


Machine Translation Systems Based on Classical-Statistical-Deep-Learning Approaches

 , , ,
, , ,  and
and
Abstract
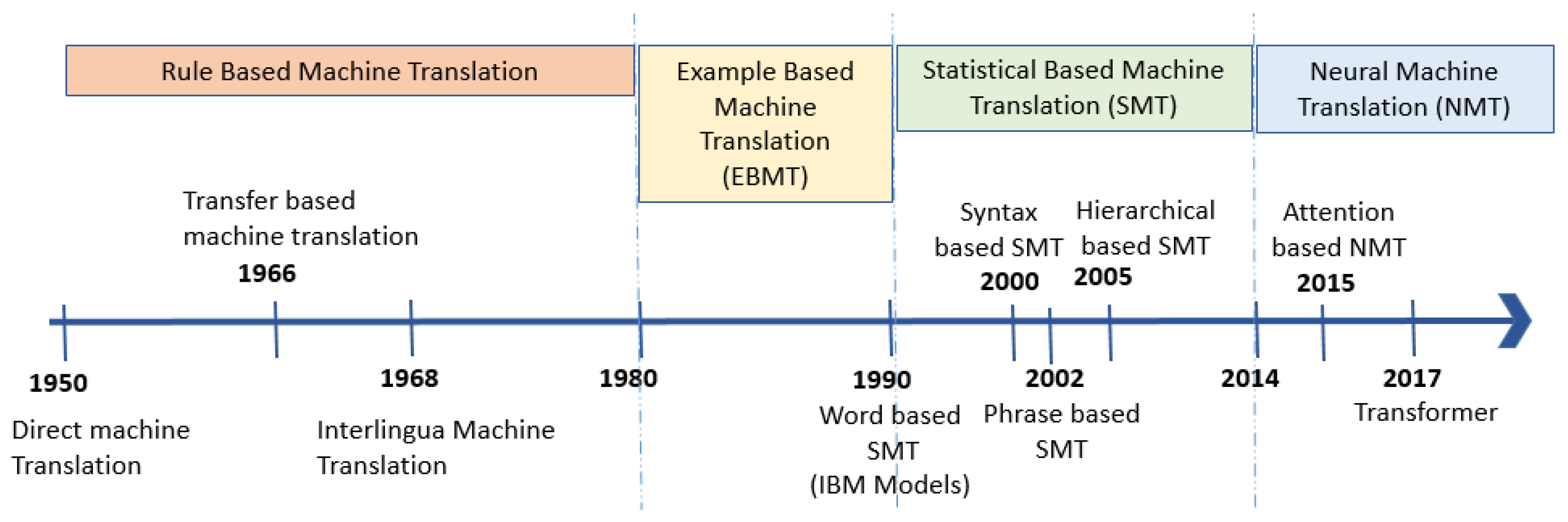
1. Introduction
- (i)
- A critical review of existing literature.
- (ii)
- A Comparative analysis of deep learning enabled methods.
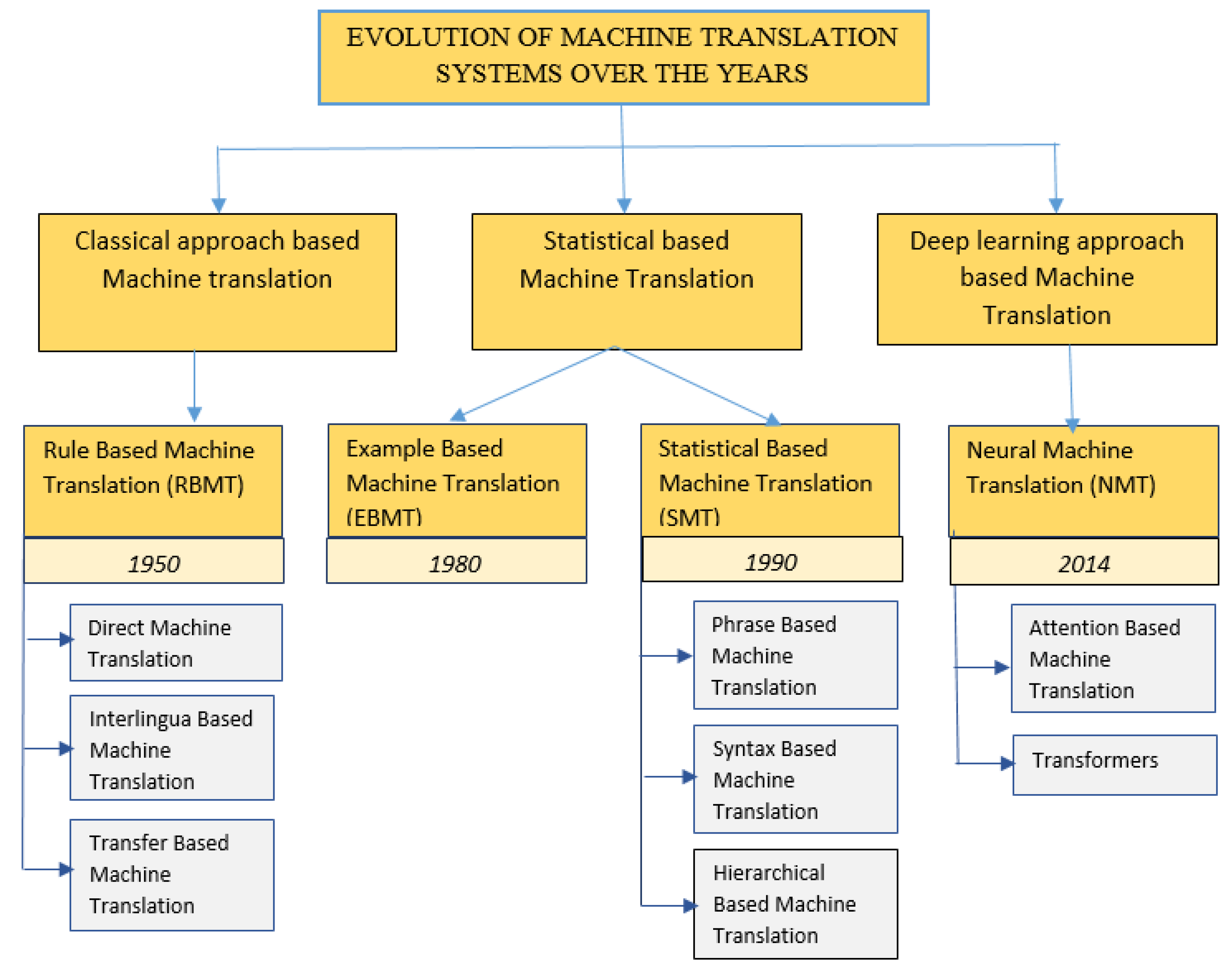
2. Classical Approach-Based Machine Translation
2.1. Rule-Based Machine Translation
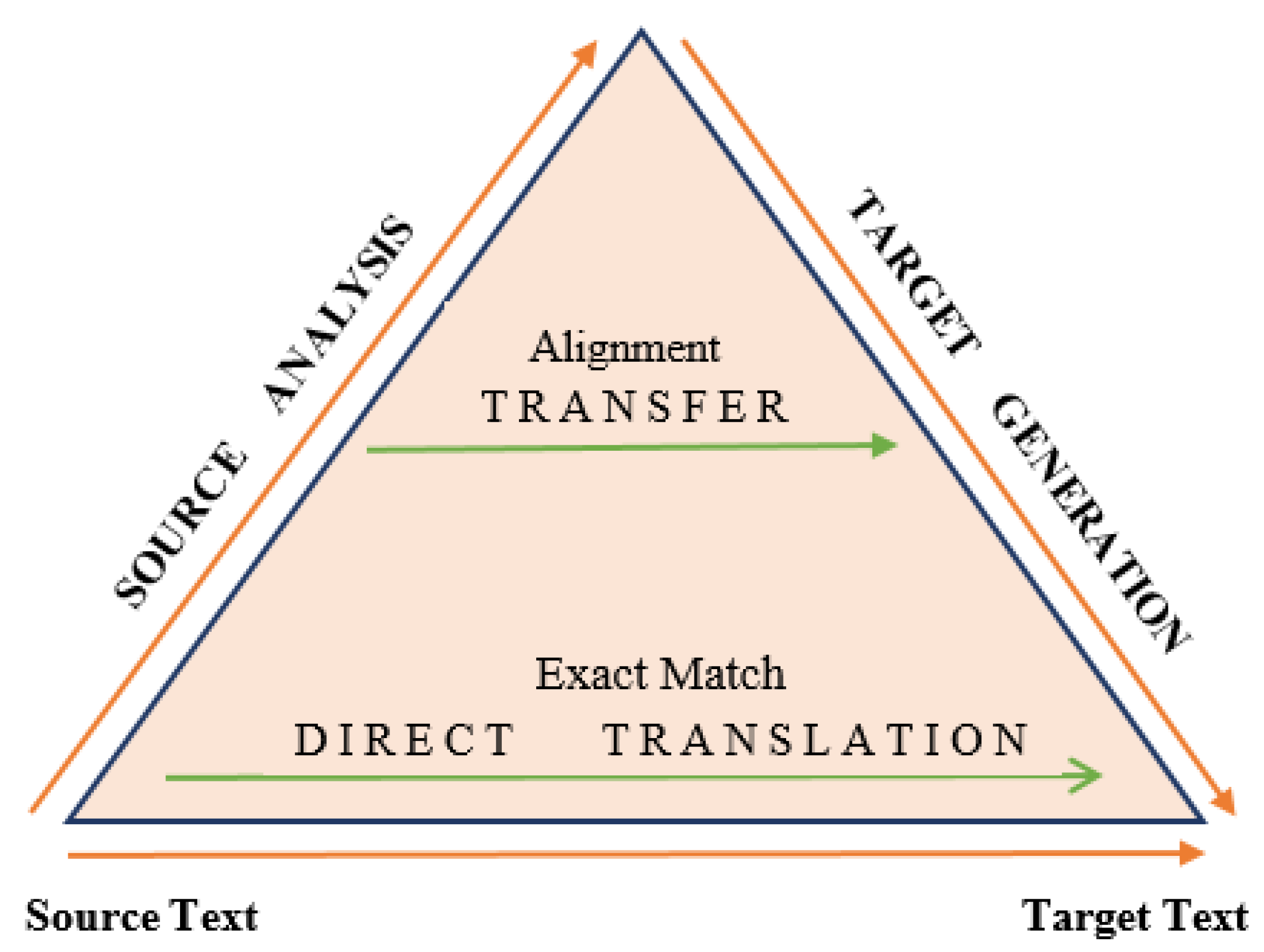
2.1.1. Direct Machine Translation
- Issues
- This approach works at the lexical level and does not account for the structural relationship between words. At the lexical level, frequent mistranslation and inappropriate syntax can be observed.
- The linguistic and computational naivety of this approach is also an issue determined in the late 1950s by an unsophisticated approach to linguistics in the MT project. The translation system developed is specific to a language pair and cannot be adapted to different language pairs.
2.1.2. Interlingua-Based Machine Translation
- Issues
- The important issue lies in defining interlingua representation which keeps the meaning of the original sentence intact.
2.1.3. Transfer-Based Machine Translation
- Issues
- Compilation of dictionaries makes one walk through the minefield of copyright issues (F. Bond et al., 2005).
- Insufficiency of the existence of good dictionaries. Building a new dictionary consumes much time and human effort.
- Inefficiency in adapting to a new domain and keeping up with changing technology. Difficulty in dealing with rule interactions in big systems, ambiguity, and idiomatic expressions. Sometimes the meaning of the source sentence is lost.
3. Statistical Approach-Based Machine Translation System
3.1. Example-Based Machine Translation (EBMT)
- Issues
- EBMT is suitable for sub-languages; once the right corpus is located, the problem comes with alignment: identification of finer granularity for sentences that correspond to each other. EBMT does not compose structure as it follows that source language structure does not impose on target language structure.
- Another issue is the storage of examples as a complex structure that derives huge computational expense.
3.2. Statistical Machine Translation
- Language Model
- Translation Model
- Issues
- Difficulty in applicability with agglutinative languages.
- The construction of a corpus is expensive due to limited resources. Do not work with languages having different word orders.
3.2.1. Phrase-Based SMT Systems
3.2.2. Syntax-Based SMT System
3.2.3. Hierarchical Based SMT Systems
4. Deep Learning Approach-Based Machine Translation System
4.1. Neural Machine Translation (NMT)
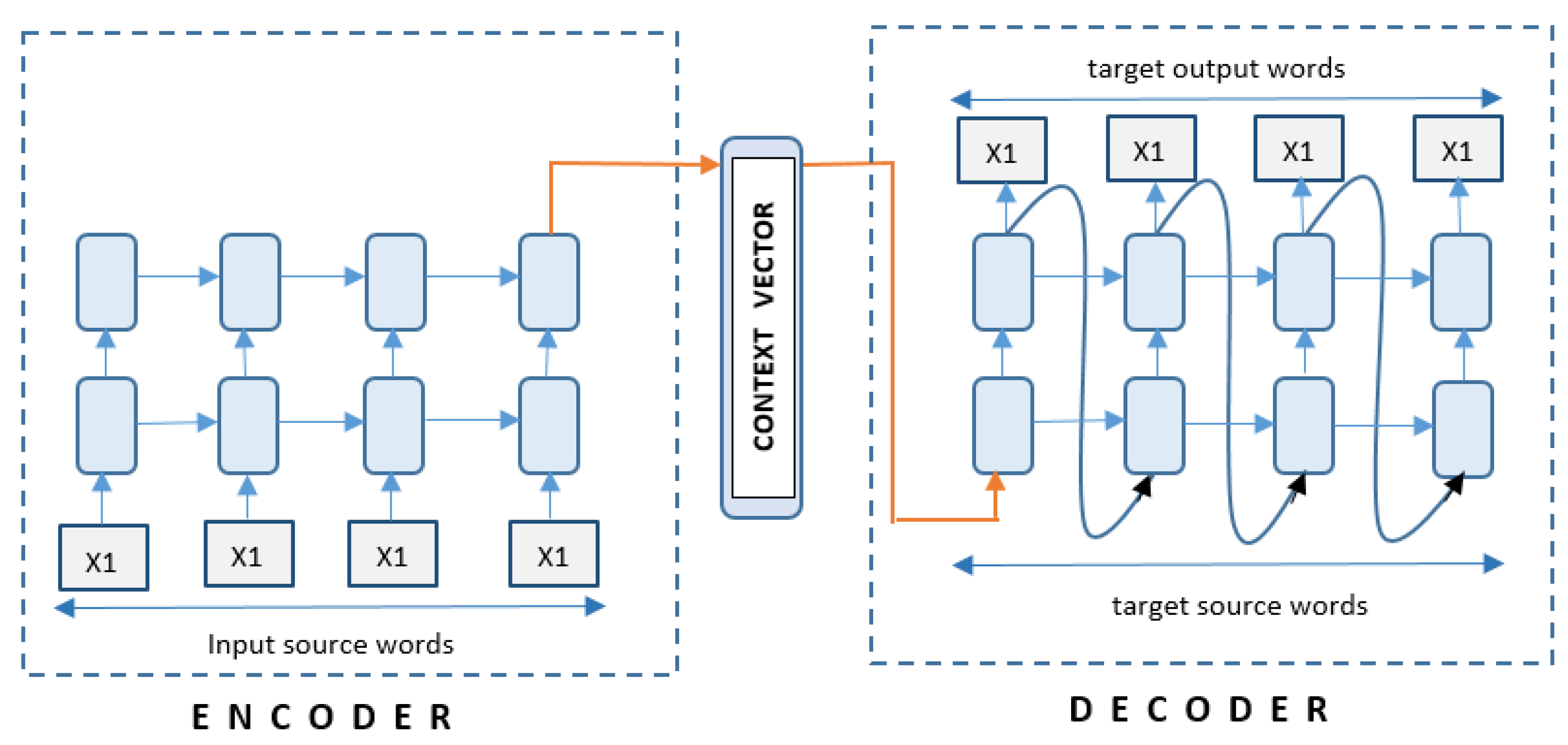
4.2. RNN Encoder-Decoder Framework
- Encoder RNN
- Decoder RNN
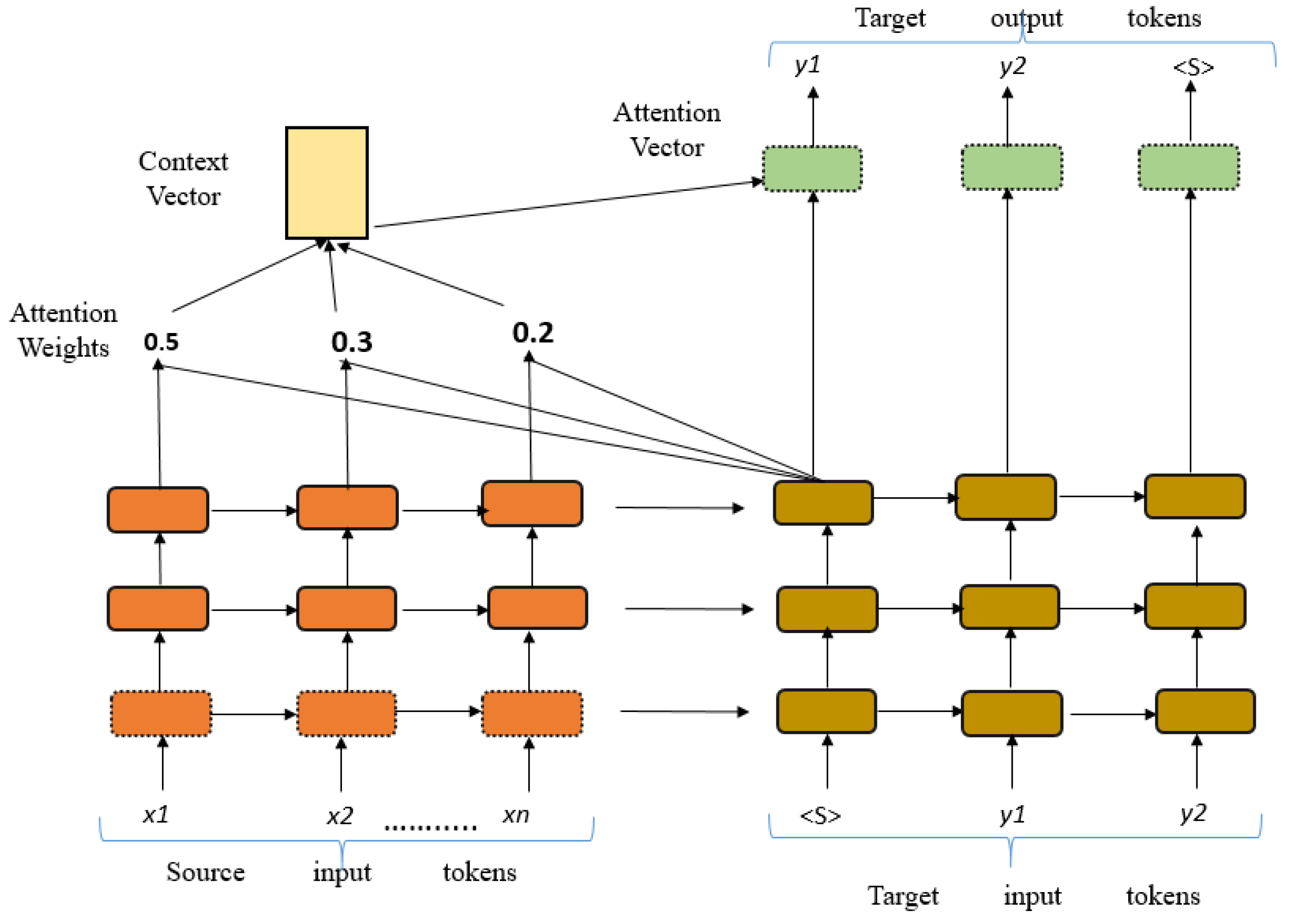
4.3. Integrated Attention Layer-Based NMT
- Global Attention
- Local Attention

| Year | Aim | Dataset | Results |
|---|---|---|---|
| 2014 [75] | Aims to show that sentences with longer lengths leads to performance degradation by using 2 models: RNN Encoder–Decoder &gated recursive convolutional neural network | English-to-French translation having bilingual, parallel corpus | BLEU scores for RNNenc = 27.81 and Moses = 33.08 |
| 2015 [80] | To present minimum risk training (MRT) for optimizing model parameters with respect to arbitrary evaluation metric for end-to-end NMT (gated RNN) | To be evaluated on 3 translation task: Chinese–English, English–French, and English–German. | MRT performed best for English–French translation (Bleu = 34.23); English–German translation (Bleu = 20.45) |
| 2015 [81] | To investigate the embeddings learned by NMT model | word corpus of English–German & English–German sentence pairs extracted from WMT’14 | RNNenc and RNNsearch outperformed alternative embedding learning architecture RNNenc & RNNsearch = 0.93 TOFEL |
| 2016 [82] | Propose new interactive attention mechanism to keep track of interaction history and leverage performance | NIST Chinese–English translation task | Out of 3 chosen systems RNNsearch, NN-Cover-80 NMT-IA-80. NMT-IA-80 performed best with average score= 36.44 |
| 2015 [83] | A stronger neural network joint model (NNJM) which summarizes useful information through convolution architecture which can augment n-gram target language model | LDC data where sentence length is upto 40 words; vocabulary limited to 20K words for English and Chinese | The proposed model achieved significant growth in performance over previous model NNJM by +1.08 Bleu score |
| 2017 [84] | A simplified architecture based on succession of convolutional layers which simultaneously encodes source information compared to RNN | WMT’16 English-Romanian; WMT’15 English–German; WMT’14 English–French. | Results show that Single layer CNN + positional embeddings (30.4 Bleu score) outperform unidirectional LSTM encoder (27.4 Bleu score) & BILSTM |
| 2018 [85] | To simplify NMT addition subtraction twin-gated recurrent network (ATR) which has simplified recurrent units has been proposed which is more transparent than LSTM/GRU | WMT’14 English–German and English–French translation tasks. | Proposed model compared with previous models ATR yield = 21.99 Bleu; after integrating context-aware encoder (ATR +CA) = 22.7 Bleu outperforming (Buck et al., 2014) by 2 Bleu; 2.41/3.26 Bleu gain against exisiting LSTM |
| 2020 [86] | To propose novel gated recurrent unit (GRU)- gated attention model (GAtt) for NMT which enables translation -sensitive source representations that contributes to discriminative context vectors | Case-insensitive (Chinese– English) and WMT’17 case sensitive (English– German) | GAtt achieved 24.38 BLEU score and GAtt-Inv achieved 26.63 BLEU score outperforming RNNsearch |
- Issues
- Domain adaptation: A well-recognized challenge in translation; words in different domains have different translations and meanings. The development of NMT targets specific use cases; hence, methods for domain adaptation should be developed.
- Data sufficiency: NMT emerged as a promising approach, but some experiments reported poor results under low-resourced conditions. It is a challenge to provide machine translation solutions for an arbitrary language where there are no or little parallel corpora available.
- Vocabulary coverage: This issue can severely affect the translation quality because the NMT can choose to have candidate words in its vocabulary (frequent words) while the remaining are considered out-of-vocabulary (OOV). This challenge exists due to the proper nouns and non-usage of many verbs. So in practical implementation, the unknown or rare words are replaced by the “UNK” token, which ultimately hurts the semantic aspect of the text.
- Sentence length: NMT is not able to handle very long sentences, and upon translation, the meaning is lost.
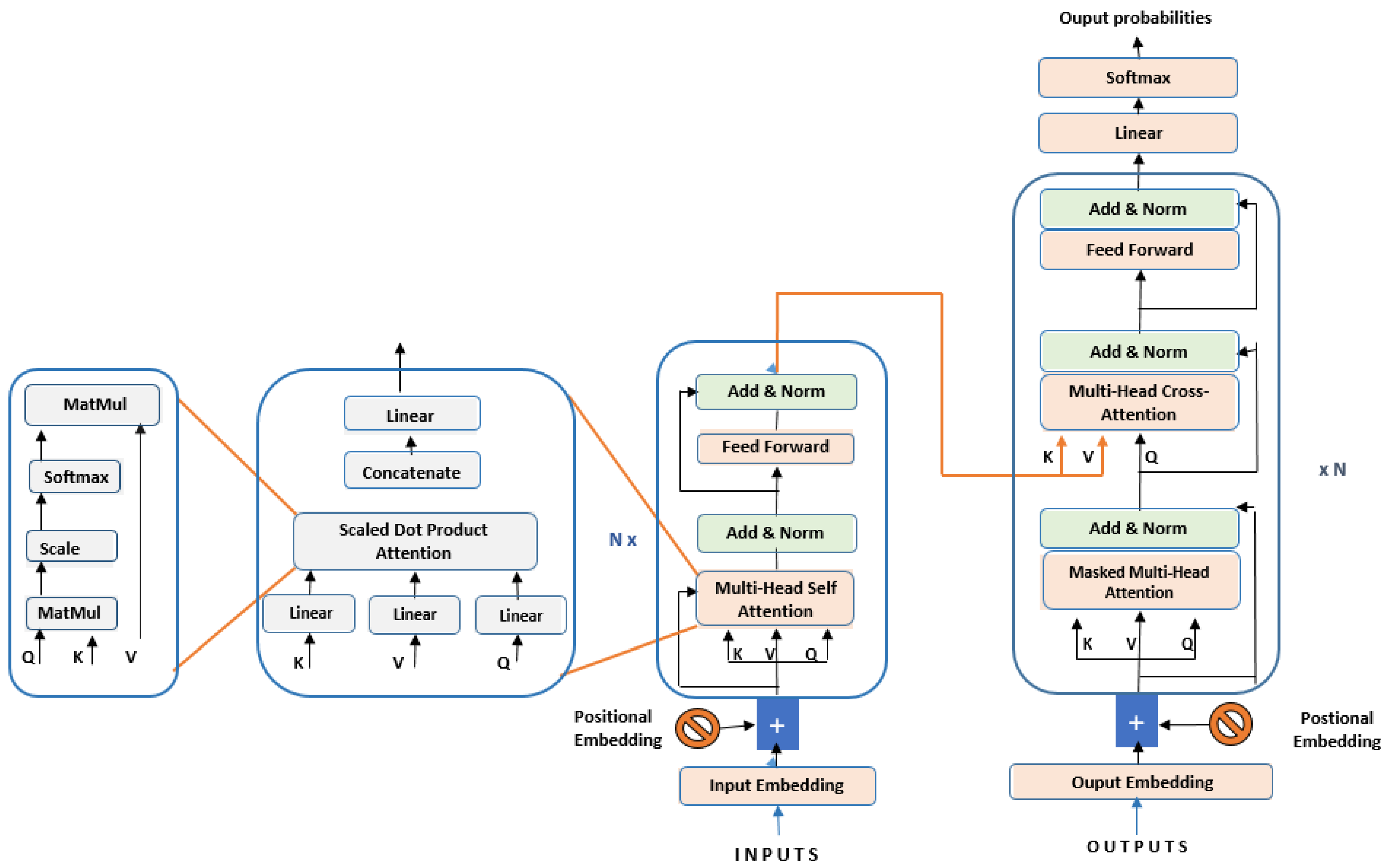
4.4. Transformers
| Author | Methodolgy | BLEU Score |
|---|---|---|
| Cho et al., 2015 [75] | Gated CNN RNNenc Moses | 22.94 27.03 35.40 |
| Shen et al., 2016 [80] | Gated RNN with Search-MRT Gated RNN with Search-MRT + PostUnk | 31.30 34.23 |
| Gehrig et al., 2017 [84] | BiLSTM 2 layered BiLSTM Deep Convolutional (8/4) | 34.3 35.3 34.6 |
| Zhang et al., 2018 [85] | RNNSearch + ATR(twin gated RNN) + BPE RNNSearch + ATR (twin gated RNN) + CA + BPE RNNSearch + ATR (twin gated RNN) + CA+ BPE+ Ensemble | 36.89 37.88 39.06 |
| Liu et al., 2020 [100] | 6L Encoder and 6L Decoder (Default Transformer) 60L Encoder and 12L Decoder (Admin) | 41.5 43.8 |
| Liu et al., 2021 [101] | Confidence aware scheduled sampling target denoising | 42.97 |
- (1)
- Input Form
- (2)
- Encoder–decoder blocks
- (3)
- Multi-head attention
5. Conclusions
6. Survey, Application and Future Works on Machine Translation
- Knowledge Distillation
- Quantization
- Pruning
- Efficient Attention
- Application of MT
- B2B industry-specific machine translation applications are adopted by different-sized business enterprises which rely on domain-related specific training data. For instance, the generic translators rely on generic data as their models are trained on it. Some businesses offer customizable solutions across various domains and some across specific domains. This industry includes military, financial, education, healthcare, legal, etc. A few examples of B2B machine translation systems are Kantan MT, SYSTRAN, Lingua Custodia (finance), SDL government, etc.
- B2C customer-based machine translation applications are generic applications that are meant for individuals (students, travelers), etc. These applications offer to perform text-to-text, speech-to-text, and image-to-text-based translation. The biggest players in B2C are Google translate where all capabilities are available under a single platform, and Facebook translate, and they are available in the form of a cloud service-independent application [132]. The wearable voice translator—‘The ili‘—is a small device that travelers can carry and offers to translate speech instantly. E-commerce platforms integrated machine translation services into their websites by providing easy access to global customers. Furthermore, due to COVID-19, virtual meetings became common so to enhance the virtual experience for learners, simultaneous translation (ST) became integrated into the video conferences to provide real-time translation in respective native languages.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hutchins, J.; Lovtskii, E. Petr Petrovich Troyanskii (1894–1950): A forgotten pioneer of mechanical translation. Mach. Transl. 2000, 15, 187–221. [Google Scholar] [CrossRef]
- Weaver, W. Translation. Mach. Transl. Lang. 1955, 14, 10. [Google Scholar]
- Lehrberger, J.; Bourbeau, L. Machine Translation: Linguistic Characteristics of MT Systems and General Methodology of Evaluation; John Benjamins Publishing: Amsterdam, The Netherlands, 1988; Volume 15. [Google Scholar]
- Scott, B.; Barreiro, A. OpenLogos MT and the SAL Representation Language. 2009. Available online: https://aclanthology.org/2009.freeopmt-1.5 (accessed on 12 October 2022).
- Ramírez Sánchez, G.; Sánchez-Martínez, F.; Ortiz Rojas, S.; Pérez-Ortiz, J.A.; Forcada, M.L. Opentrad Apertium Open-Source Machine Translation System: An Opportunity for Business and Research; Aslib: Bingley, UK, 2006. [Google Scholar]
- Ranta, A. Grammatical Framework: Programming with Multilingual Grammars; CSLI Publications, Center for the Study of Language and Information: Stanford, CA, USA, 2011; Volume 173. [Google Scholar]
- Nagao, M. A framework of a mechanical translation between Japanese and English by analogy principle. Artif. Hum. Intell. 1984, 1, 351–354. [Google Scholar]
- Sato, S.; Nagao, M. Toward memory-based translation. In Proceedings of the COLNG 1990 Volume 3: Papers Presented to the 13th International Conference on Computational Linguistics, Gothenburg, Sweden, 18–19 May 1990. [Google Scholar]
- Satoshi, S. Example-based translation of technical terms. In Proceedings of the Fiftth International Conference on Theoritcal and Methodological Issues in Machine Translation, Kyoto, Japan, 14–16 July 1993; pp. 58–68. [Google Scholar]
- Brown, P.F.; Cocke, J.; Della Pietra, S.A.; Della Pietra, V.J.; Jelinek, F.; Lafferty, J.; Mercer, R.L.; Roossin, P.S. A statistical approach to machine translation. Comput. Linguist. 1990, 16, 79–85. [Google Scholar]
- Brown, P.F.; Della Pietra, S.A.; Della Pietra, V.J.; Mercer, R.L. The mathematics of statistical machine translation: Parameter estimation. Comput. Linguist. 1993, 19, 263–311. [Google Scholar]
- Och, F.J.; Ney, H. Discriminative training and maximum entropy models for statistical machine translation. In Proceedings of the 40th Annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 10–11 July 2002; pp. 295–302. [Google Scholar]
- Manning, C.; Schutze, H. Foundations of Statistical Natural Language Processing; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Wong, Y.W.; Mooney, R. Learning for semantic parsing with statistical machine translation. In Proceedings of the Human Language Technology Conference of the NAACL, Main Conference, New York, NY, USA, 10–11 June 2006; pp. 439–446. [Google Scholar]
- Jean, S.; Cho, K.; Memisevic, R.; Bengio, Y. On using very large target vocabulary for neural machine translation. arXiv 2014, arXiv:1412.2007. [Google Scholar]
- Nirenburg, S. Knowledge-based machine translation. Mach. Transl. 1989, 4, 5–24. [Google Scholar] [CrossRef]
- Cohen, W.W. Fast effective rule induction. In Machine Learning Proceedings 1995; Elsevier: Amsterdam, The Netherlands, 1995; pp. 115–123. [Google Scholar]
- Abercrombie, G. A Rule-based Shallow-transfer Machine Translation System for Scots and English. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portoroz, Slovenia, 23–28 May 2016; pp. 578–584. [Google Scholar]
- Vauquois, B. A survey of formal grammars and algorithms for recognition and transformation in mechanical translation. In Proceedings of the Ifip Congress (2), Edinburgh, UK, 5–10 August 1968; Volume 68, pp. 1114–1122. [Google Scholar]
- Wheeler, P.J. Changes and improvements to the european commission s systran MT system 1976/84. Terminologie 1984, 1, 25–37. [Google Scholar]
- Vasconcellos, M.; León, M. SPANAM and ENGSPAN: Machine translation at the Pan American Health Organization. Comput. Linguist. 1985, 11, 122–136. [Google Scholar]
- Bharati, A.; Chaitanya, V.; Kulkarni, A.P.; Sangal, R. Anusaaraka: Machine translation in stages. Vivek-Bombay 1997, 10, 22–25. [Google Scholar]
- Vauquois, B. La Traduction Automatique à Grenoble. Number 24, Dunod. 1975. Available online: https://aclanthology.org/J85-1003.pdf (accessed on 11 December 2022).
- Gale, W.A.; Church, K.W.; Yarowsky, D. Using bilingual materials to develop word sense disambiguation methods. In Proceedings of the International Conference on Theoretical and Methodological Issues in Machine Translation, Montreal, QC, Canada, 25–27 June 1992; pp. 101–112. [Google Scholar]
- Sinha, R.; Sivaraman, K.; Agrawal, A.; Jain, R.; Srivastava, R.; Jain, A. ANGLABHARTI: A multilingual machine aided translation project on translation from English to Indian languages. In Proceedings of the 1995 IEEE International Conference on Systems, Man and Cybernetics. Intelligent Systems for the 21st Century, Vancouver, BC, Canada, 22–25 October 1995; Volume 2, pp. 1609–1614. [Google Scholar]
- Yusuf, H.R. An analysis of indonesian language for interlingual machine-translation system. In Proceedings of the COLING 1992 Volume 4: The 14th International Conference on Computational Linguistics, Nantes, France, 23–28 August 1992. [Google Scholar]
- Lonsdale, D.; Mitamura, T.; Nyberg, E. Acquisition of large lexicons for practical knowledge-based MT. Mach. Transl. 1994, 9, 251–283. [Google Scholar] [CrossRef]
- Dorr, B.J.; Marti, A.; Castellon, I. Spanish EuroWordNet and LCS-Based Interlingual MT. In Proceedings of the MT Summit Workshop on Interlinguas in MT, San Diego, CA, USA, 28 October 1997. [Google Scholar]
- Varile, G.B.; Lau, P. Eurotra practical experience with a multilingual machine translation system under development. In Proceedings of the Second Conference on Applied Natural Language Processing, Austin, TX, USA, 21–22 August 1988; pp. 160–167. [Google Scholar]
- Bennett, W.S. The LRC machine translation system: An overview of the linguistic component of METAL. In Proceedings of the 9th Conference on Computational linguistics-Volume 2, Prague, Czech Republic, 5–10 July 1982; pp. 29–31. [Google Scholar]
- Bharati, R.M.; Reddy, P.; Sankar, B.; Sharma, D.; Sangal, R. Machine translation: The shakti approach. Pre-conference tutorial. ICON 2003, 1, 1–7. [Google Scholar]
- Varga, I.; Yokoyama, S. Transfer rule generation for a Japanese-Hungarian machine translation system. In Proceedings of the Machine Translation Summit XII, Ottawa, ON, Canada, 26–30 August 2009. [Google Scholar]
- Sumita, E.; Hitoshi, H. Experiments and prospects of example-based machine translation. In Proceedings of the 29th Annual Meeting of the Association for Computational Linguistics, Berkeley, CA, USA, 18–21 June 1991; pp. 185–192. [Google Scholar]
- Somers, H. Example-based machine translation. Mach. Transl. 1999, 14, 113–157. [Google Scholar] [CrossRef]
- Mima, H.; Iida, H.; Furuse, O. Simultaneous interpretation utilizing example-based incremental transfer. In Proceedings of the 36th Annual Meeting of the Association for Computational Linguistics and 17th International Conference on Computational Linguistics, Volume 2, Montreal, QC, Canada, 10–14 August 1998; pp. 855–861. [Google Scholar]
- Nirenburg, S.; Domashnev, C.; Grannes, D.J. Two approaches to matching in example-based machine translation. In Proceedings of the 5th International Conference on Theoretical and Methodological Issues in Machine Translation (TMI-93), Kyoto, Japan, 14–16 July 1993. [Google Scholar]
- Furuse, O.; Iida, H. Constituent boundary parsing for example-based machine translation. In Proceedings of the COLING 1994 Volume 1: The 15th International Conference on Computational Linguistics, Kyoto, Japan, 16–18 August 1994. [Google Scholar]
- Cranias, L.; Papageorgiou, H.; Piperidis, S. A matching technique in example-based machine translation. arXiv 1995, arXiv:cmp-lg/9508005. [Google Scholar]
- Grefenstette, G. The World Wide Web as a resource for example-based machine translation tasks. In Proceedings of the ASLIB Conference on Translating and the Computer, London, UK, 16–17 November 1999; Volume 21, pp. 517–520. [Google Scholar]
- Brown, R.D. Example-based machine translation in the pangloss system. In Proceedings of the COLING 1996 Volume 1: The 16th International Conference on Computational Linguistics, Copenhagen, Denmark, 5–9 August 1996. [Google Scholar]
- Sumita, E. Example-based machine translation using DP-matching between work sequences. In Proceedings of the ACL 2001 Workshop on Data-Driven Methods in Machine Translation, Toulouse, France, 7 July 2001. [Google Scholar]
- Brockett, C.; Aikawa, T.; Aue, A.; Menezes, A.; Quirk, C.; Suzuki, H. English-Japanese example-based machine translation using abstract linguistic representations. In Proceedings of the COLING-02: Machine Translation in Asia, Stroudsburg, PA, USA, 1 September 2002. [Google Scholar]
- Watanabe, T.; Sumita, E. Example-based decoding for statistical machine translation. In Proceedings of the Machine Translation Summit IX, New Orleans, LA, USA, 18–22 September 2003; pp. 410–417. [Google Scholar]
- Imamura, K.; Okuma, H.; Watanabe, T.; Sumita, E. Example-based machine translation based on syntactic transfer with statistical models. In Proceedings of the COLING 2004: 20th International Conference on Computational Linguistics, Geneva, Switzerland, 23–27 August 2004; pp. 99–105. [Google Scholar]
- Aramaki, E.; Kurohashi, S.; Kashioka, H.; Kato, N. Probabilistic model for example-based machine translation. In Proceedings of the MT Summit X, Phuket, Thailand, 13–15 September 2005; pp. 219–226. [Google Scholar]
- Armstrong, S.; Way, A.; Caffrey, C.; Flanagan, M.; Kenny, D. Improving the Quality of Automated DVD Subtitles via Example-Based Machine Translation. 2006. Available online: https://aclanthology.org/2006.tc-1.9.pdf (accessed on 10 December 2022).
- Brown, P.F.; Cocke, J.; Della Pietra, S.A.; Della Pietra, V.J.; Jelinek, F.; Mercer, R.L.; Roossin, P. A statistical approach to language translation. In Proceedings of the Coling Budapest 1988 Volume 1: International Conference on Computational Linguistics, Budapest, Hungary, 22–27 August 1988. [Google Scholar]
- Och, F.J.; Tillmann, C.; Ney, H. Improved alignment models for statistical machine translation. In Proceedings of the 1999 Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora, Hong Kong, China, 7–8 October 1999. [Google Scholar]
- Marcu, D.; Wong, D. A phrase-based, joint probability model for statistical machine translation. In Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing (EMNLP 2002), Philadelphia, PA, USA, 6–7 July 2002; pp. 133–139. [Google Scholar]
- Koehn, P.; Och, F.J.; Marcu, D. Statistical phrase-based translation. Technical report, University of Southern California Marina del Rey Information Sciences Inst. 2003. Available online: https://aclanthology.org/N03-1017.pdf (accessed on 10 December 2022).
- Zens, R.; Och, F.J.; Ney, H. Phrase-based statistical machine translation. In KI 2002: Advances in Artificial Intelligence, Proceedings of the 25th Annual German Conference on AI, Aachen, Germany, 16–20 September 2002; Springer: Berlin/Heidelberg, Germany, 31 July 2002; pp. 18–32. [Google Scholar]
- Zens, R.; Ney, H. Improvements in phrase-based statistical machine translation. In Proceedings of the Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics: HLT-NAACL 2004, Boston, MA, USA, 2–7 May 2004; pp. 257–264. [Google Scholar]
- Chiang, D. A hierarchical phrase-based model for statistical machine translation. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05), Ann Arbor, MI, USA, 10 June 2005; pp. 263–270. [Google Scholar]
- Xiong, D.; Liu, Q.; Lin, S. Maximum entropy based phrase reordering model for statistical machine translation. In Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, Sydney, Australia, 10 July 2006; pp. 521–528. [Google Scholar]
- Marcu, D.; Wang, W.; Echihabi, A.; Knight, K. SPMT: Statistical machine translation with syntactified target language phrases. In Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing, Sydney, Australia, 15 July 2006; pp. 44–52. [Google Scholar]
- Wu, H.; Wang, H. Pivot language approach for phrase-based statistical machine translation. Mach. Transl. 2007, 21, 165–181. [Google Scholar] [CrossRef]
- Cherry, C. Cohesive phrase-based decoding for statistical machine translation. In Proceedings of the ACL-08: HLT, Columbus, OH, USA, 5 June 2008; pp. 72–80. [Google Scholar]
- Yamada, K.; Knight, K. A syntax-based statistical translation model. In Proceedings of the 39th Annual Meeting of the Association for Computational Linguistics, Toulouse, France, 10 July 2001; pp. 523–530. [Google Scholar]
- Yamada, K.; Knight, K. A decoder for syntax-based statistical MT. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 2 July 2002; pp. 303–310. [Google Scholar]
- Charniak, E.; Knight, K.; Yamada, K. Syntax-based language models for statistical machine translation. In Proceedings of the MT Summit IX, New Orleans, LA, USA, 23–27 September 2003; pp. 40–46. [Google Scholar]
- Ding, Y.; Palmer, M. Synchronous dependency insertion grammars: A grammar formalism for syntax based statistical MT. In Proceedings of the Workshop on Recent Advances in Dependency Grammar, Geneva, Switzerland, 28 August 2004; pp. 90–97. [Google Scholar]
- Ding, Y.; Palmer, M. Machine translation using probabilistic synchronous dependency insertion grammars. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05), Ann Arbor, MI, USA, 10 June 2005; pp. 541–548. [Google Scholar]
- Zollmann, A.; Venugopal, A. Syntax augmented machine translation via chart parsing. In Proceedings of the Workshop on Statistical Machine Translation, New York, NY, USA, 10 June 2006; pp. 138–141. [Google Scholar]
- Wang, W.; Knight, K.; Marcu, D. Binarizing syntax trees to improve syntax-based machine translation accuracy. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 10 June 2007; pp. 746–754. [Google Scholar]
- Liu, Q.; He, Z.; Liu, Y.; Lin, S. Maximum entropy based rule selection model for syntax-based statistical machine translation. In Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, Honolulu, HI, USA, 10 October 2008; pp. 89–97. [Google Scholar]
- Imamura, K. Hierarchical Phrase Alignment Harmonized with Parsing. In Proceedings of the NLPRS, Tokyo, Japan, 27–30 November 2001; pp. 377–384. [Google Scholar]
- Watanabe, T.; Imamura, K.; Sumita, E. Statistical machine translation based on hierarchical phrase alignment. In Proceedings of the 9th Conference on Theoretical and Methodological Issues in Machine Translation of Natural Languages: Papers, Keihanna, Japan, 13–17 March 2002; pp. 188–198. [Google Scholar]
- Liu, Y.; Liu, Q.; Lin, S. Tree-to-string alignment template for statistical machine translation. In Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, Sydney, Australia, 10 July 1997; pp. 609–616. [Google Scholar]
- Mistry, J.; Verma, A.; Bhattacharyya, P. Literature Survey: Study of Neural Machine Translation. Resource Centre for Indian Language Technology Solutions (CFILT). 2017. Available online: https://www.cfilt.iitb.ac.in/resources/surveys/ajay-jigar-nmt-survey-jun17.pdf (accessed on 12 December 2022).
- Liu, Y.; Zhang, J. Deep learning in machine translation. In Deep Learning in Natural Language Processing; Springer: Berlin/Heidelberg, Germany, 2018; pp. 147–183. [Google Scholar]
- Forcada, M.L.; Ñeco, R.P. Recursive hetero-associative memories for translation. In Proceedings of the International Work-Conference on Artificial Neural Networks, Lanzarote, Canary Islands, Spain, 17–19 September 1997; Springer: Berlin/Heidelberg, Germany, 1997; pp. 453–462. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Janvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Kalchbrenner, N.; Blunsom, P. Recurrent continuous translation models. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 10 October 2013; pp. 1700–1709. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. arXiv 2014, arXiv:1409.3215. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.r.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Wen, H.; Ling-yu, M. Study on recognition character in express list by mobile phone camera based on OpenCV. J. Harbin Univ. Commer. (Natural Sci. Ed.) 2015, 1, 5. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Shen, S.; Cheng, Y.; He, Z.; He, W.; Wu, H.; Sun, M.; Liu, Y. Minimum risk training for neural machine translation. arXiv 2015, arXiv:1512.02433. [Google Scholar]
- Hill, F.; Cho, K.; Jean, S.; Devin, C.; Bengio, Y. Embedding word similarity with neural machine translation. arXiv 2014, arXiv:1412.6448. [Google Scholar]
- Meng, F.; Lu, Z.; Li, H.; Liu, Q. Interactive attention for neural machine translation. arXiv 2016, arXiv:1610.05011. [Google Scholar]
- Meng, F.; Lu, Z.; Wang, M.; Li, H.; Jiang, W.; Liu, Q. Encoding source language with convolutional neural network for machine translation. arXiv 2015, arXiv:1503.01838. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Dauphin, Y.N. A convolutional encoder model for neural machine translation. arXiv 2016, arXiv:1611.02344. [Google Scholar]
- Zhang, B.; Xiong, D.; Su, J.; Lin, Q.; Zhang, H. Simplifying neural machine translation with addition-subtraction twin-gated recurrent networks. arXiv 2018, arXiv:1810.12546. [Google Scholar]
- Zhang, B.; Xiong, D.; Xie, J.; Su, J. Neural machine translation with GRU-gated attention model. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4688–4698. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 10 December 2022).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv 2019, arXiv:1910.10683. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning texture transformer network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 July 2020; pp. 5791–5800. [Google Scholar]
- Ye, L.; Rochan, M.; Liu, Z.; Wang, Y. Cross-modal self-attention network for referring image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 July 2019; pp. 10502–10511. [Google Scholar]
- Tan, H.; Bansal, M. Lxmert: Learning cross-modality encoder representations from transformers. arXiv 2019, arXiv:1908.07490. [Google Scholar]
- Su, W.; Zhu, X.; Cao, Y.; Li, B.; Lu, L.; Wei, F.; Dai, J. Vl-bert: Pre-training of generic visual-linguistic representations. arXiv 2019, arXiv:1908.08530. [Google Scholar]
- Ke, X. English synchronous real-time translation method based on reinforcement learning. Wirel. Netw. 2022, 1, 1–13. [Google Scholar] [CrossRef]
- Matsuo, Y.; LeCun, Y.; Sahani, M.; Precup, D.; Silver, D.; Sugiyama, M.; Uchibe, E.; Morimoto, J. Deep learning, reinforcement learning, and world models. Neural Netw. 2022, 152, 267–275. [Google Scholar] [CrossRef] [PubMed]
- Sebastian, M.P.; Kumar, G.S. Malayalam Natural Language Processing: Challenges in Building a Phrase-Based Statistical Machine Translation System. A Trans. Asian-Low-Resour. Lang. Inf. Process. 2023. [Google Scholar] [CrossRef]
- Zhao, T.; Li, G.; Song, Y.; Wang, Y.; Chen, Y.; Yang, J. A multi-scenario text generation method based on meta reinforcement learning. Pattern Recognit. Lett. 2023, 165, 47–54. [Google Scholar] [CrossRef]
- Liu, X.; Duh, K.; Liu, L.; Gao, J. Very deep transformers for neural machine translation. arXiv 2020, arXiv:2008.07772. [Google Scholar]
- Liu, Y.; Meng, F.; Chen, Y.; Xu, J.; Zhou, J. Confidence-aware scheduled sampling for neural machine translation. arXiv 2021, arXiv:2107.10427. [Google Scholar]
- Cheng, Y.; Tu, Z.; Meng, F.; Zhai, J.; Liu, Y. Towards robust neural machine translation. arXiv 2018, arXiv:1805.06130. [Google Scholar]
- Chelba, C.; Chen, M.; Bapna, A.; Shazeer, N. Faster transformer decoding: N-gram masked self-attention. arXiv 2020, arXiv:2001.04589. [Google Scholar]
- Zhou, L.; Ding, L.; Duh, K.; Sasano, R.; Takeda, K. Self-Guided Curriculum Learning for Neural Machine Translation. arXiv 2021, arXiv:2105.04475. [Google Scholar]
- Siddhant, A.; Bapna, A.; Cao, Y.; Firat, O.; Chen, M.; Kudugunta, S.; Arivazhagan, N.; Wu, Y. Leveraging monolingual data with self-supervision for multilingual neural machine translation. arXiv 2020, arXiv:2005.0481. [Google Scholar]
- Zhang, B.; Williams, P.; Titov, I.; Sennrich, R. Improving massively multilingual neural machine translation and zero-shot translation. arXiv 2020, arXiv:2004.11867. [Google Scholar]
- Kumar, A.; Baruah, R.; Mundotiya, R.K.; Singh, A.K. Transformer-based Neural Machine Translation System for Hindi–Marathi: WMT20 Shared Task. In Proceedings of the Fifth Conference on Machine Translation, Online, 19–20 November 2020; pp. 393–395. [Google Scholar]
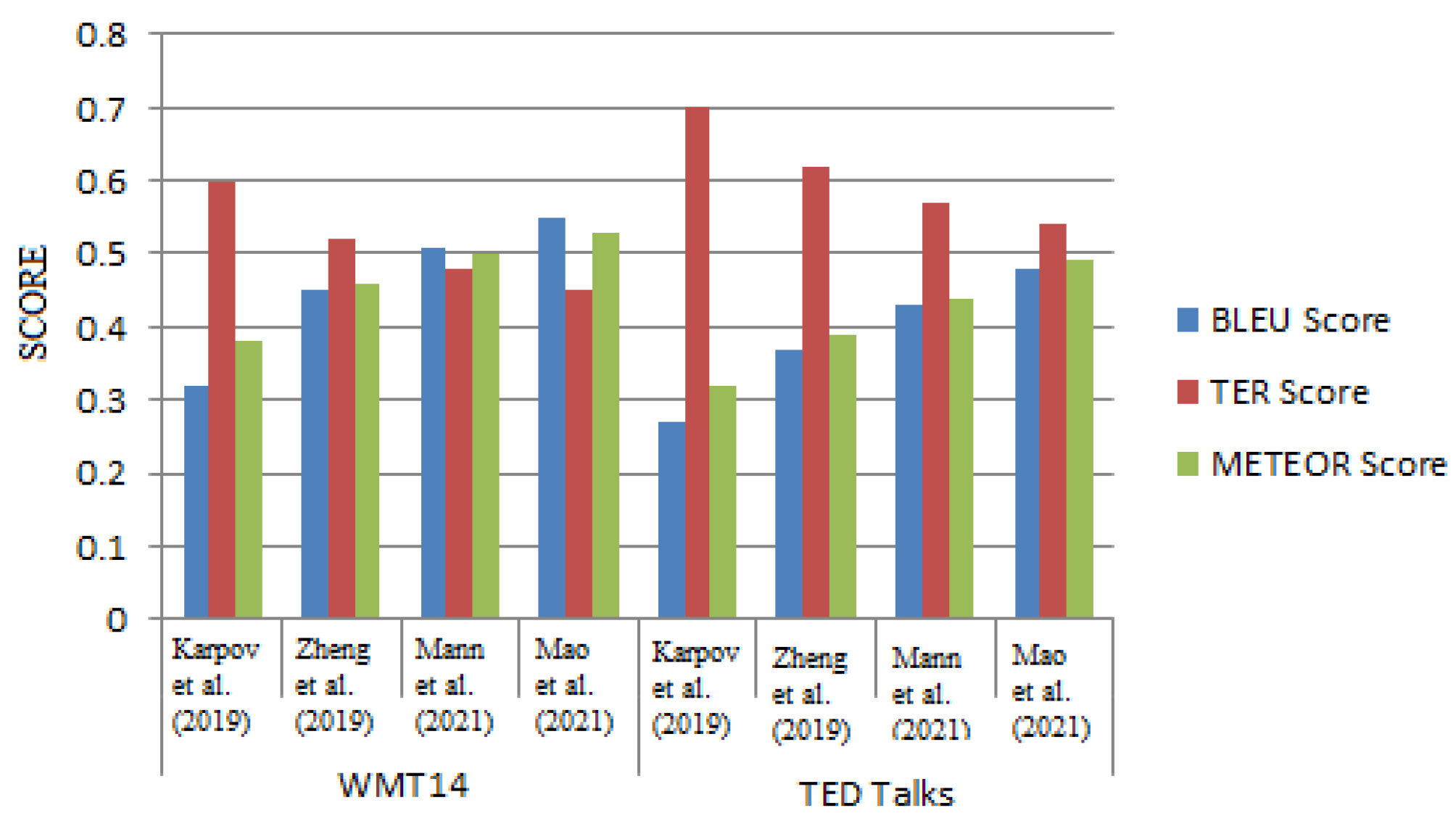
- Karpov, P.; Godin, G.; Tetko, I.V. A transformer model for retrosynthesis. In Proceedings of the International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September; Springer: Berlin/Heidelberg, Germany, 2019; pp. 817–830. [Google Scholar]
- Zheng, S.; Rao, J.; Zhang, Z.; Xu, J.; Yang, Y. Predicting retrosynthetic reactions using self-corrected transformer neural networks. J. Chem. Inf. Model. 2019, 60, 47–55. [Google Scholar] [CrossRef]
- Mann, V.; Venkatasubramanian, V. Retrosynthesis prediction using grammar-based neural machine translation: An information-theoretic approach. Comput. Chem. Eng. 2021, 155, 107533. [Google Scholar] [CrossRef]
- Mao, K.; Xiao, X.; Xu, T.; Rong, Y.; Huang, J.; Zhao, P. Molecular graph enanced transformer for retrosynthesis prediction. Neurocomputing 2021, 457, 193–202. [Google Scholar] [CrossRef]
- Wang, H.; Wu, Z.; Liu, Z.; Cai, H.; Zhu, L.; Gan, C.; Han, S. Hat: Hardware-aware transformers for efficient natural language processing. arXiv 2020, arXiv:2005.14187. [Google Scholar]
- Singh, S.; Mahmood, A. The NLP Cookbook: Modern Recipes for Transformer Based Deep Learning Architectures. IEEE Access 2021, 9, 68675–68702. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Wu, X.; Xia, Y.; Zhu, J.; Wu, L.; Xie, S.; Qin, T. A study of BERT for context-aware neural machine translation. Mach. Learn. 2022, 111, 917–935. [Google Scholar] [CrossRef]
- Turc, I.; Chang, M.W.; Lee, K.; Toutanova, K. Well-read students learn better: On the importance of pre-training compact models. arXiv 2019, arXiv:1908.08962. [Google Scholar]
- Liang, X.; Wu, L.; Li, J.; Qin, T.; Zhang, M.; Liu, T.Y. Multi-Teacher Distillation With Single Model for Neural Machine Translation. IEEE/ACM Trans. Audio, Speech, Lang. Process. 2022, 30, 992–1002. [Google Scholar] [CrossRef]
- Jooste, W.; Haque, R.; Way, A. Knowledge Distillation: A Method for Making Neural Machine Translation More Efficient. Information 2022, 13, 88. [Google Scholar] [CrossRef]
- Zafrir, O.; Boudoukh, G.; Izsak, P.; Wasserblat, M. Q8bert: Quantized 8bit bert. arXiv 2019, arXiv:1910.06188. [Google Scholar]
- Shen, S.; Dong, Z.; Ye, J.; Ma, L.; Yao, Z.; Gholami, A.; Mahoney, M.W.; Keutzer, K. Q-bert: Hessian based ultra low precision quantization of bert. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 7–12 February 2020; Volume 34, pp. 8815–8821. [Google Scholar]
- Li, Z.; Wang, Z.; Tan, M.; Nallapati, R.; Bhatia, P.; Arnold, A.; Xiang, B.; Roth, D. DQ-BART: Efficient Sequence-to-Sequence Model via Joint Distillation and Quantization. arXiv 2022, arXiv:2203.11239. [Google Scholar]
- Brix, C.; Bahar, P.; Ney, H. Successfully applying the stabilized lottery ticket hypothesis to the transformer architecture. arXiv 2020, arXiv:2005.03454. [Google Scholar]
- Behnke, M.; Heafield, K. Pruning neural machine translation for speed using group lasso. In Proceedings of the Sixth Conference on Machine Translation, Punta Cana, Dominican Republic, 10 November 2021. [Google Scholar]
- Zaheer, M.; Guruganesh, G.; Dubey, K.A.; Ainslie, J.; Alberti, C.; Ontanon, S.; Pham, P.; Ravula, A.; Wang, Q.; Yang, L.; et al. Big Bird: Transformers for Longer Sequences. In Proceedings of the NeurIPS, Virtual, Vancouver, BC, Canada, 6–14 December 2020. [Google Scholar]
- Katharopoulos, A.; Vyas, A.; Pappas, N.; Fleuret, F. Transformers are rnns: Fast autoregressive transformers with linear attention. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 13–18 July 2020; pp. 5156–5165. [Google Scholar]
- Wang, S.; Li, B.Z.; Khabsa, M.; Fang, H.; Ma, H. Linformer: Self-attention with linear complexity. arXiv 2020, arXiv:2006.04768. [Google Scholar]
- Choromanski, K.; Likhosherstov, V.; Dohan, D.; Song, X.; Gane, A.; Sarlos, T.; Hawkins, P.; Davis, J.; Mohiuddin, A.; Kaiser, L.; et al. Rethinking attention with performers. arXiv 2020, arXiv:2009.14794. [Google Scholar]
- Kitaev, N.; Kaiser, Ł.; Levskaya, A. Reformer: The efficient transformer. arXiv 2020, arXiv:2001.04451. [Google Scholar]
- Child, R.; Gray, S.; Radford, A.; Sutskever, I. Generating long sequences with sparse transformers. arXiv 2019, arXiv:1904.10509. [Google Scholar]
- Wang, H.; Wu, H.; He, Z.; Huang, L.; Church, K.W. Progress in Machine Translation. Engineering 2021, 18, 143–153. [Google Scholar] [CrossRef]
- Farooq, U.; Rahim, M.S.M.; Sabir, N.; Hussain, A.; Abid, A. Advances in machine translation for sign language: Approaches, limitations, and challenges. Neural Comput. Appl. 2021, 33, 14357–14399. [Google Scholar] [CrossRef]
- Venkatasubramanian, V.; Mann, V. Artificial intelligence in reaction prediction and chemical synthesis. Curr. Opin. Chem. Eng. 2022, 36, 100749. [Google Scholar] [CrossRef]
- Mann, V.; Venkatasubramanian, V. Predicting chemical reaction outcomes: A grammar ontology-based transformer framework. AIChE J. 2021, 67, e17190. [Google Scholar] [CrossRef]
- Schwaller, P.; Laino, T.; Gaudin, T.; Bolgar, P.; Hunter, C.A.; Bekas, C.; Lee, A.A. Molecular transformer: A model for uncertainty-calibrated chemical reaction prediction. Acs Cent. Sci. 2019, 5, 1572–1583. [Google Scholar] [CrossRef]
- Nam, J.; Kim, J. Linking the neural machine translation and the prediction of organic chemistry reactions. arXiv 2016, arXiv:1612.09529. [Google Scholar]
- Tetko, I.V.; Karpov, P.; Van Deursen, R.; Godin, G. State-of-the-art augmented NLP transformer models for direct and single-step retrosynthesis. Nat. Commun. 2020, 11, 5575. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Aim | Techniques/Datasets | Results |
|---|---|---|---|
| 1994 [37] | To propose constituent boundary parsing method for EBMT where linguistic pattern containing variable & boundaries are applied to input and possible structure is disambiguated using distance calculations | English-to-Japanese and Japanese-to-English TDMT system | Proposed method is robust and efficient with processing to me = 0.25 s |
| 1995 [38] | Aims to address an issue in EBMT of how to measure similarity between a sentence fragments and set of stored examples. | Greek–English language 8000 pair of records of derived from CELEX database | Fws (I) and retrieved example (G) 62% system is useful |
| 1999 [39] | To show example based approach to lexical choice can utilize WWW as free and adequate corpus and allow signal to overcome noise | Tested two language dictionaries: German-to- English and Spanish-to- English | Accuracy = 86%/−87%/ |
| 1999 [40] | Pangloss Example-Based Machine Translation engine (PanEBMT) with several engine translation perform parallel translations of input portions | Spanish–English data 726,406 sentence pair drawn from UN Multilingual Corpus | Achieved 70%/ of coverage of unrestricted Spanish news wire text |
| 2001 [41] | To propose an approach that extracts most similar example by utilizing DP-matching of input and example sentence while measuring semantic distance of words. | Bilingual corpus of Japanese sentences and English translations | For testing translation is graded into one of four tasks (A, B, C, D, E) Proposed approach achieves 80% of accuracy |
| 2002 [42] | To present abstract linguistic representation layer for extraction and storing bilingual translation knowledge, transfer patterns between languages, and generating output strings | MSR-MT English-Japanese system employees manually structured augmented phrase structure grammars for parsing, statistical and heuristic techniques to capture translation knowledge | Evaluation metric: +1 good MSR-MT output sentence & 1 for worst. MSR-MT scored slightly lower −0.015 and confidence measure = +/−0.16 than comparison system |
| 2003 [43] | To present a decoder based on greedy approach for SMT that takes advantage of EBMT framework | Data extracted from Basic Travel Expression Corpus (BTEC) | Proposed method outperform word by word generation beam search algorithm |
| 2004 [44] | To employ syntactic transfer approach which selects best translation by utilizing translation model and language model of SMT and improve quality over pure EBMT | Basic Travel Expression Corpus which is a collection of Japanese sentences with its English translation | The proposed methodology (All Search) scored best among all 4 methods 0.498 Bleu score |
| 2005 [45] | To propose probabilistic model which formalizes EBMT and searches translation example of highest probability along with integration of context similarity examples | IWSLT04–English-Japanese sentence pairs | Proposed model Bleu score = 0.41 which is slightly better than sate-of-the-art; Basic = 0.39 Baseline = 0.31, C1 = 0.13, C2 = 0.27 |
| 2006 [46] | Paper aims to highlight misconception that EBMT produces better results over heterogeneous data when same applied automated translation of subtitles does not hold true. | obtain aligned sets of English-to-German both homogeneous and heterogeneous data from Europarl Corpus | Improvement when trained over homogeneous data relative increase in BLEU score = 86% / |
| Year | Aim | Datasets | Results |
|---|---|---|---|
| 2002 [51] | To present SMT system based on bilingual phrases and comparing with other SMT variants. | Trained system on German and English training corpus | PBT (BLEU Score = 43.3) outperforms the SBW system (BLEU Score = 37.0) |
| 2004 [52] | Included refinements in PBT system, i.e., word penalty & phrase penalty (simple heuristics) | German–English Verbmobil task, Spanish–English Xerox task, French–English Canadian Hansards | PBT outperformed other AT & SWB IBM on Xerox and Canadian task with 67.9 BLEU Score & 27.8 BLEU Score |
| 2005 [53] | Incorporated hierarchical phrases (sub-phrases) to baseline PBT | Word aligned French–English corpus | Hierarchical PBT achieves 7.5% (BLEU metric) improvement over Pharaoh PBT |
| 2006 [54] | To propose novel reordering model for PBMT that uses maximum entropy to predict reordering of phrase pairs | Chinese-to-English translation tasks: NIST MT-05 and IWSLT-04 | Maximum Entropy (Lexical features + colocations features) 22.2 BLEU score (NIST MT -05) & 42.8 BLEU score (IWSLT-04) |
| 2006 [55] | Proposed new class of model that uses Syntactified target language Phrases (SPMT) | Chinese-to-English test corpus | SPMT outperformed baseline (PBT) by 2.64 BLEU Score. |
| 2007 [56] | To propose a novel method that incorporates pivot language for translation between limited bilingual languages. | Europarl Corpus: French to Spanish (via English); French to German (via English); French to English (via German) | Proposed method achieves absolute improvements of 0.05 and 0.04 (17.34% and 20.78% relative) on in & out of domain test sets compared to baseline for French to Spanish |
| 2008 [57] | To incorporated phrase based decoding to SMT and add a cohesion constraint based on a dependency tree for source text. | English–French Translation SMT 2006 shared task | Proposed model produced improvements ranging between 0.5 to 1.1 BLEU points on sentences. |
| Year | Aim | Datasets | Results |
|---|---|---|---|
| 2001 [58] | To propose Syntax based SMT which transforms source language parse tree to target language string. | English-Japanese corpus | Proposed model (alignment avg. score = 0.582) perform better than IBM Model 5 (alignment avg. score = 0.431) |
| 2002 [59] | To propose a decoding algorithm for syntax based SMT and decoder builds an English parse tree given a sentence in foreign language | Chinese–English translation Corpus | Bleu score = 0.085 |
| 2003 [60] | To propose translation model (YC) formed upon combination of syntax based language model (Cha01) + translation model (YK01) to leverage translation quality | pair of English parse trees and Chinese sentences | Proposed translation model: YC (0.0717 Bleu score) outperformed YT(0.1031 Bleu Score) and BT (0.0722 Bleu score) |
| 2004 [61] | To propose synchronous grammar formalism for syntax SMT to take into account pervasive structure divergence between languages which other synchronous grammar r are not capable to model. | Implemented in Chinese–English machine translation system | Proposed model score is better Bleu score = 5.0791 & NSIT Score = 0.1353 than (Yamada and Knight, 2002) between 0.099 and 0.102 |
| 2005 [62] | To implement probabilistic synchronous dependency insertion grammar on syntax based SMT to overcome nonisomorphic issue | Chinese–English | Synchronous Dependency Insertion Grammar (SDIG) system (0.132 Bleu score) than IBM Model 4 (0.109 Bleu score) |
| 2006 [63] | To introduce multiple syntactic categories and take advantage of target language parser | French-to-English Europarl data | Significant improvement over baseline (0.78 Bleu score) after employing richer extraction techniques |
| 2007 [64] | To apply series of binarization methods on syntax tree for syntax based SMT. | Chinese-to-English translation tasks. | EM- Binarization method performed the best &achieved the highest bleu score = 37.94 |
| 2008 [65] | To employ maximum entropy based rule selection (MERS) model for syntax-based SMT | Chinese-to-English FBIS training Corpus with 239k sentence pairs. MERS outperformed with 27.05 (NIST03) & 27.28 (NIST05) | Evaluated on two systems based on BLEU score Lynx and Lynx + MERS; |
| Year | Aim | Dataset | Results |
|---|---|---|---|
| 2002 [67] | To improve SMT translation by employing hierarchical phrase alignment(HPA) based on partial parse results. | 145,432 English and Japanese sentences extracted from large-scale travel conversation corpus | Results show that hierarchical phrase alignment HPA+ train can significantly boost translation performance from 61.3% to 70.0% |
| 2005 [53] | To propose phrase based SMT that uses hierarchical phrases which contain sub-phrases | Mandarin-to-English translation | Experimented against state-of the-art model PBMT Pharaoh and results suggest an increase in Bleu score PBMT = 0.2676 and proposed model = 0.2877 |
| 2007 [68] | To propose SMT based on tree-to-string (TAT) alignment template explaining the alignment between source parse tree and a target string | Chinese-to-English translation dataset of 31, 149 sentence pairs. 843, 256 Chinese words & 949, 583 English words | TAT model outperformed Pharaoh (state-of-the-art) model for PBMT |
| Year | Aim | Datasets | Results |
|---|---|---|---|
| 2018 [102] | Improving the robustness of NMT models against input perturbation with adversarial stability training | NIST Chinese–English WMT’14 English–German IWSLT English–French translation tasks | NMT system trianed by MLE on Chinese–English outperformed by +3 BLEU score; English–German improvement by +1.11 BLEU score |
| 2019 [103] | Propose N-gram mask to truncate target side window for computing self attention by making N-gram assumption | WMT’18 EnDe (newstest2012/2017) as dev/test data and WMT’14 EnFr (newstest2012 and newstest2013 as dev data and newstest2014 as test data) | Implemented N-gram self attention on Transformer Attention-layer. Setting N=8 and N=10 achieved best BLEU score within 0.3-0.4 from baseline |
| 2021 [104] | Encourage learning of NMT models, self-guided curriculum strategy is proposed. | English–German WMT’14; English–German WMt’16; Chinese–English WMT’17 | Transformer Base w/SGCL fixed: 28.62 BLEU (WMT’14) 34.07 BLEU (WMT’16) 25.34 BLEU (WMT’17) |
| 2020 [105] | Determine efficacy of monolingual data and with self supervision in Multilingual NMT | parallel and monolingual training data from WMT corpus used for 15 languages to and from English. | Multilingual NMT performed best. |
| 2020 [106] | MNMT under perform bilingual models and deliver poor zero shot translations to over this bottleneck Random online Back -translation is proposed | Perform one-to-many (English–X) and many-to-many (English–X U X-English) translation on OPUS-100 | Trained models with Transformer as base setting. Deep Transformer improved modelling capacity (+1.88 BLEU) & Transformer with proposed approach yields 29.60 BLEU & 21.23 BLEU |
| 2020 [107] | Implement transformer based NMT on both direction for Hindi-Marathi language pair | Hindi-Marathi parallel Corpus (PM India, News and Indic Word-net) | Marathi-to-Hindi = 20.72 BLEU Hindi-to-Marathi = 12.5 BLEU |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, S.; Diwakar, M.; Singh, P.; Singh, V.; Kadry, S.; Kim, J. Machine Translation Systems Based on Classical-Statistical-Deep-Learning Approaches. Electronics 2023, 12, 1716. https://doi.org/10.3390/electronics12071716
Sharma S, Diwakar M, Singh P, Singh V, Kadry S, Kim J. Machine Translation Systems Based on Classical-Statistical-Deep-Learning Approaches. Electronics. 2023; 12(7):1716. https://doi.org/10.3390/electronics12071716
Chicago/Turabian StyleSharma, Sonali, Manoj Diwakar, Prabhishek Singh, Vijendra Singh, Seifedine Kadry, and Jungeun Kim. 2023. "Machine Translation Systems Based on Classical-Statistical-Deep-Learning Approaches" Electronics 12, no. 7: 1716. https://doi.org/10.3390/electronics12071716
APA StyleSharma, S., Diwakar, M., Singh, P., Singh, V., Kadry, S., & Kim, J. (2023). Machine Translation Systems Based on Classical-Statistical-Deep-Learning Approaches. Electronics, 12(7), 1716. https://doi.org/10.3390/electronics12071716