Abstract
The portrayal of emotions by virtual characters is crucial in virtual reality (VR) communication. Effective communication in VR relies on a shared understanding, which is significantly enhanced when virtual characters authentically express emotions that align with their spoken words. While human emotions are often conveyed through facial expressions, existing facial animation techniques have mainly focused on lip-syncing and head movements to improve naturalness. This study investigates the influence of various factors in facial animation on the emotional representation of virtual characters. We conduct a comparative and analytical study using an audio-visual database, examining the impact of different animation factors. To this end, we utilize a total of 24 voice samples, representing 12 different speakers, with each emotional voice segment lasting approximately 4–5 s. Using these samples, we design six perceptual experiments to investigate the impact of facial cues—including facial expression, lip movement, head motion, and overall appearance—on the expression of emotions by virtual characters. Additionally, we engaged 20 participants to evaluate and select appropriate combinations of facial expressions, lip movements, head motions, and appearances that align with the given emotion and its intensity. Our findings indicate that emotional representation in virtual characters is closely linked to facial expressions, head movements, and overall appearance. Conversely, lip-syncing, which has been a primary focus in prior studies, seems less critical for conveying emotions, as its accuracy is difficult to perceive with the naked eye. The results of our study can significantly benefit the VR community by aiding in the development of virtual characters capable of expressing a diverse range of emotions.
1. Introduction
The continuous advancement of virtual reality (VR) and augmented reality (AR) technologies has ushered in an era where people engage in activities such as concerts, fan meetings, and professional tasks within virtual environments [1,2,3]. The recent emergence of the ‘Metaverse’ has further expanded these horizons, enabling users to perform tasks once considered implausible in virtual realms, such as banking and telemedicine [4,5,6,7]. In this evolving landscape of virtual interactions, enhancing the realism and emotional depth of virtual characters becomes increasingly vital to facilitate smooth communication among users [8,9,10,11]. Currently, most three-dimensional (3D) facial animation methods predominantly focus on achieving visual realism, with minimal attention to emotional representation. This emphasis on visual fidelity allows virtual characters to move naturally but falls short of effectively conveying emotions akin to human expressions. Human emotions are primarily expressed through vocal tones and facial expressions [12,13]. Therefore, any discrepancy between the facial expressions of virtual characters and the emotions conveyed through their voices can undermine the accurate transmission of emotions [14,15]. It is paramount for virtual characters to exhibit emotional facial features that are consistent with their vocal expressions to ensure natural and effective communication. In this study, we define several essential facial cues necessary for emotional facial animation and conduct a detailed analysis of how these cues should be precisely defined to reflect both the type and intensity of emotions.
Facial cues are highly effective tools for expressing personal emotions and include elements such as facial expressions, lip movements, head motions, and overall appearance. Facial expressions often serve as the primary focus in emotional facial animation research [16,17,18] and are typically described using the Facial Action Coding System (FACS) [19,20,21,22], a comprehensive framework for characterizing facial movements. However, lip movements, head motions, and appearance also play significant roles in emotional facial animation, contributing to the overall naturalness required to authentically represent human emotions [16,17,18]. Achieving naturalness in facial animation is paramount for effectively conveying human emotions. This naturalness requires the seamless integration of lip movements synchronized with vocal cues, natural head motions, and an overall appearance that aligns with the emotional context.
In this study, we investigated how facial factors influence emotional portrayal to facilitate natural communication. Our study involves constructing a comprehensive dataset aimed at analyzing various facial cues, using a publicly available audio-visual dataset [23] as a foundation. We enhanced this dataset by synthesizing lip movements, head motions, and overall appearances to comprehensively assess their influence on emotional representation. The primary objective of this study was to gain a profound understanding of the effects of facial cues on the generation of emotionally expressive virtual characters.
In order to achieve this, we engaged participants in evaluating and selecting appropriate combinations of facial expressions, lip movements, head motions, and appearances that align with the given emotion and its intensity. Our findings revealed that certain facial cues, namely facial expressions, head motions, and appearances, exhibit significant reliance on the emotions’ arousal or valence [24]. These cues play pivotal roles in effectively conveying emotions and enhancing the overall emotional realism of virtual characters. Moreover, we also found that contrary to our initial assumptions, meticulous attention to lip movement may not be as critical in the realm of 3D facial animation as previously thought. It appears that the influence of lip movements on emotional representation may be less substantial than anticipated.
Our results offer valuable insights that can significantly contribute to the development of emotionally expressive virtual characters, thereby enriching the immersive virtual communication experience. Notably, to the best of our knowledge, this research represents the first effort to establish a concrete correlation between facial cues and emotional representation in the field of virtual character animation. The main contributions of this study can be summarized as follows:
- 1.
- The comprehensive analysis and assessment of facial animation factors: This study conducts an in-depth analysis of various facial factors—including facial expressions, lip movements, head motions, and overall appearance—to evaluate their impact on emotional representation in virtual characters. Using synthesized animations and participant feedback, we assess how these factors contribute to effective emotional conveyance.
- 2.
- The identification and re-evaluation of key emotional cues: This research identifies crucial facial cues, such as facial expressions, head motions, and appearances, that are essential for conveying emotions, challenging previous assumptions about the role of lip movement in 3D facial animation. Recognizing the importance of these cues guides the development of more authentic virtual characters capable of expressing a diverse range of emotions.
- 3.
- A pioneering contribution to VR/AR and emotional representation research: This study represents a pioneering effort to establish a concrete correlation between facial cues and emotional representation in virtual character animation. By offering valuable insights into emotional portrayal and its impact on immersive virtual communication experiences, it significantly contributes to the development of emotionally targeted virtual characters, potentially shaping the future of VR/AR technologies.
2. Related Work
Emotions in human beings are undeniably intricate and multifaceted, making them challenging to discern solely through facial expressions, even with a wealth of data available on the individual [25]. Consequently, emotional states are typically defined by a combination of various factors, including facial expressions, eye fixations, and variations in pupil size [26,27,28,29]. However, representing human emotions using 3D virtual characters within virtual environments presents inherent limitations. The most precise method involves attaching a motion capture device to a person’s face to capture their facial expressions in real time. This method is more effective than any 3D face generation technique because it can encompass the vast range of emotional expressions exhibited by an individual. Nonetheless, due to physical and spatial constraints, researchers have focused on effectively conveying emotions in the facial animation of 3D virtual characters.
In the early stages of facial animation research, the primary focus was on generating mouth shapes aligned with audio cues. The authors of [16] pioneered the development of an end-to-end reconstruction-based network using an image-to-image translation approach based on audio cues. Subsequently, Wav2Lip [17] introduced a technique for inpainting mouth areas. While these reconstruction-based methods primarily concentrated on mouth shapes, they often overlooked other crucial factors such as facial expressions and head motion.
In response to these limitations, methods emerged that incorporated both audio-image synchronization and head motions. Researchers have [18,30] proposed models that introduced rhythmic head motions into the animation process. The pose-controllable audio-visual system (PC-AVS) [31,32,33,34] expanded upon these approaches by generating talking faces with dynamic motions encompassing mouth, eyebrow, and head movements. Unlike previous studies that focused primarily on lip synchronization with audio, these approaches aimed to create more natural facial animations by incorporating critical elements such as facial expressions and head motion.
In the realm of facial animation, emotional representation is just as crucial as lip synchronization, facial expression, and head motion. Recent research has witnessed a surge in studies dedicated to creating emotionally expressive talking faces. The authors of [35] extracted facial details from a database and projected them onto a 3D head model, facilitating the creation of realistic expressions. However, these generated emotional expressions often focused on the upper part of the face and lacked variation for extended animations. The authors of [36] introduced an end-to-end network that learned a latent code for controlling the generation of 3D mesh animations. In [37], the authors proposed speech-driven talking face generation with emotional conditioning. The authors of [38] developed the granularly controlled audio-visual talking heads (GC-AVT), enabling the generation of expressive faces that synchronized not only mouth shapes and controllable poses but also precisely animated emotional expressions.
In the pursuit of generating emotional talking heads, as previously highlighted, multiple factors such as facial expressions and head motions must be considered alongside audio-lip synchronization [39,40,41,42]. However, there are limited data on how each of these factors should be combined for optimal emotional representation to achieve maximum naturalness [43]. Therefore, this study delves into a comprehensive investigation of the effects of various factors, including facial expressions, lip movements, head motions, and overall appearance—which are all significant in emotional facial animation—on the naturalness of the final output.
3. Experiment Preparation
We defined four key features—facial expressions, lip movements, head motions, and appearance—as critical factors in emotional facial animation and prepared them for experimentation, as outlined below.
3.1. Data Selection
We utilized the multi-view emotional audio-visual dataset (MEAD) [23] to generate synthetic facial animations. The choice of the MEAD dataset stemmed from its extensive collection of sentences representing various emotion types and intensities, rendering it a valuable resource among publicly available audio-visual datasets. This dataset encompasses talking-face videos captured from 60 actors and actresses, each expressing eight emotions (i.e., anger, disgust, contempt, fear, happiness, sadness, surprise, and neutral) at three intensity levels (i.e., weak, medium, and strong). Examples from the MEAD dataset are illustrated in Figure 1.

Figure 1.
Examples from the MEAD dataset.
While some speakers had recordings of all eight emotions at three intensity levels, others only had recordings for certain emotions. Upon exploring the MEAD dataset, we identified 12 speakers who exhibited all eight emotions at three intensity levels. Consequently, our experiments focused on four emotions: Anger, Happiness, Sadness, and Surprise. The dataset comprises a total of 12 speakers, evenly divided between genders (six males and six females), each proficient in conveying specific emotions. In order to ensure diversity in lip movements, we deliberately avoided using identical sentences whenever possible, resulting in a selection of informal yet varied sentences.
3.2. Facial Expression and Lip Movement
We utilized the detailed expression capture and animation (DECA) model proposed in [44] to extract 3D facial animation data from the MEAD dataset. Figure 2 showcases examples of the 3D facial animation data obtained from the MEAD dataset using the DECA model. For each video entry in the MEAD dataset, we employed DECA to execute the FLAME (faces learned with an articulated model and expressions) fitting algorithm [45,46,47,48,49]. Specifically, we relied on the fitting outcomes produced by the FLAME template model exclusively to mitigate potential disparities in the fine-grained details of the 3D facial models, which could potentially affect participants’ assessments.
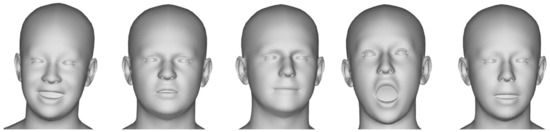
Figure 2.
Examples of the 3D facial animation data obtained from the MEAD dataset using the DECA model.
Additionally, we meticulously refined the 3D facial models to rectify any inaccuracies resulting from the template model-fitting algorithm, addressing aspects such as eye blinking and mouth shapes. Furthermore, to facilitate the analysis of the influence of lip movement, we artificially adjusted the lengths of voice segments in different sentences.
3.3. Head Motion
Since the 3D facial animation data used in our experiments were obtained through the FLAME fitting algorithm [45,46,47,48,49], we were able to manually control head motion. Consequently, we conducted experiments to ascertain the most crucial direction (angle) for human perception of head motion. We assessed the impact of head motion on the naturalness of 3D facial animation by comparing several synthesized datasets, as outlined in Table 1: no head motion (Motion 1), without pitch (Motion 2), without yaw (Motion 3), without roll (Motion 4), and ground truth (Motion 5).

Table 1.
The table presents various synthesized head motions denoted by the presence (‘O’) or absence (‘X’) of factors such as pitch, yaw, and roll. For instance, in motion 3, there is motion in the pitch and roll directions but no motion in the yaw direction. These data were utilized in Experiment IV.
3.4. Appearance
We acquired the facial texture using the FLAME fitting algorithm for each video data entry. In addition to establishing the original facial texture as a neutral reference, we also created two additional variations: a bright image and a dark image, based on this neutral reference. Figure 3 showcases examples of these images. Consequently, the participants were presented with three appearance options to choose from. Our aim was to investigate the connection between emotion representation and appearance by prompting participants to select the appearance that most accurately aligned with the emotion or mood conveyed by the given voice.

Figure 3.
Three appearance options: (a) original facial texture image, (b) bright image, and (c) dark image.
4. Experimental Design
We conducted six perceptual experiments to investigate the impact of facial cues on the expression of emotions by virtual characters. In order to achieve natural facial animation, we employed the DECA algorithm for facial animation generation, utilizing the template model outlined in Section 3.2. In order to accurately evaluate the effectiveness of each facial cue, we selected four distinct emotions (i.e., anger, happiness, sadness, and surprise), as depicted in Figure 4. We excluded disgust, contempt, and fear because the facial expression and voice changes for these emotions do not appear clearly according to intensity levels. When changes are too subtle or unclear, participants have difficulty recognizing the emotions, hindering the accuracy of the experiments. Therefore, we focused on the four emotions (anger, happiness, sadness, and surprise) that participants could more accurately perceive.
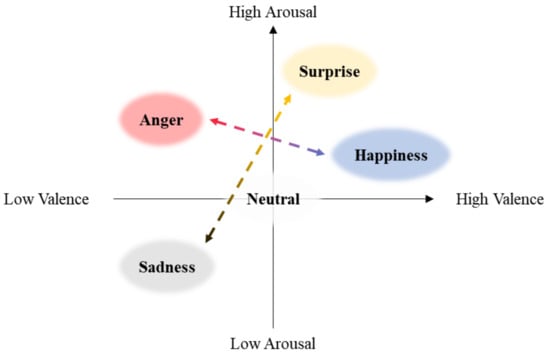
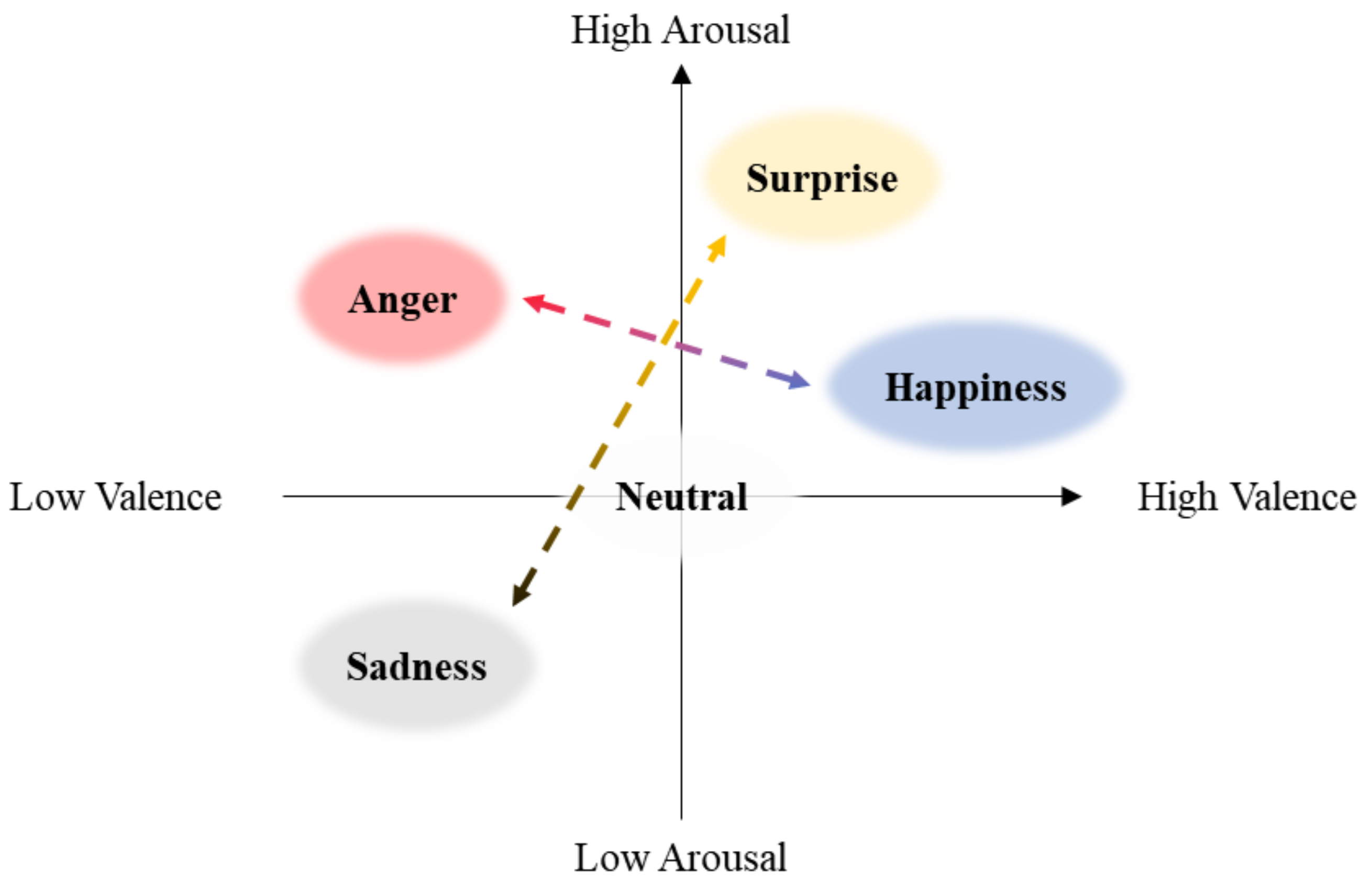
Figure 4.
The graph depicts the emotion types we utilized along the arousal and valence axes. Specifically, Anger and Happiness are diametrically opposed on the valence axis, showcasing the contrast between negative and positive valence. In contrast, Sadness and Surprise are positioned at opposite ends of the arousal axis, delineating the spectrum of emotional intensity.
In order to enable an analysis of emotional intensity, we exclusively focused on emotions categorized as Level 1 (weak) and Level 3 (strong). The questions posed in the six perceptual experiments are as follows:
- Experiment I: Voice emotion—What is the emotion being conveyed by the given voice?
- Experiment II: Facial expression—Choose a facial expression that matches the emotion being conveyed by the given voice.
- Experiment III: Lip movement—Choose all facial animations that match the given voice and its lip movements.
- Experiment IV: Head motion—Choose all head motions that move naturally according to the given voice.
- Experiment V: Appearance—Choose all appearances that match the mood of the given voice.
- Experiment VI: Naturalness score—Provide scores for all facial animations.
We divided the components of emotional facial animation into static and temporal parts. The static part includes the quality and texture of the 3D mesh. Given the complexity and multiple factors influencing 3D mesh quality, it was not chosen as a key factor. Instead, we focused on the brightness (appearance) of the texture. The temporal part encompasses facial expressions, mouth shape, head movement, eye blinking, and hair movement. We selected facial expression and mouth shape as key factors due to their direct relationship with voice. Head movement was also included as a key factor because it significantly affects the naturalness of animation. Eye blinking and hair movement, while important, were not considered critical for this study and are planned for future research.
We recruited a group of 20 participants (six females and 14 males) with ages ranging from 23 to 34 years (mean age = 27.8 years; standard deviation = 8.06), all of whom provided informed consent. None of the participants had prior experience with VR/AR technology, ensuring their unfamiliarity with 3D virtual characters and maintaining the objectivity of the experiments. Each participant sequentially responded to all six perceptual experiments using a single voice sample. The participants could choose one or multiple answers for each perceptual experiment.
In Experiments I and II, the participants selected a single response, as these experiments were not designed to assess the naturalness of facial animation. Conversely, in Experiments III, IV, and V, the participants could choose multiple options. In Experiment VI, the participants provided scores for each synthesized facial animation.
We utilized a total of 24 voice samples, representing 12 different speakers, with each emotional voice segment lasting approximately 4–5 s. During Experiments I to V, participants listened to these brief emotional voice samples and provided responses to the respective questions, with an average response time of approximately 20 s per question. The total duration of the experiment for each participant was approximately 30 min. After completing all the experiments, the participants were given the opportunity to provide feedback. The specific details of each perceptual experiment are elaborated upon below.
4.1. Experiment I: Voice Emotion
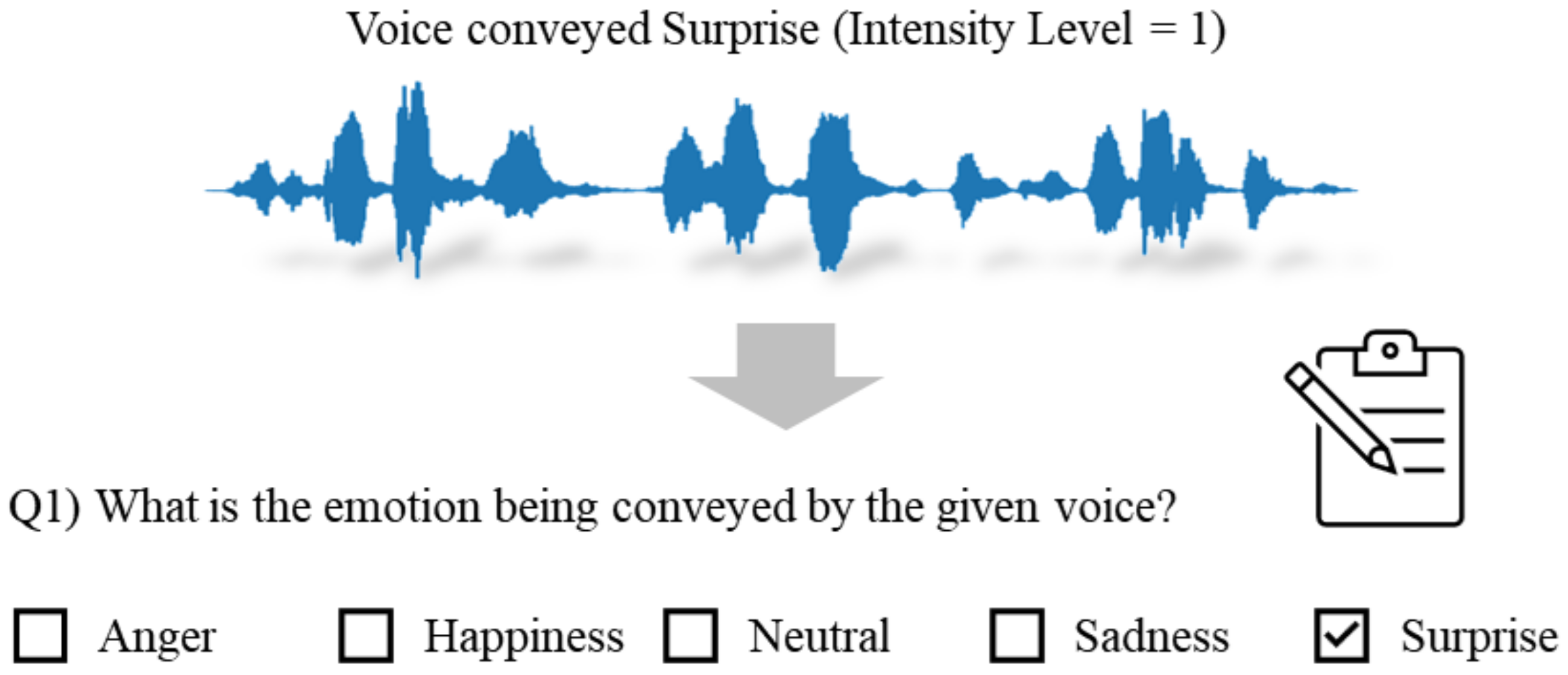
The goal of all the perceptual experiments is to investigate how emotions represented by given voices should be accurately projected onto a 3D virtual character to appear natural. Therefore, it is crucial to initially determine which emotion participants perceive from the provided voice samples and the intensity of that emotion. In Experiment I, as depicted in Figure 5, the participants were presented with a choice of five emotions: Anger, Happiness, Neutral, Sadness, and Surprise. Each participant was instructed to choose only one emotion after hearing the voice.
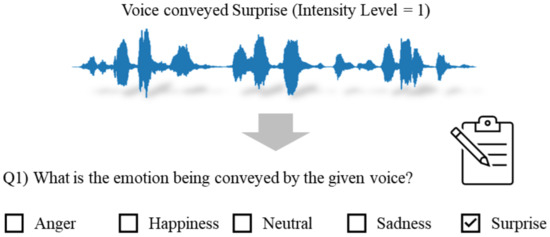
Figure 5.
Illustration of the subjective assessment phase of Experiment I.
4.2. Experiment II: Facial Expression
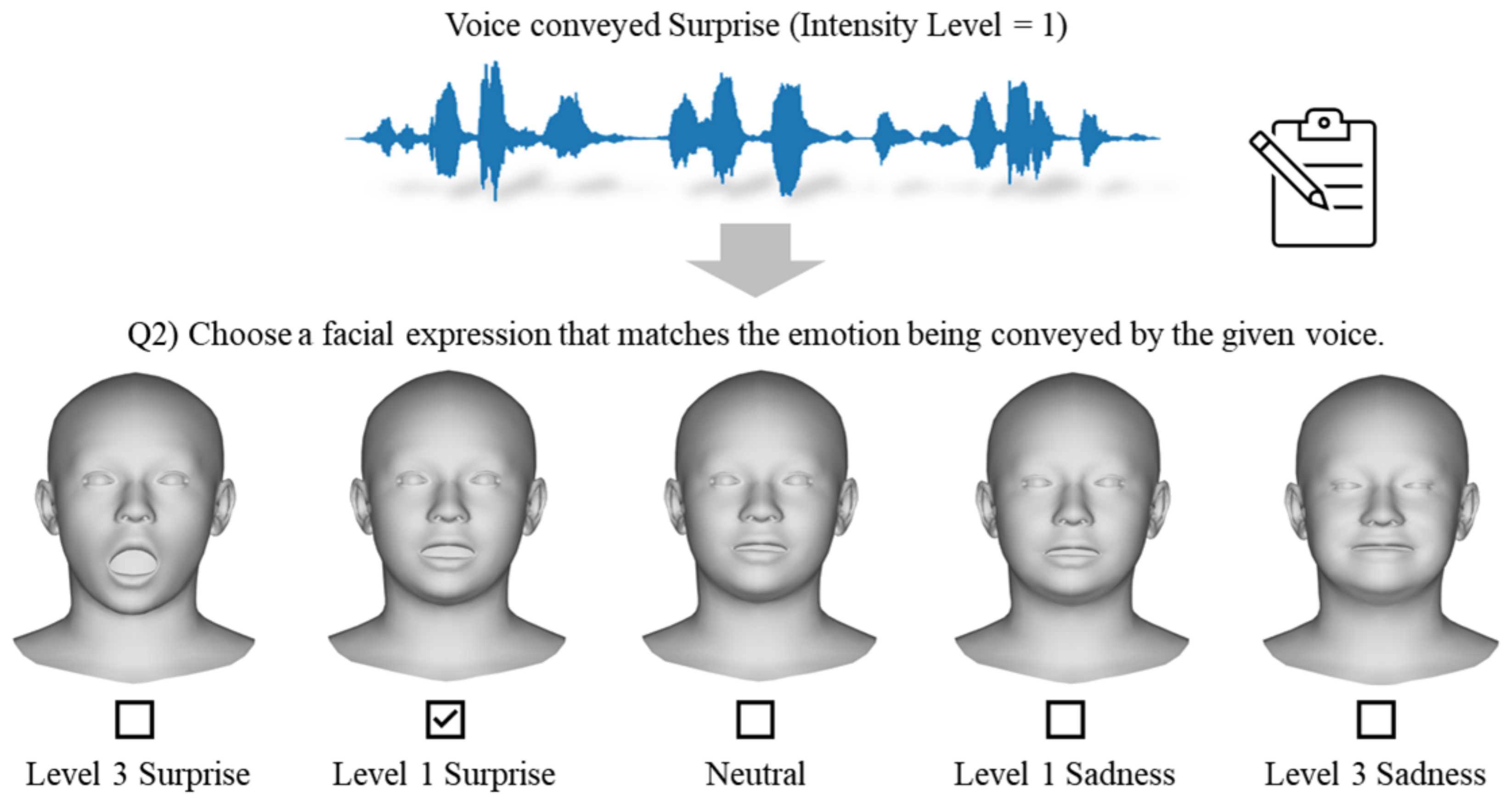
The emotional facial expressions in FACS are typically derived from combinations of facial action units (AUs), as shown in Table 2. However, individuals often convey emotions in real-life situations without strictly adhering to specific combinations of AUs. Therefore, in Experiment II, the participants were asked to indicate which facial expression appeared natural for the emotion they perceived during Experiment I. The participants were presented with five expression choices, each representing emotions opposite to the actual emotion conveyed in terms of arousal or valence, along with a neutral option. For instance, as depicted in Figure 6, if the voice conveyed Surprise, the available options to the participants would include Level 3 Surprise, Level 1 Surprise, Neutral, Level 1 Sadness, and Level 3 Sadness. Each participant was asked to choose only one facial expression after hearing the voice.
Table 2.
Mapping between emotions and actions units in the Facial Action Coding System (FACS).
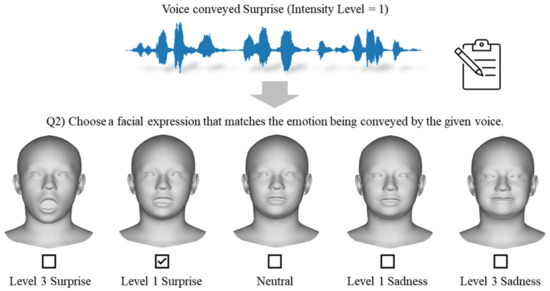
Figure 6.
Illustration of the subjective assessment phase of Experiment II.
4.3. Experiment III: Lip Movement
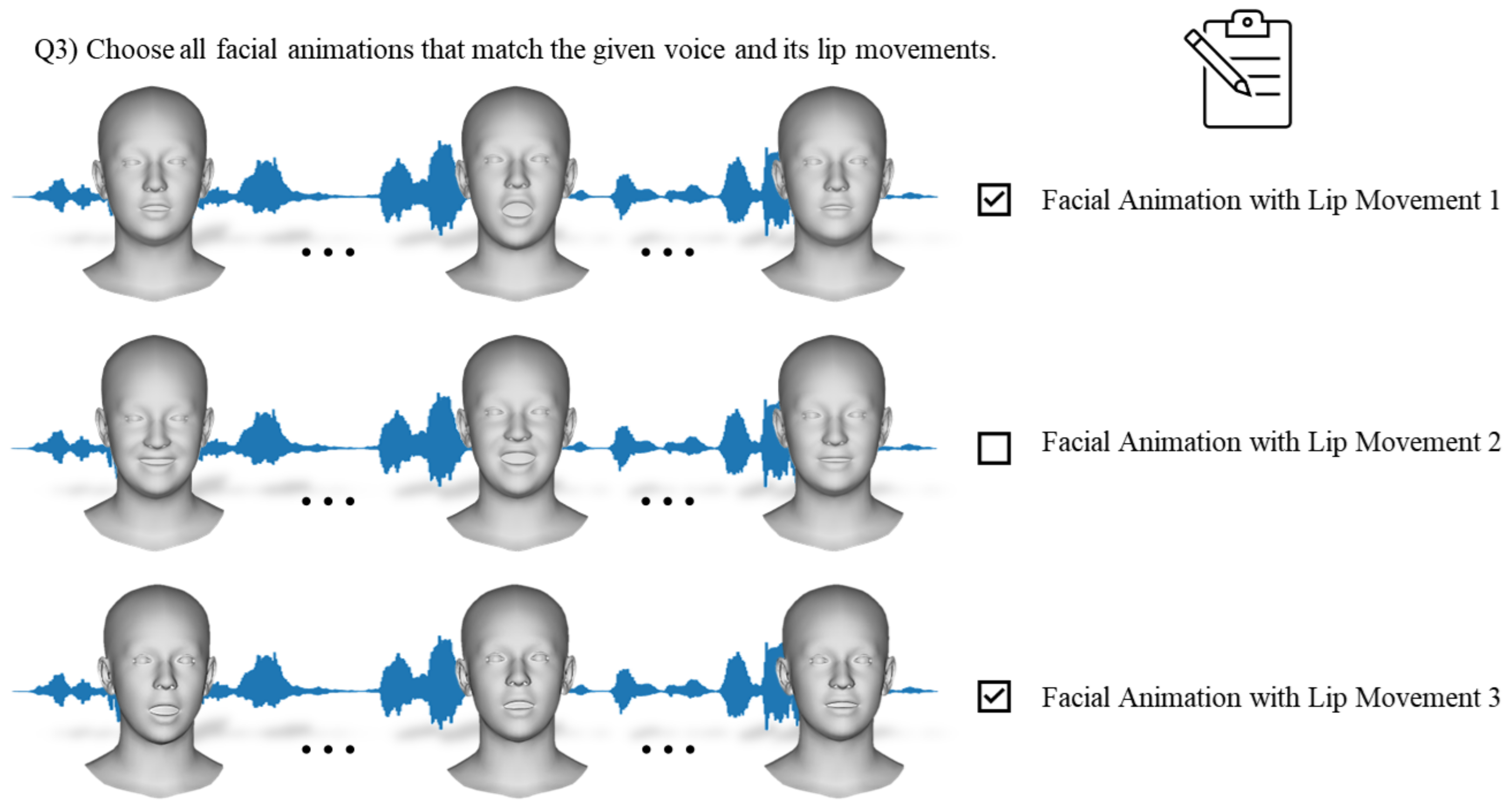
Experiment III aimed to explore the relationship between lip movement and emotional facial animation. In the context of natural facial animation, it is crucial for lip movements to synchronize with the voice and convey the intended emotion. However, minor discrepancies in the voice or inaccuracies in lip movements may not necessarily appear unnatural. For precise analysis, as illustrated in Figure 7, the participants were presented with three options for lip movements, including those corresponding to the provided voice. For example, in the figure, if lip movement 1 represents the ground truth lip movement for the given voice, lip movements 2 and 3 represent the lip movements for other voices, respectively. The script for the provided voice was not disclosed during the experiment. The participants could select one or more facial animations.
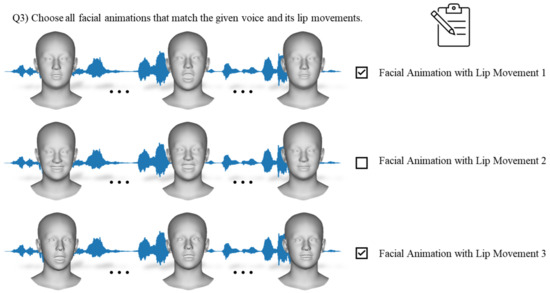
Figure 7.
Illustration of the subjective assessment phase of Experiment III.
4.4. Experiment IV: Head Motion
Head motion, much like lip movement, significantly contributes to enhancing naturalness in facial animation. Typically, when individuals speak, there is a subtle but noticeable movement of the head. We categorized head motion into three directions: pitch, yaw, and roll. Experiment IV was designed to evaluate the naturalness of facial animation when head motion was absent in each of these three directions individually. Essentially, the participants were presented with five options, each representing the absence of head motion in a specific direction, as detailed in Table 1. To this end, we generated facial animations with five different head motions. During the experiment, each participant could select one or more facial animations.
4.5. Experiment V: Appearance
Generally, no direct correlation exists between an individual’s emotions and their physical appearance. For instance, a person who appears glamorous might actually be feeling depressed and sad, while someone with a tired appearance could be quite happy. However, in virtual interactions where face-to-face communication is absent, their appearance can become a crucial factor in accurately conveying emotions.
Hence, in Experiment V, the participants were tasked with selecting an appropriate appearance for the facial animation that matched the given voice. As depicted in Figure 3, three appearance options were provided: neutral, bright, and dark. During the experiment, each participant had the opportunity to select one or more facial animations.
4.6. Experiment VI: Naturalness Score
In Experiment VI, the participants evaluated all the synthesized facial animations created using the factors selected in Experiments II to V, alongside the ground truth animation corresponding to the given voice. A Likert scale [50] was used for the quantitative assessment, ranging from 0 to 10. The number of synthesized facial animations varied from a minimum of 1 to a maximum of 45 (one facial expression from Experiment II × three types of lip movements from Experiment III × five types of head motions from Experiment IV × three types of appearances from Experiment V). A comparison was made between the highest score among the synthesized animations and the evaluation score of the ground truth.
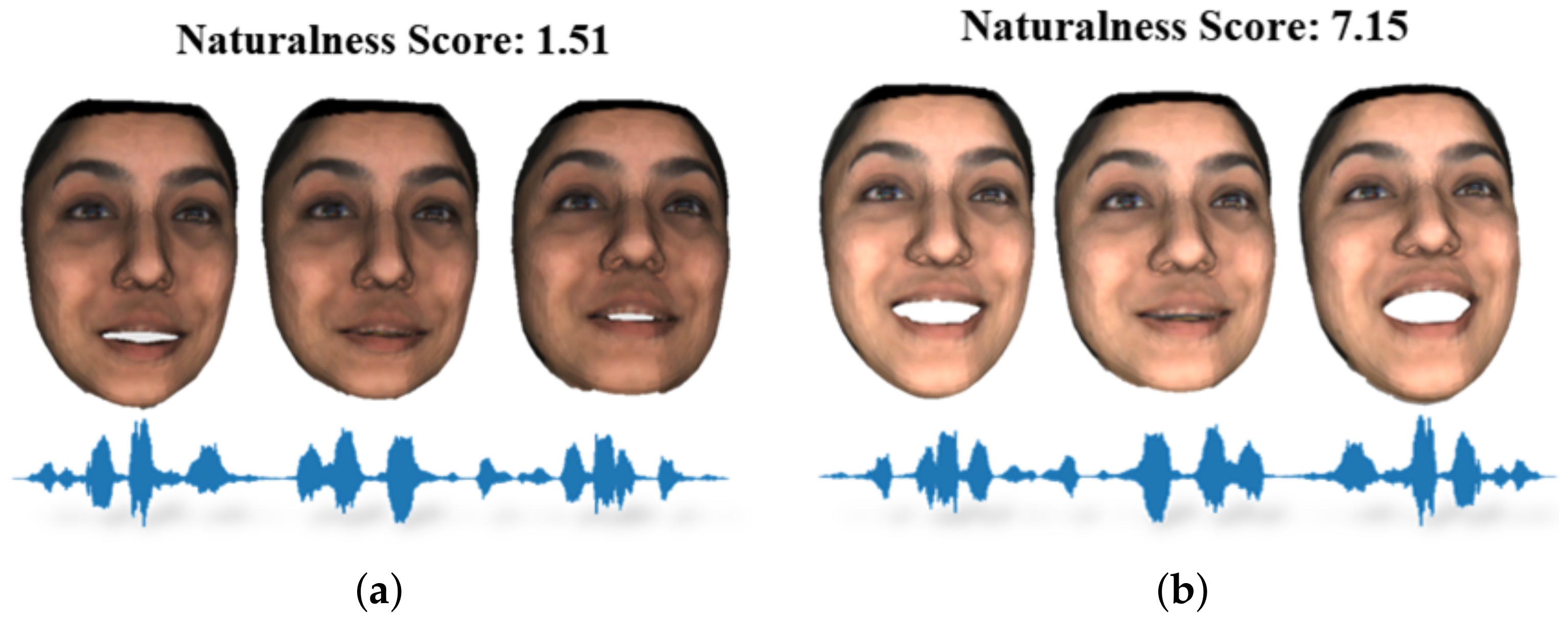
Figure 8a,b showcase two 3D facial animations that share the same joyful voice, “Those musicians harmonize marvelously!” However, their naturalness scores differ significantly due to the presence of distinct emotional facial expressions.
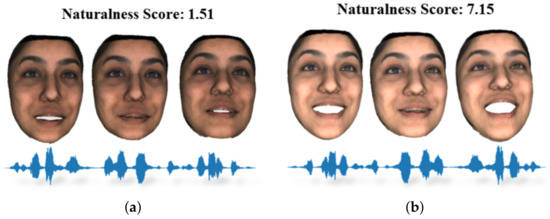
Figure 8.
(a) Happy Voice + Neutral Face and (b) Happy Voice + Happy Face; ensuring alignment between the voice and facial expressions is crucial for conveying authentic human emotions. When generating a virtual face, several key facial cues must be considered: facial expression, lip movement, head motion, and overall appearance. These factors collectively contribute to the naturalness of facial animation, making it a critical aspect of emotion conveyance.
5. Results
We conducted statistical analyses for each of the perceptual experiments. In Experiments I, II, and V, we considered a single within-subject factor (Actor/Actress). In Experiment III, we included two within-subject factors (Actor/Actress and Lip movement), and in Experiment IV, we employed two within-subject factors (Actor/Actress and Head motion). Further details on the analysis of each perceptual experiment are presented in the subsequent subsections.
5.1. Experiment I: Voice Emotion
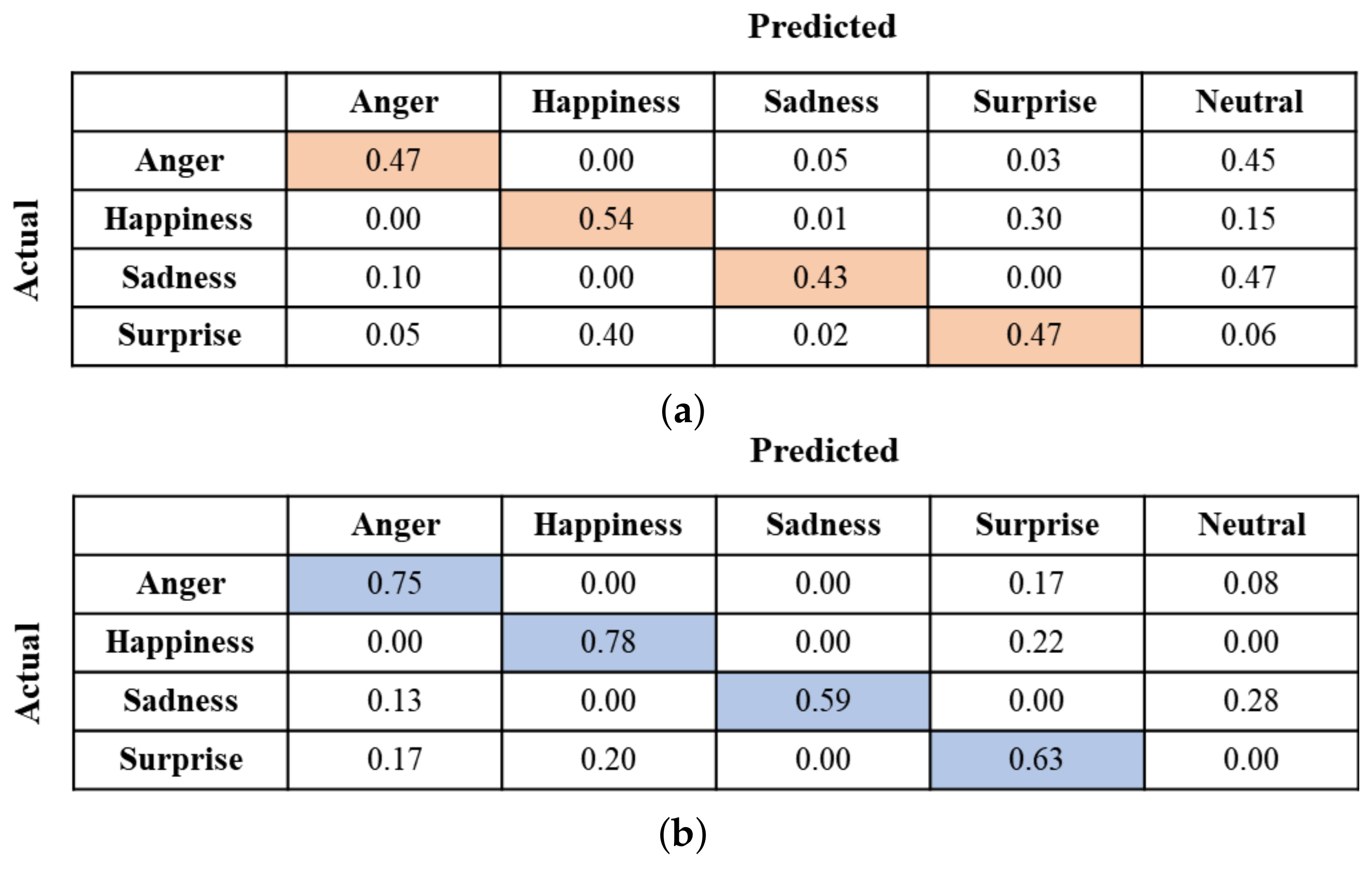
In Figure 9, the confusion matrices depict the emotions perceived by the participants based on the given voice. The diagonal elements in each confusion matrix indicate the correctly predicted rates for emotions. As shown in Figure 9a, when the emotion intensity is low, the accuracy of estimating emotions is significantly low. From the figure, we observed that misprediction, where the actual emotion is predicted as another emotion, occurred frequently for all four emotions. The participants often confused Happiness with Surprise and vice versa. Additionally, Anger and Sadness are mostly mispredicted as Neutral. Conversely, when the emotion intensity is high, the participant’s ability to accurately identify emotions improved, as demonstrated in Figure 9b. From this figure, we also observed that the rate of mispredicting Anger as Surprise somewhat increases and vice versa. These observations indicate that participants often confuse Anger with Surprise and vice versa when emotion intensity is high. For all emotions, the rate of mispredicting an emotion as Neutral decreases significantly. However, some participants still confuse Sadness with Neutral. This suggests that solely relying on the voice is insufficient for precise emotion recognition.
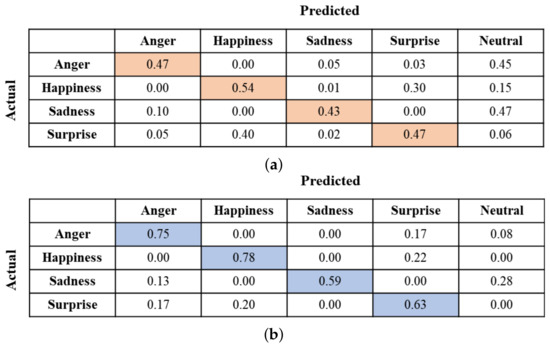
Figure 9.
Confusion matrices depicting the chosen emotions based on their corresponding intensity levels in response to the given voice. (a) Level 1 and (b) Level 3.
5.2. Experiment II: Facial Expression
The outcomes of Experiment II were influenced by the emotions and intensities that the participants selected in Experiment I rather than that of the original emotions and intensities of the provided voices. Remarkably, over 95% of the participants chose a facial expression that matched the emotion they selected in Experiment I. During the experiment, we observed that participants predominantly favored widened eyes for emotions characterized by high arousal, while they preferred closed eyes for emotions with low arousal. These results indicate that the distinction in eye size emerged as a significant factor in conveying emotional intensity. Additionally, as emotional valence increased, the participants chose expressions with higher mouth tails, whereas lower valence emotions were linked to expressions with lowered mouth tails. This finding indicates that the varying movement of mouth tails played a significant role in conveying the emotional valence of the 3D character. Moreover, over 70% of participants deemed a Level 3 facial expression to be the most natural representation of emotional facial expression. These findings indicate that when conveying emotions with 3D virtual characters, exaggerated facial expressions are perceived as more natural by humans, irrespective of the emotion’s intensity.
5.3. Experiment III: Lip Movement
During Experiment III, each participant evaluated 24 different voices, resulting in a total of 480 data points collected (24 voices per participant × 20 participants), as presented in Table 3. Since the participants could select one or more facial animations, the number of answers submitted by each participant varied from one to three. As indicated in Table 3, approximately 85.6% (411 out of 480) of the data received more than one answer. These results indicate that precise lip-synchronization is not significantly important for emotional representation in virtual characters.
Table 3.
Distribution of data obtained in Experiment III.
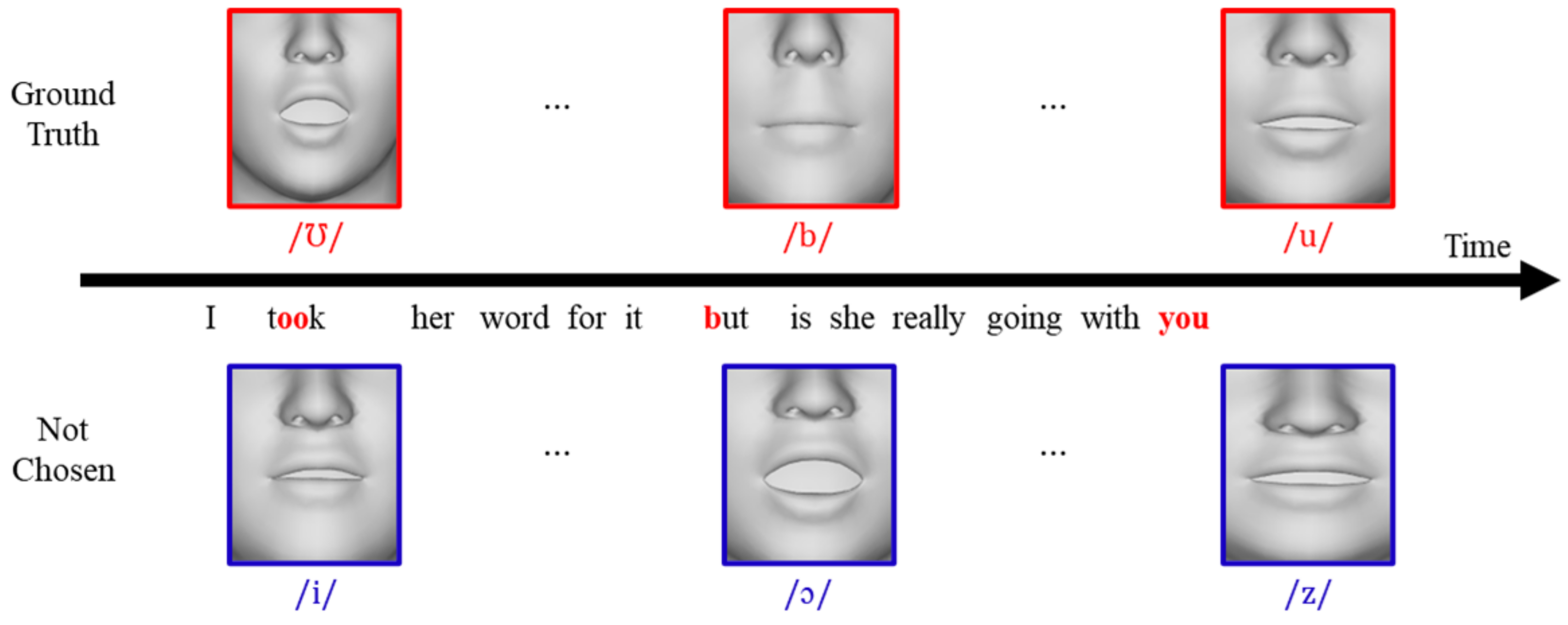
Moreover, during Experiment III, we observed that the participants readily discerned discrepancies between the voice and mouth shapes when significant variations in vowel and plosive articulation were present. For example, as illustrated in Figure 10, instances where completely different mouth shapes appeared in positions where specific mouth shapes should be distinctly represented, such as ‘took’, ‘but’, and ‘you’, led participants to not select the corresponding facial animation.

Figure 10.
Instances of unselected lip movements where participants identified discrepancies when a different mouth shape was applied to a region intended for a clear representation of the mouth shape.
5.4. Experiment IV: Head Motion
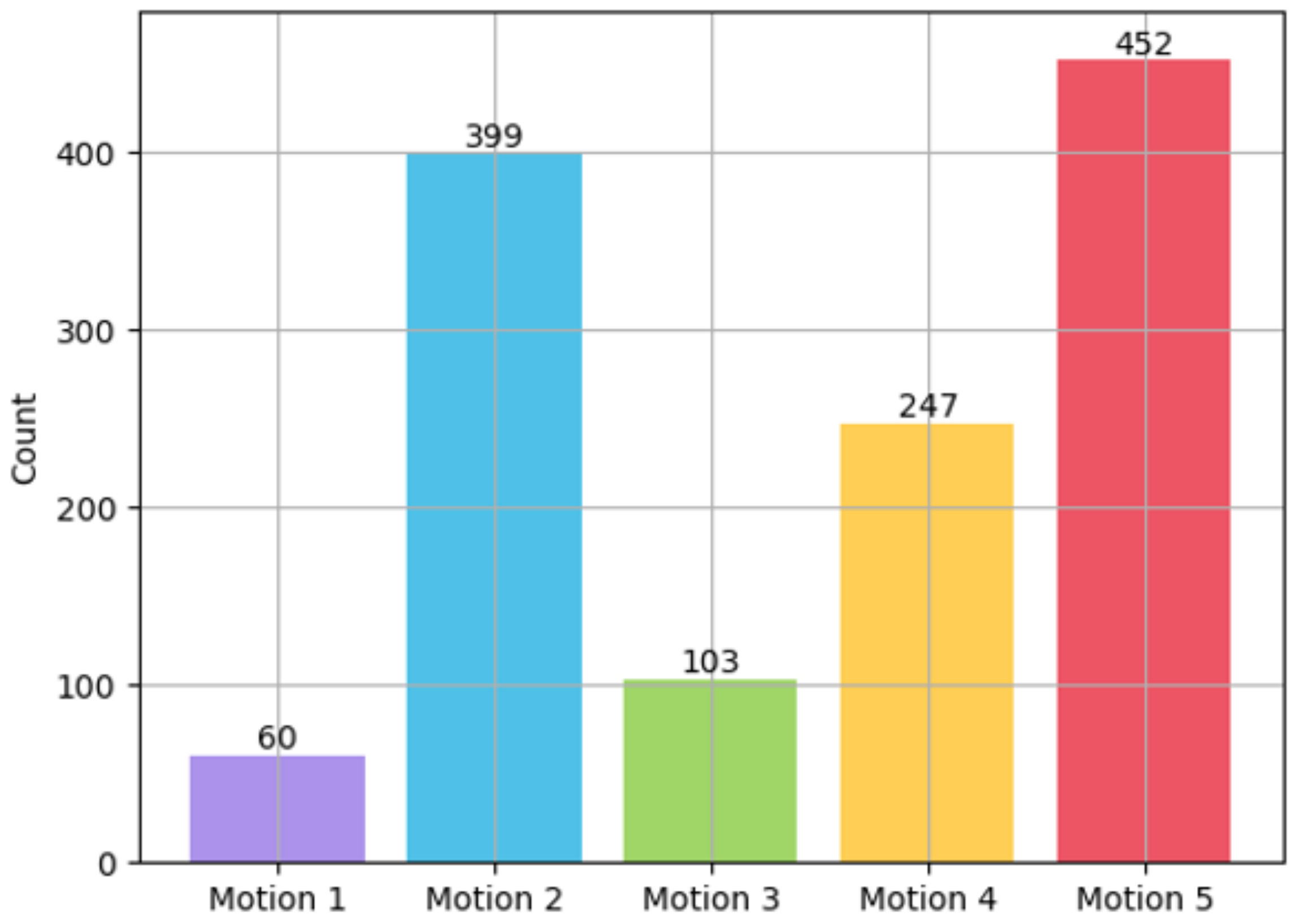
The results of Experiment IV are presented in Figure 11, showcasing the outcomes for each head motion in the sequence of Motions 1 through 5, as outlined in Table 1. The maximum number of selections for each option remains at 480, which is consistent with Experiment III, and the number of selections for each head motion is indicated above each bar graph. As depicted in Figure 11, the participants showed sensitivity to head motion in the order of yaw, roll, and pitch. During the experiment, we observed that participants exhibited heightened sensitivity to yaw-axis motion when evaluating head motion in emotional virtual characters. The yaw axis governs the rotation of the head from side to side. It was observed that when the rotation stopped on the yaw axis, the character’s gaze remained fixed in one place, leading to an awkward appearance. This underscores the importance of fluid head motion in preserving the naturalness of virtual character animations.
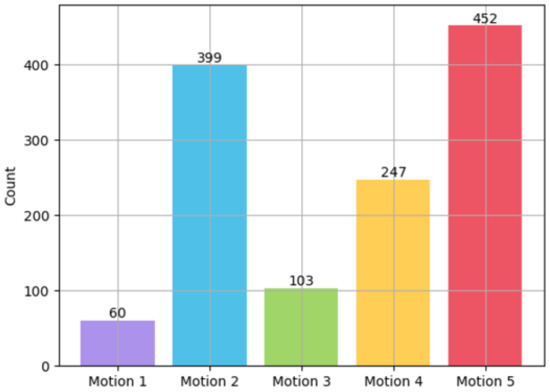
Figure 11.
Distribution of data obtained in Experiment IV according to head motion.
Contrary to our expectations before the experiment, we discovered that head motion is also influenced by the type of emotion being conveyed. For emotions characterized by high arousal, facial animations with reduced motion were perceived as unnatural. However, for low arousal emotions, facial animations with no head motion were deemed acceptable, as they featured less overall movement. For example, Motion 1 was selected when the emotion was Sadness. This implies that when the emotion has low arousal, such as Sadness, the absence of head motion is not perceived as awkward. Additionally, Motion 5 was occasionally not chosen. This result suggests that excessive head movement can lead to reduced naturalness.
5.5. Experiment V: Appearance
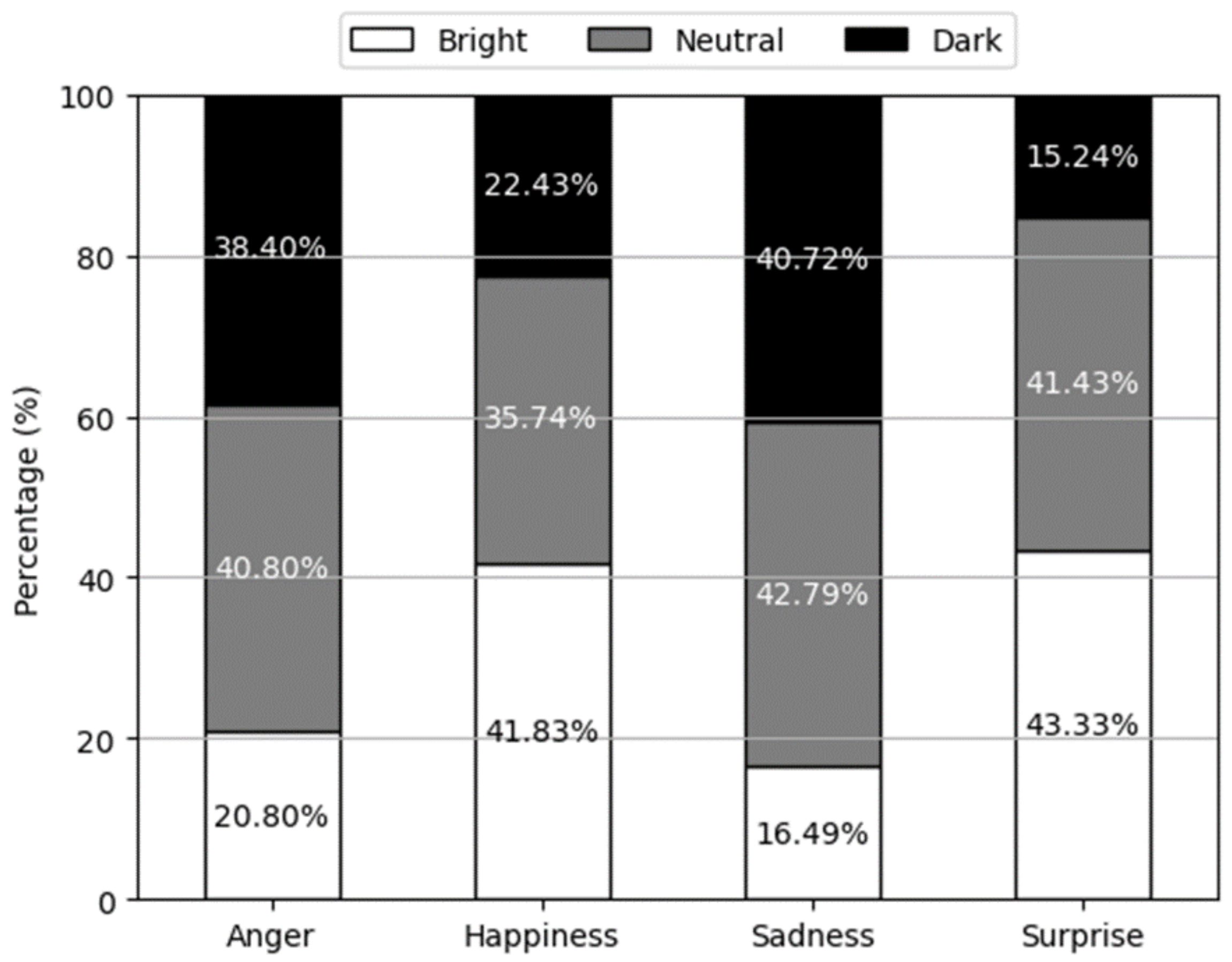
The findings from Experiment V highlight that appearance can influence the emotional expression of 3D virtual characters, even if it is not considered a critical factor. Figure 12 showcases a 100% stacked bar chart depicting the percentage of appearance selections for each emotion based on the emotions chosen by participants in Experiment I. From the results of the figure, one can see that the emotional mood conveyed by a person can be effectively assessed based on the brightness of their appearance. For emotions such as Happiness and Surprise, which demonstrate relatively high valence, the bright option was frequently chosen. On the other hand, for emotions such as Anger and Sadness, which have a relatively low valence, the dark option was often preferred.
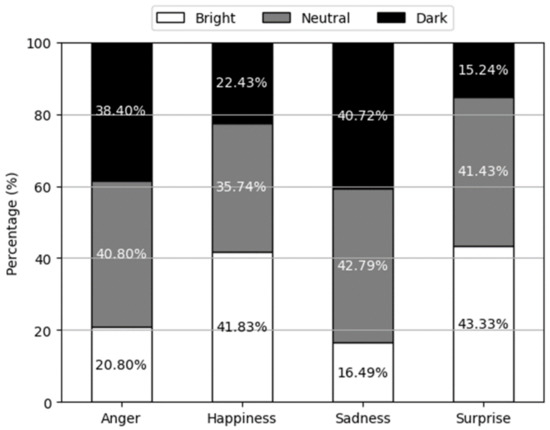
Figure 12.
Results of Experiment V according to the type of emotion and appearance.
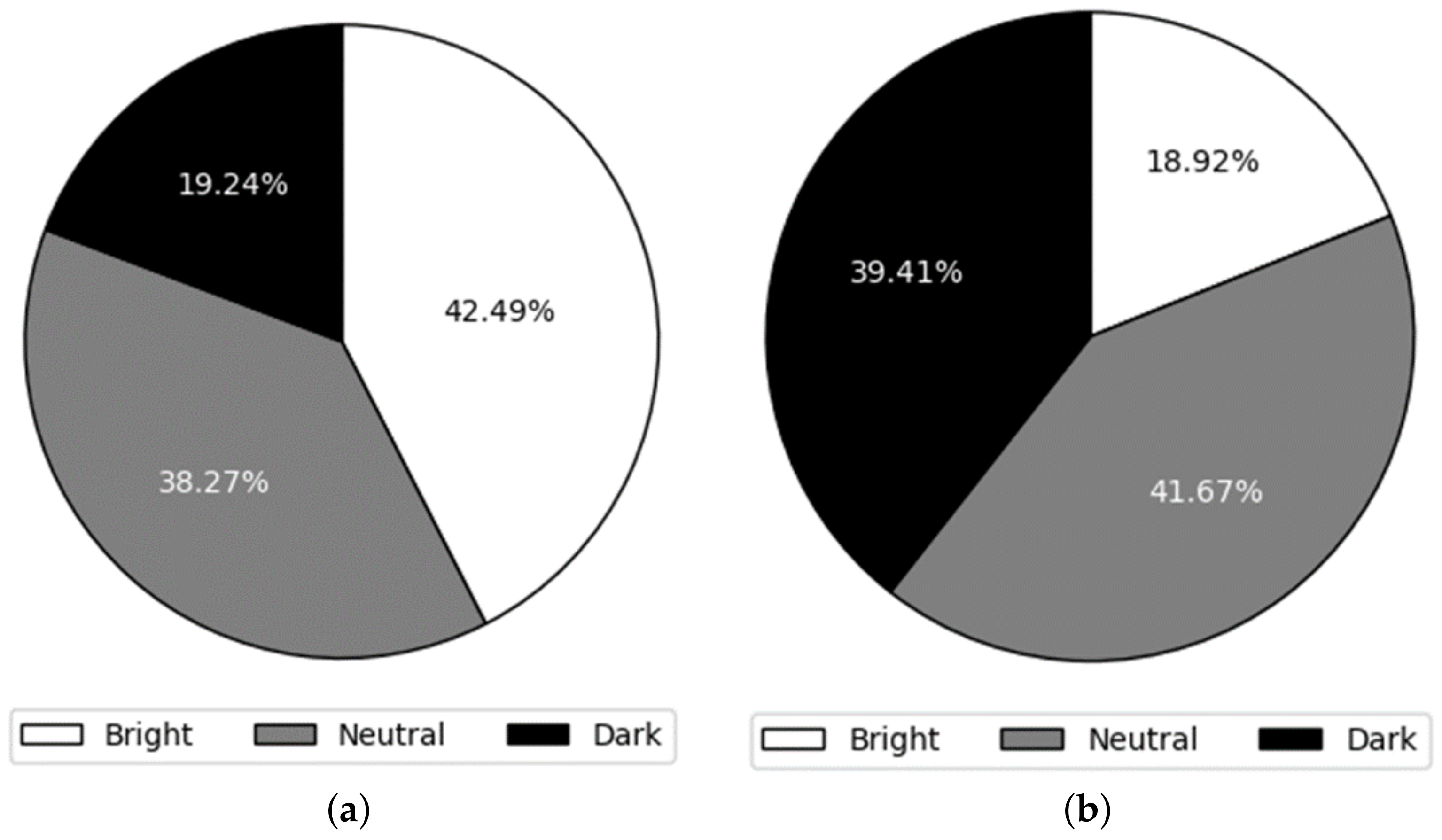
Certainly, the specific values are detailed in Figure 13. In Figure 13a, the selection ratios of bright, neutral, and dark appearances for high valence are presented. Remarkably, the ratio of bright selections is 2.2 times higher than that of the dark selections. Conversely, for low valence, the ratio of dark selections is more than twice that of the bright selections. These results emphasize the potential impact of the 3D virtual character’s appearance on their emotional expression. Additionally, these findings reveal a compelling connection between the appropriate level of brightness in appearance and the emotional valence being expressed. Specifically, participants consistently preferred a brighter appearance for emotions characterized by high valence, while they gravitated towards a darker appearance for emotions associated with low valence.
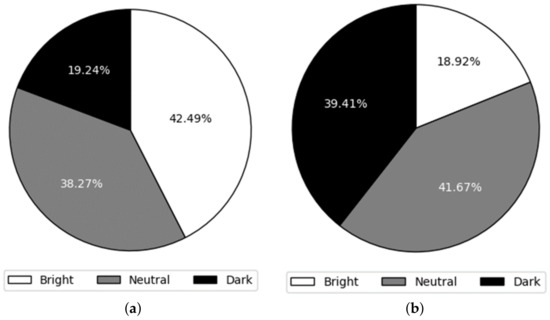
Figure 13.
Results of Experiment V according to the level of valence. (a) The sum of results of Happiness and Surprise that have high valence. (b) The sum of the results of Anger and Sadness that have low valence.
5.6. Experiment VI: Naturalness Score
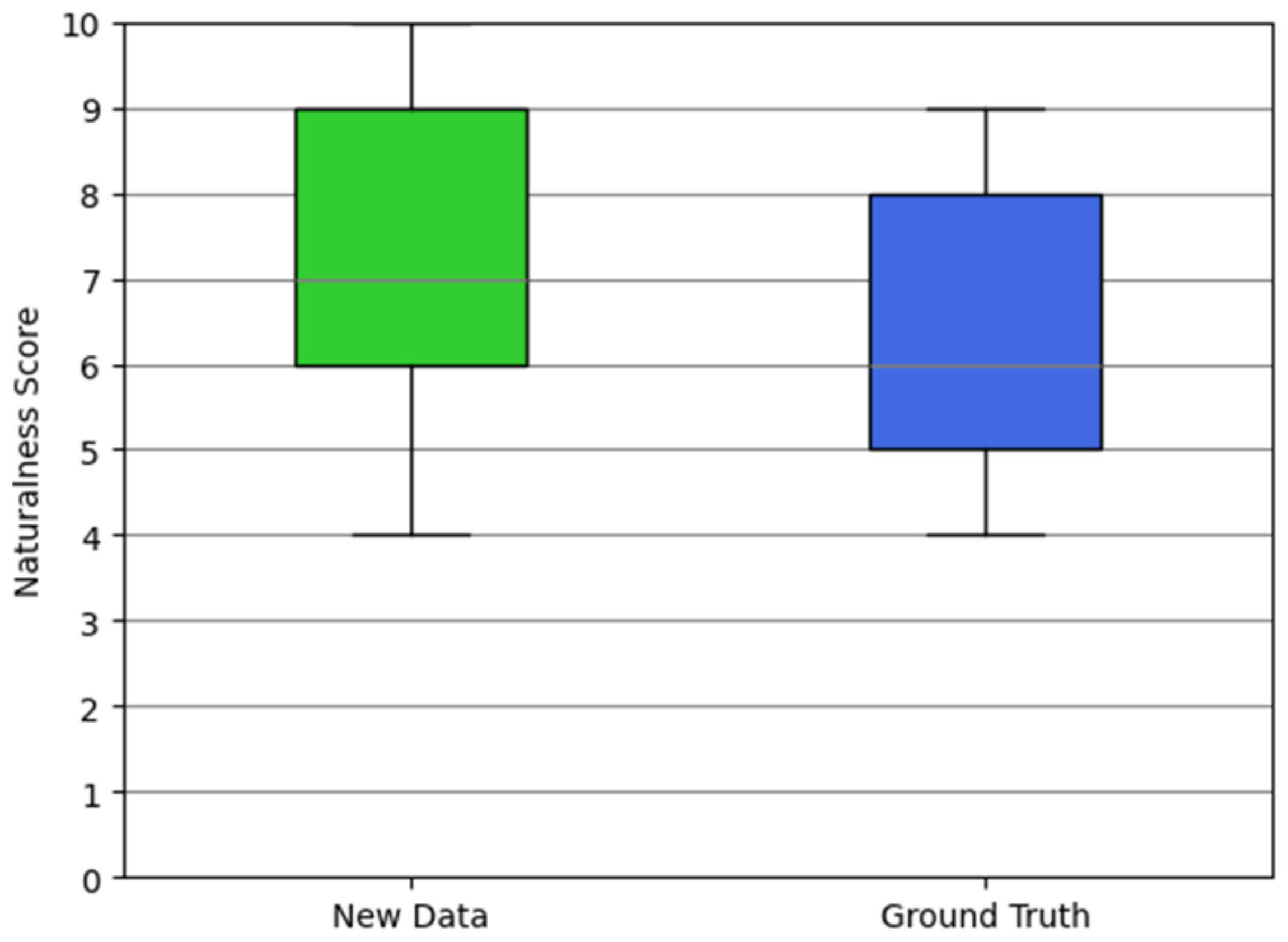
We conducted an analysis of the naturalness scores for the synthesized facial animations compared to the ground truth. The results of the naturalness evaluation are depicted in Figure 14. This analysis was carried out on a subset of 279 data points, where the emotion selected by the participants in Experiment I matched the emotion of the provided voice.
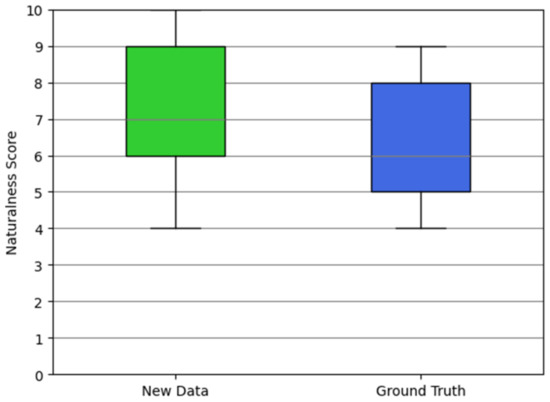
Figure 14.
Results of Experiment VI. The bottom and top of each box represent the first quartile and the third quartile of the sample, respectively.
According to the findings presented in Figure 14, the average score for the new data (i.e., facial animations with the highest score) surpasses that of the ground truth animations. Specifically, for the new data, we observed an average score of 7.641 with a standard deviation of 2.846, while for the ground truth, the average score was 6.648 with a standard deviation of 3.059. In the figure, the minimum is the smallest number among the data points. For the new data and the ground truth animations, the minimum recorded naturalness score was 4. On the other hand, the maximum is the largest number among the data points. For the new data, the maximum recorded naturalness score was 10, whereas for the ground truth animations, it was 9. These results suggest that certain synthesized facial animations exhibit a higher level of emotional expressiveness compared to the facial animations performed by the human speaker. Therefore, our results underscore the importance of considering each of the defined factors when generating 3D virtual characters in virtual environments for effective emotional representation.
6. Discussion
In this study, we conducted a comprehensive investigation into how various facial cues influence emotional 3D facial animation. We created a synthetic database by fitting 3D models using a publicly accessible audio-visual dataset. Subsequently, we synthesized a diverse range of emotional facial animations by manipulating key factors such as head motion and appearance. Specifically, we pinpointed facial expression, mouth shape, head motion, and appearance as crucial facial cues that significantly affect the emotional portrayal of virtual characters. In order to empirically assess the impacts of these cues, we devised and carried out a series of six perceptual experiments. During these experiments, the participants selected the factors that most closely matched the emotions conveyed by the provided voices. Our study culminated in evaluating the naturalness of facial animations based on these selected factors. This comprehensive analysis provided us with insights into the distinct contributions of each facial cue to the emotional depiction of virtual characters.
In Experiment I, we made a noteworthy observation: human emotion cannot be effectively conveyed solely through the voice. The participants faced difficulties in recognizing emotions in audio clips, especially with voices exhibiting high emotional intensity, resulting in an average recognition rate of 69%. Conversely, voices characterized by low emotional intensity yielded an average recognition rate of 47%. It is important to note that the emotion dataset used in this study tends to express emotions in an exaggerated manner, suggesting that the real-world emotion recognition rate is likely to be even lower. This finding emphasizes the significance of emotional representation via 3D virtual characters in 3D virtual spaces, as such representation becomes pivotal for effectively conveying emotions in situations where voice alone falls short.
In Experiment II, we made several notable observations. The participants consistently chose facial expressions based on the emotional arousal and valence associated with each emotion, even when these expressions were not explicitly listed in Table 2. Our findings underscored the following key points regarding the relationship between facial expression and emotion:
- 1.
- Arousal-linked eye size: Emotional arousal levels were discovered to influence the size of the eyes. The participants predominantly favored widened eyes for emotions characterized by high arousal, while they preferred closed eyes for emotions with low arousal. This distinction of eye size emerged as a significant factor in conveying emotional intensity.
- 2.
- Valence-linked mouth tail movement: Emotional valence levels are crucial factors influencing mouth-tail movement in facial expressions. As emotional valence increased, the participants chose expressions with higher mouth tails, whereas lower valence emotions were linked to expressions with lowered mouth tails. The varying movement of mouth tails played a significant role in conveying the emotional valence of the 3D character.
- 3.
- Independence from emotion intensity: Remarkably, the chosen facial expressions for each emotion exhibited significant variation, regardless of the emotion’s intensity. Even when participants categorized emotion intensity, their preferences tended to favor neutral or Level 3 emotional facial expressions. This highlights the necessity of integrating exaggerated facial expressions to proficiently convey emotions through 3D virtual characters, regardless of the emotional intensity being depicted.
In our third and fourth sets of experiments, which concentrated on lip movement and head motion—two facial cues acknowledged for influencing the naturalness of emotional virtual characters—we encountered unexpected results. Our findings challenged conventional wisdom in the following aspects:
- 1.
- Lip motion is insignificant for emotional representation: Unexpectedly, our experiments on lip movement revealed that precise lip synchronization is not significantly important for emotional representation in virtual characters. Even when the positions of vowels and plosives were only approximately correct, it did not substantially influence the naturalness of the virtual character’s portrayal. This counterintuitive result challenges the assumption that precise lip synchronization is a critical factor in conveying emotions through facial animation.
- 2.
- Sensitive to yaw axis in head motion: Remarkably, participants exhibited heightened sensitivity to yaw-axis motion when evaluating head motion in emotional virtual characters. The yaw axis governs the rotation of the head from side to side. It was observed that when the rotation stopped on the yaw axis, the character’s gaze remained fixed in one place, leading to an awkward appearance. This underscores the importance of fluid head motion in preserving the naturalness of virtual character animations.
- 3.
- Emotion-dependent head motion: Contrary to our initial assumption, which posited that head motion primarily depended on the direction of rotation, we discovered that head motion is also influenced by the type of emotion being conveyed. For emotions characterized by high arousal, facial animations with reduced motion were perceived as unnatural. However, for low arousal emotions, facial animations with no head motion were deemed acceptable, as they featured less overall movement. These results underscore the nuanced relationship between head motion and emotional representation.
In Experiment V, we explored the relationship between appearance and emotional perception, revealing an intriguing dimension to emotional representation in virtual characters:
- 1.
- Individuality in appearance: Traditionally, individuals have unique appearances. However, we made a noteworthy discovery: the emotional mood conveyed by a person can be effectively assessed based on the brightness of their appearance rather than relying solely on physical attributes.
- 2.
- Brighter appearance and higher valence: Our findings revealed a compelling connection between the appropriate level of brightness in appearance and the emotional valence being expressed. Specifically, the participants consistently preferred a brighter appearance for emotions characterized by high valence, while they gravitated towards a darker appearance for emotions associated with low valence.
In order to comprehensively evaluate each facial cue, we sought the participants’ assessments of the naturalness of the synthesized facial animations. In our quest for the highest-quality representation for each voice, we noted that many of the synthesized facial animations achieved naturalness scores comparable to those of the ground truth data. Interestingly, certain instances of ground truth data, characterized by excessive facial expressions or head motions compared to the emotional type or intensity, received lower naturalness scores than their synthesized counterparts. Consequently, the average scores of the newly synthesized data surpassed those of the ground truth. This phenomenon highlights an intriguing aspect of our study: the emotions perceived face-to-face differ from those experienced through 3D virtual characters in a virtual space.
7. Conclusions
In this study, we investigated the influence of facial factors on emotional portrayal to enhance natural communication through virtual characters. By leveraging a comprehensive dataset built upon the MEAD dataset, we synthesized and analyzed various facial cues, including facial expressions, lip movements, head motions, and overall appearances. Our objective was to deepen our understanding of how these cues contribute to the emotional realism of virtual characters. Through participant evaluations and selection exercises, we found that facial expressions, head motions, and appearances play critical roles in conveying emotions, often aligning closely with the emotions’ arousal or valence. Additionally, our findings challenged initial assumptions about the necessity of precise lip movement in 3D facial animation, suggesting its impact may be less pronounced than previously thought. We believe our findings will contribute to advancing emotional realism in virtual environments, with implications for enhancing VR/AR technologies and immersive experiences. Moreover, the insights gained from this study can inform the design and development of VR/AR applications in fields such as education, therapy, entertainment, and virtual communication, where realistic emotional expression is crucial for user engagement and interaction. As part of our future research, we plan to extend our study to investigate how cultural backgrounds and gender impact the perception and expression of emotions through virtual characters. Additionally, we intend to develop algorithms for the real-time adaptation of facial cues based on user interaction, enhancing responsiveness and emotional engagement in virtual interactions.
Author Contributions
Conceptualization, H.S. and B.K.; methodology, H.S.; software, H.S.; validation, H.S.; formal analysis, H.S.; investigation, H.S.; resources, H.S.; data curation, H.S.; writing—original draft preparation, H.S.; writing—review and editing, B.K.; visualization, B.K.; supervision, B.K.; project administration, B.K.; funding acquisition, B.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. RS-2022-00165652).
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Scorgie, D.; Feng, Z.; Paes, D.; Parisi, F.; Yiu, T.W.; Lovreglio, R. Virtual reality for safety training: A systematic literature review and meta-analysis. Saf. Sci. 2024, 171, 106372. [Google Scholar] [CrossRef]
- Marougkas, A.; Troussas, C.; Krouska, A.; Sgouropoulou, C. How personalized and effective is immersive virtual reality in education? A systematic literature review for the last decade. Multimed. Tools Appl. 2024, 83, 18185–18233. [Google Scholar] [CrossRef]
- Daling, L.M.; Schlittmeier, S.J. Effects of augmented reality-, virtual reality-, and mixed reality–based training on objective performance measures and subjective evaluations in manual assembly tasks: A scoping review. Hum. Factors 2024, 66, 589–626. [Google Scholar] [CrossRef] [PubMed]
- Aysan, A.F.; Gozgor, G.; Nanaeva, Z. Technological perspectives of Metaverse for financial service providers. Technol. Forecast. Soc. Chang. 2024, 202, 123323. [Google Scholar] [CrossRef]
- Mohamed, A.; Faisal, R. Exploring metaverse-enabled innovation in banking: Leveraging NFTS, blockchain, and smart contracts for transformative business opportunities. Int. J. Data Netw. Sci. 2024, 8, 35–44. [Google Scholar] [CrossRef]
- Wu, P.; Chen, D.; Zhang, R. Topic prevalence and trends of Metaverse in healthcare: A bibliometric analysis. Data Sci. Manag. 2024, 7, 129–143. [Google Scholar] [CrossRef]
- Nguyen, H.S.; Voznak, M. A bibliometric analysis of technology in digital health: Exploring health metaverse and visualizing emerging healthcare management trends. IEEE Access 2024, 12, 23887–23913. [Google Scholar] [CrossRef]
- Kwon, B.; Kim, D.; Kim, J.; Lee, I.; Kim, J.; Oh, H.; Kim, H.; Lee, S. Implementation of human action recognition system using multiple Kinect sensors. In Proceedings of the 16th Pacific-Rim Conference on Multimedia (PCM), Gwangju, Republic of Korea, 16–18 September 2015; pp. 334–343. [Google Scholar]
- Kwon, B.; Kim, J.; Lee, S. An enhanced multi-view human action recognition system for virtual training simulator. In Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Jeju, Republic of Korea, 13–16 December 2016; pp. 1–4. [Google Scholar]
- Kwon, B.; Kim, J.; Lee, K.; Lee, Y.K.; Park, S.; Lee, S. Implementation of a virtual training simulator based on 360° multi-view human action recognition. IEEE Access 2017, 5, 12496–12511. [Google Scholar] [CrossRef]
- Kwon, B.; Huh, J.; Lee, K.; Lee, S. Optimal camera point selection toward the most preferable view of 3-d human pose. IEEE Trans. Syst. Man, Cybern. Syst. 2022, 52, 533–553. [Google Scholar] [CrossRef]
- Ekman, P. Facial expression and emotion. Am. Psychol. 1993, 48, 384–392. [Google Scholar] [CrossRef] [PubMed]
- Jack, R.E.; Garrod, O.G.B.; Yu, H.; Caldara, R.; Schyns, P.G. Facial expressions of emotion are not culturally universal. Proc. Natl. Acad. Sci. USA 2012, 109, 7241–7244. [Google Scholar] [CrossRef] [PubMed]
- De Gelder, B.; Böcker, K.B.E.; Tuomainen, J.; Hensen, M.; Vroomen, J. The combined perception of emotion from voice and face: Early interaction revealed by human electric brain responses. Neurosci. Lett. 1999, 260, 133–136. [Google Scholar] [CrossRef] [PubMed]
- Pourtois, G.; De Gelder, B.; Bol, A.; Crommelinck, M. Perception of facial expressions and voices and of their combination in the human brain. Cortex 2005, 41, 49–59. [Google Scholar] [CrossRef] [PubMed]
- Jamaludin, A.; Chung, J.S.; Zisserman, A. You said that?: Synthesising talking faces from audio. Int. J. Comput. Vis. 2019, 127, 1767–1779. [Google Scholar] [CrossRef]
- Prajwal, K.R.; Mukhopadhyay, R.; Namboodiri, V.P.; Jawahar, C.V. A lip sync expert is all you need for speech to lip generation in the wild. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 484–492. [Google Scholar]
- Zhou, H.; Liu, Y.; Liu, Z.; Luo, P.; Wang, X. Talking face generation by adversarially disentangled audio-visual representation. In Proceedings of the AAAI conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 9299–9306. [Google Scholar]
- Ekman, P.; Friesen, W.V. Facial Action Coding System, 1st ed.; Consulting Psychologists Press: Washington, DC, USA, 1978; pp. 1–42. [Google Scholar]
- Ekman, P.; Friesen, W.V.; Hager, J. Facial Action Coding System, 2nd ed.; Research Nexus: Salt Lake City, UT, USA, 2002; pp. 1–527. [Google Scholar]
- Tolba, R.M.; Al-Arif, T.; El Horbaty, E.S.M. Realistic facial animation review: Based on facial action coding system. Egypt. Comput. Sci. J. 2018, 42, 1–9. [Google Scholar]
- Clark, E.A.; Kessinger, J.N.; Duncan, S.E.; Bell, M.A.; Lahne, J.; Gallagher, D.L.; O’Keefe, S.F. The facial action coding system for characterization of human affective response to consumer product-based stimuli: A systematic review. Front. Psychol. 2020, 11, 920. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.; Wu, Q.; Song, L.; Yang, Z.; Wu, W.; Qian, C.; He, R.; Qiao, Y.; Loy, C.C. MEAD: A large-scale audio-visual dataset for emotional talking-face generation. In Proceedings of the 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 700–717. [Google Scholar]
- Russell, J.A. A circumplex model of affect. J. Personal. Soc. Psychol. 1980, 39, 1161–1178. [Google Scholar] [CrossRef]
- Heaven, D. Expression of doubt. Nature 2020, 578, 502–504. [Google Scholar] [CrossRef]
- Kret, M.E.; Roelofs, K.; Stekelenburg, J.J.; De Gelder, B. Emotional signals from faces, bodies and scenes influence observers’ face expressions, fixations and pupil-size. Front. Hum. Neurosci. 2013, 7, 810. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.L.; Pei, W.; Lin, Y.C.; Granmo, A.; Liu, K.H. Emotion detection based on pupil variation. Healthcare 2023, 11, 322. [Google Scholar] [CrossRef]
- Zhang, J.; Zheng, K.; Mazhar, S.; Fu, X.; Kong, J. Trusted emotion recognition based on multiple signals captured from video. Expert Syst. Appl. 2023, 233, 120948. [Google Scholar] [CrossRef]
- Geetha, A.V.; Mala, T.; Priyanka, D.; Uma, E. Multimodal Emotion Recognition with deep learning: Advancements, challenges, and future directions. Inf. Fusion 2024, 105, 102218. [Google Scholar]
- Zhou, Y.; Han, X.; Shechtman, E.; Echevarria, J.; Kalogerakis, E.; Li, D. MakeItTalk: Speaker-aware talking-head animation. ACM Trans. Graph. 2020, 39, 221. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, L.; Ding, Y.; Fan, C. Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 3661–3670. [Google Scholar]
- Zhou, H.; Sun, Y.; Wu, W.; Loy, C.C.; Wang, X.; Liu, Z. Pose-controllable talking face generation by implicitly modularized audio-visual representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 4176–4186. [Google Scholar]
- Stypułkowski, M.; Vougioukas, K.; He, S.; Zięba, M.; Petridis, S.; Pantic, M. Diffused heads: Diffusion models beat gans on talking-face generation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 4–8 January 2024; pp. 5091–5100. [Google Scholar]
- Wang, S.; Ma, Y.; Ding, Y.; Hu, Z.; Fan, C.; Lv, T.; Zhidong, D.; Yu, X. StyleTalk++: A unified framework for controlling the speaking styles of talking heads. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 64, 4331–4347. [Google Scholar] [CrossRef] [PubMed]
- Cosatto, E.; Graf, H.P. Photo-realistic talking-heads from image samples. IEEE Trans. Multimed. 2000, 2, 152–163. [Google Scholar] [CrossRef]
- Karras, T.; Aila, T.; Laine, S.; Herva, A.; Lehtinen, J. Audio-driven facial animation by joint end-to-end learning of pose and emotion. ACM Trans. Graph. 2017, 36, 1–12. [Google Scholar] [CrossRef]
- Eskimez, S.E.; Zhang, Y.; Duan, Z. Speech driven talking face generation from a single image and an emotion condition. IEEE Trans. Multimed. 2021, 24, 3480–3490. [Google Scholar] [CrossRef]
- Liang, B.; Pan, Y.; Guo, Z.; Zhou, H.; Hong, Z.; Han, X.; Han, J.; Liu, J.; Ding, E.; Wang, J. Expressive talking head generation with granular audio-visual control. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 3387–3396. [Google Scholar]
- Lu, X.; Lu, Z.; Wang, Y.; Xiao, J. Landmark Guided 4D Facial Expression Generation. In Proceedings of the SIGGRAPH Asia 2023 Posters, Sydney, Australia, 12–15 December 2023; pp. 1–2. [Google Scholar]
- Sun, Z.; Xuan, Y.; Liu, F.; Xiang, Y. FG-EmoTalk: Talking head video generation with fine-grained controllable facial expressions. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; pp. 5043–5051. [Google Scholar]
- Tan, S.; Ji, B.; Pan, Y. Style2Talker: High-resolution talking head generation with emotion style and art style. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; pp. 5079–5087. [Google Scholar]
- Liu, C.; Lin, Q.; Zeng, Z.; Pan, Y. EmoFace: Audio-driven emotional 3D face animation. In Proceedings of the IEEE Conference Virtual Reality and 3D User Interfaces (VR), Orlando, FL, USA, 16–21 March 2024; pp. 387–397. [Google Scholar]
- Liu, Y.J.; Wang, B.; Gao, L.; Zhao, J.; Yi, R.; Yu, M.; Pan, Z.; Gu, X. 4D facial analysis: A survey of datasets, algorithms and applications. Comput. Graph. 2023, 115, 423–445. [Google Scholar] [CrossRef]
- Feng, Y.; Feng, H.; Black, M.J.; Bolkart, T. Learning an animatable detailed 3D face model from in-the-wild images. ACM Trans. Graph. 2021, 40, 88. [Google Scholar] [CrossRef]
- Li, T.; Bolkart, T.; Black, M.J.; Li, H.; Romero, J. Learning a model of facial shape and expression from 4D scans. ACM Trans. Graph 2017, 36, 194. [Google Scholar] [CrossRef]
- Jenamani, R.K.; Stabile, D.; Liu, Z.; Anwar, A.; Dimitropoulou, K.; Bhattacharjee, T. Feel the bite: Robot-assisted inside-mouth bite transfer using robust mouth perception and physical interaction-aware control. In Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction, Boulder, CO, USA, 11–15 March 2024; pp. 313–322. [Google Scholar]
- Rai, A.; Gupta, H.; Pandey, A.; Carrasco, F.V.; Takagi, S.J.; Aubel, A.; De la Torre, F. Towards realistic generative 3D face models. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 4–8 January 2024; pp. 3738–3748. [Google Scholar]
- Ma, H.; Zhang, T.; Sun, S.; Yan, X.; Han, K.; Xie, X. CVTHead: One-shot controllable head avatar with vertex-feature transformer. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 4–8 January 2024; pp. 6131–6141. [Google Scholar]
- Kim, S.B.; Lee, H.; Hong, D.H.; Nam, S.K.; Ju, J.H.; Oh, T.H. LaughTalk: Expressive 3D talking head generation with laughter. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 4–8 January 2024; pp. 6404–6413. [Google Scholar]
- Likert, R. A technique for the measurement of attitudes. Arch. Psychol. 1932, 22, 44–60. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).