
A Robust Pointer Meter Reading Recognition Method Based on TransUNet and Perspective Transformation Correction




Abstract
1. Introduction
- (i)
- This paper presents a novel pointer meter reading framework for substation inspection robots that is robust to image distortion and various illumination conditions.
- (ii)
- To eliminate the negative effects of image distortion or rotation, we propose a novel and effective dial correction method based on perspective transformation.
- (iii)
- To enhance dial information extraction under various illumination conditions, we propose an efficient dial segmentation approach that employs the Gamma correction technique for preprocessing, followed by the TransUNet segmentation network.
2. Related Works
2.1. Dail Detection
2.2. Dial Information Segmentation
2.3. Dial Correction
2.4. Reading Recognition
3. Methods
3.1. Dial Detection Module Based on YOLOv8
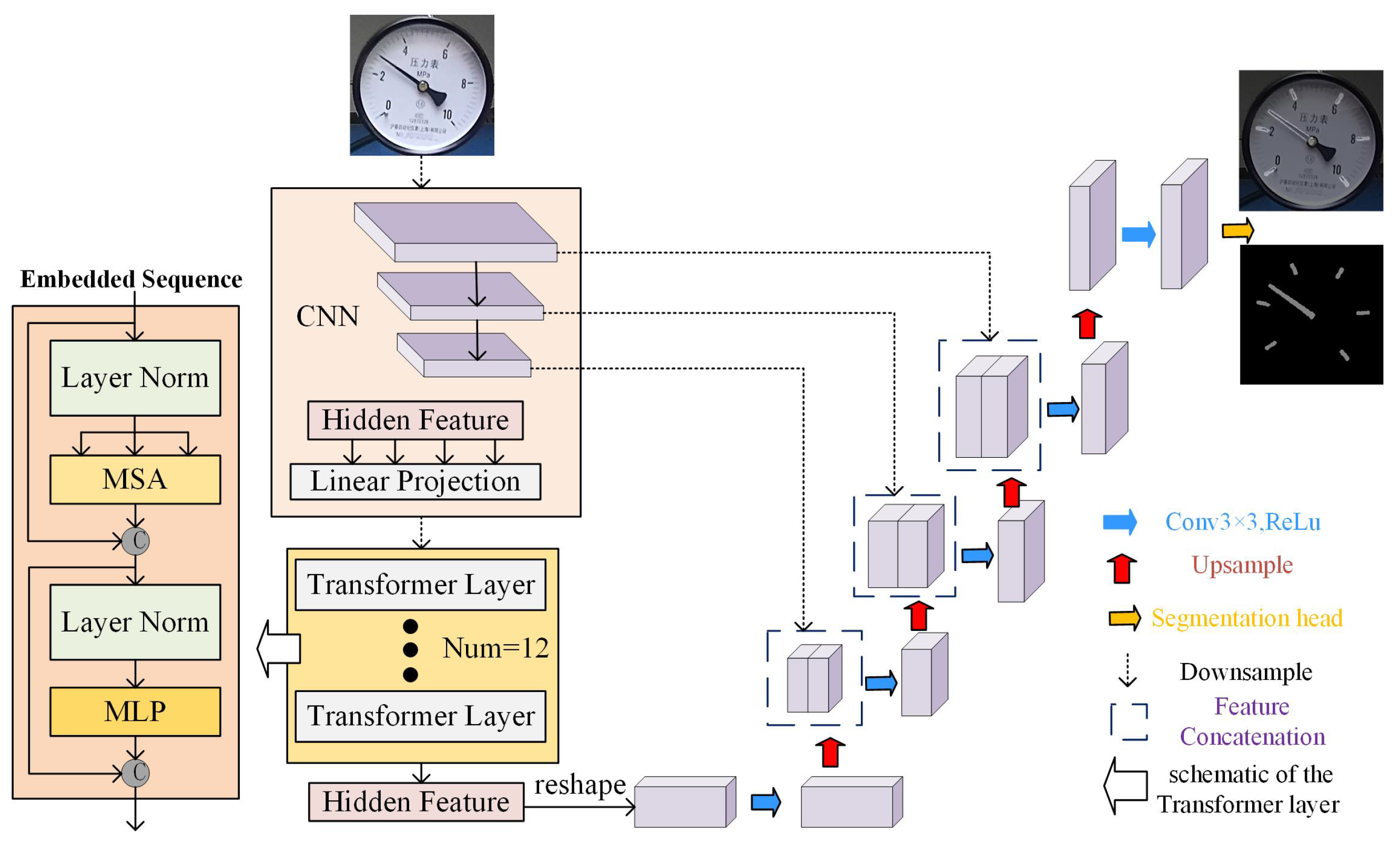
3.2. Dial Information Segmentation Module Based on TransUNet
3.2.1. Dial Image Enhancement
- (a)
- Calculate the mean value of the pixels of the luminance channel after normalization as a representative value of the luminance of the dial image.
- (b)
- Determine the value of .
- (c)
- Obtain the automatic Gamma correction.
3.2.2. Dial Information Segmentation
3.3. Key Point Fitting and Dial Correction Module
- (a)
- Key point fitting.
- (b)
- Key point matching.
- (c)
- Key point calculation in the front view.
- (d)
- Perspective matrix calculation.
3.4. Reading Recognition Module
3.4.1. Scale Values and Unit Information Recognition Based on PP-OCRv3
3.4.2. Reading Based on the WAM
4. Experiment
4.1. Experimental Details
4.1.1. Experimental Platform
4.1.2. Experimental Datasets
4.2. Ablative Experiments
4.2.1. Dial Detection Module Testing
4.2.2. Dial Information Extraction Module Testing
4.2.3. Dial Correction and Reading Module Testing
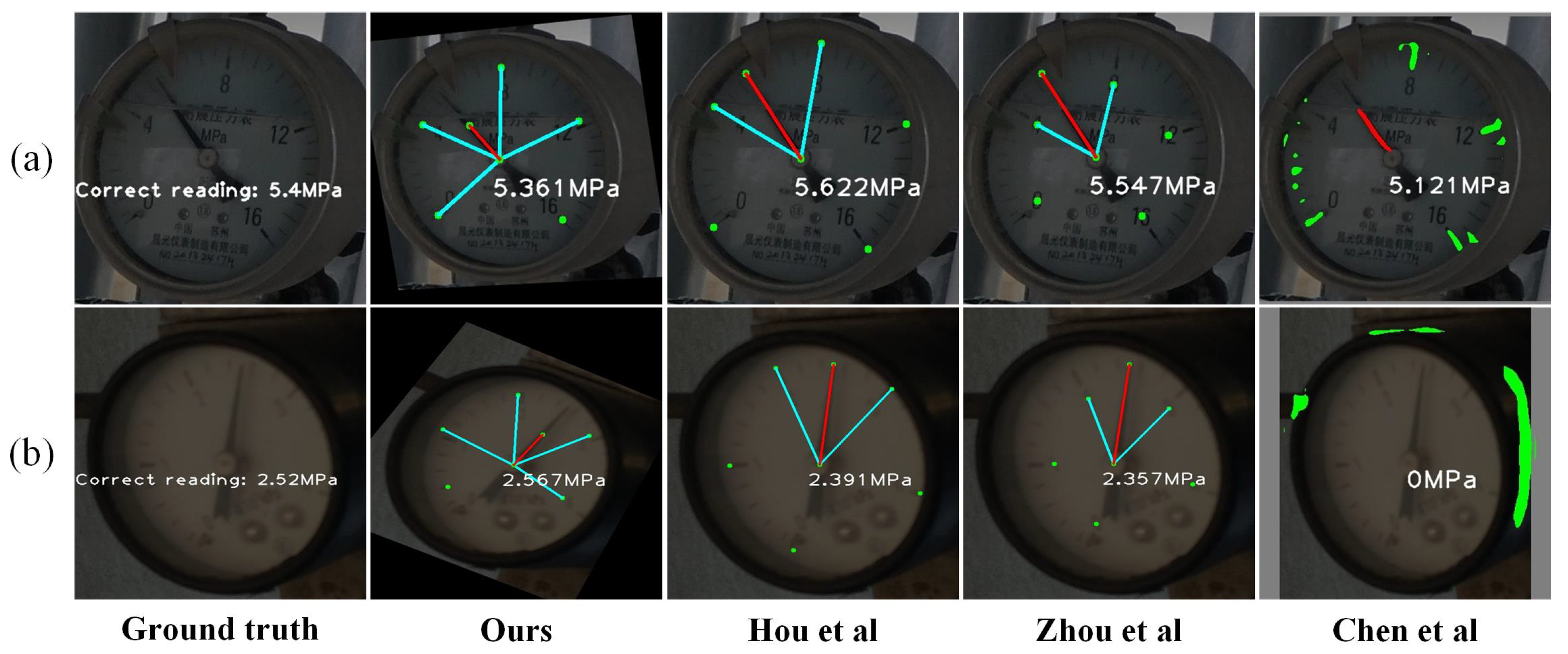
4.3. Comparative Experiments
- (a)
- Chen et al. [1] introduced the YOLOv5-U2Net-PCT algorithm, which integrates YOLOv5 for dial detection with U2Net for extracting dial information. The dial image undergoes a perspective transformation correction based on the perimeter length of the rectangle enclosing the dial. Additionally, a polar coordinate dimensionality reduction reading (PCT) method is employed to accurately calculate the meter reading.
- (b)
- Zhou et al. [2] proposed the YOLOv5-based algorithm. YOLOv5 is used to detect dials and extract dial information. The half-pointer method fits the pointer’s linear equation. The angle method calculates readings based on the scale values on either side of the pointer.
- (c)
- Hou et al. [3] proposed the YOLOX-Unet algorithm. It uses YOLOX to locate the dial and Unet to segment the dial information. The dial is corrected from an elliptical shape to a circular shape through the application of perspective transformation. The angle method calculates readings based on the scale values on either side of the pointer.
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, L.; Wu, X.; Sun, C.; Zou, T.; Meng, K.; Lou, P. An intelligent vision recognition method based on deep learning for pointer meters. Meas. Sci. Technol. 2023, 34, 055410. [Google Scholar] [CrossRef]
- Zhou, D.; Yang, Y.; Zhu, J.; Wang, K. Intelligent reading recognition method of a pointer meter based on deep learning in a real environment. Meas. Sci. Technol. 2022, 33, 055021. [Google Scholar] [CrossRef]
- Hou, L.; Wang, S.; Sun, X.; Mao, G. A pointer meter reading recognition method based on YOLOX and semantic segmentation technology. Measurement 2023, 218, 113241. [Google Scholar] [CrossRef]
- Zuo, L.; He, P.; Zhang, C.; Zhang, Z. A robust approach to reading recognition of pointer meters based on improved mask-RCNN. Neurocomputing 2020, 388, 90–101. [Google Scholar] [CrossRef]
- Ma, Y.; Jiang, Q. A robust and high-precision automatic reading algorithm of pointer meters based on machine vision. Meas. Sci. Technol. 2018, 30, 015401. [Google Scholar] [CrossRef]
- Xu, S.; Hou, C.; Wang, Z.; Li, B. Pointer gauge adaptive reading method based on a double match. Meas. Sci. Technol. 2020, 31, 115002. [Google Scholar] [CrossRef]
- Yang, Z.; Niu, W.; Peng, X.; Gao, Y.; Qiao, Y.; Dai, Y. An image-based intelligent system for pointer instrument reading. In Proceedings of the 2014 4th IEEE International Conference on Information Science and Technology, Shenzhen, China, 26–28 April 2014; pp. 780–783. [Google Scholar]
- Peng, G.; Du, B.; Cao, C.; He, D. Pointer-type instrument positioning method of intelligent inspection system for substation. J. Electron. Imaging 2022, 31, 013001. [Google Scholar] [CrossRef]
- Reis, D.; Kupec, J.; Hong, J.; Daoudi, A. Real-time flying object detection with YOLOv8. arXiv 2023, arXiv:2305.09972. [Google Scholar]
- Babakhani, P.; Zarei, P. Automatic gamma correction based on average of brightness. Adv. Comput. Sci. Int. J. 2015, 4, 156–159. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Li, C.; Liu, W.; Guo, R.; Yin, X.; Jiang, K.; Du, Y.; Du, Y.; Zhu, L.; Lai, B.; Hu, X.; et al. PP-OCRv3: More attempts for the improvement of ultra lightweight OCR system. arXiv 2022, arXiv:2206.03001. [Google Scholar]
- Ji, D.; Zhang, W.; Zhao, Q.; Yang, W. Correction and pointer reading recognition of circular pointer meter. Meas. Sci. Technol. 2022, 34, 025406. [Google Scholar] [CrossRef]
- Guo, X.; Zhu, Y.; Zhang, J.; Hai, Y.; Ma, X.; Lv, C.; Liu, S. Intelligent pointer meter interconnection solution for data collection in farmlands. Comput. Electron. Agric. 2021, 182, 105985. [Google Scholar] [CrossRef]
- Gao, J.; Guo, L.; Lv, Y.; Wu, Q.; Mu, D. Research on algorithm of pointer instrument recognition and reading based on the location of the rotation center of the pointer. In Proceedings of the 2018 IEEE International Conference on Mechatronics and Automation (ICMA), Changchun, China, 5–8 August 2018; pp. 1405–1410. [Google Scholar]
- Liu, Y.; Liu, J.; Ke, Y. A detection and recognition system of pointer meters in substations based on computer vision. Measurement 2020, 152, 107333. [Google Scholar] [CrossRef]
- Sun, J.; Huang, Z.; Zhang, Y. A novel automatic reading method of pointer meters based on deep learning. Neural Comput. Appl. 2023, 35, 8357–8370. [Google Scholar] [CrossRef]
- Wu, Y.; Liao, T.; Chen, F.; Zeng, H.; Ouyang, S.; Guan, J. Overhead Power Line Damage Detection: An Innovative Approach Using Enhanced YOLOv8. Electronics 2024, 13, 739. [Google Scholar] [CrossRef]
- Wang, F.; Wang, G.; Lu, B. YOLOv8-PoseBoost: Advancements in Multimodal Robot Pose Keypoint Detection. Electronics 2024, 13, 1046. [Google Scholar] [CrossRef]
- Alegria, E.C.; Serra, A.C. Automatic calibration of analog and digital measuring instruments using computer vision. IEEE Trans. Instrum. Meas. 2000, 49, 94–99. [Google Scholar] [CrossRef]
- Alegria, F.C.; Serra, A.C. Computer vision applied to the automatic calibration of measuring instruments. Measurement 2000, 28, 185–195. [Google Scholar] [CrossRef]
- Chi, J.; Liu, L.; Liu, J.; Jiang, Z.; Zhang, G. Machine vision based automatic detection method of indicating values of a pointer gauge. Math. Probl. Eng. 2015, 2015, 283629. [Google Scholar] [CrossRef]
- Hou, L.; Qu, H. Automatic recognition system of pointer meters based on lightweight CNN and WSNs with on-sensor image processing. Measurement 2021, 183, 109819. [Google Scholar] [CrossRef]
- Zhang, C.; Shi, L.; Zhang, D.; Ke, T.; Li, J. Pointer meter recognition method based on Yolov7 and hough transform. Appl. Sci. 2023, 13, 8722. [Google Scholar] [CrossRef]
- Hou, Z.; Ouyang, H.; Hu, X. Tilt correction method of pointer instrument. In Proceedings of the 2021 China Automation Congress (CAC), Beijing, China, 22–24 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 608–612. [Google Scholar]
- Li, Z.; Zhou, Y.; Sheng, Q.; Chen, K.; Huang, J. A high-robust automatic reading algorithm of pointer meters based on text detection. Sensors 2020, 20, 5946. [Google Scholar] [CrossRef]
- Huo, Y.; Bai, H.; Sun, L.; Fang, Y. Reading recognition of pointer meters based on an improved UNet++ network. Meas. Sci. Technol. 2023, 35, 035009. [Google Scholar] [CrossRef]
- Zhang, H.; Chen, Q.; Lei, L. A YOLOv3-Based Industrial Instrument Classification and Reading Recognition Method. Mob. Inf. Syst. 2022, 2022, 7817309. [Google Scholar] [CrossRef]
- Zhang, W.; Ji, D.; Yang, W.; Zhao, Q.; Yang, L.; Zhuoma, C. Application of Swin-Unet for pointer detection and automatic calculation of readings in pointer-type meters. Meas. Sci. Technol. 2023, 35, 025904. [Google Scholar] [CrossRef]
- Du, Y.; Li, C.; Guo, R.; Cui, C.; Liu, W.; Zhou, J.; Lu, B.; Yang, Y.; Liu, Q.; Hu, X.; et al. Pp-ocrv2: Bag of tricks for ultra lightweight ocr system. arXiv 2021, arXiv:2109.03144. [Google Scholar]
- Du, Y.; Chen, Z.; Jia, C.; Yin, X.; Zheng, T.; Li, C.; Du, Y.; Jiang, Y.G. Svtr: Scene text recognition with a single visual model. arXiv 2022, arXiv:2205.00159. [Google Scholar]
- Cui, C.; Gao, T.; Wei, S.; Du, Y.; Guo, R.; Dong, S.; Lu, B.; Zhou, Y.; Lv, X.; Liu, Q.; et al. PP-LCNet: A lightweight CPU convolutional neural network. arXiv 2021, arXiv:2109.15099. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; proceedings, part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Type |
|---|---|
| Operating system | Windows 11 64-bit |
| Graphics card | RTX-3050Ti |
| Memory | 16 G |
| CPU | AMD Ryzen 5 5600H |
| Dataset | Resolution | Brightness | Degree of Distortion |
|---|---|---|---|
| Simple-MeterData | High | Mostly good | Low |
| Complex-MeterData | Low | Low | High |
| Model | mIoU | mPA | Acc |
|---|---|---|---|
| PSPNet [33] | 74.95 | 83.28 | 98.98 |
| DeepLabv3+ [34] | 85.86 | 92.66 | 99.46 |
| Unet [35] | 87.88 | 93.33 | 99.55 |
| TransUNet | 86.12 | 94.75 | 99.58 |
| Reading | (%) | (%) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| No | Real | (1) | (2) | (3) | Ours | (1) | (2) | (3) | Ours | (1) | (2) | (3) | Ours |
| a | 1.12 | 1.191 | 1.108 | 1.108 | 1.108 | 6.339 | 1.071 | 1.071 | 1.071 | 4.4375 | 0.75 | 0.75 | 0.75 |
| b | 6.15 | 6.233 | 6.212 | 6.175 | 6.175 | 1.35 | 1.008 | 0.407 | 0.407 | 0.332 | 0.248 | 0.1 | 0.1 |
| c | 1.11 | 1.098 | 1.101 | 1.105 | 1.118 | 1.081 | 0.811 | 0.45 | 0.721 | 0.75 | 0.5625 | 0.3125 | 0.5 |
| d | 6.23 | 6.153 | 6.161 | 6.177 | 6.242 | 1.236 | 1.108 | 0.851 | 0.193 | 0.308 | 0.276 | 0.212 | 0.048 |
| e | 1.10 | 1.152 | 1.100 | 1.108 | 1.095 | 4.727 | 0.909 | 0.727 | 0.455 | 3.25 | 0.625 | 0.5 | 0.3125 |
| f | 1.11 | 1.156 | 1.121 | 1.128 | 1.109 | 4.144 | 0.991 | 1.622 | 0.09 | 2.875 | 0.6875 | 1.125 | 0.0625 |
| g | 1.10 | 0.998 | 1.093 | 1.108 | 1.109 | 9.273 | 0.636 | 0.727 | 0.818 | 6.375 | 0.4375 | 0.5 | 0.5625 |
| h | 2.80 | 2.823 | 2.774 | 2.844 | 2.812 | 0.821 | 0.929 | 1.571 | 0.429 | 0.23 | 0.26 | 0.44 | 0.12 |
| i | 6.24 | 6.312 | 6.235 | 6.234 | 6.252 | 1.154 | 0.08 | 0.096 | 0.192 | 0.288 | 0.02 | 0.024 | 0.048 |
| j | 6.25 | 6.254 | 6.278 | 6.355 | 6.372 | 0.064 | 0.448 | 1.68 | 1.952 | 0.016 | 0.112 | 0.42 | 0.488 |
| k | 1.10 | 1.158 | 1.134 | 1.127 | 1.103 | 5.273 | 3.091 | 2.455 | 0.273 | 3.625 | 2.125 | 1.6875 | 0.1875 |
| 1 | 2.79 | 2.852 | 2.831 | 2.811 | 2.792 | 2.222 | 1.47 | 0.00 | 0.072 | 0.62 | 0.41 | 0.00 | 0.02 |
| Avg | - | - | - | - | - | 3.14 | 1.046 | 0.971 | 0.556 | 1.926 | 0.543 | 0.506 | 0.267 |
| Reading | (%) | (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| No | Real | A | P + A | P + WAM | A | P + A | P + WAM | A | P + A | P + WAM |
| a | 2.80 | 2.81 | 2.817 | 2.783 | 0.36 | 0.61 | 0.61 | 0.10 | 0.17 | 0.17 |
| b | 2.81 | 2.839 | 2.815 | 2.807 | 1.03 | 0.18 | 0.11 | 0.29 | 0.05 | 0.03 |
| c | 1.10 | 1.115 | 1.098 | 1.112 | 1.36 | 0.18 | 1.09 | 0.94 | 0.13 | 0.75 |
| d | 6.20 | 6.292 | 6.264 | 6.221 | 1.48 | 1.03 | 0.34 | 0.37 | 0.26 | 0.08 |
| e | 2.78 | 2.797 | 2.789 | 2.782 | 0.61 | 0.32 | 0.07 | 0.17 | 0.09 | 0.02 |
| f | 6.10 | 6.237 | 6.364 | 6.179 | 2.25 | 4.33 | 1.3 | 0.55 | 1.06 | 0.32 |
| g | 6.20 | 6.259 | 6.196 | 6.195 | 0.95 | 0.07 | 0.08 | 0.24 | 0.02 | 0.02 |
| h | 0.62 | 0.617 | 0.619 | 0.615 | 0.48 | 0.16 | 0.81 | 0.19 | 0.06 | 0.31 |
| i | 0.64 | 0.631 | 0.631 | 0.641 | 1.41 | 1.41 | 0.16 | 0.56 | 0.56 | 0.06 |
| j | 6.25 | 6.259 | 6.245 | 6.209 | 0.14 | 0.08 | 0.66 | 0.04 | 0.02 | 0.16 |
| k | 0.63 | 0.618 | 0.63 | 0.63 | 1.91 | 0.00 | 0.00 | 0.75 | 0.00 | 0.00 |
| 1 | 2.80 | 2.832 | 2.827 | 2.811 | 1.14 | 0.96 | 0.39 | 0.32 | 0.27 | 0.11 |
| Avg | - | - | - | - | 1.09 | 0.78 | 0.47 | 0.38 | 0.22 | 0.17 |
| Methods | Extraction of Dial Information | Correction | Reading |
|---|---|---|---|
| Chen et al. [1] | U2Net | ✓ | PCT |
| Zhou et al. [2] | YOLOv5 | ✕ | Proximate angle |
| Hou et al. [3] | Unet | ✓ | Proximate angle |
| Ours | TransUNet | ✓ | WAM |
| Methods | Accuracy (%) | (%) | (%) |
|---|---|---|---|
| Chen et al. [1] | 91.12 | 8.88 | 8.24 |
| Zhou et al. [2] | 94.76 | 5.24 | 1.76 |
| Hou et al. [3] | 96.83 | 3.17 | 1.18 |
| Ours | 97.81 | 2.19 | 1.04 |
| Methods | Accuracy (%) | (%) | (%) |
|---|---|---|---|
| Chen et al. [1] | 86.97 | 13.03 | 2.61 |
| Zhou et al. [2] | 87.38 | 12.26 | 1.87 |
| Hou et al. [3] | 88.24 | 11.76 | 2.29 |
| Ours | 93.39 | 6.61 | 1.49 |
| Methods | Detection (s) | Extraction of Dial Information (s) | Correction (s) | Reading (s) | In Total (s) |
|---|---|---|---|---|---|
| Chen et al. [1] | 0.03 | 1.05 | 0.01 | 1.28 | 2.37 |
| Zhou et al. [2] | 0.03 | 0.07 | 0 | 0.01 | 0.11 |
| Hou et al. [3] | 0.03 | 0.15 | 0.34 | 0.01 | 0.53 |
| Ours | 0.03 | 0.17 | 0.01 | 0.01 + 2.36 (OCR) | 2.58 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, L.; Wu, W.; Ding, J.; Ye, W.; Li, C.; Liang, Q. A Robust Pointer Meter Reading Recognition Method Based on TransUNet and Perspective Transformation Correction. Electronics 2024, 13, 2436. https://doi.org/10.3390/electronics13132436
Tan L, Wu W, Ding J, Ye W, Li C, Liang Q. A Robust Pointer Meter Reading Recognition Method Based on TransUNet and Perspective Transformation Correction. Electronics. 2024; 13(13):2436. https://doi.org/10.3390/electronics13132436
Chicago/Turabian StyleTan, Liufan, Wanneng Wu, Jinxin Ding, Weihao Ye, Cheng Li, and Qiaokang Liang. 2024. "A Robust Pointer Meter Reading Recognition Method Based on TransUNet and Perspective Transformation Correction" Electronics 13, no. 13: 2436. https://doi.org/10.3390/electronics13132436
APA StyleTan, L., Wu, W., Ding, J., Ye, W., Li, C., & Liang, Q. (2024). A Robust Pointer Meter Reading Recognition Method Based on TransUNet and Perspective Transformation Correction. Electronics, 13(13), 2436. https://doi.org/10.3390/electronics13132436