1. Introduction
Natural language processing (NLP) is a field that utilizes computational techniques to learn, understand, and generate human language content [
1]. It encompasses various sub-problems such as part-of-speech tagging, named entity recognition, and semantic role labeling [
2]. The primary objective of NLP is to enable computers to comprehend and communicate with humans using a natural language, leading to the development of unified architectures and advanced algorithms for language processing predictions [
3]. Furthermore, NLP has been crucial in extracting features from unstructured text, facilitating the extraction and retrieval of information from such data [
4].
Some of the main domains of NLP include machine translation, text classification (e.g., spam detection), sentiment analysis, speech recognition, and natural language generation [
5]. Also, NLP is often utilized to extract human sentiment or emotions from textual documents [
5] where sentiment is commonly expressed by labeling it into three categories: neutral, positive, and negative [
6]. Sentiment analysis can be conducted at three levels: document level, where the general opinion of the author is determined; sentence level, where sentiment based on a sentence can distinguish between objective and subjective sentences; and feature level, where sentiment is associated with a specific object (revealing what the opinion specifically pertains to) [
6]. Emotion analysis expands the labeling process by seeking specific emotions in the text such as anger, happiness, sadness, etc. Two prominent models of emotion used in digital systems are discrete and dimensional and both can be used for text analysis [
7]. The practical difference between them lies in the fact that the discrete model labels each individual emotion on a single continuous scale from 0.0 to 1.0, while the dimensional model assigns several emotions along different features defined on a scale from 1.0 to 9.0, or 1.0 to 7.0. Commonplace theories of emotion are more thoroughly explained in
Section 3.1.
Sentiment and emotion analysis are useful in many use cases, for example, business purposes, to monitor opinions about a product or company; political purposes, to analyze political speech about various individuals, ideas, or organizations; or scientific purposes, to analyze regional or global sentiment about significant societal events and their aftermath (e.g., the COVID-19 pandemic, earthquakes, tsunami, terrorist attacks, etc.). The ML approach within NLP, in its most basic form, involves training a ML model to label texts [
6]. This approach can be unsupervised or supervised. Some commonly used models include the naive Bayes classifier, support vector machines, logistic regression, decision tree, or k-nearest neighbors (KNN) algorithm. The hybrid model presented here combines these two approaches [
7].
The analysis methodology is typically divided into lexicon-based, ML-based, or hybrid approaches [
7]. In the lexicon-based approach—which is used in this study—texts are labeled by identifying text segments (n-grams) in a pre-collected lexicon with labeled words. An n-gram is a sequence of n words (instead of words, it can be syllables or letters) in the text [
8]. When the parameter
n is equal to 1, it is called a unigram, when
n is equal to 2, it is called a bigram, with
n equal to 3, it is a trigram, and so on. In the conducted experiment, our model exclusively utilized unigrams. However, since the model is n-gram agnostic, any n-gram can be employed, in principle.
The goal of this paper is to present a novel hybrid NLP lexicon-based model for the classification of emotions in unlabeled texts in the Croatian language and validate its usability in real-world scenarios employing a unique text corpus related to a conjugation major natural disasters (the COVID-19 pandemic and earthquakes) that occurred in Croatia in 2020. In its basic form, the model is straightforward, relying on unigrams, input preprocessing, and lexical matching to acquire emotion values. To gather further insights into the relationship between semantics and emotion, the model can employ ML techniques.
The remainder of the paper is structured as follows:
Section 2 explains the motivation for this research.
Section 3 provides an overview of sentiment analysis methods, specifically focusing on emotion models in digital systems, and examines how they are used in specific cases.
Section 4 describes the architecture of the developed hybrid NLP model, which is then applied to a textual dataset of spelling corrections collected before and during the aforementioned natural disasters in Croatia.
Section 5 presents the results of the sentiment analysis experiment, while
Section 6 discusses them.
Section 7 concludes the paper.
2. Motivation
The psychological effects of societal events on local populations are crucial in developing strategies for emotional resilience and recovery. Advanced sentiment analysis techniques can map these dynamics and provide useful information for effective interventions and support mechanisms. The research presented here aims to improve our understanding of sentiment analysis in crisis situations and support policy makers in recovery efforts.
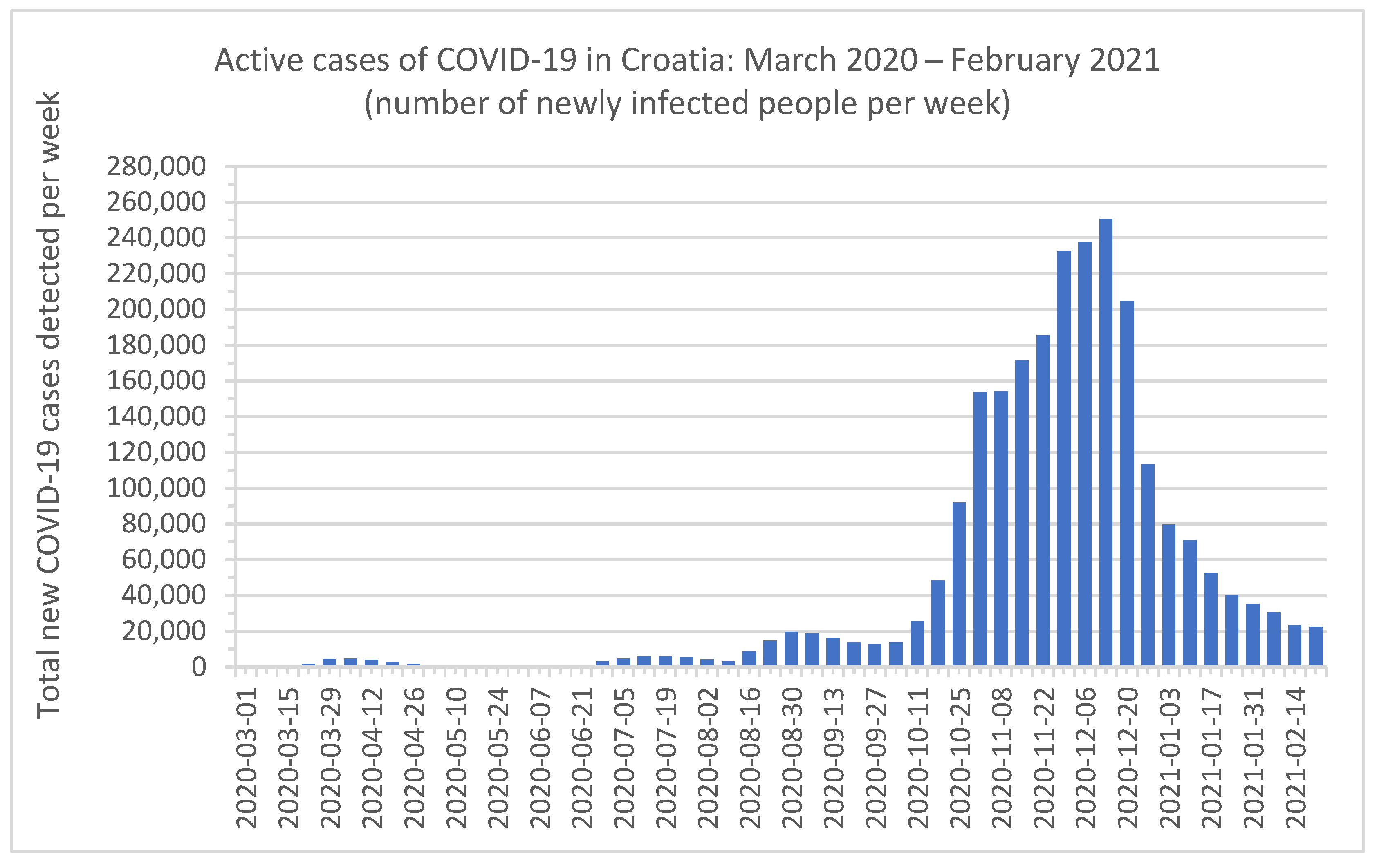
Three major disasters struck Croatia in 2020, events that had not occurred in the previous 140 years [
9,
10,
11]. This period was unique because of its unprecedented concentration and rapid succession of events. First, there was the global coronavirus pandemic, which just in itself posed a formidable challenge to the healthcare infrastructure, economy, education, and society as a whole. As can be seen in
Figure 1, during 2020, the number of active cases per week rose sharply towards the end of the year, surpassing 250,000 active cases (more than 6.5% of the total population), with the healthcare system facing challenges in providing care for all patients, not just those suffering from COVID-19 [
12,
13]. In addition to this, during the COVID-19 pandemic, Croatia was hit with two powerful earthquakes near the most significant, and most densely populated, national urban centers. This series of events marked a special and difficult period for Croatia during 2020, unexpectedly affecting its people and infrastructure for a significant period to come.
On 22 March 2020 at 6:24 local time, during strict lockdown restrictions, the Croatian capital of Zagreb was hit by the strongest earthquake in the last 140 years—measuring 5.5 on the Richter scale [
9]. The epicenter was within the city borders at a depth of only 10 km. The magnitude of the earthquake caused significant damage as more than 1900 buildings were reported to have been damaged to the point of becoming uninhabitable. Unfortunately, there was 1 fatality, and 26 people were reported injured. To bring things into perspective, Zagreb is the largest city of the Republic of Croatia. The population of the Zagreb urban agglomeration is slightly above one million people, which represents more than 1/3 of the total population of Croatia. Given this significant demographic concentration, the earthquake in Zagreb had a profound impact on a large number of people in the region [
14].
Later the same year, another major earthquake struck Croatia. On 29 December 2020, an earthquake of magnitude 6.4 on the Richter scale hit central Croatia, with an epicenter located roughly 3 km west-southwest of city of Petrinja, only some 50 km from the capital Zagreb [
10]. The earthquake caused extensive devastation with damage observed as far as 60 km from the epicenter. The quake was strongly felt in Zagreb as well as the whole densely populated northwestern part of the Croatia and in neighboring Slovenia and Bosnia. The Petrinja earthquake left 8 dead and at least 36 injured, 10 severely, and estimated damage costs of more than EUR 5.5 billion [
15]. Approximately 150,000 people were directly affected by this disaster, causing not only immediate shock and trauma but also significant disruptions in their daily lives.
Figure 2 displays seismic maps with the precise close proximity locations and magnitudes of the Zagreb and Petrinja earthquakes.
Furthermore, many people found their homes severely damaged or completely destroyed, making them uninhabitable. The loss of essential services aggravated their hardships for some time to come, as many areas were left without electricity, running water, and other critical infrastructure and utilities. These challenges required urgent and extensive recovery efforts. All of this aggravated the overall crisis and left some residents in the affected area deeply anxious and bewildered, which was also reflected in stories published in daily newspapers, social media, and other local and national communication channels over a longer time period [
18,
19].
The collective impact of all three disastrous events (COVID-19 pandemic, Zagreb and Petrinja earthquakes) left a major mark on the emotional state and psychological well-being of the local population [
20]. This was reflected in various textual materials, including newspaper articles and social media posts, and could be examined using sentiment analysis techniques. Moreover, sentiment analysis can reveal trends in public mood dynamics, providing insights into how communities adapt and recover from these challenges over time.
3. Related Work in Sentiment Analysis
When investigating sentiment analysis, it is important to understand the basic frameworks and methodologies that have influenced the field. This section examines the various theoretical foundations and practical implementations that define current research in sentiment analysis. First, this section introduces emotion models that can be used in digital systems and explains the multifaceted dynamics between emotion and cognition, especially in the context of human–computer interaction. In addition, this section emphasizes how to incorporate machine learning methods to establish correlations between different emotion models and thus increase the robustness of emotion recognition methods. The application of these theories in different disciplines such as psychology, neuroscience, and artificial intelligence shows how versatile they are and the crucial role they play in the development of computational approaches to understanding human emotional responses.
3.1. Emotion Models
Emotion models, in general as well as in digital systems, are broadly categorized into three major groups: dimensional theories, discrete emotion theories, and cognitive theories of emotion [
21]. Among these, dimensional models are most commonly applied in multimedia stimuli databases for the annotation of pictures, video and sounds utilized for the elicitation of specific emotion states, followed by discrete models such as Paul Ekman’s “Big Six” emotion model [
21,
22]. Cognitive models are mainly used in understanding and predicting the complex interplay between cognitive processes and emotional responses. These models focus on understanding, and emulating in computer systems, how thoughts, beliefs, and perceptions influence emotional reactions to events or stimuli.
Emotion models are widely applied in various fields such as psychology, neuroscience, artificial intelligence, affective computing, and human–computer interaction [
21]. They are central in the investigation of the interplay between cognitive, behavioral, and emotional components. The importance of temporal dynamics is considered in order to understand both the immediate emotional responses and the longer-lasting responses (e.g., moods and feelings) following cognitive processes. Discrete and dimensional emotion models are commonly considered distinct and mutually independent. However, previous studies have shown that it is possible to establish a correlation between data points in both models by employing ML techniques to identify patterns in a multidimensional space that integrates the semantics and emotions of stimulation [
23,
24].
In addition to the process of emotion formation, the emotions models also deal with classification of affective information. The classification of emotions is particularly important for their computer processing. Two main approaches to classification are the discrete approach and the dimensional approach, as mentioned above. If emotions are considered discrete, we describe them with separate concepts (i.e., words) and consider them completely distinct from each other. On the other hand, the dimensional approach to emotions defines them by evaluating them on continuous scales, meaning that by positioning them in a vector space, one can determine the similarity or opposition of emotions.
3.1.1. Discrete Emotions Model
Discrete or categorical theories of emotion claim that dimensional emotion models do not accurately reflect the neural systems underlying emotional responses. Instead, proponents of these theories propose that there are many emotions that are universal across cultures and have an evolutionary and biological basis [
25,
26]. However, which discrete emotions, basic emotions, or emotion norms, as they are also called, are included in these theories and what their mutual relationship is, remains a matter of research [
21].
Ekman proposed a notable model of six fundamental emotions, namely happiness, sadness, fear, disgust, anger, and surprise, associating them with specific facial expressions that are culturally independent [
26]. Ekman distinguishes emotions from other affective states based on nine characteristics: universal signals, presence in other primates, characteristic physiology, universal events that trigger emotions, coherence of emotional response, rapid onset, short duration, automatic determination of stimuli, and unwanted occurrence [
26].
Plutchik proposed a hierarchical model of eight primary emotions: anger, anticipation, disgust, fear, happiness or joy, sadness, surprise, and trust [
27]. He positioned these emotions in a hierarchical concept space called the Wheel of Emotions to illustrate their opposites. As such, Plutchik’s model represents a hybrid emotion model—not exclusively discrete but partially dimensional. Additionally, he defined additional norms derived from the eight basic emotions, also depicted on the so-called Wheel of Emotions hierarchical and circular diagram [
28]. In this framework, the [
28] intensity of emotions is defined by proximity to the center of the Wheel of Emotions, where emotions in the middle are more intense, and those on the edges are less intense.
3.1.2. Dimensional Emotions Model
In parallel with discrete models of emotions, dimensional models have also been developed and have been extensively used in digital systems, especially for annotation of multimedia for emotion stimulation [
22] and estimation of emotions using physiological signals [
29,
30].
As early as 1897, Wundt defined a dimensional model of emotions using three dimensions: pleasure–displeasure, arousal–calmness, tension–relaxation [
31]. Much later, in 1980, Russell popularized the dimensional approach in the so-called circumplex model of emotions, also called the pleasure–arousal–dominance (PAD) model [
21,
32,
33,
34]. This model suggests that affective states arise from combining three affective dimensions: valence (
), arousal (
), and dominance (
). In the most affective multimedia databases, their values range from 1.0 to 9.0 on a Likert scale [
21]:
Positivity and negativity of a stimulus are specified by valence, while arousal describes the intensity or energy level. Dominance represents the controlling and dominant nature of the emotion, or in other words, how much the person experiencing the emotion feels constrained in their behavior; i.e., it describes whether the emotion dominates the individual. According to the circumplex model of affect, all emotions can be represented as a combination of affective dimensions valence, arousal, and dominance within a 3D emotion space, allowing for the analysis of similarity between different emotion states using an appropriate distance metrics [
21]. However, in practice, the dimension dominance is frequently omitted from description of emotion space because it was shown to be the least informative measure of the elicited affect [
35]. Furthermore, some studies indicate the importance of the sense of control in behavior and health analysis, which is a significant factor driving the use of such a model [
35]. Another dimensional model of emotion is the PANA model, with axes for positive affect and negative affect [
36]. This model is similar to the pleasure–arousal 2D model but rotated by 45 degrees. The PAD model of emotion and the relationship with discrete emotions is shown in
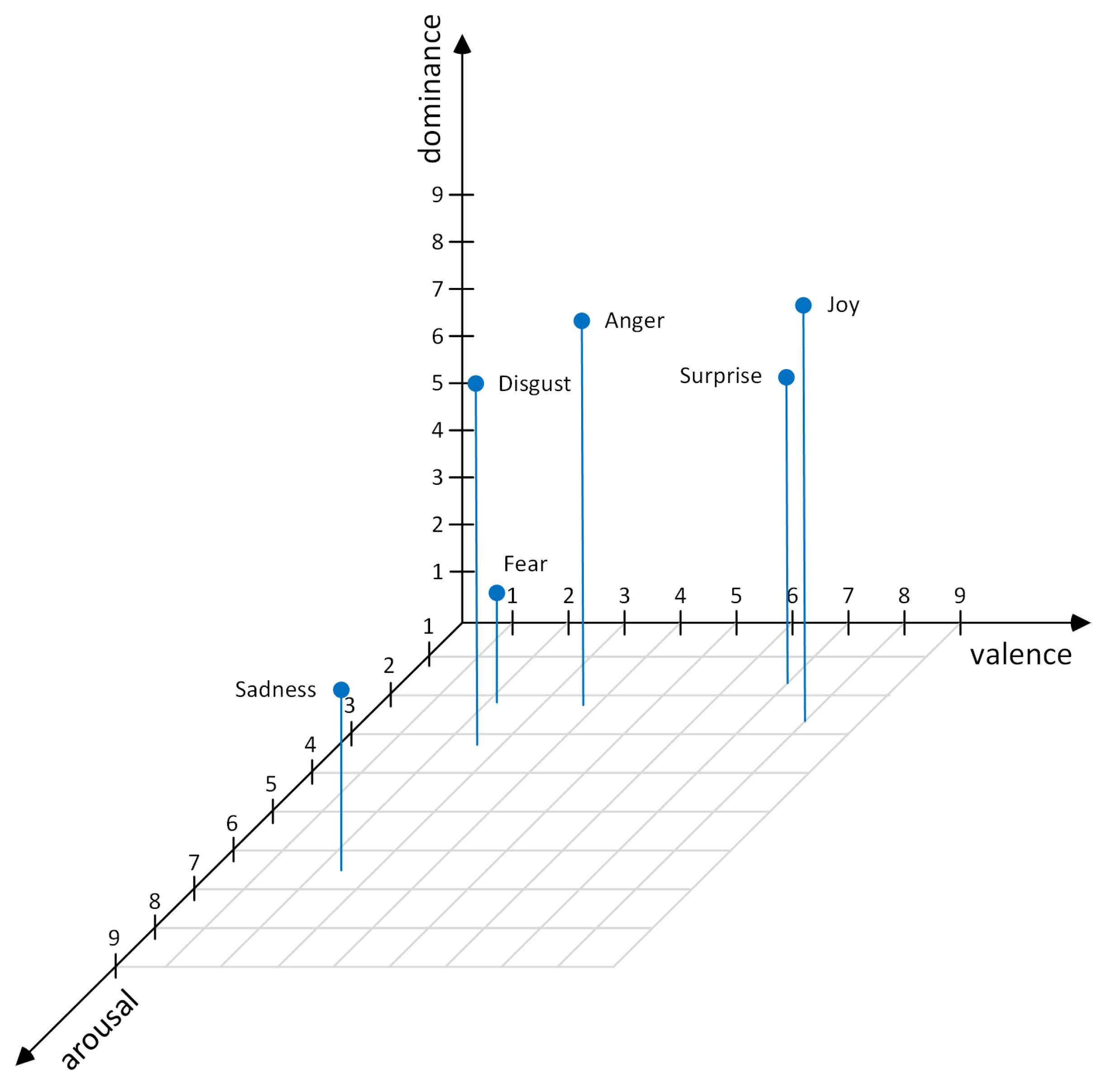
Figure 3.
As can be seen in
Figure 3 anger, disgust, and fear are all in the negative valence area, indicating that they are unpleasant emotions. Anger is distinguished by increased arousal and dominance, implying a high level of emotional activation as well as a sense of assertiveness or control. Disgust exhibits moderate arousal and dominance, whereas fear scores lower on dominance, indicating a lack of control when experiencing this emotion. Sadness is displayed as well in the negative valence area, but with lower arousal and dominance, indicating a lack of energy and feeling subdued. In contrast, joy and surprise are in the positive valence section, indicating that they are pleasant. Joy has high levels of arousal and dominance, indicating a vigorous and controlling emotional state, whereas surprise has high levels of arousal but moderate levels of dominance, possibly reflecting the unexpected nature of this emotion, which often leaves individuals feeling less in control.
3.2. Lexicon-Based Approach
Lexicon-based approaches in sentiment analysis have gained significant attention due to their robustness and effectiveness in capturing sentiment from text. These approaches utilize sentiment lexicons, which consist of words and phrases with associated sentiment orientations, to determine the overall sentiment of a given text [
37]. The sentiment lexicons play a crucial role in sentiment analysis, as they provide sentiment labels or scores to individual sentiment words, enabling the analysis of sentiment in various contexts, including microblog-like environments and social media [
38,
39].
Lexicon-based methods have been shown to be effective in cross-domain sentiment analysis and can be enhanced with multiple sources of knowledge, making them versatile and adaptable for different applications [
37]. These approaches offer a simple yet powerful way to obtain prior sentiment information from opinionated words in texts, making them valuable for analyzing sentiment in diverse languages and domains [
40,
41]. The use of sentiment lexicons in lexicon-based approaches provides a solid foundation for sentiment analysis, offering a comprehensive and reliable method for extracting sentiment-related information from text [
42].
The assumption of the lexicon-based approach is that the sentiment label of a sentence or text can be identified with the aggregated labels of words (i.e., n-grams). However, this may not always be accurate. For example, in the sentence “This film was neither good nor interesting”, the final sentiment might be positive if the words “good” and “interesting” are recognized. The problem with this approach lies in homonyms, which require different sentiment labels. This approach may also face challenges with phrases or sarcasm [
43].
To improve the performance of this approach, it is beneficial to create domain-specific lexicons, use semantic analysis for recognizing negations, sarcasm, or phrases, or employ larger n-grams. Another drawback is the lack of support for various languages. The advantages of this approach are simplicity and speed.
3.3. Machine Learning Methods for Sentiment Analysis
A significant surge in interest in sentiment analysis occurred in the 2000s, driven by the increasing volume of information on internet blogs and user review platforms, necessitating the automated processing of human opinions. Concurrently, ML methods gained popularity.
In recent years, various methods for sentiment analysis have been explored, including aforementioned sentiment lexicon-based, ML-based, and deep learning-based approaches. These methods have been instrumental in analyzing textual data from diverse sources such as social media, product reviews, and customer feedback. Recent studies have emphasized the use of ML algorithms, including deep learning models, for sentiment analysis across multilingual corpora, demonstrating their effectiveness in capturing sentiment from diverse linguistic sources [
44,
45].
An influential work from that era, authored by Pang and Lee [
46], provide an overview of the use cases, challenges, and approaches for sentiment analysis. Opinion mining is a term often equated with sentiment analysis. Key applications for sentiment analysis include market research, review analysis (pertaining to movies, series, products, restaurants, etc.), studying political attitudes, or integrating sentiment analysis as a component of a larger system (e.g., recommendation systems). Sentiment analysis poses diverse challenges, varying depending on the approach employed.
The integration of ML in sentiment analysis has enabled the extraction of valuable insights from large volumes of unstructured textual data, contributing to a deeper understanding of public sentiment and opinion. The application of ML in sentiment analysis has extended beyond textual data to encompass multimodal analysis, exploring the structure of emotions through diverse data modalities [
47].
ML techniques have been extended to social media platforms, such as Twitter, where sentiment analysis has been utilized to extract valuable insights from user-generated content, highlighting the versatility and relevance of ML in sentiment analysis [
48,
49].
The integration of ML in sentiment analysis has facilitated language-independent sentiment analysis, enabling the development of methods that can effectively capture sentiment across different languages and language pairs [
45,
50]. This has significant implications for cross-lingual sentiment analysis and the ability to extract sentiment from multilingual sources, contributing to a more comprehensive understanding of public opinion and sentiment on a global scale. The use of ML techniques has been instrumental in predicting the effects of sentiment, such as news sentiments, on various domains, including the stock market, underscoring the practical applications and impact of sentiment analysis in real-world scenarios [
51].
Classifiers based on gradient boosting are often used, such as LightGBM and XGBoost. The idea of gradient boosting is to create an ensemble of models where new models are better in cases where previous ones make mistakes. This approach, as demonstrated in [
52], has outperformed previous models. It is emphasized that LGBM particularly excels in cases where the dataset is imbalanced.
In the field of deep learning, one of the commonly used models is the Long Short-Term Memory (LSTM) network. LSTM is a recurrent neural network, meaning it has the ability to interpret sequential data (i.e., words in text). Although LSTM can achieve good results in sentiment analysis, its drawback is the long training time. In addition to LSTMs, possibilities of pre-trained transformer models that are fine-tuned for various use cases are being studied. Transformer models use attention mechanisms to focus on relevant words in the input text [
53], giving them the capability to capture longer word dependencies, i.e., larger context.
An alternative method in sentiment analysis on social media involved investigating the feasibility of utilizing text and emotions expressions in visual data to analyze Twitter/X activity. This approach specifically targeted accounts that had a substantial number of followers [
54,
55]. The study examined a dataset of more than 16,000 tweets collected from the accounts of 22 prominent startup founders, recognized for their substantial number of followers, gathered over a span of four months. The analysis of word usage in these tweets involved the application of conventional NLP techniques, such as frequency analysis and a comprehensive qualitative evaluation that focused on the distribution of words. Furthermore, the study included an assessment of the profile images of the founders in order to conduct facial emotion analysis and emotion mining. The findings correlate the basic emotional states inferred from these images to Twitter/X engagement metrics, such as tweet frequency and follower growth, over the observed period [
54,
55].
The use of ML algorithms has facilitated the construction of sentiment corpora, essential for training and validating sentiment analysis models [
56]. These corpora play a pivotal role in enhancing the accuracy and robustness of sentiment analysis systems, especially in domains such as product reviews and customer sentiment. Furthermore, the integration of ML in sentiment analysis has not been without challenges, as evidenced by the emergence of adversarial ML in this context [
57]. Adversarial ML techniques have been explored to address potential vulnerabilities and manipulations in sentiment analysis models, ensuring the reliability and security of sentiment classification systems.
3.4. Sentiment Analysis for Croatian Language
Recent research has shown a growing interest in sentiment analysis for the Croatian language, particularly in the context of social media content related to the COVID-19 pandemic. For instance, a study by Babić et al. [
58] developed an NL-based framework for sentiment analysis of a large dataset of tweets in Croatian, focusing on sentiments related to the pandemic. This research highlights the application of sentiment analysis in understanding public discourse and sentiments during the COVID-19 pandemic within the Croatian linguistic context. In [
59], a case of domain-specific sentiment classification for Croatian was presented, shedding light on the challenges and opportunities in sentiment analysis for Slavic languages.
Sentiment analysis in the Croatian language has also been explored in the context of social media content related to other topics. For example, research conducted via content analysis on Facebook comments in the Croatian language, revealing the dominant sentiment of the comments to be positive, demonstrating the application of sentiment analysis in understanding public sentiment in the Croatian social media landscape [
60]. These studies collectively contribute to the growing body of research on sentiment analysis in Croatian language, providing valuable insights into the sentiments expressed by Croatian speakers in various contexts, from public health crises to social media interactions.
3.5. Sentiment Analysis during Societal Crises
The COVID-19 pandemic, besides its impact on physical health, has had a significant effect on people’s mental health [
61]. The pervasive fear of the disease, coupled with isolation, the shift to online learning and remote working, and the need to wear protective masks, contribute to stress and negative psychological outcomes [
62,
63]. These effects are frequently manifested in textual expressions found on social media platforms or published in various forms of public communication. By examining the sentiments expressed on these platforms, a deeper understanding of how society is responding to the pandemic can be gained. Furthermore, to better cope with the pandemic (or other traumatic global or regional events), it is possible to explore emotions conveyed through news articles or social media and draw new conclusions about reactions to changes in the development or control of the pandemic and other similar events [
64].
A large number of scientific studies have been published that investigate the impact of the COVID-19 pandemic on emotions and sentiments. Previous studies have demonstrated that the COVID-19 pandemic has had a lasting impact on various aspects of human needs, including physiological needs, safety needs, and the need for care or affection (for example, see [
65,
66]). Among vulnerable groups, increased stress has been observed in individuals with chronic illnesses, while anxiety and sleep disorders have been noted in those with existing mental health conditions [
67]. Specifically, younger participants have exhibited indications of anxiety, middle-aged individuals have displayed feelings of anger, and older individuals have displayed heightened and enduring sadness [
68,
69].
The idea of monitoring sentiment during disease outbreaks is not entirely new or related solely to COVID-19 pandemic. In [
70], a range of psychological issues related to the Ebola virus outbreak and their corresponding sentiments were tracked. The response of the World Health Organization, which initially elicited negative sentiment as a result of travel bans, subsequently reverted to less severe negative sentiments. The inception of the vaccine initially elicited unfavorable sentiment characterized by apprehensions, but subsequently, sentiment pertaining to the vaccine shifted towards positivity. Lexicons containing words labeled as positive or negative were employed for the purpose of sentiment assessment.
In various diseases and disorders (flu, swine flu, meningitis, depression, bipolar disorder, etc.) were analyzed using Twitter data processed in two steps: identifying personal and news texts and measuring individual concerns and media stances [
71]. The results achieved in these studies encourage the exploration of different methods of sentiment and emotion analysis in documents in the Croatian language.
4. Hybrid NLP Model for Sentiment Analysis
The hybrid model for sentiment analysis presented in this paper is based on n-grams and efficiently integrates lexicon-based and machine learning (ML) approaches to enhance its analytical capabilities. In its most basic form, the model is lexicon-based and relies on unigrams, input preprocessing, and lexical matching to acquire emotion values. To gather additional insights into the relationship between semantics and emotion, the model can employ ML techniques. This feature improves flexibility and versatility of the model.
The lexical matching component assigns predetermined emotion values to individual input words, making the interpretation of results simple and straightforward. This supervised learning process involves utilizing an existing lexicon with a list of words and corresponding sentiment or emotional ratings. Three emotion lexicons are used: Affective Norms for English Words (ANEW), eXtended ANEW (XANEW), and NRC Word-Emotion Association Lexicon (EmoLex) [
72,
73,
74]. Sentiment-rated words in these corpuses are sought in preprocessed input texts, and the ratings of the identified words are then averaged to obtain the final text sentiment score aligned with dimensional and discrete emotion models.
In order to broaden its range and overcome the inherent limitations of the lexicon approach, the model can be extended to include not only unigrams but also n-grams of different token lengths. This expansion allows the inclusion of various machine learning algorithms commonly used in NLP, such as the naive Bayes classifier, support vector machines (SVMs), decision trees, random forests, and advanced neural networks like LSTM, GRU, and Transformers.
The ML aspect of the presented model is also evident in the investigation of the relationship between dimensional emotion values and discrete norms, as well as the analysis of the semantics and sentiments of n-grams. Empirical evidence has demonstrated the presence of statistically significant correlations between specific pairs of discrete and dimensional emotions [
23]. Similarly, unsupervised ML methods have demonstrated the ability to transform ratings from the discrete emotion space into distinct clusters in the dimensional space for specific pairs of discrete–dimensional emotions [
24].
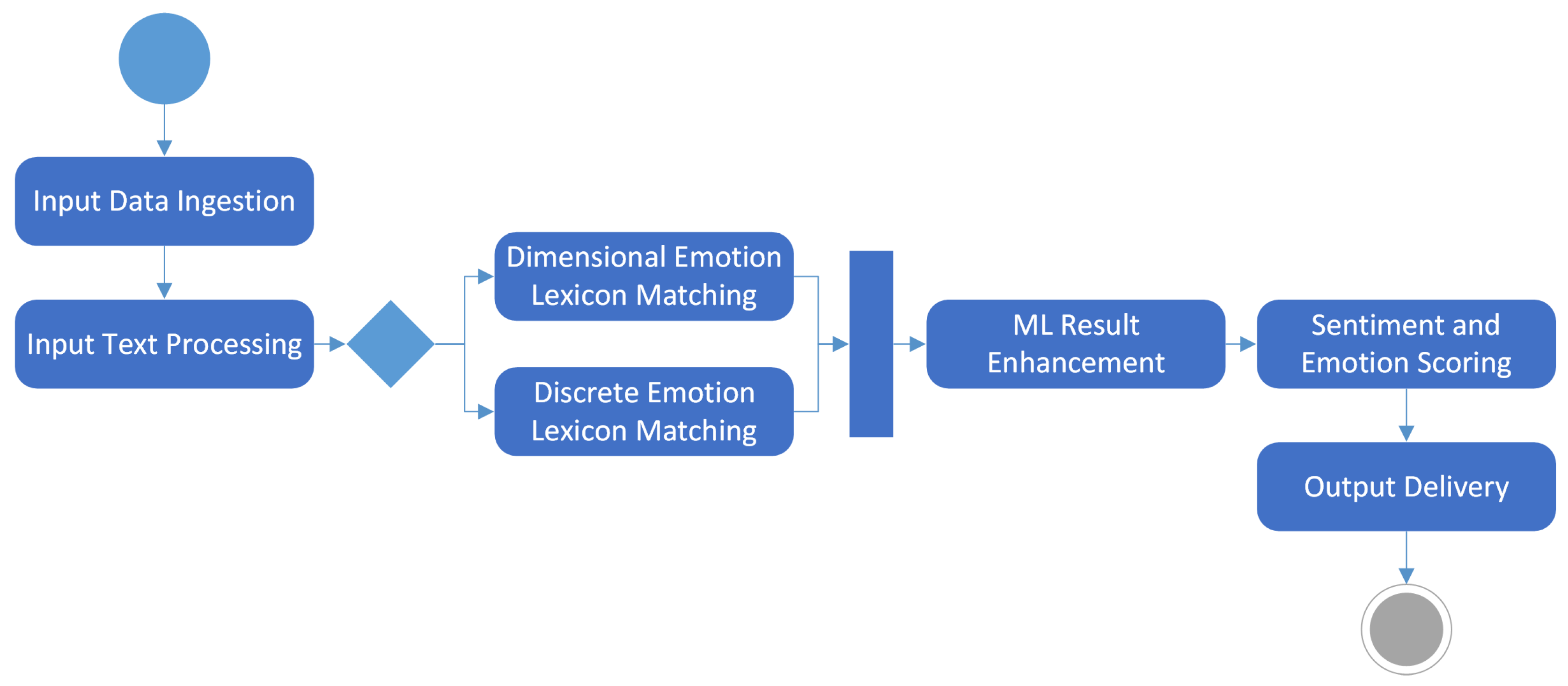
The hybrid model workflow for sentiment analysis is described as a UML activity diagram in
Figure 4.
After data ingestion, the sentiment analysis process of the presented model begins with the processing of input text data, which is typically unstructured. This text is first segmented into n-grams. In the lexicon matching step, each n-gram is then matched against an emotion lexicon where each entry is associated with predefined emotional and emotion lexicon scores. Standardized lexicons provide a baseline sentiment score for each n-gram based on its contained words, offering an initial estimation of the text’s emotional tone. To enhance the understanding of the text and overcome the inherent limitations of the lexicon-based approach (such as context insensitivity and the inability to handle novel expressions), various ML algorithms may be employed. Finally, in the sentiment and emotion scoring step, the results from both the lexicon-based and ML-enhanced analyses are obtained to produce a comprehensive sentiment score for each text input. The scores include discrete emotions (emotion norms such as happiness, sadness, anger, etc.) scored on a scale reflecting intensity of each norm and its presence within the text, and dimensional emotions. The dimensional output is measured along axes valence (pleasant–unpleasant), arousal (activated–deactivated), and dominance (controlled–uncontrolled), providing a multidimensional view of the emotions expressed by the input text. The output is a detailed sentiment profile of the text, which includes both aggregate scores and detailed emotion metrics.
The Hybrid NLP model for sentiment analysis has five distinct advantages over other available models in the field:
Multidimensional emotion analysis: Unlike many traditional models, which only provide one-dimensional sentiment analysis, this hybrid model combines discrete and dimensional emotion theories. This allows the model to provide a more comprehensive appraisal of sentiments expressed in text.
N-gram flexibility: The model is intended to work with n-grams of varying lengths, from unigrams to bigrams and beyond, making it highly adaptable to different corpus sizes and preprocessing capabilities.
Language independence: Depending on the translation service used, the model can be applied to any language, making it ideal for global use. The accuracy of the translation service determines the quality of the sentiment analysis.
No need for training data: Unlike many ML-based NLP models, which require extensive datasets to train before being deployed, this hybrid model is pre-trained using existing emotion lexicons and does not require any additional training data. This feature enables its immediate deployment and application.
Input dataset reuse: The presented model also has an advantage in that it can repurpose existing input datasets created for various NLP applications. The model can perform sentiment analysis without having to generate or collect new specialized datasets. In the experiment, the model was efficient in reusing existing corpora of spelling corrections in Croatian as input for sentiment analysis [
75].
4.1. Emotion Lexicons
Affective Norms for English Words (ANEW) is a textual dataset (lexicon) with emotional ratings for English words [
72]. The ratings in the lexicon were created in an experiment using the Self-Assessment Manikin (SAM), a visual method for collecting subjective responses from participants in controlled conditions [
76]. The ANEW lexicon contains 1034 rated words. The ratings follow the PAD model with scales for valence, arousal, and dominance. The participants could choose a rating from 1.0 to 9.0 for each evaluated word, and the collected ratings were averaged and statistically processed to obtain the aggregated dimensional emotion value for each word in the dataset. However, a potential issue with the ANEW is the limited number of words in the lexicon because text comprehension, and emotion elicitation from textual stimuli, becomes less significant if only a small number of words are recognized in the text (e.g., less than 10%). Therefore, an extension of ANEW, called XANEW (eXtended ANEW), that addresses this concern by encompassing 13,915 words was developed [
73]. New words, not present in ANEW, were rated through crowdsourcing. Similar instructions were used for participants as in the creation of ANEW, without employing SAM.
Apart from ANEW and XANEW, the EmoLex was used to rate n-grams according to discrete emotion theories [
74]. LemoLex includes 14,154 words and annotates them with 8 emotions from the Plutchik’s wheel: anger, fear, anticipation, trust, surprise, sadness, joy, and disgust [
74]. It also includes labels for negative and positive sentiment for words, which are binary. Like XANEW, EmoLex was created by manual annotation on a crowdsourcing platform. Unlike previous datasets, EmoLex includes translations into more than 100 languages, including Croatian. It has been used for the analysis of emotions in Shakespearean characters [
77], identifying the saddest songs by Radiohead [
78], and researching emotions related to COVID-19 in India [
79], among other applications.
4.2. N-Gram Datasets
The presented hybrid NLP model for sentiment analysis is based on n-grams collected from input texts received for spellchecking using the Croatian online spellchecker ispravi.me [
80,
81]. As already explained, ANEW, XANEW, and EmoLex lexicons were used by the hybrid NLP model to evaluate input documents. The input text dataset consisted of a subset of n-grams acquired by ispravi.me from October 2019 to March 2021. This period is significant as it allows for the comparison of sentiment and emotions in three distinct periods:
Before the COVID-19 virus spread and the earthquakes (October 2019–March 2020);
During the first wave of the pandemic and the Zagreb earthquake (March 2020–June 2020);
During the second wave of the pandemic and the Petrinja earthquake (August 2020–February 2021).
The n-grams were organized into textual files with filenames in the form “COVID-year-month-day-n”, where n is the n-gram’s order. The process of n-gram creation and preparation is explained in [
81]. The data have not been filtered based on content, allowing for the tracking of the general trend of sentiment. This approach aims to provide an impression of the baseline measures of sentiment and emotions before documents mentioning COVID-19 appear.
4.3. Emotion Lexicon Processing
The processing of the emotion lexicon started by utilizing the Python data analysis library Pandas for the input of the dataset in comma-separated values (CSV) format [
82]. The first step involved translating words into the Croatian language. For the translation, the Google Translate API through the
googletrans library [
83] and Microsoft’s Text Translation REST API [
84] were employed. XANEW was loaded from a CSV file, and a column indicating the translation of words was added using the
df.apply method for all rows of the Pandas DataFrame structure. Following translation into Croatian, lemmatization was performed using the CLASSLA library [
85].
The CLASSLA library is built on the foundation of Stanford’s Stanza library, adapted for working with Slovenian, Croatian, Serbian, Macedonian, and Bulgarian languages. The library’s functions include tokenization, sentence splitting, part-of-speech tagging, lemmatization, dependency analysis, and named entity recognition [
85].
Lemmatization is a process in which a word is transformed into its canonical form or lemma. It differs from stemming, which removes affixes from different word forms, resulting in the base or pseudoroot that is not a valid word by itself. The entire lemmatization process is illustrated in
Figure 5. As can be seen in this figure, as an example the initial input word “addictive” from the XANEW dataset undergoes two different translations utilizing Google Translator and Microsoft’s automated translation services. This results in two different Croatian terms “ovisnički” and “zarazna” which are stored in two separate lexicons containing different translations of XANEW. The next step in the processing pipeline involves lemmatization and combining of both Croatian translations. While lemmatization has minimal impact on most words after translation, it was applied to ensure consistency between lexicon processing and document annotation and to address certain inconsistencies introduced by translators. The translation quality was assessed by verifying if the translated words were correct Croatian terms using the ispravi.me spellchecker, which showed that 12,076 words from Google’s translator and 11,721 words from Microsoft’s translator exist in the Croatian word dictionary. The verification involved manual checking if the translated words are indeed correct Croatian terms.
Since the EmoLex lexicon includes token translations from English into Croatian, only the second preprocessing step was applied, where the already translated words were lemmatized (
Figure 6).
4.4. N-Grams Preprocessing
Preprocessing on n-grams was accomplished during the spellchecking process and n-grams were stored in a text file [
81,
86,
87]. Using the tokenization and lemmatization functions of the CLASSLA library, the n-grams were processed, and lemmatized words were saved as the final result. Lemmas were recorded in lowercase. Simultaneously, stop words were removed using the
stopwordsiso library [
88]. The complete processing procedure is shown in
Figure 7.
4.5. Model Creation and Application on the Experimental Dataset
Models are created as individual Python classes which receive the lexicon in the form of a Python dictionary. First, the lemmatized lexicon is loaded from a CSV file. Then, a hashing table is used where the words (lemmas) are set as dictionary keys, and the emotion ratings as dictionary values. To ensure unique keys in the dictionary, emotion ratings for English words were averaged into a single rating for the translated word in Croatian. Additionally, a Python Counter object was created which calculates how many times a distinct word was found in input texts to obtain token frequency.
As can be seen in
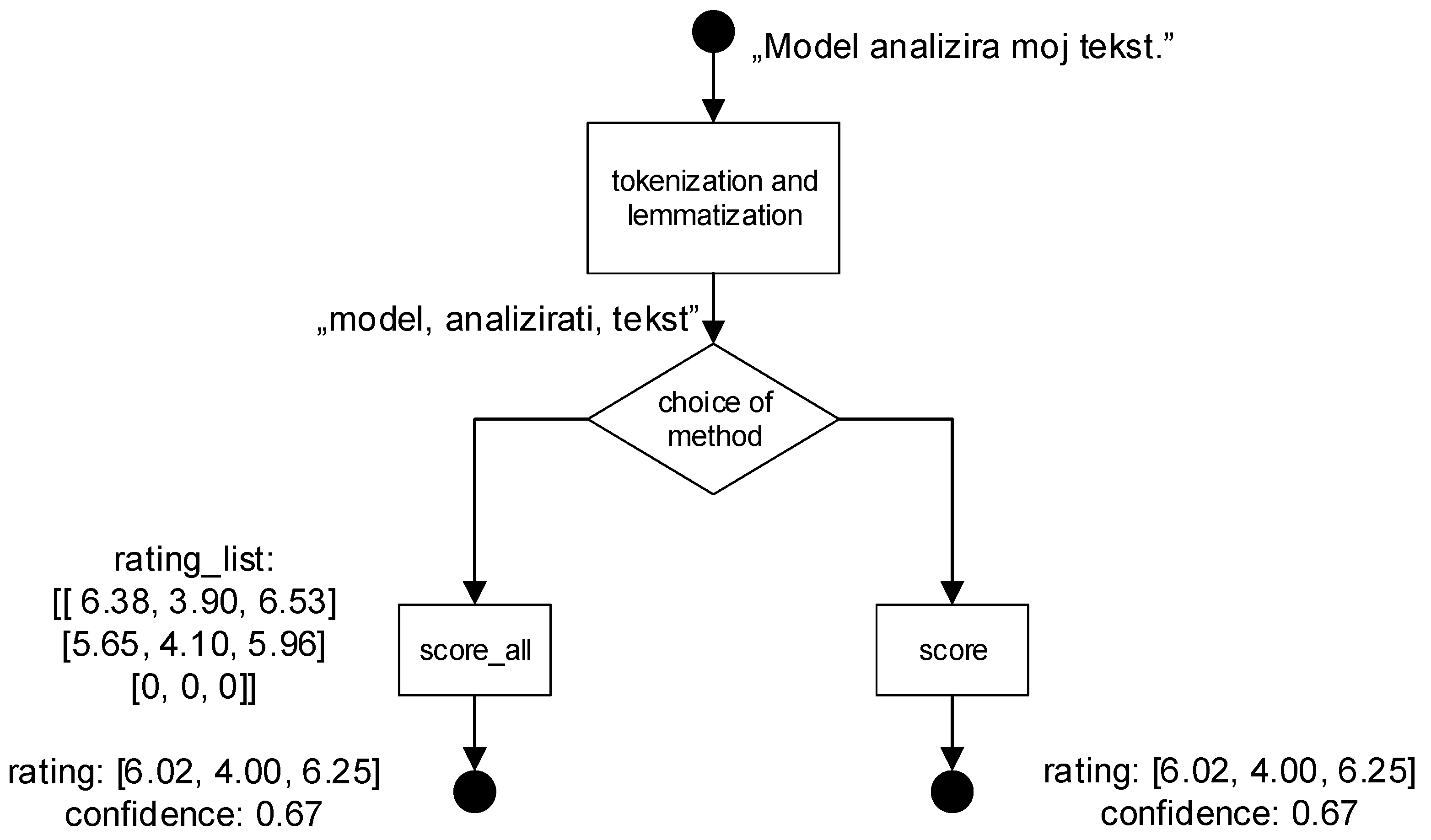
Figure 8, the Model class has two methods:
score and
score_all. Both methods take as an input argument a text variable containing different words separated by commas:
The score method returns the average rating for the words in the input argument excluding words not found in the lexicon. Furthermore, the method returns reliability—a real number value indicating the percentage of words present in the lexicon.
The score_all method, includes the functionality of the score method and also returns a list with individual sentiments ratings for words in the input argument.
Words not found in the lexicon receive a sentiment rating of 0. This rating does not contribute to the overall text score but marks the position in the list of the word that did not receive a rating from the lexicon. Both methods increment the corresponding values of the Counter object when a word is detected. The Model object is saved as a pickle file (i.e., to be converted into a byte stream if needed). Two emotion dimensional models are created: one with Google’s translation of XANEW and the other with Microsoft’s translation of XANEW.
Figure 8 illustrates how the implemented decision algorithm for the dimensional model is applied on a specific input sentence “Model analizira moj tekst” (English: “The model analyzes my text”). The variable
rating represents pleasure, arousal, and dominance for the entire input, while
rating_list shows labels for individual words. In this example, it is assumed that the word “tekst” (English: “text”) is not present in the lexicon (resulting in a confidence of 0.67, and the last element in the list of ratings containing 0). The model with the discrete EmoLex lexicon functions in the same way, using vectors with eight dimensions to store each discrete emotion rating.
All models in this experiment are constructed using unigrams. The decision to focus on simpler unigram models in the Croatian language was made to prioritize testing their capabilities before moving on to creating and testing more complex n-gram lexicons. Lexicons that include bigrams or trigrams are only occasionally employed, and their development is more complex, particularly for the Croatian language.
5. Experimental Results
The discrete and dimensional emotion models were deployed on the n-gram dataset that represents public sentiment in response to the COVID-19 pandemic and the two major earthquakes that struck Croatia in 2020. The dataset was collected by the spellchecking service ispravi.me and analyzed for the period from October 2019 to March 2021. In total, the processed corpus contained 12,135,672 data files with 2,937,934,768 tokens (405,571,794 in 2019, 651,472,299 in 2020, and 1,880,890,675 in 2021).
The results were obtained by applying the model’s score function to preprocessed n-grams. Two lists were created for each day of the data set. The first list contains the n-gram ratings for each day, the second is a confidence list. The confidence list makes it possible to filter the scores and only consider the cases in which a significant proportion of the words recognized in the lexicon occur, thus ensuring the reliability and relevance of the undertaken analysis.
For result analysis and visualization, the Python seaborn library [
89] was utilized, relying on matplotlib and Pandas DataFrame objects. To identify outliers (i.e., maximum or minimum values of discrete emotions and emotional dimensions detected in the corpus) in further analysis, z-scores are used [
90]. The z-score is calculated as the difference between a value and the mean, divided by the standard deviation:
where 𝑥 represents an individual data point and
μ is the mean value or average of all the data points in the dataset. Furthermore,
σ denotes the standard deviation of the dataset, which is a measure of the dispersion or variability of the data points 𝑥 around the mean
μ. A smaller standard deviation indicates that the data points tend to be closer to the mean, while a larger standard deviation indicates that the data points are spread over a wider range of values.
Outliers were detected on the following dates: 22 March, 25 December, and 28 December 2020, due to the Zagreb earthquake, COVID-19 maximum, and Petrinja earthquake, respectively. A detailed analysis of results is provided in
Section 5.1 and
Section 5.2.
5.1. Results Using the Dimensional Emotion Model
The presented analysis of the performance of the dimensional model used aggregated average sentiment scores on a daily, weekly, and monthly basis. The generated visualizations include a side-by-side comparison of the results of two versions of the model: one with Google’s translation service and the other with Microsoft’s.
This comparative analysis shows that the differences in the automatic translation services used do not have a significant impact on the overall results of the sentiment analysis. For the sake of clarity and consistency, the values of the model obtained with the Google translation service are used to explain the results of the experiment.
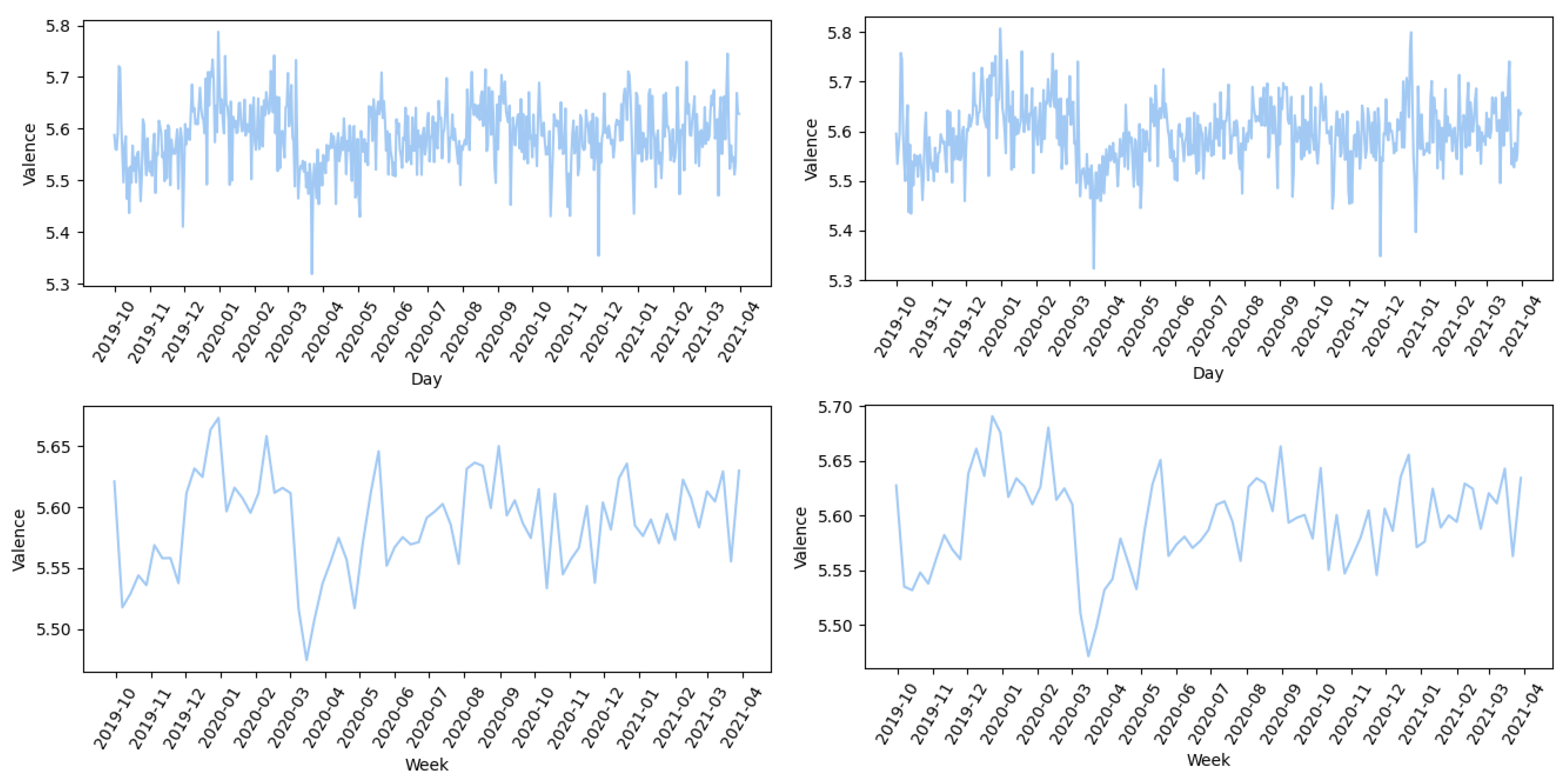
Figure 9 illustrates the development of active COVID-19 cases in Croatia. It shows the progression of the first outbreak (March to June 2020), followed by a subsequent increase (August 2020 to February 2021), which describes the first and second waves of the pandemic. As can be seen in
Figure 9, there has been a drastic change in the valence between the second and third months. Although valence reached low values in October and November, its lowest value (
val = 5.54) occurred in March 2020. The only week with an average valence below 5.50 (
val = 5.47) was the week starting 16 March 2020, which was the week following the declaration of the pandemic and the first week of the closure of educational institutions.
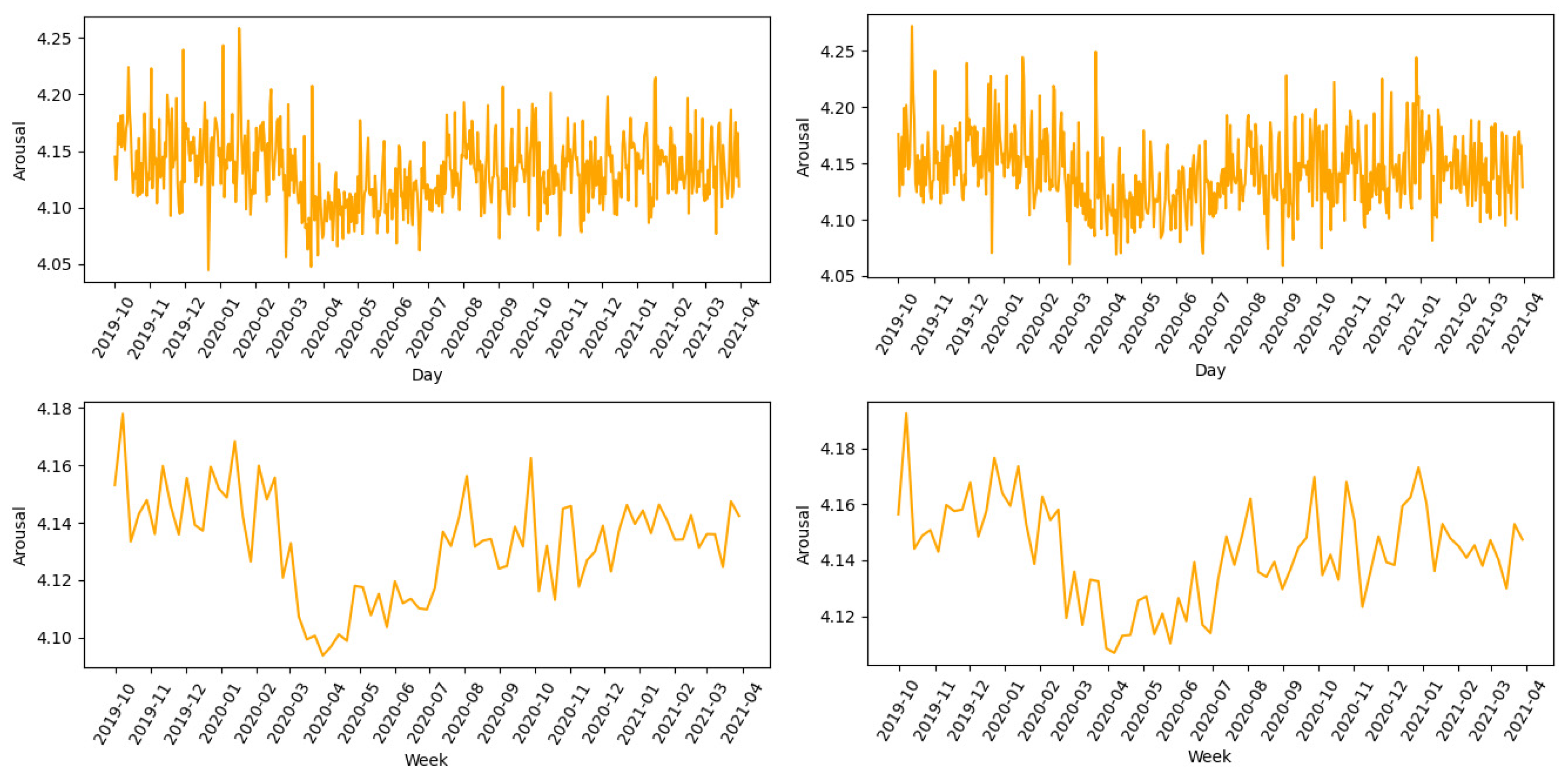
Figure 10 displays the progress of the arousal emotion dimension, which reaches its minimum a few weeks after the lowest value of the valence dimension but exhibits an additional and noticeable decline from February to March 2020. In addition,
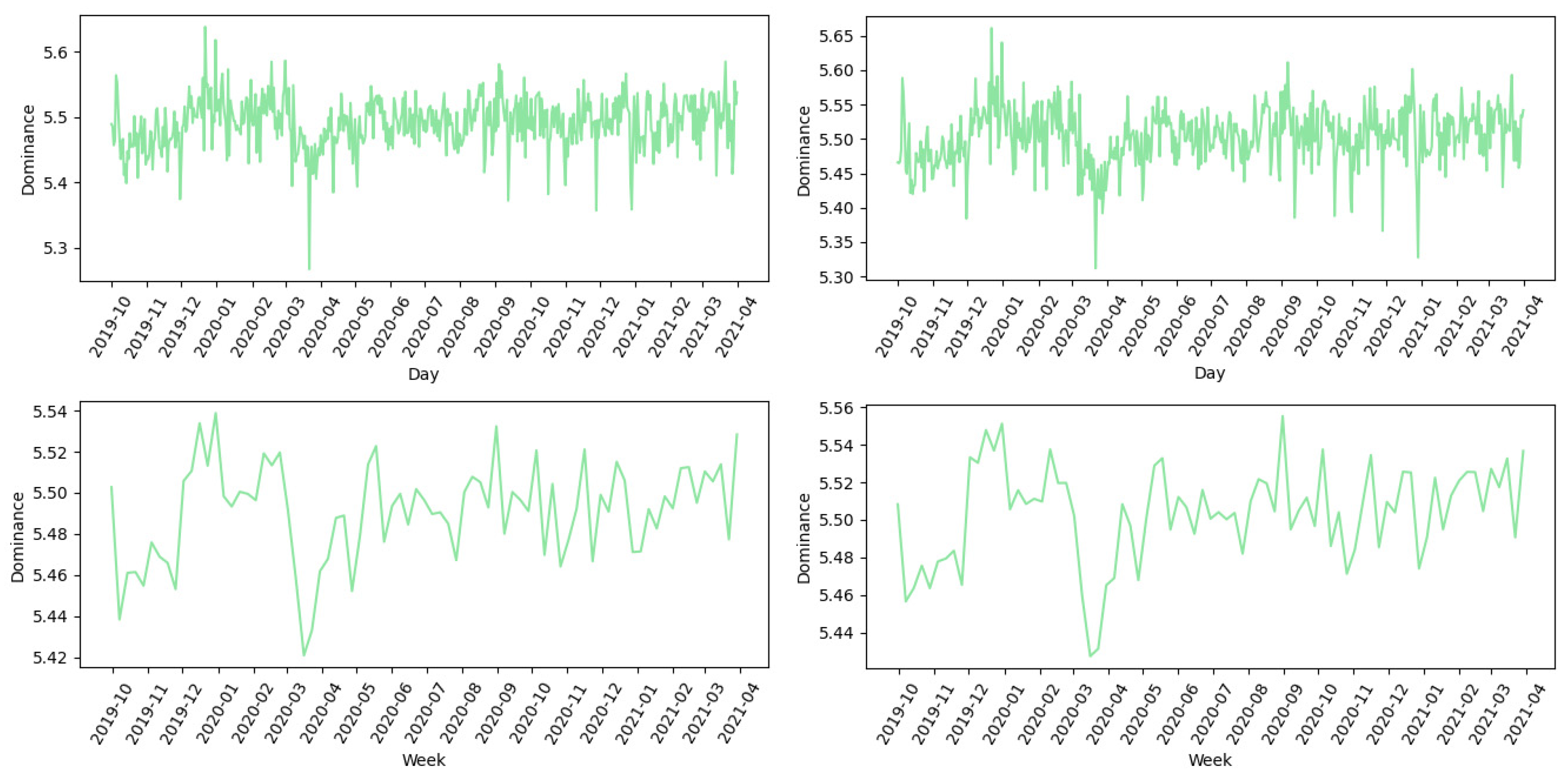
Figure 11 shows that the dominance dimension dropped to its lowest value of
dom = 5.46 in March, indicating a period in which individuals’ ability to effectively regulate their emotions decreased significantly. This convergence of results indicates a critical period of emotional upheaval that correlates with key phases of the pandemic.
The presented charts also facilitate an analysis of the recovery time—the time required for valence, arousal, and dominance values to return to pre-pandemic levels. Comfort and excitement reach a local maximum in August 2020, while dominance reaches its maximum in September 2020—indicating a normalization of the sentiment towards the coronavirus before the onset of the second wave. The second wave is most pronounced in the valence drop in November 2020.
However, the start of the second wave is clearly underlined by a significant dip in valence in November 2020. A closer look at the weekly average values reveals an interesting pattern: it takes around two months for the values for valence (val) and dominance (dom) to return to their pre-pandemic level. They rise from the values observed at the beginning of March (val = 5.61, dom = 5.49) to the values observed in the second week of May (val = 5.61, dom = 5.51). Arousal, on the other hand, indicates a more protracted path to baseline and does not return to the initial values until early August 2020.
The most emotionally negative day in the complete analyzed dataset was 22 March 2020, when a magnitude 5.5 earthquake occurred in Zagreb, with a valence value val = 5.32. The z-score for this day is z = −4.38, which is well above the commonly used z-score threshold of 3.0. The valence is also low (val = 5.44) on 29 December 2020, when a magnitude 6.2 earthquake occurred in Petrinja. The dominance also reaches its minimum (dom = 5.27) on the day of the earthquake in Zagreb, with z = −5.70. The difference between the two earthquakes and the pandemic can be seen on the arousal scale. On the day of the earthquake, the arousal value is ar = 4.21, the highest value for this month.
From this, it can be concluded that an earthquake, as a brief shocking event, elicits elevated arousal, while the pandemic, also a negative event, generally simulates emotions of lesser intensity.
5.2. Results Using the Discrete Emotional Model
The analysis results of the discrete model were obtained by employing the EmoLex corpus on the subset of texts related to the Croatian earthquakes in 2020. Emotions, as in the previous analysis of the dimensional model for COVID-19, are shown per day, week, and month. The results were described using the 8-axis Plutchik’s emotion model, which includes the emotion norms anger, fear, anticipation, trust, surprise, sadness, joy, and disgust.
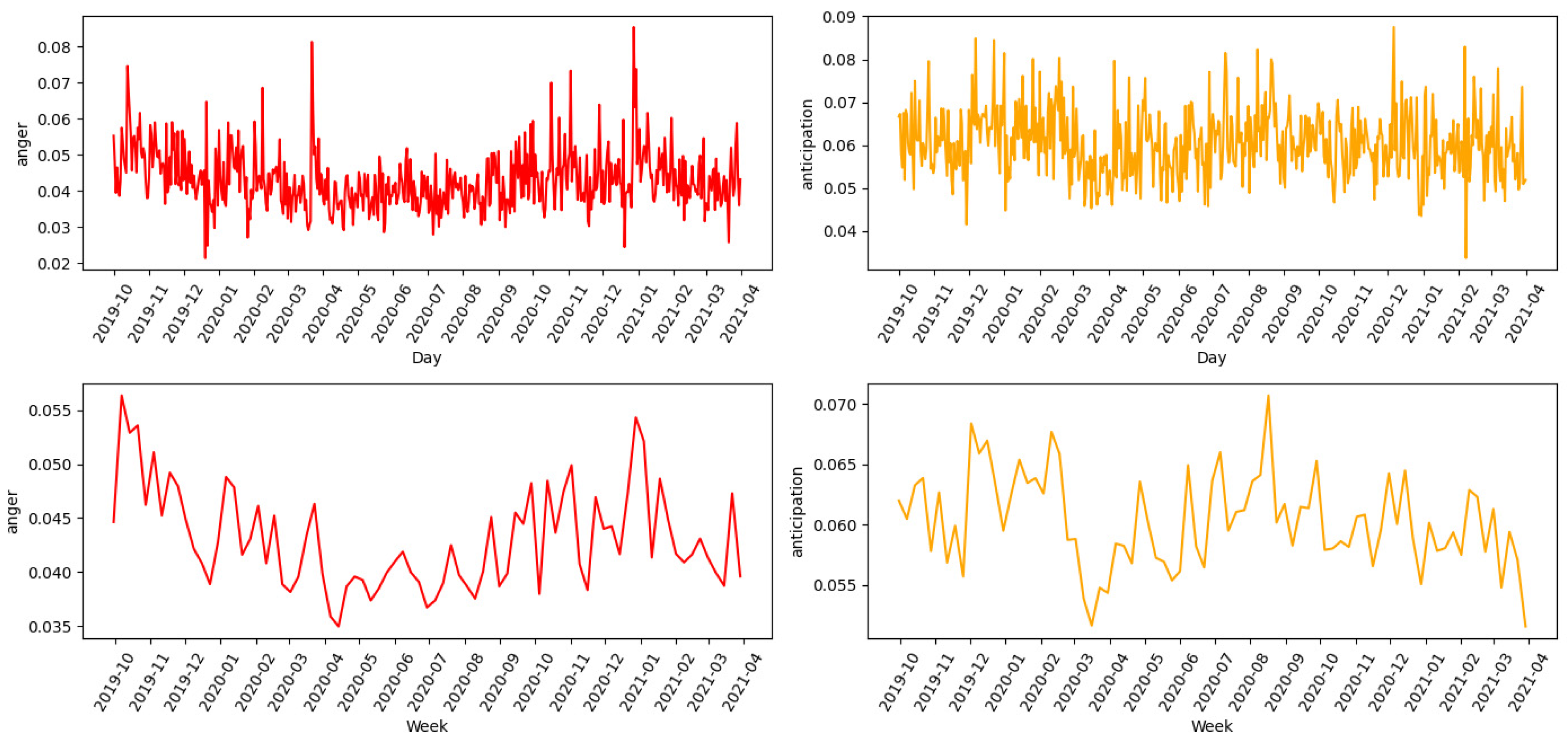
Peak levels of discrete emotion anger (shown in
Figure 12) are recorded on days experiencing earthquakes, with z-scores
z = 4.70 and
z = 5.21, respectively. In contrast, the onset of the pandemic marks a period of notably reduced anger, reflecting its minimal presence during the initial wave and the first lockdown. This aligns with the dimensional emotion analysis, as anger is categorized as a motivating emotion increasing arousal. On the other hand, discrete emotion fear (
Figure 13) manifests itself both during the earthquake events and throughout the first wave of the pandemic, consistently with the COVID-19 analysis presented in the previous section.
During the first wave of the pandemic, happiness is particularly low, while sadness peaks on the days of the earthquake and in the following week after the Petrinja quake, as shown in (
Figure 14). The emotions of anticipation and disgust remain relatively stable, with daily fluctuations showing no significant deviations from the norm (z-scores remain below 3 in absolute terms).
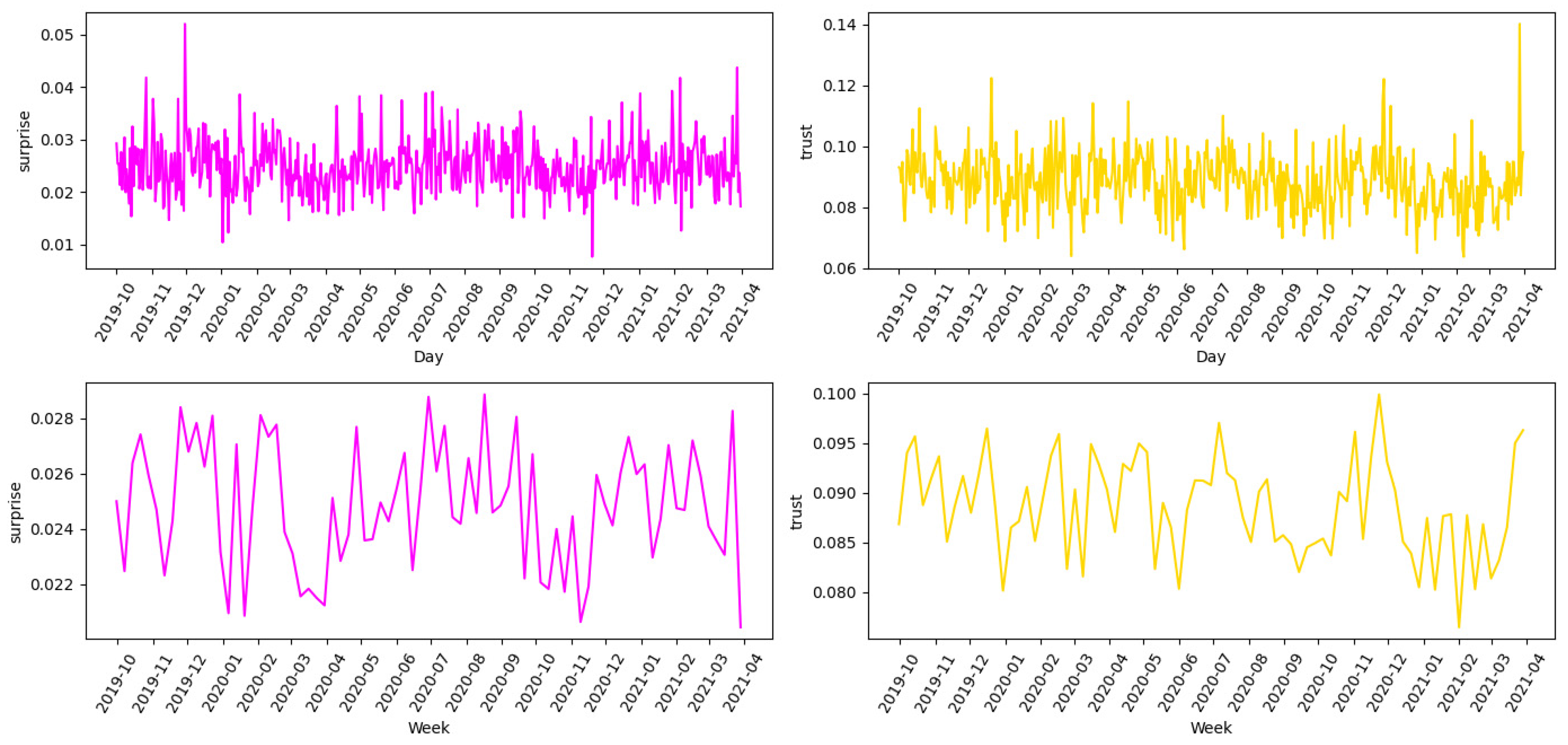
The statistical analysis shows that the feeling of happiness is not subject to strong daily fluctuations. However, it is obvious that this discrete emotion reaches its lowest point during the peak of the pandemic and rises again to pre-crisis levels in the breaks between these waves. As for surprise and trust, these emotion norms do not show significant fluctuations in relation to either the earthquakes or the pandemic, as shown in
Figure 15. This pattern suggests a consistent emotional baseline that remains unaffected by these specific events.
6. Discussion
Concerning the sentiment analysis based on the dimensional emotion model, the analysis revealed a significant decrease in valence, arousal, and dominance in Croatia during the first wave of the pandemic, especially in the week of the closure of educational institutions. Minimal values of valence and dominance (5.47 and 5.42, respectively) were observed during that specific week. For the recovery process (i.e., the return of valence and dominance values to pre-pandemic levels), two months were required, but a subsequent decline in valence and dominance can be observed after recovery, at the beginning of the second wave of the pandemic. According to the discrete model, the emotion norms fear and sadness dominated during the COVID-19 pandemic.
Besides emotions related to the pandemic, prominent changes in dimensional emotion values were observed during the earthquakes in Zagreb in March 2020 and in Petrinja in December 2020. Earthquakes were characterized by discomfort, arousal, and dominance (i.e., the lack of control over the emotion stimulating event—as would be expected for a sudden earthquake). The main discrete emotions identified during earthquakes were sadness, fear, and anger.
Interestingly, the recovery period was significantly longer during the earthquakes than during the pandemic, lasting several months. This notable phenomenon may be ascribed to numerous aftershock seismic events of different intensities and the sensation of powerlessness, highlighting the enduring and significant influence of natural catastrophes on the psychological condition of those impacted. The enduring consequences of these ongoing seismic incidents, which were made worse by the ongoing global health crisis, presented a multifaceted description of societal distress and resilience.
Because of the absence of a suitable sentiment analysis lexicon for the Croatian language, which further complicated the development of the model and implementation of the experiment, automatic translation into English was required. Automatic translation was, therefore, required. The utilization of translated lexicons in sentiment analysis introduced the possibility of inaccuracies, which emphasizes the need to develop native language resources for sentiment analysis research. During the results dissemination, it became evident that even sophisticated automated translation services cannot capture every detail and linguistic specificity of the source language. This deficiency may have an adverse impact on the precision of sentiment analysis. We believe that the results would be even more representative and detailed if the Croatian lexicon were available.
Therefore, the development or adaptation of a dedicated Croatian sentiment lexicon would significantly improve the precision of sentiment analysis. Such a lexicon could better capture the details and cultural context of the Croatian language, allowing for a more accurate representation of semantics and emotion. This points to an important direction for future research and development in the field of NLP: the creation of comprehensive, language-specific sentiment lexicons that can support accurate sentiment analysis.
7. Conclusions and Future Work
In this study, a new lexicon-based sentiment analysis model was employed to analyze Croatian language data during the COVID-19 pandemic and two major earthquakes in 2020. The affective lexicons used were Extended ANEW, containing ratings in the form of a dimensional emotion model (valence, arousal, and dominance), and the NRC Word-Emotion Association Lexicon, with ratings in the form of an 8-axis discrete emotion model (anger, anticipation, disgust, fear, joy, sadness, surprise, trust). These existing lexicons were translated into Croatian using freely available automated services, and Python software modules were developed using these lexicons for sentiment analysis, as well as for evaluating and visualizing the results.
As explained in
Section 4, the presented model is simple, versatile, and efficient in reusing existing corpora of spelling correction for sentiment analysis. Also, the model is extensible and can be generated with unigrams in its simplest form or can be expanded to incorporate n-word sequences.
The decision to use n-grams instead of a bag-of-words model not only enhances our current sentiment analysis capabilities, but also creates a solid foundation for incorporating advanced linguistic features such as embeddings in the future. By taking this proactive approach, we ensure that our model remains at the forefront of sentiment analysis technology and is prepared to adapt and grow with emerging computational techniques and theories.
In addition to the analysis of sentiments during long-term phenomena, under the conditions of a pandemic that has spread across a large region or even globally, such as was the case with COVID-19, the presented hybrid NLP model was used to detect different significant short-term societal events that significantly influence human emotions (i.e., earthquakes). By analyzing the emotional changes in texts utilized for spellchecking at Croatian online spellchecker ispravi.me during the COVID-19 pandemic and the earthquakes in Croatia during 2020, we have found that the presented model is capable of accurately capturing the intricacies of human emotions during natural disasters based on a corpus that was not initially developed for this purpose. This research contributes to expanding the field of sentiment analysis by presenting an approach that not only accounts for linguistic details, but also provides important insights into the complicated nature of emotional responses in times of various societal crises.
Furthermore, our research in underrepresented linguistic contexts points to the importance of developing and refining lexicon-based models for sentiment analysis in languages other than English. By incorporating and augmenting pre-existing standardized affective datasets to include the Croatian language, we have achieved a new and positive result in the development of more comprehensive and representative sentiment analysis tools.
The applicability of the presented hybrid model in addressing actual crises in the real world demonstrates its potential usefulness for policy makers, mental health professionals and crisis response groups. We believe that the model may provide valuable insights into public sentiment and emotional trends in societal crises that can be used to develop support strategies and targeted interventions to mitigate the psychological impact of such events.
In the context of future work and considering the results obtained, it would be advisable to continue research into the creation of large lexicons tailored to specific types of societal crisis and for specific languages. Such lexicons would improve the precision and practicality of sentiment analysis in different cultural and linguistic settings. Furthermore, exploring the possible fusion of more traditional ML techniques and novel large language model (LLM) deep learning methods could open up new opportunities to improve the precision and predictive power of sentiment analysis models.
It is important to note that this model relies on n-grams rather than the more traditional bag-of-words method for two important reasons that are closely related to its evolution. First, n-grams provide a richer linguistic context compared to bag-of-words models because they contain information about the order of tokens, not just their frequency. This facilitates understanding of the expressed context, which is frequently required for accurate interpretation of feelings and emotions in the text. Second, the authors plan to continually improve the model and incorporate text embeddings into future versions. Embeddings provide a comprehensive understanding of the meaning and usage patterns of words and phrases in a given corpus by representing them in a multidimensional space. n-grams are inherently better suited to the inclusion of embeddings than bag-of-words models, as they match the embeddings’ ability to understand context and sequence.
Looking even more into the future, it would be prudent to follow a more holistic approach in NLP where the advancement of AI could be enhanced by combining data-driven techniques with an understanding of inherent cognitive structures (contrast of two primary theories of knowledge acquisition—nativism vs. empiricism—in AI) [
91]. This approach may have the potential to result in the creation of AI systems that are more resilient, flexible, and in tune with human cognition, enabling them to truly comprehend language rather than merely recognizing patterns [
91]. It is also important to promote a dialog between various disciplines including cognitive science, linguistics, philosophy, and computer science in order to enhance AI research and practice in the field of NLP.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}