
Research on Aspect-Level Sentiment Analysis Based on Adversarial Training and Dependency Parsing

Abstract
1. Introduction
- The introduction of dependency parsing information in aspect-level sentiment analysis. By constructing an adjacency matrix of syntactic dependency relations, the model can more precisely capture the semantic correlations between different aspects in the text, thereby improving the precision and accuracy of sentiment analysis;
- To better integrate the features of both BERT and syntactic dependency relations, a multi-head attention mechanism is adopted. This mechanism considers different feature word vectors simultaneously, allowing the model to comprehend the semantic information of the text more comprehensively, thereby enhancing the performance;
- In order to bolster the robustness and generalizability of the model, an adversarial training mechanism is introduced. By applying small perturbations to the BERT embedding layer, FGM (fast gradient method) can make the model better resist attacks from adversarial samples, thus improving the model’s stability and reliability in real-world applications.
2. Related Work
2.1. Aspect-Level Sentiment Analysis
2.2. Dependency Analysis
2.3. Adversarial Training
2.4. Attention Mechanisms
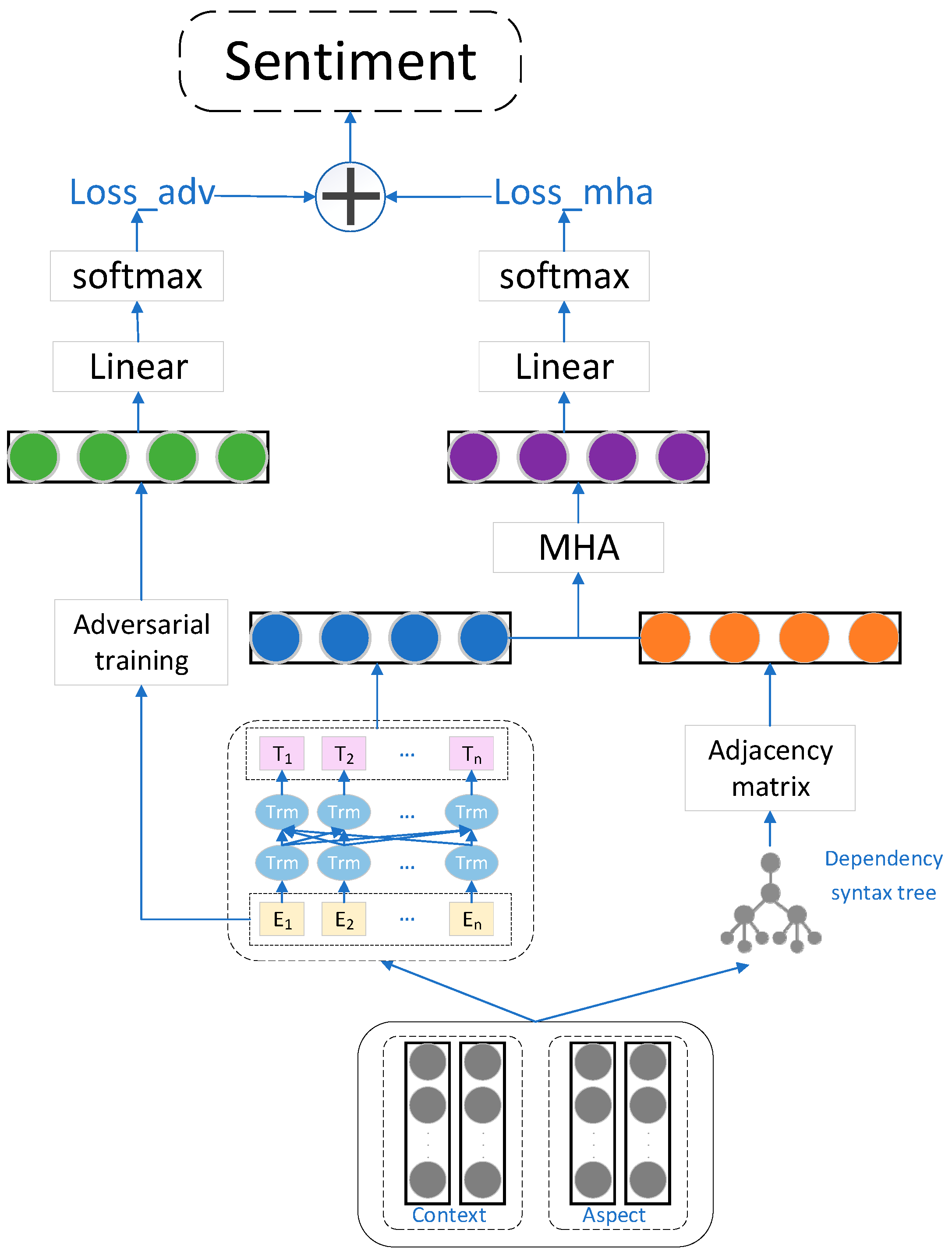
3. Overall Model Design
3.1. Task Definition
3.2. Model Architecture
3.2.1. Text Embedding Layer
3.2.2. BERT Encoding Layer
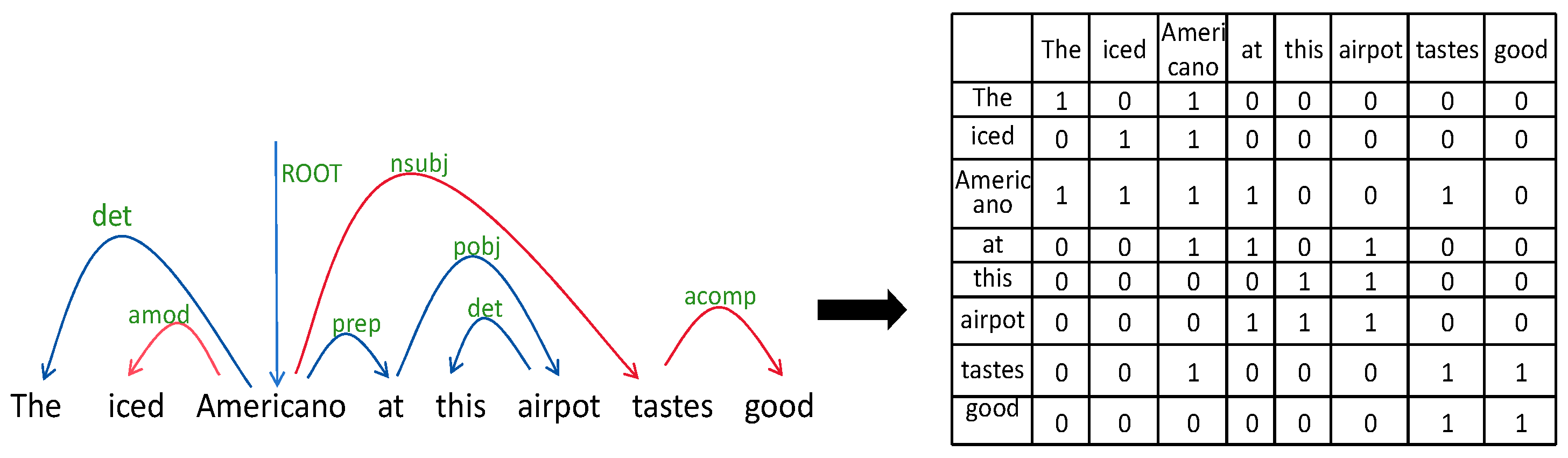
3.2.3. Dependency Syntax Relation Information Layer
3.2.4. Adversarial Training Layer
3.2.5. Multi-Head Attention Mechanism Layer
3.2.6. Output Layer
4. Experimental Analysis
4.1. Experimental Dataset and Experimental Environment
4.2. Experimental Parameter Setting
4.3. Evaluation Indicators
4.4. Comparative Experiments
- (1)
- LSTM [36] is an aspect-level sentiment analysis model based on long short-term memory networks that uses a recurrent neural network structure for modeling and can capture temporal information in text. It performs sentiment classification by integrating the target word and context relationships through two LSTM layers that depend on the target;
- (2)
- TD-LSTM [37] utilizes LSTM to encode the contexts on both sides of the aspect term from different directions, and performs sentiment classification by concatenating the resulting feature representations;
- (3)
- MemNet [38] is a deep memory network model combined with an attention mechanism. By constructing multiple computational layers, each input layer adaptively selects deeper-level information and captures the correlation between each context word and the aspect via attention layers. The output of the final attention layer is utilized for sentiment polarity assessment;
- (4)
- IAN [39] utilizes two LSTM layers to acquire the hidden representations of the context and aspect terms. To precisely capture the semantic relationship between context words and the aspect term, an interactive attention mechanism is incorporated;
- (5)
- RAM [40] is a memory neural network model based on a recurrent attention mechanism that can effectively obtain the sentiment features between words that are farther apart;
- (6)
- AEN [41] utilizes an encoder with an attention mechanism to establish a sentiment analysis model between the context and its corresponding aspect term;
- (7)
- ASGCN [42] constructs a graph convolutional network on the sentence’s dependency tree to extract syntactic information. By integrating attention with masked aspect vectors and semantic information, it enhances sentiment classification performance;
- (8)
- GPT3+Prompt [43] is a language model that can be guided to perform aspect-level sentiment analysis tasks and generate relevant text by adding prompts.
4.5. Ablation Experiment
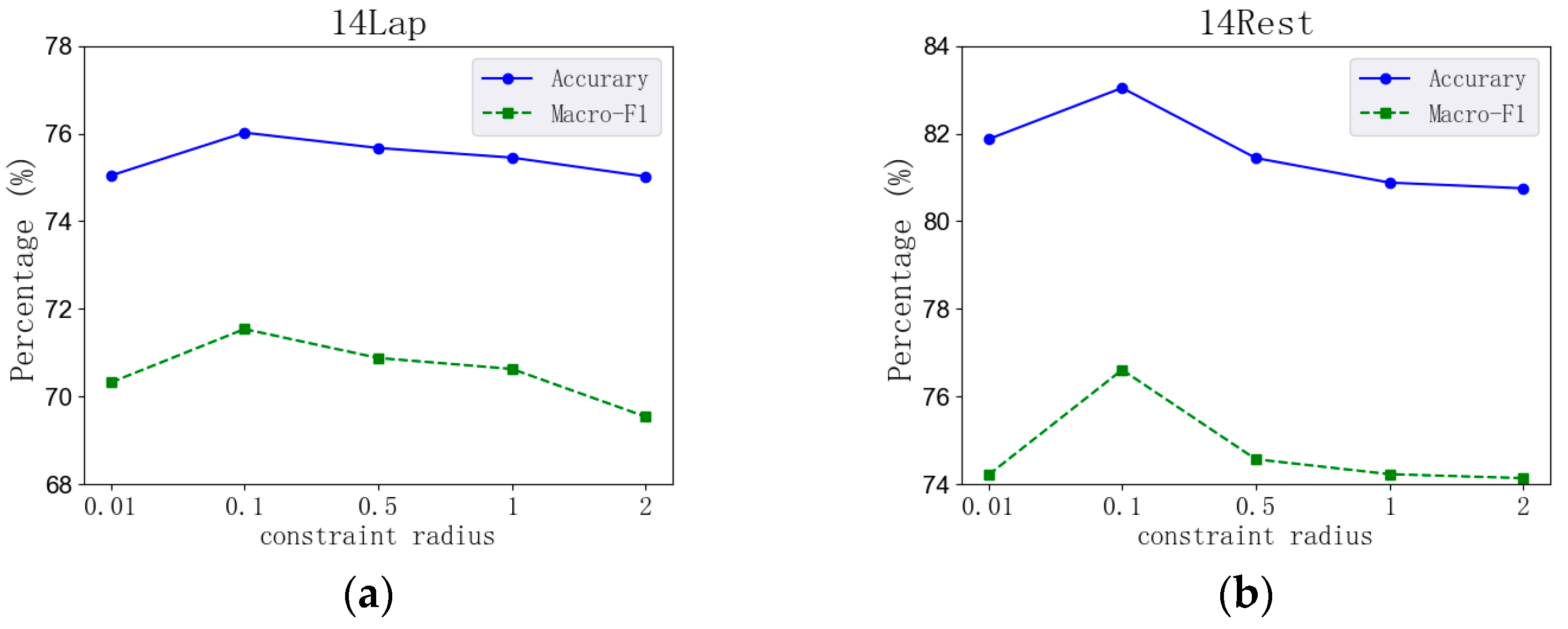
4.6. Analysis of Model Parameters
4.7. Case Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Saberi, B.; Saad, S. Sentiment analysis or opinion mining: A review. Int. J. Adv. Sci. Eng. Inf. Technol. 2017, 7, 166–1666. [Google Scholar]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef]
- Thet, T.T.; Na, J.C.; Khoo, C.S.G. Aspect-based sentiment analysis of movie reviews on discussion boards. J. Inf. Sci. 2010, 36, 823–848. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zhuang, L.; Wayne, L.; Ya, S.; Jun, Z. A robustly optimized BERT pre-training approach with post-training. In Proceedings of the 20th Chinese National Conference on Computational Linguistics, Huhhot, China, 13–15 August 2021; pp. 1218–1227. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 5753–5763. [Google Scholar]
- Mao, R.; Liu, Q.; He, K.; Li, W.; Cambria, E. The biases of pre-trained language models: An empirical study on prompt-based sentiment analysis and emotion detection. IEEE Trans. Affect. Comput. 2022, 14, 1743–1753. [Google Scholar] [CrossRef]
- Kiritchenko, S.; Zhu, X.; Cherry, C.; Mohammad, S. Detecting aspects and sentiment in customer reviews. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval), Dublin, Ireland, 23–24 August 2014; pp. 437–442. [Google Scholar]
- Akhtar, M.S.; Ekbal, A.; Bhattacharyya, P. Aspect based sentiment analysis in Hindi: Resource creation and evaluation. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 2703–2709. [Google Scholar]
- Patra, B.G.; Mandal, S.; Das, D.; Bandyopadhyay, S. Ju_cse: A conditional random field (crf) based approach to aspect based sentiment analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014; pp. 370–374. [Google Scholar]
- Cheng, L.C.; Chen, Y.L.; Liao, Y.Y. Aspect-based sentiment analysis with component focusing multi-head co-attention networks. Neurocomputing 2022, 489, 9–17. [Google Scholar] [CrossRef]
- Huang, Y.; Peng, H.; Liu, Q.; Yang, Q.; Wang, J.; Orellana-Martín, D.; Pérez-Jiménez, M.J. Attention-enabled gated spiking neural P model for aspect-level sentiment classification. Neural Netw. 2023, 157, 437–443. [Google Scholar] [CrossRef]
- Ayetiran, E.F. Attention-based aspect sentiment classification using enhanced learning through CNN-BiLSTM networks. Knowl.-Based Syst. 2022, 252, 109409. [Google Scholar] [CrossRef]
- Zeng, Y.; Li, Z.; Chen, Z.; Ma, H. Aspect-level sentiment analysis based on semantic heterogeneous graph convolutional network. Front. Comput. Sci. 2023, 17, 176340. [Google Scholar] [CrossRef]
- Gu, T.; Zhao, H.; He, Z.; Li, M.; Ying, D. Integrating external knowledge into aspect-based sentiment analysis using graph neural network. Knowl. Based Syst. 2023, 259, 110025. [Google Scholar] [CrossRef]
- Xiao, L.; Xue, Y.; Wang, H.; Hu, X.; Gu, D.; Zhu, Y. Exploring fine-grained syntactic information for aspect-based sentiment classification with dual graph neural networks. Neurocomputing 2022, 471, 48–59. [Google Scholar] [CrossRef]
- Mewada, A.; Dewang, R.K. SA-ASBA: A hybrid model for aspect-based sentiment analysis using synthetic attention in pre-trained language BERT model with extreme gradient boosting. J. Supercomput. 2023, 79, 5516–5551. [Google Scholar] [CrossRef]
- Xu, M.; Zeng, B.; Yang, H.; Chi, J.; Chen, J.; Liu, H. Combining dynamic local context focus and dependency cluster attention for aspect-level sentiment classification. Neurocomputing 2022, 478, 49–69. [Google Scholar] [CrossRef]
- Mao, R.; Li, X. Bridging towers of multi-task learning with a gating mechanism for aspect-based sentiment analysis and sequential metaphor identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 13534–13542. [Google Scholar]
- Nguyen, D.Q.; Verspoor, K. An improved neural network model for joint POS tagging and dependency parsing. arXiv 2018, arXiv:1807.03955. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Shafahi, A.; Najibi, M.; Ghiasi, M.A.; Xu, Z.; Dickerson, J.; Studer, C.; Davis, L.S.; Taylor, G.; Goldstein, T. Adversarial training for free! Adv. Neural Inf. Process. Syst. 2019, 32, 3358–3369. [Google Scholar]
- Zhu, C.; Cheng, Y.; Gan, Z.; Sun, S.; Goldstein, T.; Liu, J. Freelb: Enhanced adversarial training for natural language understanding. arXiv 2019, arXiv:arxiv:1909.11764. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. Adv. Neural Inf. Process. Syst. 2014, 27, 2204–2212. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014; pp. 55–60. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Kirange, D.K.; Deshmukh, R.R. Emotion classification of restaurant and laptop review dataset: Semeval 2014 task 4. Int. J. Comput. Appl. 2015, 113, 17–20. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Chinchor, N.; Sundheim, B.M. MUC-5 evaluation metrics. In Proceedings of the Fifth Message Understanding Conference (MUC-5), Baltimore, MD, USA, 25–27 August 1993. [Google Scholar]
- Yang, Y.; Liu, X. A re-examination of text categorization methods. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Berkeley, CA, USA, 15–19 August 1999; pp. 42–49. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef]
- Tang, D.; Qin, B.; Feng, X.; Liu, T. Effective LSTMs for target-dependent sentiment classification. arXiv 2015, arXiv:1512.01100. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Aspect level sentiment classification with deep memory network. arXiv 2016, arXiv:1605.08900. [Google Scholar]
- Ma, D.; Li, S.; Zhang, X.; Wang, H. Interactive attention networks for aspect-level sentiment classification. arXiv 2017, arXiv:1709.00893. [Google Scholar]
- Chen, P.; Sun, Z.; Bing, L.; Yang, W. Recurrent attention network on memory for aspect sentiment analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 452–461. [Google Scholar]
- Song, Y.; Wang, J.; Jiang, T.; Liu, Z.; Rao, Y. Attentional encoder network for targeted sentiment classification. arXiv 2019, arXiv:1902.09314. [Google Scholar]
- Zhang, C.; Li, Q.; Song, D. Aspect-based sentiment classification with aspect-specific graph convolutional networks. arXiv 2019, arXiv:1909.03477. [Google Scholar]
- Fei, H.; Li, B.; Liu, Q.; Bing, L.; Li, F.; Chua, T.S. Reasoning implicit sentiment with chain-of-thought prompting. arXiv 2023, arXiv:2305.11255. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Labels | Meanings |
|---|---|
| ROOT | Root node |
| det | Dependency |
| amod | Adjectives |
| nsubj | Noun subjects |
| prep | Prepositional modifiers |
| pobj | Object of a preposition |
| acomp | Complement of an adjective |
| Datasets | Negative | Neutral | Postive | |||
|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | |
| Laptops | 851 | 128 | 455 | 167 | 976 | 337 |
| Restaurants | 807 | 196 | 637 | 196 | 2164 | 727 |
| Experimental Environment Configuration Table | Configuration Information |
|---|---|
| Operating System CPU | AMD Ryzen 7 7735H with Radeon Graphics 3.20 GHz |
| Graphics card | NVIDIA GeForce RTX 4060 |
| Deep Learning Framework | Pytorch |
| Development Environment | Pycharm |
| Coefficient | 0.8–1.0 | 0.6–0.8 | 0.4–0.6 | 0.2–0.4 | 0–0.2 |
|---|---|---|---|---|---|
| Level | Almost perfect | Substantial | Moderate | Fair | Slight |
| Comparative Models | Laptops | Restaurants | ||||
|---|---|---|---|---|---|---|
| Accurary | Macro-F1 | Kappa | Accurary | Macro-F1 | Kappa | |
| LSTM | 66.77 | 61.78 | - | 74.29 | 62.58 | - |
| TD-LSTM | 68.81 | 64.67 | - | 76.00 | 64.51 | - |
| MemNet | 70.64 | 65.17 | - | 79.61 | 69.64 | - |
| IAN | 71.20 | 66.69 | - | 76.86 | 66.71 | - |
| RAM | 72.32 | 67.90 | 0.6745 | 76.92 | 68.71 | 0.7148 |
| AEN | 73.69 | 68.59 | 0.6886 | 77.06 | 69.35 | 0.7262 |
| ASGCN | 75.55 | 71.05 | 0.6904 | 80.77 | 72.02 | 0.7377 |
| GPT3 + Prompt | 77.87 | 73.04 | - | 85.45 | 78.96 | - |
| BAMD(Ours) | 76.02 | 71.54 | 0.7171 | 83.04 | 76.61 | 0.7853 |
| Models | Laptops | Restaurants | ||
|---|---|---|---|---|
| Accurary | Macro-F1 | Accurary | Macro-F1 | |
| w/o DS | 74.52 | 70.31 | 80.57 | 76.22 |
| w/o AT | 73.45 | 69.63 | 78.63 | 73.25 |
| w/o MHA | 73.58 | 69.97 | 79.78 | 74.56 |
| BAMD | 76.02 | 71.54 | 83.04 | 80.26 |
| Num | Examples | TD-LSTM | ASGCN | BAMD | Label |
|---|---|---|---|---|---|
| 1 | The food is great but the service was dreadful! | Negative (×) | Positive (√) | Positive (√) | Positive |
| 2 | I’m delighted to return to the familiar embrace of Apple’s operating system. | Positive (√) | Negative (×) | Positive (√) | Positive |
| 3 | Did not enjoy the new Windows 8 and touchscreen functions. | Natural (×) | Positive (×) | Negative (√) | Negative |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, E.; Zhu, J.; Zhang, L.; Wang, Y.; Lin, W. Research on Aspect-Level Sentiment Analysis Based on Adversarial Training and Dependency Parsing. Electronics 2024, 13, 1993. https://doi.org/10.3390/electronics13101993
Xu E, Zhu J, Zhang L, Wang Y, Lin W. Research on Aspect-Level Sentiment Analysis Based on Adversarial Training and Dependency Parsing. Electronics. 2024; 13(10):1993. https://doi.org/10.3390/electronics13101993
Chicago/Turabian StyleXu, Erfeng, Junwu Zhu, Luchen Zhang, Yi Wang, and Wei Lin. 2024. "Research on Aspect-Level Sentiment Analysis Based on Adversarial Training and Dependency Parsing" Electronics 13, no. 10: 1993. https://doi.org/10.3390/electronics13101993
APA StyleXu, E., Zhu, J., Zhang, L., Wang, Y., & Lin, W. (2024). Research on Aspect-Level Sentiment Analysis Based on Adversarial Training and Dependency Parsing. Electronics, 13(10), 1993. https://doi.org/10.3390/electronics13101993