3.1. Problem Description
The main task studied in this paper is the problem of online task-free CL. Beginning with the typical scenario of CL classification tasks, many replay-based CL paradigms have shown good performance, which are still followed in this paper. Assuming a set of
n different tasks
, each task’s data distribution is denoted by
, representing the task index. The model observes a data stream that can undergo abrupt changes from
to
, but the model is unaware of the time of the abrupt change in the data distribution. The data seen by the model at a certain time
t from the data stream is represented as
, and in a noisy environment,
is the noisy label. Notably, the representation of samples differs greatly between settings with and without tasks. In both task-free and task-aware settings, the representation of samples differs significantly. In the task-aware setting, the general form of a sample at any given time is represented as
or
, where the task identifier
i is visible to the neural network. This information helps predict the model output. The minimization of the optimization objective can be represented as:
where
L is the corresponding loss function. Due to the adoption of a replay-based approach in this paper, a replay buffer
B is maintained for the model.
and
represent mini-batches from the online data stream, and the replay buffer during fine-tuning is denoted by BB. The loss function integrates values from both the memory buffer and online data streams, forming the basis for learning with noisy labels. This highlights the model’s capacity to assimilate new knowledge while preserving old task information. Replay-based methods naturally excel in retaining previous model knowledge, as demonstrated by this formulation.
CL algorithms in training mode settings can be categorized into class incremental and task incremental [
19], also known as task-agnostic and task-aware learning. The distinction between these lies in the use of task identifiers. In task-aware learning, task identifiers are visible to the model during training and testing, aiding in clarifying task boundaries. During training, only the classifier head corresponding to the updated task identifier is selected, while during testing, only the relevant classifier head is activated for prediction. In contrast, task-agnostic learning requires all classifier heads to participate in training and prediction output. The difference between them is reflected in the structure of the model output layer. In task-based CL [
20,
21,
22], each new task requires an additional output head, extending the model’s output layer to accommodate specific task predictions. In contrast, task-agnostic learning keeps all classifier heads fixed during both training and testing stages [
23]. There is a more illustrative description of the differences between these two settings in
Figure 1.
In [
24], it was explicitly pointed out that noisy labels can lead to retrogressive forgetting consequences [
25]. In the context of CL, the negative impact of noisy labels lies in disrupting the high-quality memory buffer, leading to more severe catastrophic forgetting phenomena [
26,
27], which hinders subsequent task learning. The study [
24] finds that a clean buffer can help improve performance. Conducting CL in a noisy environment is entirely reasonable based on replay-based methods.
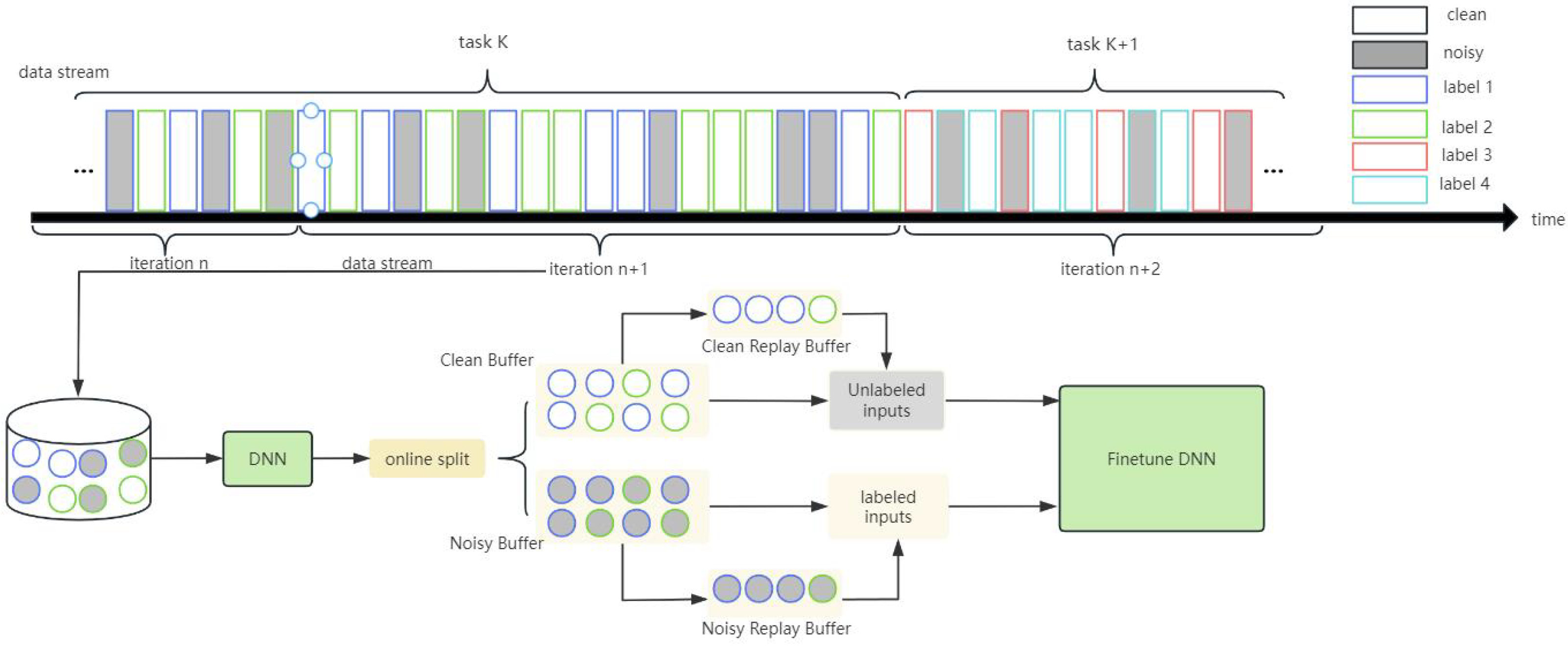
3.3. Online Buffer Separation and Important Example Retaining
The process of dividing the online data stream determines the quality of the labeled data and unlabeled data involved in fine-tuning. Following the paradigm of online CL, a fixed number of samples are taken from the data stream each time, which constitutes an online iteration. The model is represented as . During each iteration, the network engages in supervised learning with a minimal learning rate. Initially, the DNN tends to grasp simple patterns, gradually memorizing noisy labels. Samples with clean labels with minimal losses are prioritized for memorization by the neural network. To differentiate between high-confidence samples and noisy ones, threshold hyperparameters can be configured.
Due to the task-agnostic setting, assuming a total of
c classes need to be learned, it means the model always maintains
c classifier heads, and all classifier heads participate in the prediction output of each sample. The prediction vector of sample
can be represented as
. Correspondingly, the label can be represented as
. This paper computes the distance between them to describe their difference:
Due to the characteristics of class incremental learning,
can contain classes that the model has not yet learned, which is incorrect. It is necessary to filter out the classes that will only appear in the future from
to assist the model in making as accurate judgments as possible in classifying noise. The prediction accuracy might be enhanced by employing a class-specific binary mask. In this approach, the mask distinguishes between previously learned and newly introduced classes. Specifically, it assigns a value of 1 to positions corresponding to both old and current classes, signifying the recognition of these classes, while positions corresponding to yet-to-be-learned classes are set to 0. Solely setting bits related to current task labels to 1 is not exhaustive in capturing the model’s evolving comprehension. Consider a common scenario: the classes contained in task
t may correspond to the labels of previous tasks, and the mask bits corresponding to previous task labels will be set to 0. In our approach, we allow predictions of samples to point to labels contained in previous tasks, avoiding the erroneous auxiliary effect of the mask. The mask bit for class
j of
is represented as
. The formula for calculating the distance of samples with the addition of the corrected mask, which is the mean-squared error loss, is described as follows:
Compare the distances of all samples in each iteration; mark the samples with distances smaller than the threshold as clean-labeled samples; fill the online buffer with clean samples. Therefore, other samples with larger distances are filled into the buffer for noisy samples as follows:
For the threshold in the above formula, this paper uses the average distance of all samples in the batch to identify as follows:
From the online buffer of clean samples, select the smallest samples based on the distance, and add them to the replay buffer of clean samples. Correspondingly, select the largest samples based on the distance, and add them to the replay buffer of noisy samples. and are treated as hyperparameters.
The above content describes the process of online sample partitioning and sample selection. There are limitations to existing methods related to noisy label learning, such as SPR [
6], which advocates learning feature representations on reliable samples. However, in noisy environments, the limited number of clean samples restricts the model from fully learning the feature representations of each class. Subsequent experiments will also demonstrate the necessity of replaying noisy samples.
3.4. Clean Label Learning
Clean-labeled samples are limited. Despite filtering out the most reliable samples from the online data stream, the network may memorize some noise samples due to the memory effect of deep neural networks, leading to inevitable interference. To enhance the generalization ability and robustness of deep neural networks, the learning of labeled samples introduces a modified data augmentation method called MixUp [
27], which generates new examples and labels through linear interpolation. Assume
and
are two data augmentations of an example
, along with their one-hot encoded labels. This results in the MixUp augmentation
. This method of data augmentation effectively introduces prior knowledge [
11] to the network, enhancing its generalization ability, as shown in
Figure 2, and the process is shown in the following formula:
To learn from clean label images, no additional auxiliary learning measures are needed. The augmented samples mentioned above are fed into Net 1, and the corresponding cross-entropy loss referred to as the loss on-labeled samples is computed using the predicted
. As shown in Equation (
9),
N represents the number of input clean-labeled samples,
represents the label of the
ith sample, and
represents the prediction corresponding to the
ith sample by Net 1.
3.5. Noisy Label Learning
This section shows the fine-tuning framework for learning from noisy labels and entails extracting more information from samples with relatively higher proportions of correctly partitioned noisy labels while minimizing the influence of mislabeled data. Drawing inspiration from the supervised contrastive learning framework SCL2 [
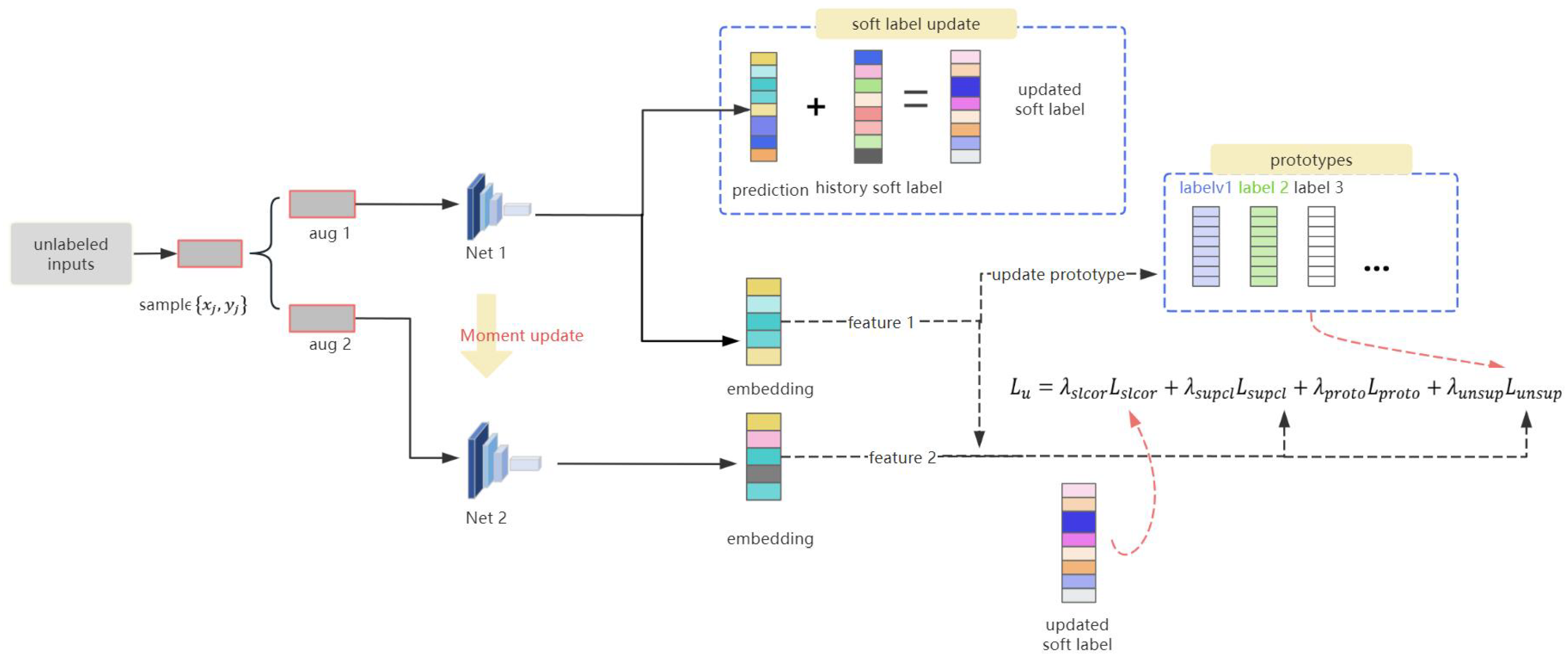
28], we optimized its components and introduced a finite memory buffer for caching historical feature representations. Subsequently, we devised a composite loss for unlabeled samples, which integrates unsupervised contrastive learning loss, supervised contrastive learning loss based on soft labels, supervised prototype contrastive learning loss based on soft labels, and corrected soft label loss.
In handling examples with noisy labels, two networks are utilized, denoted in this paper as Net 1 and Net 2. Both networks maintain identical architectures, and Net 1’s parameters are periodically used to perform momentum updates on Net 2’s weights. These momentum updates maintain approximate parameter equality between the two networks while ensuring that the weights of Net 2 change more slowly than those of Net 1, thus preventing Net 1 from being heavily influenced by noise and maintaining model robustness.
For each data example in the unlabeled sample set U, two different data augmentations are obtained, labeled as and . These augmentations, and , are, respectively, fed into two models with identical network structures, referred to as Net 1 and Net 2. Net 1 will output the low-dimensional feature embedding of , denoted as . In addition to the aforementioned feature embedding, another important output of Net 1 is the prediction regarding the first data augmentation , represented as , which is generated through the fully connected layer of the Net 1. The second data augmentation is input into Net 2, which only needs to output the low-dimensional feature embedding for this augmented sample, represented as .
3.6. Loss Function Analysis
The first component of the loss is called soft-label-corrected loss (
). The research on noisy label correction [
16] proposed the idea of correcting labels using linear interpolation between the original noisy labels and soft labels. The corrected label is represented as
, where
represents the network’s output prediction. If the corrected label is used as the supervision signal, the cross-entropy loss can be expressed as follows:
Equation (
10) represents the recent network predictions introduced as supervision signals. The short-term memory effect of neural networks prevents using original noisy labels as supervision signals, as the network quickly memorizes some noisy labels, leading to performance degradation. As the number of iterations increases, the influence of the original labels on the network should decrease. The supervision signals are updated with iterations to generate more accurate soft targets. Based on the above discussion, naturally, the updating process of the supervision signals is represented as follows:
The epoch is represented by
k. At any
-th moment, historical supervision is incorporated into the current supervision update. The update of supervision is summarized as the exponential moving average of historical supervision. The loss of all epochs is divided into the first epoch (first term) and other epochs (second term) as expressed in the following:
where
represents the model’s prediction for
in the
s-th epoch. Since there are no historical soft labels in the first epoch, the original labels are temporarily used as the supervision. In the first term of the loss, it is weighted by
.
is a real number in the interval
, ensuring that, as the epochs progress, the weight of the original labels in the supervision decreases gradually. The weights of the updated
increase, especially for the recent
. As the iteration progresses, the model’s predictions become more accurate, which are then used to correct the soft labels more accurately.
The second part of the loss is the supervised contrastive learning loss, denoted as
. Given
N sample label pairs
in a mini-batch, we obtain
augmented sample pairs
through feature extraction on two networks. Here,
and
represent two different versions of augmentation for
, and correspondingly,
. Within these
augmented samples, for any index
s representing a sample,
, we denote the index of a sample that shares the same class label as the
s-th sample as
t. These two augmented samples are considered positive. The loss for this part is represented as follows:
where
represents the features of other samples in the same batch as
, but with the same category as
. Soft labels are used as supervised information for sample category discrimination.
denotes the number of enhanced samples in the batch that have the same category as
. Using
I as the indicator function, its value is 1 when the subscript condition is satisfied; otherwise, it is 0. Clearly,
serves as the positive sample for
, and
serves as the negative sample.
is the temperature coefficient. When computing
, it ensures that positive and negative samples are better distinguished, promoting the network to learn information from features and sample labels from the same category.
The third part of the loss concerns global prototype learning. Maintaining a global prototype matrix provides prototype vectors for class centers, assisting the network in discrimination. The objective is to make the low-dimensional feature representations output by the training network closer to the prototypes of their respective classes. In each subsequent epoch, if the update condition is met, the current prototypes are updated with the exponential moving average of historical prototype vectors and low-dimensional features. This enables the prototypes to evolve as more samples are seen by the model, better characterizing the class centers of each class. The loss formula is shown as follows:
where
k represents the class label.
m denotes the coefficient for the exponential moving average. Here, it is necessary to use supervised information to distinguish the class of prototypes, ensuring that the most correct prototypes are selected for updating. To maintain the stability of prototypes in describing class features, prototype updates can only be performed when two conditions are met. The prototype learning loss function is as follows:
In the above loss, represents the soft label and is the temperature coefficient. There are two prerequisites for prototype updates: first, setting a threshold requires that the aforementioned is less than ; second, when the sample soft label is the same as the network prediction, meeting this condition restricts the speed of prototype updates and maintaining the stability of the network.
Finally, the completely unsupervised loss function is denoted as
. As shown in
Figure 3, a small buffer with a queue structure is utilized to store the outputs of Net 2 over a period of time, serving as negative samples. The feature buffer is represented as
M, with a capacity limit of
. The low-dimensional features of recent online samples in Net 2 are stored in the queue as
. As the queue has limited capacity, this part of the loss is expressed as:
where
represents the feature representation obtained from Net 2 and
represents the temperature coefficient in this context.
denotes several historical features in the queue
M.
Figure 4 summarizes the learning process of unlabeled samples. It depicts the dual-model structure and indicates momentum updates. The main components of the loss function and the information contained in the model output within the loss function are also annotated in the figure.
The loss function computed on the complete set of noise-labeled samples is as follows (
represents the weight coefficient for each component):







{kind=link}
{kind=link}
{kind=link}
{kind=link}