
Secure Task Offloading and Resource Allocation Strategies in Mobile Applications Using Probit Mish-Gated Recurrent Unit and an Enhanced-Searching-Based Serval Optimization Algorithm


Abstract
:1. Introduction
1.1. Problem Statement
- Most of the existing works performed task offloading and resource allocation by verifying the task features with the global scheme alone but failed to analyze the local computing features.
- The existing works did not focus on the traffic attributes for load balancing. This resulted in more energy consumption.
- The security of smart contracts was not ensured in the previous works, which lowered the trustworthiness of the networks.
- System consistency is a major challenge for storing hashed information in the cloud computing environment.
1.2. Contributions
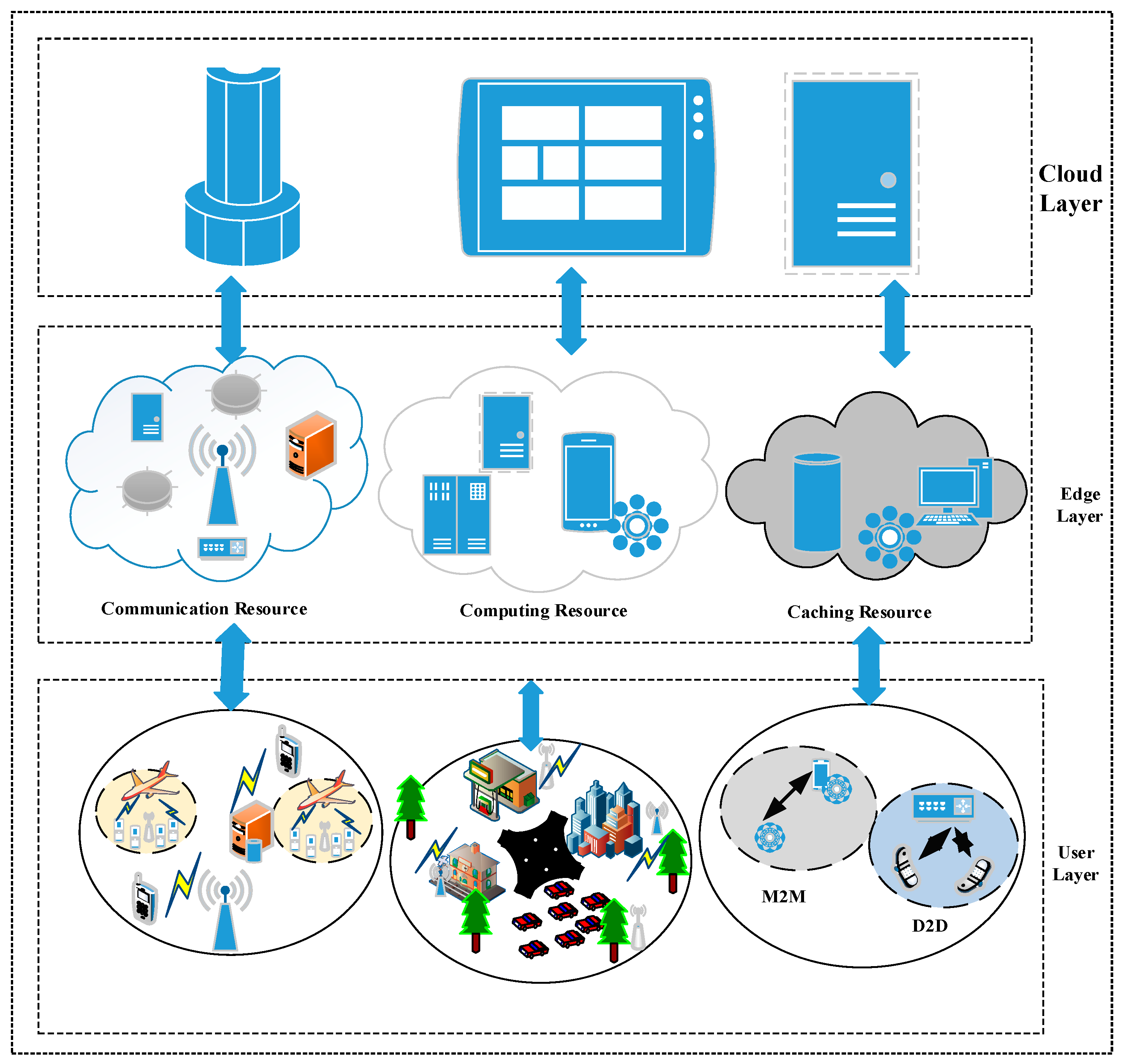
2. Literature Review
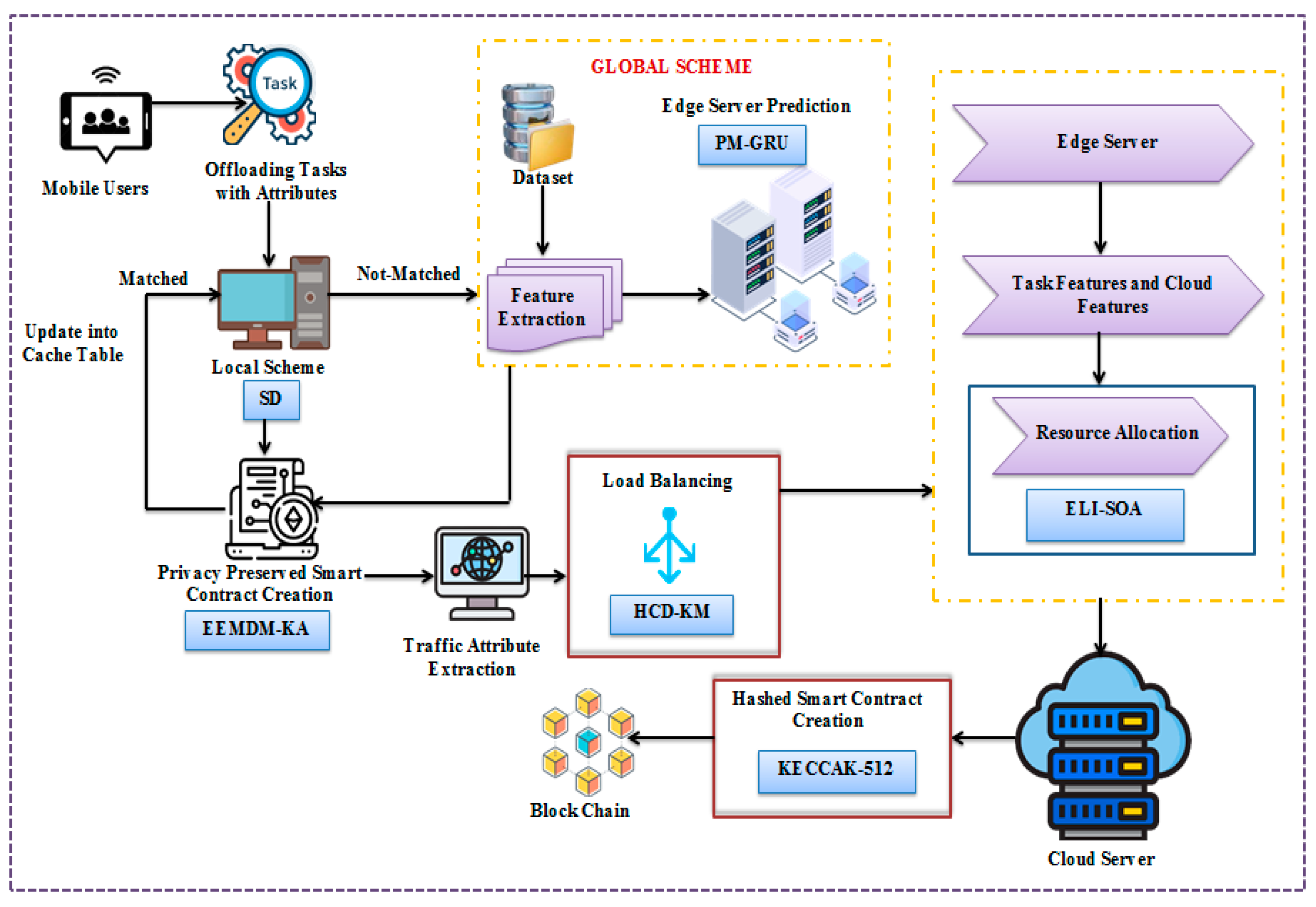
3. Secure Task Offloading with PM-GRU and ELI-SOA
- (1)
- The local scheme: The local scheme, which is primarily linked to mobile users’ data and is used to control all tasks and manage data coming from offloaded tasks, is a sub-part of the integral MEC system framework. It is also in charge of making updates to data when attributes match, and then details about the appropriate edge server are produced. If the attributes do not match, they are inputted into the server scheme, which predicts the edge server based on the Probit model and GRU.
- (2)
- The global scheme: A physical location that is close to the systems of mobile devices (apps) managing extracted information coming from a dataset and from the EEMDM-KA program is designated in our approach as the location for edge server prediction; this server is led by the proposed PM-GRU as the global scheme, and it manages datasets and feature extraction.
- (3)
- The load-balancing model: Defined as HCD-KM, this technique represents a method of proportionally distributing network traffic across a whole MEC system; most information, such as text, videos, images, and other data, is processed inside this component to allow mobile users to interchange information properly and efficiently. Its information passes through the local scheme, and EEMDM-KA passes through the program for traffic attribute extraction to arrive at the load-balancing scheme and, finally, be sent to the cloud server.
- (4)
- The resource allocation scheme: Resource allocation, which is the process of assigning and managing HCD-KM, delivers better ELI-SOA assets by providing complete cloud service in a manner that provides reliable profitability to the blockchain for KECCAK 512. This system includes managing tangible assets, such as hardware, to make the best use of softer assets, such as human capital.
- (5)
- The blockchain: The blockchain framework manages all processing to avoid any leakages of MEC data from the edge server while delivering secure and reliable task offloading.
- (6)
- Smart contact creation: Smart contracts are created and hashed based on the Keccak 512-bit Hash Generator. This system is adopted to automate the execution of any agreement so that all users can be promptly certain of the outcome without any intermediary’s involvement or loss of time.
- (7)
- Task offloading model: This model’s main role consists of transferring all resource-intensive computational tasks to other connected systems.
3.1. Mobile Cloud Resource Allocation
- Input: Here, the extracted features are considered as the input. indicates the inputs in the present time frame, and indicates the input from the previous hidden state. The inputs proceed to flow via the gates.
- Probit Mish Activation Function: The Probit Mish activation function (PMAF) is employed to improve the learning process and convergence rate. This is formulated as follows:
- Reset Gate: This gate should decide how much irrelevant information needs to be eradicated from the gates. The reset gate is determined as follows:
- Update Gate: The update gate decides how much crucial information needs to be allowed through the gates for further computation. The update gate can be written in a mathematical form as follows:
- Candidate Hidden State: This gate considers the reset gate and determines what relevant information needs to be stored. This is formulated as follows:
- Hidden State: Finally, the hidden state makes a decision about what information needs to be passed through the network as an outcome, and it is defined as follows:
| Algorithm 1 pseudo-code for the Probit Mish–GRU. |
| Input: Extracted features |
| Output: Edge Server Prediction |
| Begin: |
| Initialize , , , , , iteration , and maximum iteration |
| Set |
| While |
| For 1 to number of |
| Perform reset gate |
| Apply Probit Mish activation function |
| Implement update gate |
| Calculate |
| Execute hidden state: |
| End For |
| End While |
| Return |
| End |
3.2. Secure Resource Allocation in MEC
- Step 1: The number of clusters is specified; then, the centroid point is randomly initialized by using Equation (21):
- Step 2: During the next part of the derivation, the value of the distance between and is estimated by using the HCM technique. The HCM technique is used to effectively calculate the distance among the data points. The data points are then assigned to the cluster that has the nearest distance value. This can be expressed as follows:
- Step 3: Finally, the centroid point is recalculated, and the clustering process is repeated until it converges. Thus, the load-balanced requests are given as follows:
- Input features: Here, the task features and cloud features are chosen to perform RA. The task features, such as the number of dimensions, speed, cost, weight, and data size, are extracted. Then, cloud features, such as size, RAM, bandwidth, length, file size, storage, and VM, are also taken into account to allocate the optimal resources. The -many extracted features are initialized as follows:
- Population Initialization: First, the population of the SOA is initialized in the search space. Here, is assumed to be the serval. This is structured in the form of a matrix as follows:
- Fitness Function: In this step, the fitness value of is derived by considering the minimum response time . This can be estimated by using Equation (28):
- Exploration Phase (prey selection and attack): In this phase, an exploration is carried out according to strategies followed by the serval to perform prey selection and attack. The exploration stage can be briefly described as follows:
- Exploitation Phase (chasing process): After the process of attacking the prey, the exploitation phase takes place based on the chasing strategy of the serval. Here, the entropic linear interpolation (ELI) method is used to update the serval’s position, and its value is defined as follows:
| Algorithm 2 pseudo-code for the ELI-SOA algorithm. |
| Input: Extracted features () |
| Output: Allocated resources |
| Begin: |
| Initialize , , , , iteration , and maximum iteration |
| Set |
| While |
| For 1 to G of |
| Initialize population in the search space |
| Estimate the FFV |
| Implement Exploration Phase |
| If |
| Update the serval’s position to |
| Else |
| No need to update the serval’s position |
| End If |
| Perform Exploitation phase |
| Update FFV and serval position |
| End For |
| End While |
| Return |
| End |
- Theta Step:
- For and ,
- For and ,
- For , , and ,
- Rho Step:
- For ,
- Assume that .
- For and for ,
- Pi Step:
- For , , and ,
- Chi Step:
- For , , and ,
- Iota Step:
- For ,
4. Results and Discussion
4.1. Dataset Description
4.2. Simulation and Analysis Parameters
4.3. Performance Analysis
5. Conclusions and Future Work
5.1. Conclusions
Advantages and Drawbacks
5.2. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhu, X.; Zhou, M. Multiobjective Optimized Cloudlet Deployment and Task Offloading for Mobile-Edge Computing. IEEE Internet Things J. 2021, 8, 15582–15595. [Google Scholar] [CrossRef]
- Li, W.; Jin, S. Performance evaluation and optimization of a task offloading strategy on the mobile edge computing with edge heterogeneity. J. Supercomput. 2021, 77, 12486–12507. [Google Scholar] [CrossRef]
- Liao, J.X.; Wu, X.W. Resource Allocation and Task Scheduling Scheme in Priority-Based Hierarchical Edge Computing System. In Proceedings of the 2020 19th Distributed Computing and Applications for Business Engineering and Science, DCABES, Xuzhou, China, 16–19 October 2020; pp. 46–49. [Google Scholar] [CrossRef]
- Lin, B.; Lin, X.; Zhang, S.; Wang, H.; Bi, S. Computation task scheduling and offloading optimization for collaborative mobile edge computing. In Proceedings of the International Conference on Parallel and Distributed Systems-ICPADS, Hong Kong, China, 2–4 December 2020; pp. 728–734. [Google Scholar] [CrossRef]
- Xu, J.; Liu, X.; Zhu, X. Deep Reinforcement Learning Based Computing Offloading and Resource Allocation Algorithm for Mobile Edge Networks. In Proceedings of the 2020 IEEE 6th International Conference on Computer and Communications, ICCC, Chengdu, China, 11–14 December 2020; pp. 1542–1547. [Google Scholar] [CrossRef]
- Xue, J.; An, Y. Joint Task Offloading and Resource Allocation for Multi-Task Multi-Server NOMA-MEC Networks. IEEE Access 2021, 9, 16152–16163. [Google Scholar] [CrossRef]
- Zhang, N.; Guo, S.; Dong, Y.; Liu, D. Joint task offloading and data caching in mobile edge computing networks. Comput. Netw. 2020, 182, 107446. [Google Scholar] [CrossRef]
- Chen, X.; Liu, G. Joint Optimization of Task Offloading and Resource Allocation via Deep Reinforcement Learning for Augmented Reality in Mobile Edge Network. In Proceedings of the 2020 IEEE 13th International Conference on Edge Computing, EDGE, Beijing, China, 19–23 October 2020; pp. 76–82. [Google Scholar] [CrossRef]
- Peng, K.; Nie, J.; Kumar, N.; Cai, C.; Kang, J.; Xiong, Z.; Zhang, Y. Joint optimization of service chain caching and task offloading in mobile edge computing. Appl. Soft Comput. 2021, 103, 107142. [Google Scholar] [CrossRef]
- Jiang, W.; Feng, D.; Sun, Y.; Feng, G.; Wang, Z.; Xia, X.-G. Joint Computation Offloading and Resource Allocation for NOMA based multi-access mobile computing systems. IEEE Trans. Serv. Comput. 2022, 196, 108256. [Google Scholar] [CrossRef]
- Alfakih, T.; Hassan, M.M.; Gumaei, A.; Savaglio, C.; Fortino, G. Task offloading and resource allocation for mobile edge computing by deep reinforcement learning based on SARSA. IEEE Access 2020, 8, 54074–54084. [Google Scholar] [CrossRef]
- Mohammed, A.; Nahom, H.; Tewodros, A.; Habtamu, Y.; Hayelom, G. Deep Reinforcement Learning for Computation Offloading and Resource Allocation in Blockchain-Based Multi-UAV-Enabled Mobile Edge Computing. In Proceedings of the 2020 17th International Computer Conference on Wavelet Active Media Technology and Information Processing, ICCWAMTIP, Chengdu, China, 18–20 December 2020; pp. 295–299. [Google Scholar] [CrossRef]
- Jiang, H.; Dai, X.; Xiao, Z.; Iyengar, A.K. Joint Task Offloading and Resource Allocation for Energy-Constrained Mobile Edge Computing. IEEE Trans. Mob. Comput. 2023, 22, 4000–4015. [Google Scholar] [CrossRef]
- Wang, G.; Yu, X.; Xu, F.; Cai, J. Task offloading and resource allocation for UAV-assisted mobile edge computing with imperfect channel estimation over Rician fading channels. EURASIP J. Wirel. Commun. Netw. 2020, 2020, 169. [Google Scholar] [CrossRef]
- Nath, S.; Wu, J. Deep reinforcement learning for dynamic computation offloading and resource allocation in cache-assisted mobile edge computing systems. Intell. Converg. Netw. 2020, 1, 181–198. [Google Scholar] [CrossRef]
- Shahidinejad, A.; Ghobaei-Arani, M. Joint computation offloading and resource provisioning for edge-cloud computing environment: A machine learning-based approach. Softw. Pract. Exp. 2020, 50, 2212–2230. [Google Scholar] [CrossRef]
- Tao, X.; Ota, K.; Dong, M.; Qi, H.; Li, K. Performance guaranteed computation offloading for mobile-edge cloud computing. IEEE Wirel. Commun. Lett. 2017, 6, 774–777. [Google Scholar] [CrossRef]
- Wang, X.; Wang, K.; Wu, S.; Di, S.; Jin, H.; Yang, K.; Ou, S. Dynamic resource scheduling in mobile edge cloud with cloud radio access network. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 2429–2445. [Google Scholar] [CrossRef]
- von Mankowski, J.; Durmaz, E.; Papa, A.; Vijayaraghavan, H.; Kellerer, W. Aerial-aided multiaccess edge computing: Dynamic and joint optimization of task and service placement and routing in multilayer networks. IEEE Trans. Aerosp. Electron. Syst. 2022, 59, 2593–2607. [Google Scholar] [CrossRef]
- Zhang, C.; Li, Z.; He, C.; Wang, K.; Pan, C. Deep Reinforcement Learning Based Trajectory Design and Resource Allocation for UAV-Assisted Communications. IEEE Commun. Lett. 2023, 213, 88–98. [Google Scholar] [CrossRef]
- Baidas, M.W. Resource allocation for offloading-efficiency maximization in clustered NOMA-enabled mobile edge computing networks. Comput. Netw. 2021, 189, 107919. [Google Scholar] [CrossRef]
- Kuang, Z.; Ma, Z.; Li, Z.; Deng, X. Cooperative computation offloading and resource allocation for delay minimization in mobile edge computing. J. Syst. Arch. 2021, 118, 102167. [Google Scholar] [CrossRef]
- Liao, Y.; Shou, L.; Yu, Q.; Ai, Q.; Liu, Q. Joint offloading decision and resource allocation for mobile edge computing enabled networks. Comput. Commun. 2020, 154, 361–369. [Google Scholar] [CrossRef]
- Pereira, R.S.; Lieira, D.D.; da Silva, M.A.C.; Pimenta, A.H.M.; da Costa, J.B.D.; Rosário, D.; Villas, L.; Meneguette, R.I. Reliable: Resource allocation mechanism for 5G network using mobile edge computing. Sensors 2020, 20, 5449. [Google Scholar] [CrossRef]
- Tong, Z.; Deng, X.; Ye, F.; Basodi, S.; Xiao, X.; Pan, Y. Adaptive computation offloading and resource allocation strategy in a mobile edge computing environment. Inf. Sci. 2020, 537, 116–131. [Google Scholar] [CrossRef]
- Ning, Z.; Sun, S.; Wang, X.; Guo, L.; Wang, G.; Gao, X.; Kwok, R.Y.K. Intelligent resource allocation in mobile blockchain for privacy and security transactions: A deep reinforcement learning based approach. Sci. China Inf. Sci. 2021, 64, 162303. [Google Scholar] [CrossRef]
- Yu, Z.; Xu, X.; Zhou, W. Task Offloading and Resource Allocation Strategy Based on Deep Learning for Mobile Edge Computing. Comput. Intell. Neurosci. 2022, 2022, 1427291. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Xue, K.; Tian, H.; Hong, J.; Wei, D.S.L.; Hong, P. An Identity Management and Authentication Scheme Based on Redactable Blockchain for Mobile Networks. IEEE Trans. Veh. Technol. 2020, 69, 6688–6698. [Google Scholar] [CrossRef]
- Li, J.; Yang, Z.; Wang, X.; Xia, Y.; Ni, S. Task offloading mechanism based on federated reinforcement learning in mobile edge computing. Digit. Commun. Netw. 2023, 9, 492–504. [Google Scholar] [CrossRef]
- Chaieb, M.; Ben Sassi, D. Measuring and evaluating the Home Health Care Scheduling Problem with Simultaneous Pick-up and Delivery with Time Window using a Tabu Search metaheuristic solution. Appl. Soft Comput. 2021, 113, 107957. [Google Scholar] [CrossRef]
- Amiri, M.; Mohammad-Khanli, L.; Mirandola, R. A sequential pattern mining model for application workload prediction in cloud environment. J. Netw. Comput. Appl. 2018, 105, 21–62. [Google Scholar] [CrossRef]
- Liang, Z.; Shu, T.; Ding, Z. A Novel Improved Whale Optimization Algorithm for Global Optimization and Engineering Applications. Mathematics 2024, 12, 636. [Google Scholar] [CrossRef]
- Dehghani, M.; Trojovský, P. Serval Optimization Algorithm: A New Bio-Inspired Approach for Solving Optimization Problems. Biomimetics 2022, 7, 204. [Google Scholar] [CrossRef]
- Pirani, M.; Thakkar, P.; Jivrani, P. A Comparative Analysis of ARIMA, GRU, LSTM and BiLSTM on Financial Time Series Forecasting. In Proceedings of the 2022 IEEE International Conference on Distributed Computing and Electrical, Ballari, India, 23–24 April 2022. [Google Scholar]
- Bhuvaneswaria, A.; Timothy Jones Thomasb, J.; Kesavanc, P. Embedded Bi-directional GRU and LSTMLearning Models to Predict Disasterson Twitter Data. In Proceedings of the International Conference on Recent Trends in Advanced Computing 2019, ICRTAC, Chennai, India, 11–12 November 2019. [Google Scholar]
- Wang, J.-B.; Yang, H.; Cheng, M.; Wang, J.-Y.; Lin, M.; Wang, J. Joint Optimization of Offloading and Resources Allocation in Secure Mobile Edge Computing Systems. IEEE Trans. Veh. Technol. 2020, 69, 8843–8854. [Google Scholar] [CrossRef]
- Mahenge, M.P.J.; Li, C.; Sanga, C.A. Energy-efficient task offloading strategy in mobile edge computing for resource-intensive mobile applications. Digit. Commun. Netw. 2022, 8, 1048–1058. [Google Scholar] [CrossRef]
- Elgendy, I.A.; Zhang, W.-Z.; Zeng, Y.; He, H.; Tian, Y.-C.; Yang, Y. Efficient and Secure Multi-User Multi-Task Computation Offloading for Mobile-Edge Computing in Mobile IoT Networks. IEEE Trans. Netw. Serv. Manag. 2020, 17, 2410–2422. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Pathirana, P.N.; Ding, M.; Seneviratne, A. Privacy-Preserved Task Offloading in Mobile Blockchain with Deep Reinforcement Learning. IEEE Trans. Netw. Serv. Manag. 2020, 17, 2536–2549. [Google Scholar] [CrossRef]
- Qi, P. Task Offloading and Scheduling Strategy for Intelligent Prosthesis in Mobile Edge Computing Environment. Wirel. Commun. Mob. Comput. 2022, 2022, 2890473. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Main Contributions | Weaknesses | Advantages |
|---|---|---|---|
| [16] | This study addressed the challenges of meeting user QoS requests, including improving the quality of user experience with the purpose of increasing the performance of user experience with mobile communication environments. | The research provides a consistent survey of approaches to secure computational offloading based on AI technology. | There is a significant lack of details concerning resource allocation strategies, and IoT was not properly mentioned in the literature. |
| [20] | This study presented a series of investigations of task-aware multi-unmanned aerial vehicle (UAV)-enabled MEC networks using RA- and DRL-based trajectory planning; there was an important focus on mobile system implementation. | The proposed system might design poor trajectories due to the massive space between ground devices. | The authors adopted the DDPG approach to design trajectories. Similarly, the particle swarm optimization (PSO) algorithm was used to carry out the RA procedure. This model had a completion time of 10 ms, which was considered high performance compared with the results obtained in recent works in the same context. This result showed the high feasibility and supremacy of the system. |
| [22] | This study proposed an approach using cooperative computation offloading and RA to reduce transmission delay in an MEC system. The structure of the design was based on minimizing the frequency of CPU cycles and transmission power. | The proposed method did not consider all of the EC factors in the CS implementation. | The adoption of a monotonic optimization method to minimize the transmission power and the integration of the Sheng Jin formula (SJF) to reduce the CPU cycle frequency were important contributions that minimized the latency and upgraded the RA. |
| [28] | This study introduced an identity management and authentication scheme for mobile systems based on blockchain technology; user authentication was ensured and secured using a public key and self-sovereign identities (SSIs) under blockchain monitoring. | The proposed technique took too much time to complete the validation process. | The model was adopted and generalized well to reduce network delay and storage space and allow good management of resource allocations. |
| Techniques/Makespan (ms) | Number of Tasks | ||||
|---|---|---|---|---|---|
| 100 | 200 | 300 | 400 | 500 | |
| Proposed HCD-KM | 2145 | 4123 | 6124 | 8245 | 10,227 |
| KM | 2867 | 4878 | 6713 | 8852 | 10,869 |
| PAM | 3446 | 5369 | 7423 | 9324 | 11,337 |
| BIRCH | 3845 | 5748 | 7812 | 9748 | 11,875 |
| FCM | 4428 | 6245 | 8354 | 10,278 | 12,434 |
| Methods | Privacy Preservation Rate (%) |
|---|---|
| Proposed: exponential EMD matrix based on k-Anonymization | 97 |
| KA | 94 |
| L-Diversity | 90 |
| T-Closeness | 87 |
| Randomization | 83 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sindi, A.O.N.; Si, P.; Li, Q. Secure Task Offloading and Resource Allocation Strategies in Mobile Applications Using Probit Mish-Gated Recurrent Unit and an Enhanced-Searching-Based Serval Optimization Algorithm. Electronics 2024, 13, 2462. https://doi.org/10.3390/electronics13132462
Sindi AON, Si P, Li Q. Secure Task Offloading and Resource Allocation Strategies in Mobile Applications Using Probit Mish-Gated Recurrent Unit and an Enhanced-Searching-Based Serval Optimization Algorithm. Electronics. 2024; 13(13):2462. https://doi.org/10.3390/electronics13132462
Chicago/Turabian StyleSindi, Ahmed Obaid N., Pengbo Si, and Qi Li. 2024. "Secure Task Offloading and Resource Allocation Strategies in Mobile Applications Using Probit Mish-Gated Recurrent Unit and an Enhanced-Searching-Based Serval Optimization Algorithm" Electronics 13, no. 13: 2462. https://doi.org/10.3390/electronics13132462
APA StyleSindi, A. O. N., Si, P., & Li, Q. (2024). Secure Task Offloading and Resource Allocation Strategies in Mobile Applications Using Probit Mish-Gated Recurrent Unit and an Enhanced-Searching-Based Serval Optimization Algorithm. Electronics, 13(13), 2462. https://doi.org/10.3390/electronics13132462