
Automatic Classification of Defective Solar Panels in Electroluminescence Images Based on Random Connection Network



Abstract
1. Introduction
2. Materials and Methods
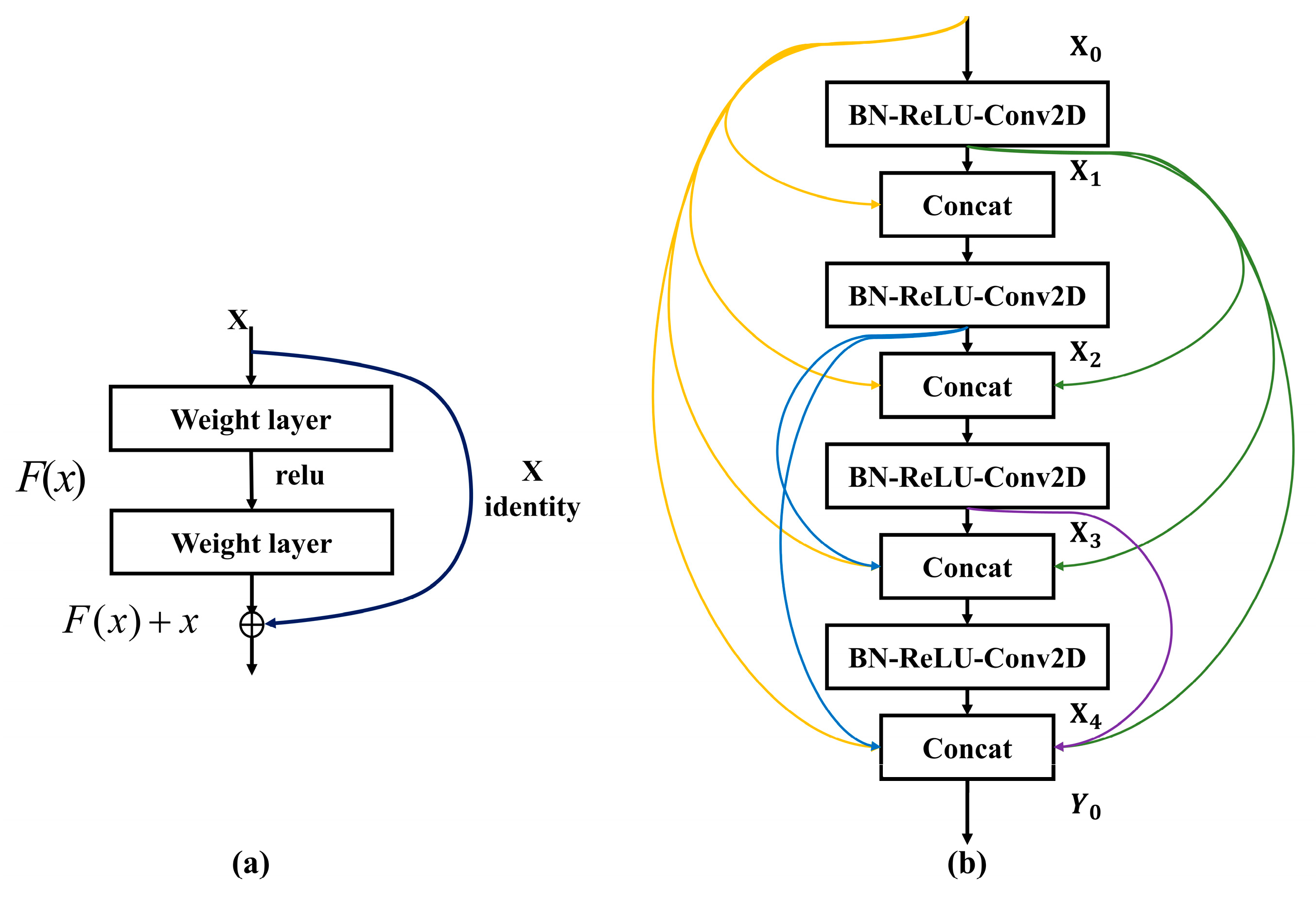
2.1. Proposed Model
2.2. Data Enhancement Model
3. Experiments
3.1. Experimental Configuration
3.2. Data Enhancement
3.3. Evaluation Indicator
3.4. Evaluation Criteria
3.5. Results Analysis and Discussion
4. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhu, H.; Yan, W.; Liu, Y.; Hu, D.; Tu, Y.; Huang, Z.; Tan, X. Design investigation on 100 μm-thickness thin silicon PERC solar cells with assistance of machine learning. Mater. Sci. Semicond. Process. 2022, 137, 106198. [Google Scholar] [CrossRef]
- Li, P.; Cao, Q.; Li, J.; Wang, Y.; Pei, G.; Gao, C.; Zhao, H.; Liu, X. Effect of regenerator on the direct steam generation solar power system characterized by prolonged thermal storage and stable power conversion. Renew. Energy 2020, 159, 1099–1116. [Google Scholar] [CrossRef]
- Dao, V.A.; Kim, S.; Lee, Y.; Kim, S.; Park, J.; Ahn, S.; Yi, J. High-efficiency heterojunction with intrinsic thin-layer solar cells: A review. Curr. Photovolt. Res. 2013, 1, 73–81. [Google Scholar]
- Feldmann, F.; Bivour, M.; Reichel, C.; Steinkemper, H.; Hermle, M.; Glunz, S.W. Tunnel oxide passivated contacts as an alternative to partial rear contacts. Sol. Energy Mater. Sol. Cells 2014, 131, 46–50. [Google Scholar] [CrossRef]
- Clement, F.; Menkoe, M.; Kubera, T.; Harmel, C.; Hoenig, R.; Wolke, W.; Wirth, H.; Biro, D.; Preu, R. Industrially feasible multi-crystalline metal wrap through (MWT) silicon solar cells exceeding 16% efficiency. Sol. Energy Mater. Sol. Cells 2009, 93, 1051–1055. [Google Scholar] [CrossRef]
- Verlinden, P. Backside-contact silicon solar cells with improved efficiency for the ’96 world solar challenge. Proc. 15th EU-PVSEC 1997. Available online: https://cir.nii.ac.jp/crid/1570854176739872768 (accessed on 18 June 2024).
- Dehzangi, A.; Larki, F.; Majlis, B.Y.; Naseri, M.G.; Navasery, M.; Abdullah, A.M.; Hutagalung, S.D.; Hamid, N.A.; Noor, M.M.; Vakilian, M. Impact of KOH etching on nanostructure fabricated by local anodic oxidation method. Int. J. Electrochem. Sci. 2013, 8, 8084–8096. [Google Scholar] [CrossRef]
- Rajput, A.S.; Ho, J.W.; Zhang, Y.; Nalluri, S.; Aberle, A.G. Quantitative estimation of electrical performance parameters of individual solar cells in silicon photovoltaic modules using electroluminescence imaging. Sol. Energy 2018, 173, 201–208. [Google Scholar] [CrossRef]
- Karimi, A.M.; Fada, J.S.; Hossain, M.A.; Yang, S.; Peshek, T.J.; Braid, J.L.; French, R.H. Automated pipeline for photovoltaic module electroluminescence image processing and degradation feature classification. IEEE J. Photovolt. 2019, 9, 1324–1335. [Google Scholar] [CrossRef]
- Ji, S.; Jia, Y.; Yang, X.; Liu, Z.; Zhu, L. A method for measuring electric field distribution along insulator surfaces based on electroluminescence effect and its image processing algorithm. IEEE Trans. Dielectr. Electr. Insul. 2022, 29, 939–947. [Google Scholar] [CrossRef]
- Fioresi, J.; Colvin, D.J.; Frota, R.; Gupta, R.; Li, M.; Seigneur, H.P.; Vyas, S.; Oliveira, S.; Shah, M.; Davis, K.O. Automated defect detection and localization in photovoltaic cells using semantic segmentation of electroluminescence images. IEEE J. Photovolt. 2021, 12, 53–61. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. arXiv 2019, arXiv:1912.0170332. [Google Scholar] [CrossRef]
- Chetlur, S.; Woolley, C.; Vandermersch, P.; Cohen, J.; Tran, J.; Catanzaro, B.; Shelhamer, E. cudnn: Efficient primitives for deep learning. arXiv 2014, arXiv:1410.0759. [Google Scholar] [CrossRef]
- Zeng, N.; Wang, Z.; Zineddin, B.; Li, Y.; Du, M.; Xiao, L.; Liu, X.; Young, T. Image-based quantitative analysis of gold immunochromatographic strip via cellular neural network approach. IEEE Trans. Med. Imaging 2014, 33, 1129–1136. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. arXiv 2016, arXiv:1605.06409v3. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Hussain, T.; Hussain, M.; Al-Aqrabi, H.; Alsboui, T.; Hill, R. A review on defect detection of electroluminescence-based photovoltaic cell surface images using computer vision. Energies 2023, 16, 4012. [Google Scholar] [CrossRef]
- Zhao, X.; Song, C.; Zhang, H.; Sun, X.; Zhao, J. HRNet-based automatic identification of photovoltaic module defects using electroluminescence images. Energy 2023, 267, 126605. [Google Scholar] [CrossRef]
- Korovin, A.; Vasilev, A.; Egorov, F.; Saykin, D.; Terukov, E.; Shakhray, I.; Zhukov, L.; Budennyy, S. Anomaly detection in electroluminescence images of heterojunction solar cells. Sol. Energy 2023, 259, 130–136. [Google Scholar] [CrossRef]
- Xie, X.; Lai, G.; You, M.; Liang, J.; Leng, B. Effective transfer learning of defect detection for photovoltaic module cells in electroluminescence images. Sol. Energy 2023, 250, 312–323. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, X.; Wei, H.; Zhang, K. A lightweight network for photovoltaic cell defect detection in electroluminescence images based on neural architecture search and knowledge distillation. Appl. Energy 2024, 355, 122184. [Google Scholar] [CrossRef]
- Zhou, W.; Wang, H.; Wan, Z. Ore image classification based on improved CNN. Comput. Electr. Eng. 2022, 99, 107819. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Feng, Q.; Li, F.; Li, H.; Liu, X.; Fei, J.; Xu, S.; Lu, C.; Yang, Q. Feature reused network: A fast segmentation network model for strip steel surfaces defects based on feature reused. Vis. Comput. 2024, 40, 3633–3648. [Google Scholar] [CrossRef]
- Souaidi, M.; Lafraxo, S.; Kerkaou, Z.; El Ansari, M.; Koutti, L. A multiscale polyp detection approach for gi tract images based on improved densenet and single-shot multibox detector. Diagnostics 2023, 13, 733. [Google Scholar] [CrossRef]
- Xie, S.; Kirillov, A.; Girshick, R.; He, K. Exploring randomly wired neural networks for image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1284–1293. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar] [CrossRef]
- Sun, W.; Zhang, X.; He, X. Lightweight image classifier using dilated and depthwise separable convolutions. J. Cloud Comput. 2020, 9, 55. [Google Scholar] [CrossRef]
- Sharma, A.K.; Rana, A.; Kim, K.K. Lightweight image classifier for CIFAR-10. J. Sens. Sci. Technol. 2021, 30, 286–289. [Google Scholar] [CrossRef]
- Deitsch, S.; Christlein, V.; Berger, S.; Buerhop-Lutz, C.; Maier, A.; Gallwitz, F.; Riess, C. Automatic classification of defective photovoltaic module cells in electroluminescence images. Sol. Energy 2019, 185, 455–468. [Google Scholar] [CrossRef]
- Akram, M.W.; Li, G.; Jin, Y.; Chen, X.; Zhu, C.; Zhao, X.; Khaliq, A.; Faheem, M.; Ahmad, A. CNN based automatic detection of photovoltaic cell defects in electroluminescence images. Energy 2019, 189, 116319. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Name | Activations |
|---|---|
| Input layer | 224 × 224 × 3 |
| Convolution | 7 × 7, 64, /2 |
| Batch normalization | 112 × 112, 64 |
| Max pooling | 56 × 56, 64 |
| Block1 | |
| Block2 | |
| Block3 | |
| Block4 |
| Algorithm | Accuracy | Loss | Parameters |
|---|---|---|---|
| RandomNet50 | 88.23% | 0.34 | 15.2 × 106 |
| ResNet50 | 83.15% | 0.41 | 21.3 × 106 |
| DenseNet50 | 87.46% | 0.35 | 7.0 × 106 |
| Block Name | Activations-1 | Activations-2 | Activations-3 |
|---|---|---|---|
| Block1 | |||
| Block2 | |||
| Block3 | |||
| Block4 |
| Structure | Accuracy |
|---|---|
| Activations-1 | 88.23% |
| Activations-2 | 88.15% |
| Activations-3 | 88.06% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, W.; Shi, Y.; Yang, R.; Ye, B.; Qiang, H. Automatic Classification of Defective Solar Panels in Electroluminescence Images Based on Random Connection Network. Electronics 2024, 13, 2429. https://doi.org/10.3390/electronics13132429
Xu W, Shi Y, Yang R, Ye B, Qiang H. Automatic Classification of Defective Solar Panels in Electroluminescence Images Based on Random Connection Network. Electronics. 2024; 13(13):2429. https://doi.org/10.3390/electronics13132429
Chicago/Turabian StyleXu, Weiyue, Yinhao Shi, Ruxue Yang, Bo Ye, and Hao Qiang. 2024. "Automatic Classification of Defective Solar Panels in Electroluminescence Images Based on Random Connection Network" Electronics 13, no. 13: 2429. https://doi.org/10.3390/electronics13132429
APA StyleXu, W., Shi, Y., Yang, R., Ye, B., & Qiang, H. (2024). Automatic Classification of Defective Solar Panels in Electroluminescence Images Based on Random Connection Network. Electronics, 13(13), 2429. https://doi.org/10.3390/electronics13132429