
Feature Selection for Data Classification in the Semiconductor Industry by a Hybrid of Simplified Swarm Optimization

Abstract
1. Introduction
- Propose a hybrid feature selection method combining mutual information (MI) with a simplified swarm optimization (SSO) algorithm using non-binary encoding. This method reduces data dimensionality and accurately selects key factors for anomaly prediction.
- Develop an anomaly detection approach suitable for multivariate, imbalanced data that is applied to real-world cases for precise, real-time wafer quality management.
2. Preliminary Issues
2.1. Feature Selection
2.1.1. Filter Methods
2.1.2. Wrappers
2.1.3. Embedded Methods
2.1.4. Hybrid Methods
2.2. Classification Algorithms
2.2.1. K-Nearest Neighbor (KNN)
2.2.2. Support Vector Machine (SVM)
- linear kernel—
- polynomial function—
- hyperbolic tangent, also known as sigmoid—
- Gaussian radial basis function, RBF—
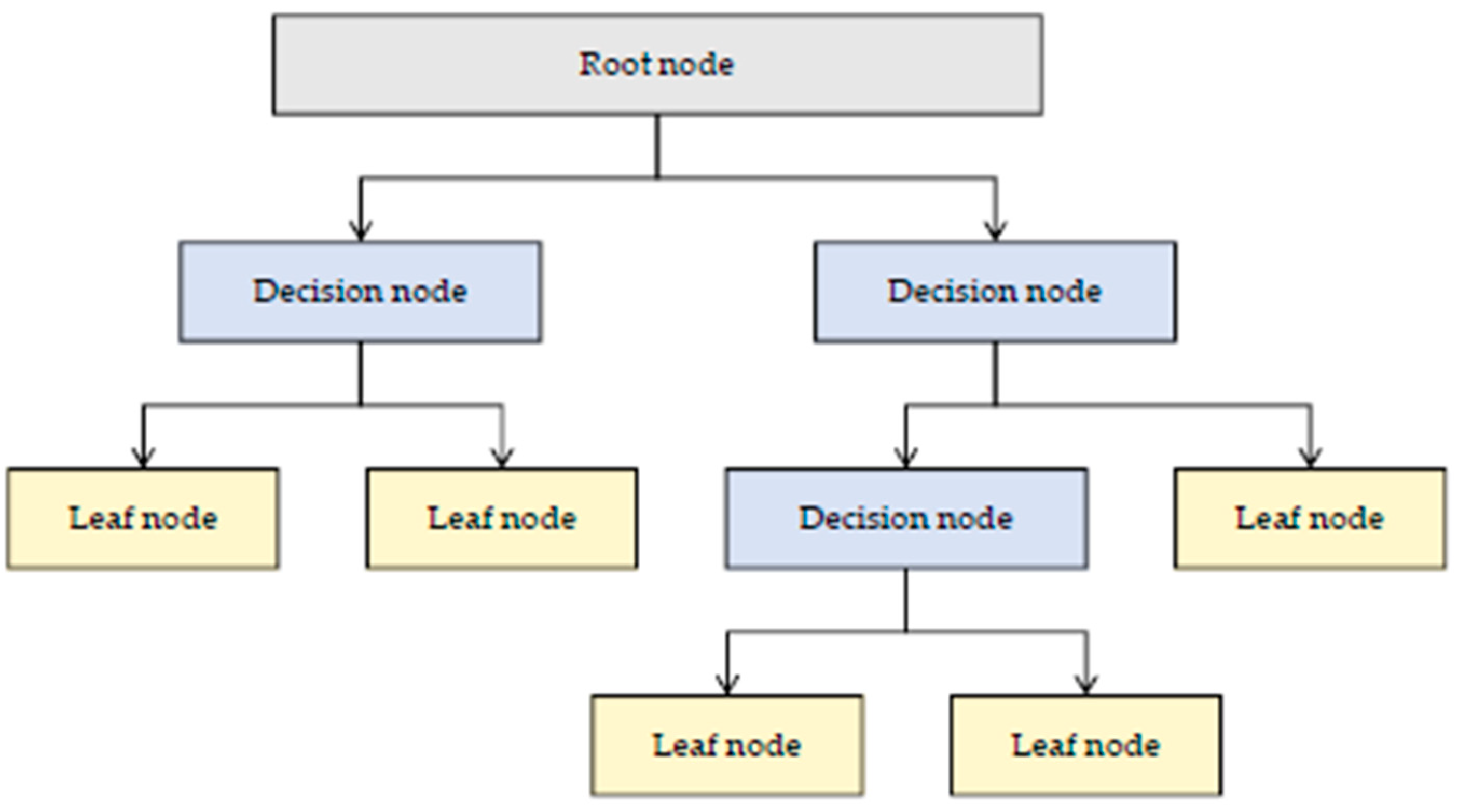
2.2.3. Decision Tree and Random Forest
2.3. Simplified Swarm Optimization
3. The Proposed Approach
3.1. Mutual Information
3.2. Feature Selection Based on SSO
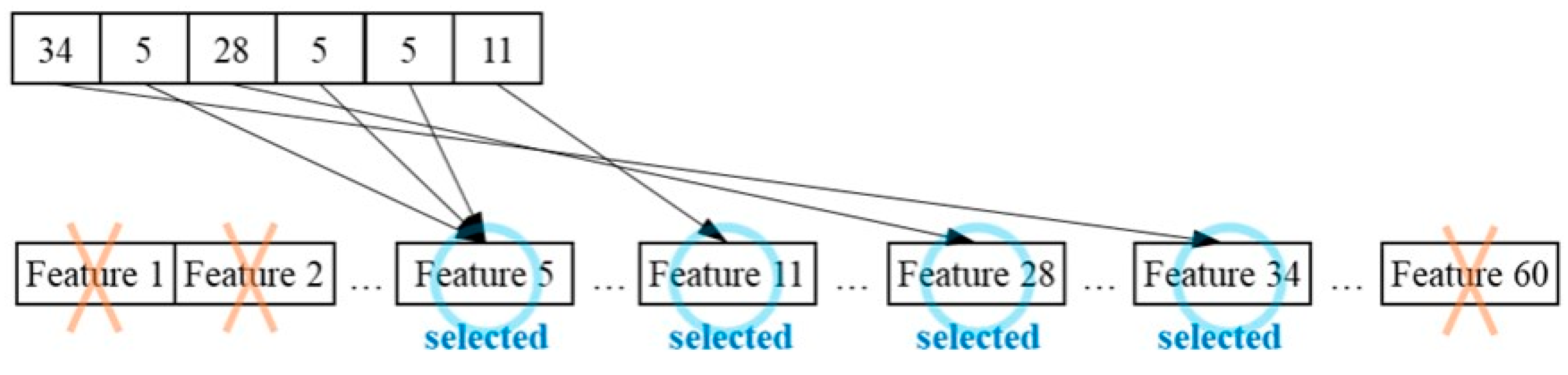
3.2.1. Particle Encoding Method
3.2.2. Fitness Function
3.2.3. Updating Steps
4. Experimental Results and Analysis
4.1. Description of the Datasets
4.2. MI-SSO Parameter Configuration
4.3. Experimental Results
- MI—This method uses only MI for feature selection. It sequentially selects the top K features based on their MI values (K = 1, 2, …) and evaluates their classification performance by incorporating them into the model. The process continues until there is no improvement in classification results for 100 consecutive solutions. This identifies the top K features that yield the best model performance.
- MI-GA—This method adapts SSO using a genetic algorithm (GA), with crossover and mutation probabilities set to 0.8 and 0.2, respectively [68].
- MI-PSO—This method adapts SSO using a particle swarm optimization (PSO) algorithm, with the inertia weight w set to 0.9 and the acceleration constants (c1, c2) set to (2, 2) [49].
4.4. Case Verification
- Lot number—unique batch identifier;
- Wafer number—sequential number up to 25 wafers per batch;
- Parameter name—corresponding measurement parameters for each test;
- Measurement equipment—recorded equipment performing the test.
- Measurement points 1 to 5—floating-point numbers representing different characteristics at different positions on the same wafer;
- Label—category indicating wafer quality as good, bad, or risk.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Moore, G.E. Cramming more components onto integrated circuits. Proc. IEEE 1998, 86, 82–85. [Google Scholar] [CrossRef]
- Mack, C.A. Fifty years of Moore’s law. IEEE Trans. Semicond. Manuf. 2011, 24, 202–207. [Google Scholar] [CrossRef]
- Kikuchi, M. Semiconductor Fabrication Facilities: Equipment, Materials, Processes, and Prescriptions for Industrial Revitalization; Shimao: Taipei, Taiwan, 2016. [Google Scholar]
- Kourti, T.; MacGregor, J.F. Process analysis, monitoring and diagnosis, using multivariate projection methods. Chemom. Intell. Lab. Syst. 1995, 28, 3–21. [Google Scholar] [CrossRef]
- Baly, R.; Hajj, H. Wafer classification using support vector machines. IEEE Trans. Semicond. Manuf. 2012, 25, 373–383. [Google Scholar] [CrossRef]
- He, Q.P.; Wang, J. Fault detection using the k-nearest neighbor rule for semiconductor manufacturing processes. IEEE Trans. Semicond. Manuf. 2007, 20, 345–354. [Google Scholar] [CrossRef]
- Piao, M.; Jin, C.H.; Lee, J.Y.; Byun, J.Y. Decision tree ensemble-based wafer map failure pattern recognition based on radon transform-based features. IEEE Trans. Semicond. Manuf. 2018, 31, 250–257. [Google Scholar] [CrossRef]
- Shin, C.K.; Park, S.C. A machine learning approach to yield management in semiconductor manufacturing. Int. J. Prod. Res. 2000, 38, 4261–4271. [Google Scholar] [CrossRef]
- Cheng, K.C.C.; Chen, L.L.Y.; Li, J.W.; Li, K.S.M.; Tsai, N.C.Y.; Wang, S.J.; Huang, A.Y.-A.; Chou, L.; Lee, C.-S.; Chen, J.E.; et al. Machine learning-based detection method for wafer test induced defects. IEEE Trans. Semicond. Manuf. 2021, 34, 161–167. [Google Scholar] [CrossRef]
- Bolón-Canedo, V.; Sánchez-Maroño, N.; Alonso-Betanzos, A. Feature Selection for High-Dimensional Data; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Venkatesh, B.; Anuradha, J. A review of feature selection and its methods. Cybern. Inf. Technol. 2019, 19, 3–26. [Google Scholar] [CrossRef]
- Fernández, A.; García, S.; Galar, M.; Prati, R.C.; Krawczyk, B.; Herrera, F. Learning from Imbalanced Data Sets; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Kaur, H.; Pannu, H.S.; Malhi, A.K. A systematic review on imbalanced data challenges in machine learning: Applications and solutions. ACM Comput. Surv. (CSUR) 2019, 52, 1–36. [Google Scholar] [CrossRef]
- Jiang, D.; Lin, W.; Raghavan, N. A Gaussian mixture model clustering ensemble regressor for semiconductor manufacturing final test yield prediction. IEEE Access 2021, 9, 22253–22263. [Google Scholar] [CrossRef]
- Fan, S.K.S.; Lin, S.C.; Tsai, P.F. Wafer fault detection and key step identification for semiconductor manufacturing using principal component analysis, AdaBoost and decision tree. J. Ind. Prod. Eng. 2016, 33, 151–168. [Google Scholar] [CrossRef]
- Chien, C.F.; Wang, W.C.; Cheng, J.C. Data mining for yield enhancement in semiconductor manufacturing and an empirical study. Expert Syst. Appl. 2007, 33, 192–198. [Google Scholar] [CrossRef]
- Eesa, A.S.; Orman, Z.; Brifcani, A.M.A. A novel feature-selection approach based on the cuttlefish optimization algorithm for intrusion detection systems. Expert Syst. Appl. 2015, 42, 2670–2679. [Google Scholar] [CrossRef]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature selection: A data perspective. ACM Comput. Surv. (CSUR) 2017, 50, 1–45. [Google Scholar] [CrossRef]
- Zebari, R.; Abdulazeez, A.; Zeebaree, D.; Zebari, D.; Saeed, J. A comprehensive review of dimensionality reduction techniques for feature selection and feature extraction. J. Appl. Sci. Technol. Trends 2020, 1, 56–70. [Google Scholar] [CrossRef]
- Jović, A.; Brkić, K.; Bogunović, N. A review of feature selection methods with applications. In Proceedings of the 2015 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 25–29 May 2015; pp. 1200–1205. [Google Scholar]
- Dash, M.; Liu, H. Feature selection for classification. Intell. Data Anal. 1997, 1, 131–156. [Google Scholar] [CrossRef]
- Kira, K.; Rendell, L.A. The feature selection problem: Traditional methods and a new algorithm. In Proceedings of the Tenth National Conference on Artificial Intelligence, San Jose, CA, USA, 12–16 July 1992; Volume 2, pp. 129–134. [Google Scholar]
- Kononenko, I.; Šimec, E.; Robnik-Šikonja, M. Overcoming the myopia of inductive learning algorithms with RELIEFF. Appl. Intell. 1997, 7, 39–55. [Google Scholar] [CrossRef]
- Kononenko, I. Estimating attributes: Analysis and extensions of RELIEF. In Proceedings of the European Conference on Machine Learning, Catania, Italy, 6–8 April 1994; pp. 171–182. [Google Scholar]
- Yang, H.; Moody, J. Data visualization and feature selection: New algorithms for nongaussian data. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 29 November–4 December 1999; Volume 12. [Google Scholar]
- Karegowda, A.G.; Manjunath, A.; Jayaram, M. Comparative study of attribute selection using gain ratio and correlation based feature selection. Int. J. Inf. Technol. Knowl. Manag. 2010, 2, 271–277. [Google Scholar]
- Azhagusundari, B.; Thanamani, A.S. Feature selection based on information gain. Int. J. Innov. Technol. Explor. Eng. (IJITEE) 2013, 2, 18–21. [Google Scholar]
- Alhaj, T.A.; Siraj, M.M.; Zainal, A.; Elshoush, H.T.; Elhaj, F. Feature selection using information gain for improved structural-based alert correlation. PLoS ONE 2016, 11, e0166017. [Google Scholar] [CrossRef] [PubMed]
- Jadhav, S.; He, H.; Jenkins, K. Information gain directed genetic algorithm wrapper feature selection for credit rating. Appl. Soft Comput. 2018, 69, 541–553. [Google Scholar] [CrossRef]
- Amaldi, E.; Kann, V. On the approximability of minimizing nonzero variables or unsatisfied relations in linear systems. Theor. Comput. Sci. 1998, 209, 237–260. [Google Scholar] [CrossRef]
- Soufan, O.; Kleftogiannis, D.; Kalnis, P.; Bajic, V.B. DWFS: A wrapper feature selection tool based on a parallel genetic algorithm. PLoS ONE 2015, 10, e0117988. [Google Scholar] [CrossRef]
- Vieira, S.M.; Mendonça, L.F.; Farinha, G.J.; Sousa, J.M. Modified binary PSO for feature selection using SVM applied to mortality prediction of septic patients. Appl. Soft Comput. 2013, 13, 3494–3504. [Google Scholar] [CrossRef]
- Cai, J.; Luo, J.; Wang, S.; Yang, S. Feature selection in machine learning: A new perspective. Neurocomputing 2018, 300, 70–79. [Google Scholar] [CrossRef]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Sarkar, S.D.; Goswami, S.; Agarwal, A.; Aktar, J. A novel feature selection technique for text classification using Naive Bayes. Int. Sch. Res. Not. 2014, 2014, 717092. [Google Scholar] [CrossRef]
- Bostani, H.; Sheikhan, M. Hybrid of binary gravitational search algorithm and mutual information for feature selection in intrusion detection systems. Soft Comput. 2017, 21, 2307–2324. [Google Scholar] [CrossRef]
- Zhang, J.; Xiong, Y.; Min, S. A new hybrid filter/wrapper algorithm for feature selection in classification. Anal. Chim. Acta 2019, 1080, 43–54. [Google Scholar] [CrossRef] [PubMed]
- Naqa, I.E.; Murphy, M.J. What is machine learning? In Machine Learning in Radiation Oncology; Springer: Berlin/Heidelberg, Germany, 2015; pp. 3–11. [Google Scholar]
- Zhou, Z.; Wen, C.; Yang, C. Fault detection using random projections and k-nearest neighbor rule for semiconductor manufacturing processes. IEEE Trans. Semicond. Manuf. 2014, 28, 70–79. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Awad, M.; Khanna, R.; Awad, M.; Khanna, R. Support vector machines for classification. In Efficient Learning Machines: Theories, Concepts, and Applications for Engineers and System Designers; Apress: Berkeley, CA, USA, 2015; pp. 39–66. [Google Scholar]
- Nutt, C.L.; Mani, D.R.; Betensky, R.A.; Tamayo, P.; Cairncross, J.G.; Ladd, C.; Pohl, U.; Hartmann, C.; McLaughlin, M.E.; Batchelor, T.T.; et al. Gene expression-based classification of malignant gliomas correlates better with survival than histological classification. Cancer Res. 2003, 63, 1602–1607. [Google Scholar]
- Alon, U.; Barkai, N.; Notterman, D.A.; Gish, K.; Ybarra, S.; Mack, D.; Levine, A.J. Broad patterns of gene expression revealed by clustering analysis of tumor and normal colon tissues probed by oligonucleotide arrays. Proc. Natl. Acad. Sci. USA 1999, 96, 6745–6750. [Google Scholar] [CrossRef]
- Cervantes, J.; Garcia-Lamont, F.; Rodríguez-Mazahua, L.; Lopez, A. A comprehensive survey on support vector machine classification: Applications, challenges and trends. Neurocomputing 2020, 408, 189–215. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C.J. Classification and Regression Trees; Chapman & Hall/CRC: New York, NY, USA, 1984. [Google Scholar]
- Beheshti, Z.; Shamsuddin, S.M.H. A review of population-based meta-heuristic algorithms. Int. J. Adv. Soft Comput. Appl 2013, 5, 1–35. [Google Scholar]
- Yeh, W.C. A two-stage discrete particle swarm optimization for the problem of multiple multi-level redundancy allocation in series systems. Expert Syst. Appl. 2009, 36, 9192–9200. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Yeh, W.C.; Chuang, M.C.; Lee, W.C. Uniform parallel machine scheduling with resource consumption constraint. Appl. Math. Model. 2015, 39, 2131–2138. [Google Scholar] [CrossRef]
- Yeh, W.C.; Wei, S.C. Economic-based resource allocation for reliable Grid-computing service based on Grid Bank. Future Gener. Comput. Syst. 2012, 28, 989–1002. [Google Scholar] [CrossRef]
- Lee, W.C.; Chuang, M.C.; Yeh, W.C. Uniform parallel-machine scheduling to minimize makespan with position-based learning curves. Comput. Ind. Eng. 2012, 63, 813–818. [Google Scholar] [CrossRef]
- Corley, H.W.; Rosenberger, J.; Yeh, W.C.; Sung, T.K. The cosine simplex algorithm. Int. J. Adv. Manuf. Technol. 2006, 27, 1047–1050. [Google Scholar] [CrossRef]
- Yeh, W.C. A new algorithm for generating minimal cut sets in k-out-of-n networks. Reliab. Eng. Syst. Safety 2006, 91, 36–43. [Google Scholar] [CrossRef]
- Luo, C.; Sun, B.; Yang, K.; Lu, T.; Yeh, W.C. Thermal infrared and visible sequences fusion tracking based on a hybrid tracking framework with adaptive weighting scheme. Infrared Phys. Technol. 2019, 99, 265–276. [Google Scholar] [CrossRef]
- Bae, C.; Yeh, W.C.; Wahid, N.; Chung, Y.Y.; Liu, Y. A New Simplified Swarm Optimization (SSO) Using Exchange Local Search Scheme. Int. J. Innov. Comput. Inf. Control 2012, 8, 4391–4406. [Google Scholar]
- Yeh, W.C. A new exact solution algorithm for a novel generalized redundancy allocation problem. Inf. Sci. 2017, 408, 182–197. [Google Scholar] [CrossRef]
- Hsieh, T.J.; Yeh, W.C. Knowledge discovery employing grid scheme least squares support vector machines based on orthogonal design bee colony algorithm. IEEE Trans. Syst. Man Cybern. Part B (Cybernetics) 2011, 41, 1198–1212. [Google Scholar] [CrossRef] [PubMed]
- Chung, Y.Y.; Wahid, N. A hybrid network intrusion detection system using simplified swarm optimization (SSO). Appl. Soft Comput. 2012, 12, 3014–3022. [Google Scholar] [CrossRef]
- Lai, C.M.; Yeh, W.C.; Chang, C.Y. Gene Selection using Information Gain and Improved Simplified Swarm Optimization. Neurocomputing 2016, 218, 331–338. [Google Scholar] [CrossRef]
- Song, X.F.; Zhang, Y.; Guo, Y.N.; Sun, X.Y.; Wang, L. Variable-size cooperative coevolutionary particle swarm optimization for feature selection on high-dimensional data. IEEE Trans. Evol. Comput. 2020, 24, 882–895. [Google Scholar] [CrossRef]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. Int. Jt. Conf. Arti 1995, 14, 1137–1145. [Google Scholar]
- Gorodkin, J. Comparing two K-category assignments by a K-category correlation coefficient. Comput. Biol. Chem. 2004, 28, 367–374. [Google Scholar] [CrossRef] [PubMed]
- Chicco, D.; Jurman, G. A statistical comparison between Matthews correlation coefficient (MCC), prevalence threshold, and Fowlkes–Mallows index. J. Biomed. Inform. 2023, 144, 104426. [Google Scholar] [CrossRef]
- Zhu, Z.; Ong, Y.S.; Dash, M. Markov blanket-embedded genetic algorithm for gene selection. Pattern Recognit. 2007, 40, 3236–3248. [Google Scholar] [CrossRef]
- Petricoin, E.F.; Ardekani, A.M.; Hitt, B.A.; Levine, P.J.; Fusaro, V.A.; Steinberg, S.M.; Mills, G.B.; Simone, C.; A Fishman, D.; Kohn, E.C.; et al. Use of proteomic patterns in serum to identify ovarian cancer. Lancet 2002, 359, 572–577. [Google Scholar] [CrossRef] [PubMed]
- Dabba, A.; Tari, A.; Meftali, S.; Mokhtari, R. Gene selection and classification of microarray data method based on mutual information and moth flame algorithm. Expert Syst. Appl. 2021, 166, 114012. [Google Scholar] [CrossRef]
- Heris, M.K. Practical Genetic Algorithms in Python and MATLAB—Video Tutorial. Yarpiz. 2020. Available online: https://yarpiz.com/632/ypga191215-practical-genetic-algorithms-in-python-and-matlab (accessed on 10 January 2024).
- Chen, K.; Xue, B.; Zhang, M.; Zhou, F. Evolutionary multitasking for feature selection in high-dimensional classification via particle swarm optimization. IEEE Trans. Evol. Comput. 2021, 26, 446–460. [Google Scholar] [CrossRef]
- Chaudhuri, A.; Sahu, T.P. A hybrid feature selection method based on Binary Jaya algorithm for micro-array data classification. Comput. Electr. Eng. 2021, 90, 106963. [Google Scholar] [CrossRef]
- Baliarsingh, S.K.; Muhammad, K.; Bakshi, S. SARA: A memetic algorithm for high-dimensional biomedical data. Appl. Soft Comput. 2021, 101, 107009. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Number of Features | Number of Instances | Numbers of Classes and Proportions | Source |
|---|---|---|---|---|
| Brain2 | 10,367 | 50 | 4 (14:7:14:15) | [42] |
| Breast | 24,481 | 97 | 2 (51:46) | [65] |
| Colon | 2000 | 60 | 2 (40:22) | [43] |
| Lung | 3312 | 203 | 5 (139:17:21:20:6) | [18] |
| MLL | 12,582 | 72 | 3 (24:20:28) | [65] |
| Ovarian | 15,154 | 253 | 2 (162:91) | [66] |
| Dataset | KNN | SVM | RF | |
|---|---|---|---|---|
| Avg. | MCC | 0.742544 | 0.758584 | 0.757617 |
| #F | 21.552381 | 20.628571 | 21.666667 | |
| Time (min) | 6.666159 | 5.785098 | 11.083760 |
| Dataset | Cg | 0.4 | 0.4 | 0.4 | 0.5 | 0.5 | 0.5 | 0.6 | 0.6 |
|---|---|---|---|---|---|---|---|---|---|
| Cp | 0.5 | 0.6 | 0.7 | 0.5 | 0.6 | 0.7 | 0.6 | 0.7 | |
| Cw | 0.7 | 0.8 | 0.9 | 0.8 | 0.9 | 0.7 | 0.7 | 0.8 | |
| Brain2 | MCC | 0.8796 | 0.9025 | 0.8937 | 0.8795 | 0.8954 | 0.8898 | 0.8913 | 0.8887 |
| #F | 29.0 | 26.8 | 23.1 | 27.4 | 23.2 | 26.9 | 27.5 | 24.5 | |
| Breast | MCC | 0.7024 | 0.7903 | 0.8278 | 0.8129 | 0.8337 | 0.8330 | 0.7787 | 0.7886 |
| #F | 30.2 | 29.2 | 25.6 | 29.8 | 25.4 | 29.7 | 29.1 | 28.2 | |
| Colon | MCC | 0.8682 | 0.8661 | 0.8825 | 0.8597 | 0.8623 | 0.8674 | 0.8715 | 0.8763 |
| #F | 27.6 | 27.5 | 28.1 | 27.5 | 27.6 | 27.3 | 27.4 | 28.0 | |
| Lung | MCC | 0.8471 | 0.8857 | 0.9120 | 0.8846 | 0.9113 | 0.8441 | 0.8538 | 0.8921 |
| #F | 32.2 | 32.1 | 33.1 | 32.7 | 31.1 | 30.4 | 32.8 | 32.8 | |
| MLL | MCC | 0.9920 | 0.9952 | 0.9933 | 0.9907 | 0.9939 | 0.9932 | 0.9924 | 0.9920 |
| #F | 23.5 | 20.7 | 15.7 | 20.4 | 15.8 | 21.9 | 22.6 | 19.9 | |
| Ovarian | MCC | 0.9979 | 0.9982 | 0.9987 | 0.9977 | 0.9977 | 0.9981 | 0.9969 | 0.9983 |
| #F | 21.5 | 19.6 | 14.4 | 19.6 | 14.6 | 20.1 | 19.4 | 17.3 | |
| Avg. | MCC | 0.8812 | 0.9063 | 0.9180 | 0.9042 | 0.9157 | 0.9043 | 0.8974 | 0.9060 |
| #F | 27.3333 | 25.9833 | 23.3333 | 26.2333 | 22.9500 | 26.0500 | 26.4667 | 25.1167 | |
| Fitness | 0.9433 | 0.9553 | 0.9608 | 0.9542 | 0.9597 | 0.9543 | 0.9510 | 0.9551 |
| 0.6 | 0.6 | 0.7 | 0.7 | 0.8 | 0.8 | 0.9 | 0.9 | 1 | 1 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Nvar | 30 | 50 | 30 | 50 | 30 | 50 | 30 | 50 | 30 | 50 |
| Brain2 | MCC | 0.9005 | 0.9061 | 0.9087 | 0.9021 | 0.9057 | 0.8976 | 0.9018 | 0.9080 | 0.9115 | 0.9120 |
| #F | 15.2 | 23.2 | 16.7 | 22.4 | 16.5 | 22.2 | 16.3 | 22.8 | 22.7 | 32.5 | |
| Fitness | 0.9527 | 0.9553 | 0.9566 | 0.9534 | 0.9551 | 0.9513 | 0.9533 | 0.9561 | 0.9579 | 0.9581 | |
| Breast | MCC | 0.8644 | 0.846246 | 0.815585 | 0.840691 | 0.8381 | 0.8524 | 0.8036 | 0.8521 | 0.7710 | 0.8522 |
| #F | 17 | 25.4 | 16.4 | 27.3 | 16.5 | 26.6 | 17.1 | 26.1 | 22.9 | 34.7 | |
| Fitness | 0.9355 | 0.9269 | 0.9124 | 0.9243 | 0.9231 | 0.9298 | 0.9067 | 0.9297 | 0.8912 | 0.9297 | |
| Colon | MCC | 0.8793 | 0.8718 | 0.8756 | 0.8714 | 0.8715 | 0.8750 | 0.8754 | 0.8746 | 0.8782 | 0.8710 |
| #F | 20.7 | 28.3 | 19.3 | 27.3 | 18.9 | 27.3 | 20.3 | 28 | 23 | 29.8 | |
| Fitness | 0.9422 | 0.9384 | 0.9404 | 0.9382 | 0.9385 | 0.9399 | 0.9403 | 0.9397 | 0.9416 | 0.9380 | |
| Lung | MCC | 0.9009 | 0.9193 | 0.9064 | 0.9157 | 0.9044 | 0.9061 | 0.9035 | 0.9146 | 0.9083 | 0.9135 |
| #F | 23.1 | 31.8 | 23 | 33.6 | 22.2 | 33 | 24.1 | 33.3 | 26 | 37.3 | |
| Fitness | 0.9526 | 0.9612 | 0.9552 | 0.9594 | 0.9543 | 0.9549 | 0.9538 | 0.9589 | 0.9561 | 0.9583 | |
| MLL | MCC | 0.9929 | 0.9941 | 0.9927 | 0.9943 | 0.9916 | 0.9936 | 0.9949 | 0.9930 | 0.9958 | 0.9951 |
| #F | 10.7 | 16.6 | 10.7 | 15.8 | 10.3 | 16.9 | 9.8 | 16.6 | 21 | 31.9 | |
| Fitness | 0.9966 | 0.9971 | 0.9965 | 0.9972 | 0.9960 | 0.9969 | 0.9975 | 0.9966 | 0.9979 | 0.9976 | |
| Ovarian | MCC | 0.9979 | 0.9974 | 0.9975 | 0.9984 | 0.9988 | 0.9980 | 0.9987 | 0.9984 | 0.9987 | 0.9987 |
| #F | 8.9 | 15 | 8.5 | 14.6 | 8.2 | 14.8 | 8.3 | 15.1 | 21.8 | 31.2 | |
| Fitness | 0.9990 | 0.9987 | 0.9988 | 0.9992 | 0.9994 | 0.9990 | 0.9994 | 0.9992 | 0.9993 | 0.9993 |
| Hyperparameters | Numerical Value | Illustrate |
|---|---|---|
| K | 100 | Number of candidate solutions |
| Ngen | 100 | Number of iterations |
| Nsol | 50 | Number of solutions |
| Nvar | 30 or 50 | Solution length, depending on the dataset |
| Cp | 0.4 | SSO hyperparameter |
| Cg | 0.7 | SSO hyperparameter |
| Cw | 0.9 | SSO hyperparameter |
| 0.6, 0.7, 0.8, 0.9 or 1 | Fitness function hyperparameters, depending on the dataset | |
| k | 4 | Number of layers in SCV |
| Dataset | Average | MI | MI-GA | MI-PSO | MI-SSO |
|---|---|---|---|---|---|
| Brain2 | MCC | 0.900086 | 0.853529 | 0.857373 | 0.903063 |
| #F | 94 | 39.9 | 28.5 | 31.133333 | |
| Breast | MCC | 0.833606 | 0.720417 | 0.535284 | 0.848164 |
| #F | 90 | 25.933333 | 14.466667 | 16.333333 | |
| Colon | MCC | 0.67774 | 0.76019 | 0.86627 | 0.930007 |
| #F | 18 | 26.1 | 20.366667 | 19.633333 | |
| Lung | MCC | 0.953074 | 0.874127 | 0.452402 | 0.918722 |
| #F | 117 | 39.733333 | 17.766667 | 33.5 | |
| MLL | MCC | 0.984438 | 0.972186 | 0.993398 | 0.994614 |
| #F | 4 | 26.433333 | 16.466667 | 13.666667 | |
| Ovarian | MCC | 0.999289 | 0.992263 | 0.998102 | 0.99863 |
| #F | 53 | 25.933333 | 12.8 | 8.633333 |
| Dataset | MI-GA | MI-PSO | MI-SSO |
|---|---|---|---|
| SEMI | 6.580849 | 6.904897 | 6.644581 |
| Brain2 | 3.241753 | 3.209523 | 3.228779 |
| Breast | 4.874745 | 4.494404 | 4.755814 |
| Colon | 5.430743 | 5.18067 | 5.423277 |
| Lung | 3.115069 | 3.180372 | 3.13715 |
| MLL | 4.260329 | 4.080748 | 4.283061 |
| Ovarian | 4.92204 | 4.471951 | 4.887172 |
| Average | 4.632218 | 4.503224 | 4.622833 |
| Dataset | Average | MIM-mMFA | VS-CCPSO | MTPSO | TOPSIS-Jaya | SARA-SVM | MI-SSO |
|---|---|---|---|---|---|---|---|
| Brain2 | ACC | 1 | 0.8047 | 0.8540 | 0.921967 | ||
| #F | 11.93 | 81.46 | 1066.32 | 31.3 | |||
| Breast | ACC | 0.868 | 0.924472 | ||||
| #F | 25.9 | 16.7 | |||||
| Colon | ACC | 1 | 0.9776 | 0.9702 | 0.952861 | ||
| #F | 26.3 | 18.9 | 9 | 19.766667 | |||
| Lung | ACC | 0.9791 | 0.9740 | 0.956916 | |||
| #F | 370.79 | 343.24 | 32.6 | ||||
| MLL | ACC | 1 | 0.9962 | 0.996235 | |||
| #F | 33 | 12.9 | 13.366667 | ||||
| Ovarian | ACC | 0.9818 | 0.9952 | 0.9915 | 0.999297 | ||
| #F | 35.9 | 18.5 | 6 | 8.7 |
| Batch Number | Max | Min | Max | Max/Min … | Max | Min | Mark |
|---|---|---|---|---|---|---|---|
| A | 4.00636 | 3.88418 | 0.669097 | … | 4.99095 | 4.98854 | good |
| B | 3.96926 | 3.87155 | 0.611947 | 4.9946 | 4.99371 | good | |
| C | 4.12133 | 3.88967 | 0.611947 | 4.98923 | 4.98752 | bad | |
| … | … | … | … | … | … | … |
| 0.6 | 0.6 | 0.7 | 0.7 | 0.8 | 0.8 | 0.9 | 0.9 | 1 | 1 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Nvar | 30 | 50 | 30 | 50 | 30 | 50 | 30 | 50 | 30 | 50 |
| SEMI | MCC | 0.9558 | 0.9604 | 0.9616 | 0.9610 | 0.9613 | 0.9639 | 0.9634 | 0.9607 | 0.9631 | 0.9562 |
| #F | 21.3 | 29.5 | 23.3 | 31.9 | 23.5 | 32.6 | 22.5 | 35.2 | 25.9 | 38.7 | |
| Fitness | 0.9760 | 0.9754 | 0.9777 | 0.9749 | 0.9775 | 0.9759 | 0.9787 | 0.9738 | 0.9775 | 0.9710 |
| Dataset | Average | MI | MI-GA | MI-PSO | MI-SSO |
|---|---|---|---|---|---|
| SEMI | ACC | 0.993177 | 0.981726 | 0.990751 | 0.994009 |
| MCC | 0.957388 | 0.882505 | 0.941981 | 0.962464 | |
| #F | 35 | 25.9 | 22.64 | 23.5 | |
| Fitness | 0.972539 | 0.945294 | 0.970054 | 0.977992 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yeh, W.-C.; Chu, C.-L. Feature Selection for Data Classification in the Semiconductor Industry by a Hybrid of Simplified Swarm Optimization. Electronics 2024, 13, 2242. https://doi.org/10.3390/electronics13122242
Yeh W-C, Chu C-L. Feature Selection for Data Classification in the Semiconductor Industry by a Hybrid of Simplified Swarm Optimization. Electronics. 2024; 13(12):2242. https://doi.org/10.3390/electronics13122242
Chicago/Turabian StyleYeh, Wei-Chang, and Chia-Li Chu. 2024. "Feature Selection for Data Classification in the Semiconductor Industry by a Hybrid of Simplified Swarm Optimization" Electronics 13, no. 12: 2242. https://doi.org/10.3390/electronics13122242
APA StyleYeh, W.-C., & Chu, C.-L. (2024). Feature Selection for Data Classification in the Semiconductor Industry by a Hybrid of Simplified Swarm Optimization. Electronics, 13(12), 2242. https://doi.org/10.3390/electronics13122242