
Speech Enhancement Performance Based on the MANNER Network Using Feature Fusion


Abstract
:1. Introduction
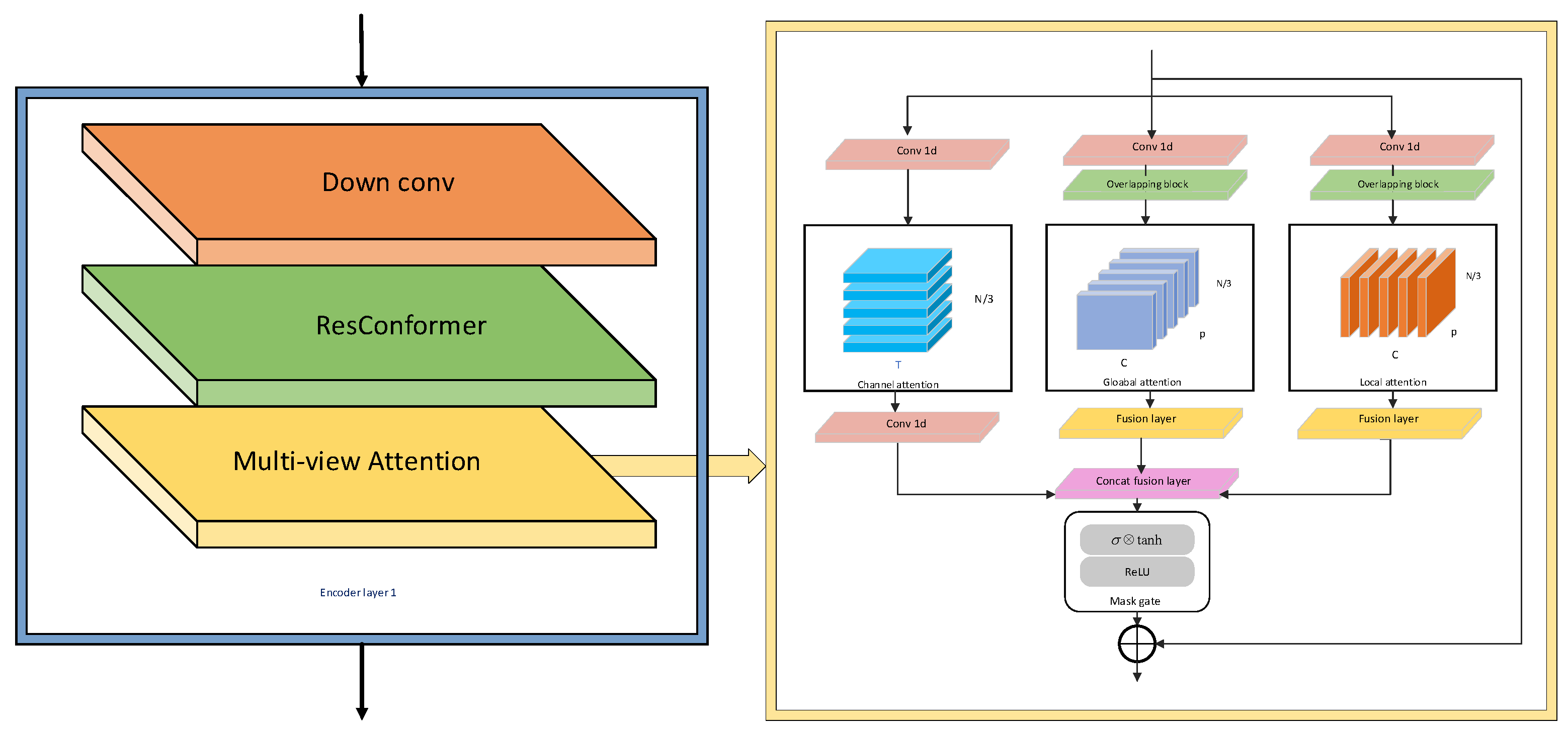
2. AF-MANNER Network
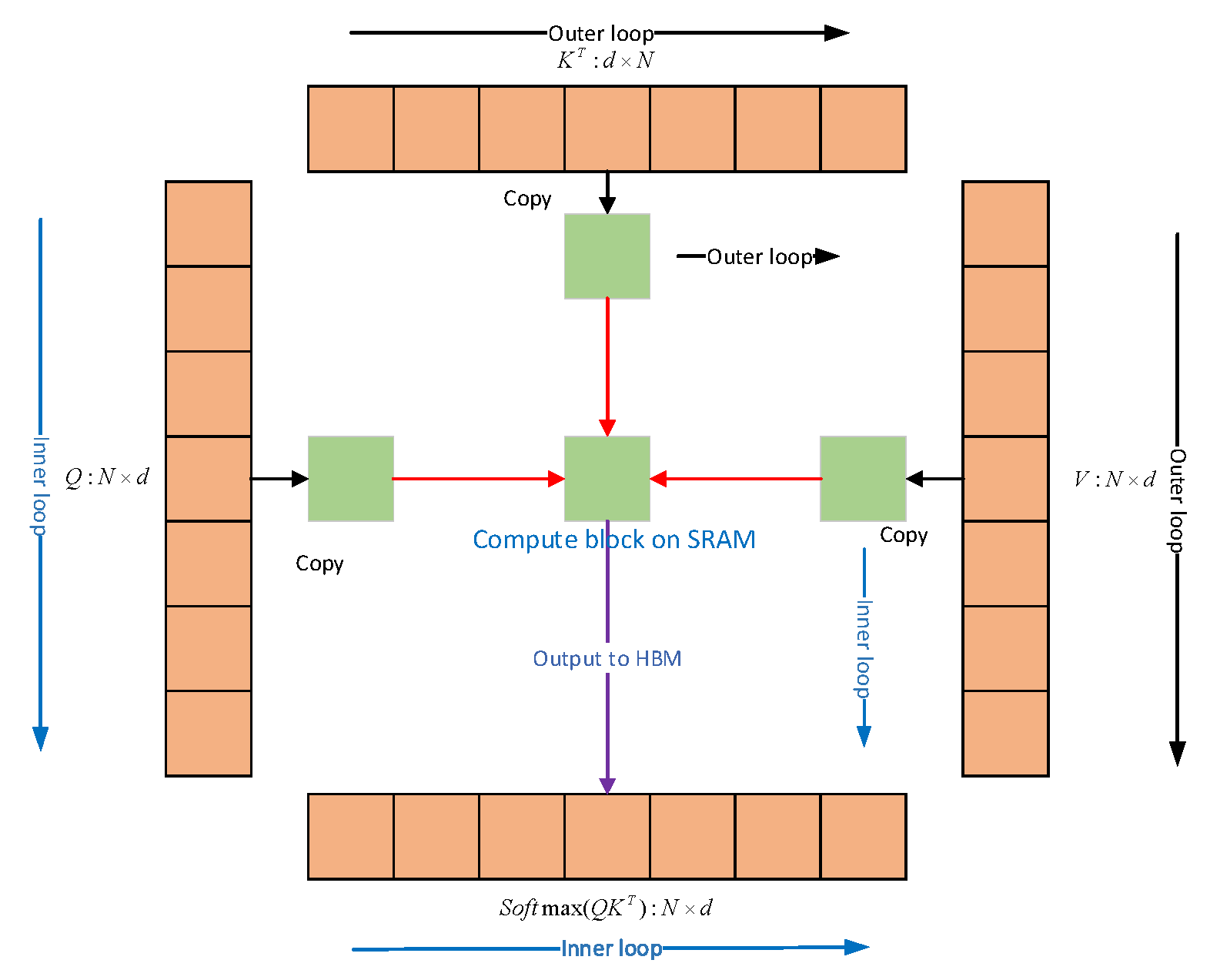
2.1. Flash Attention
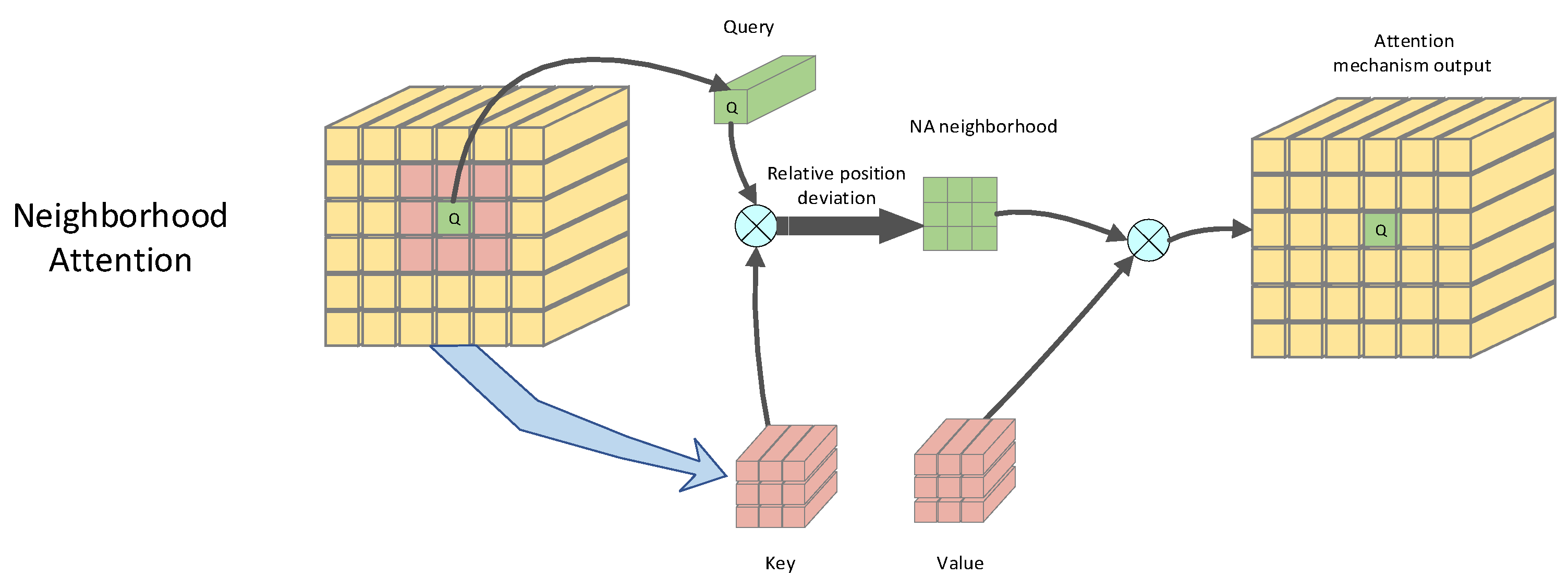
2.2. Neighborhood Attention
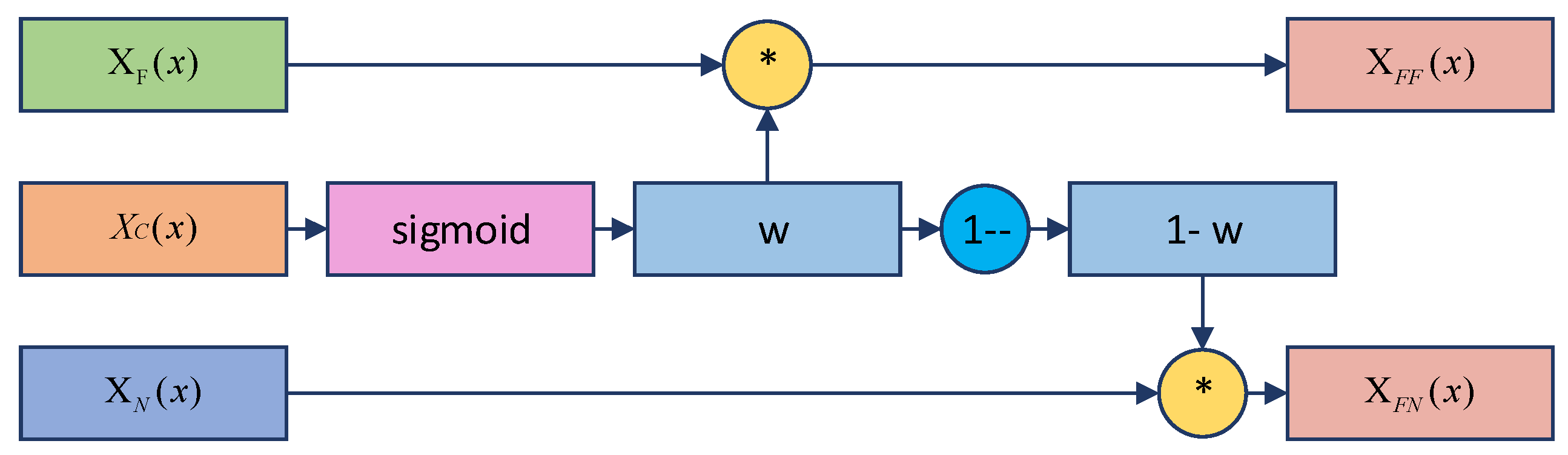
2.3. Fuse Block
2.4. Improved MANNER Network
3. Experimental Setup
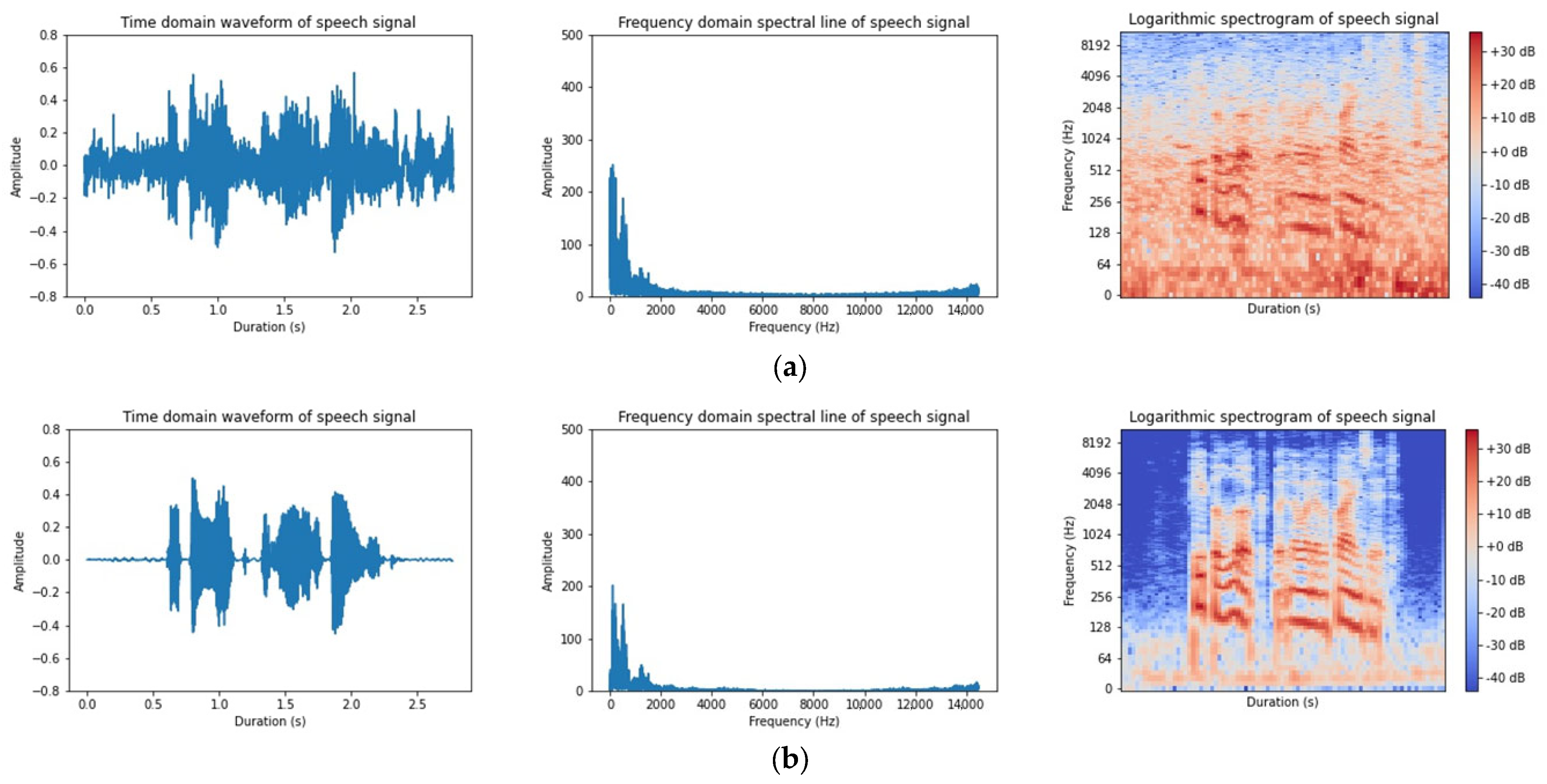
3.1. Experimental Data Set
3.2. Evaluation Indicators
3.3. Experimental Platform
4. Results
4.1. Parameter Settings
4.2. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jeong, J.; Mondol, S.; Kim, Y.; Lee, S. An Effective Learning Method for Automatic Speech Recognition in Korean CI Patients’ Speech. Electronics 2021, 10, 807. [Google Scholar] [CrossRef]
- Faghani, M.; Rezaee-Dehsorkh, H.; Ravanshad, N.; Aminzadeh, H. Ultra-Low-Power Voice Activity Detection System Using Level-Crossing Sampling. Electronics 2023, 12, 795. [Google Scholar] [CrossRef]
- Price, M.; Glass, G.; Chandrakasan, A.P. A Low-Power Speech Recognizer and Voice Activity Detector Using Deep Neural Networks. IEEE J. Solid-State Circuits 2018, 53, 66–75. [Google Scholar] [CrossRef]
- Oh, S.; Cho, M.; Shi, Z.; Lim, J.; Kim, Y.; Jeong, S.; Chen, Y.; Rother, R.; Blaauw, D.; Kim, H.; et al. An Acoustic Signal Processing Chip with 142-nW Voice Activity Detection Using Mixer-Based Sequential Frequency Scanning and Neural Network Classification. IEEE J. Solid-State Circuits 2019, 54, 3005–3016. [Google Scholar] [CrossRef]
- Park, S.-M.; Kim, Y.-G. A Metaverse: Taxonomy, Components, Applications, and Open Challenges. IEEE Access 2022, 10, 4209–4251. [Google Scholar]
- Hu, Y.; Hou, N.; Chen, C.; Chng, E.S. Interactive Feature Fusion for End-to-End Noise-Robust Speech Recognition. In Proceedings of the ICASSP 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022. [Google Scholar]
- Shi, Y.; Bai, J.; Xue, P.; Shi, D. Fusion Feature Extraction Based on Auditory and Energy for Noise-Robust Speech Recognition. IEEE Access 2019, 7, 81911–81922. [Google Scholar] [CrossRef]
- Li, C. Robotic Emotion Recognition Using Two-Level Features Fusion in Audio Signals of Speech. EEE Sens. J. 2022, 22, 17447–17454. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Pandey, A.; Wang, D. Dual-path Self-Attention RNN for Real-Time Speech Enhancement. arXiv 2020, arXiv:2010.12713. [Google Scholar]
- Ozan, O.; Jo, S.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.; Kainz, B.; et al. Attention U-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Giri, R.; Isik, U.; Krishnaswamy, A. Attention Wave-U-Net for Speech Enhancement. In Proceedings of the 2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 20–23 October 2019. [Google Scholar]
- Hwang, J.-W.; Park, R.-H.; Park, H.-M. Efficient Audio-Visual Speech Enhancement Using Deep U-Net with Early Fusion of Audio and Video Information and RNN Attention Blocks. IEEE Access 2021, 9, 137584–137598. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Wang, K.; He, B.; Zhu, W.-P. TSTNN:Two-stage Transformer based Neural Network for Speech Enhancement in the Time Domain. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Park, H.J.; Kang, B.H.; Shin, W.; Kim, J.S.; Han, S.W. MANNER: Multi-View Attention Network for Noise Erasure. arXiv 2022, arXiv:2203.02181. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2016, arXiv:1409.0473. [Google Scholar]
- Luong, M.-T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Atkinson, R.C.; Herrnstein, R.J. Perception and Motivation; Learning and Cognition. In Stevens’ Handbook of Experimental Psychology, 3rd ed.; Lindzey, G., Luce, R.D., Eds.; John Wiley & Sons: Oxford, UK, 1988; Volume 1, p. 739. [Google Scholar]
- Gulati, A.; Qin, J. Conformer: Convolution-augmented Transformer for Speech Recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Dao, T.; Fu, D.Y.; Ermon, S.; Rudra, A.; Ré, C. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. arXiv 2022, arXiv:2205.14135. [Google Scholar]
- Hassani, A.; Walton, S.; Li, J.; Li, S.; Shi, H. Neighborhood Attention Transformer. arXiv 2022, arXiv:2204.07143. [Google Scholar]
- Veaux, C.; Yamagishi, J.; King, S. The voice bank corpus: Design, collection and data analysis of a large regional accent speech database. In Proceedings of the 2013 International Conference Oriental COCOSDA Held Jointly with 2013 Conference on Asian Spoken Language Research and Evaluation (O-COCOSDA/CASLRE), Gurgaon, India, 25–27 November 2013. [Google Scholar]
- Thiemann, J.; Ito, N.; Vincent, E. The diverse environments multi-channel acoustic noise database: A database of multichannel environmental noise recordings. J. Acoust. Soc. Am. 2013, 5, 3591. [Google Scholar] [CrossRef]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (pesq): An objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing, (Cat. No.01CH37221), Salt Lake City, UT, USA, 7–11 May 2001. [Google Scholar]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. An Algorithm for Intelligibility Prediction of Time–Frequency Weighted Noisy Speech. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2125–2136. [Google Scholar] [CrossRef]
- Hu, Y.; Loizou, P.C. Evaluation of Objective Quality Measures for Speech Enhancement. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 229–238. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Configuration Information |
|---|---|
| CPU | i7-12700F |
| GPU | NVIDIA RTX3090 |
| RAM | 16.0 GB |
| Operating System | Ubuntu 22.04 |
| GPU Accelerator | CUDA 11.6 |
| Development Language | Python 3.8 |
| Development Framework | PyTorch 1.12 |
| Audio Reading Tool | Torchaudio |
| Audio Visualization Tool | Matplotlib |
| Model | STOI | PESQ |
|---|---|---|
| MANNER | 91.74 | 2.4399 |
| Flash MANNER | 93.44 | 2.5697 |
| Flash fuse MANNER | 93.25 | 2.5739 |
| AF-MANNER | 93.65 | 2.5942 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Li, J.; Shao, L.; Liu, H.; Zhu, L.; Zhu, X. Speech Enhancement Performance Based on the MANNER Network Using Feature Fusion. Electronics 2023, 12, 1768. https://doi.org/10.3390/electronics12081768
Wang S, Li J, Shao L, Liu H, Zhu L, Zhu X. Speech Enhancement Performance Based on the MANNER Network Using Feature Fusion. Electronics. 2023; 12(8):1768. https://doi.org/10.3390/electronics12081768
Chicago/Turabian StyleWang, Shijie, Ji Li, Lei Shao, Hongli Liu, Lihua Zhu, and Xiaochen Zhu. 2023. "Speech Enhancement Performance Based on the MANNER Network Using Feature Fusion" Electronics 12, no. 8: 1768. https://doi.org/10.3390/electronics12081768
APA StyleWang, S., Li, J., Shao, L., Liu, H., Zhu, L., & Zhu, X. (2023). Speech Enhancement Performance Based on the MANNER Network Using Feature Fusion. Electronics, 12(8), 1768. https://doi.org/10.3390/electronics12081768