Abstract
The problems that the multi-view attention network for noise erasure (MANNER) cannot take into account are the local and global features in the speech enhancement of long sequences. An attention and feature fusion MANNER (AF-MANNER) network is proposed, which improves the multi-view attention (MA) module in MANNER and replaces the global and local attention in the module. AF-MANNER also designs the feature-weighted fusion module to fuse the features of flash attention and neighborhood attention to enhance the feature expression of the network. The final ablation studies show that this network exhibits a good performance in speech enhancement and that its structure is valuable for improving the intelligibility and perceptual quality of speech.
1. Introduction
Speech enhancement techniques aim to separate clean speech from interference in order to improve the intelligibility and perceptual quality of the speech, and are used in various fields such as automatic speech recognition, voice activity detection, and speech emotion recognition. Automatic speech recognition (ASR) is the study of technologies that enable the conversion of acoustic signals into textual information. Intelligent voice interaction is more natural and requires less space on a device. ASR models are used to interconnect smart voice assistants such as Siri and Bixby on personal cell phones for network interconnection. An ASR model was also used to improve the recognition rate of the speech of non-standard cochlear implant users [1]. ASR models trained on standard speech datasets are not available for people using non-standard speech, and this study personalizes the pre-trained models. The voice activity detection (VAD) technique is used for speech and non-speech classification. VAD as a wake-up system can activate the power-consuming processing system in the presence of a voice [2,3,4]. The hardware VAD system should be designed with a low power consumption and low complexity. Using the VAD wake-up system can significantly reduce the power consumption of the whole system. Speech emotion recognition (SER) is gaining attention with the development of the metaverse [5]. SER is able to use emotion recognition to achieve more realistic interactions and increase the immersion of these interactions.
The emergence of neural-network-based speech enhancement models has greatly facilitated the development of speech enhancement. The application of feature fusion technology to a speech enhancement network makes its feature information acquisition more complete and further improves the speech enhancement performance. In speech enhancement, feature fusion techniques are often used to integrate speech enhancement with other speech-related techniques. The speech feature information is interacted with so that the enhanced speech can learn complementary information for a clear speech extraction from multiple perspectives. Hu et al. [6] built a joint system containing a speech enhancement module and an automatic speech recognition module. Its two branches were used to exchange information between the speech-enhancing features and noisy features. A weight mask was used to indicate which features could be retained, and then the features were weighted and summed, complementing the clean speech information with useful noise features to improve the speech enhancement performance. Since noise can pose a great threat to this speech recognition and enhancement, feature fusion techniques play an important role in noise-robust speech recognition. Shi et al. [7] proposed the use of a power-law nonlinear function to extract a new feature that could simulate the auditory features of the human ear. Then, by introducing speech enhancement techniques into the feature extraction front-end, the extracted features and their first-order differences were combined into new hybrid features that fully characterized the auditory and energy information in the speech signal. Feature fusion has also been used in speech emotion recognition. The aspect of intelligent robotics research requires a lot of interaction between humans and robots, so speech emotion recognition is a very important part of this. Li et al. [8] studied robot–human interactions and made a robot’s emotion expression more accurate by fusing different features to represent its signals.
The time–frequency domain approach to speech enhancement converts the short-time Fourier transform (STFT) of the original signal into a spectrogram, from which the clean speech is estimated. Although the spectrogram contains the time and frequency of the signal, it needs to process both the amplitude and phase information, using the complex value information to estimate the complex value mask. This increases the difficulty and complexity of the model. U-Net [9,10,11] utilizes a U-shaped architecture for an efficient feature compression, incorporating the multi-scale features of speech based on a neural network model. The two-path model structure splits long sequences into smaller blocks and iteratively extracts the local feature and global feature information. At a limited model size, it accomplishes the task of speech separation well, but its characterization is still limited at small channel sizes. In order to improve the denoising quality of the U-Net architecture, Giri et al. [12] proposed an attention-based mechanism for the U-Net architecture. Their research did not involve a study of the use of similar attentional mechanisms for a complex-spectrum U-net. To address the problem of its difficulty in capturing the long sequence features in U-Net networks, Hwang et al. [13] proposed an A-VSE model based on the U-Net structure, using recurrent neural network attention (RA) to extend the U-Net to capture all the features. The A-VSE model successfully removed the competing speech and effectively estimated the complex spectral mask for the speech enhancement, but did not yet consider the robustness of the speech recognition model. A transformer model [14] is a natural language processing model that is based on self-attentive mechanisms. Wang et al. [15] designed the two-stage transformer model, which can effectively remove the burst background noise with a short duration and poor correlation. TSTNN can effectively extract the local and global contextual information of long-sequence speech, but the inference speed of the TSTNN model is slow and its memory usage rate is low. Based on the U-net structure and attention mechanisms, Park et al. [16] proposed the Multi-view Attention Network for Noise ERasure (MANNER), with emphasis on the channel and long sequence features to evaluate clean speech. However, the attention mechanism in the baseline network operates through a matrix dot product and Softmax. Since Softmax is calculated in the whole during the operation, the higher the dimension of the matrix, the more efficient the memory reading and writing that is required, which increases the memory usage and makes the speech enhancement less effective. The algorithm performs on a large amount of data, resulting in slow training and a lengthy time for the speech enhancement. The buffer window interval for the local attention in the baseline network is not flexible, which affects the network’s grasping of the feature information and leads to a lower quality of the speech enhancement. The baseline network cannot take into account both the local and global features in the speech enhancement of long sequences, which affects the control of the integrity of the feature information and the accuracy of the semantic expression when performing the speech enhancement.
Based on the above issues, flash attention and neighborhood attention were used in place of global attention and local attention [17,18] in the multi-view attention (MA) module to effectively solve the problem of baseline networks finding it more difficult to extract local and global features and fully express speech information. A feature fusion module was built to couple these flash attention features and neighborhood attention features. The new network used a fusion module to combine these features of flash attention and neighborhood attention to normalize the attention mechanism. The advantages of these two attention mechanisms are exhibited to improve the completeness of the global feature information and local feature information extraction. The AF-MANNER structure was designed and the ablation studies proved that its structure had a great improvement on the speech enhancement performance.
2. AF-MANNER Network
MANNER consists of a convolutional encoder–decoder with a multi-viewpoint attention mechanism [19]. Its U-shaped symmetric structure uses convolutional blocks to compress the features of the information channel and completes the feature fusion by retaining the features of each encoding layer to each decoding layer through hopping connections. The encoder and decoder in the network consist of upsampling and downsampling convolutional layers, a ResConformer block, and an MA module. The Conformer module [20] is a convolutional enhancement converter that was proposed by Anmol Gulati et al. They combined convolution and a self attention module and took full advantage of the self attention module’s feature of obtaining global feature information. Then, by using convolution to effectively capture the local feature information, based on the relative offsets for supplementation, the extracted features could achieve good results. In MANNER, inspired by the Conformer, the ResConformer is designed to avoid losing the data detail information and enhance the acquisition of the voice feature information. The ResConformer module extends the information channel size at a deep level, enabling the MANNER network to obtain richer feature data.
First of all, MANNER performs a channel transformation after a noisy input of a signal length T, which passes through a one-dimensional convolutional layer. A batch normalization and ReLU activation are then performed. The one-dimensional convolutional layer transforms the information channel to N, according to . Then, it goes through the encoder module for encoding, through the linear layer for linear variation, and into the decoder for decoding. The encoder and decoder are both 60 layers. Finally, the channel transformation is performed through one-dimensional convolution, and the final output is clean audio.
The MA module consists of channel attention [21], global attention, and local attention. The structure diagram of the encoder and MA module is shown in Figure 1.
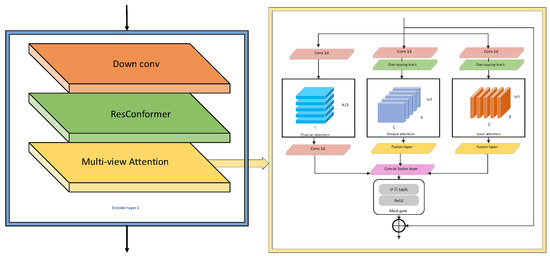
Figure 1.
Structure of encoder and MA module.
The global variables in the MA module must consider the source element at each target element, which is computationally expensive and causes information loss when processing the long sequences of speech signals. Just concentrating on the local source location information for each target element does not provide flexibility, and local variables need to minimize the computational load that is associated with the learning of these local features by training and extending vast volumes of data. Therefore, MANNER causes the problems of a difficulty in capturing complete long sequence features and the inflexible movement of the window for capturing these local features, which leads to computational difficulties.
2.1. Flash Attention
Dao et al. [22] proposed flash attention, which this paper uses to replace the global attention in the MA module. To accelerate the attention mechanism, flash attention mainly uses tiling and recomputation to sense the number of reads and writes between the High Bandwidth Memory (HBM) and Static Random Memory (SRAM) levels in the GPU, and this approach is able to reduce the computational complexity. Firstly, as shown in Figure 2, the flash attention extracts an attention matrix of an N × N size on the High Bandwidth Memory, which is a relatively slow computational memory. It is then iterated through the K and V matrices during the outer loop and the Q matrix during the inner loop. Then, the Q, K, and V matrices are loaded on the Static Random Memory and the attention calculation is performed. Finally, the output is reassembled in the HBM.
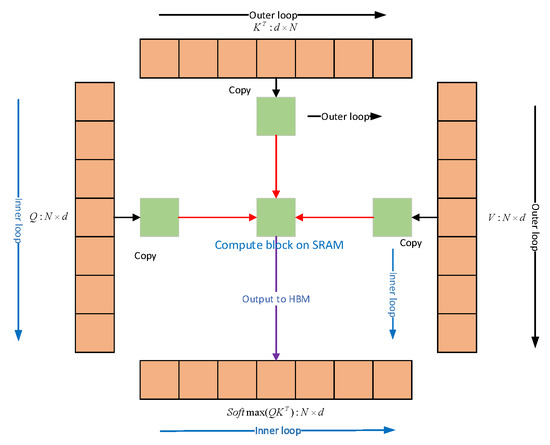
Figure 2.
Q, K, and V structure of flash attention.
The flash attention is calculated incrementally by block, using chunked Softmax and the storage of the normalized Softmax coefficients to complete the recalculation of the attention. The final fine-grained control of the memory accesses is implemented on the CUDA kernel. The chunked Softmax is shown as:
This transfers the chunk matrix from the HBM to the SRAM for a memory read and write acceleration.
In the forward operation, only the intermediate operations are saved in the HBM, and the recalculation of the attention matrices and is achieved by combining them with the Q, K, and V matrices in the backpropagation process, as according to Equation (4).
2.2. Neighborhood Attention
Ali Hassani et al. [23] proposed neighborhood attention (NA) and this paper uses this neighborhood attention to replace the local attention in the MA module. NA is based on Self Attention (SA) [14]. Locating SA to the neighborhood of the target element presents a similar but superior way of working toward convolution. Its sliding window is equivalent to the convolution kernel. The Q, K, and V structure of the single-pixel neighborhood attention is shown in Figure 3. Neighborhood attention has a flexible sliding window mode and its acceptance field can grow flexibly under a dynamic moving window without additional element cyclic shift operations. Neighborhood attention can maintain translational isotropy and all its elements can maintain the same attention duration.
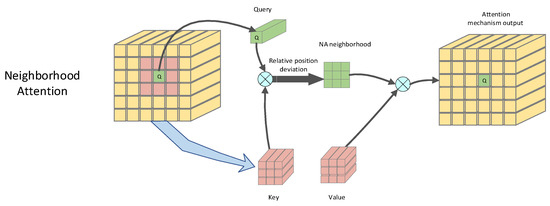
Figure 3.
Q, K, and V structure of neighborhood attention.
Given a d-dimensional source input matrix X, the attention score of the ith input element is defined by choosing the click model, as shown in Equation (5).
where is the query value of the ith input element, is the neighboring key value, is the jth neighboring element of the ith input element, and is the relative position bias of the jth neighboring element. Defining the neighborhood value mapped to V is shown as follows:
Thus, the neighborhood of the ith target element of the neighboring domain size z notes the definition output, as shown in Equation (7).
where is the output for the neighborhood attention mechanism, and is the scalar parameter.
SA allows each target element to focus on all the source input elements, while NA locates the attention of each target element to its own surrounding neighborhoods. The acceptance domain of NA grows to the same size as the input, which is defined in the same way as SA.
2.3. Fuse Block
Convolution achieves the extraction of the local features from the speech through convolutional kernels. A convolutional structure that uses a finite convolutional kernel size suffers from the problem of an insufficient global information representation. The attention mechanism can perform a similarity calculation on the overall feature data and achieve the global feature extraction. However, there is still a possibility of losing the local spatial information, which can lead to a decrease in the accuracy of the speech enhancement. For the problems of a difficulty in acquiring the local features with an attention mechanism and an inadequate representation of the global information through convolution, a fuse-block-named feature-weighting fusion module is built. Flash attention can use fewer memory accesses for an accurate computation and can avoid the reading and writing attention matrices between HBMs. The sliding window of neighborhood attention ensures that its perceptual field grows without additional pixel shifts. The feature-weighting fusion module can bring together the advantages of flash attention and neighborhood attention to improve the network’s feature fitting ability and express the feature information more fully.
The principle of the feature-weighting fusion module is shown in Figure 4. Since channel attention extracts the correlation of the features between the channels, channel attention features are used as a constraint when coupling the flash features and neighborhood features.
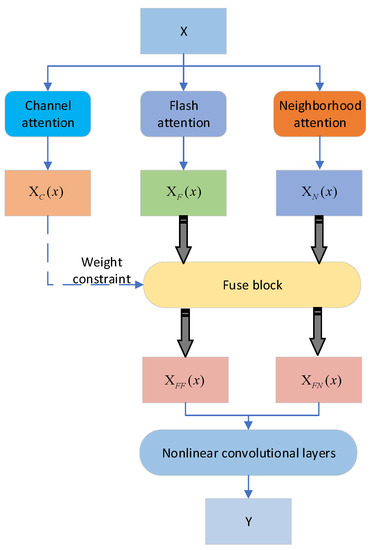
Figure 4.
Schematic diagram of the fuse block.
In Figure 4, X is the input for the module. Firstly, the channel attention module, flash attention module, and neighborhood attention module are, respectively, used to implement the channel attention feature map , flash attention feature map , and neighborhood attention feature map . The flash coupling feature map and the neighborhood coupling feature map are obtained by adjusting the input of the coupling module. The enhanced flash attention feature map and neighborhood attention feature map are summed, and the sum of these feature maps is mapped nonlinearly through a nonlinear convolutional layer to improve the feature-fitting ability and achieve the fusion of the flash features and neighborhood features. The equation is shown as:
The computational flow of the fuse block is shown in Figure 5.
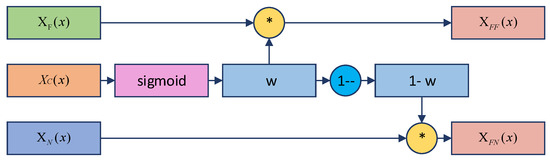
Figure 5.
Fuse block coupling calculation process.
The channel attention feature map is normalized to obtain the channel relevance weight w. Since the channel correlation weight w represents the effective expression ability of the different feature maps’ features, the sum is, respectively, obtained by coupling w with the neighborhood attention feature map and flash attention feature map to achieve the enhanced expression of the effective features in the neighborhood features and flash features.
2.4. Improved MANNER Network
The MA module of the baseline MANNER is improved, as shown in Figure 6a. The original MA module is replaced with the improved MA module to form the AF-MANNER, which is shown in Figure 6b.
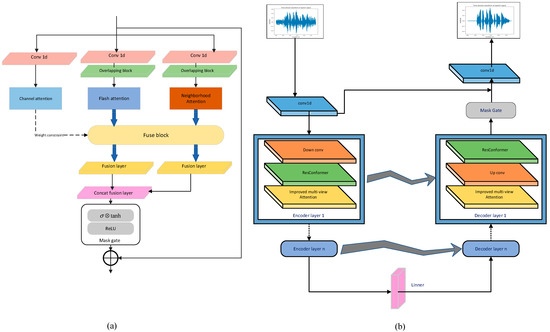
Figure 6.
(a) Structure of the improved MA module; and (b) structure of the AF-MANNER.
3. Experimental Setup
3.1. Experimental Data Set
The experiments were conducted using the VoiceBank-DEMAND dataset [24,25]. The data used were noisy speech and clean speech pairs. The clean speech dataset was provided by the publicly available VoiceBank speech library at the University of Edinburgh. The noisy speech dataset was derived from the diverse environment multichannel noise database DEMAND. Noisy speech is a superposition of clean speech and noisy data with different signal-to-noise ratios in the form of additive noise, which is used for the training and validation of speech enhancement models. This speech database is permanently available at: http://dx.doi.org/10.7488/ds/1356 (accessed on 1 May 2021).
The training dataset that was used in this paper contained 11,572 noisy speech segments, which were formed by overlaying the clean speech of 14 male and 14 female voice volunteers selected from the VoiceBank corpus, with 8 randomly selected noises from DEMAND, and randomly mixed with 4 signal-to-noise ratios of 0 dB, 5 dB, 10 dB, and 15 dB. The test dataset that was used in this paper contained 824 noisy speech segments, which consisted of the blindly selected clean speech of one male and one female from the VoiceBank corpus, which was overlaid with five noises selected from DEMAND and randomly mixed at four higher signal-to-noise ratios (SNRs) of 2.5 dB, 7.5 dB, 12.5 dB, and 17.5 dB. The sampling frequency of all the sounds was set to 16,000 Hz for a fair comparison.
In general, the larger the SNR, the smaller the noise mixed in the signal and the higher the sound quality, otherwise the opposite was true. The larger the SNR of the noisy speech, after mixing it with clean speech, the more difficult it was for the network to remove the noise or recover the original speech signal. The dataset with higher SNRs than the training dataset was selected for testing. This would better validate the network’s strengths and weaknesses in its voice enhancement performance under more demanding conditions.
3.2. Evaluation Indicators
The basic principle of an objective speech quality assessment is to combine the physical characteristics parameters of the speech signal with a mathematical model. Additionally, evaluation scores are generated based on the computer calculation of the quantitative distances or correlations between the clean and enhanced speech. Once the network is automated, objective evaluation methods enable the effective maintenance of standards during its design, commissioning, and operation. They significantly improve the evaluation efficiency and reduce the difficulty, so that the speech enhancement algorithms can be evaluated effectively. The ablation studies used a perceptual evaluation of the speech quality (PESQ) [26] and short-time objective intelligibility (STOI) [27,28] to objectively evaluate the enhancement effect.
PESQ is an equivalent standard algorithm for speech quality assessment. The smaller the difference between the measured enhanced speech and the clean speech, the smaller the disturbance density and the higher the PESQ score. After a series of computational processes, such as preprocessing, temporal alignment, perceptual filtering, and masking effects, the PESQ score can be obtained. For formal subjective tests, the scores range from 1 to 4.5, but may fall below 1 in cases of severe degradation. The PESQ score takes values in the interval [−0.5, 4.5]. STOI is a scalar value that has a monotonic positive correlation with the average intelligibility of the speech in the time–frequency domain, and it is defined as the degree of correlation between the short-time envelope of the clean speech and the enhanced speech. The clean speech and the enhanced speech complete the signal segmentation normalization and filtering of the useless frames in the time–frequency domain to complete the signal reconstruction, and then the discrete Fourier transform (DFT) decomposes it into one-third octave bands and analyzes the short-time envelope segments. After compensating the level difference of the enhanced speech, the short-time envelope correlation coefficients of the two signals are calculated to obtain the STOI scores. The STOI score takes values in the interval [1, 100].
3.3. Experimental Platform
The hardware and software configurations of the experimental host are shown in Table 1.

Table 1.
Experimental host software and hardware configuration.
4. Results
The experiments in this section were conducted separately for the improved network and original network in terms of the voice enhancement performance, to verify the effectiveness of the AF-MANNER.
4.1. Parameter Settings
The experiments in this section used Pytorch for the training, setting the batch size to 2 and the epoch setting to 50 times. The convolution kernel size was set to seven and the fill size was set to three. The baseline MANNER, flash MANNER, flash fuse MANNER, and AF-MANNER were trained and validated separately with the same training set.
4.2. Experimental Results
As shown in Figure 7b,c, the enhanced results of MANNER on the waveform plot suffered from a severe speech loss relative to the clean speech. The noise removal removed some of the useful speech segments together, which did not effectively recover the speech signal and caused serious distortion problems. The recovery of the speech amplitude was poor and did not recover the approximate amplitude and contour of the speech.
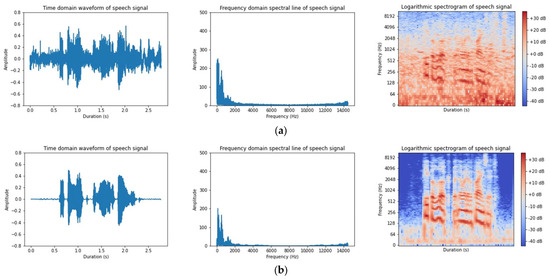
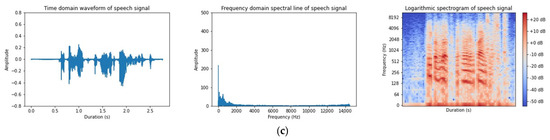
Figure 7.
Comparison of speech enhancement samples: (a) noise; (b) clean; and (c) MANNER.
As shown in Figure 8a, there was basically no corruption or loss of the useful speech segments in the enhanced results of the flash MANNER. The voice signal was well protected, while most of the noise was eliminated. It was basically the same as the clean speech spectrum between a 0 Hz–2000 Hz frequency, and the noise cancellation effects in the other frequency bands were also obvious. Although some of the low-frequency noise was not completely eliminated, the useful speech segments were largely retained.
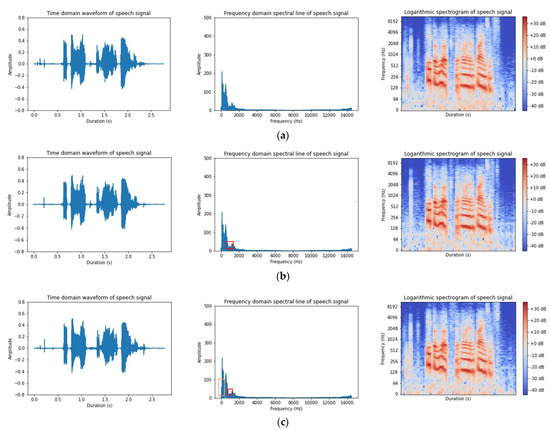
Figure 8.
Comparison of speech enhancement samples: (a) flash MANNER; (b) flash fuse MANNER; and (c) AF-MANNER.
As shown in Figure 8b, the flash fuse MANNER effectively removed the noise in the time domain waveform plot. The cluttered background noise was reduced a lot, without affecting the original speech and separating it nicely. The enhanced speech spectrogram was almost indistinguishable from the clean speech. The useful speech signals were restored and the background noise was separated and eliminated. The enhanced speech spectrogram eliminated more low-amplitude background noise and high-frequency-band noise compared to the flash MANNER, and the speech enhancement performance was greatly improved.
As shown in Figure 8c, it can be found that the enhanced speech of AF-MANNER was very close to the clean speech in the time domain waveform plot. Only a very small portion of the non-speech fragments with a low amplitude were not eliminated and the noise cancellation effect was obvious. From the spectrogram, it can be seen that the enhanced speech of AF-MANNER had some useful speech segments in the low frequency band of 0 Hz–128 Hz, which were not fully recovered. This is shown in the orange box in Figure 8c. There was a noise fragment of about 10 dB in the 128 Hz–4096 Hz frequency band that was not completely eliminated. However, the overall enhanced speech of AF-MANNER basically preserved the speech spectrum information of the speech signal. Some speech spectrum details were also not lost, and there was almost no speech distortion. By comparing the red boxes in Figure 8, it can be seen that the enhanced speech performance of the improved network improved compared to the flash fuse MANNER noise cancellation capability.
As shown in Table 2, the STOI and PESQ metrics for the enhanced speech are calculated separately. The improved speech STOI score for the flash MANNER is 93.44, which is 1.85% better than that of the MANNER, and its PESQ score of 2.5697 is 5.31% better than the MANNER’s. Both the perceptual quality and short-term intelligibility significantly increased in the enhanced speech that was produced by the flash attention improved network. The STOI score for the flash fuse MANNER is 93.25, which is 1.51 points higher than the MANNER’s score, implying a 1.64% improvement. The PESQ score for the flash fuse MANNER is 2.5739, showing a 5.49% improvement and implying a 0.134 increase from the baseline. The STOI score for the AF-MANNER is 93.65, which is 1.91 points higher than the baseline and implies a 2.08% improvement. The PESQ score for the AF-MANNER is 2.5942, which is 0.1543 points higher than the baseline and implies a 6.32% improvement.
Table 2.
Comparison of objective scores of enhanced speech quality.
5. Conclusions
The AF-MANNER structure is proposed, which efficiently uses the complementary feature extraction advantages of a U-net structure and the attention mechanism in MANNER. This is to address the problems of MANNER, such as its computational difficulty and poor speech enhancement for long sequence speech enhancement. The structure considers the need to improve the model’s global and local features’ expression ability. This is achieved by replacing the global attention with flash attention to meet the model’s lightweighting requirements. Local attention is also replaced with neighborhood attention to improve the problem of the model tending to lose its local feature information. A fuse block is designed for the information coupling and establishing a feature information interaction between the flash attention and neighborhood attention. The AF-MANNER network has a strong ability for noise cancellation, but tends to cause the problem of over-focusing on this noise cancellation ability and ignoring the protection of the speech signal, which reduces the intelligibility of the speech. In speech enhancement, the objective function is not usually correlated with the evaluation metric. Therefore, even if the objective function is continuously optimized, the quality of the enhanced speech is still not greatly improved. Additionally, some evaluation metrics cannot be used as loss functions because they are not differentiable. The future directions of this work will focus on investigating the model’s noise elimination capability. Additionally, a feature mapping module will be designed to alleviate the mismatch of the speech evaluation metrics.
Author Contributions
Conceptualization, X.Z.; writing—original draft preparation, S.W.; supervision, J.L.; project administration, L.S. and H.L.; funding acquisition, L.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China, grant number 52277016.
Institutional Review Board Statement
The study did not require ethical approval and did not involve human or animal research.
Informed Consent Statement
This study did not involve human studies.
Data Availability Statement
The data of the simulation is unavailable because of the privacy issue of the data.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Jeong, J.; Mondol, S.; Kim, Y.; Lee, S. An Effective Learning Method for Automatic Speech Recognition in Korean CI Patients’ Speech. Electronics 2021, 10, 807. [Google Scholar] [CrossRef]
- Faghani, M.; Rezaee-Dehsorkh, H.; Ravanshad, N.; Aminzadeh, H. Ultra-Low-Power Voice Activity Detection System Using Level-Crossing Sampling. Electronics 2023, 12, 795. [Google Scholar] [CrossRef]
- Price, M.; Glass, G.; Chandrakasan, A.P. A Low-Power Speech Recognizer and Voice Activity Detector Using Deep Neural Networks. IEEE J. Solid-State Circuits 2018, 53, 66–75. [Google Scholar] [CrossRef]
- Oh, S.; Cho, M.; Shi, Z.; Lim, J.; Kim, Y.; Jeong, S.; Chen, Y.; Rother, R.; Blaauw, D.; Kim, H.; et al. An Acoustic Signal Processing Chip with 142-nW Voice Activity Detection Using Mixer-Based Sequential Frequency Scanning and Neural Network Classification. IEEE J. Solid-State Circuits 2019, 54, 3005–3016. [Google Scholar] [CrossRef]
- Park, S.-M.; Kim, Y.-G. A Metaverse: Taxonomy, Components, Applications, and Open Challenges. IEEE Access 2022, 10, 4209–4251. [Google Scholar]
- Hu, Y.; Hou, N.; Chen, C.; Chng, E.S. Interactive Feature Fusion for End-to-End Noise-Robust Speech Recognition. In Proceedings of the ICASSP 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022. [Google Scholar]
- Shi, Y.; Bai, J.; Xue, P.; Shi, D. Fusion Feature Extraction Based on Auditory and Energy for Noise-Robust Speech Recognition. IEEE Access 2019, 7, 81911–81922. [Google Scholar] [CrossRef]
- Li, C. Robotic Emotion Recognition Using Two-Level Features Fusion in Audio Signals of Speech. EEE Sens. J. 2022, 22, 17447–17454. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Pandey, A.; Wang, D. Dual-path Self-Attention RNN for Real-Time Speech Enhancement. arXiv 2020, arXiv:2010.12713. [Google Scholar]
- Ozan, O.; Jo, S.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.; Kainz, B.; et al. Attention U-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Giri, R.; Isik, U.; Krishnaswamy, A. Attention Wave-U-Net for Speech Enhancement. In Proceedings of the 2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 20–23 October 2019. [Google Scholar]
- Hwang, J.-W.; Park, R.-H.; Park, H.-M. Efficient Audio-Visual Speech Enhancement Using Deep U-Net with Early Fusion of Audio and Video Information and RNN Attention Blocks. IEEE Access 2021, 9, 137584–137598. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Wang, K.; He, B.; Zhu, W.-P. TSTNN:Two-stage Transformer based Neural Network for Speech Enhancement in the Time Domain. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Park, H.J.; Kang, B.H.; Shin, W.; Kim, J.S.; Han, S.W. MANNER: Multi-View Attention Network for Noise Erasure. arXiv 2022, arXiv:2203.02181. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2016, arXiv:1409.0473. [Google Scholar]
- Luong, M.-T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Atkinson, R.C.; Herrnstein, R.J. Perception and Motivation; Learning and Cognition. In Stevens’ Handbook of Experimental Psychology, 3rd ed.; Lindzey, G., Luce, R.D., Eds.; John Wiley & Sons: Oxford, UK, 1988; Volume 1, p. 739. [Google Scholar]
- Gulati, A.; Qin, J. Conformer: Convolution-augmented Transformer for Speech Recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Dao, T.; Fu, D.Y.; Ermon, S.; Rudra, A.; Ré, C. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. arXiv 2022, arXiv:2205.14135. [Google Scholar]
- Hassani, A.; Walton, S.; Li, J.; Li, S.; Shi, H. Neighborhood Attention Transformer. arXiv 2022, arXiv:2204.07143. [Google Scholar]
- Veaux, C.; Yamagishi, J.; King, S. The voice bank corpus: Design, collection and data analysis of a large regional accent speech database. In Proceedings of the 2013 International Conference Oriental COCOSDA Held Jointly with 2013 Conference on Asian Spoken Language Research and Evaluation (O-COCOSDA/CASLRE), Gurgaon, India, 25–27 November 2013. [Google Scholar]
- Thiemann, J.; Ito, N.; Vincent, E. The diverse environments multi-channel acoustic noise database: A database of multichannel environmental noise recordings. J. Acoust. Soc. Am. 2013, 5, 3591. [Google Scholar] [CrossRef]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (pesq): An objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing, (Cat. No.01CH37221), Salt Lake City, UT, USA, 7–11 May 2001. [Google Scholar]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. An Algorithm for Intelligibility Prediction of Time–Frequency Weighted Noisy Speech. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2125–2136. [Google Scholar] [CrossRef]
- Hu, Y.; Loizou, P.C. Evaluation of Objective Quality Measures for Speech Enhancement. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 229–238. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).