
Multi-USV Dynamic Navigation and Target Capture: A Guided Multi-Agent Reinforcement Learning Approach


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- A novel formulation of the MPE problem as a multi-USV operation in a floating city environment that can be applied in target pursuit in multi-intersection urban areas.
- We develop a hybrid deep reinforcement learning framework that leverages heuristic mechanisms to guide group mission learning of multiple unmanned surface vehicles. The proposed framework consists of subgoal generation in the form of navigation targets based on the knowledge of the environment, and a goal selection heuristic model based on immune network models is used to select subgoals for execution by an actor-critic proximal policy optimization model.
- A simulation experiment is conducted to analyze the performance of the proposed framework in realizing the target-capturing behavior of a multi-USV group.
2. Preliminaries
2.1. Multi-Agent Observation Models
2.2. Partially Observable Stochastic Games
- n is the number of agents (controller agents or USVs);
- S is the finite set of states;
- are the finite set of actions available to the agents which form the joint action set ;
- are the finite set of observations of the agents. The joint observation is denoted as ;
- is the Markovian state transition function, where denotes the probability of reaching state after the joint action in state s. The joint action of all agents at a stage t is denoted as ;
- , are the reward functions of the agents.
Proximal Policy Optimization
2.3. The Artificial Immune Network
3. Problem Formulation
3.1. Description of the Multi-USV Target Capture
3.2. The Multi-USV Learning Formulation
Reward Function
3.3. Intruder Boat Policy Strategy
4. Approach
4.1. Framework Design
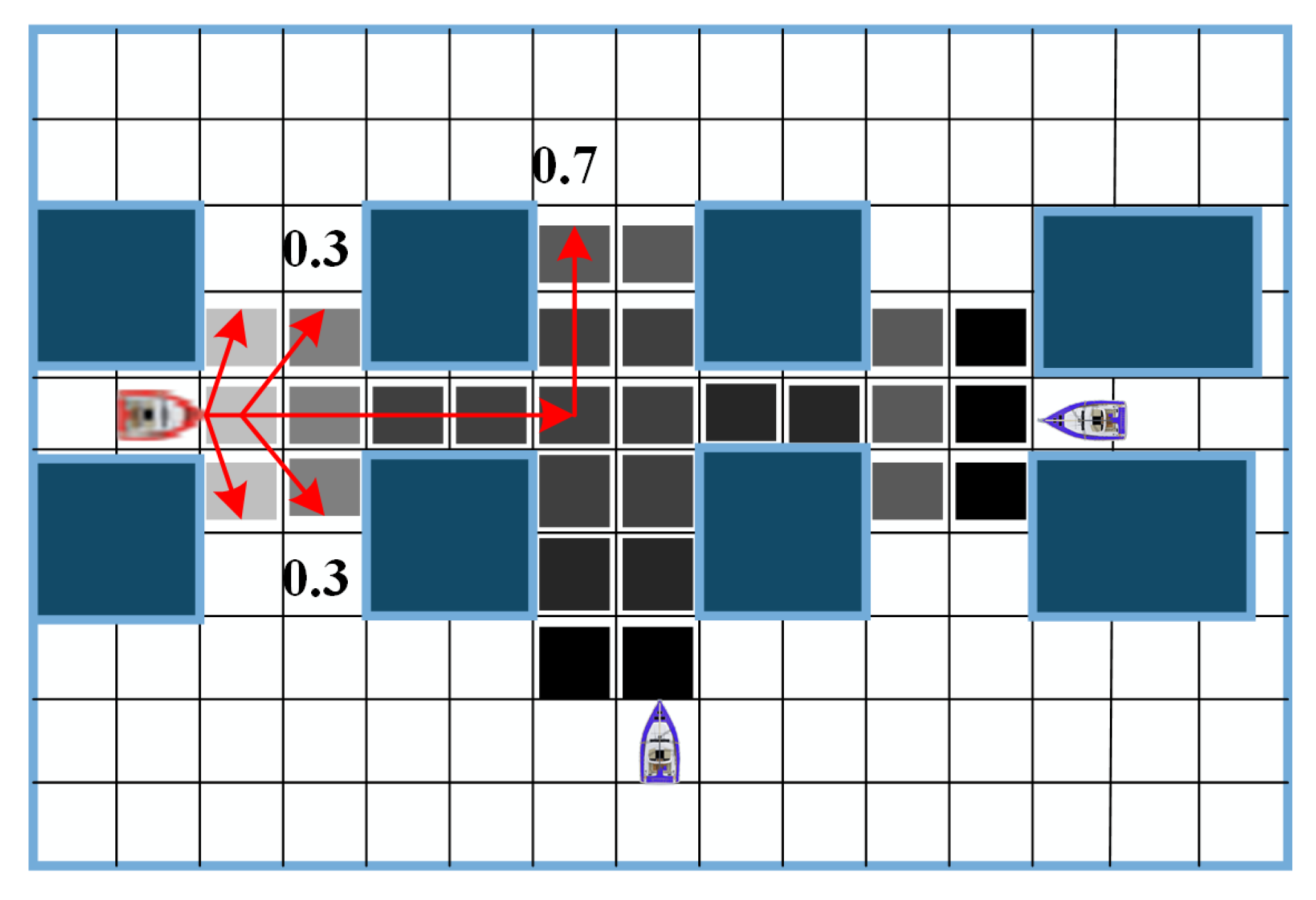
4.2. Goal Selection Algorithm
| Algorithm 1: Subgoal (navigation point) selection algorithm. |
 |
4.3. Task Execution Policy Learning
| Algorithm 2: Proximal policy optimization training. |
 |
5. Experiment and Results
5.1. USV Physical Model
5.2. USV Dynamic Model
- is a vector of the position and Euler angles in the m-frame;
- is a vector of the linear and angular velocities in the d-frame;
- is the hydrodynamic terms of the relative velocities vector (i.e., the difference between the vessel velocity relative to the fluid velocity and the marine currents expressed in the reference frame);
- represents the forces and moments of environmental disturbances of superimposed wind, currents, and waves;
- The parameters J, M, D, and C are the rotational transformation, inertia, damping, and coriolis and centric fugal matrices, respectively.
5.3. Experimental Settings
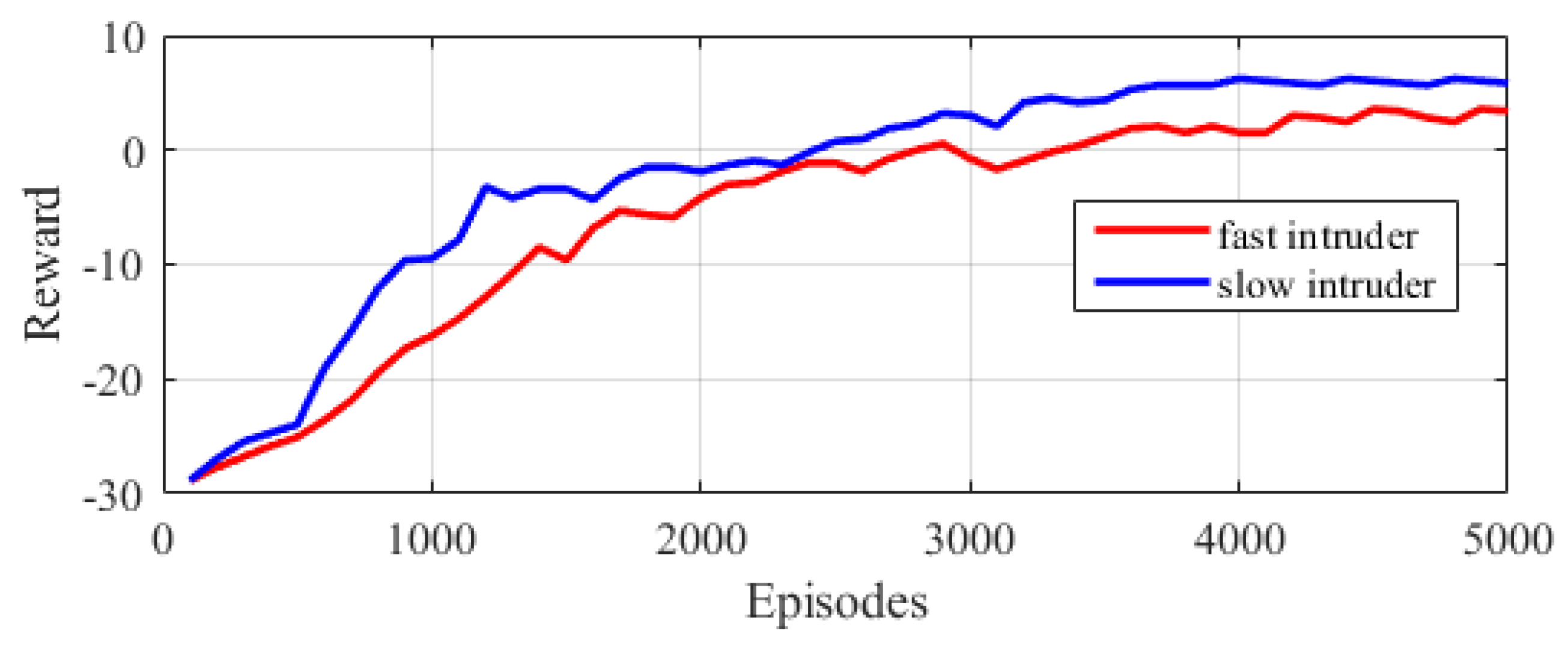
5.4. Experimental Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Berns, K.; Nezhadfard, A.; Tosa, M.; Balta, H.; Cubber, G.D. Unmanned Ground Robots for Rescue Tasks; IntechOpen Limited: London, UK, 2017. [Google Scholar] [CrossRef]
- Martz, J.; Al-Sabban, W.; Smith, R.N. Survey of unmanned subterranean exploration, navigation, and localisation. IET Cyber Syst. Robot. 2020, 2, 1–13. [Google Scholar] [CrossRef]
- Winston, C. Autonomous Vehicles Could Improve Policing, Public Safety, and Much More. Available online: https://www.brookings.edu/blog/techtank/2020/08/25/autonomous-vehicles-could-improve-policing-public-safety-and-much-more/ (accessed on 7 February 2023).
- Wolf, M.; Rahmani, A.; de la Croix, J.; Woodward, G.; Hook, J.V.; Brown, D.; Schaffer, S.; Lim, C.; Bailey, P.; Tepsuporn, S.; et al. CARACaS multi-agent maritime autonomy for unmanned surface vehicles in the Swarm II harbor patrol demonstration. In Proceedings of the Unmanned Systems Technology XIX, Anaheim, CA, USA, 11–13 April 2017; Karlsen, R.E., Gage, D.W., Shoemaker, C.M., Nguyen, H.G., Eds.; International Society for Optics and Photonics. SPIE: Washington, DC, USA, 2017; Volume 10195, pp. 218–228. [Google Scholar]
- Maritime Executive, T. [Video] Demonstration of Autonomous Vessel Operations. Available online: https://maritime/-executive.com/article/video-demonstration-of-autonomous-vessel-operations (accessed on 7 February 2023).
- Eshel, T. Unmanned Boats Demonstrate Autonomous Swarm, Gunnery Support Techniques—Defense Update. Available online: https://defenseupdate.com/20141006_usv_demo.html (accessed on 7 February 2023).
- Zhang, T.; Li, Q.; Zhang, C.S.; Liang, H.W.; Li, P.; Wang, T.M.; Li, S.; Zhu, Y.L.; Wu, C. Current trends in the development of intelligent unmanned autonomous systems. Front. Inf. Technol. Electron. Eng. 2017, 18, 68–85. [Google Scholar] [CrossRef]
- Howard, A.; Parker, L.E.; Sukhatme, G.S. The SDR Experience: Experiments with a Large-Scale Heterogeneous Mobile Robot Team. In Proceedings of the Experimental Robotics IX, New York, NY, USA, 2–4 March 2006; Ang, M.H., Khatib, O., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 121–130. [Google Scholar]
- Liu, Y.; Song, R.; Bucknall, R.; Zhang, X. Intelligent multi-task allocation and planning for multiple unmanned surface vehicles (USVs) using self-organising maps and fast marching method. Inf. Sci. 2019, 496, 180–197. [Google Scholar] [CrossRef]
- Xue, K.; Huang, Z.; Wang, P.; Xu, Z. An Exact Algorithm for Task Allocation of Multiple Unmanned Surface Vehicles with Minimum Task Time. J. Mar. Sci. Eng. 2021, 9, 907. [Google Scholar] [CrossRef]
- Antonyshyn, L.; Silveira, J.; Givigi, S.; Marshall, J. Multiple Mobile Robot Task and Motion Planning: A Survey. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Cortés, J.; Egerstedt, M. Coordinated Control of Multi-Robot Systems: A Survey. SICE J. Control Meas. Syst. Integr. 2017, 10, 495–503. [Google Scholar] [CrossRef]
- Balhara, S.; Gupta, N.; Alkhayyat, A.; Bharti, I.; Malik, R.Q.; Mahmood, S.N.; Abedi, F. A survey on deep reinforcement learning architectures, applications and emerging trends. IET Commun. 2022; early access. [Google Scholar] [CrossRef]
- Wang, X.; Wang, S.; Liang, X.; Zhao, D.; Huang, J.; Xu, X.; Dai, B.; Miao, Q. Deep Reinforcement Learning: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–15. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6382–6393. [Google Scholar]
- Setyawan, G.E.; Hartono, P.; Sawada, H. Cooperative Multi-Robot Hierarchical Reinforcement Learning. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 2022. [Google Scholar] [CrossRef]
- Xia, J.; Luo, Y.; Liu, Z.; Zhang, Y.; Shi, H.; Liu, Z. Cooperative multi-target hunting by unmanned surface vehicles based on multi-agent reinforcement learning. Def. Technol. 2022, in press. [Google Scholar] [CrossRef]
- Bansal, T.; Pachocki, J.; Sidor, S.; Sutskever, I.; Mordatch, I. Emergent Complexity via Multi-Agent Competition. arXiv. 2017. Available online: https://arxiv.org/abs/1710.03748 (accessed on 7 February 2023).
- Zhao, W.; Chu, H.; Miao, X.; Guo, L.; Shen, H.; Zhu, C.; Zhang, F.; Liang, D. Research on the Multiagent Joint Proximal Policy Optimization Algorithm Controlling Cooperative Fixed-Wing UAV Obstacle Avoidance. Sensors 2020, 20, 4546. [Google Scholar] [CrossRef]
- Han, R.; Chen, S.; Hao, Q. Cooperative Multi-Robot Navigation in Dynamic Environment with Deep Reinforcement Learning. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 448–454. [Google Scholar] [CrossRef]
- Long, P.; Fan, T.; Liao, X.; Liu, W.; Zhang, H.; Pan, J. Towards Optimally Decentralized Multi-Robot Collision Avoidance via Deep Reinforcement Learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 6252–6259. [Google Scholar] [CrossRef]
- Wen, J.; Liu, S.; Lin, Y. Dynamic Navigation and Area Assignment of Multiple USVs Based on Multi-Agent Deep Reinforcement Learning. Sensors 2022, 22, 6942. [Google Scholar] [CrossRef] [PubMed]
- Awheda, M.D.; Schwartz, H.M. Decentralized learning in pursuit-evasion differential games with multi-pursuer and single-superior evader. In Proceedings of the 2016 Annual IEEE Systems Conference (SysCon), Orlando, FL, USA, 18–21 April 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Yuan, Z.; Wu, T.; Wang, Q.; Yang, Y.; Li, L.; Zhang, L. T3OMVP: A Transformer-Based Time and Team Reinforcement Learning Scheme for Observation-Constrained Multi-Vehicle Pursuit in Urban Area. Electronics 2022, 11, 1339. [Google Scholar] [CrossRef]
- Liang, L.; Deng, F.; Lu, M.; Chen, J. Analysis of Role Switch for Cooperative Target Defense Differential Game. IEEE Trans. Autom. Control 2021, 66, 902–909. [Google Scholar] [CrossRef]
- Li, W. A Dynamics Perspective of Pursuit-Evasion: Capturing and Escaping When the Pursuer Runs Faster Than the Agile Evader. IEEE Trans. Autom. Control 2017, 62, 451–457. [Google Scholar] [CrossRef]
- Li, Y.; He, J.; Chen, C.; Guan, X. Intelligent Physical Attack Against Mobile Robots With Obstacle-Avoidance. IEEE Trans. Robot. 2023, 39, 253–272. [Google Scholar] [CrossRef]
- Xu, Y.; Yang, H.; Jiang, B.; Polycarpou, M.M. Multiplayer Pursuit-Evasion Differential Games With Malicious Pursuers. IEEE Trans. Autom. Control 2022, 67, 4939–4946. [Google Scholar] [CrossRef]
- Wei, W.; Wang, J.; Du, J.; Fang, Z.; Jiang, C.; Ren, Y. Underwater Differential Game: Finite-Time Target Hunting Task with Communication Delay. In Proceedings of the ICC 2022—IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; pp. 3989–3994. [Google Scholar] [CrossRef]
- Pan, T.; Yuan, Y. A Region-Based Relay Pursuit Scheme for a Pursuit–Evasion Game With a Single Evader and Multiple Pursuers. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 1958–1969. [Google Scholar] [CrossRef]
- Ye, J.; Wang, Q.; Ma, B.; Wu, Y.; Xue, L. A Pursuit Strategy for Multi-Agent Pursuit-Evasion Game via Multi-Agent Deep Deterministic Policy Gradient Algorithm. In Proceedings of the 2022 IEEE International Conference on Unmanned Systems (ICUS), Guangzhou, China, 28–30 October 2022; pp. 418–423. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, K.; Ye, J.; Wu, Y.; Xue, L. Apollonius Partitions Based Pursuit-evasion Game Strategies by Q-Learning Approach. In Proceedings of the 2022 41st Chinese Control Conference (CCC), Hefei, China, 25–27 July 2022; pp. 4843–4848. [Google Scholar] [CrossRef]
- Sidney N Givigi, J.; Schwartz, H.M. Decentralized strategy selection with learning automata for multiple pursuer–evader games. Adapt. Behav. 2014, 22, 221–234. [Google Scholar] [CrossRef]
- Wang, H.; Yue, Q.; Liu, J. Research on Pursuit-evasion games with multiple heterogeneous pursuers and a high speed evader. In Proceedings of the 27th Chinese Control and Decision Conference (2015 CCDC), Qingdao, China, 23–25 May 2015; pp. 4366–4370. [Google Scholar] [CrossRef]
- Du, W.; Guo, T.; Chen, J.; Li, B.; Zhu, G.; Cao, X. Cooperative pursuit of unauthorized UAVs in urban airspace via Multi-agent reinforcement learning. Transp. Res. Part Emerg. Technol. 2021, 128, 103122. [Google Scholar] [CrossRef]
- Zhang, R.; Zong, Q.; Zhang, X.; Dou, L.; Tian, B. Game of Drones: Multi-UAV Pursuit-Evasion Game With Online Motion Planning by Deep Reinforcement Learning. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–10. [Google Scholar] [CrossRef]
- Özkahraman, Ö.; Ögren, P. 3D Pursuit-Evasion for AUVs. Researchgate. 2018. Available online: https://www.researchgate.net/publication/327903971_3D_Pursuit-Evasion_for_AUVs (accessed on 7 February 2023).
- Liang, X.; Wang, H.; Luo, H. Collaborative Pursuit-Evasion Strategy of UAV/UGV Heterogeneous System in Complex Three-Dimensional Polygonal Environment. Complexity 2020, 2020, 7498740. [Google Scholar] [CrossRef]
- de Souza, C.; Newbury, R.; Cosgun, A.; Castillo, P.; Vidolov, B.; Kulić, D. Decentralized Multi-Agent Pursuit Using Deep Reinforcement Learning. IEEE Robot. Autom. Lett. 2021, 6, 4552–4559. [Google Scholar] [CrossRef]
- Ma, J.; Lu, H.; Xiao, J.; Zeng, Z.; Zheng, Z. Multi-robot Target Encirclement Control with Collision Avoidance via Deep Reinforcement Learning. J. Intell. Robot. Syst. 2020, 99, 371–386. [Google Scholar] [CrossRef]
- Zhang, T.; Liu, Z.; Wu, S.; Pu, Z.; Yi, J. Multi-Robot Cooperative Target Encirclement through Learning Distributed Transferable Policy. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Bernstein, D.S.; Zilberstein, S.; Immerman, N. The Complexity of Decentralized Control of Markov Decision Processes. In Proceedings of the Sixteenth Conference on Uncertainty in Artificial Intelligence, San Francisco, CA, USA, 30 June– 3 July 2000; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2000; pp. 32–37. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust Region Policy Optimization. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. Available online: https://arxiv.org/abs/1707.06347 (accessed on 7 February 2023).
- Heess, N.M.O.; Dhruva, T.; Sriram, S.; Lemmon, J.; Merel, J.; Wayne, G.; Tassa, Y.; Erez, T.; Wang, Z.; Eslami, S.M.A.; et al. Emergence of Locomotion Behaviours in Rich Environments. arXiv 2017, arXiv:1707.02286. Available online: https://arxiv.org/pdf/1707.02286.pdf (accessed on 7 February 2023).
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Harley, T.; Lillicrap, T.P.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Jerne, N.K. Towards a network theory of the immune system. Ann. D’Immunologie 1973, 125C, 373–389. [Google Scholar] [PubMed]
- Farmer, J.; Packard, N.H.; Perelson, A.S. The immune system, adaptation, and machine learning. Phys. Nonlinear Phenom. 1986, 22, 187–204. [Google Scholar] [CrossRef]
- Nantogma, S.; Pan, K.; Song, W.; Luo, R.; Xu, Y. Towards Realizing Intelligent Coordinated Controllers for Multi-USV Systems Using Abstract Training Environments. J. Mar. Sci. Eng. 2021, 9, 560. [Google Scholar] [CrossRef]
- McCue, L. Handbook of Marine Craft Hydrodynamics and Motion Control [Bookshelf]. IEEE Control Syst. Mag. 2016, 36, 78–79. [Google Scholar] [CrossRef]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nantogma, S.; Zhang, S.; Yu, X.; An, X.; Xu, Y. Multi-USV Dynamic Navigation and Target Capture: A Guided Multi-Agent Reinforcement Learning Approach. Electronics 2023, 12, 1523. https://doi.org/10.3390/electronics12071523
Nantogma S, Zhang S, Yu X, An X, Xu Y. Multi-USV Dynamic Navigation and Target Capture: A Guided Multi-Agent Reinforcement Learning Approach. Electronics. 2023; 12(7):1523. https://doi.org/10.3390/electronics12071523
Chicago/Turabian StyleNantogma, Sulemana, Shangyan Zhang, Xuewei Yu, Xuyang An, and Yang Xu. 2023. "Multi-USV Dynamic Navigation and Target Capture: A Guided Multi-Agent Reinforcement Learning Approach" Electronics 12, no. 7: 1523. https://doi.org/10.3390/electronics12071523
APA StyleNantogma, S., Zhang, S., Yu, X., An, X., & Xu, Y. (2023). Multi-USV Dynamic Navigation and Target Capture: A Guided Multi-Agent Reinforcement Learning Approach. Electronics, 12(7), 1523. https://doi.org/10.3390/electronics12071523