



Prediction of Machine-Generated Financial Tweets Using Advanced Bidirectional Encoder Representations from Transformers




Abstract
1. Introduction
2. Literature Review
Research Gap
- We meticulously compiled a substantial dataset of finance-related tweets sourced from Twitter, forming the cornerstone of our research.
- Utilizing this financial tweet dataset, we harnessed advanced language models, including ChatGPT, QuillBot, and SpinBot, to craft pertinent content, augmenting the depth and breadth of our collection for in-depth analysis.
- The prepared dataset of four classes was properly preprocessed before applying models.
- The different versions of Bidirectional Encoder Representations from Transformers (BERT) models, including BERT Base Cased, BERT Base Un-Cased, BERT Large Cased, BERT Large Un-Cased, Distilbert Base Cased, and Distilbert Base Un-Cased, are fine-tuned in this study.
- The performance of the “BERT Base Cased” model is also compared with various machine learning models, including Logistic Regression, Random Forest Classifier, Gradient Boosting Classifier, K Neighbors Classifier, Decision Tree Classifier, Multi-layer Perceptron (MLP) Classifier, AdaBoost Classifier, Bagging Classifier, Support Vector Classifier (SVC), and Quadratic Discriminant Analysis.
- The machine learning models are trained with TF-IDF and Word2Vec separately to properly show the robustness of the proposed fine-tuned “BERT Base Cased” model.
3. Materials and Methods
3.1. Dataset
Preprocessing
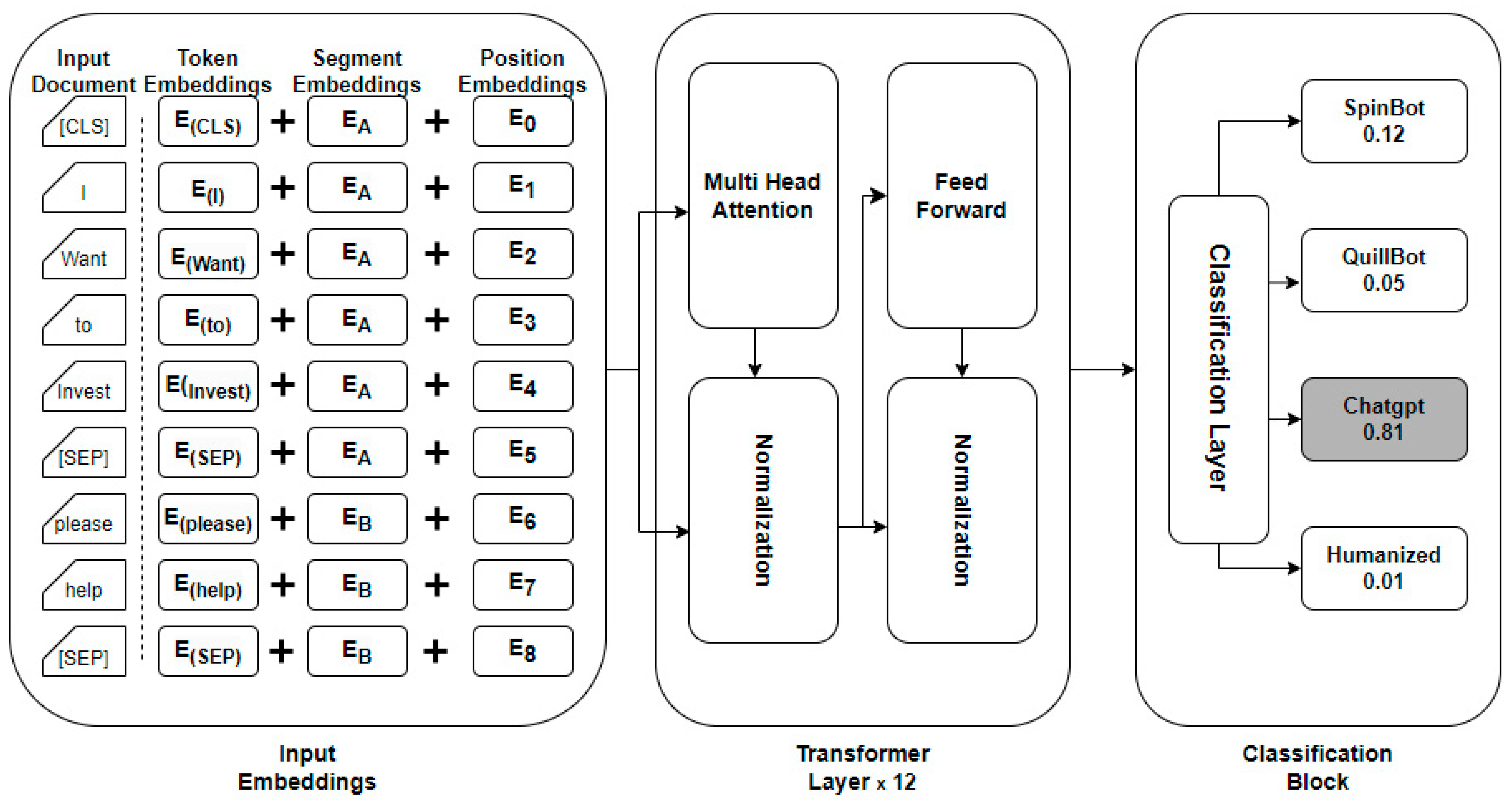
3.2. BERT Transformer Model
- BERT takes input sequences of tokens, which are the basic units of text (words or subwords).
- Each input sequence starts with a special token [CLS], which stands for classification, followed by the actual text tokens, and ends with a special token [SEP], which indicates the end of the sequence.
- BERT also uses WordPiece embeddings, which break down words into subword units to handle rare or out-of-vocabulary words.
- BERT utilizes the transformer architecture, which consists of multiple layers of self-attention mechanisms and feedforward neural networks.
- The self-attention mechanism allows the model to weigh the importance of different words in the input sequence when encoding each word representation.
- Each transformer layer processes the input sequence in parallel, allowing for efficient computation of contextual word embeddings.
- BERT is pretrained using two unsupervised learning tasks:
- Masked Language Model (MLM): BERT randomly masks some of the input tokens and then tries to predict the original words based on the context provided by the surrounding tokens.
- Next Sentence Prediction (NSP): BERT is trained to predict whether a pair of sentences appear consecutively in a document or not, helping the model learn relationships between sentences.
- After pretraining, BERT can be fine-tuned on a specific text classification task [24].
- The [CLS] token representation from the final transformer layer is used as the aggregate sequence representation for the classification task.
- A simple classification layer (e.g., a SoftMax classifier) is added on top of the [CLS] representation to predict the class label for the input text.
- Bidirectional Context: BERT considers context from both directions, capturing richer semantic meaning compared to traditional models.
- Transfer Learning: Pretraining on a large corpus allows BERT to learn general language representations, which can be fine-tuned on smaller, task-specific datasets for improved performance.
- Attention Mechanism: The self-attention mechanism in BERT helps the model focus on relevant parts of the input sequence, enhancing its ability to understand complex relationships in text.
4. Experiments and Discussion
4.1. Evaluation Metrics
- Accuracy: To evaluate the overall accuracy of the model’s predictions, the accuracy metric computes the ratio of correctly classified cases to total samples, see Equation (1). However, when errors have varying degrees of importance or when datasets are uneven, relying solely on accuracy may not be adequate to provide a comprehensive evaluation.
- Precision: The ability of a model to correctly identify positive samples from the set of actual positives is referred to as its precision. This metric calculates the ratio of true positives to the sum of true positives and false positives, see Equation (2). In short, accuracy indicates how well the model performs when it generates a positive forecast.
- Recall: Recall measures how successfully the model separates positive samples from the actual positive pool. It is also frequently referred to as sensitivity or the true positive rate. This statistic is computed as the ratio of true positives to the sum of true positives and false negatives, see Equation (3). In essence, recall offers an assessment of the extent to which the model’s favorable predictions hold.
- F1-Score: Recall and precision are balanced in the F1-score, a comprehensive measure. It is calculated as these two measurements’ harmonic mean, see Equation (4). This is particularly helpful when there is an unequal distribution of errors between the classes or when there is no difference in the relative importance of the two error categories. The F1-score, which ranges from 0 to 1, is a combined assessment of the model’s recall and precision abilities. It operates most effectively at 1.
4.2. Experiments Setup
4.3. Hyperparameter Tuning
4.4. Experimental Results and Discussion
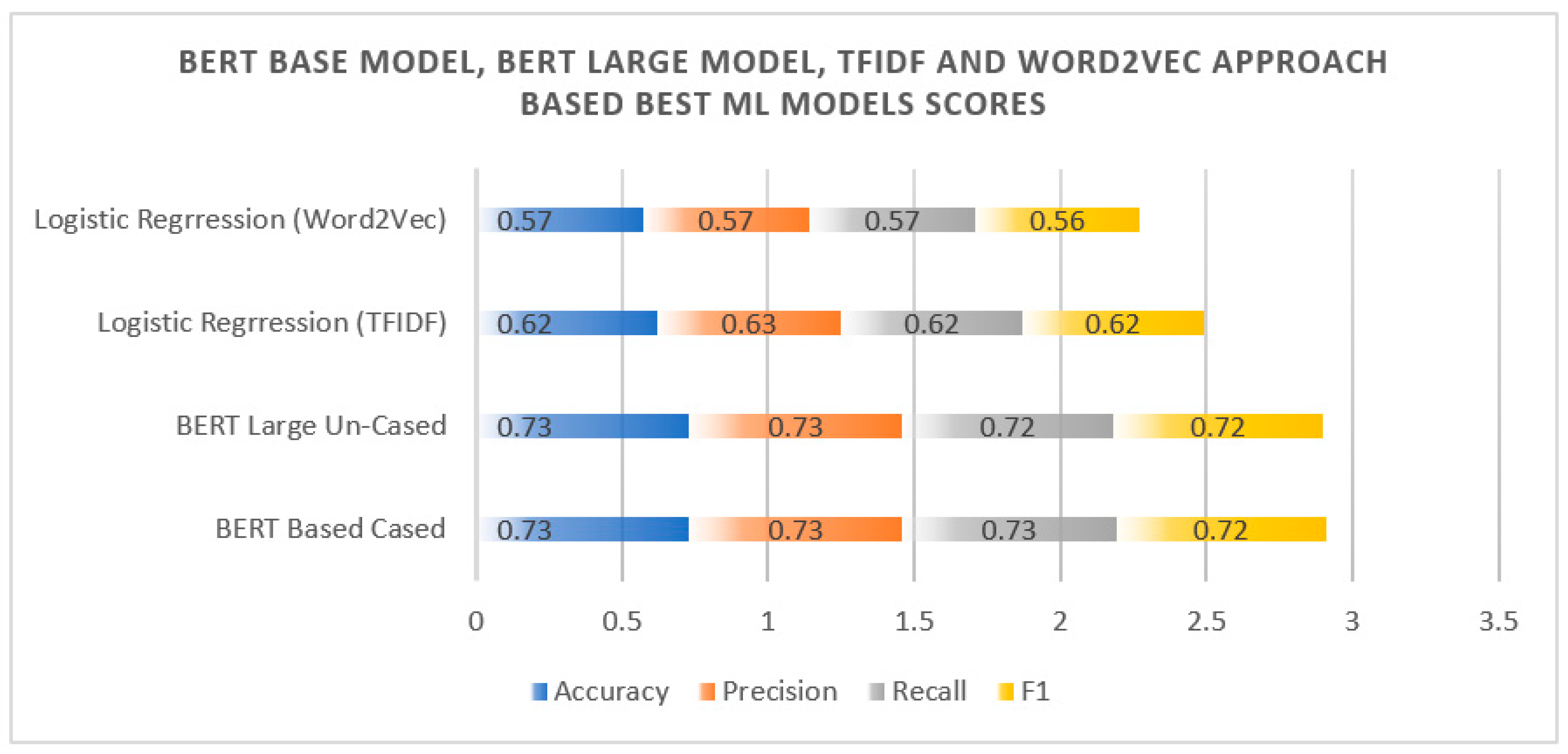
4.5. Robustness of the Proposed Model
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gao, C.A.; Howard, F.M.; Markov, N.S.; Dyer, E.C.; Ramesh, S.; Luo, Y.; Pearson, A.T. Comparing scientific abstracts generated by ChatGPT to real abstracts with detectors and blinded human reviewers. NPJ Digit. Med. 2023, 6, 75. [Google Scholar] [CrossRef]
- Naveed, H.; Khan, A.U.; Qiu, S.; Saqib, M.; Anwar, S.; Usman, M.; Akhtar, N.; Barnes, N.; Mian, A. A comprehensive overview of large language models. arXiv 2024, arXiv:2307.06435. [Google Scholar]
- Liu, X.; Zheng, Y.; Du, Z.; Ding, M.; Qian, Y.; Yang, Z.; Tang, J. GPT Understands, Too; Elsevier: Amsterdam, The Netherlands, 2023; Available online: https://www.sciencedirect.com/science/article/pii/S2666651023000141 (accessed on 29 March 2024).
- Topal, M.O.; Bas, A.; van Heerden, I. Exploring transformers in natural language generation: Gpt, bert, and xlnet. arXiv 2021, arXiv:2102.08036. [Google Scholar]
- Mindner, L.; Schlippe, T.; Schaaff, K. Classification of human-and ai-generated texts: Investigating features for chatgpt. In International Conference on Artificial Intelligence in Education Technology; Springer: Singapore, 2023. [Google Scholar] [CrossRef]
- Shahriar, S.; Hayawi, K. Let’s have a chat! A Conversation with ChatGPT: Technology, Applications, and Limitations. arXiv 2023, arXiv:2302.13817. [Google Scholar] [CrossRef]
- Kasneci, E.; Seßler, K.; Küchemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; Günnemann, S.; Hüllermeier, E.; et al. ChatGPT for good? On opportunities and challenges of large language models for education. Learn. Individ. Differ. 2023, 103, 102274. [Google Scholar] [CrossRef]
- Wu, T.; He, S.; Liu, J.; Sun, S.; Liu, K.; Han, Q.L.; Tang, Y. A Brief Overview of ChatGPT: The History, Status Quo and Potential Future Development. IEEE/CAA J. Autom. Sin. 2023, 10, 1122–1136. [Google Scholar] [CrossRef]
- Fitria, T.N. QuillBot as an online tool: Students’ alternative in paraphrasing and rewriting of English writing. Englisia J. Lang. Educ. Humanit. 2021, 9, 183–196. [Google Scholar] [CrossRef]
- SpinBot—Article Spinning, Text Rewriting, Content Creation Tool. Available online: https://spinbot.com/ (accessed on 29 March 2024).
- Yu, P.; Chen, J.; Feng, X.; Xia, Z. CHEAT: A Large-scale Dataset for Detecting ChatGPT-writtEn AbsTracts. arXiv 2023, arXiv:2304.12008v2. [Google Scholar]
- Liao, W.; Liu, Z.; Dai, H.; Xu, S.; Wu, Z.; Zhang, Y.; Huang, X.; Zhu, D.; Cai, H.; Liu, T.; et al. Differentiate ChatGPT-generated and Human-written Medical Texts. arXiv 2023, arXiv:2304.11567. [Google Scholar] [CrossRef]
- Alamleh, H.; AlQahtani, A.A.S.; ElSaid, A. Distinguishing Human-Written and ChatGPT-Generated Text Using Machine Learning. In Proceedings of the 2023 Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 27–28 April 2023; Available online: https://ieeexplore.ieee.org/abstract/document/10137767/?casa_token=BlKrjOFl998AAAAA:1b4KRytwxB1ynRxSVQFS15jLxeBtpntkB9UxP7y-uct08P-iKuys0-l736FwJNRDASbCDht7_ZuOs8s (accessed on 5 September 2023).
- Chen, Y.; Kang, H.; Zhai, V.; Li, L.; Singh, R.; Raj, B. GPT-Sentinel: Distinguishing Human and ChatGPT Generated Content. arXiv 2023, arXiv:2305.07969v2. [Google Scholar]
- Katib, I.; Assiri, F.Y.; Abdushkour, H.A.; Hamed, D.; Ragab, M. Differentiating Chat Generative Pretrained Transformer from Humans: Detecting ChatGPT-Generated Text and Human Text Using Machine Learning. Mathematics 2023, 11, 3400. [Google Scholar] [CrossRef]
- Hamed, A.A.; Wu, X. Improving Detection of ChatGPT-Generated Fake Science Using Real Publication Text: Introducing xFakeBibs a Supervised-Learning Network Algorithm. arXiv 2023, arXiv:2308.11767. [Google Scholar]
- Perkins, M. Academic Integrity considerations of AI Large Language Models in the post-pandemic era: ChatGPT and beyond. J. Univ. Teach. Learn. Pract. 2023, 20, 7. [Google Scholar] [CrossRef]
- Maddigan, P.; Susnjak, T. Chat2VIS: Generating Data Visualizations via Natural Language Using ChatGPT, Codex and GPT-3 Large Language Models. IEEE Access 2023, 11, 45181–45193. [Google Scholar] [CrossRef]
- Kumarage, T.; Garland, J.; Bhattacharjee, A.; Trapeznikov, K.; Ruston, S.; Liu, H. Stylometric Detection of AI-Generated Text in Twitter Timelines. arXiv 2023, arXiv:2303.03697. [Google Scholar]
- Pardos, Z.A.; Bhandari, S. Learning gain differences between ChatGPT and human tutor generated algebra hints. arXiv 2023, arXiv:2302.06871v1. [Google Scholar]
- Dipta, S.R.; Shahriar, S. HU at SemEval-2024 Task 8A: Can Contrastive Learning Learn Embeddings to Detect Machine-Generated Text? arXiv 2024, arXiv:2402.11815v2. [Google Scholar]
- Tweet-Preprocessor PyPI. Available online: https://pypi.org/project/tweet-preprocessor/ (accessed on 31 October 2023).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL HLT 2019—2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies—Proceedings of the Conference, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. Available online: https://arxiv.org/abs/1810.04805v2 (accessed on 28 March 2024).
- Arase, Y.; Tsujii, J. Transfer Fine-Tuning: A BERT Case Study. In Proceedings of the EMNLP-IJCNLP 2019—2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Proceedings of the Conference, Hong Kong, China, 3–7 November 2019; pp. 5393–5404. [Google Scholar] [CrossRef]
- Evaluation Metrics Machine Learning. Available online: https://www.analyticsvidhya.com/blog/2019/08/11-important-model-evaluation-error-metrics/ (accessed on 8 December 2020).
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108v4. [Google Scholar]
- Alammary, A.S. BERT Models for Arabic Text Classification: A Systematic Review. Appl. Sci. 2022, 12, 5720. [Google Scholar] [CrossRef]
- Chawla, S.; Kaur, R.; Aggarwal, P. Text classification framework for short text based on TFIDF-FastText. Multimed. Tools Appl. 2023, 82, 40167–40180. [Google Scholar] [CrossRef]
- Li, Q.; Zhao, S.; Zhao, S.; Wen, J. Logistic Regression Matching Pursuit algorithm for text classification. Knowl. Based Syst. 2023, 277, 110761. Available online: https://www.sciencedirect.com/science/article/pii/S0950705123005117 (accessed on 29 March 2024). [CrossRef]
- Khan, T.A.; Sadiq, R.; Shahid, Z.; Alam, M.M.; Bin, M.; Su’ud, M. Sentiment Analysis using Support Vector Machine and Random Forest. J. Inform. Web Eng. 2024, 3, 67–75. [Google Scholar] [CrossRef]
- Kumar, P.; Wahid, A. Social Media Analysis for Sentiment Classification Using Gradient Boosting Machines. In Proceedings of the International Conference on Communication and Computational Technologies: ICCCT 2021, Chennai, India, 16–17 December 2021; pp. 923–934. [Google Scholar] [CrossRef]
- Shah, K.; Patel, H.; Sanghvi, D.; Shah, M. A comparative analysis of logistic regression, random forest and KNN models for the text classification. Augment. Hum. Res. 2020, 5, 12. [Google Scholar] [CrossRef]
- Charbuty, B.; Abdulazeez, A. Classification based on decision tree algorithm for machine learning. J. Appl. Sci. Technol. Trends 2021, 2, 20–28. [Google Scholar] [CrossRef]
- Saha, N.; Das, P.; Saha, H.N. Authorship attribution of short texts using multi-layer perceptron. Int. J. Appl. Pattern Recognit. 2018, 5, 251–259. [Google Scholar] [CrossRef]
- Zhang, X.; Xiong, G.; Hu, Y.; Zhu, F.; Dong, X.; Nyberg, T.R. A method of SMS spam filtering based on AdaBoost algorithm. In Proceedings of the 2016 12th World Congress on Intelligent Control and Automation (WCICA), Guilin, China, 12–15 June 2016. [Google Scholar] [CrossRef]
- Jafarzadeh, H.; Mahdianpari, M.; Gill, E.; Mohammadimanesh, F.; Homayouni, S. Bagging and Boosting Ensemble Classifiers for Classification of Multispectral, Hyperspectral and PolSAR Data: A Comparative Evaluation. Remote Sens. 2021, 13, 4405. [Google Scholar] [CrossRef]
- Han, T. Research on Chinese Patent Text Classification Based on SVM. In Proceedings of the 2nd International Conference on Mathematical Statistics and Economic Analysis, MSEA 2023, Nanjing, China, 26–28 May 2023. [Google Scholar] [CrossRef]
- Ghosh, A.; SahaRay, R.; Chakrabarty, S.; Bhadra, S. Robust generalised quadratic discriminant analysis. Pattern Recognit. 2021, 117, 107981. Available online: https://www.sciencedirect.com/science/article/pii/S0031320321001680 (accessed on 29 March 2024). [CrossRef]
- Cahyani, D.E.; Patasik, I. Performance comparison of tf-idf and word2vec models for emotion text classification. Bull. Electr. Eng. Inform. 2021, 10, 2780–2788. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Original Financial Tweet | ChatGPT-3.5 Regenerated Text | SpinBot Regenerated Text | QuillBot Regenerated Text |
|---|---|---|---|
| “oil price fall last month the pakistani consumer see half benefit”. | “Despite a recent fall in oil prices, Pakistani consumers only see half of the benefits”. | “oil cost fall last month the pakistani purchaser see half advantage”. | “When the price of oil fell last month, Pakistani consumers benefited by half”. |
| “so country borrow money pay interest loan burden future generation daily interest payment sit huge amount dead capital urban holding worth form govt-owned land building”. | “The country’s borrowing money to pay interest on loans burdens future generations, with daily interest payments sitting on a huge amount of dead capital in the form of government-owned land and buildings”. | “so country acquire cash pay revenue advance weight group of people yet to come everyday premium installment sit colossal sum dead capital metropolitan holding worth structure govt-possessed land building”. | “Therefore, the nation borrows money, pays interest on loans, and burdens future generations with daily interest payments while sitting on enormous amounts of dead capital from government-owned land buildings”. |
| Hardware Information | Related Configuration |
|---|---|
| Operating system | Windows 10 |
| Google Colab | Free Version |
| System Ram | 12.7 GB |
| Disk | 107.7 GB |
| CUDA Version | 12.2 |
| NVIDIA-SMI | 535.104.05 |
| GPU Memory | 12–16 GB |
| Hyperparameters | Appropriate Value |
|---|---|
| Optimizer | Adam |
| Learning Rate | 0.0001 |
| Epochs | 10 |
| Batch Size | 32 |
| Optimizer | Adam |
| Learning Rate | 0.0001 |
| Epochs | 10 |
| Model | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| BERT Base Cased | 0.73 | 0.73 | 0.73 | 0.72 |
| BERT Base Un-Cased | 0.68 | 0.68 | 0.67 | 0.67 |
| BERT Large Cased | 0.68 | 0.68 | 0.68 | 0.67 |
| BERT Large Un-Cased | 0.73 | 0.73 | 0.72 | 0.72 |
| Distilbert Base Cased | 0.63 | 0.64 | 0.63 | 0.63 |
| Distilbert Base Un-Cased | 0.64 | 0.64 | 0.63 | 0.63 |
| Model | ROC Curve |
|---|---|
| BERT Base Cased | 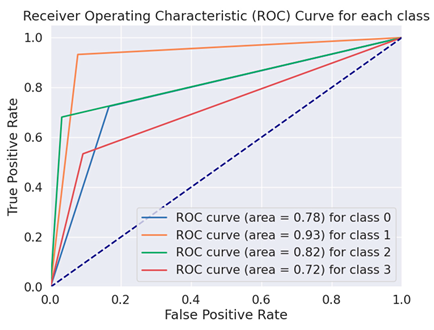 |
| BERT Base Un-Cased |  |
| BERT Large Cased | 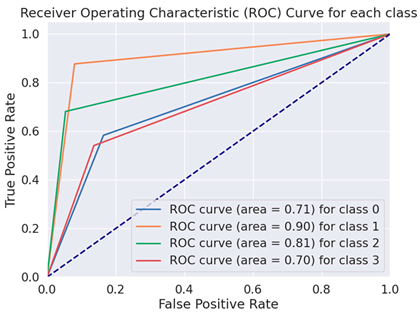 |
| BERT Large Un-Cased | 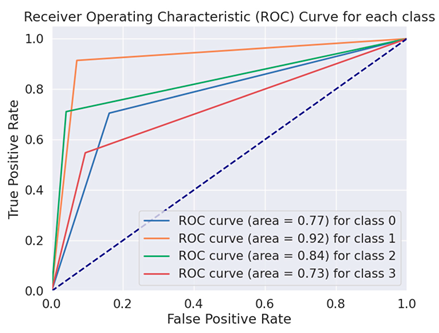 |
| Distilbert Base Cased | 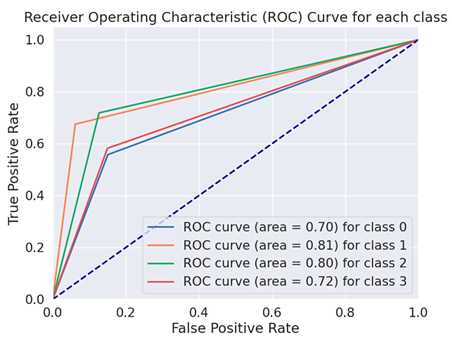 |
| Distilbert Base Un-Cased | 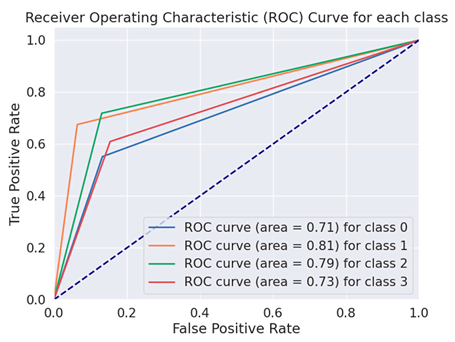 |
| Model | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| Logistic Regression [29] | 0.62 | 0.63 | 0.62 | 0.62 |
| Random Forest Classifier [30] | 0.56 | 0.57 | 0.56 | 0.57 |
| Gradient Boosting Classifier [31] | 0.64 | 0.66 | 0.64 | 0.64 |
| K-Neighbors Classifier [32] | 0.34 | 0.34 | 0.34 | 0.34 |
| Decision Tree Classifier [33] | 0.48 | 0.49 | 0.48 | 0.49 |
| MLP Classifier [34] | 0.52 | 0.53 | 0.52 | 0.52 |
| AdaBoost Classifier [35] | 0.56 | 0.57 | 0.56 | 0.55 |
| Bagging Classifier [36] | 0.52 | 0.52 | 0.52 | 0.52 |
| SVC [37] | 0.62 | 0.63 | 0.62 | 0.63 |
| Quadratic Discriminant Analysis [38] | 0.17 | 0.25 | 0.17 | 0.15 |
| Model | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| Logistic Regression [29] | 0.57 | 0.57 | 0.57 | 0.56 |
| Random Forest Classifier [30] | 0.47 | 0.47 | 0.47 | 0.47 |
| Gradient Boosting Classifier [31] | 0.47 | 0.47 | 0.47 | 0.47 |
| K-Neighbors Classifier [32] | 0.46 | 0.45 | 0.46 | 0.45 |
| Decision Tree Classifier [33] | 0.40 | 0.40 | 0.40 | 0.40 |
| MLP Classifier [34] | 0.59 | 0.59 | 0.59 | 0.58 |
| AdaBoost Classifier [35] | 0.54 | 0.52 | 0.54 | 0.52 |
| Bagging Classifier [36] | 0.44 | 0.44 | 0.44 | 0.44 |
| SVC [37] | 0.53 | 0.56 | 0.53 | 0.52 |
| Quadratic Discriminant Analysis [38] | 0.52 | 0.40 | 0.52 | 0.38 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arshed, M.A.; Gherghina, Ș.C.; Dur-E-Zahra; Manzoor, M. Prediction of Machine-Generated Financial Tweets Using Advanced Bidirectional Encoder Representations from Transformers. Electronics 2024, 13, 2222. https://doi.org/10.3390/electronics13112222
Arshed MA, Gherghina ȘC, Dur-E-Zahra, Manzoor M. Prediction of Machine-Generated Financial Tweets Using Advanced Bidirectional Encoder Representations from Transformers. Electronics. 2024; 13(11):2222. https://doi.org/10.3390/electronics13112222
Chicago/Turabian StyleArshed, Muhammad Asad, Ștefan Cristian Gherghina, Dur-E-Zahra, and Mahnoor Manzoor. 2024. "Prediction of Machine-Generated Financial Tweets Using Advanced Bidirectional Encoder Representations from Transformers" Electronics 13, no. 11: 2222. https://doi.org/10.3390/electronics13112222
APA StyleArshed, M. A., Gherghina, Ș. C., Dur-E-Zahra, & Manzoor, M. (2024). Prediction of Machine-Generated Financial Tweets Using Advanced Bidirectional Encoder Representations from Transformers. Electronics, 13(11), 2222. https://doi.org/10.3390/electronics13112222