing |
| Require: D’(T): 20 classes’ data for meta-training Require: feature extractor, Pyramid Pooling Module: pre-trained on D’(T) Require: CWT: meta-trained classifier weight transformer 1: for all epochs: 2: Sample support image and query image from D’(T) 3: Extract support feature by feature extractor and Pyramid Pooling Module 4: for i in range(200) 5: Use support feature training the Pyramid Pooling Module, Conv Block1, classifier 6: end for 7: Extract query feature by feature extractor and Pyramid Pooling Module 8: Calculate the new query weights by CWT 9: Make convolution of query feature and new query weights and predict result 10: end for |
- During meta-testing the remaining 20 classes of data are used.
- For each class, five annotated images are randomly sampled as support images to train the PPM, Conv Block1, and classifier in Figure 3.
- An unlabeled image is inputted as the query image. It undergoes feature extraction through the feature extractor and utilizes the PPM and Conv Block1 trained with support images. The extracted features are then inputted into the classifier weight transformer trained during the previous meta-training for final prediction.
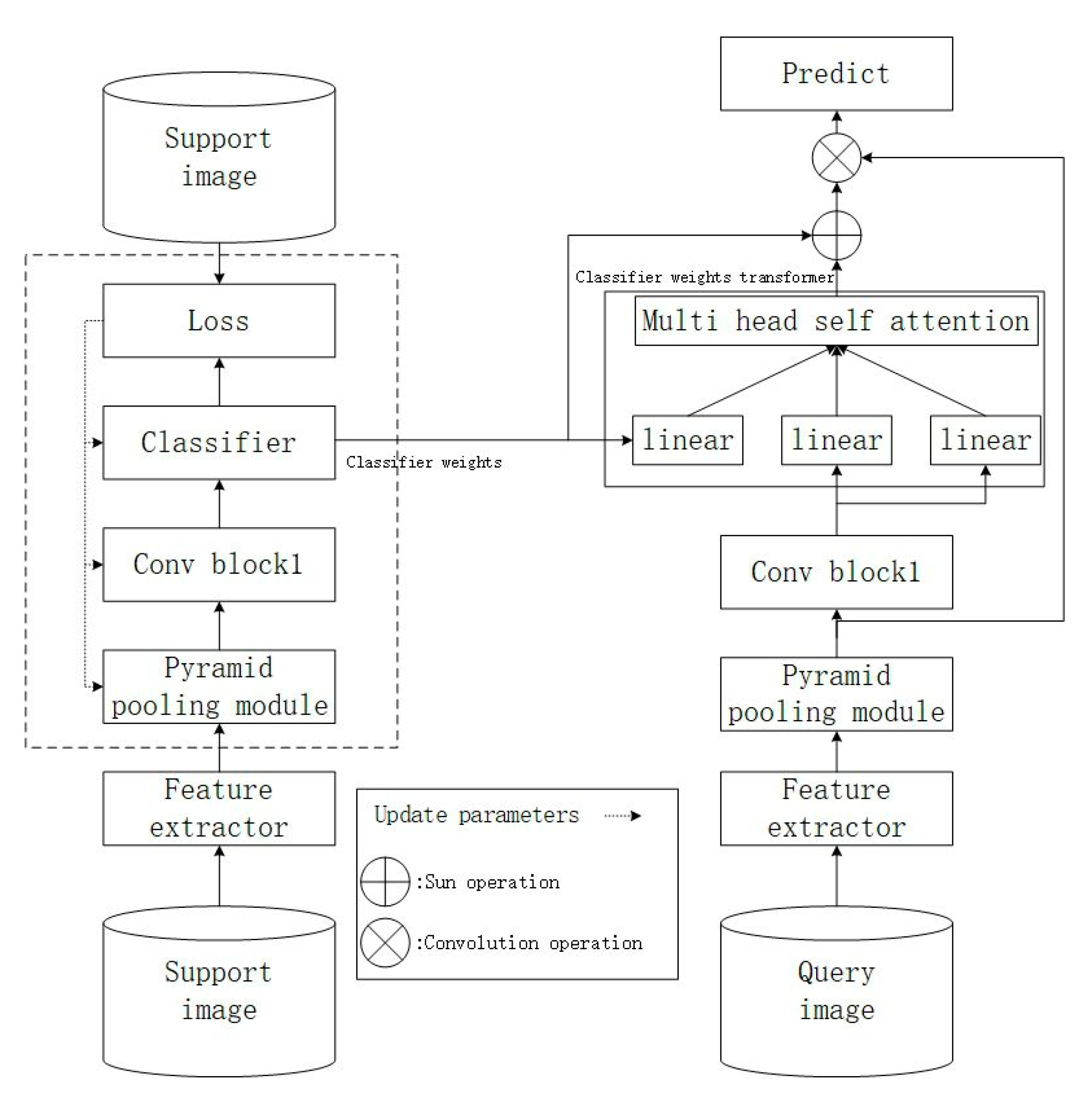
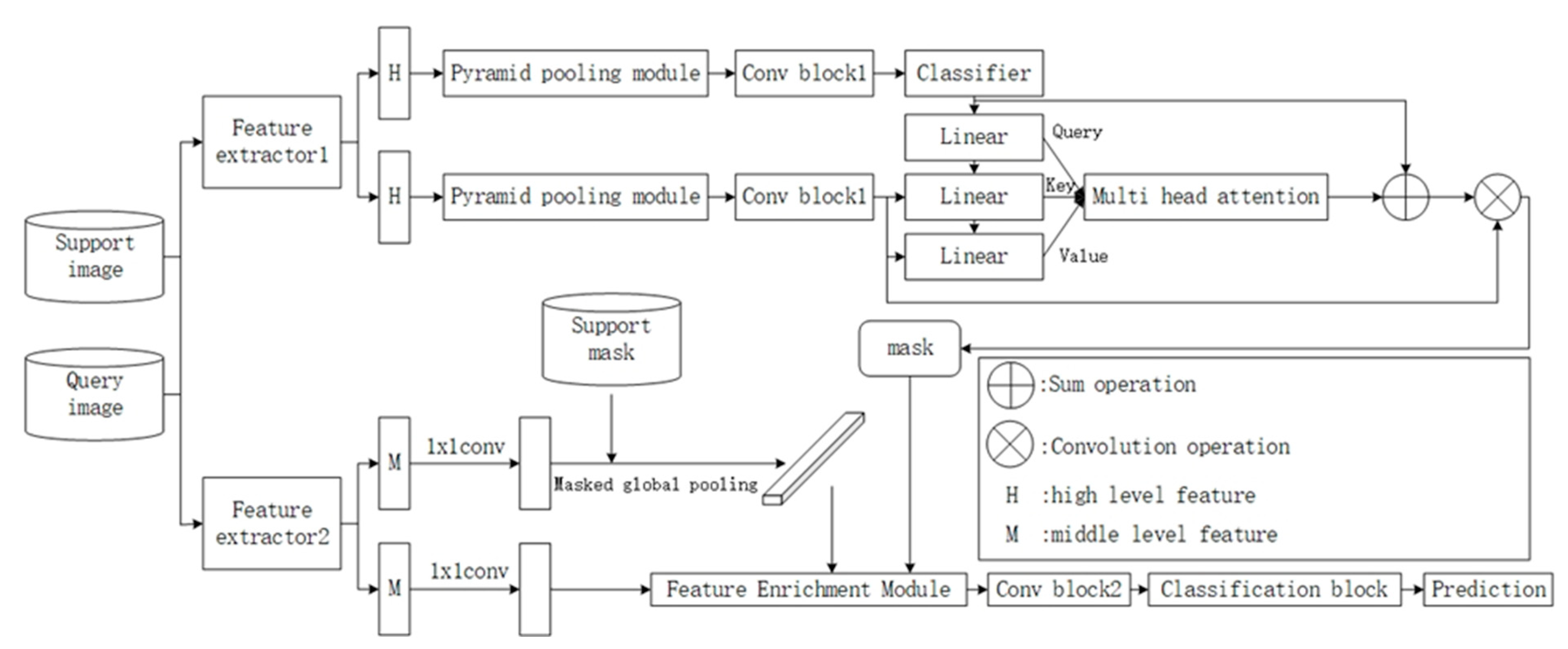
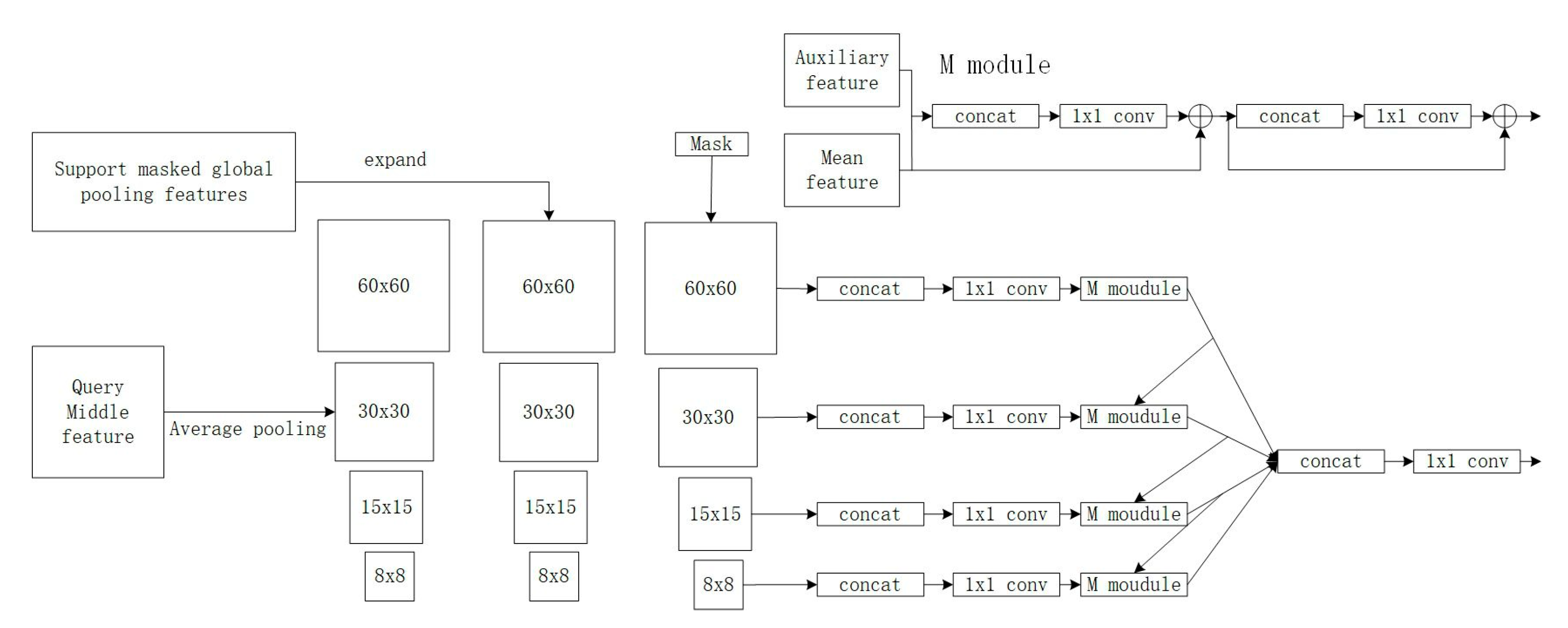
4.1.2. Meta-Learning Classification Weight Transfer Network for Generating Masked Few-Shot Image Segmentation Framework
| Algorithm 5. Meta-Training |
| Require: D(T): 60 classes’ data for meta-training Require: CVT: pre-trained classifier weight transformer 1: for all epoch: 2: Sample support image and query image from D(T) 3: Extract support feature by feature extractor 1 and Pyramid Pooling Module 4: for i in range (200) 5: Use support feature training the classifier 6: end for 7: Extract query feature by feature extractor 1 and Pyramid Pooling Module 8: Calculate the new query weights by CWT and generate query mask 9: Extract support and query middle-level feature M 10: Input M and query mask to Feature Enrichment Module, then get new query feature 11: Predict the result by classification block 12: Compute the loss 13: Update Feature Enrichment Module, Conv Block2, classification block parameters 14: end for |
- The dataset used in this experiment consists of a total of 80 classes, which will be divided into four branches, each containing 20 classes. During training, 60 of these classes will be utilized. The query image serves as the segmentation target.
- In Figure 4, both feature extractor 1, Pyramid Pooling Module, Conv Block1, linear, and feature extractor 2 utilize pre-trained parameters. These parameters remain unchanged during both the training and testing phases.
- Taking the five-shot experiment as an example, five annotated images per class are randomly sampled from the training data to serve as support images, while one annotated image per class is designated as the query image. Subsequently, feature extractor 1 and feature extractor 2 are employed to individually extract high-order features (H) and mid-order features (M).
- Next, in Figure 4, utilizing the high-order features from the support images, a linear classifier is trained. The high-order features extracted from the query image are inputted into the pre-trained linear layer to compute the attention score for the query. This score is then convolved with the query features to generate a mask.
- Following this, the mid-order features (M) extracted from both the support and query images, along with the mask generated in steps 3 and 4, are inputted into the Feature Enrichment Module (FEM). This process generates new query features, which are then passed through Conv Block2 and the classification block to predict the final results and update the parameters of the Feature Enrichment Module, Conv Block2, and classification block.
| Algorithm 6. Meta-Testing |
| Require: D(T): 20 classes’ data for meta-testing Require: CWT: pre-trained classifier weight transformer Require: FEM: meta-trained Feature Enrichment Module 1: for all epochs: 2: Sample support image and query image from D(T) 3: Extract support feature by feature extractor 1 and pyramid pooling module 4: for i in range (200) 5: Use support feature training the classifier 6: end for 7: Extract query feature by feature extractor 1 and pyramid pooling module 8: Calculate the new query weights by CWT and generate query mask 9: Extract support and query middle-level feature M by feature extractor 2 10: Input M and query mask to FEM, then get new query feature 11: Predict the result by trained classification block 12: end for |
- For the test phase, the remaining 20 classes are utilized, with five annotated images randomly sampled per class to serve as support images, along with one unlabeled query image.
- The method of generating the mask follows the same procedure as steps 3–4 during training. Subsequently, the mask, mid-order features of the query image, and mid-order features of the support images are inputted into the trained Feature Enrichment Module, conv block2, and classification block to predict the results for the query image.
4.2. Feature Extraction
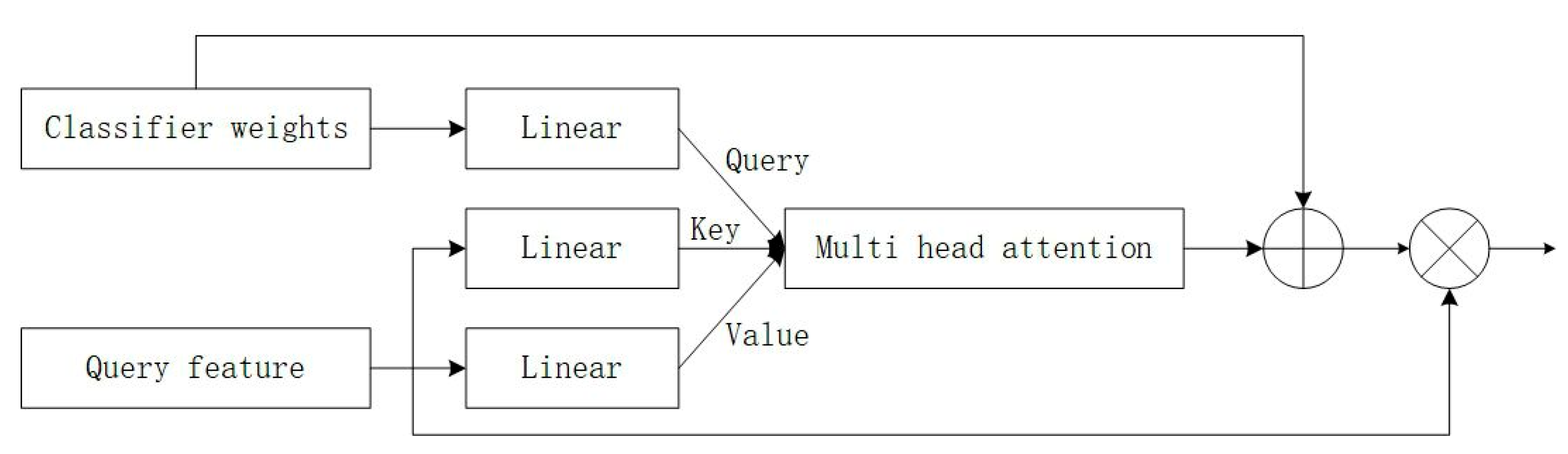
4.3. Classifier Weight Transformer
4.4. Prior Mask Generation
- Input the high-level features of the support image, extract contextual information through the Pyramid Pooling Module, and train a temporary classifier.
- Input the high-level features of the query image through the Pyramid Pooling Module, and use the trained Classifier Weight Transformer (CWT) to predict the mask.
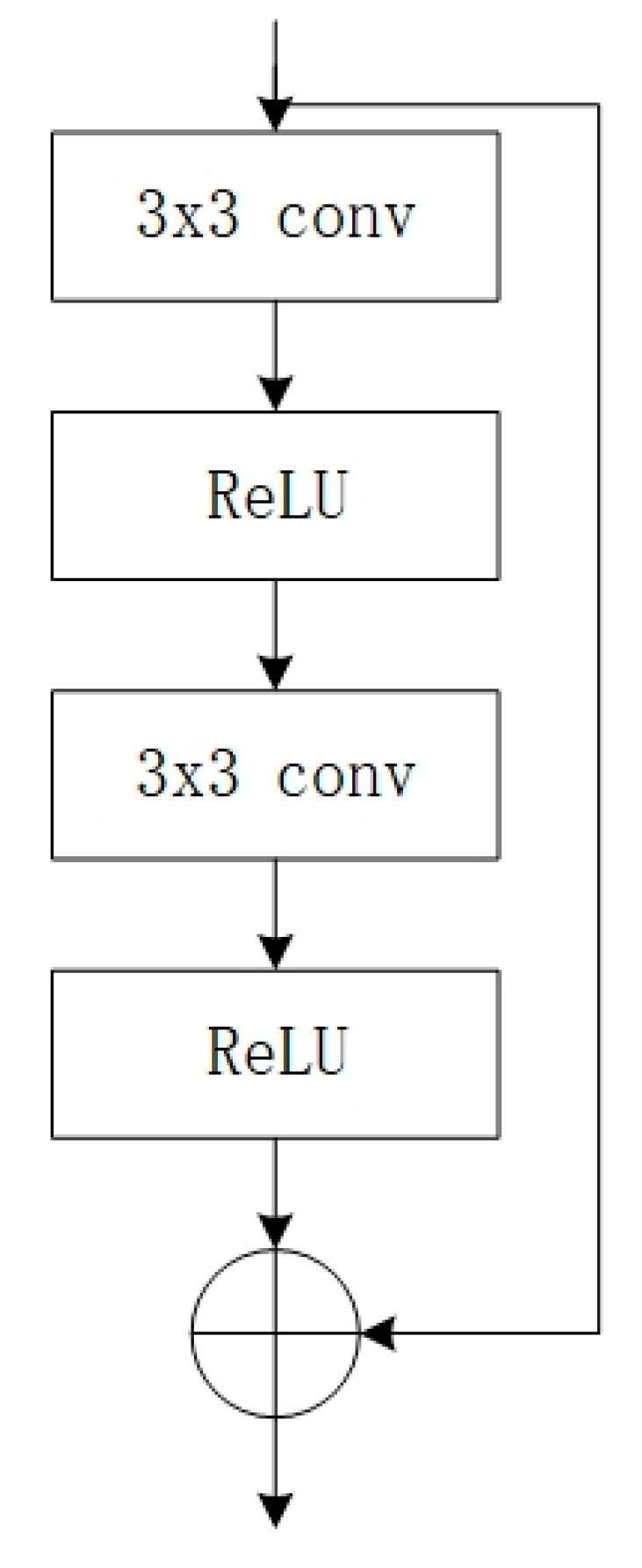
4.5. Feature Enhancement
4.6. Loss Function
- -
- C is the number of classes. Since our target is to segment the foreground and background, C = 2.
- -
- represents the ground truth labels of the target image
- -
- denotes the predicted results.
5. Experimental Results and Analysis
5.1. Experimental Environment and Setup
5.2. Experimental Dataset
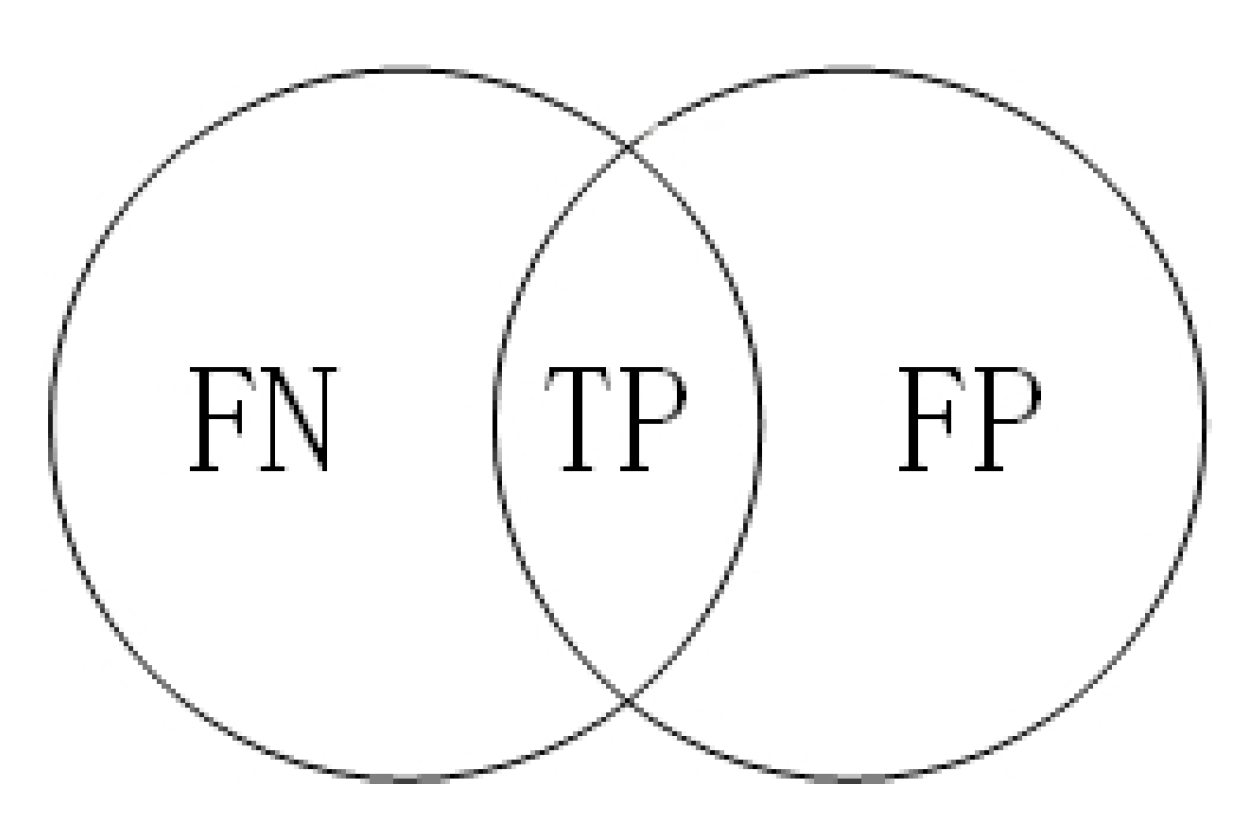
5.3. Evaluation Mechanism
- TP (True Positive): Pixels labeled as 1 in the ground truth and predicted as 1 by the model, or pixels labeled as 0 in the ground truth and predicted as 0, indicating correct predictions.
- FN (False Negative): Pixels labeled as 0 in the ground truth but predicted as 1 by the model, representing prediction errors.
- FP (False Positive): Pixels labeled as 1 in the ground truth but predicted as 0 by the model, indicating prediction errors.
5.4. Experimental Results Comparison and Analysis
- Experimental Architecture 1: Updated Partial Network CWT Architecture
- ▪
- One-shot Experiment: As shown in Table 4, where mIOU is converted to percentages (%) for comparison.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Split-0 | Split-1 | Split-2 | Split-3 | Mean |
|---|---|---|---|---|---|
| CWT | 32.2 | 36.0 | 31.6 | 31.6 | 32.9 |
| PFENet | 34.3 | 33.0 | 32.3 | 30.1 | 32.4 |
| PFENet++ | 40.9 | 46.0 | 42.3 | 40.1 | 42.3 |
| Proposed | 28.0 | 35.7 | 34.3 | 38.4 | 34.1 |
- ▪
- 5-shot Experiment: As shown in Table 5, where mIOU is converted to percentages (%) for comparison.
- Experimental Architecture 2: Meta-learning Classification Weight Transfer Network for Generating Masks in Few-shot Image Segmentation
- ▪
- One-shot Experiment: As shown in Table 6, where mIOU is converted to percentages (%) for comparison.
- Five-shot Experiment: As shown in Table 7, where mIOU is converted to percentages (%) for comparison.
| Methods | Split-0 | Split-1 | Split-2 | Split-3 | Mean |
|---|---|---|---|---|---|
| CWT | 40.1 | 43.8 | 39.0 | 42.4 | 41.3 |
| PFENet | 38.5 | 38.6 | 38.2 | 34.3 | 37.4 |
| PFENet++ | 47.5 | 53.3 | 47.3 | 46.4 | 48.6 |
| Proposed | 42.9 | 47.0 | 40.2 | 45.8 | 43.9 |
- -
- Consistency with CWT: The original CWT method, which also employs high-level features for feature extraction and segmentation, achieved the best performance in their experiments. Maintaining consistency with this approach simplifies the comparison.
- -
- Alignment with PFENet++ Improvements: Recent advancements in PFENet++, particularly its use of high-level features to generate masks with contextual information, have shown positive impacts on overall model performance. This suggests that focusing on high-level features can be beneficial.
6. Conclusions and Future Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Vu, D.-Q.; Le, N.; Wang, J.-C. Teaching Yourself: A Self-Knowledge Distillation Approach to Action Recognition. IEEE Access 2021, 9, 105711–105723. [Google Scholar] [CrossRef]
- Cao, H.N.; Duc-Quang, V.; Huong, H.L.; Chien-Lin, H.; Jia-Ching, W. Cyclic Transfer Learning for Mandarin-English Code-Switching Speech Recognition. IEEE Signal Process. Lett. 2023, 30, 1387–1391. [Google Scholar]
- Pranata, Y.D.; Wang, K.-C.; Wang, J.-C.; Idram, I.; Lai, J.-Y.; Liu, J.-W.; Hsieh, I.-H. Deep Learning and SURF for Automated Classification and Detection of Calcaneus Fractures in CT Images. Comput. Methods Programs Biomed. 2019, 171, 27–37. [Google Scholar] [CrossRef] [PubMed]
- Thi Le, P.; Pham, T.; Hsu, Y.-C.; Wang, J.-C. Convolutional Blur Attention Network for Cell Nuclei Segmentation. Sensors 2022, 22, 1586. [Google Scholar] [CrossRef] [PubMed]
- Putri, W.R.; Liu, S.-H.; Aslam, M.S.; Li, Y.-H.; Chang, C.-C.; Wang, J.-C. Self-Supervised Learning Framework toward State-of-the-Art Iris Image Segmentation. Sensors 2022, 22, 2133. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.-Y.; Chang, P.-C.; Ding, J.-J.; Tai, T.-C.; Santoso, A.; Liu, Y.-T.; Wang, J.-C. Spectral–Temporal Receptive Field-Based Descriptors and Hierarchical Cascade Deep Belief Network for Guitar Playing Technique Classification. IEEE Trans. Cybern. 2022, 52, 3684–3695. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Tai, T.-C.; Wang, J.-C.; Santoso, A.; Mathulaprangsan, S.; Chiang, C.-C.; Wu, C.-H. Sound Events Recognition and Retrieval Using Multi-Convolutional-Channel Sparse Coding Convolutional Neural Networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1875–1887. [Google Scholar] [CrossRef]
- Quintero, F.O.L.; Contreras-Reyes, J.E. Estimation for finite mixture of simplex models: Applications to biomedical data. Stat. Model. 2018, 18, 129–148. [Google Scholar] [CrossRef]
- Ranaldi, L.; Pucci, G. Knowing Knowledge: Epistemological Study of Knowledge in Transformers. Appl. Sci. 2023, 13, 677. [Google Scholar] [CrossRef]
- Wang, K.; Wang, X.; Cheng, Y. Few-shot learning based on enhanced pseudo-labels and graded pseudo-labeled data selection. Int. J. Mach. Learn. Cybern. 2023, 14, 1783–1795. [Google Scholar] [CrossRef]
- Jiang, C.; Wang, T.; Li, S.; Wang, J.; Wang, S.; Antoniou, A. Few-shot Class-Incremental Semantic Segmentation via Pseudo-Labeling and Knowledge Distillation. In Proceedings of the 2023 4th International Conference on Information Science, Parallel and Distributed Systems (ISPDS), Guangzhou, China, 14–16 July 2023; IEEE: Piscataway, NJ, USA, 2023. [Google Scholar]
- Yu, X.; Ouyang, B.; Principe, J.C.; Farrington, S.; Reed, J.; Li, Y. Weakly supervised learning of point-level annotation for coral image segmentation. In Proceedings of the OCEANS 2019 MTS/IEEE SEATTLE, Seattle, WA, USA, 27–31 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–7. [Google Scholar]
- Jhou, F.-C.; Liang, K.-W.; Lo, C.-H.; Wang, C.-Y.; Chen, Y.-F.; Wang, J.-C.; Chang, P.-C. Mask Generation with Meta-Learning Classifier Weight Transformer Network for Few-Shot Image Segmentation. In Proceedings of the 2023 International Conference on Consumer Electronics—Taiwan (ICCE-Taiwan), PingTung, Taiwan, 17–19 July 2023; pp. 457–458. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. Proc. Mach. Learn. Res. 2017, 70, 1126–1135. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical Networks for Few-Shot Learning. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Gidaris, S.; Komodakis, N. Dynamic Few-Shot Visual Learning without Forgetting. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Goldblum, M.; Reich, S.; Fowl, L.; Ni, R.; Cherepanova, V.; Goldstein, T. Unraveling Meta-Learning: Understanding Feature Representations for Few-Shot Tasks. Proc. Mach. Learn. Res. 2020, 119, 3607–3616. [Google Scholar]
- Liu, J.; Song, L.; Qin, Y. Prototype Rectification for Few-Shot Learning. In Proceedings of the Computer Vision—ECCV 2020, Lecture Notes in Computer Science, Glasgow, UK, 23–28 August 2020; pp. 741–756. [Google Scholar]
- Chen, Y.; Liu, Z.; Xu, H.; Darrell, T.; Wang, X. Meta-Baseline: Exploring Simple Meta-Learning for Few-Shot Learning. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Lecture Notes in Computer Science, Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. ParseNet: Looking Wider to See Better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Shaban, A.; Bansal, S.; Liu, Z.; Essa, I.; Boots, B. One-Shot Learning for Semantic Segmentation. In Proceedings of the British Machine Vision Conference 2017, London, UK, 4–7 September 2017. [Google Scholar]
- Dong, N.; Xing, E.P. Few-Shot Semantic Segmentation with Prototype Learning. In Proceedings of the British Machine Vision Conference 2018, Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. PANet: Few-Shot Image Semantic Segmentation with Prototype Alignment. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Zhang, C.; Lin, G.; Liu, F.; Yao, R.; Shen, C. CANet: Class-Agnostic Segmentation Networks with Iterative Refinement and Attentive Few-Shot Learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 19–20 June 2019. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lu, Z.; He, S.; Zhu, X.; Zhang, L.; Song, Y.-Z.; Xiang, T. Simpler Is Better: Few-Shot Semantic Segmentation with Classifier Weight Transformer. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Tian, Z.; Zhao, H.; Shu, M.; Yang, Z.; Li, R.; Jia, J. Prior Guided Feature Enrichment Network for Few-Shot Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1050–1065. [Google Scholar] [CrossRef] [PubMed]
- Luo, X.; Tian, Z.; Zhang, T.; Yu, B.; Tang, Y.; Jia, J. PFENet++: Boosting Few-Shot Semantic Segmentation with the Noise-Filtered Context-Aware Prior Mask. arXiv 2021, arXiv:2109.13788. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ramírez-Parietti, I.; Contreras-Reyes, J.E.; Idrovo-Aguirre, B.J. Cross-sample entropy estimation for time series analysis: A nonparametric approach. Nonlinear Dyn. 2021, 105, 2485–2508. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Lecture Notes in Computer Science. 2014; pp. 740–755. [Google Scholar]
- Nguyen, K.; Todorovic, S. Feature Weighting and Boosting for Few-Shot Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Semantic Segmentation Evaluation Index MIOU. Available online: https://blog.csdn.net/qq_34197944/article/details/103574436/ (accessed on 17 December 2019).

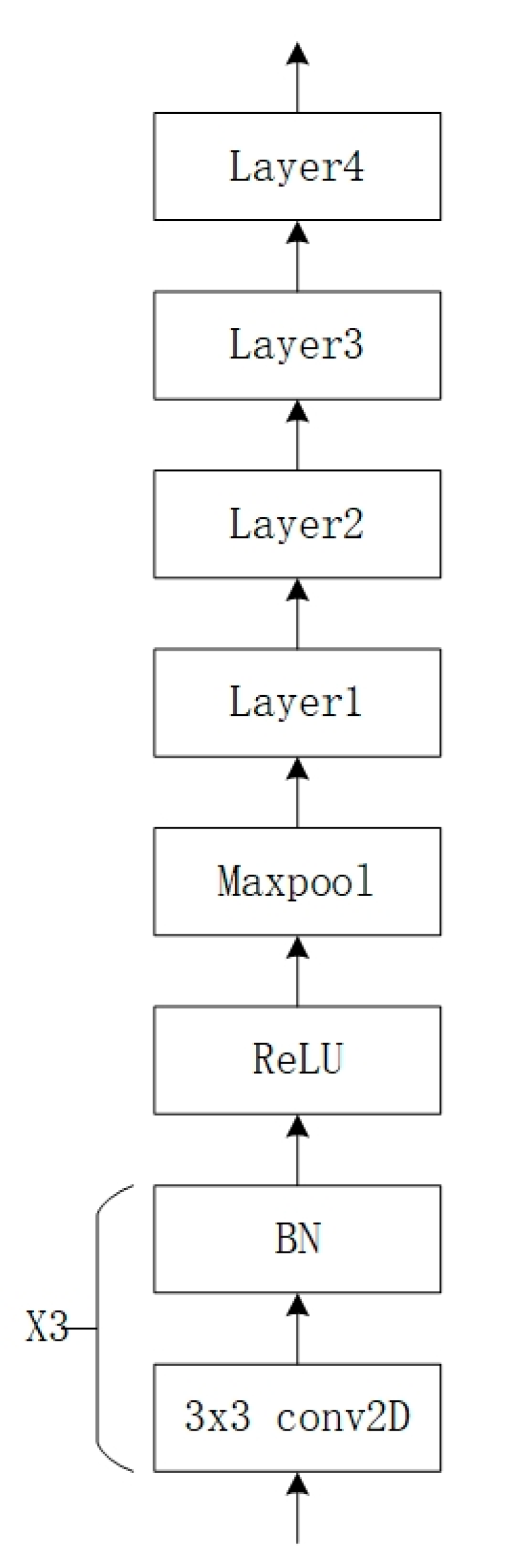
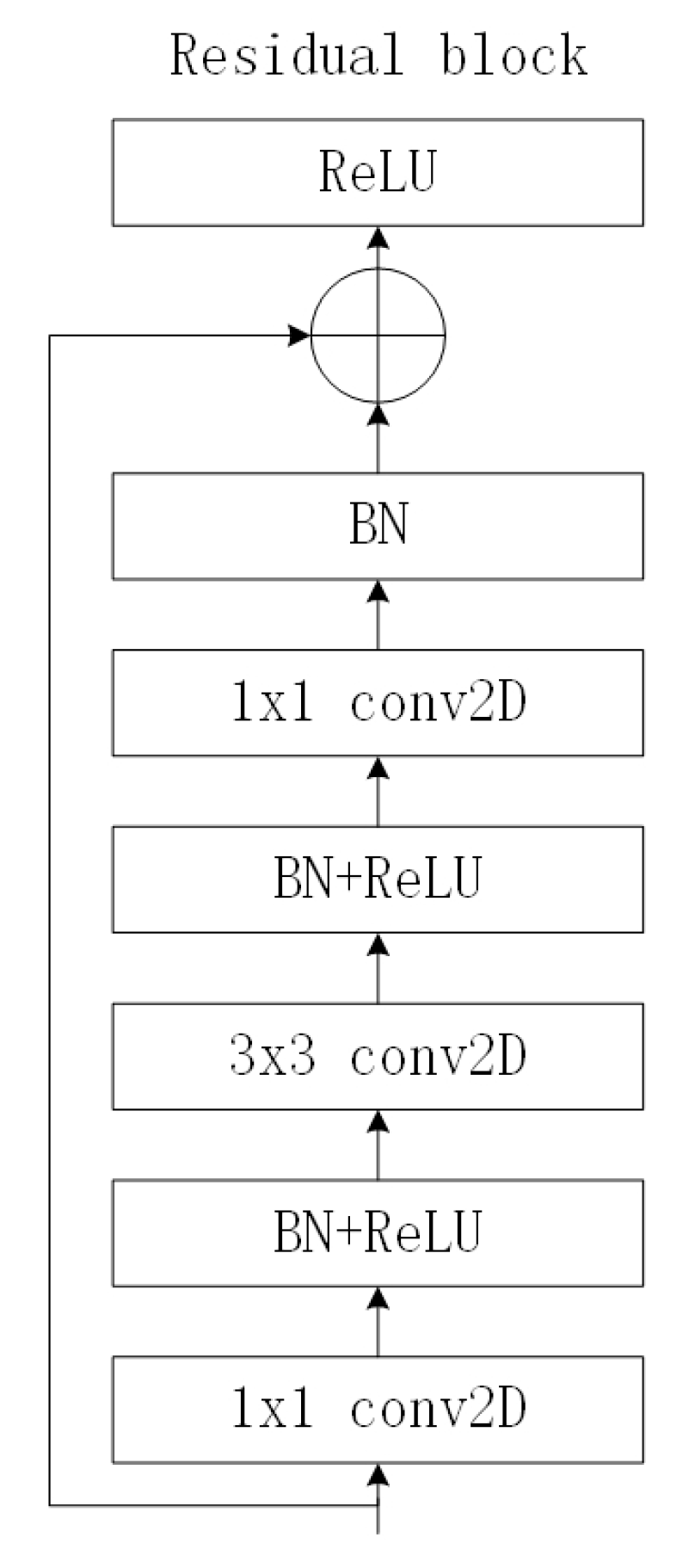











| Layer Name | Residual Blocks |
|---|---|
| Layer 1 | |
| Layer 2 | |
| Layer 3 | |
| Layer 4 |
| Device | Parameters | |
|---|---|---|
| CPU | Intel Core i7-9700k @ 3.60 GHz | |
| GPU | GeForce RTX2080 8 GB | |
| RAM | DDR4-3200 MHz 64 GB | |
| OS | Ubuntu 18.04 | |
| Software language | Python 3.7 | |
| Neural network tool | Pytorch | |
| Training setting | Epoch | 15 |
| Classifier learning rate | 0.1 | |
| Learning rate | 0.0025 | |
| Optimizer | SGD | |
| Image size | 473 × 473 | |
| Split-0 | Split-1 | Split-2 | Split-3 |
|---|---|---|---|
| 1: person | 2: bicycle | 3: car | 4: motorcycle |
| 5: airplane | 6: bus | 7: train | 8: truck |
| 9: boat | 10: traffic light | 11: fire hydrant | 12: stop sign |
| 13: parking meter | 14: bench | 15: bird | 16: cat |
| 17: dog | 18: horse | 19: sheep | 20: cow |
| 21: elephant | 22: bear | 23: zebra | 24: giraffe |
| 24: backpack | 26: umbrella | 27: handbag | 28: tie |
| 29: suitcase | 30: frisbee | 31: skis | 32: snowboard |
| 33: sports ball | 34: kite | 35: baseball bat | 36: baseball glove |
| 37: skateboard | 38: surfboard | 39: tennis racket | 40: bottle |
| 41: wine glass | 42: cup | 43: fork | 44: knife |
| 45: spoon | 46: bowl | 47: banana | 48: apple |
| 49: sandwich | 50: orange | 51: broccoli | 52: carrot |
| 53: hot dog | 54: pizza | 55: donut | 56: cake |
| 57: chair | 58: sofa | 59: potted plant | 60: bed |
| 61: dining table | 62: toilet | 63: tv | 64: laptop |
| 65: mouse | 66: remote | 67: keyboard | 68: cellphone |
| 69: microwave | 70: oven | 71: toaster | 72: sink |
| 73: refrigerator | 74: book | 75: clock | 76: vase |
| 77: scissors | 78: teddy bear | 79: hair drier | 80: toothbrush |
| Methods | Split-0 | Split-1 | Split-2 | Split-3 | Mean |
|---|---|---|---|---|---|
| CWT | 40.1 | 43.8 | 39.0 | 42.4 | 41.3 |
| PFENet | 38.5 | 38.6 | 38.2 | 34.3 | 37.4 |
| PFENet++ | 47.5 | 53.3 | 47.3 | 46.4 | 48.6 |
| Proposed | 35.0 | 40.5 | 39.4 | 41.2 | 39.0 |
| Methods | Split-0 | Split-1 | Split-2 | Split-3 | Mean |
|---|---|---|---|---|---|
| CWT | 32.2 | 36.0 | 31.6 | 31.6 | 32.9 |
| PFENet | 34.3 | 33.0 | 32.3 | 30.1 | 32.4 |
| PFENet++ | 40.9 | 46.0 | 42.3 | 40.1 | 42.3 |
| Proposed | 34.3 | 37.9 | 32.2 | 34.0 | 34.6 |
| Methods | Split-0 | Split-1 | Split-2 | Split-3 | Mean |
|---|---|---|---|---|---|
| CWT | 32.2 | 36.0 | 31.6 | 31.6 | 32.9 |
| PFENet | 34.3 | 33.0 | 32.3 | 30.1 | 32.4 |
| PFENet++ | 40.9 | 46.0 | 42.3 | 40.1 | 42.3 |
| Proposed | 34.3 | 37.9 | 32.2 | 34.0 | 34.6 |
| Proposed (H + M feature) | 33.1 | 33.5 | 30.9 | 31.5 | 32.2 |
| Methods | Split-0 | Split-1 | Split-2 | Split-3 | Mean |
|---|---|---|---|---|---|
| CWT | 40.1 | 43.8 | 39.0 | 42.4 | 41.3 |
| PFENet | 38.5 | 38.6 | 38.2 | 34.3 | 37.4 |
| PFENet++ | 47.5 | 53.3 | 47.3 | 46.4 | 48.6 |
| Proposed | 42.9 | 47.0 | 40.2 | 45.8 | 43.9 |
| Proposed (H + M feature) | 38.0 | 40.7 | 36.1 | 35.8 | 37.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.-H.; Le, P.T.; Jhou, F.-C.; Su, M.-H.; Li, K.-C.; Chen, S.-L.; Pham, T.; He, J.-L.; Wang, C.-Y.; Wang, J.-C.; et al. Few-Shot Image Segmentation Using Generating Mask with Meta-Learning Classifier Weight Transformer Network. Electronics 2024, 13, 2634. https://doi.org/10.3390/electronics13132634
Wang J-H, Le PT, Jhou F-C, Su M-H, Li K-C, Chen S-L, Pham T, He J-L, Wang C-Y, Wang J-C, et al. Few-Shot Image Segmentation Using Generating Mask with Meta-Learning Classifier Weight Transformer Network. Electronics. 2024; 13(13):2634. https://doi.org/10.3390/electronics13132634
Chicago/Turabian StyleWang, Jian-Hong, Phuong Thi Le, Fong-Ci Jhou, Ming-Hsiang Su, Kuo-Chen Li, Shih-Lun Chen, Tuan Pham, Ji-Long He, Chien-Yao Wang, Jia-Ching Wang, and et al. 2024. "Few-Shot Image Segmentation Using Generating Mask with Meta-Learning Classifier Weight Transformer Network" Electronics 13, no. 13: 2634. https://doi.org/10.3390/electronics13132634
APA StyleWang, J.-H., Le, P. T., Jhou, F.-C., Su, M.-H., Li, K.-C., Chen, S.-L., Pham, T., He, J.-L., Wang, C.-Y., Wang, J.-C., & Chang, P.-C. (2024). Few-Shot Image Segmentation Using Generating Mask with Meta-Learning Classifier Weight Transformer Network. Electronics, 13(13), 2634. https://doi.org/10.3390/electronics13132634