
An Accurate and Invertible Sketch for Super Spread Detection


Abstract
1. Introduction
- (1)
- We proposed an innovative invertible sketch data structure called SSD-AIS for super spread detection with small memory demands, which guarantees accuracy. Meanwhile, SSD-AIS can provide an exact spread estimation for the super spread.
- (2)
- We presented a mathematical analysis of memory usage and insert time, and the expectation of cardinality for a super spread.
- (3)
- We implemented SSD-AIS with two standard cardinality estimators (AC and LC estimators). Trace-driven evaluations showed that SSD-AIS with the AC estimator and SSD-AIS with the LC estimator had higher accuracy in super spread detection compared to the state-of-art with small memory demands. And the average relative error of cardinality estimation of a super spread in SSD-AIS with the LC estimator is 2.6–19.6 times lower than the previous algorithms. The source code of SSD-AIS implementation and the related algorithms have been released at Github [24].
2. Related Works
3. Overview
3.1. Subsection
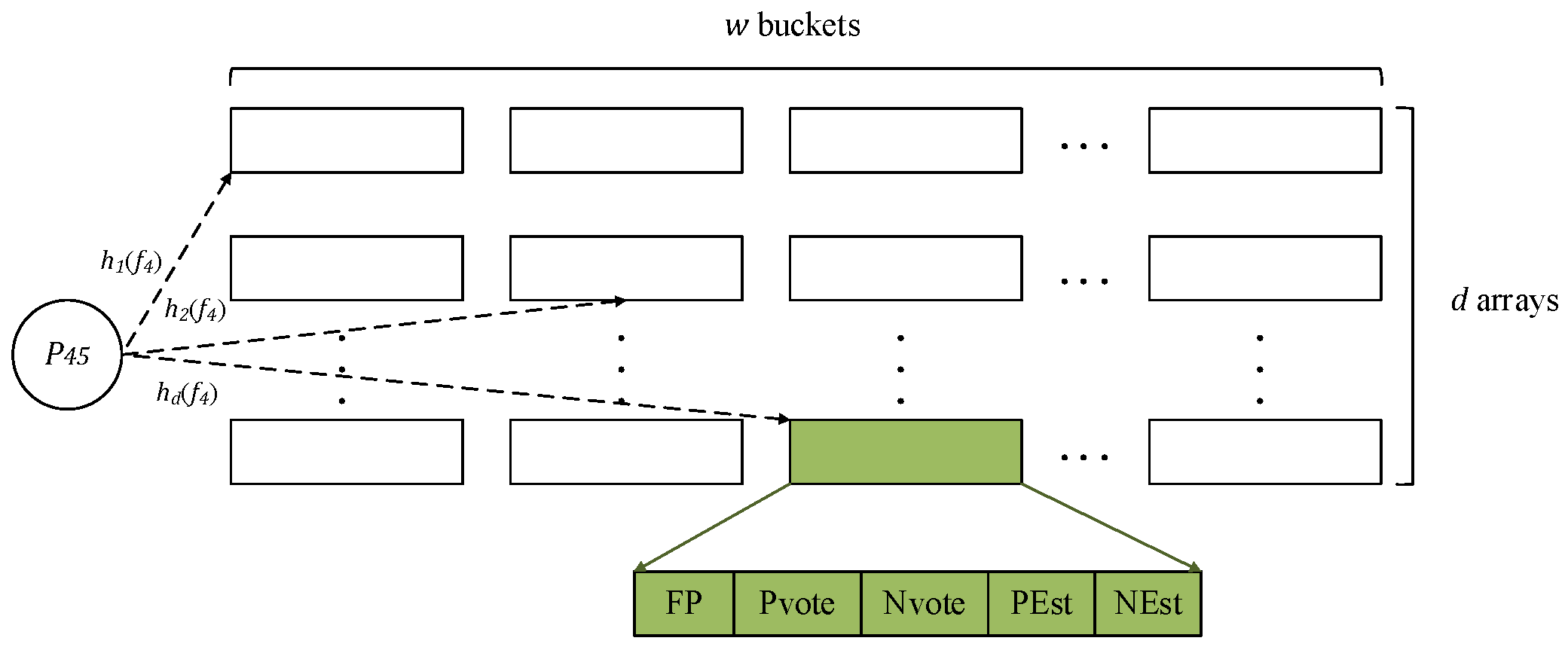
3.2. Data Structure
3.3. Basic Operations
| Algorithm 1: Insertion |
Output: update SSD-AIS 1 to d do mod w; then ; ); ); then ); ); ; then ); ); then ; |
| Algorithm 2: Query process |
Output: 1 to d do 1 to d do; then to set do ; then into ; |
| Algorithm 3: PointQuery |
of flow 1 to d do ; ; to a big value; then ; ; then ; 10 else 11 return 0; |
4. Theoretical Analysis
4.1. Space and Time Complexities
4.2. Error Analysis
5. Evaluation
5.1. Setup
- (1)
- Recommender System Dataset: The dataset used in the experiment was collected from a real-world e-commerce website [32] and we used the visitor behavior data. We took the item ID as the flow label and visitor ID as the element identifier. Then, there were approximately 2.7 M items and 200 k flows. The flow cardinality in this dataset is defined as the number of distinct visitors viewing the item, reflecting the popularity of the corresponding product.
- (2)
- CAIDA Dataset: This dataset contains anonymized IP traces collected in 2016 by CAIDA [33]. In this experiment, we considered the destination IP address as the flow label and all packets toward the same destination constituted a flow. The source IP address was used as the element identifier. The first 4 M packets of this dataset belonging to approximately 50 K flows were used in the experiment. The flow spread in this dataset is the number of distinct source IP addresses communicating with the same destination IP address, which may reflect the victims of the DDoS attack.
5.2. Metrics
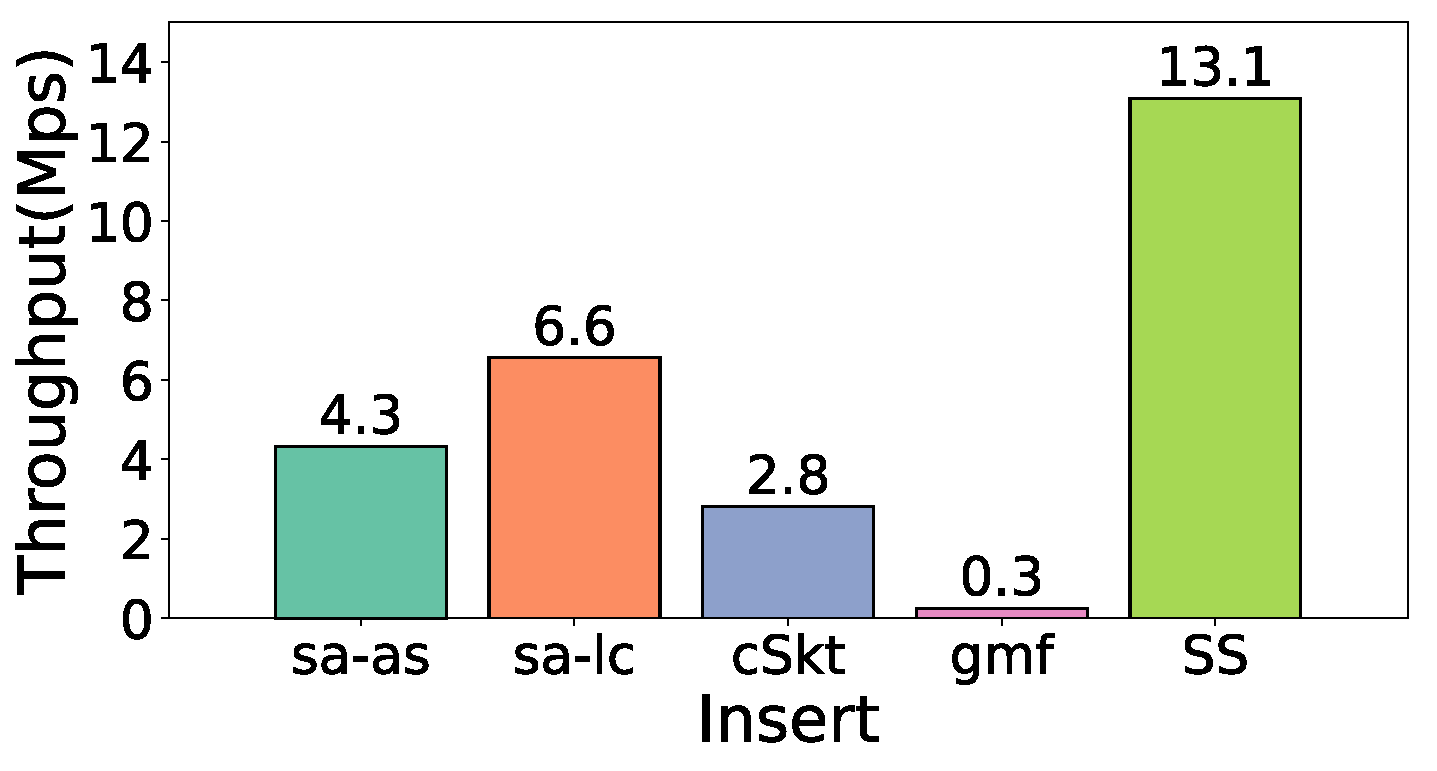
- Throughput: All packets are inserted and the corresponding throughput is calculated. The throughput is defined as , where represents the total processing time. The measuring method is inserting millions of packets per second and the unit of the throughput is Mps. We repeated the experiments 10 times and recorded and reported the average value of the throughput.
- Detection time: Time spent reporting all super spreads. The experiments were repeated 10 times, and the average detection time was recorded and reported.
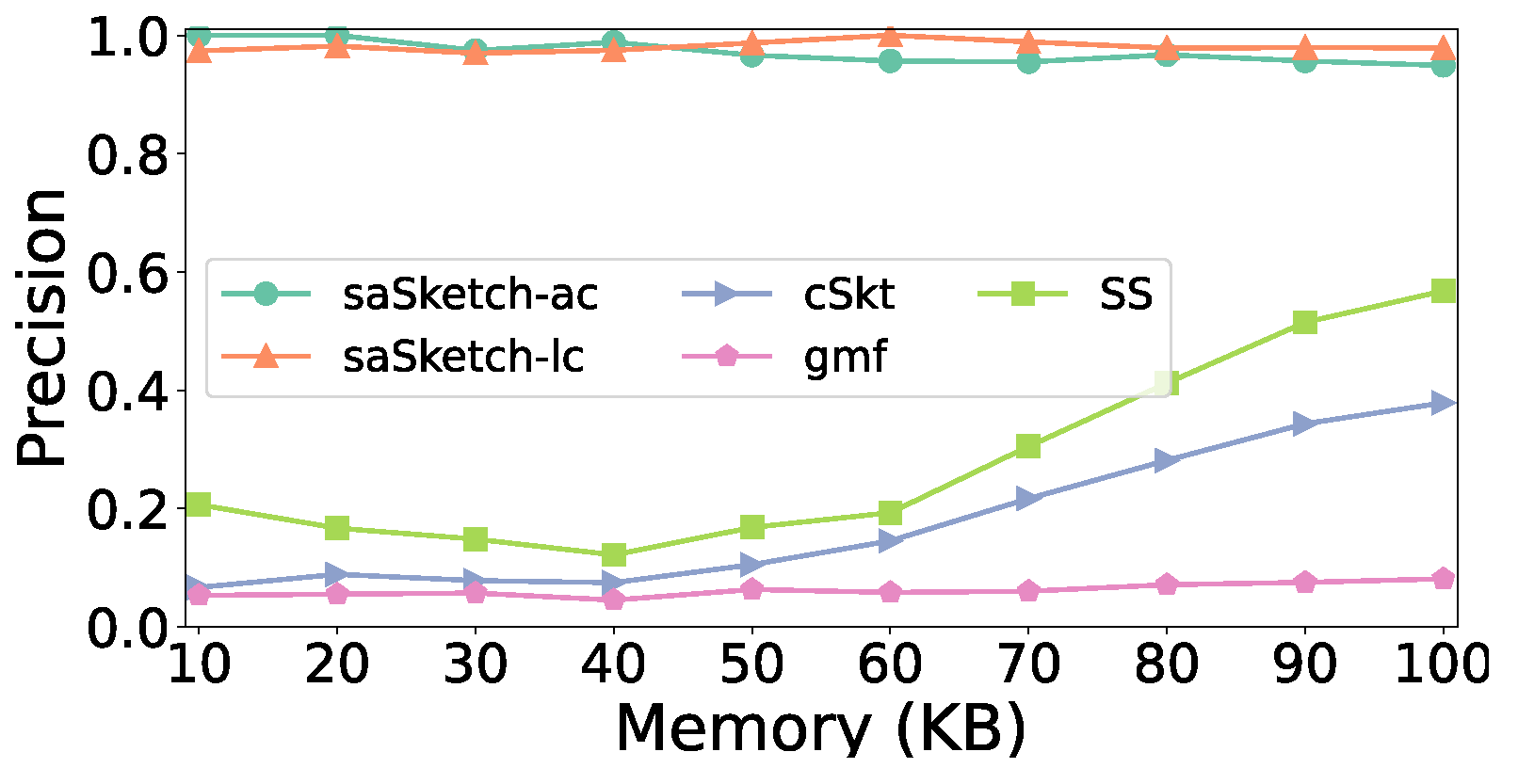
- Precision: Fraction of true super spreads reported over all reported spreads.
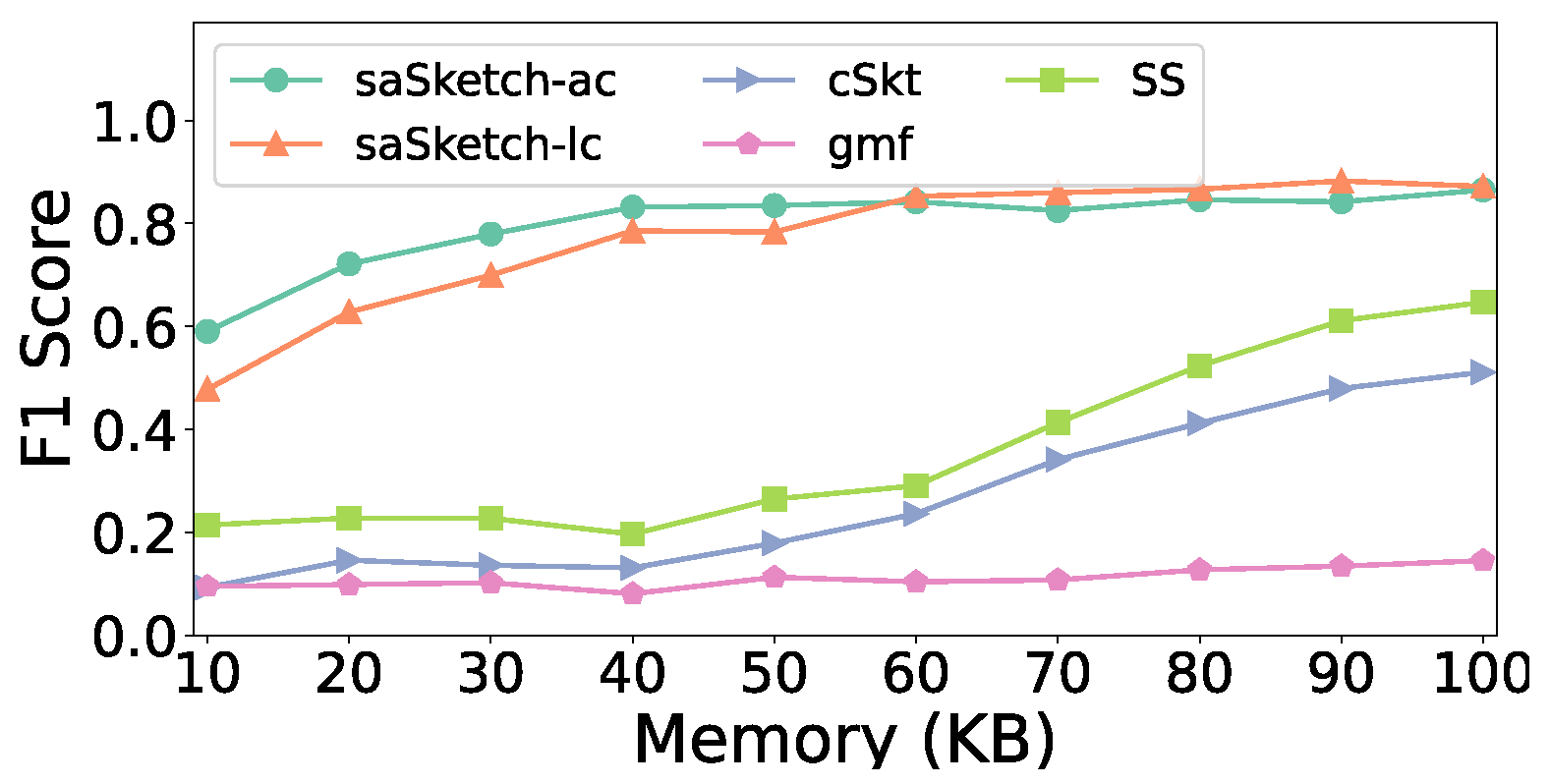
- Recall: Fraction of true super spreads reported over all true super spreads.
- F1 Score: The F1 score is the harmonic mean of the precision and recall, which is defined as .
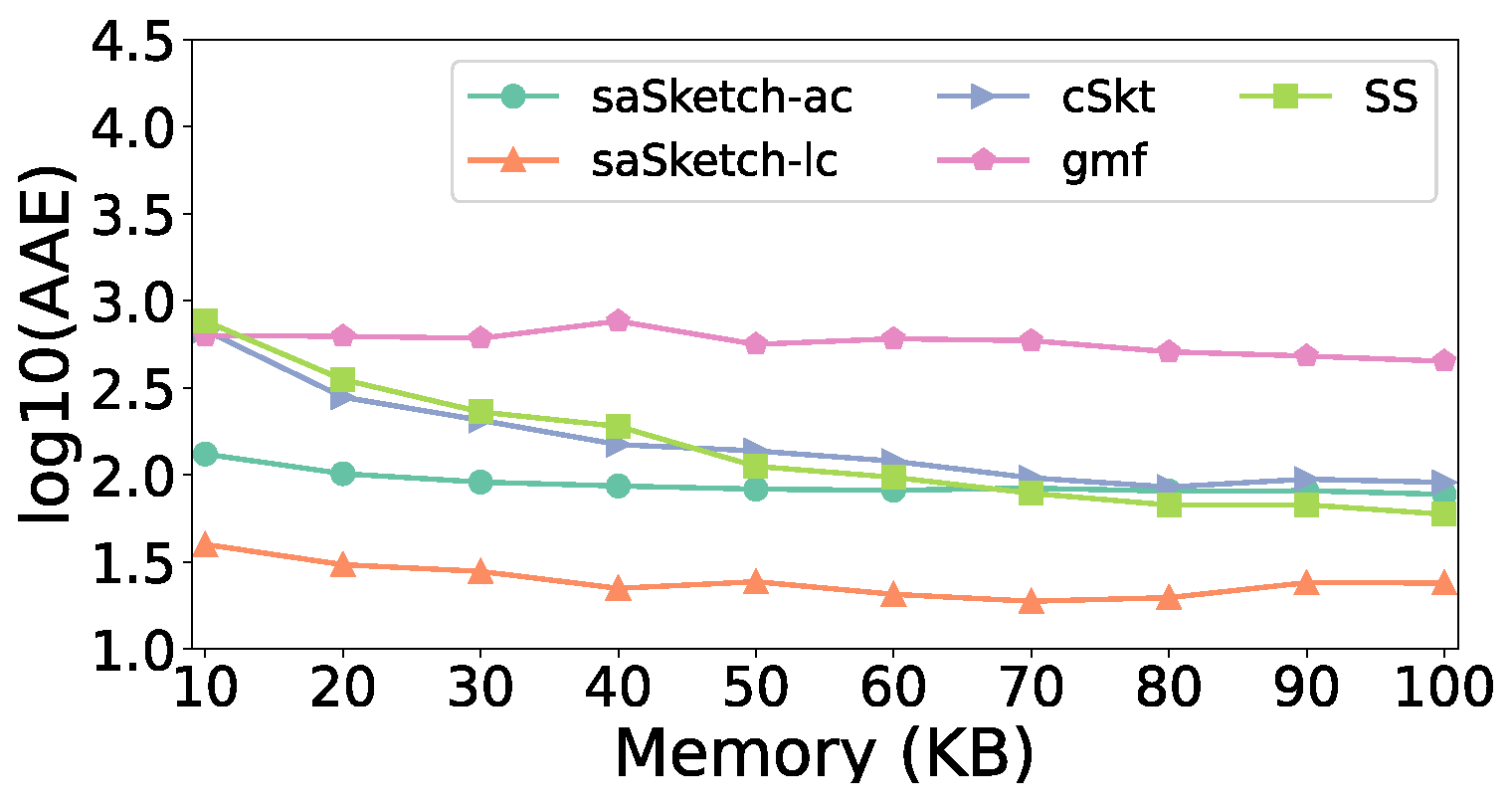
- Average Absolute Error (AAE): AAE is defined as , where is the true super spreads reported.
- Average Relative Error (ARE): ARE is defined as .
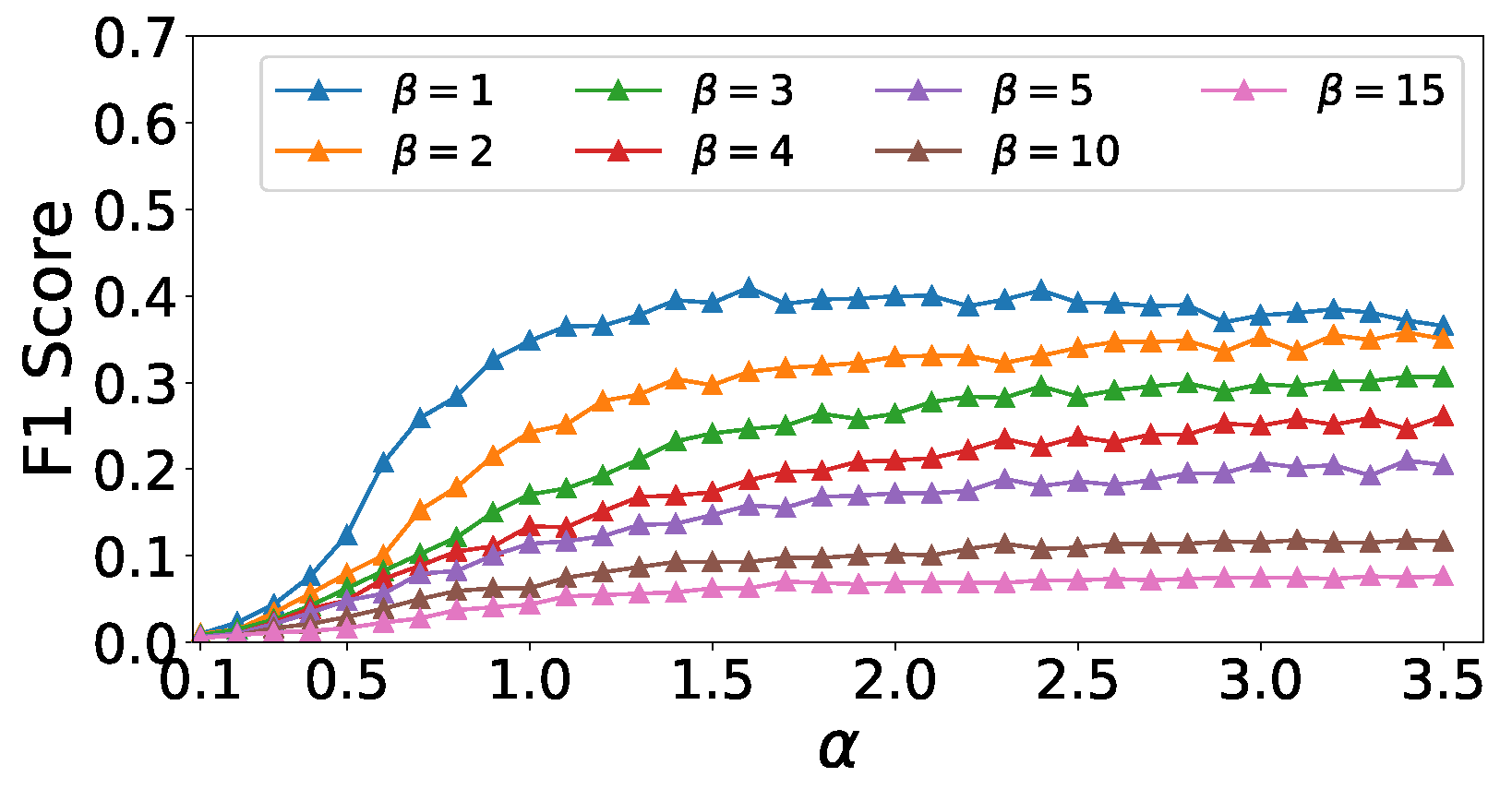
5.3. Experiments on Parameters and
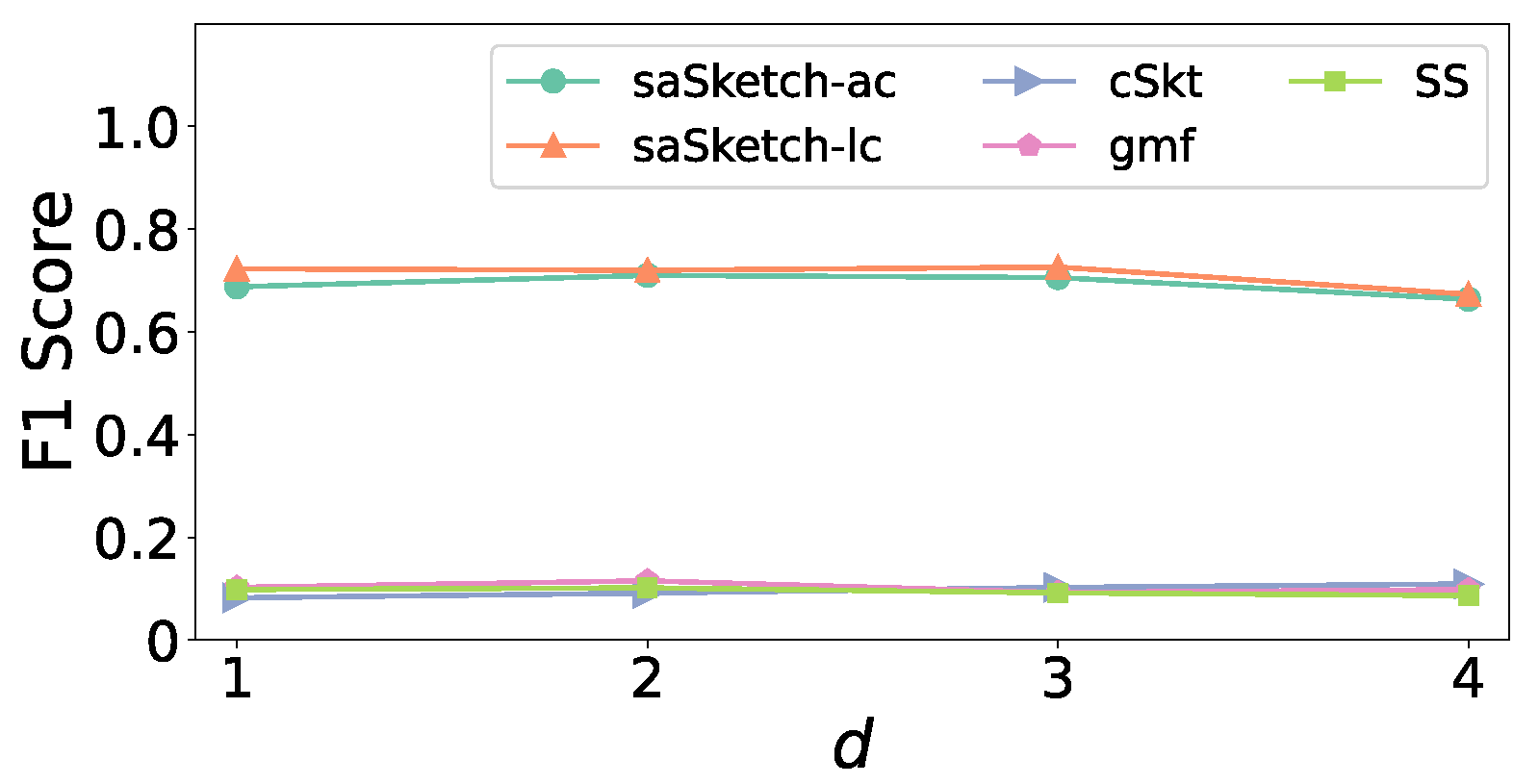
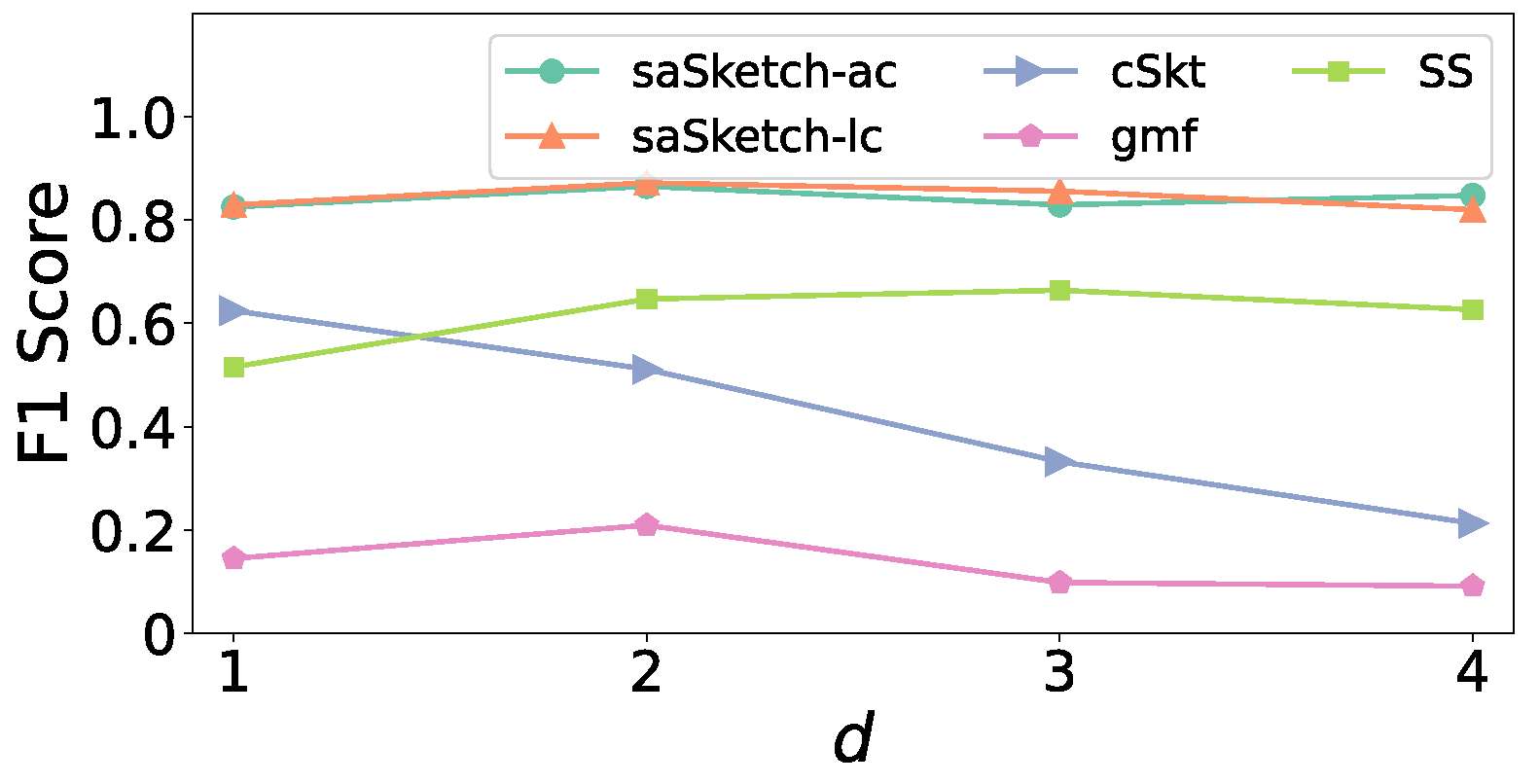
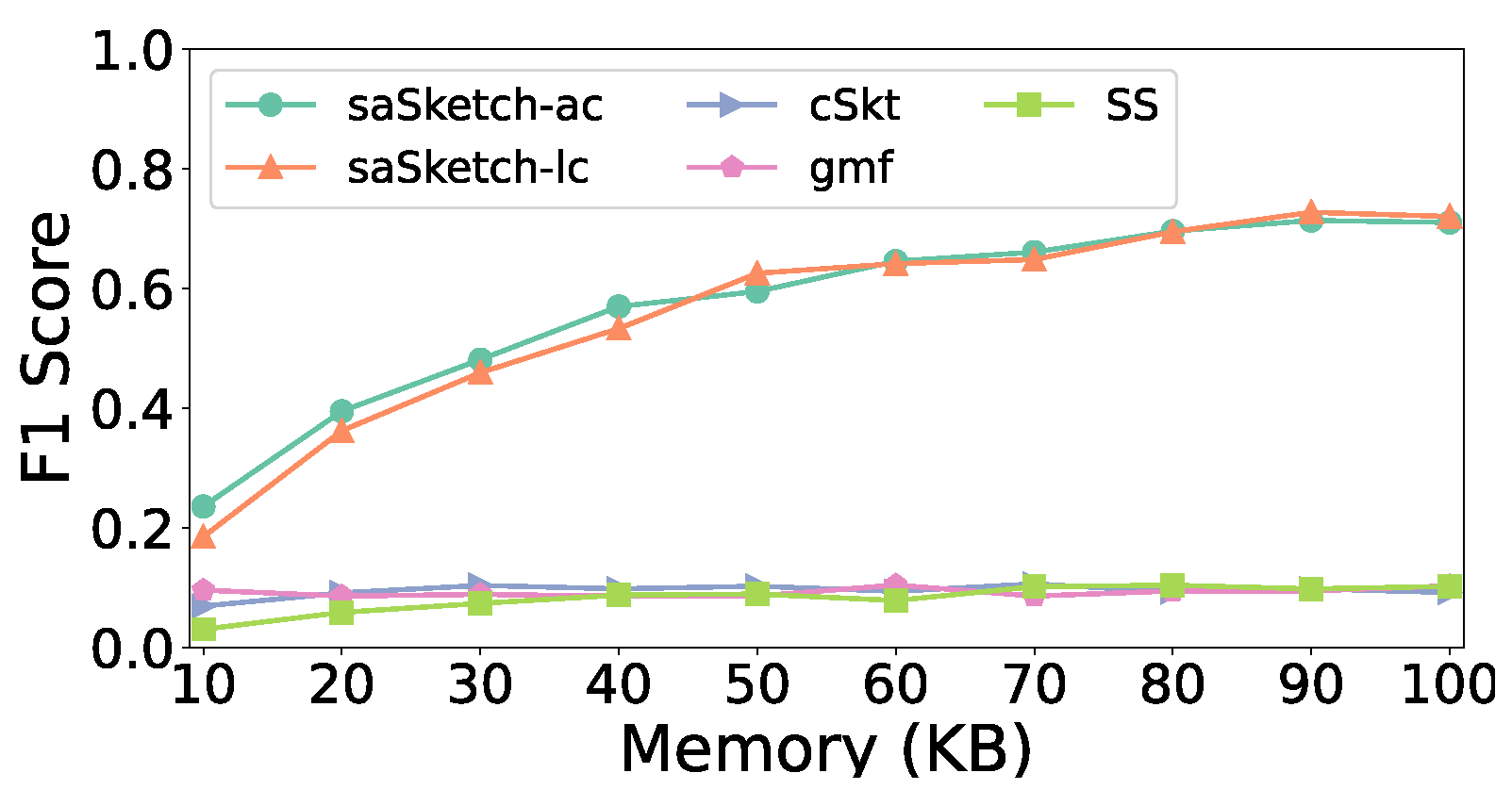
5.4. Experiments on Accuracy
- (1)
- Effects of
- (2)
- Effect of memory
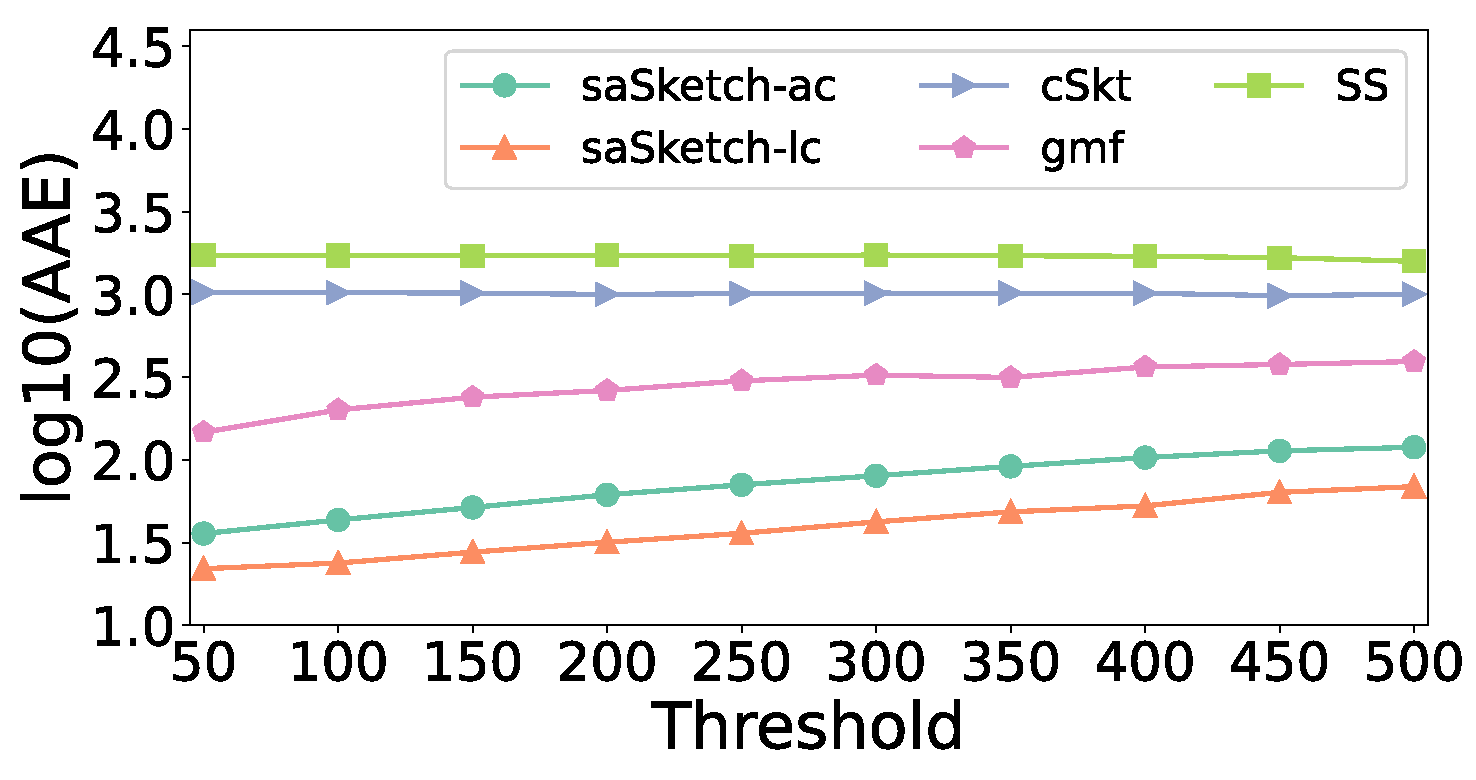
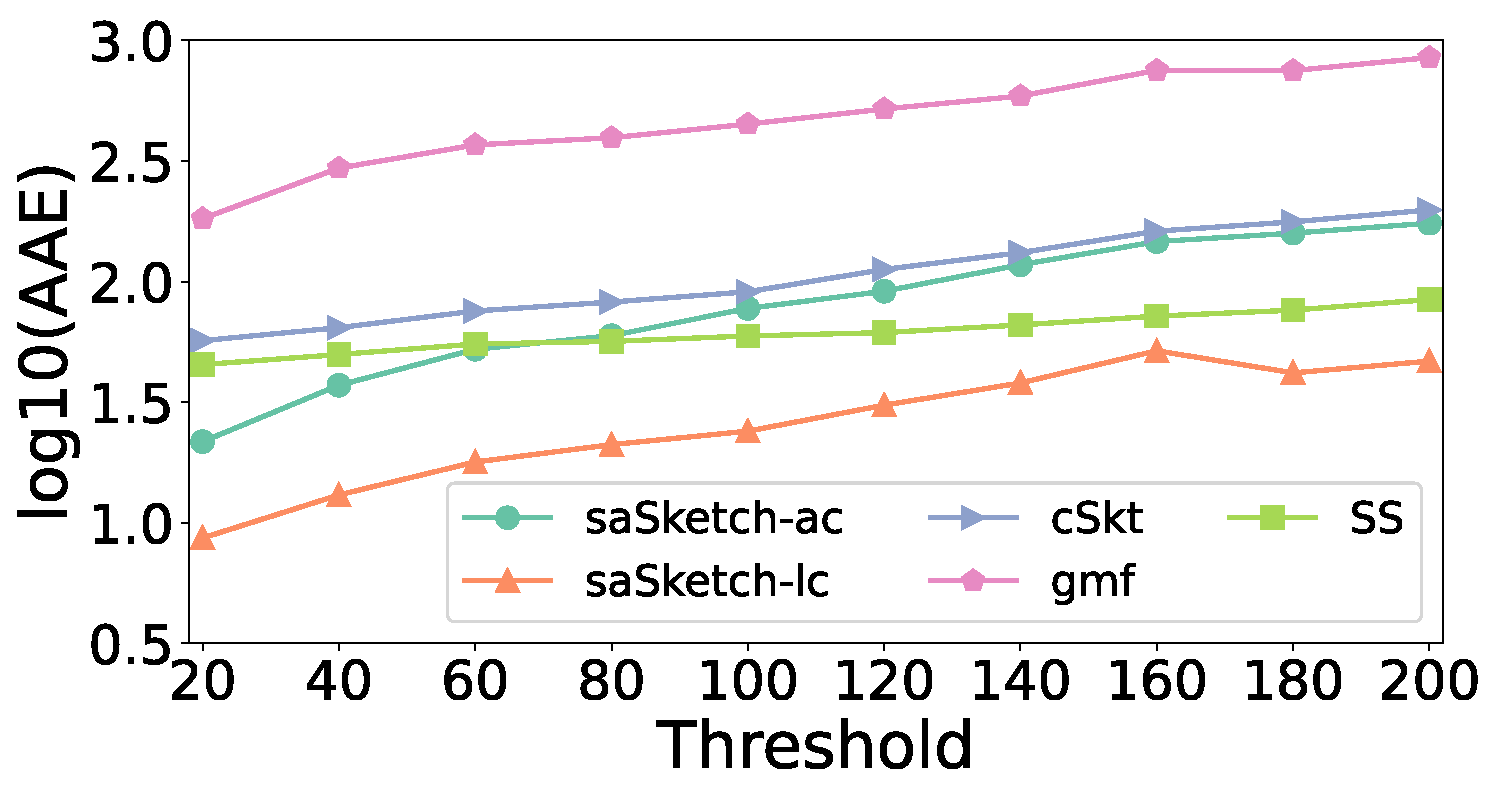
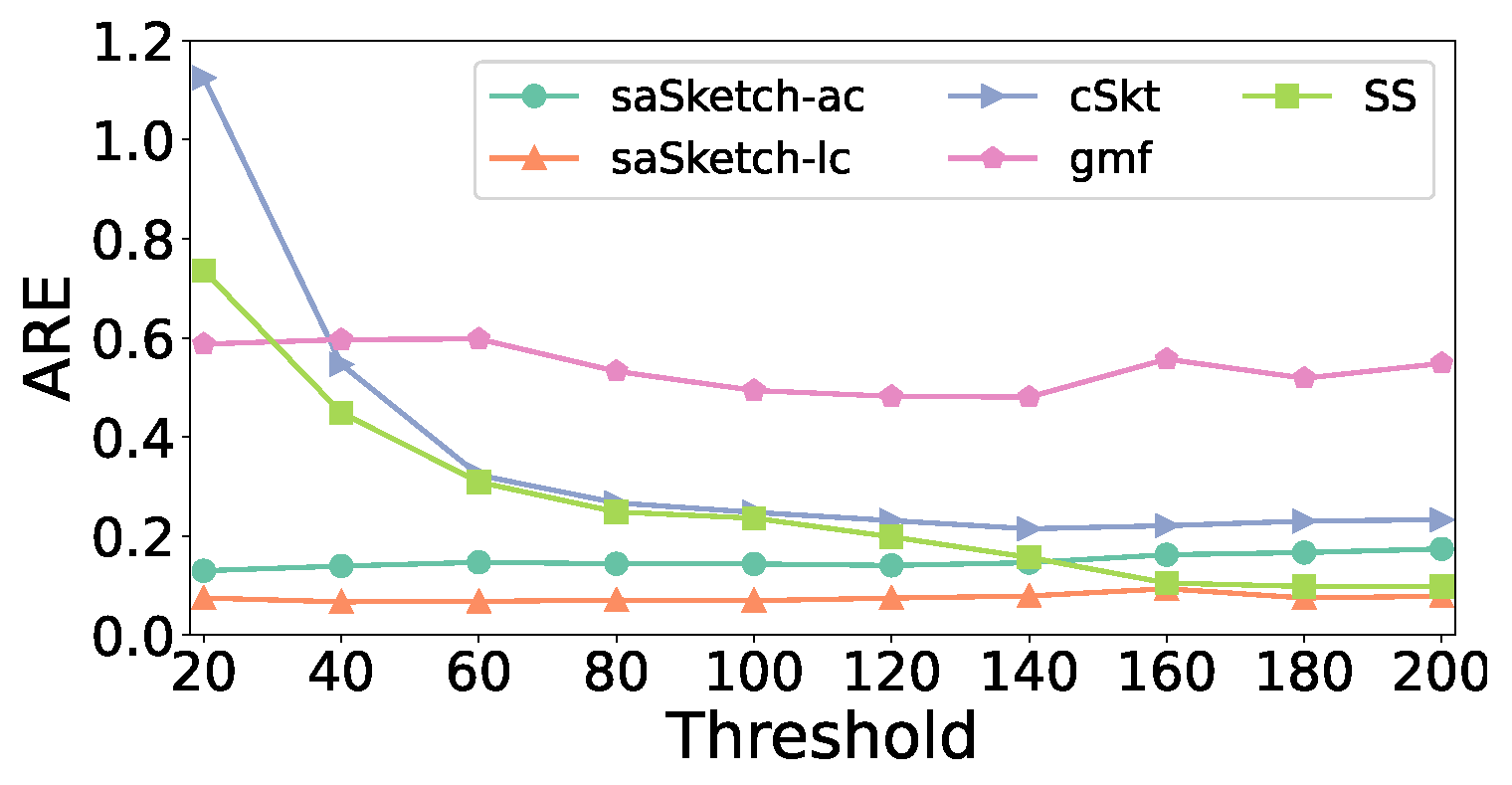
5.5. Experiments on AAE and ARE
- (1)
- Effect of memory
- (2)
- Effect of threshold
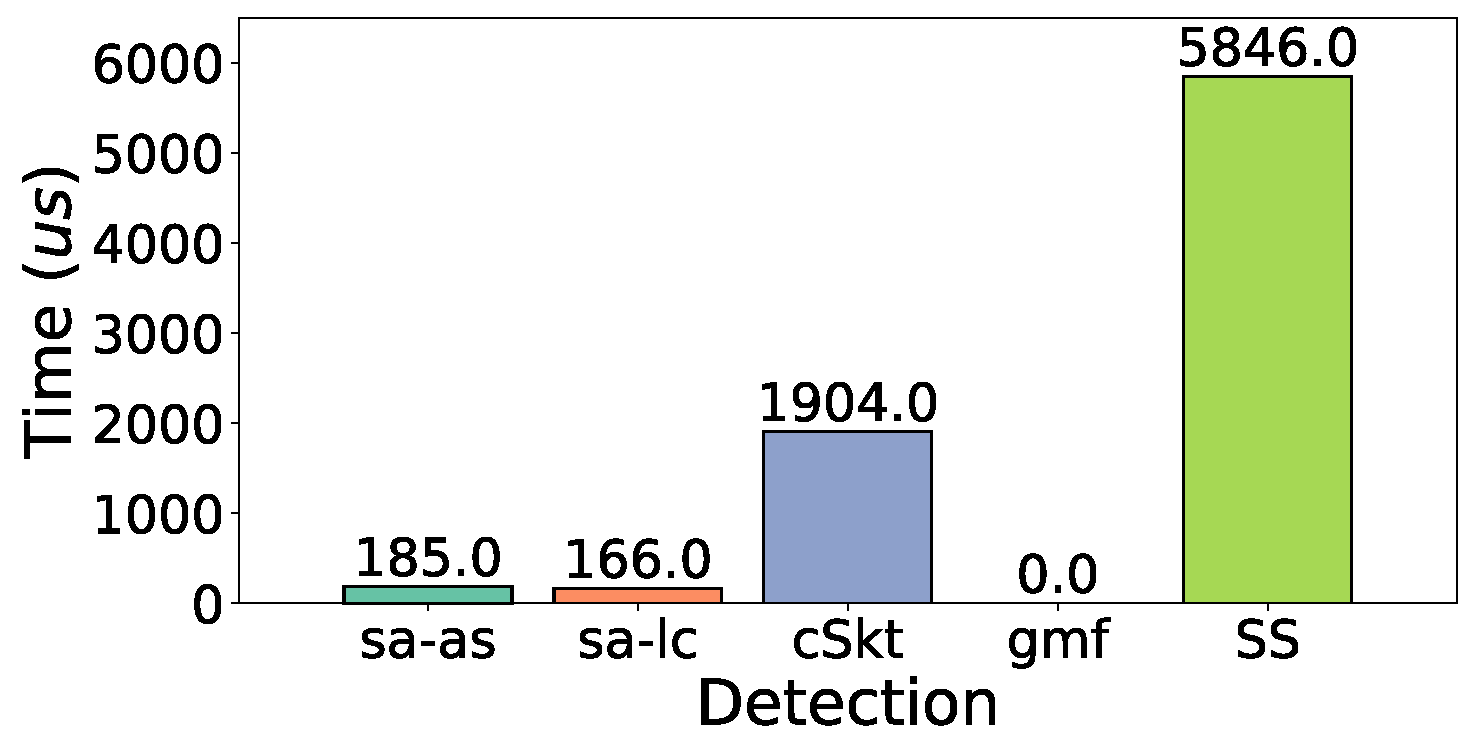
5.6. Experiments on Performance
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tan, L.-Z.; Su, W.; Zhang, W.; Lv, J.; Zhang, Z.; Miao, J.; Liu, X.; Li, N. In-band network telemetry: A survey. Comput. Netw. 2021, 186, 107763. [Google Scholar] [CrossRef]
- Li, S.; Luo, L.; Guo, D. Sketch for Traffic Measurement: Design Optimization Application and Implementation. arXiv 2020, arXiv:2012.07214. Available online: https://arxiv.org/abs/2012.07214 (accessed on 5 January 2021).
- Pendleton, M.; Garcia-Lebron, R.; Cho, J.-H.; Xu, S. A survey on systems security metrics. ACM Comput. Surv. 2017, 49, 62. [Google Scholar] [CrossRef]
- Cao, J.; Jin, Y.; Chen, A.; Bu, T.; Zhang, Z.-L. Identifying high cardinality internet hosts. In Proceedings of the IEEE International Conference on Computer Communications, Rio de Janeiro, Brazil, 19–25 April 2009; pp. 810–818. [Google Scholar] [CrossRef]
- Durumeric, Z.; Bailey, M.; Halderman, J.A. An Internet-Wide View of Internet-Wide Scanning. In Proceedings of the 23rd USENIX Security Symposium, San Diego, CA, USA, 20–22 August 2014; pp. 65–78. Available online: https://www.usenix.org/conference/usenixsecurity14/technical-sessions/presentation/durumeric (accessed on 10 May 2021).
- Fayaz, S.K.; Tobioka, Y.; Sekar, V.; Bailey, M. Bohatei: Flexible and Elastic Ddos Defense. In Proceedings of the 24th USENIX Security Symposium, Washington, DC, USA, 12–14 August 2015; pp. 817–832. Available online: https://www.usenix.org/conference/usenixsecurity15/technical-sessions/presentation/fayaz (accessed on 20 January 2021).
- Liu, Y.; Chen, W.; Guan, Y. Identifying high-cardinality hosts from network-wide traffic measurements. IEEE Trans. Dependable Secur. Comput. 2016, 13, 547–558. [Google Scholar] [CrossRef]
- Qun, H.; Lee, P.P.C.; Bao, Y. Sketchlearn: Relieving user burdens in approximate measurement with automated statistical inference. In Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, Budapest, Hungary, 20–25 August 2018; pp. 576–590. [Google Scholar] [CrossRef]
- Lu, J.; Chen, H.; Sun, P.; Hu, T.; Zhang, Z. OrderSketch: An unbiased and fast sketch for frequency estimation of data streams. Comput. Netw. 2021, 201, 108563. [Google Scholar] [CrossRef]
- Liu, Z.; Manousis, A.; Vorsanger, G.; Sekar, V.; Braverman, V. One sketch to rule them all: Rethinking network flow monitoring with univmon. In Proceedings of the Annual Conference of the ACM Special Interest Group, Florianopolis, Brazil, 22–26 August 2016; pp. 101–114. [Google Scholar] [CrossRef]
- Yang, T.; Jiang, J.; Liu, P.; Huang, Q.; Gong, J.; Zhou, Y.; Miao, R.; Li, X.; Uhlig, S. Elastic sketch: Adaptive and fast network-wide measurements. In Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, Budapest, Hungary, 20–25 August 2018; pp. 561–575. [Google Scholar] [CrossRef]
- Wu, K.; Otoo, E.J.; Shoshani, A. Optimizing bitmap indices with efficient compression. ACM Trans. Database Syst. 2006, 31, 1–38. [Google Scholar] [CrossRef]
- Whang, K.-Y.; Vander-Zanden, B.T.; Taylor, H.M. A linear-time probabilistic counting algorithm for database applications. ACM Trans. Database Syst. 1990, 15, 208–229. [Google Scholar] [CrossRef]
- Durand, M.; Flajolet, P. Loglog counting of large cardinalities. In Proceedings of the Algorithms-ESA 2003: 11th Annual European Symposium, Budapest, Hungary, 16–19 September 2003; pp. 16–19. [Google Scholar]
- Cai, M.; Pan, J.; Kwok, Y.-K.; Hwang, K. Fast and accurate traffic matrix measurement using adaptive cardinality counting. In Proceedings of the Annual Conference of the ACM Special Interest Group on Data Communication Workshop on Mining NETWORK Data, Philadelphia, PA, USA, 26 August 2005; pp. 205–206. [Google Scholar] [CrossRef]
- Flajolet, P.; Fusy, É.; Gandouet, O.; Meunier, F. Hyperloglog: The Analysis of a Near-Optimal Cardinality Estimation Algorithm. In Proceedings of the Discrete Mathematics and Theoretical Computer Science, Nancy, France, 1 January 2007; pp. 127–146. Available online: https://algo.inria.fr/flajolet/Publications/FlFuGaMe07.pdf (accessed on 5 December 2020).
- Zhang, Z.; Hsu, C.; Au, M.H.; Harn, L.; Cui, J.; Xia, Z.; Zhao, Z. PRLAP-IoD: A PUF-based Robust and Lightweight Authentication Protocol for Internet of Drones. Comput. Netw. 2024, 238, 110118. [Google Scholar] [CrossRef]
- Cormode, G.; Muthukrishnan, S. Space efficient mining of multigraph streams. In Proceedings of the Twenty-Fourth ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, Baltimore, MD, USA, 13–15 June 2005; pp. 271–282. [Google Scholar] [CrossRef]
- Ma, C.; Chen, S.; Zhang, Y.; Xiao, Q.; Odegbile, O.O. Super spreader identification using geometric-min filter. IEEE/ACM Trans. Netw. 2022, 30, 299–312. [Google Scholar] [CrossRef]
- Tang, L.; Huang, Q.; Lee, P.P.C. SpreadSketch: Toward Invertible and Network-Wide Detection of Superspreaders. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 1608–1617. [Google Scholar] [CrossRef]
- Venkataraman, S.; Song, D.X.; Gibbons, P.B.; Blum, A. New Streaming Algorithms for Fast Detection of Superspreaders. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 2 February 2005; Available online: https://www.ndss-symposium.org/ndss2005/new-streaming-algorithms-fast-detection-superspreaders/ (accessed on 17 March 2021).
- Estan, C.; Varghese, G.; Fisk, M. Bitmap algorithms for counting active flows on high speed links. IEEE/ACM Trans. Netw. 2003, 14, 925–937. [Google Scholar]
- Boyer, R.S.; Moore, J.S. MJRTY: A Fast Majority Vote Algorithm. Autom. Reason. Essays Honor. Woody Bledsoe 1991, 1, 105–118. [Google Scholar]
- SuperKeeper. Available online: https://anonymous.4open.science/r/SuperKeeper-B004/README.md (accessed on 15 March 2021).
- Liu, Y.; Chen, W.; Guan, Y. A fast sketch for aggregate queries over high-speed network traffic. In Proceedings of the IEEE International Conference on Computer Communications, Orlando, FL, USA, 25–30 March 2012; pp. 2741–2745. [Google Scholar] [CrossRef]
- Wang, P.; Guan, X.; Qin, T.; Huang, Q. A data streaming method for monitoring host connection degrees of high-speed links. IEEE Trans. Inf. Forensics Secur. 2011, 6, 1086–1098. [Google Scholar] [CrossRef]
- Liu, W.; Qu, W.; Gong, J.; Li, K. Detection of superpoints using a vector bloom filter. IEEE Trans. Inf. Forensics Secur. 2016, 11, 514–527. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhang, Y.; Ma, C.; Chen, S.; Odegbile, O. Generalized sketch families for network traffic measurement. ACM Meas. Anal. Comput. Syst. 2019, 3, 1–34. [Google Scholar] [CrossRef]
- Cormode, G.; Muthukrishnan, S. An improved data stream summary: The count-min sketch and its applications. J. Algorithms 2005, 55, 58–75. [Google Scholar] [CrossRef]
- Yu, M.; Jose, L.; Miao, R. Software Defined Traffic Measurement with OpenSketch. In Proceedings of the 10th USENIX Symposium on Networked Systems Design and Implementation, Lombard, IL, USA, 2–5 April 2013; pp. 29–42. Available online: https://www.usenix.org/conference/nsdi13/technical-sessions/presentation/yu (accessed on 15 January 2021).
- Schweller, R.T.; Li, Z.; Chen, Y.; Gao, Y.; Gupta, A.; Zhang, Y.; Dinda, P.A.; Kao, M.-Y.; Memik, G. Reversible sketches: Enabling monitoring and analysis over high-speed data streams. IEEE/ACM Trans. Netw. 2007, 15, 1059–1072. [Google Scholar]
- Ecommerce Dataset. Available online: https://www.kaggle.com/retailrocket/ecommerce-dataset?select=events.csv (accessed on 15 January 2021).
- The Caida Anonymized Internet Traces. 2016. Available online: http://www.caida.org/data/overview/ (accessed on 17 March 2021).
- Murmurhash. Available online: https://github.com/aappleby/smhasher/tree/master/src (accessed on 15 June 2021).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Estimator | Memory | Remark |
|---|---|---|
| Bitmap | m | m = n, n is the real cardinality of flow |
| Linear Counter | m | mln (m) > n |
| LogLog | 32 m | Recommended as m = 128 |
| Adaptive Counter | 32 m | Recommended as m = 128 |
| HyperLogLog | 5 m | Recommended as m = 128 |
| Notations | Meanings |
|---|---|
| A data stream | |
| The number of flows in | |
| 32 m | |
| 32 m | |
| 5 m | |
| The fingerprint of flow | |
| Real spread of flow | |
| Estimated spread of flow | |
| Array number | |
| The bucket number in an array | |
| Predefined parameter | |
| Predefined parameter |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Lu, J.; Ren, Q.; Li, Z.; Hu, Y.; Chen, H. An Accurate and Invertible Sketch for Super Spread Detection. Electronics 2024, 13, 222. https://doi.org/10.3390/electronics13010222
Zhang Z, Lu J, Ren Q, Li Z, Hu Y, Chen H. An Accurate and Invertible Sketch for Super Spread Detection. Electronics. 2024; 13(1):222. https://doi.org/10.3390/electronics13010222
Chicago/Turabian StyleZhang, Zheng, Jie Lu, Quan Ren, Ziyong Li, Yuxiang Hu, and Hongchang Chen. 2024. "An Accurate and Invertible Sketch for Super Spread Detection" Electronics 13, no. 1: 222. https://doi.org/10.3390/electronics13010222
APA StyleZhang, Z., Lu, J., Ren, Q., Li, Z., Hu, Y., & Chen, H. (2024). An Accurate and Invertible Sketch for Super Spread Detection. Electronics, 13(1), 222. https://doi.org/10.3390/electronics13010222