5.1. Model Prediction Result
In response to the question raised in RQ1, we compare our method with the baseline algorithms mentioned in
Section 4.3, using the F1-Score as the evaluation metric, as specified in
Section 4.2. For each experiment, we use one project as the target project and each of the other five projects as the source project, conducting single-source cross-project defect prediction experiments. The results of all single-source cross-project software defect predictions are presented in
Table 4. We used a bold font to indicate the best-case scenario for this cross-project prediction.
In all the comparison experiments, our proposed SDP-MTF method achieves the highest average F1-Score of 0.7061, which is on average 8% to 15.2% better than other algorithms. Meanwhile, in all but three cross-project pair experiments, “Lucene → Camel”, “Camel → Log4j” and “Xalan → Log4j”, SDP-MTF achieves the highest average F1-Score of 0.7061, which is 8% to 15.2% higher than other algorithms. SDP-MTF achieves the highest precision and F1-Score. Specifically, SDP-MTF improves F1-Score by up to 28.2% and 13.8% on average compared to the NNFilter algorithm; it improves F1-Score by up to 35.8% and 13.7% on average compared to the TCA+ algorithm; compared to the DBN algorithm, SDP-MTF improves F1-Score by up to 25.6% of F1-Score, with an average improvement of 15.2% of F1-Score; for AC-GAN, SDP-MTF improves up to 30.5% of F1-Score, with an average improvement of 8% of F1-Score, and the algorithm outperforms SDP-MTF on three project pairs, making it the best performing algorithm among the compared algorithms. Finally, CNN-THFL and BATM, similar to SDP-MTF, use the idea of combining statistical features with semantic features, and in terms of F1-Score, SDP-MTF improves 23.6% to CNN-THFL, with an average of 10.3%, and vs. BATM, SDP-MTF improves up to 30%, with an average of 5.6% on average.
Figure 4 shows the stability of each algorithm’s F1-Score on different target projects. We show the maximum, minimum, and median values of each algorithm’s F1-Score under different source projects when each project is the target project, as well as the stability of different algorithms in terms of IQR. The boxplots with different projects as target projects are separated by dashed lines, where the six different algorithms are distinguished by different colors. In this case,
Figure 4a shows the performance of the algorithms when the target project is Camel, Log4j and Lucene, while
Figure 4b demonstrates the case of the algorithms when the target project is Poi, Xalan and Xerces.
Combining the information from the above pictures, Camel has a large difference in F1-Score from the other projects, so in the subsequent discussion, we will focus on the cross-project pairs with the other projects as the target projects, and the reasons for the poor performance of Camel’s project will be discussed in the final analysis section. In the cross-project prediction except Camel, the SDP-MTF algorithm shows the best results with the smallest IQR, i.e., the best stability, and has the highest rankings on the majority of the project pairs, and the IQR is small on each target project, and the IQR for the F1-Score is 0.02, which is ranked the second best among all algorithms, and has a good stability and generalization ability.
For the other six comparative baseline algorithms. BATM, which uses two features with adversarial learning, was ranked second with an F1-Score of 0.6290. It is ranked fourth for stability with an IQR of 0.1082. And then is followed by AC-GAN, which employs the idea of adversarial learning, and is ranked third in terms of average F1-Score performance, while the algorithm is generally stable, with an IQR of 0.15 for the F1-Score, and is ranked fifth overall. The algorithm that ranked fourth in prediction effectiveness is CNN-THFL, an algorithm that also uses statistical features and semantic features of the code, and the algorithm has an IQR of 0.06, for the F1-Score, and ranks third in stability. The fifth and sixth-ranked algorithms are TCA+ and NNfilter which use coded statistical features and transfer learning of statistical features from the perspective of features and instances, respectively, and both perform poorly in terms of stability performance, with an IQR of 0.24 for the F1-Score of NNFliter, and 0.23 for the TCA+ algorithm, respectively. The final algorithm that performs poorly in our experiments is DBN which uses semantic features alone, with an IQR of 0.06, and ranked third in terms of stability. The algorithm that performed less well in our experiments was DBN with semantic features alone, with an average F1 value of 0.594, but this algorithm was the most stable with an IQR of 0.01 for the F1-Score.
The performance of the baseline algorithms also gives some useful information: first, the first and second-ranked algorithms are SDP-MTF and AC-GAN, while the DBN method using semantic features alone is slightly insufficient in terms of F1-Score, which side by side indicates that the semantic features need to be learned and processed further during the transfer process, and also need to be supplemented with deep transfer learning for cross-project coordination; second, the same as SDP- MTF also using the method BATM CNN-THFL that combines code statistical features and semantic features performs better than NNfilter, TCA+ algorithm that uses code statistical features alone and DBN algorithm that uses semantic features alone, which proves that the use of the combination of code statistical features and semantic features can improve the F1-Score and validates the motivation of our proposed method. We will discuss the project and algorithm effects in more depth in the subsequent analysis.
RQ1 Results: Our proposed SDP-MTF method outperformed the baseline algorithms in terms of F1-Score, ranking second in stability among all algorithms.
5.2. Impact of Fusion Features on the Experimental Model
This subsection develops ablation experiments for RQ2, aiming to explore whether our proposed feature fusion approach improves the effect of cross-project software defect prediction.
Table 5 shows the F1-Score of the algorithm for SDP-MTF versus the algorithm using a feature alone. SDP-MTF uses a combination of code statistical features and semantic features to fuse them into new features that mine more information within the project to improve the final prediction effect. We compare the performance of the algorithms SDP-DS (Deep-learning based Semantic Feature) using semantic features alone, SDP-CS (Code Statistic Feature) using code statistical features alone, and SDP-MTF with fused features through ablation experiments. The first two columns of the table represent the source and target projects, the third to last column is the F1-Score, and the last row represents the average performance of each algorithm.
It is easy to see that SDP-MTF using fused features outperforms SDP-DS using semantic features alone and SDP-CS using code statistical features alone, while comparing SDP-DS and SDP-CS, they perform similarly, with SDP-DS using only semantic features slightly outperforming SDP-CS using code statistical features alone. The average SDP-DS F1-Score using only semantic features is 0.6311, which is 7.4 percentage points lower than the SDP-MTF algorithm. The average F1-Score of the SDP-CS algorithm using code statistical features alone is 0.5990, which is 10.7 percentage points lower than the SDP-MTF algorithm using fused features. On the algorithm using code semantic and statistical features alone, the semantic features are slightly better but still have a large gap with the fusion features, which proves the effectiveness of the fusion features, and verifies that a single type of feature will lead to a lower effect, and also verifies our view that there is a need for complementary information between the two features.
The bars in
Figure 5 represent, from left to right, the fusion feature algorithm SDP-MTF, the semantic feature alone SDP-DS, and the code statistical feature alone SDP-CS. From the figure, we can see that the stability of SDP-MTF is better than that of SDP-DS with the semantic feature alone and SDP-CS with the code statistical feature alone. CS, with the smallest IQR, which we believe is related to the introduction of multiple types of features, compensates for the feature information while improving the generalization ability of the model. The four-digit scores of SDP-DS and SDP-CS are similarly spaced, specifically, the IQR of the SDP-DS F1-Score with semantic features only is 0.07, while the IQR of the SDP-CS with code statistical features only is 0.08.
From the comparison in RQ2, we can draw the following informative conclusion: the prediction effect using fused features is higher than the result of using a feature alone while keeping other experimental conditions constant. Meanwhile, our experiments also answer RQ2 that the use of fusion features can effectively improve the prediction effect of the model, and under the same experimental conditions, the prediction effect is better than the effect of the model that uses semantic features and code statistics features alone. Fusion features can be more effective in solving the problem of a single type of feature, and at the same time, the introduction of fusion features can make the feature information more comprehensive, effectively making up for the problem of insufficient feature information mining.
RQ2 Result: Our proposed method of using fusion features is effective and can significantly improve the prediction effect of cross-project defects when comparing the models using code statistical features alone and semantic features alone.
5.3. Impact of Feature Dimensions on Model Result
This subsection conducts experiments for RQ3 with the aim of exploring the impact of the dimension of the fusion features of SDP-MTF on the effect of the model. The fusion features we use consist of two parts, the coded statistical features with feature transfer and the AST-based semantic features, in this subsection, the generated dimensions of the semantic features are directly generated using Bi-LSTM control, whereas the dimensions of the statistical features are usually reduced or unchanged after feature transfer, and we will use a fully connected layer to control the length of the statistical features. We use Statistic to represent the code statistical features for the upper part of the fusion features, and Deep Semantic to represent the semantic features for the lower part of the fusion features and use the F1-Score as the judging metrics for this experiment.
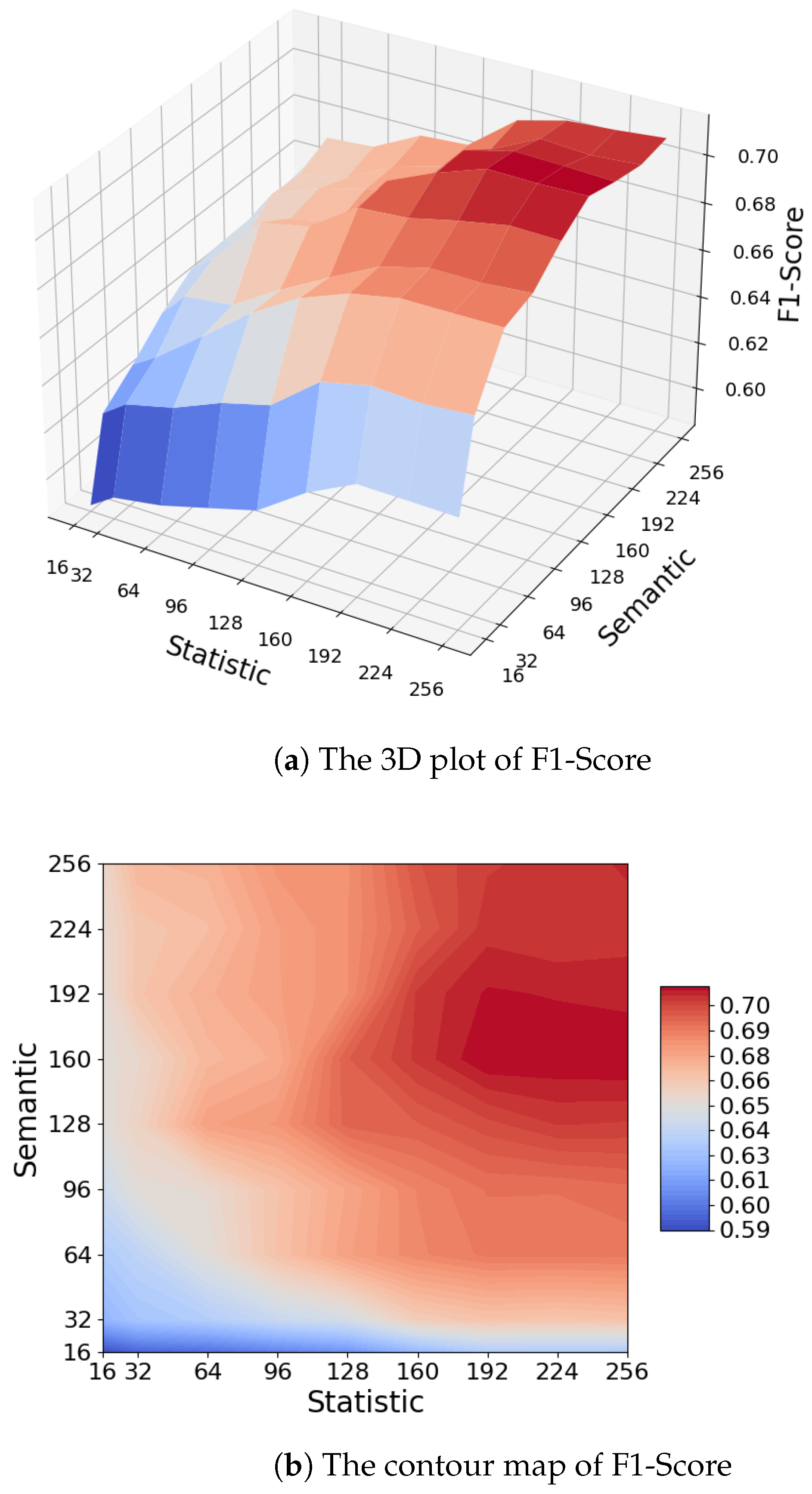
First, we make the two parts of the features to be generated using 16, 32, 64, 96, 128, 160, 192, 224 and 256 dimensions for all the data for the experiment.
Figure 6a,b are the 3D plots of the F1-Score of the SDP-MTF using different combinations of dimensions and the corresponding contour schematics.
The closer the color to red in
Figure 6 represents a higher F1-Score for that combination of dimensions, and the closer the color to blue indicates a lower F1-Score. We can see that the F1-Score of the model is low when the generated dimensions of both embeddings are low, and the F1-Score of the model starts to improve with the increase in feature dimensions, but when both embeddings are in high dimensions, the model dimensions gradually level off and no longer rise, and even have a tendency to fall. When the difference between the dimensions of the statistical feature dimension and the semantic feature is large, the model will tend to use the feature with a large dimension more for classification, resulting in the failure of the fusion feature, and the F1-Score tends to be closer to the performance of the feature alone. When the semantic feature dimension is low, Bi-LSTM cannot adequately capture the complexity of the utterance structure, leading to information loss, which affects the final task performance, so it is important to ensure the dimension of the semantic features, and it also restricts the statistical feature dimension not to differ too much from it. When the vector dimension is high, although the embedding vectors contain rich information, it may lead to overfitting, and also increase the computational complexity and memory requirements, which is the reason why the final F1-Score in
Figure 6 has leveled off or even decreased. The model achieved the best average results at 160 dimensions for statistical features and 192 dimensions for semantic features, so we chose this parameter for model prediction in subsequent experiments and other research questions.
Next, we will explore the effect of each of the two feature lengths on the model’s effectiveness. Since the best results of the model were obtained when the statistical features were 160 dimensions and the semantic features were 192 dimensions, we will control the dimension change in a single variable in the next experiments while setting the other vector dimension to the above dimensions as a way to ensure the validity and reliability of the experiments.
Figure 7 shows the performance of F1-Score of SDP-MTF on cross-project prediction when the dimension of a single vector is varied and the other vector is fixed to the nearest dimension, in which the red curve Statistic indicates the change in F1 value produced by the method when the dimension of the statistically based feature vectors is varied, in which case the dimension of the deep semantic vectors generated based on the Bi-LSTM is fixed at 192 dimensions; similarly, the gray Deep Semantic curve represents the change in the F1 value of the model caused by the change in the dimension of the semantic features, at which time the dimension of the statistical features is fixed to be unchanged at 160 dimensions. We can see that in all the experiments, the F1-Score of SDP-MTF is affected by the fusion feature dimensions, and the trend is that the F1-Score is lower in low dimensions, and as the vector dimensions increase, the F1-Score increases, and then tends to stabilize, and a smooth trend occurs after high dimensions. Among the two types of vectors, the model is more sensitive to changes in the dimension of the semantic features generated by Bi-LSTM, and the slopes of the folds are relatively larger.
Therefore, it can be concluded that the dimension size of the fused features has an effect on the final prediction results of the model, which is manifested in the fact that the F1-Score of the model firstly increases with the dimension of the two types of vectors, and then it tends to be stable or slightly fluctuates; therefore, the selection of appropriate generation dimension for the two types of vectors is necessary, and both types of vectors have an effect on the prediction results of the model. Meanwhile, the generating dimensions of 160 dimensions and 192 dimensions that we chose for the two features achieved the best results in our experiments, which also proved the effectiveness of our experiments.
RQ3 Results: The dimension of the fused features has an effect on the prediction effect of SDP-MTF, which is shown as follows: (1) when the dimension of the fused features is low, the prediction effect is low; (2) as the dimension of the fused features increases, the prediction effect appears to increase firstly and then stabilize; (3) when the dimension of the two vectors in the fused features has a large difference, the prediction effect tends to be the effect of the feature with larger dimension alone; (4) the model reaches the best result at 160 dimensions for the code statistical features and 192 dimensions for the semantic features, which is the final choice of the fusion feature dimension in our model.
5.4. Effectiveness of Multiple Transfer Learning
This subsection develops the ablation experiment for RQ4. This research question aims to investigate the effectiveness of multiple transfer learning methods for feature transfer and deep transfer learning, which refer to the method applied to statistical feature TCA+ and the method applied to deep adaptive neural networks with fused features, respectively.
Table 6 shows the effect and F1-Score performance of the algorithmic model.
We set up the following ablation experiments: SDP-ND (Non-Domain Adaptation based), which uses fusion features generated by feature transfer but does not use a domain adaptation layer, SDP-NT (Non-TCA+ based), which is a method that uses the domain adaptation idea but does not use TCA+ for the code statistics features in the fusion features, and the original model SDP-MTF, i.e., the method that uses the multiple transfer learning idea.
From the table, we can learn that the SDP-MTF algorithm effectively improves the F1-Score using the transfer learning idea, which confirms the effectiveness of our proposed multiple transfer idea. In addition to this, the method SDP-NT without TCA+ outperforms the SDP-ND method without a domain adaptation layer. The SDP-NT method achieves an F1-Score of 0.6087, which is a 9.7% percentage difference compared to the SDP-MTF method; whereas, the SDP-ND method performs poorly in cross-project prediction due to the lack of a domain adaptation layer, with an average F1-Score of 0.5191, which is lower than the SDP-MTF method by 18.7%. This validates the need for transfer learning and the effectiveness of multiple transfer learning.
Figure 8 shows the stability effect of different algorithms. From left to right in the figure are SDP-MTF, SDP-ND without Domain Adaptation Layer and SDP-NT without TCA+. In terms of stability, SDP-UT has a similar IQR as SDP-MTF, with an IQR of 0.03 for the F1-Score, which indicates that both have similar generalization-ability and both have good stability. While the stability of SDP-UD is poorer, the IQR is 0.14, respectively, and the data fluctuate more. The comparison of the three suggests that multiple migration learning does not have a large impact on the fluctuation of the prediction effect.
We can infer the following information from this experiment: first, the idea of multiple transfer learning used by the method is effective, and our SDP-MTF method shows sufficient advantages, whether comparing algorithms that do not use the domain adaptation layer or methods that do not use feature transfer learning. Second, in terms of the stability of the algorithm, the use of multiple transfer learning does not cause large fluctuations in the predictors. Finally, the domain adaptation layer of deep transfer learning can effectively improve the prediction effect using semantic features and is an effective deep transfer method.
RQ4 Results: The idea of transfer learning method with deep adaptive neural network and multiple transfer learning with feature transfer that we use is effective, and under the same experimental conditions, SDP-MTF shows advantages in F1-Score over the algorithm without feature transfer and without domain adaptation layer, which improves the prediction.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}