
Adapting Pre-Trained Self-Supervised Learning Model for Speech Recognition with Light-Weight Adapters




Abstract
1. Introduction
2. Related Work
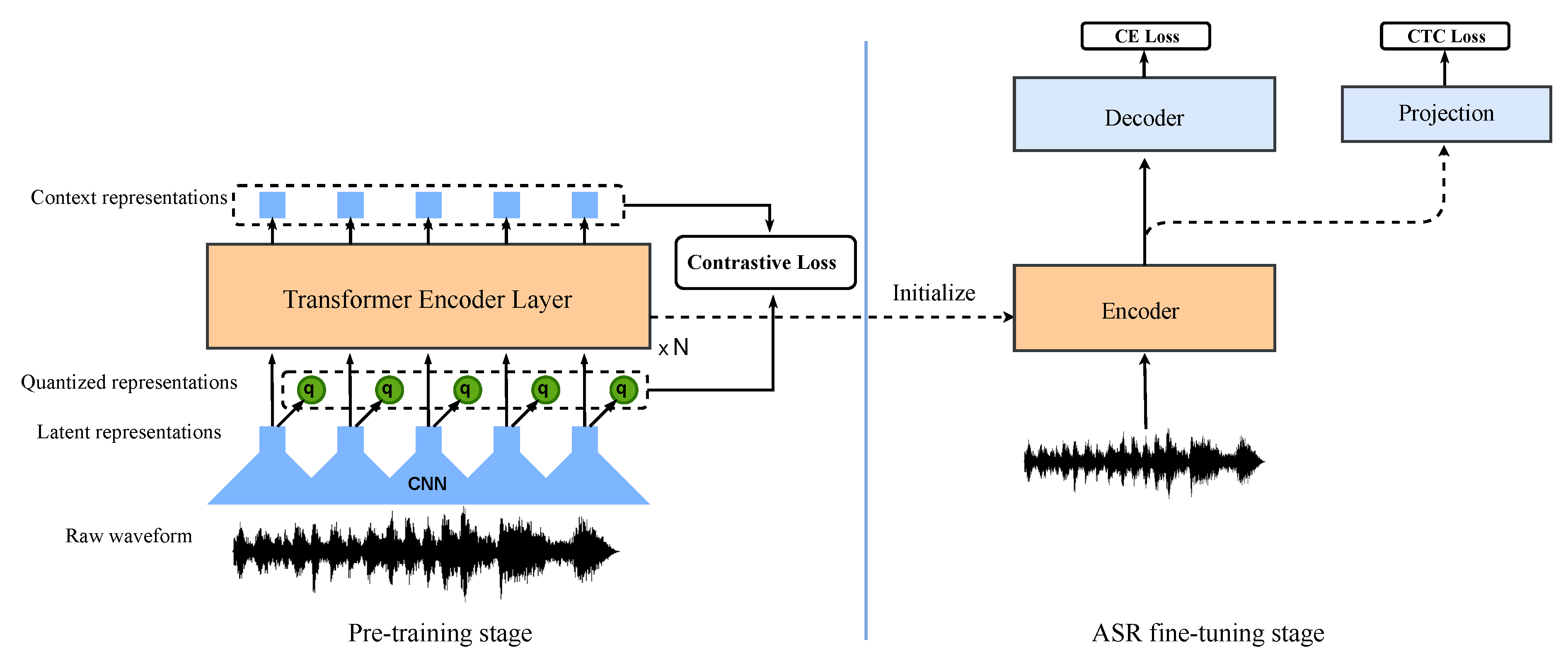
2.1. Pre-Trained Speech Models
2.2. PSMs in End-to-End Speech Recognition
3. Adaptation with Light-Weight Adapters
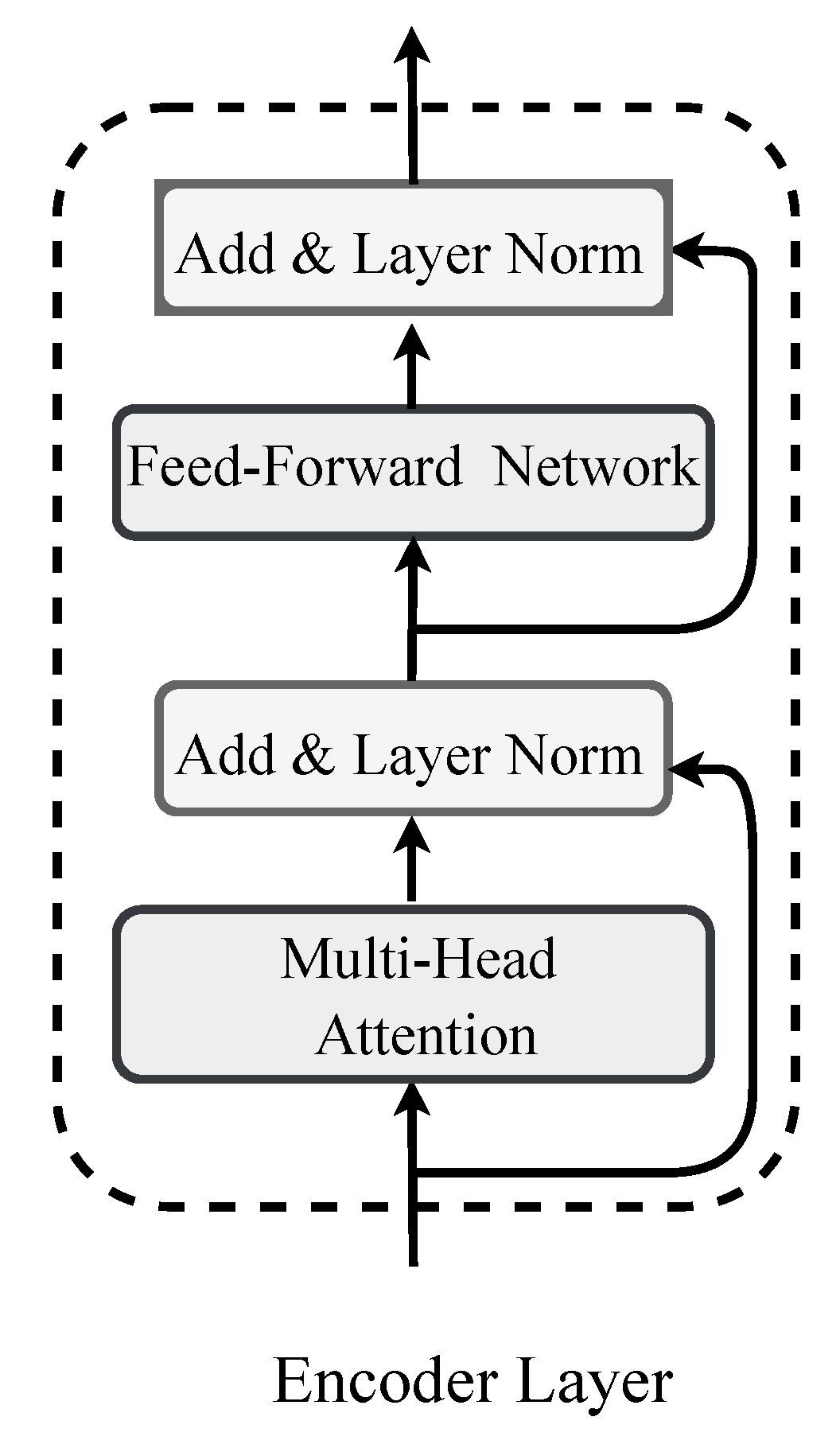
3.1. Transformer Encoder
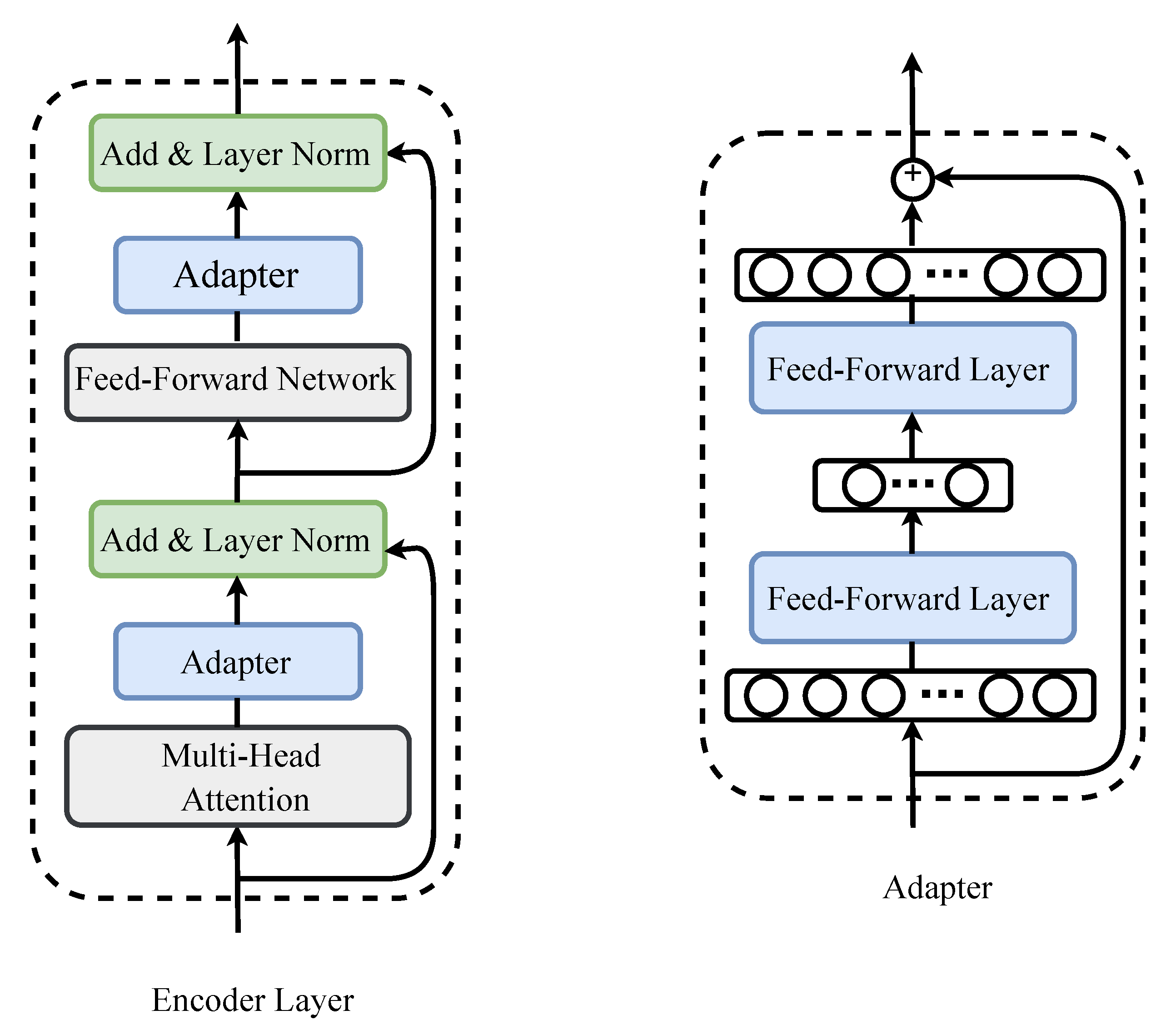
3.2. Light-Weight Adapters
4. Experiments
4.1. Datasets
4.2. Experimental Setup
5. Results and Discussion
5.1. Main Results
5.2. Ablation Study
5.3. Transfer to Encoder–Decoder-Based E2E ASR
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Watanabe, S.; Hori, T.; Kim, S.; Hershey, J.R.; Hayashi, T. Hybrid CTC/attention Architecture for End-to-End Speech Recognition. IEEE J. Sel. Top. Signal Process. 2017, 11, 1240–1253. [Google Scholar] [CrossRef]
- Chan, W.; Jaitly, N.; Le, Q.V.; Vinyals, O. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4960–4964. [Google Scholar]
- Graves, A.; Jaitly, N. Towards end-to-end speech recognition with recurrent neural networks. In Proceedings of the International Conference on Machine Learning (ICML), Beijing, China, 21–26 June 2014; pp. 1764–1772. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-based models for speech recognition. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 577–585. [Google Scholar]
- Chiu, C.C.; Sainath, T.N.; Wu, Y.; Prabhavalkar, R.; Nguyen, P.; Chen, Z. State-of-the-Art Speech Recognition with Sequence-to-Sequence Models. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AL, Canada, 15–20 April 2018; pp. 4774–4778. [Google Scholar]
- Baevski, A.; Zhou, H.; Mohamed, A.; Auli, M. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Virtual, 6–12 December 2020. [Google Scholar]
- Chiu, C.C.; Qin, J.; Zhang, Y.; Yu, J.; Wu, Y. Self-supervised learning with random-projection quantizer for speech recognition. In Proceedings of the International Conference on Machine Learning (ICML), Baltimore, MD, USA, 17–23 July 2022; pp. 3915–3924. [Google Scholar]
- Baevski, A.; Hsu, W.N.; Xu, Q.; Babu, A.; Gu, J.; Auli, M. data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language. In Proceedings of the International Conference on Machine Learning (ICML), Baltimore, MD, USA, 17–23 July 2022; pp. 1298–1312. [Google Scholar]
- Liu, A.; Yang, S.W.; Chi, P.H.; Hsu, P.C.; Lee, H.Y. Mockingjay: Unsupervised speech representation learning with deep bidirectional Transformer encoders. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6419–6423. [Google Scholar]
- Chung, Y.A.; Hsu, W.N.; Tang, H.; Glass, J. Generative pre-training for speech with autoregressive predictive coding. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3497–3501. [Google Scholar]
- Jiang, D.; Lei, X.; Li, W.; Luo, N.; Hu, Y.; Zou, W.; Li, X. Improving Transformer-based Speech Recognition Using Unsupervised Pre-training. arXiv 2019, arXiv:1910.09932. [Google Scholar]
- Jiang, D.; Li, W.; Zhang, R.; Cao, M.; Luo, N.; Han, Y.; Zou, W.; Li, X. A Further Study of Unsupervised Pre-training for Transformer Based Speech Recognition. arXiv 2020, arXiv:2005.09862. [Google Scholar]
- Chorowski, J.; Weiss, R.J.; Bengio, S.; van den Oord, A. Unsupervised speech representation learning using WaveNet autoencoders. IEEE ACM Trans. Audio Speech Lang. Process. 2019, 27, 2041–2053. [Google Scholar] [CrossRef]
- Chung, Y.A.; Glass, J. Improved speech representations with multi-target autoregressive predictive coding. arXiv 2020, arXiv:2004.05274. [Google Scholar]
- Schneider, S.; Baevski, A.; Collobert, R.; Auli, M. wav2vec: Unsupervised pre-training for speech recognition. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 3465–3469. [Google Scholar]
- Pascual, S.; Ravanelli, M.; Serrà, J.; Bonafonte, A.; Bengio, Y. Learning Problem-Agnostic Speech Representations from Multiple Self-Supervised Tasks. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 161–165. [Google Scholar]
- Ravanelli, M.; Zhong, J.; Pascual, S.; Swietojanski, P.; Monteiro, J.; Trmal, J.; Bengio, Y. Multi-Task Self-Supervised Learning for Robust Speech Recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6989–6993. [Google Scholar]
- Jiang, D.; Li, W.; Cao, M.; Zhang, R.; Zou, W.; Han, K.; Li, X. Speech SIMCLR: Combining Contrastive and Reconstruction Objective for Self-supervised Speech Representation Learning. arXiv 2020, arXiv:2010.13991. [Google Scholar]
- Song, X.; Wang, G.; Huang, Y.; Wu, Z.; Su, D.; Meng, H. Speech-XLNet: Unsupervised Acoustic Model Pretraining for Self-Attention Networks. In Proceedings of the INTERSPEECH, Shanghai, China, 25–29 October 2020; pp. 3765–3769. [Google Scholar]
- Liu, A.; Li, S.W.; Lee, H.Y. TERA: Self-supervised learning of Transformer encoder representation for speech. IEEE ACM Trans. Audio Speech Lang. Process. 2020, 27, 2351–2366. [Google Scholar] [CrossRef]
- Chen, S.; Wang, C.; Chen, Z.; Wu, Y.; Liu, S.; Chen, Z.; Li, J.; Kanda, N.; Yoshioka, T.; Xiao, X.; et al. WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing. IEEE J. Sel. Top. Signal Process. 2022, 16, 1505–1518. [Google Scholar] [CrossRef]
- Baevski, A.; Auli, M.; Rahman Mohamed, A. Effectiveness of self-supervised pre-training for speech recognition. arXiv 2019, arXiv:1911.03912. [Google Scholar]
- Wang, W.; Tang, Q.; Livescu, K. Unsupervised Pre-Training of Bidirectional Speech Encoders via Masked Reconstruction. In Proceedings of the ICASSP 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6889–6893. [Google Scholar]
- Yi, C.; Wang, J.; Cheng, N.; Zhou, S.; Xu, B. Applying Wav2vec2.0 to Speech Recognition in Various Low-resource Languages. arXiv 2020, arXiv:2012.12121. [Google Scholar]
- Cheng, Y.; Shiyu, Z.; Bo, X. Efficiently Fusing Pretrained Acoustic and Linguistic Encoders for Low-Resource Speech Recognition. IEEE Signal Process. Lett. 2021, 28, 788–792. [Google Scholar]
- McCloskey, M.; Cohen, N.J. Catastrophic Interference in Connectionist Networks: The Sequential Learning Problem. Psychol. Learn. Motiv. 1989, 24, 109–165. [Google Scholar]
- Dodge, J.; Ilharco, G.; Schwartz, R.; Farhadi, A.; Hajishirzi, H.; Smith, N. Fine-Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early Stopping. arXiv 2020, arXiv:2002.06305. [Google Scholar]
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; de Laroussilhe, Q. Parameter-Efficient Transfer Learning for NLP. arXiv 2019, arXiv:1902.00751. [Google Scholar]
- Wang, R.; Tang, D.; Duan, N.; Wei, Z.; Huang, X.; Ji, J.; Cao, G.; Jiang, D.; Zhou, M. K-Adapter: Infusing Knowledge into Pre-Trained Models with Adapters. arXiv 2020, arXiv:2002.01808. [Google Scholar]
- Qi, J.; Yang, C.H.H.; Chen, P.Y.; Tejedor, J. Exploiting Low-Rank Tensor-Train Deep Neural Networks Based on Riemannian Gradient Descent with Illustrations of Speech Processing. IEEE ACM Trans. Audio Speech Lang. Process. 2023, 31, 633–642. [Google Scholar] [CrossRef]
- Yang, C.H.H.; Qi, J.; Siniscalchi, S.M.; Lee, C.H. An Ensemble Teacher-Student Learning Approach with Poisson Sub-sampling to Differential Privacy Preserving Speech Recognition. In Proceedings of the 2022 13th International Symposium on Chinese Spoken Language Processing (ISCSLP), Singapore, 11–14 December 2022; pp. 1–5. [Google Scholar]
- Kahn, J.; Riviere, M.; Zheng, W.; Kharitonov, E.; Xu, Q.; Mazare, P. Libri-Light: A Benchmark for ASR with Limited or No Supervision. arXiv 2019, arXiv:1912.07875. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the ICASSP, Brisbane, QL, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Paul, D.B.; Baker, J. The Design for the wall street journal-based CSR Corpus. In Proceedings of the workshop on Speech and Natural Language, Harriman, NY, USA, 23–26 February 1992; pp. 357–362. [Google Scholar]
- van den Oord, A.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Chen, S.; Wu, Y.; Wang, C.; Chen, Z.; Chen, Z.; Liu, S.; Wu, J.; Qian, Y.; Wei, F.; Li, J.; et al. Unispeech-Sat: Universal Speech Representation Learning With Speaker Aware Pre-Training. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 7–13 May 2022; pp. 6152–6156. [Google Scholar]
- Vaessen, N.; Van Leeuwen, D.A. Fine-Tuning Wav2Vec2 for Speaker Recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 7–13 May 2022; pp. 7967–7971. [Google Scholar]
- Huang, Z.; Watanabe, S.; Yang, S.w.; García, P.; Khudanpur, S. Investigating Self-Supervised Learning for Speech Enhancement and Separation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 7–13 May 2022; pp. 6837–6841. [Google Scholar]
- Nguyen, H.; Bougares, F.; Tomashenko, N.; Estève, Y.; Besacier, L. Investigating Self-Supervised Pre-Training for End-to-End Speech Translation. In Proceedings of the INTERSPEECH, Shanghai, China, 25–29 October 2020; pp. 1466–1470. [Google Scholar]
- Fukuda, R.; Sudoh, K.; Nakamura, S. Improving Speech Translation Accuracy and Time Efficiency with Fine-tuned wav2vec 2.0-based Speech Segmentation. IEEE ACM Trans. Audio Speech Lang. Process. 2023, 1–12. [Google Scholar] [CrossRef]
- Huh, J.; Heo, H.S.; Kang, J.; Watanabe, S.; Chung, J.S. Augmentation adversarial training for self-supervised speaker recognition. arXiv 2020, arXiv:2007.12085. [Google Scholar]
- Chen, X.; He, K. Exploring Simple Siamese Representation Learning. arXiv 2020, arXiv:2011.10566. [Google Scholar]
- Giorgi, J.M.; Nitski, O.; Bader, G.D.; Wang, B. DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations. arXiv 2020, arXiv:2006.03659. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernocký, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the INTERSPEECH, Chiba, Japan, 26–30 September 2010; pp. 1045–1048. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Rivière, M.; Joulin, A.; Mazaré, P.E.; Dupoux, E. Unsupervised Pretraining Transfers Well Across Languages. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 414–7418. [Google Scholar]
- Rebuffi, S.A.; Bilen, H.; Vedaldi, A. Learning multiple visual domains with residual adapters. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 506–516. [Google Scholar]
- Sung, Y.L.; Cho, J.; Bansal, M. VL-Adapter: Parameter-Efficient Transfer Learning for Vision-and-Language Tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LO, USA, 18–24 June 2022; pp. 5227–5237. [Google Scholar]
- Chen, T.; Zhu, L.; Deng, C.; Cao, R.; Wang, Y.; Zhang, S.; Li, Z.; Sun, L.; Zang, Y.; Mao, P. SAM-Adapter: Adapting Segment Anything in Underperformed Scenes. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Paris, France, 2–3 October 2023; pp. 3367–3375. [Google Scholar]
- Shah, A.; Thapa, S.; Jain, A.; Huang, L. ADEPT: Adapter-based Efficient Prompt Tuning Approach for Language Models. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), Toronto, ON, Canada, 9–14 July 2023; pp. 121–128. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 3–8 December 2018; pp. 6000–6010. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wu, F.; Fan, A.; Baevski, A.; Dauphin, Y.N.; Auli, M. Pay Less Attention with Lightweight and Dynamic Convolutions. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Ao, J.; Zhang, Z.; Zhou, L.; Liu, S.; Li, H.; Ko, T.; Dai, L.; Li, J.; Qian, Y.; Wei, F. Pre-Training Transformer Decoder for End-to-End ASR Model with Unpaired Speech Data. In Proceedings of the INTERSPEECH, Virtual, 14 September 2022. [Google Scholar]
- Ling, S.; Liu, Y. DeCoAR 2.0: Deep Contextualized Acoustic Representations with Vector Quantization. arXiv 2020, arXiv:2012.06659. [Google Scholar]
- Park, D.S.; Zhang, Y.; Jia, Y.; Han, W.; Chiu, C.C.; Li, B.; Wu, Y.; Le, Q.V. Improved Noisy Student Training for Automatic Speech Recognition. In Proceedings of the INTERSPEECH, Shanghai, China, 25–29 October 2020; pp. 2817–2821. [Google Scholar]
- Talnikar, C.; Likhomanenko, T.; Collobert, R.; Synnaeve, G. Joint Masked CPC and CTC Training for ASR. arXiv 2020, arXiv:2011.00093. [Google Scholar]
- Watanabe, S.; Hori, T.; Karita, S.; Hayashi, T.; Nishitoba, J. ESPnet: End-toend speech processing toolkit. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018; pp. 2207–2211. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Method | Fine-Tuning Data | Test-Clean | Test-Other |
|---|---|---|---|
| Continuous BERT + LM [22] | 10 min | 49.5 | 66.3 |
| 1 h | 22.4 | 44.0 | |
| 10 h | 14.1 | 34.3 | |
| Continuous BERT + LM [22] | 10 min | 16.3 | 25.2 |
| 1 h | 9.0 | 17.6 | |
| 10 h | 5.9 | 14.1 | |
| DeCoAR 2.0 + LM [57] | 1 h | 13.8 | 29.1 |
| 10 h | 5.4 | 11.3 | |
| 100 h | 5.0 | 12.1 | |
| WavLM [21] | 1 h | 24.5 | 29.2 |
| 10 h | 9.8 | 16.0 | |
| 100 h | 5.7 | 12.0 | |
| Whole model fine-tuning [6] | 10 min | 46.9 | 50.9 |
| 1 h | 24.5 | 30.2 | |
| 10 h | 9.4 | 16.6 | |
| 100 h | 6.1 | 13.3 | |
| Proposed FTA | 10 min | 38.7 | 44.7 |
| 1 h | 19.2 | 26.7 | |
| 10 h | 9.4 | 17.0 | |
| 100 h | 5.4 | 13.5 |
| Method/WER | # Params | Test-Clean | Test-Other |
|---|---|---|---|
| Noisy student + LM [58] | - | 4.2 | 8.6 |
| Joint CPC-CTC [59] | - | 6.2 | 13.9 |
| Whole model fine-tuning [6] | 95 M | 6.1 | 13.3 |
| Proposed FTA | |||
| Adapter | 14 M | 5.4 | 13.5 |
| Adapter | 9 M | 6.3 | 13.7 |
| Adapter | 7 M | 6.4 | 14.1 |
| Method/WER | test_dev93 | test_eval92 |
|---|---|---|
| Transformer (ESPnet) [60] | 18.6 | 14.8 |
| + LM [60] | 8.8 | 5.6 |
| Whole model fine-tuning | ||
| top 12 layers (full) | 7.7 | 6.4 |
| top 8 layers | 9.2 | 8.4 |
| top 6 layers | 10.0 | 8.8 |
| top 4 layers | 15.0 | 13.2 |
| Proposed FTA | ||
| Adapter | 7.7 | 6.1 |
| Adapter | 7.6 | 6.5 |
| Adapter | 8.0 | 6.5 |
| Adapter | 8.2 | 7.1 |
| Adapter | 7.9 | 6.2 |
| Adapter | 7.9 | 6.4 |
| Adapter | 10.7 | 9.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yue, X.; Gao, X.; Qian, X.; Li, H. Adapting Pre-Trained Self-Supervised Learning Model for Speech Recognition with Light-Weight Adapters. Electronics 2024, 13, 190. https://doi.org/10.3390/electronics13010190
Yue X, Gao X, Qian X, Li H. Adapting Pre-Trained Self-Supervised Learning Model for Speech Recognition with Light-Weight Adapters. Electronics. 2024; 13(1):190. https://doi.org/10.3390/electronics13010190
Chicago/Turabian StyleYue, Xianghu, Xiaoxue Gao, Xinyuan Qian, and Haizhou Li. 2024. "Adapting Pre-Trained Self-Supervised Learning Model for Speech Recognition with Light-Weight Adapters" Electronics 13, no. 1: 190. https://doi.org/10.3390/electronics13010190
APA StyleYue, X., Gao, X., Qian, X., & Li, H. (2024). Adapting Pre-Trained Self-Supervised Learning Model for Speech Recognition with Light-Weight Adapters. Electronics, 13(1), 190. https://doi.org/10.3390/electronics13010190