
OccTr: A Two-Stage BEV Fusion Network for Temporal Object Detection

Abstract
1. Introduction
- •
- We propose OccTr, a novel framework that integrates the BEV feature and preframe result for sufficient temporal fusion. By incorporating an occupancy grid map, our model enhances the efficiency and accuracy of perception tasks in multicamera autonomous driving.
- •
- We design an occupancy grid map, incorporating an occupancy generation stage and a temporal cues fusion stage, to effectively generate and update the occupancy map using a preframe detector. Furthermore, we successfully integrate two distinct temporal cues—BEV feature and occupancy map—employing diverse methodologies.
- •
- The temporal fusion framework OccTr is assessed on the nuScenes dataset. In comparison to the baseline, OccTr achieves an NDS of 37.35% on the nuScenes test set, surpassing the baseline by 1.94 points. Experiments demonstrate that the prior provided by the back-end detection results effectively improved the accuracy of object detection, and the cross-attention modality of fusion was also very effective.
2. Related Works
2.1. Temporal Camera-Based 3D Perception
2.2. Occupancy-Based Perception
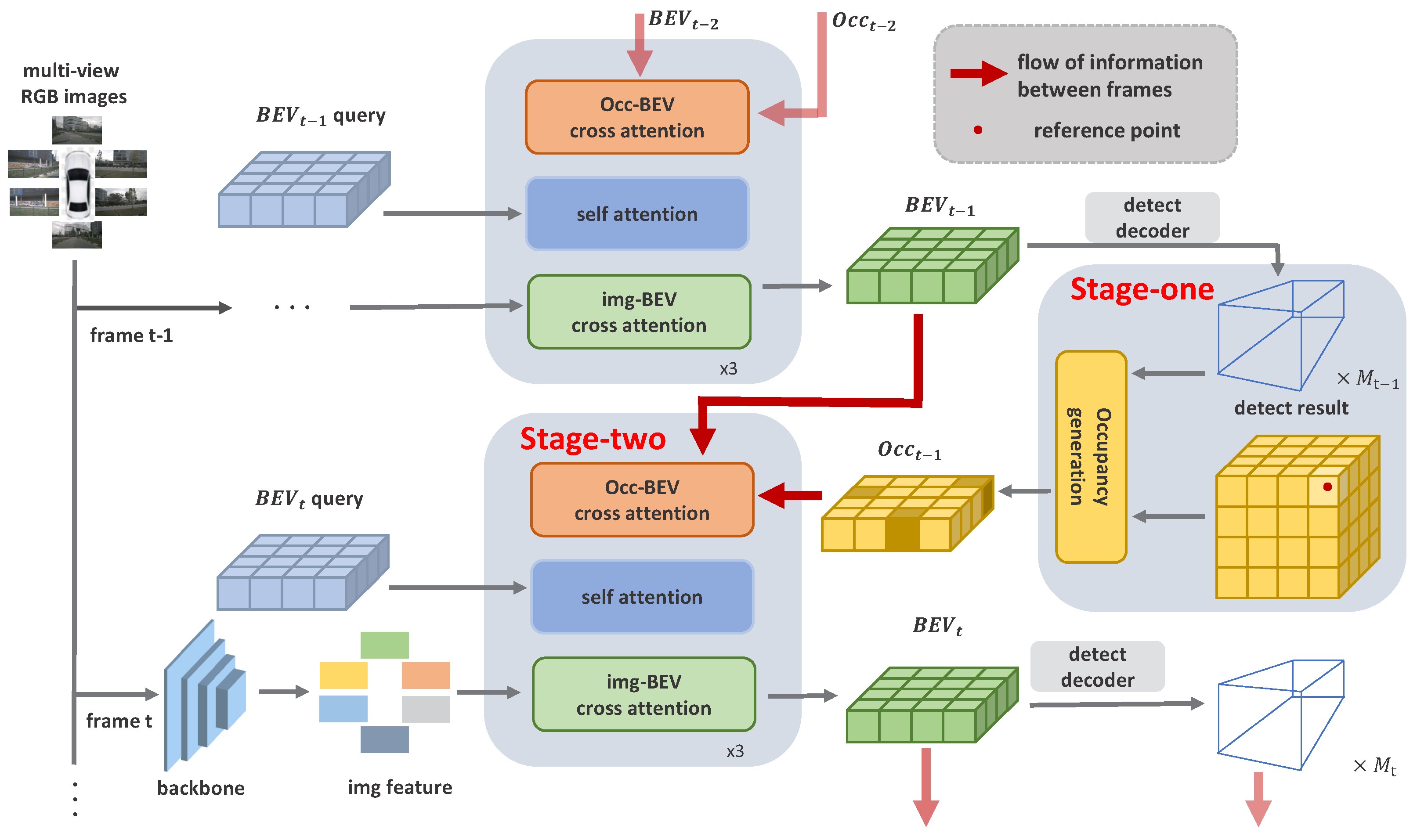
3. Proposed Method
3.1. Overall Architecture
3.2. Occupancy Map Generation
3.3. Time Cues Fusion
3.4. BEV Feature Alignment
4. Experiments and Results
4.1. Datasets
4.2. Implementation Details
4.3. 3D Object Detection Results
4.3.1. Occ-Bev Fusion Methods
4.3.2. Resolution Factor
4.3.3. Object Detection Results
4.4. Ablation Study
4.5. Visualization
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| IOV | Internet of Vehicles |
| BEV | Bird’s-eye view |
| NDS | nuScenes Detection Score |
| IoU | Intersection over union |
| AP | Average precision |
| mAP | Mean average precision |
| APH | Average precision with heading information |
References
- Kong, X.; Wang, J.; Hu, Z.; He, Y.; Zhao, X.; Shen, G. Mobile Trajectory Anomaly Detection: Taxonomy, Methodology, Challenges, and Directions. IEEE Inter. Things J. 2024, 11, 19210–19231. [Google Scholar] [CrossRef]
- Kong, X.; Lin, H.; Jiang, R.; Shen, G. Anomalous Sub-Trajectory Detection With Graph Contrastive Self-Supervised Learning. IEEE Trans. Veh. Technol. 2024, 1–13. [Google Scholar] [CrossRef]
- Hu, P.; Ziglar, J.; Held, D.; Ramanan, D. What you see is what you get: Exploiting visibility for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhou, B.; Krähenbühl, P. Cross-view transformers for real-time map-view semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Li, Z.; Wang, W.; Li, H.; Xie, E.; Sima, C.; Lu, T.; Yu, Q.; Dai, J. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Li, Y.; Yu, Z.; Choy, C.; Xiao, C.; Alvarez, J.M.; Fidler, S.; Feng, C.; Anandkumar, A. Voxformer: Sparse voxel transformer for camera-based 3d semantic scene completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wang, T.; Zhu, X.; Pang, J.; Lin, D. FCOS3D: Fully Convolutional One-Stage Monocular 3D Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Saha, A.; Maldonado, O.M.; Russell, C.; Bowden, R. Translating images into maps. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 3–27 May 2022. [Google Scholar]
- Li, Y.; Huang, B.; Chen, Z.; Cui, Y.; Liang, F.; Shen, M.; Liu, F.; Xie, E.; Sheng, L.; Ouyang, W.; et al. Fast-BEV: A Fast and Strong Bird’s-Eye View Perception Baseline. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 1–14. [Google Scholar] [CrossRef]
- Xie, E.; Yu, Z.; Zhou, D.; Philion, J.; An kumar, A.; Fidler, S.; Luo, P.; Alvarez, J. M2BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Birds-Eye View Representation. arXiv 2022, arXiv:2204.05088. [Google Scholar]
- Can, Y.B.; Liniger, A.; Unal, O.; Paudel, D.P.; Gool, L.V. Understanding Bird’s-eye View Semantic hd-maps Using an Onboard Monocular Camera. arXiv 2020, arXiv:2012.03040. Available online: https://api.semanticscholar.org/CorpusID:227342485 (accessed on 16 June 2024).
- Mohapatra, S.; Yogamani, S.; Gotzig, H.; Milz, S.; Mäder, P. BEVDetNet: Bird’s Eye View LiDAR Point Cloud based Real-time 3D Object Detection for Autonomous Driving. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021. [Google Scholar]
- Beltrán, J.; Guindel, C.; Moreno, F.M.; Cruzado, D.; García, F.; Escalera, A.d. Birdnet: A 3d object detection framework from lidar information. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018. [Google Scholar]
- Wang, Y.; Chao, W.; Garg, D.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-Lidar from Visual Depth Estimation: Bridging the Gap in 3d Object Detection for Autonomous Driving. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D.; Han, S. Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023. [Google Scholar]
- Zhang, Y.; Zhu, Z.; Zheng, W.; Huang, J.; Huang, G.; Zhou, J.; Lu, J. Beverse: Unified perception and prediction in birds-eye-view for vision-centric autonomous driving. arXiv 2022, arXiv:2205.09743. [Google Scholar]
- Li, Y.; Ge, Z.; Yu, G.; Yang, J.; Wang, Z.; Shi, Y.; Sun, J.; Li, Z. BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection. arXiv 2022, arXiv:2206.10092. [Google Scholar] [CrossRef]
- Wang, Y.; Guizilini, V.; Zhang, T.; Wang, Y.; Zhao, H.; Solomon, J.M. Detr3d: 3d object detection from multi-view images via 3d-to-2d queries. In Proceedings of the Conference on Robot Learning (CoRL), London, UK, 8–11 November 2021. [Google Scholar]
- Liu, Y.; Wang, T.; Zhang, X.; Sun, J. Petr: Position embedding transformation for multi-view 3d object detection. arXiv 2022, arXiv:2203.05625. [Google Scholar]
- Philion, J.; Fidler, S. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In Proceedings of the 2020 European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Pan, B.; Sun, J.; Andonian, A.; Oliva, A.; Zhou, B. Cross-view semantic segmentation for sensing surroundings. IEEE Robot. Autom. Lett. 2020, 5, 4867–4873. [Google Scholar] [CrossRef]
- Huang, J.; Huang, G.; Zhu, Z.; Du, D. Bevdet: High-performance multi-camera 3d object detection in bird-eye-view. arXiv 2021, arXiv:2112.11790. [Google Scholar]
- Schönberger, J.L.; Frahm, J.-M. Structure-from-motion revisited. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Jiang, Y.; Zhang, L.; Miao, Z.; Zhu, X.; Gao, J.; Hu, W.; Jiang, Y. PolarFormer: Multi-camera 3D Object Detection with Polar Transformers. In Proceedings of the AAAI conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023. [Google Scholar]
- Yang, C.; Chen, Y.; Tian, H.; Tao, C.; Zhu, X.; Zhang, Z.; Huang, G.; Li, H.; Qiao, Y.; Lu, L.; et al. BEVFormer v2: Adapting Modern Image Backbones to Bird’s-Eye-View Recognition via Perspective Supervision. arXiv 2022, arXiv:2211.10439. [Google Scholar]
- Chen, Y.; Tai, L.; Sun, K.; Li, M. Monopair: Monocular 3d Object Detection Using pairwise spatial relationships. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Hu, A.; Murez, Z.; Mohan, N.; Dudas, S.; Hawke, J.; Badrinarayanan, V.; Cipolla, R.; Kendall, A. FIERY: Future instance prediction in bird’s-eye view from surround monocular cameras. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Huang, J.; Huang, G. Bevdet4d: Exploit temporal cues in multi-camera 3d object detection. arXiv 2022, arXiv:2203.17054. [Google Scholar]
- Yang, W.; Liu, B.; Li, W.; Yu, N. Tracking Assisted Faster Video Object Detection. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 1750–1755. Available online: https://api.semanticscholar.org/CorpusID:199490530 (accessed on 15 July 2019).
- Li, Y.; Bao, H.; Ge, Z.; Yang, J.; Sun, J.; Li, Z. Bevstereo: Enhancing depth estimation in multi-view 3d object detection with dynamic temporal stereo. In Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023. [Google Scholar]
- Elfes, A.; Matthies, L. Sensor integration for robot navigation: Combining sonar and stereo range data in a grid-based representataion. In Proceedings of the 26th IEEE Conference On Decision And Control, Los Angeles, California, USA, 9–11 December 1987; Volume 26, pp. 1802–1807. [Google Scholar]
- Zhang, Y.; Zhu, Z.; Du, D. Occformer: Dual-path transformer for vision-based 3d semantic occupancy prediction. arXiv 2023, arXiv:2304.05316. [Google Scholar]
- Wei, Y.; Zhao, L.; Zheng, W.; Zhu, Z.; Zhou, J.; Lu, J. Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving. arXiv 2023, arXiv:2303.09551. [Google Scholar]
- Sun, J.; Xie, Y.; Zhang, S.; Chen, L.; Zhang, G.; Bao, H.; Zhou, X. You Don’t Only Look Once: Constructing spatial-temporal memory for integrated 3d object detection and tracking. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Huang, Y.; Zheng, W.; Zhang, Y.; Zhou, J.; Lu, J. Tri-perspective view for vision-based 3d semantic occupancy prediction. arXiv 2023, arXiv:2302.07817. [Google Scholar]
- Cao, A.-Q.; de Charette, R. Monoscene: Monocular 3d semantic scene completion. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Newcombe, R.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.; Kohi, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. KinectFusion: Real-time dense surface mapping and tracking. In Proceedings of the 2011 10th IEEE International Symposium On Mixed And Augmented Reality, Basel, Switzerland, 26–29 October 2011; pp. 127–136. [Google Scholar]
- Li, Z.; Zhang, C.; Ma, W.-C.; Zhou, Y.; Huang, L.; Wang, H.; Lim, S.; Zhao, H. Voxelformer: Bird’s-eye-view feature generation based on dual-view attention for multi-view 3d object detection. arXiv 2023, arXiv:2304.01054. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in Perception for Autonomous Driving: Waymo Open Dataset. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Modify | RES | NDS ↑ | mAP ↑ | mATE ↓ | mASE ↓ | mAOE ↓ | mAVE ↓ | mAAE ↓ |
|---|---|---|---|---|---|---|---|---|---|
| OccTr-S | S&D | 200 | 0.1796 | 0.1118 | 1.0651 | 0.3476 | 1.2153 | 1.1771 | 0.4156 |
| OccTr-Cat | Concat | 200 | 0.1784 | 0.1117 | 1.0662 | 0.3632 | 1.1792 | 1.2127 | 0.4116 |
| OccTr | Cro | 200 | 0.1803 | 0.1129 | 1.0632 | 0.3465 | 1.1564 | 1.1857 | 0.4151 |
| Method | Image-RES | Occ-RES | NDS ↑ | mAP ↑ | mATE ↓ | mASE ↓ | mAOE ↓ | mAVE ↓ | mAAE ↓ |
|---|---|---|---|---|---|---|---|---|---|
| VPN | 1600 × 900 | − | 0.3330 | 0.2530 | − | − | − | − | − |
| PointPillars | LiDAR | − | 0.4530 | 0.3050 | 0.5170 | 0.2900 | 0.5000 | 0.3160 | 0.3680 |
| MEGVII | LiDAR | − | 0.6330 | 0.5280 | 0.3000 | 0.2470 | 0.3790 | 0.2450 | 0.1400 |
| FCOS3D | 1600 × 900 | − | 0.3730 | 0.2990 | 0.7850 | 0.2680 | 0.5570 | 1.3960 | 0.1540 |
| DETR3D | 1600 × 900 | − | 0.3740 | 0.3030 | 0.8600 | 0.2780 | 0.4370 | 0.9670 | 0.2350 |
| BEVFormer-tiny | 800 × 450 | − | 0.3541 | 0.2524 | 0.8995 | 0.2937 | 0.6549 | 0.6571 | 0.2158 |
| OccTr-50 | 800 × 450 | 50 × 50 | 0.3688 | 0.2645 | 0.8860 | 0.2927 | 0.6118 | 0.6352 | 0.2083 |
| OccTr-200 | 800 × 450 | 200 × 200 | 0.3735 | 0.2711 | 0.8757 | 0.2916 | 0.6199 | 0.6168 | 0.2165 |
| Method | Img-RES | Occ-RES | IoU = 0.5 | IoU = 0.7 | ||
|---|---|---|---|---|---|---|
| L1 | L2 | L1 | L2 | |||
| DETR3D | 1600 × 900 | - | 0.220 | 0.216 | 0.055 | 0.051 |
| BEVFormer-tiny | 800 × 450 | - | 0.151 | 0.120 | 0.038 | 0.032 |
| OccTr | 800 × 450 | 200 × 200 | 0.154 | 0.122 | 0.039 | 0.032 |
| Method | Modify | NDS ↑ | mAP ↑ |
|---|---|---|---|
| BEVFormer-tiny | − | 0.3541 | 0.2524 |
| OccTr-mask | O | 0.3605 | 0.2594 |
| OccTr | O&C | 0.3735 | 0.2711 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, Q.; Yu, X.; Ou, L. OccTr: A Two-Stage BEV Fusion Network for Temporal Object Detection. Electronics 2024, 13, 2611. https://doi.org/10.3390/electronics13132611
Fu Q, Yu X, Ou L. OccTr: A Two-Stage BEV Fusion Network for Temporal Object Detection. Electronics. 2024; 13(13):2611. https://doi.org/10.3390/electronics13132611
Chicago/Turabian StyleFu, Qifang, Xinyi Yu, and Linlin Ou. 2024. "OccTr: A Two-Stage BEV Fusion Network for Temporal Object Detection" Electronics 13, no. 13: 2611. https://doi.org/10.3390/electronics13132611
APA StyleFu, Q., Yu, X., & Ou, L. (2024). OccTr: A Two-Stage BEV Fusion Network for Temporal Object Detection. Electronics, 13(13), 2611. https://doi.org/10.3390/electronics13132611