
GraM: Geometric Structure Embedding into Attention Mechanisms for 3D Point Cloud Registration




Abstract
1. Introduction
- As far as authors know, this is the first proposal to embed the geometric structure into an improved REGTR network. The proposed GraM effectively promotes the local features integrated with information on geometric structure and global features.
- We introduce the attention mechanism to the point cloud registration task and optimize the feature extraction on the REGTR network, significantly improving the accuracy and efficiency of the low-overlap point cloud registration task.
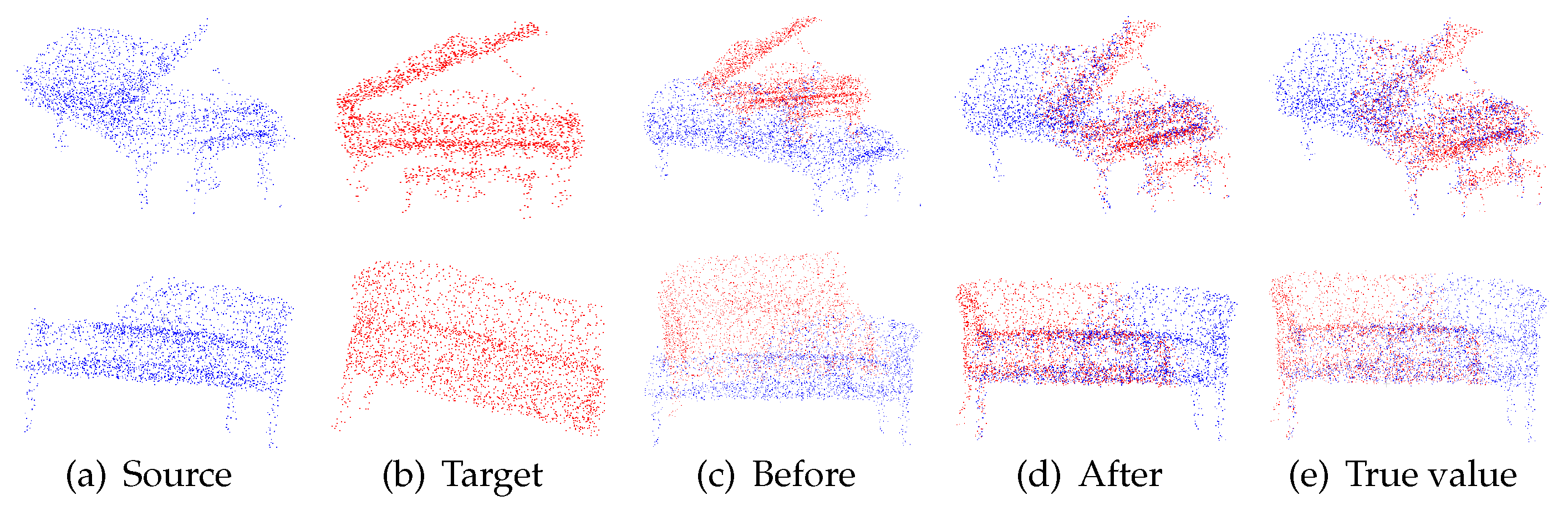
- Comprehensive experiments on the reconstructed ModelNet40 and KITTI datasets show that GraM obtains better accuracy than state-of-the-art methods.
2. Related Work
3. Preliminary
3.1. Problem Definition
3.2. Transformer Model
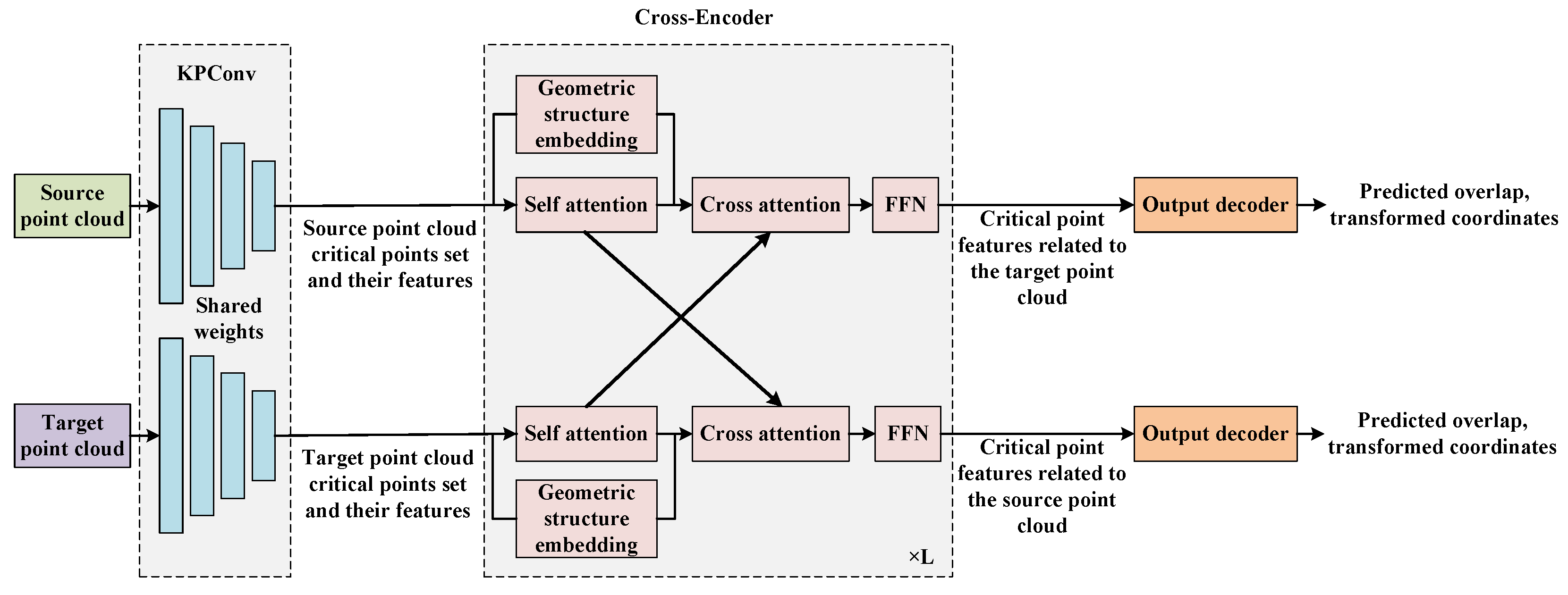
4. The Proposed Method
4.1. The Overall Network Architecture
4.1.1. Feature Extraction
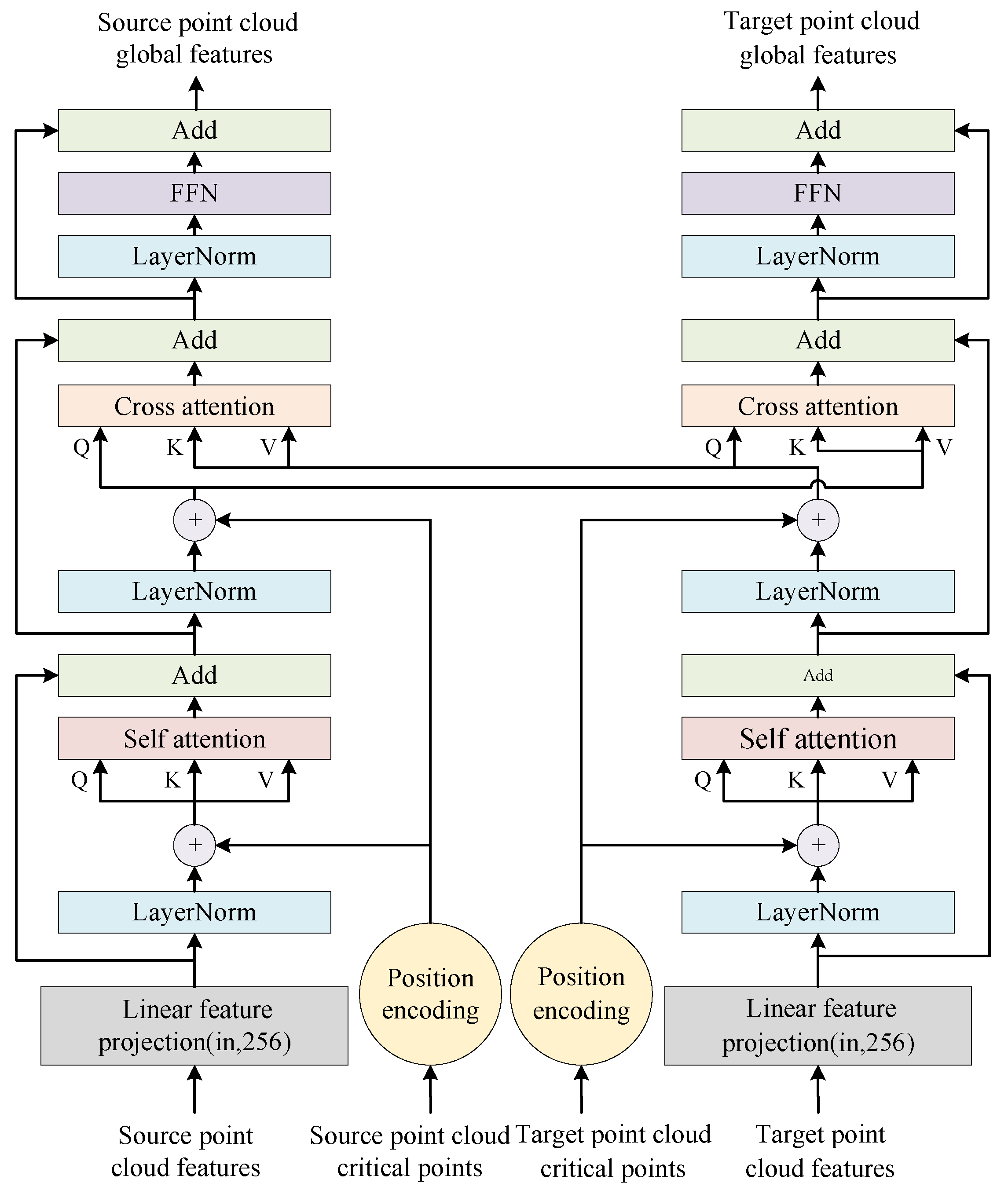
4.1.2. Cross-Encoder
4.1.3. Output Decoder
4.2. The Loss Function
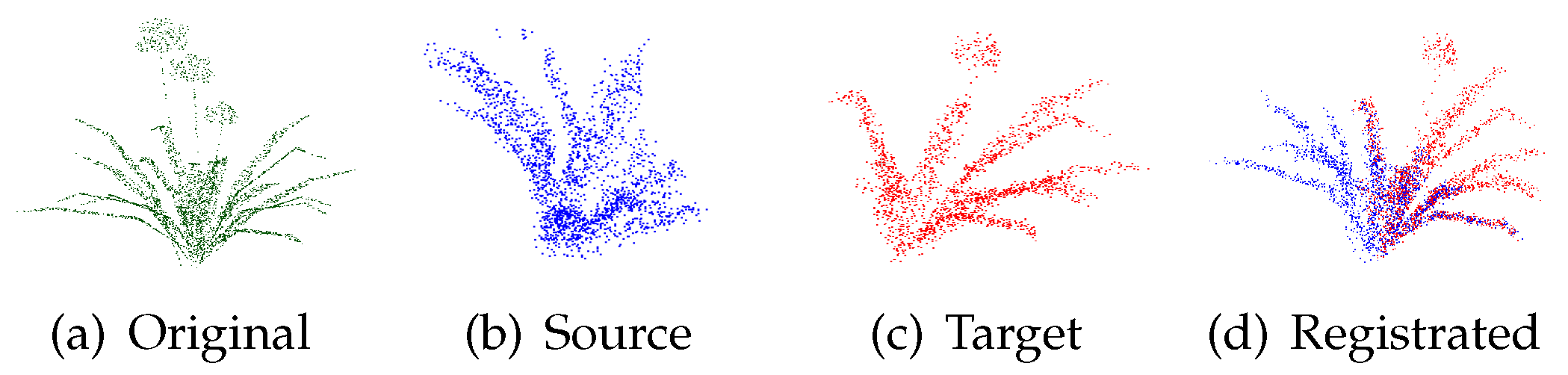
5. Experiments
5.1. Dataset
5.2. Evaluation Metrics
5.3. Baselines
5.4. Experimental Setup
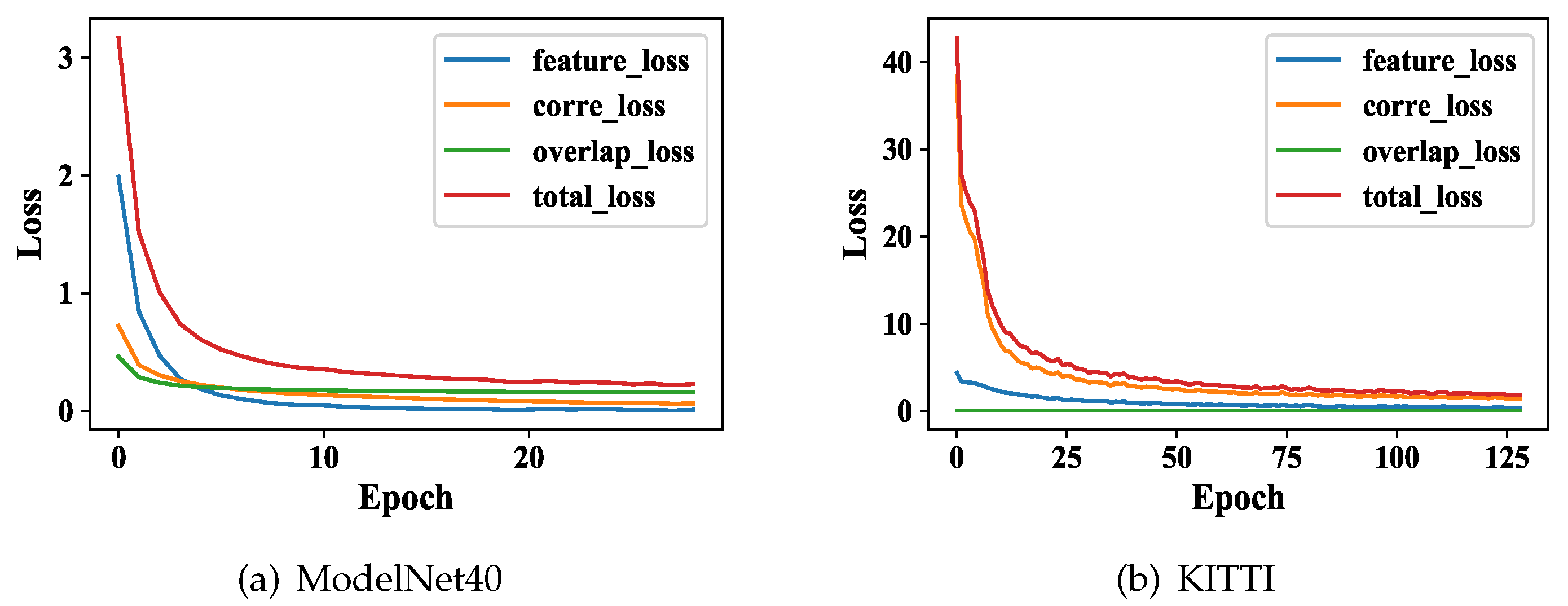
5.5. Convergence Analysis
5.6. Comparison with State-of-the-Art Methods
5.7. Analysis Sensitivity of Sampling Radius
5.8. Ablation Studies
5.8.1. Effectiveness of GraM’s Each Component
5.8.2. Effectiveness of GraM with Different Loss Functions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Azuma, R.T. A survey of augmented reality. Presence Teleoperators Virtual Environ. 1997, 6, 355–385. [Google Scholar] [CrossRef]
- Carmigniani, J.; Furht, B.; Anisetti, M.; Ceravolo, P.; Damiani, E.; Ivkovic, M. Augmented reality technologies, systems and applications. Multimed. Tools Appl. 2011, 51, 341–377. [Google Scholar] [CrossRef]
- Billinghurst, M.; Clark, A.; Lee, G. A survey of augmented reality. Now 2015, 8, 73–272. [Google Scholar]
- Liu, D.; Long, C.; Zhang, H.; Yu, H.; Dong, X.; Xiao, C. ARShadowGAN: Shadow generative adversarial network for augmented reality in single light scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8139–8148. [Google Scholar]
- Popișter, F.; Popescu, D.; Păcurar, A.; Păcurar, R. Mathematical Approach in Complex Surfaces Toolpaths. Mathematics 2021, 9, 1360. [Google Scholar] [CrossRef]
- Luo, K.; Yang, G.; Xian, W.; Haraldsson, H.; Hariharan, B.; Belongie, S. Stay Positive: Non-Negative Image Synthesis for Augmented Reality. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10050–10060. [Google Scholar]
- Joseph, K.; Khan, S.; Khan, F.S.; Balasubramanian, V.N. Towards open world object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 5830–5840. [Google Scholar]
- Merickel, M. 3D reconstruction: The registration problem. Comput. Vis. Graph. Image Process. 1988, 42, 206–219. [Google Scholar] [CrossRef]
- Izadi, S.; Kim, D.; Hilliges, O.; Molyneaux, D.; Newcombe, R.; Kohli, P.; Shotton, J.; Hodges, S.; Freeman, D.; Davison, A.; et al. Kinectfusion: Real-time 3D reconstruction and interaction using a moving depth camera. In Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology, Santa Barbara, CA, USA, 16–19 October 2011; pp. 559–568. [Google Scholar]
- Pan, X.; Xia, Z.; Song, S.; Li, L.E.; Huang, G. 3D Object detection with pointformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7463–7472. [Google Scholar]
- Shi, X.; Ye, Q.; Chen, X.; Chen, C.; Chen, Z.; Kim, T.K. Geometry-based distance decomposition for monocular 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 15172–15181. [Google Scholar]
- Zou, Z.; Ye, X.; Du, L.; Cheng, X.; Tan, X.; Zhang, L.; Feng, J.; Xue, X.; Ding, E. The devil is in the task: Exploiting reciprocal appearance-localization features for monocular 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 2713–2722. [Google Scholar]
- Yew, Z.J.; Lee, G.H. REGTR: End-to-end point cloud correspondences with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 6677–6686. [Google Scholar]
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. Proc. SPIE 1992, 1611, 586–606. [Google Scholar] [CrossRef]
- Billings, S.D.; Boctor, E.M.; Taylor, R.H. Iterative most-likely point registration (IMLP): A robust algorithm for computing optimal shape alignment. PLoS ONE 2015, 10, e0117688. [Google Scholar] [CrossRef] [PubMed]
- Segal, A.; Haehnel, D.; Thrun, S. Generalized-ICP. In Proceedings of the Robotics: Science and Systems, Seattle, WA, USA, 28 June–1 July 2009; Volume 2, p. 435. [Google Scholar]
- Zhu, H.; Guo, B.; Zou, K.; Li, Y.; Yuen, K.V.; Mihaylova, L.; Leung, H. A review of point set registration: From pairwise registration to groupwise registration. Sensors 2019, 19, 1191. [Google Scholar] [CrossRef]
- Huang, S.; Gojcic, Z.; Usvyatsov, M.; Wieser, A.; Schindler, K. Predator: Registration of 3d point clouds with low overlap. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4267–4276. [Google Scholar]
- Zeng, A.; Song, S.; Nießner, M.; Fisher, M.; Xiao, J.; Funkhouser, T. 3DMatch: Learning local geometric descriptors from rgb-d reconstructions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1802–1811. [Google Scholar]
- Yew, Z.J.; Lee, G.H. 3DFeat-Net: Weakly supervised local 3d features for point cloud registration. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 607–623. [Google Scholar]
- Yew, Z.J.; Lee, G.H. RPM-Net: Robust point matching using learned features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11824–11833. [Google Scholar]
- Wang, Y.; Solomon, J.M. Deep closest point: Learning representations for point cloud registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3523–3532. [Google Scholar]
- Wang, H.; Liu, Y.; Dong, Z.; Wang, W. You only hypothesize once: Point cloud registration with rotation-equivariant descriptors. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 1630–1641. [Google Scholar]
- Zhang, Y.; Zhang, W.; Li, J. Partial-to-partial point cloud registration by rotation invariant features and spatial geometric consistency. Remote Sens. 2023, 15, 3054. [Google Scholar] [CrossRef]
- Liu, Q.; Zhu, H.; Zhou, Y.; Li, H.; Chang, S.; Guo, M. Density-invariant features for distant point cloud registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 18215–18225. [Google Scholar]
- Deng, H.; Birdal, T.; Ilic, S. 3D local features for direct pairwise registration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3244–3253. [Google Scholar]
- Aoki, Y.; Goforth, H.; Srivatsan, R.A.; Lucey, S. PointNetLK: Robust & efficient point cloud registration using pointnet. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 7163–7172. [Google Scholar]
- Baker, S.; Matthews, I. Lucas-kanade 20 years on: A unifying framework. Int. J. Comput. Vis. 2004, 56, 221–255. [Google Scholar] [CrossRef]
- Choy, C.; Dong, W.; Koltun, V. Deep global registration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2514–2523. [Google Scholar]
- Choy, C.; Park, J.; Koltun, V. Fully convolutional geometric features. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8958–8966. [Google Scholar]
- Yu, H.; Hou, J.; Qin, Z.; Saleh, M.; Shugurov, I.; Wang, K.; Busam, B.; Ilic, S. Riga: Rotation-invariant and globally-aware descriptors for point cloud registration. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 3796–3812. [Google Scholar] [CrossRef] [PubMed]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. KPConv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6411–6420. [Google Scholar]
- Qin, Z.; Yu, H.; Wang, C.; Guo, Y.; Peng, Y.; Ilic, S.; Hu, D.; Xu, K. GeoTransformer: Fast and Robust Point Cloud Registration With Geometric Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9806–9821. [Google Scholar] [CrossRef] [PubMed]
- Gojcic, Z.; Zhou, C.; Wegner, J.D.; Guibas, L.J.; Birdal, T. Learning multiview 3d point cloud registration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1759–1769. [Google Scholar]
- Kabsch, W. A solution for the best rotation to relate two sets of vectors. Acta Cryst. 1976, 32, 922–923. [Google Scholar] [CrossRef]
- Umeyama, S. Least-squares estimation of transformation parameters between two point patterns. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 376–380. [Google Scholar] [CrossRef]
- van den Oord, A.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Ind. Robot. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | ModelNet40 | LowModelNet40 | KITTI | |||
|---|---|---|---|---|---|---|
| RRE (°) | RTE (m) | RRE (°) | RTE (m) | RRE (°) | RTE (m) | |
| RPMNet | 1.712 | 0.018 | 7.342 | 0.124 | 1.021 | 0.633 |
| DCP | 11.975 | 0.171 | 16.501 | 0.300 | 0.965 | 0.583 |
| PointNetLK | 29.725 | 0.297 | 48.567 | 0.507 | 2.352 | 0.936 |
| REGTR | 1.473 | 0.014 | 3.930 | 0.087 | 0.482 | 0.425 |
| 3DFeatNet | 2.057 | 0.039 | 4.026 | 0.073 | 0.254 | 0.259 |
| Predator | 1.948 | 0.026 | 3.568 | 0.072 | 0.277 | 0.068 |
| DGR | 2.004 | 0.024 | 3.627 | 0.069 | 0.373 | 0.320 |
| GraM | 0.925 | 0.010 | 2.653 | 0.049 | 0.270 | 0.110 |
| Method | KITTI | |||
|---|---|---|---|---|
| RRE (°) | RTE (m) | RR (%) | TC (h) | |
| radius-0.4 | 0.352 | 0.214 | 97.3 | 4.27 |
| radius-0.5 | 0.413 | 0.325 | 96.1 | 6.24 |
| radius-0.3 | 0.270 | 0.110 | 99.8 | 3.51 |
| Method | ModelNet40 | KITTI | ||
|---|---|---|---|---|
| RRE (°) | RTE (m) | RRE (°) | RTE (m) | |
| Baseline (REGTR) * | 1.473 | 0.014 | 0.482 | 0.425 |
| Our GraM (REGTR+KPConv) † | 1.248 | 0.013 | 0.324 | 0.301 |
| Our Final GraM (REGTR+KPConv+GSE) ‡ | 0.925 | 0.010 | 0.270 | 0.110 |
| † relative to * | 0.225↓ | 0.001↓ | 0.158↓ | 0.124↓ |
| ‡ relative to † | 0.323↓ | 0.003↓ | 0.054↓ | 0.191↓ |
| Method | ModelNet40 | KITTI | |||
|---|---|---|---|---|---|
| RRE (°) | RTE (m) | RRE (°) | RTE (m) | RR(%) | |
| Baseline ( loss in Equation (12)) | 2.442 | 0.020 | 0.302 | 0.174 | 98.9 |
| Our GraM () | 2.206 | 0.016 | 0.345 | 0.142 | 98.6 |
| Our GraM () | 2.125 | 0.015 | 0.342 | 0.139 | 99.1 |
| Our GraM () | 2.241 | 0.017 | 0.351 | 0.153 | 98.0 |
| Our Final GraM () | 1.623 | 0.013 | 0.270 | 0.110 | 99.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, P.; Zhong, L.; Wang, R.; Zhu, J.; Zhai, X.; Zhang, J. GraM: Geometric Structure Embedding into Attention Mechanisms for 3D Point Cloud Registration. Electronics 2024, 13, 1995. https://doi.org/10.3390/electronics13101995
Liu P, Zhong L, Wang R, Zhu J, Zhai X, Zhang J. GraM: Geometric Structure Embedding into Attention Mechanisms for 3D Point Cloud Registration. Electronics. 2024; 13(10):1995. https://doi.org/10.3390/electronics13101995
Chicago/Turabian StyleLiu, Pin, Lin Zhong, Rui Wang, Jianyong Zhu, Xiang Zhai, and Juan Zhang. 2024. "GraM: Geometric Structure Embedding into Attention Mechanisms for 3D Point Cloud Registration" Electronics 13, no. 10: 1995. https://doi.org/10.3390/electronics13101995
APA StyleLiu, P., Zhong, L., Wang, R., Zhu, J., Zhai, X., & Zhang, J. (2024). GraM: Geometric Structure Embedding into Attention Mechanisms for 3D Point Cloud Registration. Electronics, 13(10), 1995. https://doi.org/10.3390/electronics13101995