

Enhancing IoT Security: Optimizing Anomaly Detection through Machine Learning


Abstract
1. Introduction
1.1. Contributions
1.2. Paper Layout
2. Related Works
3. Materials and Methods
3.1. Learning Models for Anomaly Detection
3.1.1. Extreme Gradient Boosting
3.1.2. Support Vector Machines
3.1.3. Deep Convolutional Neural Networks
3.2. Datasets
3.2.1. IoT-23 Dataset
3.2.2. NSL-KDD Dataset
3.2.3. TON_IoT Dataset
3.3. Data Preprocessing and Model Training
3.3.1. Preprocessing the IoT-23 Dataset
3.3.2. Preprocessing the NSL-KDD Dataset
3.3.3. Preprocessing the TON_IoT Dataset
3.3.4. Training XGBoost
3.3.5. Training SVMs
3.3.6. Training DCNN
4. Evaluation Metrics
5. Results
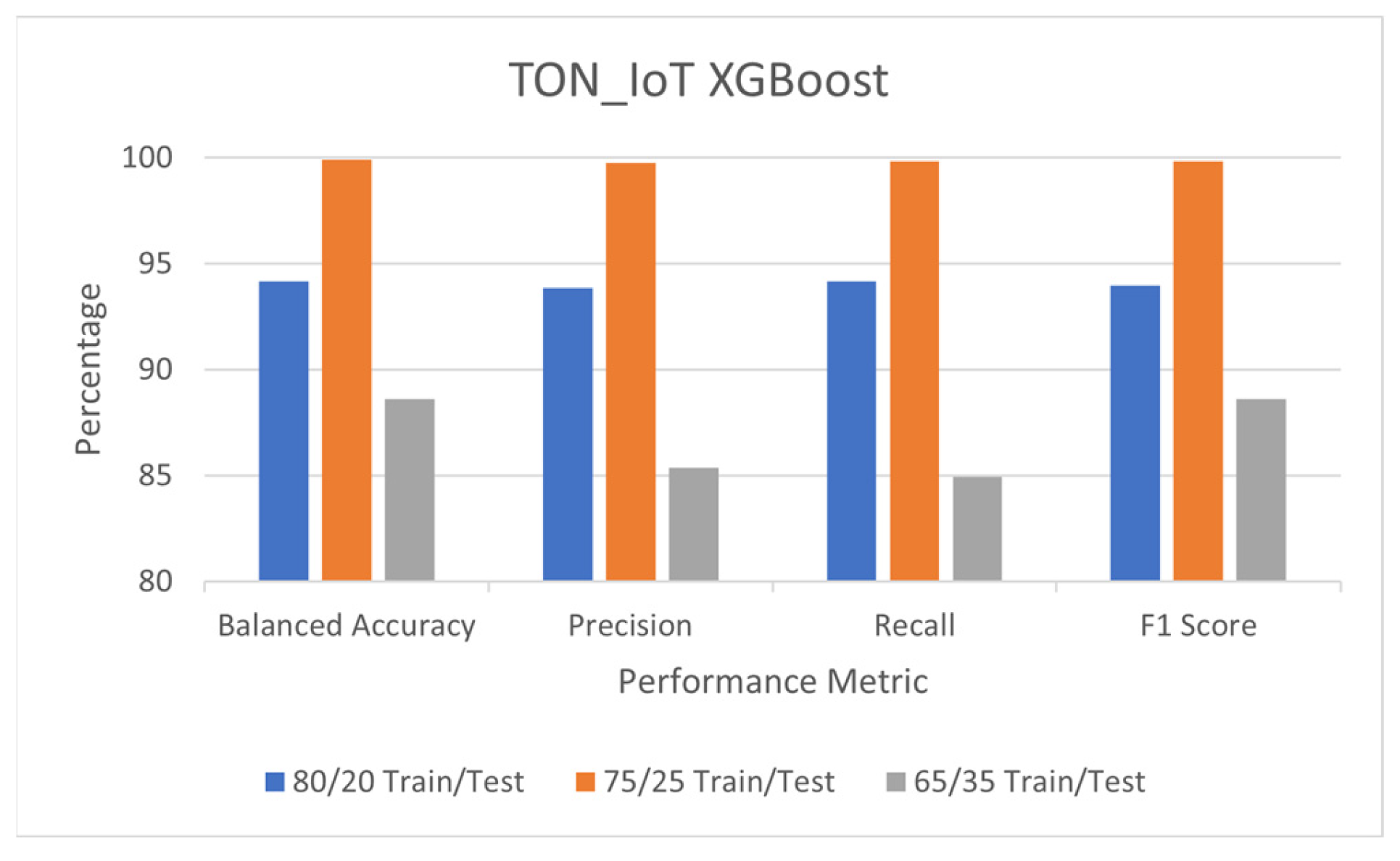
5.1. Detection Performance of XGBoost
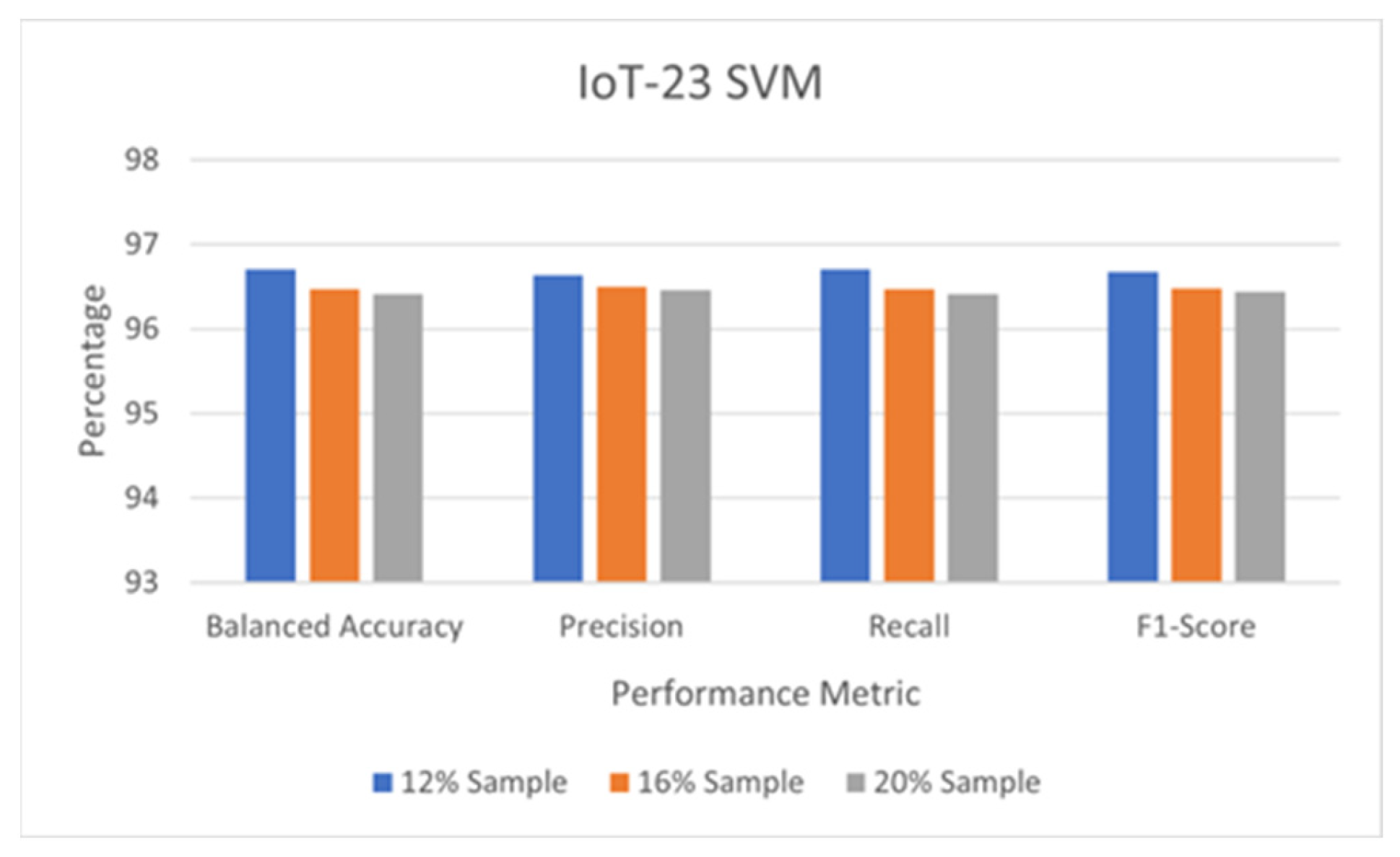
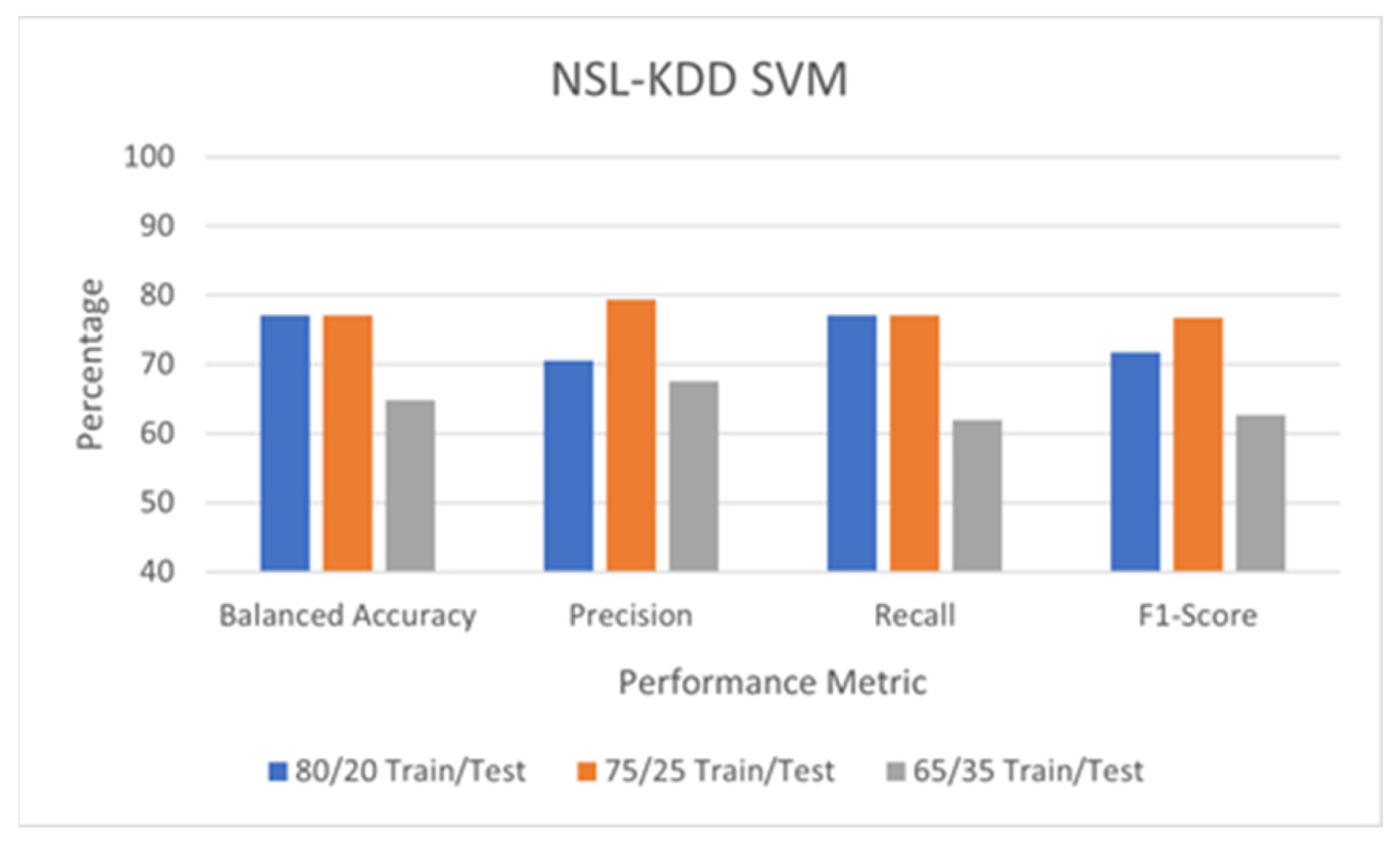
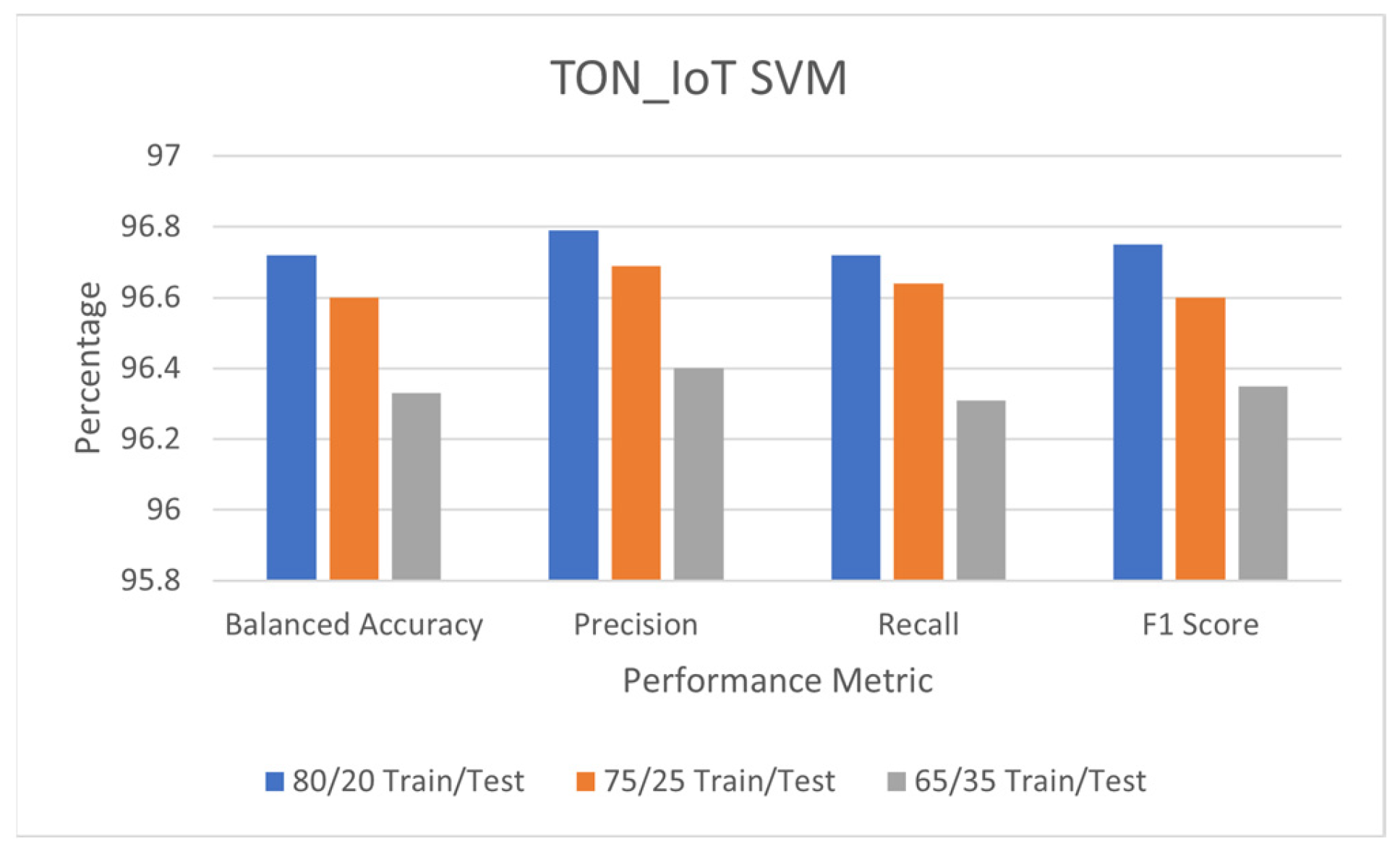
5.2. Detection Performance of SVM
5.3. Detection Performance of the DCNN
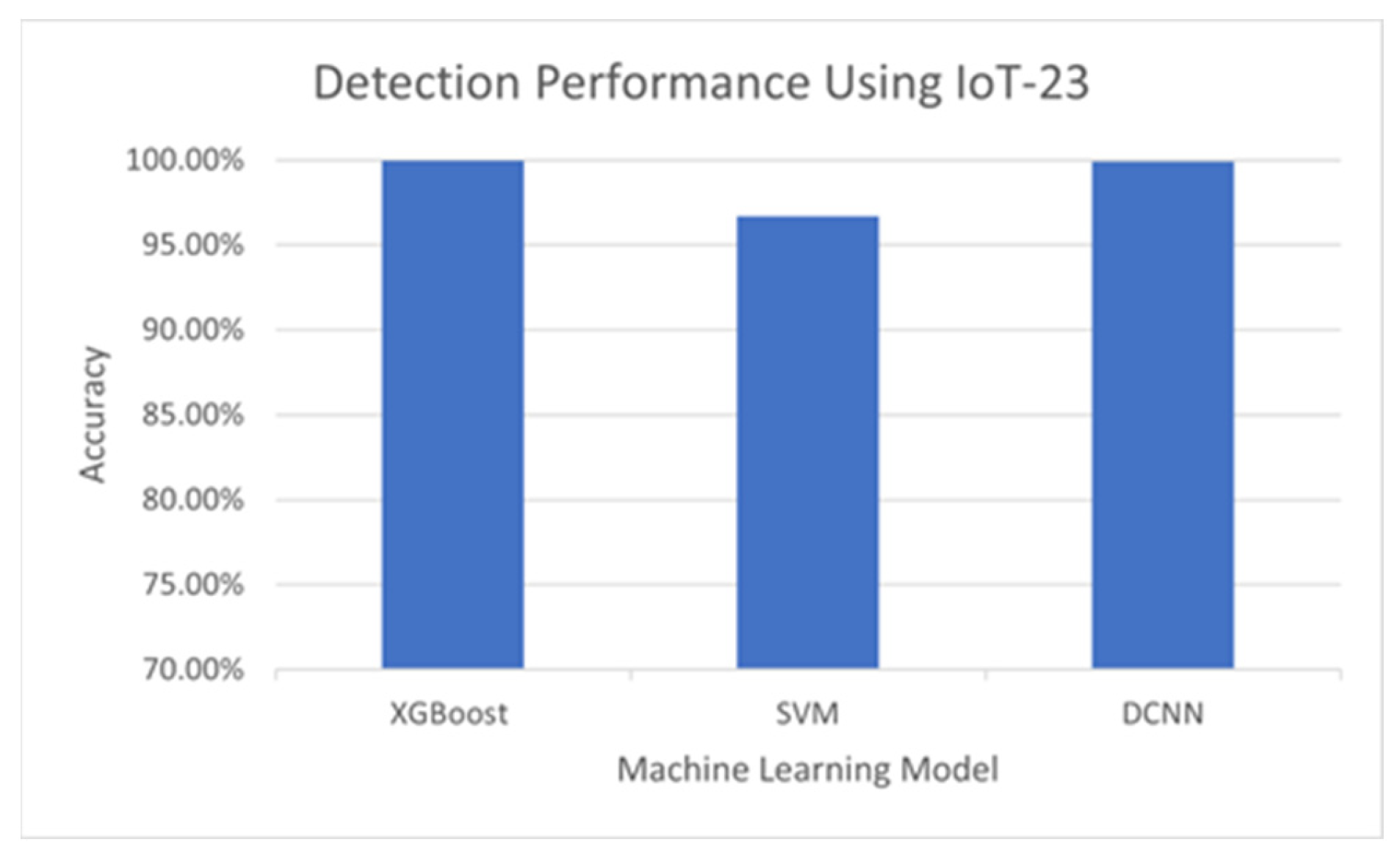
5.4. Comparison of Detection Performance
6. Efficiency, Real-World Data, and Limitation Discussion
6.1. Efficiency
6.2. Verification with Real-World Data
6.3. Limitation Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hossain, M.; Kayas, G.; Hasan, R.; Skjellum, A.; Noor, S.; Islam, S.M.R. A Holistic Analysis of Internet of Things (IoT) Security: Principles, Practices, and New Perspectives. Future Internet 2024, 16, 40. [Google Scholar] [CrossRef]
- Cole, T. Interview with Kevin Ashton—Inventor of IoT: Is Driven by the Users. Available online: https://www.avnet.com/wps/portal/silica/resources/article/interview-with-iot-inventor-kevin-ashton-iot-is-driven-by-the-users/ (accessed on 1 April 2022).
- Al-Hejri, I.; Azzedin, F.; Almuhammadi, S.; Eltoweissy, M. Lightweight Secure and Scalable Scheme for Data Transmission in the Internet of Things. Arab. J. Sci. Eng. 2024. [Google Scholar] [CrossRef]
- Vailshery, L.S. Global IoT and Non-IoT Connections 2010–2025. Available online: https://www.statista.com/statistics/1101442/iot-number-of-connected-devices-worldwide/ (accessed on 1 April 2022).
- Posey, B.; Shea, S. What Are IoT Devices?—Definition from Techtarget.com. Available online: https://internetofthingsagenda.techtarget.com/definition/IoT-device (accessed on 1 April 2022).
- Shea, S.; Wigmore, I. IoT Security (Internet of Things Security). Available online: https://www.techtarget.com/iotagenda/definition/IoT-security-Internet-of-Things-security (accessed on 1 April 2022).
- Wu, X.W.; Cao, Y.; Dankwa, R. Accuracy vs Efficiency: Machine Learning Enabled Anomaly Detection on the Internet of Things. In Proceedings of the IEEE International Conference on Internet of Things and Intelligence Systems, Bali, Indonesia, 24–26 November 2022; pp. 245–251. [Google Scholar]
- Fraihat, S.; Makhadmeh, S.; Awad, M.; Al-Betar, M.A.; Al-Redhaei, A. Intrusion detection system for large-scale IoT NetFlow networks using machine learning with modified Arithmetic Optimization Algorithm. Internet Things 2023, 22, 100819. [Google Scholar] [CrossRef]
- Awad, M.; Fraihat, S.; Salameh, K.; Al Redhaei, A. Examining the Suitability of NetFlow Features in Detecting IoT Network Intrusions. Sensors 2022, 22, 6164. [Google Scholar] [CrossRef] [PubMed]
- Garcia, S.; Parmisano, A.; Erquiaga, M.J. IoT-23: A Labeled Dataset with Malicious and Benign IoT Network Traffic (Version 1.0.0). 2020. Available online: https://www.stratosphereips.org/datasets-iot23 (accessed on 18 February 2021).
- NSL-KDD Dataset. Available online: https://www.unb.ca/cic/datasets/nsl.html (accessed on 18 February 2021).
- TON_IoT Datasets. Available online: https://research.unsw.edu.au/projects/toniot-datasets (accessed on 18 February 2021).
- Hossain, M.T.; Imran, M.A. ToN-IoT: A dataset for traffic analysis of IoT devices. In Proceedings of the IEEE International Conference on Communications, Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Alsaedi, A.; Moustafa, N.; Tari, Z.; Mahmood, A.; Anwar, A. TON_IoT Telemetry Dataset: A New Generation Dataset of IoT and IIoT for Data-Driven Intrusion Detection Systems. IEEE Access 2022, 8, 165130–165150. [Google Scholar] [CrossRef]
- Cañedo, J.; Skjellum, A. Using Machine Learning to secure IoT systems. In Proceedings of the 2016 14th Annual Conference on Privacy, Security and Trust (PST), Auckland, New Zealand, 12–14 December 2016; pp. 219–222. [Google Scholar]
- Hussain, F.; Hussain, R.; Hassan, S.A.; Hossain, E. Machine Learning in IoT security: Current solutions and future challenges. IEEE Commun. Surv. Tutor. 2020, 22, 1686–1721. [Google Scholar] [CrossRef]
- Dalal, K.R. Analyzing the role of supervised and unsupervised Machine Learning in IoT. In Proceedings of the 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 2–4 July 2020; pp. 75–79. [Google Scholar]
- Vitorino, J.; Andrade, R.; Praca, I.; Sousa, O.; Maia, E. A Comparative Analysis of Machine Learning Techniques for IoT Intrusion Detection. In Proceedings of the 14th International Symposium on Foundations and Practice of Security (FPS 2021), Paris, France, 7–10 December 2021; pp. 191–207. [Google Scholar]
- Diro, A.; Chilamkurti, N.; Nguyen, V.D.; Heyne, W. A Comprehensive Study of Anomaly Detection Schemes in IoT Networks Using Machine Learning Algorithms. Sensors 2021, 21, 8320. [Google Scholar] [CrossRef] [PubMed]
- Balega, M.; Farag, W.; Ezekiel, S.; Wu, X.-W.; Deak, A.; Good, Z. IoT Anomaly Detection Using a Multitude of Machine Learning Algorithms. In Proceedings of the 2022 IEEE Applied Imagery Pattern Recognition Workshop, Washington, DC, USA, 11–13 October 2022; pp. 1–6. [Google Scholar]
- Good, Z.; Farag, W.; Wu, X.-W.; Ezekiel, S.; Balega, M.; May, F.; Deak, A. Comparative Analysis of Machine Learning Techniques for IoT Anomaly Detection Using the NSL-KDD Dataset. Int. J. Comput. Sci. Netw. Secur. 2023, 23, 46–52. [Google Scholar]
- What Is Machine Learning? Available online: https://www.ibm.com/cloud/learn/machine-learning (accessed on 1 April 2022).
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009; Volume 2. [Google Scholar]
- Chang, W.; Liu, Y.; Xiao, Y.; Yuan, X.; Xu, X.; Zhang, S.; Zhou, S. A Machine Learning based prediction method for hypertension outcomes based on medical data. Diagnostics 2019, 9, 178. [Google Scholar] [CrossRef] [PubMed]
- XGBoost Documentation. Available online: https://xgboost.readthedocs.io/en/stable/index.html (accessed on 1 June 2021).
- Vapnik, V. Estimation of Dependences Based on Empirical Data; Springer: New York, NY, USA, 2006. [Google Scholar] [CrossRef]
- Jakkula, V. Tutorial on Support Vector Machine (SVM); School of EECS, Washington State University: Pullman, WA, USA, 2006; Volume 37, p. 3. [Google Scholar]
- Pupale, R. Support Vector Machines (SVM)—An Overview. Available online: https://towardsdatascience.com/https-medium-com-pupalerushikesh-svm-f4b42800e989 (accessed on 1 April 2022).
- Deep Convolutional Neural Networks. Available online: https://www.run.ai/guides/deep-learning-for-computer-vision/deep-convolutional-neural-networks (accessed on 1 April 2022).
- Stoian, N. Machine Learning for Anomaly Detection in IoT Networks: Malware Analysis on the IoT-23 Dataset. Bachelor’s Thesis, University of Twente, Enschede, The Netherlands, 2020. [Google Scholar]
- Lippmann, R.; Fried, D.; Graf, I.; Haines, J.; Kendall, K.; McClung, D.; Weber, D.; Webster, S.; Wyschogrod, D.; Cunningham, R.; et al. Evaluating intrusion detection systems: The 1998 darpa offline intrusion detection evaluation. In Proceedings of the DARPA Information Survivability Conference and Exposition, DISCEX’00, Hilton Head, SC, USA, 25–27 January 2000; Volume 2, pp. 12–26. [Google Scholar]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD Cup 99 dataset. In Proceedings of the IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Revathi, S.; Malathi, A. A detailed analysis on the NSL-KDD dataset using various machine learning techniques for intrusion detection. Int. J. Eng. Res. Technol. 2013, 2, 1848–1853. [Google Scholar]
- Moustafa, N.; Keshky, M.; Debiez, E.; Janicke, H. Federated TON_IoT Windows Datasets for Evaluating AI-Based Security Applications. In Proceedings of the IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Guangzhou, China, 29 December 2020; pp. 848–855. [Google Scholar]
- Hale, J. The 3 Most Important Composite Classification Metrics. Available online: https://towardsdatascience.com/the-3-most-important-composite-classification-metrics-b1f2d886dc7b (accessed on 1 April 2022).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Publications vs. This Paper | Dataset Features Selected (to Increase Detection Accuracy)? | Identified the Optimal Detection Model Regarding Accuracy? | Multiple Datasets Used? | Detection Efficiency Thoroughly Studied? |
|---|---|---|---|---|
| [7] | N/A * | Compared ML models regarding accuracy and identified the most accurate ML model | No | Compared ML models regarding accuracy and identified the most accurate ML model |
| [8] | Yes | Studied only one detection model | Yes | N/A |
| [9] | Yes | Studied only one detection model | Yes | N/A |
| [15] | No | Yes | No | No |
| [19] | No | Yes | No | No |
| [20] | No | Yes | No | No |
| [21] | No | Yes | No | No |
| This paper | Yes | Compared ML models regarding accuracy and identified the most accurate ML model | Used multiple datasets to evaluate the ML models’ performance in different environments | Compared ML models regarding accuracy and identified the most accurate ML model |
| Network | Depth/Layers | Parameters | Image Size |
|---|---|---|---|
| AlexNet | 8 | 61 | 227 × 227 |
| GoogleNet | 22 | 4 | 224 × 224 |
| ResNet-50 | 50 | 23 | 224 × 224 |
| VGG16 | 16 | 138 | 224 × 224 |
| VGG19 | 19 | 144 | 224 × 224 |
| Label Encoding | Type of Capture |
|---|---|
| 0 | Benign |
| 1 | DDoS |
| 2 | Okiru |
| 3 | PartOfAHorizontalPortScan |
| DCNN | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| AlexNet | ||||
| 80/20 | 94.59 | 88.10 | 72.99 | 79.84 |
| 75/25 | 95.94 | 96.64 | 76.19 | 85.21 |
| 70/30 | 97.13 * | 96.43 | 92.01 | 88.64 |
| 65/35 | 95.87 | 97.06 | 75.99 | 85.24 |
| GoogleNet | ||||
| 80/20 | 98.37 | 98.61 | 90.49 | 94.38 |
| 75/25 | 97.47 | 98.07 | 81.77 | 89.18 |
| 70/30 | 99.16 * | 96.64 | 97.41 | 97.03 |
| 65/35 | 85.96 | 42.95 | 49.86 | 46.15 |
| ResNet-50 | ||||
| 80/20 | 99.85 * | 99.28 | 99.48 | 99.38 |
| 75/25 | 99.81 | 99.45 | 99.11 | 99.28 |
| 70/30 | 99.79 | 99.63 | 98.98 | 99.30 |
| 65/35 | 99.48 | 98.60 | 99.36 | 98.98 |
| VGG16 | ||||
| 80/20 | 99.83 | 99.54 | 99.35 | 99.44 |
| 75/25 | 99.64 | 99.39 | 98.21 | 98.80 |
| 70/30 | 99.42 | 96.65 | 99.02 | 97.82 |
| 65/35 | 99.90 * | 99.86 | 99.31 | 99.59 |
| VGG19 | ||||
| 80/20 | 99.63 | 99.67 | 97.42 | 98.53 |
| 75/25 | 98.22 | 99.00 | 91.44 | 95.07 |
| 70/30 | 99.69 * | 99.61 | 97.93 | 98.76 |
| 65/35 | 99.21 | 99.45 | 91.17 | 96.74 |
| DCNN | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| AlexNet | ||||
| 80/20 | 90.60 | 90.53 | 90.63 | 90.58 |
| 75/25 | 90.53 | 90.50 | 90.70 | 90.60 |
| 70/30 | 90.79 * | 91.23 | 90.45 | 90.84 |
| 65/35 | 90.59 | 90.82 | 90.34 | 90.58 |
| GoogleNet | ||||
| 80/20 | 93.49 | 93.42 | 93.57 | 93.49 |
| 75/25 | 92.81 | 92.84 | 92.71 | 92.77 |
| 70/30 | 92.15 | 92.16 | 92.36 | 92.26 |
| 65/35 | 93.75 * | 93.69 | 93.80 | 93.74 |
| ResNet-50 | ||||
| 80/20 | 96.19 * | 96.15 | 96.21 | 96.18 |
| 75/25 | 94.86 | 94.84 | 94.83 | 94.84 |
| 70/30 | 94.71 | 94.86 | 94.55 | 94.70 |
| 65/35 | 94.66 | 94.60 | 94.77 | 94.69 |
| VGG16 | ||||
| 80/20 | 95.20 * | 95.41 | 95.01 | 95.21 |
| 75/25 | 94.33 | 94.38 | 94.23 | 94.30 |
| 70/30 | 93.20 | 93.23 | 93.44 | 93.33 |
| 65/35 | 94.78 | 94.96 | 94.60 | 94.78 |
| VGG19 | ||||
| 80/20 | 92.97 | 93.02 | 93.22 | 93.11 |
| 75/25 | 93.95 | 94.03 | 93.83 | 93.93 |
| 70/30 | 95.02 | 94.96 | 95.07 | 95.02 |
| 65/35 | 95.23 * | 95.21 | 95.19 | 95.20 |
| DCNN | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| AlexNet | ||||
| 80/20 | 64.08 | 69.66 | 65.07 | 67.29 |
| 75/25 | 67.02 | 75.48 | 68.12 | 71.61 |
| 70/30 | 92.29 * | 92.71 | 92.11 | 92.41 |
| 65/35 | 89.14 | 91.30 | 88.70 | 89.98 |
| GoogleNet | ||||
| 80/20 | 54.80 | 55.98 | 55.42 | 55.70 |
| 75/25 | 61.03 | 63.15 | 61.71 | 62.42 |
| 70/30 | 87.83 * | 89.26 | 87.46 | 88.35 |
| 65/35 | 81.04 | 81.01 | 81.01 | 81.01 |
| ResNet-50 | ||||
| 80/20 | 92.98 * | 92.96 | 93.01 | 92.98 |
| 75/25 | 90.82 | 91.38 | 90.6 | 90.99 |
| 70/30 | 88.93 | 91.13 | 88.48 | 89.78 |
| 65/35 | 89.03 | 91.22 | 88.57 | 89.88 |
| VGG16 | ||||
| 80/20 | 84.98 * | 86.24 | 84.60 | 85.41 |
| 75/25 | 63.39 | 68.40 | 64.35 | 66.32 |
| 70/30 | 70.98 | 80.84 | 72.08 | 76.21 |
| 65/35 | 74.81 | 78.53 | 72.08 | 76.21 |
| VGG19 | ||||
| 80/20 | 69.88 | 73.52 | 70.62 | 71.04 |
| 75/25 | 71.79 | 72.71 | 72.14 | 72.43 |
| 70/30 | 86.76 | 88.41 | 86.34 | 87.37 |
| 65/35 | 88.85 * | 91.12 | 88.39 | 89.74 |
| XGBoost | SVM | DCNN | |
|---|---|---|---|
| Training (s) | 0.7748 | 556.11 | 9916.9 |
| Testing (s) | 0.0032 | 79.06 | 342.49 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Balega, M.; Farag, W.; Wu, X.-W.; Ezekiel, S.; Good, Z. Enhancing IoT Security: Optimizing Anomaly Detection through Machine Learning. Electronics 2024, 13, 2148. https://doi.org/10.3390/electronics13112148
Balega M, Farag W, Wu X-W, Ezekiel S, Good Z. Enhancing IoT Security: Optimizing Anomaly Detection through Machine Learning. Electronics. 2024; 13(11):2148. https://doi.org/10.3390/electronics13112148
Chicago/Turabian StyleBalega, Maria, Waleed Farag, Xin-Wen Wu, Soundararajan Ezekiel, and Zaryn Good. 2024. "Enhancing IoT Security: Optimizing Anomaly Detection through Machine Learning" Electronics 13, no. 11: 2148. https://doi.org/10.3390/electronics13112148
APA StyleBalega, M., Farag, W., Wu, X.-W., Ezekiel, S., & Good, Z. (2024). Enhancing IoT Security: Optimizing Anomaly Detection through Machine Learning. Electronics, 13(11), 2148. https://doi.org/10.3390/electronics13112148