
DFEN: Dual Feature Enhancement Network for Remote Sensing Image Caption

Abstract
1. Introduction
- This paper proposes a DFEN model accurately representing ground object information in remote sensing images. DFEN is the first model to improve ground objects from image and text levels;
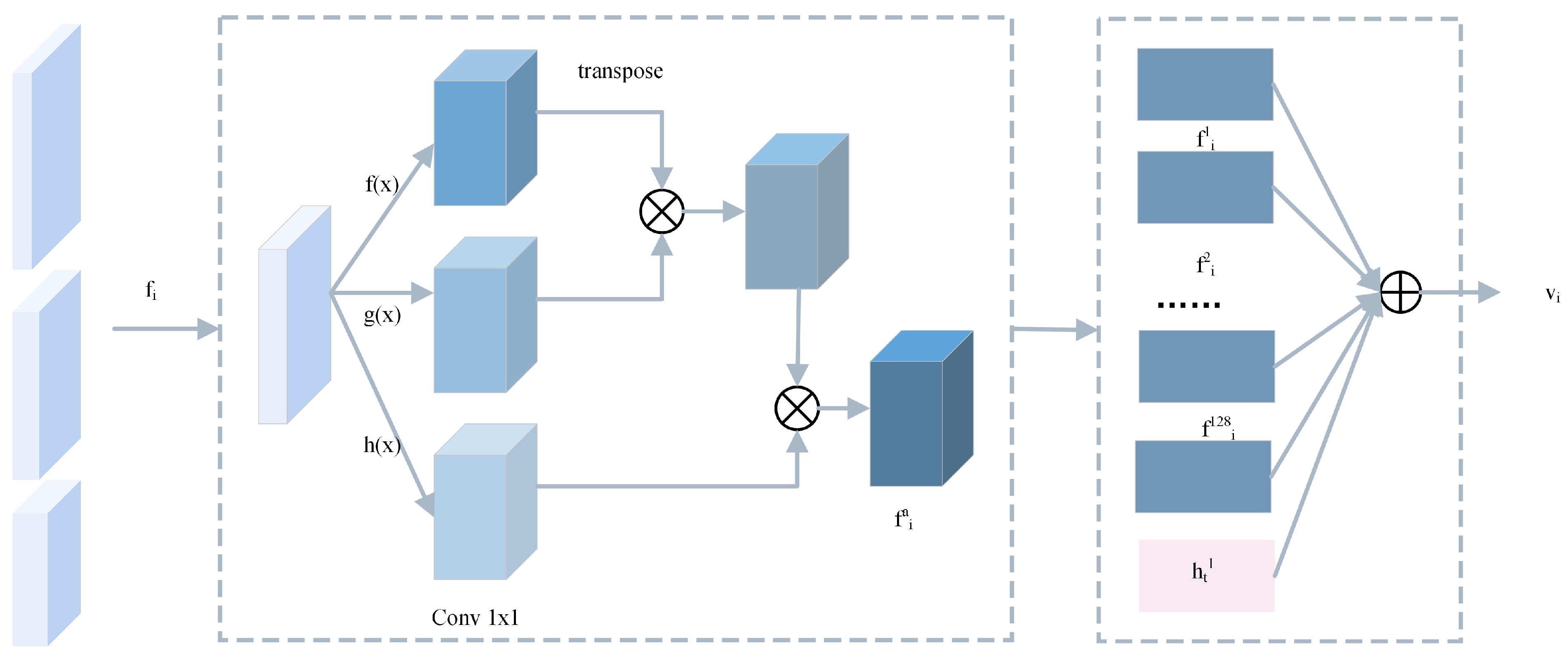
- The Image-Enhance module is used in this paper to obtain more discriminative image context features in order to enrich the visual representation of image ground objects from an image level. The Image-Enhance module facilitates the representation of visual features of the remote sensing images;
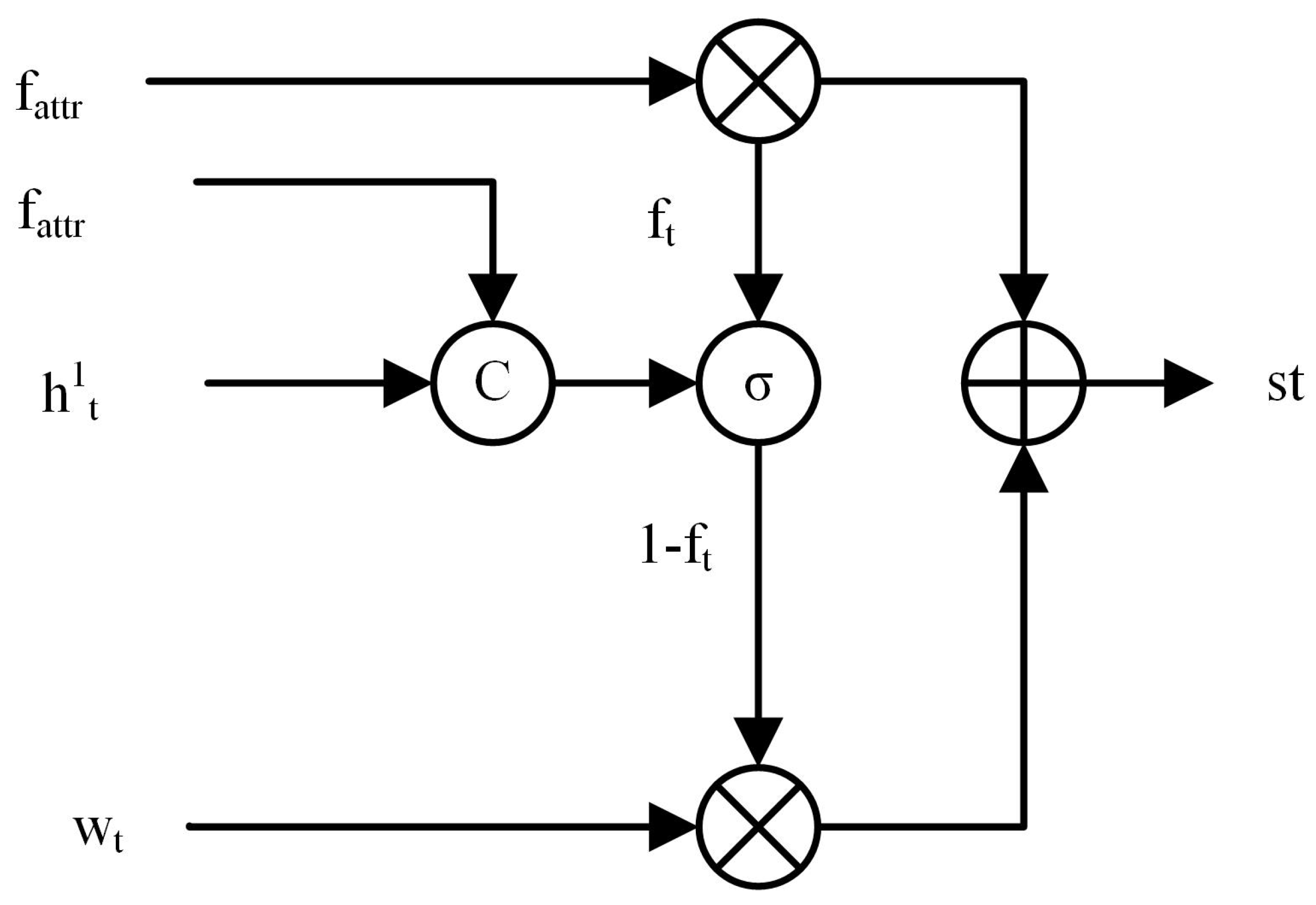
- The Text-Enhance module is used in this paper to obtain text guidance features with high graphical interaction to guide the model to focus on the correct ground object information and achieve accurate ground object information focus from a text perspective. The Text-Enhance module combines remote sensing image caption and multi-label classification tasks.
2. Related Work
3. Proposed Method
3.1. Image-Enhance Module
3.2. Text-Enhance Module
4. Experiments
4.1. Remote Sensing Image Caption Datasets and Evaluation Metrics
4.1.1. Remote Sensing Image Caption Datasets
4.1.2. Remote Sensing Image Caption Evaluation Metrics
4.2. Experimental Environment and Parameter Settings
4.3. Comparison Experiment and Result Analysis
- CSMLF [24] model proposes a collective semantic metric learning approach in which five reference captions are transformed into a collective caption.
- Sound-a [16] model uses sound as an additional input to guide the generation of remote sensing image captions. Different sounds of the same image are fed into the trained model, resulting in different captions.
- RTRMN [17] model generates captions with the help of topic word information. During training, the model extracts topic words from captions for remote sensing images.
- SD-RSIC [18] model uses a summary-driven mechanism and an enhanced word vocabulary to provide more detailed captions for semantically complex remote sensing images.
- CapFormer [25] model uses the Swin transformer model as the visual feature processing model and the decoding part of the transformer model as the text generation, avoiding the loss of information from multiple pooling operations.
4.4. Ablation Experiment and Result Analysis
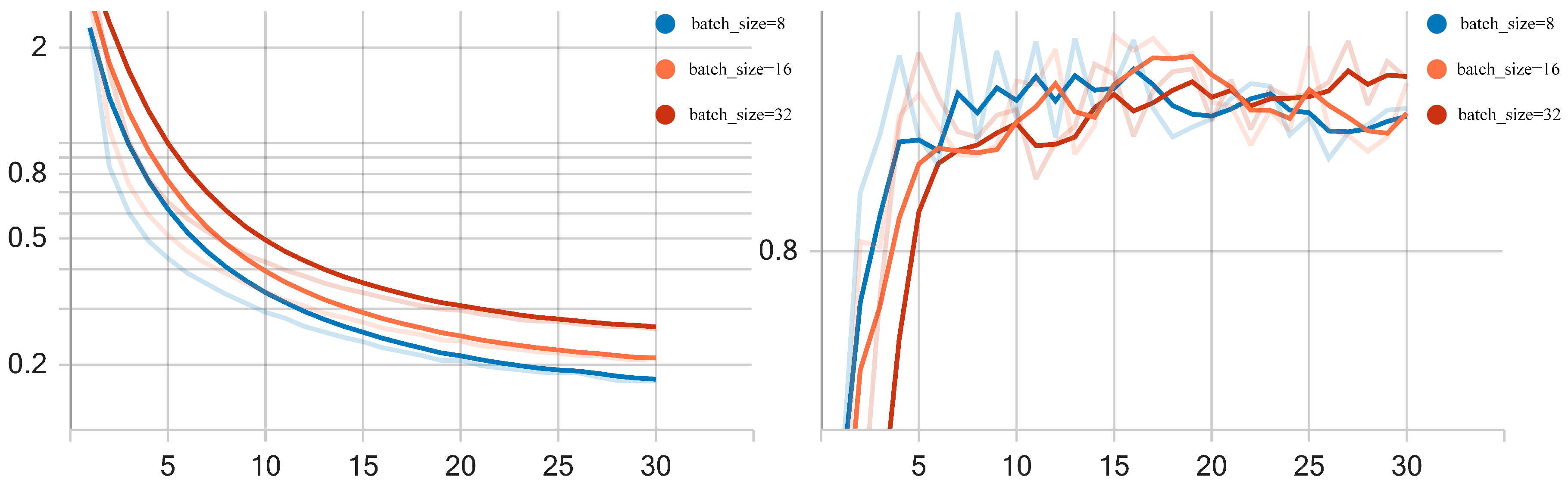
4.5. Setting and Analysis of Experimental Parameters
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, Y.; Yu, X. An overview of image caption generation methods. Comput. Intell. Neurosci. 2020, 2020, 3062706. [Google Scholar]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Zhao, B. A systematic survey of remote sensing image captioning. IEEE Access 2021, 9, 154086–154111. [Google Scholar] [CrossRef]
- Qu, B.; Li, X.; Tao, D.; Lu, X. Deep semantic understanding of high resolution remote sensing image. In Proceedings of the 2016 International Conference on Computer, Information and Telecommunication Systems (Cits), Kunming, China, 6–8 July 2016; pp. 1–5. [Google Scholar]
- Lu, X.; Wang, B.; Zheng, X.; Li, X. Exploring Models and Data for Remote Sensing Image Caption Generation. IEEE Trans. Geosci. Remote Sens. 2018, 4, 2183–2195. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, X.; Tang, X.; Zhou, H.; Li, C. Description generation for remote sensing images using attribute attention mechanism. Remote Sens. 2019, 11, 612. [Google Scholar] [CrossRef]
- Huang, W.; Wang, Q.; Li, X. Denoising-Based Multiscale Feature Fusion for Remote Sensing Image Captioning. IEEE Geosci. Remote Sens. Lett. 2021, 18, 436–440. [Google Scholar] [CrossRef]
- Anderson, P.; He, X.; Buehler, C. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Wang, C.; Jiang, Z.; Yuan, Y. Instance-Aware Remote Sensing Image Captioning with Cross-Hierarchy Attention. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 980–983. [Google Scholar]
- Yuan, Z.; Li, X.; Wang, Q. Exploring Multi-Level Attention and Semantic Relationship for Remote Sensing Image Captioning. IEEE Access 2020, 8, 2608–2620. [Google Scholar] [CrossRef]
- Qin, Y.; Du, Y.; Zhang, Y.; Lu, H. Look Back and Predict Forward in Image Captioning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8359–8367. [Google Scholar]
- Gao, L.; Fan, K.; Song, J.; Liu, X.; Xu, X.; Shen, H. Deliberate Attention Networks for Image Captioning. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8320–8327. [Google Scholar]
- Huang, L.; Wang, W.; Chen, J.; Wei, X.-Y. Attention on Attention for Image Captioning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4633–4642. [Google Scholar]
- Zhao, R.; Shi, Z.; Zou, Z. High-Resolution Remote Sensing Image Captioning Based on Structured Attention. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Sultana, F.; Sufian, A.; Dutta, P. Evolution of image segmentation using deep convolutional neural network: A survey. Knowl.-Based Syst. 2020, 201–202, 106062. [Google Scholar] [CrossRef]
- Lu, X.; Wang, B.; Zheng, X. Sound Active Attention Framework for Remote Sensing Image Captioning. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1985–2000. [Google Scholar] [CrossRef]
- Wang, B.; Zheng, X.; Qu, B.; Lu, X. Retrieval Topic Recurrent Memory Network for Remote Sensing Image Captioning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 256–270. [Google Scholar] [CrossRef]
- Sumbul, G.; Nayak, S.; Demir, B. SD-RSIC: Summarization-Driven Deep Remote Sensing Image Captioning. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6922–6934. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 5–9 June 2005; pp. 65–72. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of summaries. In Proceedings of the Workshop on Text Summarization Branches Out, Post-Conference Workshop of ACL 2004, Barcelona, Spain, 4–10 July 2004; pp. 74–81. [Google Scholar]
- Vedantam, R.; Zitnick, C.L.; Parikh, D. CIDEr: Consensus-based image description evaluation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Anderson, P.; Fernando, B.; Johnson, M.; Gould, S. Spice: Semantic propositional image caption evaluation. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 382–398. [Google Scholar]
- Wang, B.; Lu, X.; Zheng, X.; Li, X. Semantic descriptions of high-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1274–1278. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Z.; Ma, A.; Zhong, Y. Capformer: Pure Transformer for Remote Sensing Image Caption. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 7996–7999. [Google Scholar]
- Staniszewski, M.; Foszner, P.; Wereszczynski, K.; Michalczuk, A.; Polanski, A. Application of crowd simulations in the evaluation of tracking algorithms. Sensors 2020, 20, 4960. [Google Scholar] [CrossRef] [PubMed]
- Ciampi, L.; Messina, N.; Falchi, F.; Gennaro, C.; Amato, G. Virtual to Real Adaptation of Pedestrian Detectors. Sensors 2020, 20, 5250. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| METHOD | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGE-L | CIDEr | SPICE |
|---|---|---|---|---|---|---|---|---|
| CSMLF | 0.436 | 0.273 | 0.186 | 0.121 | 0.132 | 0.393 | 0.223 | 0.076 |
| Sound-a | 0.783 | 0.728 | 0.676 | 0.633 | 0.380 | 0.686 | 2.906 | 0.420 |
| RTRMN | 0.803 | 0.732 | 0.682 | 0.639 | 0.426 | 0.773 | 3.127 | 0.453 |
| SD-RSIC | 0.748 | 0.664 | 0.598 | 0.538 | 0.390 | 0.695 | 2.132 | - |
| DFEN (Ours) | 0.851 | 0.784 | 0.728 | 0.677 | 0.459 | 0.805 | 3.177 | 0.501 |
| METHOD | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGE-L | CIDEr | SPICE |
|---|---|---|---|---|---|---|---|---|
| CSMLF | 0.600 | 0.458 | 0.387 | 0.343 | 0.248 | 0.502 | 0.756 | 0.262 |
| sound-a | 0.716 | 0.632 | 0.547 | 0.466 | 0.313 | 0.604 | 1.803 | 0.387 |
| SD_RSIC | 0.761 | 0.666 | 0.586 | 0.517 | 0.366 | 0.657 | 1.690 | - |
| DFEN (Ours) | 0.798 | 0.697 | 0.614 | 0.542 | 0.373 | 0.723 | 2.009 | 0.449 |
| METHOD | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGE-L | CIDEr | SPICE |
|---|---|---|---|---|---|---|---|---|
| CSMLF | 0.576 | 0.386 | 0.283 | 0.222 | 0.213 | 0.446 | 0.530 | 0.200 |
| sound-a | 0.620 | 0.482 | 0.390 | 0.320 | 0.273 | 0.514 | 1.638 | 0.360 |
| RTRMN | 0.620 | 0.462 | 0.364 | 0.297 | 0.283 | 0.554 | 1.515 | 0.332 |
| SD_RSIC | 0.644 | 0.474 | 0.369 | 0.300 | 0.249 | 0.523 | 0.794 | - |
| CapFormer | 0.661 | 0.499 | 0.400 | 0.326 | - | 0.498 | 0.912 | - |
| DFEN (Ours) | 0.766 | 0.636 | 0.538 | 0.463 | 0.373 | 0.685 | 2.605 | 0.477 |
| DataSet | METHOD | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGE-L | CIDEr | SPICE |
|---|---|---|---|---|---|---|---|---|---|
| UCM | Baseline | 0.765 | 0.678 | 0.619 | 0.573 | 0.394 | 0.724 | 2.678 | 0.444 |
| Baseline-v | 0.770 | 0.685 | 0.627 | 0.579 | 0.406 | 0.735 | 2.736 | 0.472 | |
| Baseline-st | 0.833 | 0.759 | 0.701 | 0.651 | 0.456 | 0.800 | 3.168 | 0.494 | |
| DFEN | 0.851 | 0.784 | 0.728 | 0.677 | 0.459 | 0.805 | 3.177 | 0.501 | |
| Sydney | Baseline | 0.775 | 0.663 | 0.578 | 0.506 | 0.358 | 0.700 | 1.862 | 0.415 |
| Baseline-v | 0.784 | 0.673 | 0.583 | 0.508 | 0.356 | 0.713 | 1.939 | 0.438 | |
| Baseline-st | 0.780 | 0.683 | 0.610 | 0.553 | 0.368 | 0.715 | 1.979 | 0.450 | |
| DFEN | 0.798 | 0.697 | 0.614 | 0.542 | 0.373 | 0.723 | 2.009 | 0.449 | |
| RSICD | Baseline | 0.715 | 0.576 | 0.477 | 0.402 | 0.343 | 0.646 | 2.133 | 0.427 |
| Baseline-v | 0.727 | 0.584 | 0.484 | 0.410 | 0.334 | 0.643 | 2.184 | 0.422 | |
| Baseline-st | 0.758 | 0.626 | 0.526 | 0.45 | 0.359 | 0.679 | 2.566 | 0.478 | |
| DFEN | 0.766 | 0.636 | 0.538 | 0.463 | 0.373 | 0.685 | 2.605 | 0.477 |
| DataSet | Batch_Size | Training Time |
|---|---|---|
| UCM | 8 | 15.37 |
| 16 | 13.87 | |
| 32 | 15.93 |
| Model | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGE-L | CIDEr | SPICE |
|---|---|---|---|---|---|---|---|---|
| ResNet18 | 0.851 | 0.784 | 0.728 | 0.677 | 0.459 | 0.805 | 3.177 | 0.501 |
| ResNet34 | 0.856 | 0.786 | 0.727 | 0.671 | 0.458 | 0.813 | 3.176 | 0.510 |
| ResNet50 | 0.865 | 0.803 | 0.746 | 0.700 | 0.462 | 0.807 | 3.224 | 0.524 |
| ResNet101 | 0.862 | 0.797 | 0.742 | 0.694 | 0.453 | 0.805 | 3.194 | 0.498 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, W.; Yang, W.; Chen, D.; Wei, F. DFEN: Dual Feature Enhancement Network for Remote Sensing Image Caption. Electronics 2023, 12, 1547. https://doi.org/10.3390/electronics12071547
Zhao W, Yang W, Chen D, Wei F. DFEN: Dual Feature Enhancement Network for Remote Sensing Image Caption. Electronics. 2023; 12(7):1547. https://doi.org/10.3390/electronics12071547
Chicago/Turabian StyleZhao, Weihua, Wenzhong Yang, Danny Chen, and Fuyuan Wei. 2023. "DFEN: Dual Feature Enhancement Network for Remote Sensing Image Caption" Electronics 12, no. 7: 1547. https://doi.org/10.3390/electronics12071547
APA StyleZhao, W., Yang, W., Chen, D., & Wei, F. (2023). DFEN: Dual Feature Enhancement Network for Remote Sensing Image Caption. Electronics, 12(7), 1547. https://doi.org/10.3390/electronics12071547