1. Introduction
In today’s digital era, vast quantities of semi-structured and unstructured textual data are continuously generated on the internet. Amidst this deluge of information, it is imperative to extract the core and critical details and organize them into a suitable data structure. Google introduced the groundbreaking concept of the knowledge graph in 2012 [
1], which has revolutionized the way we perceive and utilize data. Currently, entity relation extraction technology stands as one of the pivotal techniques for constructing extensive knowledge graphs. This technology adeptly transforms unstructured textual information into structured relational triplets. This is achieved through the intricate feature modeling of the text, bridging the gap between raw data and meaningful insights.
The purpose of entity relation extraction technology is to extract subjects, objects, and the relationships between them from text, thereby forming relational triplets. Early entity relation extraction models primarily utilized a pipeline approach [
2,
3] for extracting subjects, objects, and their relationships. This approach divides entity relation extraction into two separate tasks: entity recognition and relation classification. However, this method is prone to error propagation, which can negatively impact the performance of the model. To address this issue, subsequent research has adopted a joint extraction approach [
4,
5] for relation extraction. This method extracts complete relational triplet information through semantic feature modeling. Therefore, this method heavily relies on the performance of the semantic feature extraction model. Early feature modeling methods based on machine learning were unable to meet the requirements of entity relation extraction tasks. Subsequent research has significantly improved model performance by leveraging deep neural networks [
6,
7] to extract relational triplets.
Despite the remarkable progress achieved using entity relation extraction methods based on joint extraction, current mainstream models still face challenges such as the issue of multiple triplets and overlapping, which hinder further improvements in model performance.
Figure 1 illustrates the issue of overlapping in entity relation extraction tasks, as proposed by scholars such as Miwa and Bansal [
8] and Zeng et al. [
9]. The entity pair overlap (EPO) issue refers to the presence of multiple implicit relationships between a subject and an object. Single entity overlap (SEO), on the other hand, refers to a situation where a subject has relational information with multiple objects. Traditional methods for joint extraction methods have difficulty addressing the overlapping issues effectively. Related models suggest using the Seq2Seq framework to generate all relational triplets to address the issue of overlapping [
8,
9]. In subsequent research, Fu et al. [
10] proposed utilizing the graph data structure to construct a graph convolutional neural network to address the issue of overlapping. Wei and Su et al. [
11] proposed the CasRel framework, which divides the entity relation extraction task into subject identification and object-relation identification tasks. This approach enables the matching of a single subject with multiple objects, thereby addressing the issue of overlapping. Currently, the CasRel framework has been widely applied to entity relation extraction tasks and has achieved significant progress.
While the aforementioned methods have addressed the overlapping issue to a certain extent, most of the existing models overlook the dependency relationships that exist between subject information, objects, and subject–object pairs. In addition, mainstream models often focus solely on extracting semantic features or optimizing extraction methods, neglecting the impact of positional features in the text on entity relation extraction. Therefore, this paper proposes a method for entity relation extraction based on subject position complex exponential embedding, named SPECE (subject position encoder in complex embedding for relation extraction). Firstly, this paper utilizes the BERT pre-trained model and residual dilated convolutional neural network to extract semantic features. Then, a complex exponential embedding approach is proposed to combine the positional encoding features with textual features. Compared to previous models, our proposed model incorporates subject information into the entity relation extraction task. Furthermore, our model proposes to incorporate the positional information of the subject and introduces a novel embedding approach to achieve feature fusion.
The main contributions of this paper are as follows:
(1) Designing an encoding layer based on BERT and DGCNN to extract semantic features, alleviating the issue of long-distance dependencies in the model and enhancing its performance when dealing with long texts.
(2) Designing a subject position-based encoding method and propose a complex exponential embedding technique to achieve the fusion of subject features with textual semantic features.
(3) Compared to other baseline models, our proposed SPECE model demonstrates significant improvements in the F1 score on both datasets. Additionally, we conducted ablation experiments to verify the effectiveness of the subject position encoding and complex exponential embedding techniques.
This article is divided into six chapters.
Section 1 is an introduction to relationship extraction.
Section 2 is related work, introducing recent issues and methods related to triplet extraction.
Section 3 introduces the various parts of the model.
Section 4 presents the completed relevant experiments and their results.
Section 5 is an analysis of the experimental results.
Section 6 is a conclusion and outlook on this method.
2. Related Works
Early models used a pipeline approach to divide the task of entity relationship extraction into two parts: entity recognition and relationship classification. However, this method suffers from error propagation, which limits the performance improvement of the model. To solve this problem, scholars have proposed a joint extraction approach that utilizes an encoding layer to capture semantic feature information and designs a decoding layer to obtain complete relation triplets. Zheng et al. [
12] designed the NovelTagging annotation structure and employed a joint extraction method to achieve relation extraction. The NovelTagging annotation structure is inspired by the commonly used BIEOS (begin, inside, end, other, single) tagging approach in the named entity recognition tasks. Additionally, they introduced the use of “1” and “0” labels to distinguish between the subject and object entities within a relation triplet. This method transforms the complex task of entity-relation extraction into a relatively simpler task of label classification.
As the joint extraction method requires the direct prediction of complete relation triplet information, models that employ this approach heavily rely on extracting semantic features. In recent years, scholars have widely adopted large-scale semantic models, such as ELMo (embeddings from language models) and BERT (bidirectional encoder representations from transformers), to extract semantic features. These models enable the accurate capture of meaningful information from text data, significantly enhancing the performance of various natural language processing tasks, such as entity and relation extraction. Scholars such as Huang et al. [
13] have introduced the BERT pre-trained model as an encoding layer to capture semantic information from sentences. They utilize a pipeline approach to achieve relation extraction. Wadden et al. [
14] utilized the BERT pre-trained model as the encoding layer for the entity-relation extraction task. They dynamically generated entity-relation graphs based on textual features and introduced graph convolutional networks (GCNs) to achieve relation extraction.
Despite the significant performance improvements achieved by the entity-relation extraction models based on language models, most of these models overlook the issues of multiple triplet extraction and overlapping. Certain end-to-end entity-relation extraction models exhibit poor performance when predicting multiple triplets. Consequently, the problem of overlapping significantly hinders the optimization of model performance. Therefore, Zeng et al. [
15] employed a Seq2Seq model and introduced a copy mechanism to predict the subject, relation, and object information in sequence. Fu et al. [
10] propose the utilization of a graphical data structure to record entity information and employ graph convolutional neural networks to achieve entity-relation extraction. Ye et al. [
16] proposed a generative approach based on the transformer [
17] architecture for predicting relational triplets. To address the challenge of predicting multiple triplets using end-to-end models, Wei and Su [
11] propose the CasRel framework. The CasRel framework transforms the task of entity-relation extraction into subject recognition, object identification, and relation identification. This approach allows for matching relationships between a single subject and multiple objects, enabling the extraction of multiple triplets. In addition, Li et al. [
18] proposed a parallel relation extraction framework named LAPREL, which integrates label information into the sentence-embedding process through a label-aware mechanism. Furthermore, an entity recognition module is implemented to refine the fuzzy boundary relation extraction, resulting in a more accurate extraction of relational triples. Also, Liao et al. [
19] proposed SCDM based on the span and a cascaded dual decoding. Lai et al. [
20] proposed a joint entity and relation extraction model called RMAN. Two multi-head attention layers are applied to incorporate additional semantic information and enhance the effectiveness. Both the SCDN and RMAN models have demonstrated the significance of semantic features in addressing the issue of triplet overlapping.
Indeed, the models mentioned above primarily focus on extracting semantic features from the text to enhance their performance in entity-relation extraction tasks. However, they tend to overlook the significance of subject features and positional information in this process. In this paper, we propose a subject position complex exponential embedding-based entity-relation extraction model (SPECE). This model utilizes BERT and DGCNN as its encoding layers. The decoding end consists of a subject recognition module, a position encoding embedding module, and an object and relation recognition module. In the following sections, we will delve into the details of these modules.
3. Model
This chapter will provide a detailed introduction to the various modules and structural characteristics of the SPECE model.
Figure 2 shows the complete structure of our model. The goal of the entity relationship extraction task is to extract the relationship of the triplets contained in unstructured text
, in which
s represents subject,
r represents relation, and
o represents object. Firstly, we transform the input text into semantic feature information
through an encoding layer. Then, based on semantic features
, the model designs a subject recognition module to predict the starting position
information of the subject. In addition, encoding the input text based on the subject’s location information to obtain the subject’s location code
. Then, we use the embedding layer to extract positional feature information
. Our model proposes a complex exponential embedding method to obtain deeper level feature information
. Finally, we design an object and relationship recognition model to identify the starting position
, ending positions
of the object, and the corresponding relationship information
r.
3.1. Encoder
3.1.1. BERT
Our model uses word segmentation and embedding layers provided by BERT [
21] to map input text into vectors and obtains its semantic feature information through a multi-layer transformer model
.
3.1.2. DGCNN
At present, natural language processing models typically utilize temporal networks to extract semantic features from text. However, temporal networks face challenges such as gradient dispersion and gradient explosion. In response to this issue, scholars such as Zeng et al. [
6] proposed a convolutional neural network based on position embedding to extract relation triplets. It is worth noting that our model uses dilated convolutions instead of traditional convolutions. This network expands the receptive field of the convolution kernel by inserting several untrained zeros between them, thereby achieving the perception of a larger range of input information. In addition, considering the information transmission problem of deep neural networks, we propose a dilated convolutional neural network based on a residual threshold mechanism. The overall network structure diagram is shown in
Figure 3.
The DGCNN calculation formula is as follows:
where
, and
are the dimensions of the input feature. Inspired by Dauphin et al. [
22], the DGCNN model uses a threshold mechanism to control the degree of feature retention and forgetting.
Firstly, the DGCNN model introduces a dilated graph convolutional neural network to capture long-distance text feature information and incorporates another dilated graph convolutional neural network to extract crucial features. The threshold features are used to control the retention degree of the first dilated graph convolutional output features and the forgetting degree of the input features. The convolutional kernel parameters of the two components of the dilated convolution in the DGCNN model share the same weight and bias vector , where d is the input feature dimension , and k is the convolutional kernel size. Then, we use Sigmoid function as the nonlinear activation function of the threshold feature , as the memory coefficient of the dilated convolutional feature . In addition, the forgetting coefficient of the dilated convolution is regarded as the memory coefficient of the input feature . Finally, the DGCNN model multiplies and adds the two parts of the features with their respective memory coefficients to obtain the semantic feature as the output of the DGCNN model.
The DGCNN network utilizes dilated convolutions to extract temporal feature information from distant input text. This approach not only addresses the problem of distant dependencies in temporal models but also surpasses the limitations of standard convolutional networks. These networks are limited by the size of convolution kernels and struggle to capture distant textual feature information. On the other hand, the DGCNN model introduces a residual threshold mechanism to enhance model performance by regulating the information flow within the model. The residual mechanism allows each piece of feature information to flow to the downstream network, enhancing the model’s convergence ability and reducing overfitting.
3.2. Decoder
3.2.1. Subject Tagger
This article uses the CasRel [
11] framework as the decoding end of the model. This framework uses a “1” to mark the start and end positions of the subject and similarly uses a “0” to mark other positions in the input text. Based on this annotation structure and the output feature
of the encoding layer, we construct a binary classifier to predict the probability of each input character becoming the start or end position of the subject. The specific operation is as follows:
where
and
represent the probabilities of the
position becoming the start and end positions of the subject. During training, the model uses the following maximum likelihood function to calculate the loss value for the subject recognition task.
where
L is the length of the input text sequence,
and
are the label values at the
position, and
is the predicted value at that position.
represents a value of 1 when
z is a positive sample, and 0 otherwise. The semi-joint extraction method uses the maximum likelihood function shown in Equation (
7) to calculate the loss value and optimize it.
3.2.2. Subject Position Encoder
Considering the relevant information that exists between the subject features and the text features, our model suggests incorporating subject features into the entity relationship extraction task. The mainstream models tend to extract the semantic features of the subject by constructing a semantic feature network while ignoring the spatial information of the subject. Dufter et al. [
23] believe that without position information, the meaning of a sentence is not well defined. Ke et al. [
24] believe that the information conveyed by a character is closely correlated with its position within the text. They suggest that extracting the correlation information between characters through position embedding and other methods can enhance the model’s feature extraction capability. Raffel et al. [
25] believe that the positional relationship between characters also affects the expression of semantic features of characters, and that extracting relative position information can capture the correlation information between texts.
Based on the theoretical analysis of the location features mentioned above, this paper proposes a model for entity relationship extraction that relies on the location features of the subject. It utilizes the complex exponential embedding method to fuse location features and text semantic features. First, we obtain the location information and of the subject through the subject recognition module. Then, we perform location encoding on the input text by considering the absolute distance between the sentence text and the subject text. Specifically, the characters located before the subject text will be marked with the distance between the current character and the first character of the subject as the location encoder, while the characters located after the subject text will be marked with the distance between the current character and the last character of the subject as the location encoder. It is worth noting that this annotation structure marks all the location encoders of the subject text as 0. However, it is difficult to directly apply location encoding to entity relationship extraction models. On the one hand, location encoding is influenced by the text length, which can result in a large encoded value. The direct utilization of this value may cause gradient explosion. On the other hand, location encoding features are only one-dimensional, making it challenging to capture rich semantic features. Therefore, our model introduces an embedding layer to map integer location encoding to multidimensional feature vectors. The embedding layer introduces a trainable matrix, enabling the model to iteratively optimize the relevant parameter information of the embedding layer. This allows for a more accurate fitting of the location feature information.
3.2.3. Complex Embedding
The position-encoded features generated based on trainable matrices can effectively extract spatial information from text. However, this method can only optimize the parameters of a single spatial feature during the training process and cannot learn the correlation information between position-encoded features. In addition, common feature fusion methods do not consider the correlation information between the semantic features and spatial features. Inspired by Wang et al. [
26], our model proposes a feature embedding method based on complex exponentials. Firstly, to extract the relative position information of the spatial encoding features, the method utilizes Equation (
8) as the mapping function for the position-encoded features, which adheres to the equality relations specified in Equations (9) and (10).
According to Equations (9) and (10), in the complex exponential-based position encoding feature embedding method, based on the characteristics of complex exponential operations, the position encoding feature of the
bit can be obtained by the linear mapping of the
bit through operator
. The value of operator
is determined by the relative positional
k among texts, so this embedding method can reflect the relative position feature information between position encoders. Our model expands the mapping function in Equation (
8) to obtain Equation (
11).
As shown in Equation (
11), the mapping function based on complex exponential includes three parameters that can be optimized: amplitude
A, initial phase
, and period
. In order to enhance the performance of the model, we use trainable parameters to fit the three feature parameters. This enables the model to extract more accurate parameter information during iterative training. Our model utilizes encoding layer features and position encoding features. It introduces a linear layer to incorporate amplitude feature information
A, utilizes word segmentation information of the input text
, introduces an embedding layer to incorporate period parameter information
, and utilizes position encoding information
to introduce an additional embedding layer for initial phase parameter information
. Finally, the position encoding features are combined with the text semantic features to obtain the output features of the position encoding feature embedding method
, as shown in Equations (12)–(14).
The position encoding embedding technique based on complex exponential not only utilizes the characteristics of exponential operations to extract relative spatial feature information about positions but also addresses the limitation of training-based position encoding features that can only be trained independently. In addition, the method introduces trainable parameters based on the characteristics of complex exponential functions. This allows it to optimize parameter information through iterative training, thereby more accurately extracting positional feature information and enhancing the model’s generalization ability.
3.2.4. Relation-Object Tagger
Based on the output feature
of the complex exponential embedding method, our model constructs the same subject recognition module for each predefined relationship to predict whether there is corresponding object information under the relationship. The specific calculation process is as follows:
where
and
represent the probabilities of the
position becoming the start and end positions of the subject when predicting the
relationship. Our model also uses the maximum likelihood function in Equation (
17) to calculate the loss values for the object and relationship prediction tasks. Combining the prediction results of the subject recognition module and the object and relationship recognition module, we use the following loss function to calculate the total loss value:
where
D represents the training dataset,
is the
sentence in the dataset, and
represents the subject
S and relationship
r contained in the
sentence.
5. Discussion
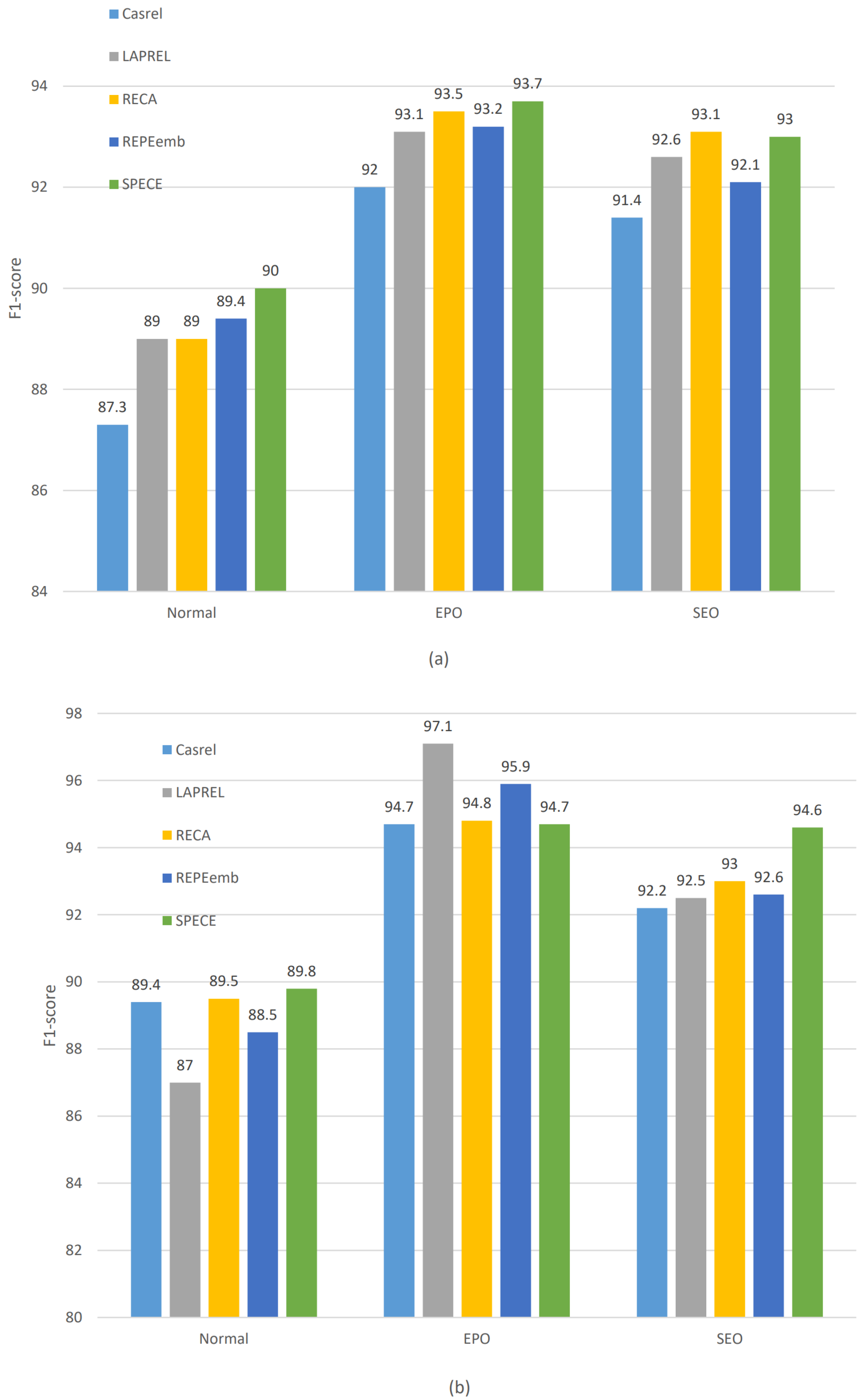
Introducing subject position encoding features and using corresponding embedding algorithms can effectively enhance the model’s performance. On both the NYT dataset and the WebNLG dataset, the F1-score of the SPECE model has shown improvement. In comparison to the SCDM model, the SPECE model increased F1-scores by 0.3% and 0.7% on the respective datasets. The experimental results above indicate that utilizing the location feature information of the subject can significantly enhance the performance of the model compared to models designed with complex structures like RMAN, LAPREL, and SAHT. Our model utilizes complex exponential embedding to fuse positional features with text semantic features. Then, a trainable matrix is introduced into the embedding layer, and the relevant parameters of the embedding layer are obtained through iterative optimization. Due to the positional information of the main features, it can be more accurately fitted. This confirms that our model can achieve better performance in entity relationship extraction tasks.
Meanwhile, in the ablation experiment, we found that incorporating subject position encoding features into the entity relationship extraction model can enhance model performance. The REPEemb model, which introduces subject position encoding features through linear addition, achieved a modest improvement in F1-score on the NYT dataset. However, its performance did not exhibit significant changes in the WebNLG dataset. The experimental results indicate that introducing only spatial feature information is challenging to effectively enhance the model’s capability to extract relationship triplets. The model needs to design a reasonable position embedding method to effectively utilize this feature information. In addition, by comparing the experimental results of the SPECE model and the model, it is demonstrated that introducing trainable parameters for position encoding feature extraction can effectively enhance the generalization ability of the model and the effectiveness of the complex exponential embedding method.
In addition to this, we also experimentally analyze the performance of the model when dealing with entity overlapping sentences as well as multi-relational ternary sentences. For the NYT dataset, the SPECE model performs significantly better than the other models in dealing with regular statements and optimizes its performance in dealing with EPO and SEO problems, and the F1 value also improves in dealing with EPO and SEO problems. For the WebNLG model, the SPECE model performs optimally in processing regular utterances and SEO problems. And in dealing with the multi-triad problem, better performance can be obtained because this method can fit the feature information of the location more accurately. The above experiments show the applicability of our proposed SPECE model in dealing with the entity overlap problem as well as the multi-triad problem.







{kind=link}
{kind=link}
{kind=link}
{kind=link}